 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
wav2letter++: The Fastest Open-source Speech Recognition System
Dec 18, 2018
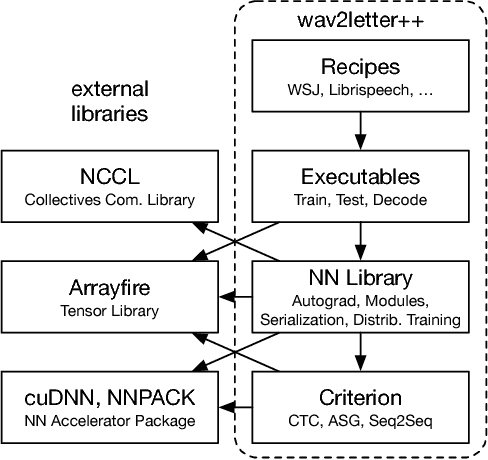
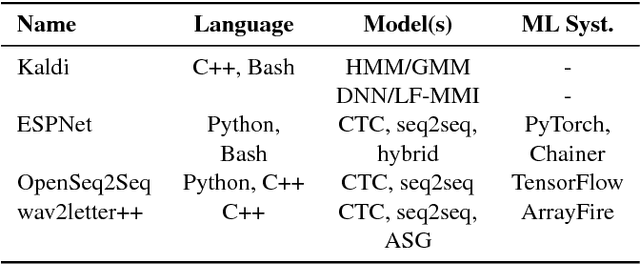

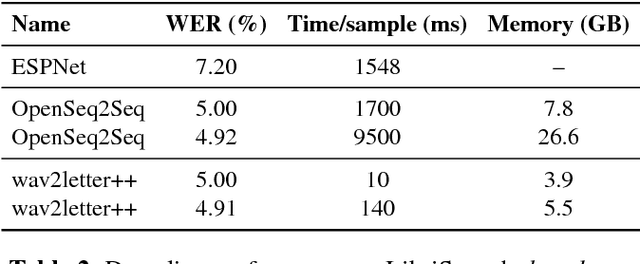
This paper introduces wav2letter++, the fastest open-source deep learning speech recognition framework. wav2letter++ is written entirely in C++, and uses the ArrayFire tensor library for maximum efficiency. Here we explain the architecture and design of the wav2letter++ system and compare it to other major open-source speech recognition systems. In some cases wav2letter++ is more than 2x faster than other optimized frameworks for training end-to-end neural networks for speech recognition. We also show that wav2letter++'s training times scale linearly to 64 GPUs, the highest we tested, for models with 100 million parameters. High-performance frameworks enable fast iteration, which is often a crucial factor in successful research and model tuning on new datasets and tasks.
Multiple-hypothesis CTC-based semi-supervised adaptation of end-to-end speech recognition
Mar 31, 2021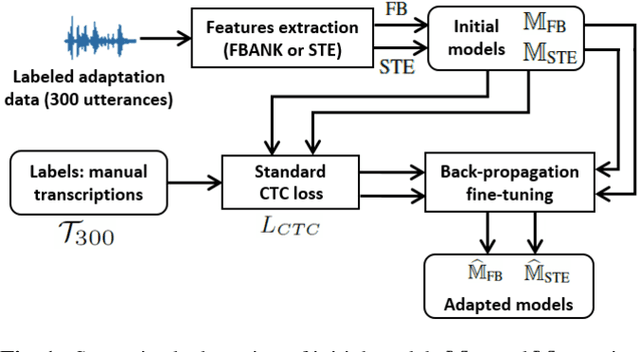

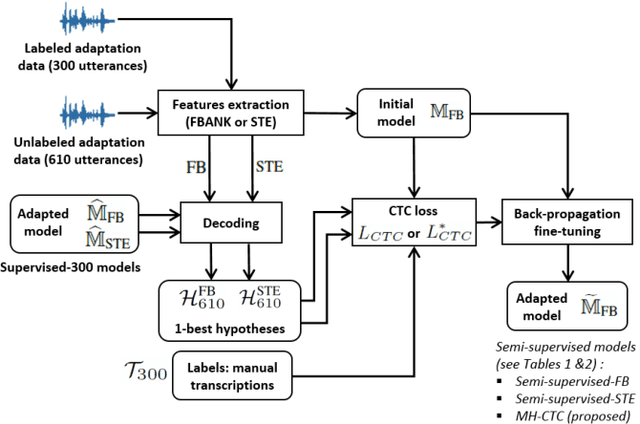
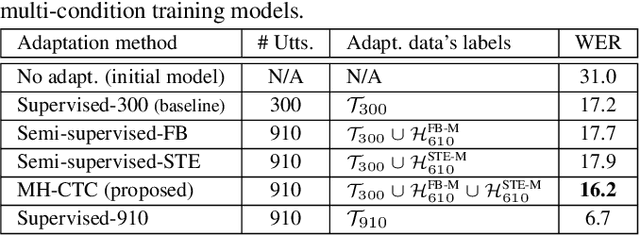
This paper proposes an adaptation method for end-to-end speech recognition. In this method, multiple automatic speech recognition (ASR) 1-best hypotheses are integrated in the computation of the connectionist temporal classification (CTC) loss function. The integration of multiple ASR hypotheses helps alleviating the impact of errors in the ASR hypotheses to the computation of the CTC loss when ASR hypotheses