 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Efficient Self-supervised Learning with Contextualized Target Representations for Vision, Speech and Language
Dec 14, 2022
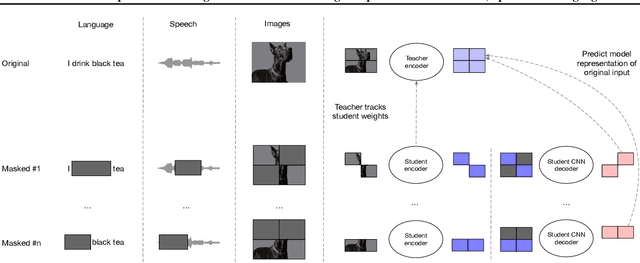
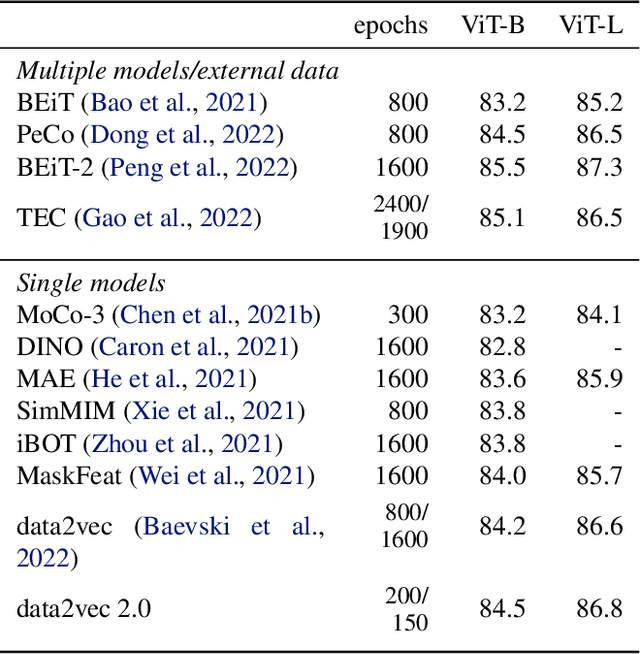
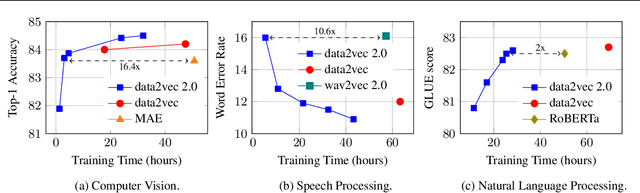

Current self-supervised learning algorithms are often modality-specific and require large amounts of computational resources. To address these issues, we increase the training efficiency of data2vec, a learning objective that generalizes across several modalities. We do not encode masked tokens, use a fast convolutional decoder and amortize the effort to build teacher representations. data2vec 2.0 benefits from the rich contextualized target representations introduced in data2vec which enable a fast self-supervised learner. Experiments on ImageNet-1K image classification show that data2vec 2.0 matches the accuracy of Masked Autoencoders in 16.4x lower pre-training time, on Librispeech speech recognition it performs as well as wav2vec 2.0 in 10.6x less time, and on GLUE natural language understanding it matches a retrained RoBERTa model in half the time. Trading some speed for accuracy results in ImageNet-1K top-1 accuracy of 86.8\% with a ViT-L model trained for 150 epochs.