are used. When being applied in semi-supervised adaptation scenarios where part of the adaptation data do not have labels, the CTC loss of the proposed method is computed from different ASR 1-best hypotheses obtained by decoding the unlabeled adaptation data. Experiments are performed in clean and multi-condition training scenarios where the CTC-based end-to-end ASR systems are trained on Wall Street Journal (WSJ) clean training data and CHiME-4 multi-condition training data, respectively, and tested on Aurora-4 test data. The proposed adaptation method yields 6.6% and 5.8% relative word error rate (WER) reductions in clean and multi-condition training scenarios, respectively, compared to a baseline system which is adapted with part of the adaptation data having manual transcriptions using back-propagation fine-tuning.
BembaSpeech: A Speech Recognition Corpus for the Bemba Language
Feb 09, 2021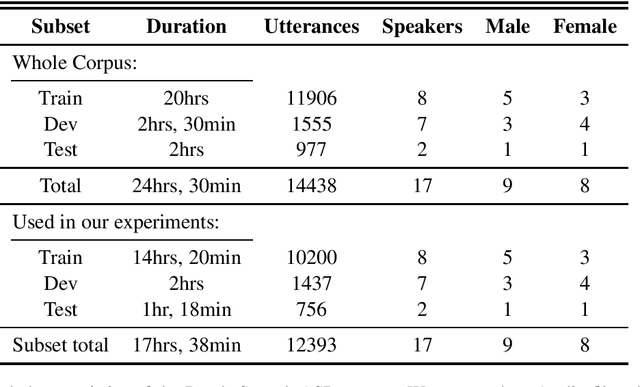

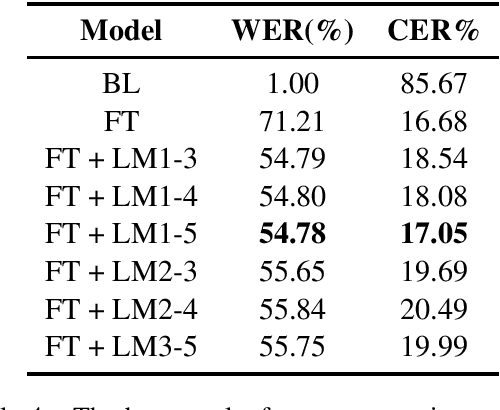
We present a preprocessed, ready-to-use automatic speech recognition corpus, BembaSpeech, consisting over 24 hours of read speech in the Bemba language, a written but low-resourced language spoken by over 30% of the population in Zambia. To assess its usefulness for training and testing ASR systems for Bemba, we train an end-to-end Bemba ASR system by fine-tuning a pre-trained DeepSpeech English model on the training portion of the BembaSpeech corpus. Our best model achieves a word error rate (WER) of 54.78%. The results show that the corpus can be used for building ASR systems for Bemba. The corpus and models are publicly released at https://github.com/csikasote/BembaSpeech.