Convolutional Speech Recognition with Pitch and Voice Quality Features
Sep 02, 2020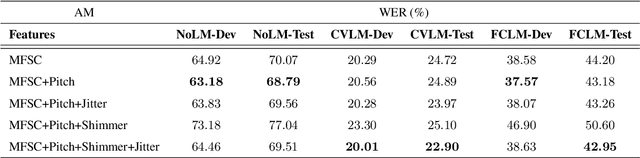
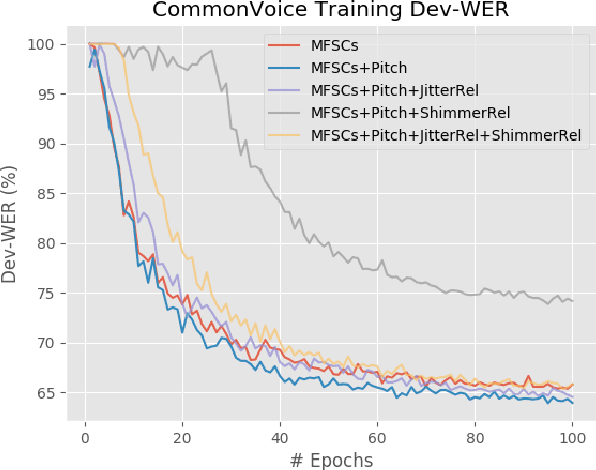
The effects of adding pitch and voice quality features such as jitter and shimmer to a state-of-the-art CNN model for Automatic Speech Recognition are studied in this work. Pitch features have been previously used for improving classical HMM and DNN baselines, while jitter and shimmer parameters have proven to be useful for tasks like speaker or emotion recognition. Up to our knowledge, this is the first work combining such pitch and voice quality features with modern convolutional architectures, showing improvements up to 2% absolute WER points, for the publicly available Spanish Common Voice dataset. Particularly, our work combines these features with mel-frequency spectral coefficients (MFSCs) to train a convolutional architecture with Gated Linear Units (Conv GLUs). Such models have shown to yield small word error rates, while being very suitable for parallel processing for online streaming recognition use cases. We have added pitch and voice quality functionality to Facebook's wav2letter speech recognition framework, and we provide with such code and recipes to the community, to carry on with further experiments. Besides, to the best of our knowledge, our Spanish Common Voice recipe is the first public Spanish recipe for wav2letter.
Detection of Cross-Dataset Fake Audio Based on Prosodic and Pronunciation Features
May 23, 2023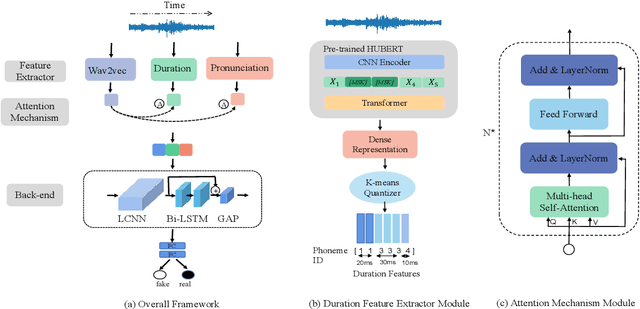
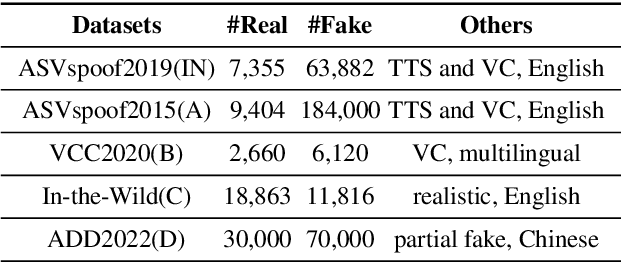
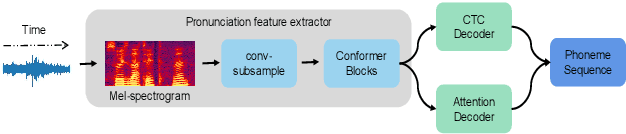

Existing fake audio detection systems perform well in in-domain testing, but still face many challenges in out-of-domain testing. This is due to the mismatch between the training and test data, as well as the poor generalizability of features extracted from limited views. To address this, we propose multi-view features for fake audio detection, which aim to capture more generalized features from prosodic, pronunciation, and wav2vec dimensions. Specifically, the phoneme duration features are extracted from a pre-trained model based on a large amount of speech data. For the pronunciation features, a Conformer-based phoneme recognition model is first trained, keeping the acoustic encoder part as a deeply embedded feature extractor. Furthermore, the prosodic and pronunciation features are fused with wav2vec features based on an attention mechanism to improve the generalization of fake audio detection models. Results show that the proposed approach achieves significant performance gains in several cross-dataset experiments.
Federated Acoustic Modeling For Automatic Speech Recognition
Feb 08, 2021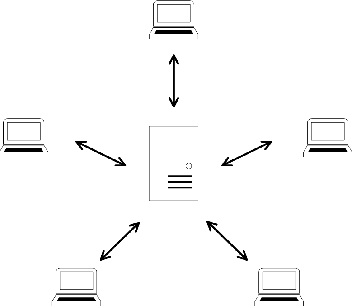

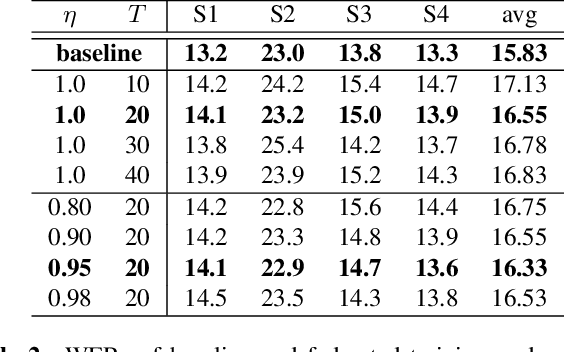

Data privacy and protection is a crucial issue for any automatic speech recognition (ASR) service provider when dealing with clients. In this paper, we investigate federated acoustic modeling using data from multiple clients. A client's data is stored on a local data server and the clients communicate only model parameters with a central server, and not their data. The communication happens infrequently to reduce the communication cost. To mitigate the non-iid issue, client adaptive federated training (CAFT) is proposed to canonicalize data across clients. The experiments are carried out on 1,150 hours of speech data from multiple domains. Hybrid LSTM acoustic models are trained via federated learning and their performance is compared to traditional centralized acoustic model training. The experimental results demonstrate the effectiveness of the proposed federated acoustic modeling strategy. We also show that CAFT can further improve the performance of the federated acoustic model.
Improving Transformer-based Speech Recognition Using Unsupervised Pre-training
Oct 22, 2019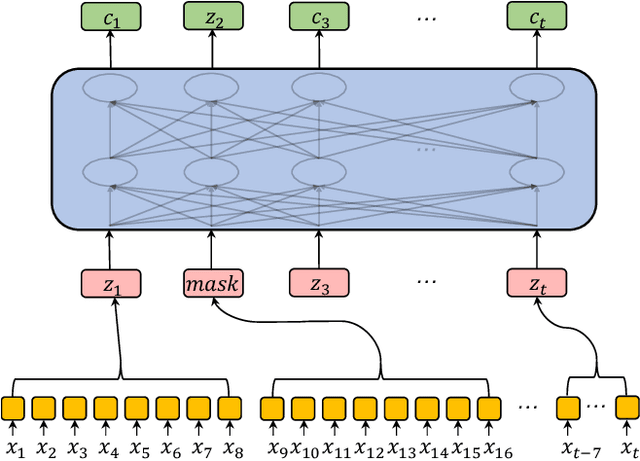
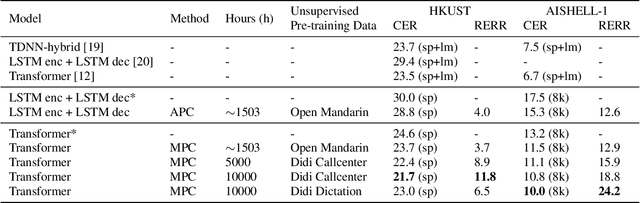
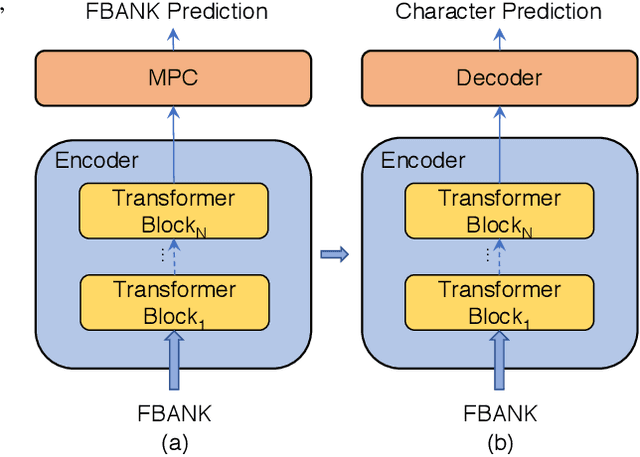
Speech recognition technologies are gaining enormous popularity in various industrial applications. However, building a good speech recognition system usually requires significant amounts of transcribed data which is expensive to collect. To tackle this problem, we propose a novel unsupervised pre-training method called masked predictive coding, which can be applied for unsupervised pre-training with Transformer based model. Experiments on HKUST show that using the same training data and other open source Mandarin data, we can reduce CER of a strong Transformer based baseline by 3.7%. With the same setup, we can reduce CER of AISHELL-1 by 12.9%.