FullStop:Punctuation and Segmentation Prediction for Dutch with Transformers
Jan 09, 2023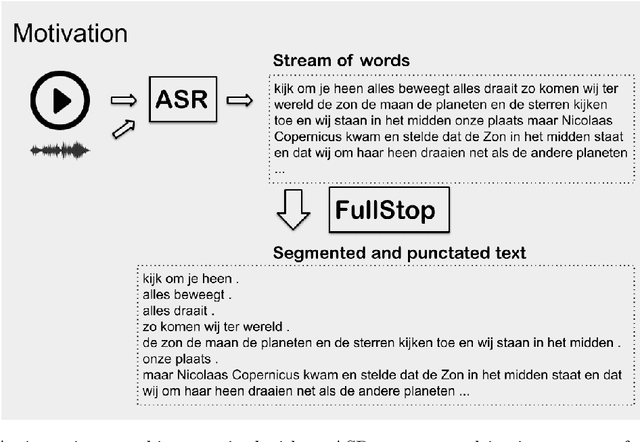


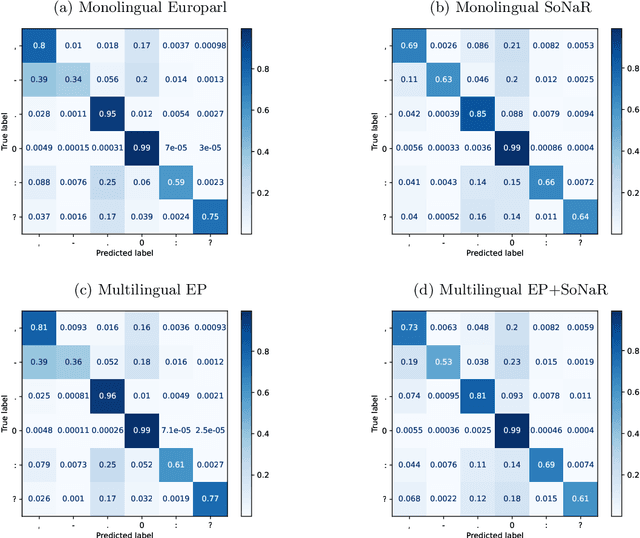
When applying automated speech recognition (ASR) for Belgian Dutch (Van Dyck et al. 2021), the output consists of an unsegmented stream of words, without any punctuation. A next step is to perform segmentation and insert punctuation, making the ASR output more readable and easy to manually correct. As far as we know there is no publicly available punctuation insertion system for Dutch that functions at a usable level. The model we present here is an extension of the models of Guhr et al. (2021) for Dutch and is made publicly available. We trained a sequence classification model, based on the Dutch language model RobBERT (Delobelle et al. 2020). For every word in the input sequence, the models predicts a punctuation marker that follows the word. We have also extended a multilingual model, for cases where the language is unknown or where code switching applies. When performing the task of segmentation, the application of the best models onto out of domain test data, a sliding window of 200 words of the ASR output stream is sent to the classifier, and segmentation is applied when the system predicts a segmenting punctuation sign with a ratio above threshold. Results show to be much better than a machine translation baseline approach.