Tree-constrained Pointer Generator for End-to-end Contextual Speech Recognition
Sep 17, 2021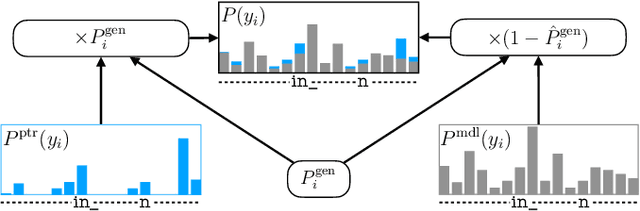

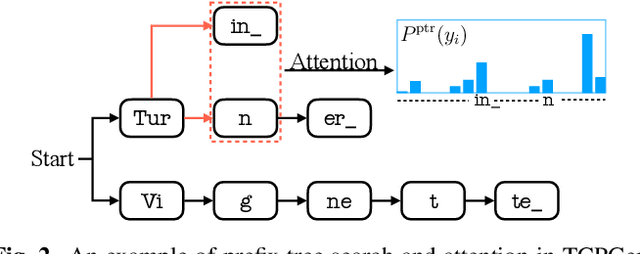
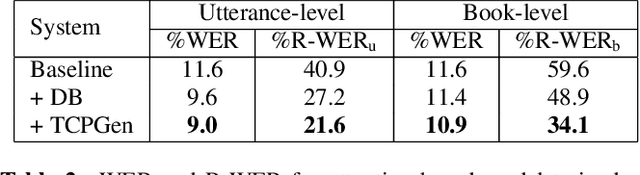
Contextual knowledge is important for real-world automatic speech recognition (ASR) applications. In this paper, a novel tree-constrained pointer generator (TCPGen) component is proposed that incorporates such knowledge as a list of biasing words into both attention-based encoder-decoder and transducer end-to-end ASR models in a neural-symbolic way. TCPGen structures the biasing words into an efficient prefix tree to serve as its symbolic input and creates a neural shortcut between the tree and the final ASR output distribution to facilitate recognising biasing words during decoding. Systems were trained and evaluated on the Librispeech corpus where biasing words were extracted at the scales of an utterance, a chapter, or a book to simulate different application scenarios. Experimental results showed that TCPGen consistently improved word error rates (WERs) compared to the baselines, and in particular, achieved significant WER reductions on the biasing words. TCPGen is highly efficient: it can handle 5,000 biasing words and distractors and only add a small overhead to memory use and computation cost.
Fast offline Transformer-based end-to-end automatic speech recognition for real-world applications
Jan 14, 2021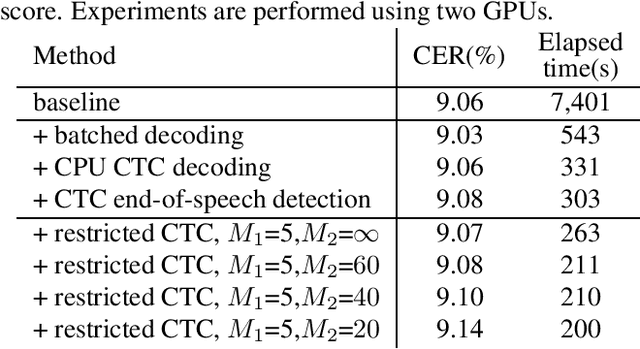
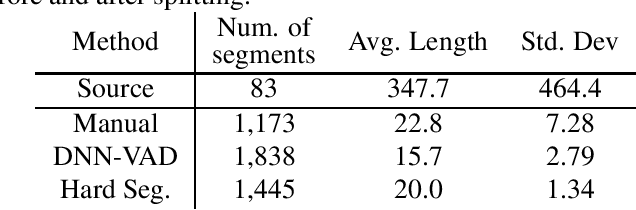
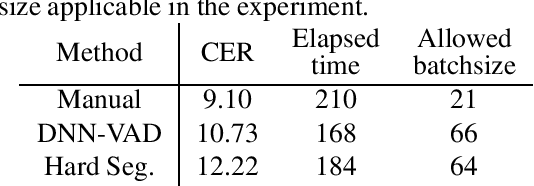
Many real-world applications require to convert speech files into text with high accuracy with limited resources. This paper proposes a method to recognize large speech database fast using the Transformer-based end-to-end model. Transfomers have improved the state-of-the-art performance in many fields as well as speech recognition. But it is not easy to be used for long sequences. In this paper, various techniques to speed up the recognition of real-world speeches are proposed and tested including parallelizing the recognition using batched beam search, detecting end-of-speech based on connectionist temporal classification (CTC), restricting CTC prefix score and splitting long speeches into short segments. Experiments are conducted with real-world Korean speech recognition task. Experimental results with an 8-hour test corpus show that the proposed system can convert speeches into text in less than 3 minutes with 10.73% character error rate which is 27.1% relatively low compared to conventional DNN-HMM based recognition system.
StarGAN-VC+ASR: StarGAN-based Non-Parallel Voice Conversion Regularized by Automatic Speech Recognition
Aug 10, 2021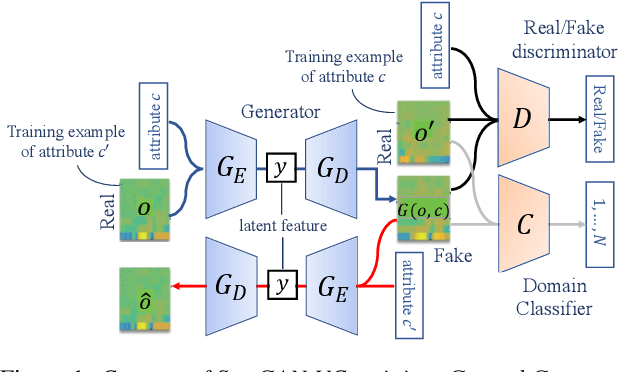
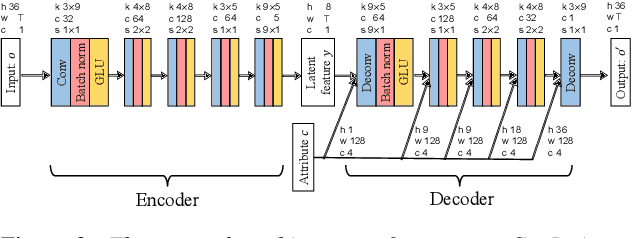
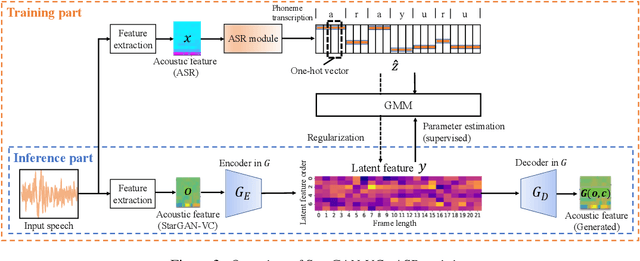
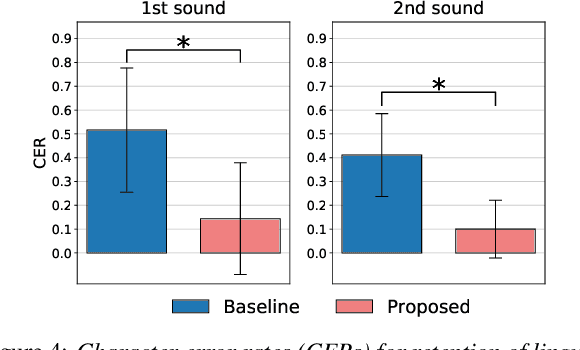
Preserving the linguistic content of input speech is essential during voice conversion (VC). The star generative adversarial network-based VC method (StarGAN-VC) is a recently developed method that allows non-parallel many-to-many VC. Although this method is powerful, it can fail to preserve the linguistic content of input speech when the number of available training samples is extremely small. To overcome this problem, we propose the use of automatic speech recognition to assist model training, to improve StarGAN-VC, especially in low-resource scenarios. Experimental results show that using our proposed method, StarGAN-VC can retain more linguistic information than vanilla StarGAN-VC.