Training Autoregressive Speech Recognition Models with Limited in-domain Supervision
Oct 27, 2022
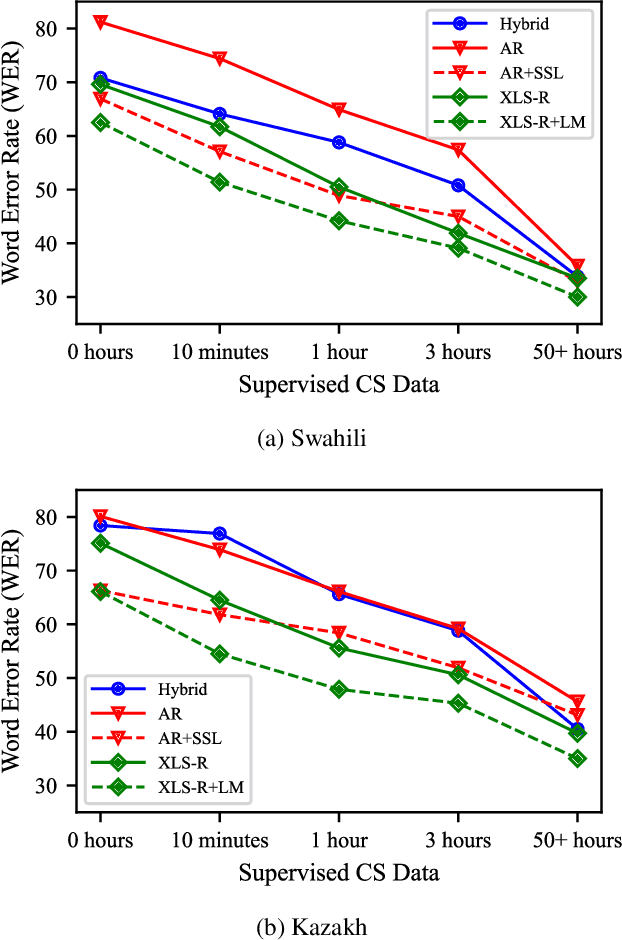

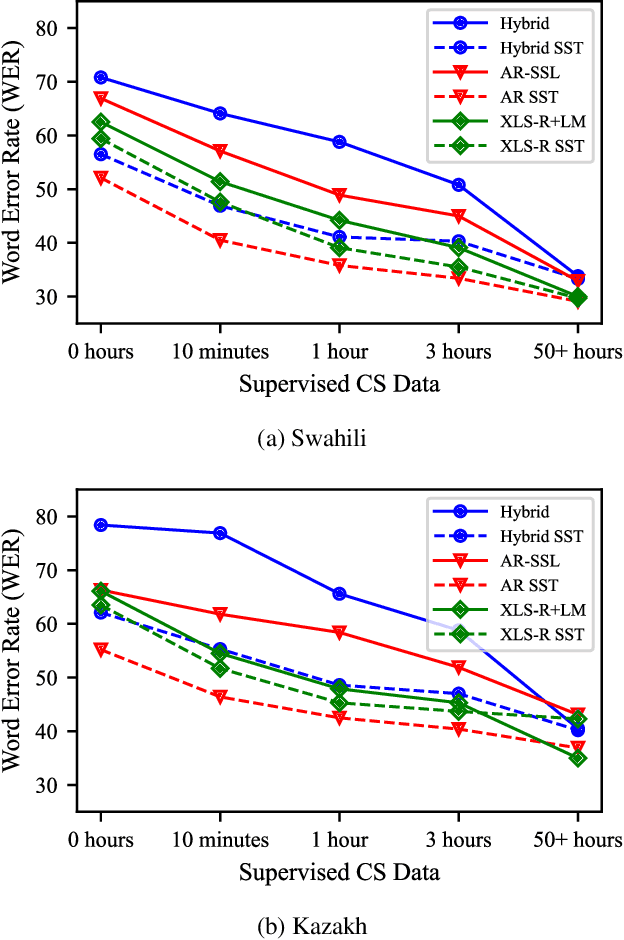
Advances in self-supervised learning have significantly reduced the amount of transcribed audio required for training. However, the majority of work in this area is focused on read speech. We explore limited supervision in the domain of conversational speech. While we assume the amount of in-domain data is limited, we augment the model with open source read speech data. The XLS-R model has been shown to perform well with limited adaptation data and serves as a strong baseline. We use untranscribed data for self-supervised learning and semi-supervised training in an autoregressive encoder-decoder model. We demonstrate that by using the XLS-R model for pseudotranscription, a much smaller autoregressive model can outperform a finetuned XLS-R model when transcribed in-domain data is limited, reducing WER by as much as 8% absolute.