Training Autoregressive Speech Recognition Models with Limited in-domain Supervision
Oct 27, 2022
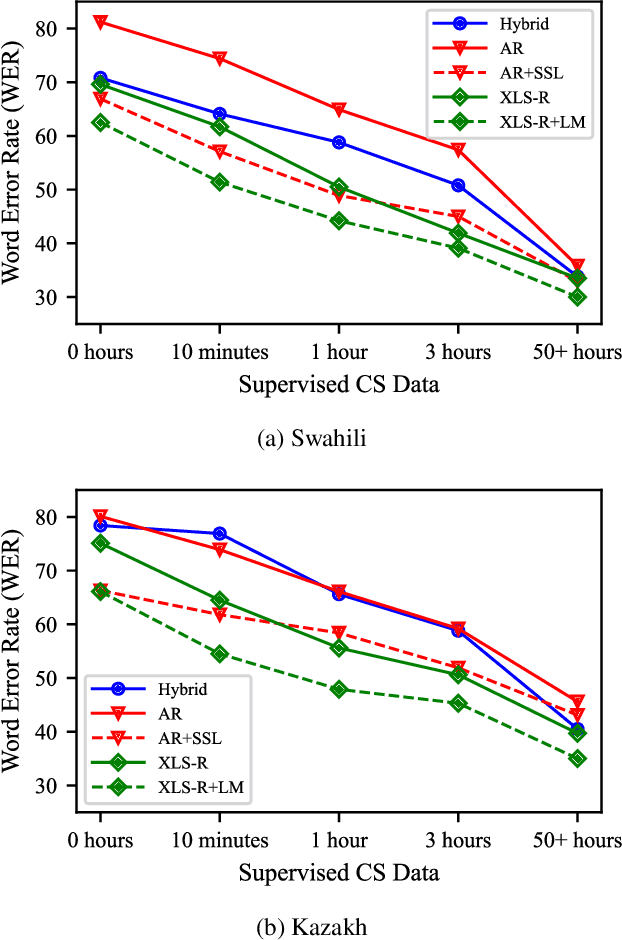

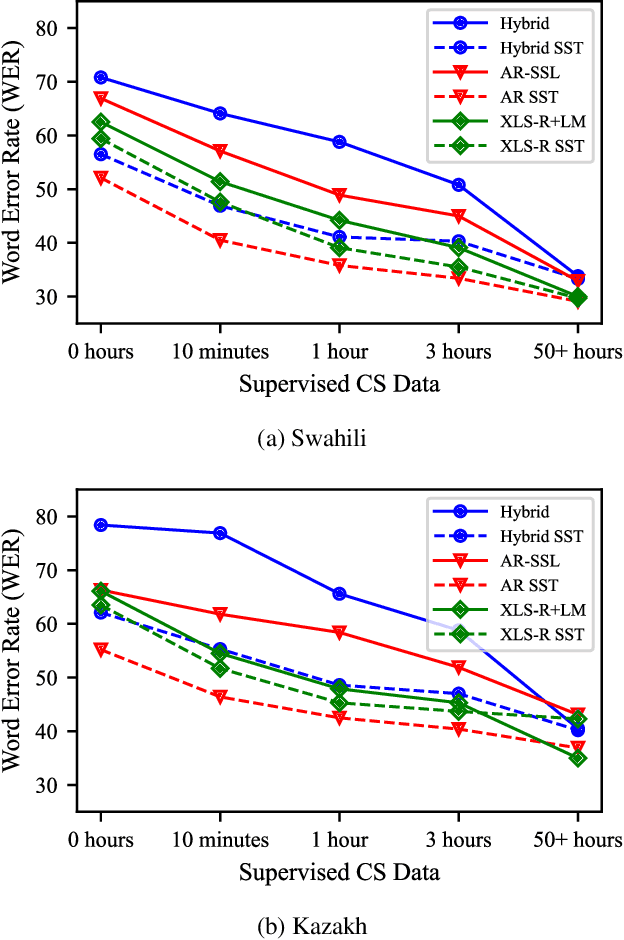
Advances in self-supervised learning have significantly reduced the amount of transcribed audio required for training. However, the majority of work in this area is focused on read speech. We explore limited supervision in the domain of conversational speech. While we assume the amount of in-domain data is limited, we augment the model with open source read speech data. The XLS-R model has been shown to perform well with limited adaptation data and serves as a strong baseline. We use untranscribed data for self-supervised learning and semi-supervised training in an autoregressive encoder-decoder model. We demonstrate that by using the XLS-R model for pseudotranscription, a much smaller autoregressive model can outperform a finetuned XLS-R model when transcribed in-domain data is limited, reducing WER by as much as 8% absolute.
Memory-efficient Speech Recognition on Smart Devices
Feb 23, 2021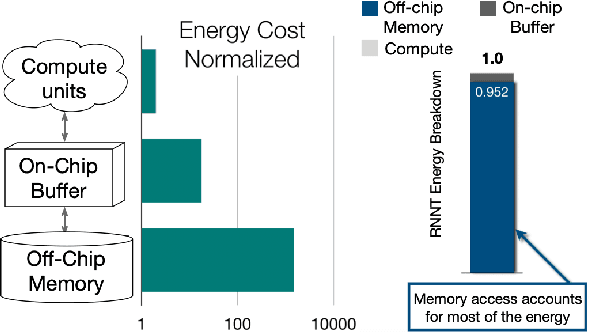
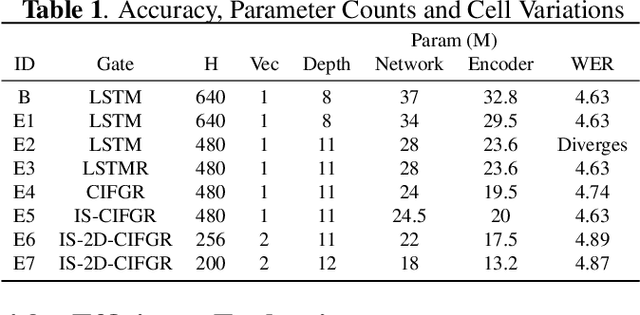
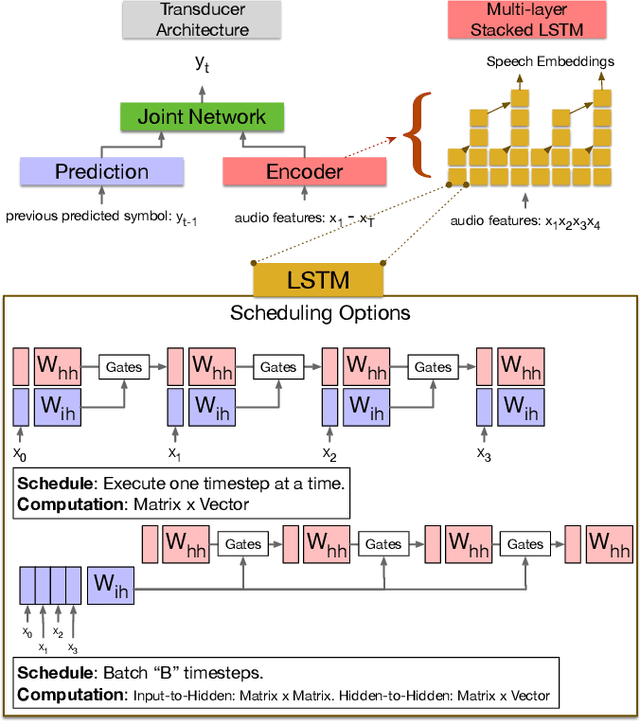
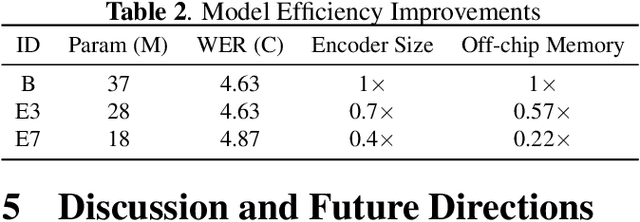
Recurrent transducer models have emerged as a promising solution for speech recognition on the current and next generation smart devices. The transducer models provide competitive accuracy within a reasonable memory footprint alleviating the memory capacity constraints in these devices. However, these models access parameters from off-chip memory for every input time step which adversely effects device battery life and limits their usability on low-power devices. We address transducer model's memory access concerns by optimizing their model architecture and designing novel recurrent cell designs. We demonstrate that i) model's energy cost is dominated by accessing model weights from off-chip memory, ii) transducer model architecture is pivotal in determining the number of accesses to off-chip memory and just model size is not a good proxy, iii) our transducer model optimizations and novel recurrent cell reduces off-chip memory accesses by 4.5x and model size by 2x with minimal accuracy impact.