SynthASR: Unlocking Synthetic Data for Speech Recognition
Jun 14, 2021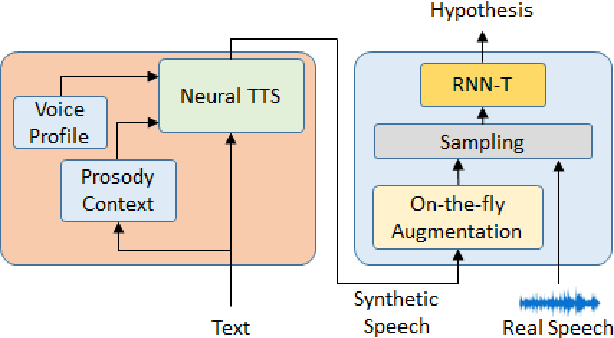
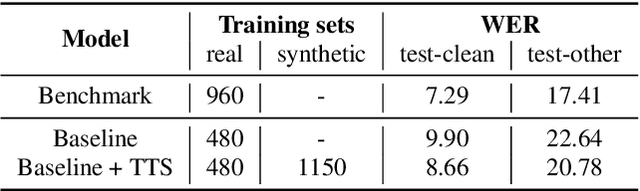
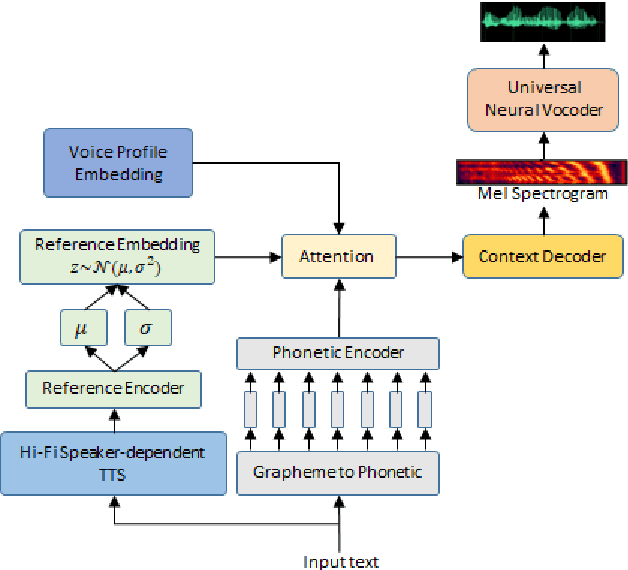
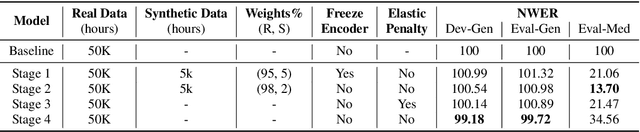
End-to-end (E2E) automatic speech recognition (ASR) models have recently demonstrated superior performance over the traditional hybrid ASR models. Training an E2E ASR model requires a large amount of data which is not only expensive but may also raise dependency on production data. At the same time, synthetic speech generated by the state-of-the-art text-to-speech (TTS) engines has advanced to near-human naturalness. In this work, we propose to utilize synthetic speech for ASR training (SynthASR) in applications where data is sparse or hard to get for ASR model training. In addition, we apply continual learning with a novel multi-stage training strategy to address catastrophic forgetting, achieved by a mix of weighted multi-style training, data augmentation, encoder freezing, and parameter regularization. In our experiments conducted on in-house datasets for a new application of recognizing medication names, training ASR RNN-T models with synthetic audio via the proposed multi-stage training improved the recognition performance on new application by more than 65% relative, without degradation on existing general applications. Our observations show that SynthASR holds great promise in training the state-of-the-art large-scale E2E ASR models for new applications while reducing the costs and dependency on production data.
GM-TCNet: Gated Multi-scale Temporal Convolutional Network using Emotion Causality for Speech Emotion Recognition
Oct 28, 2022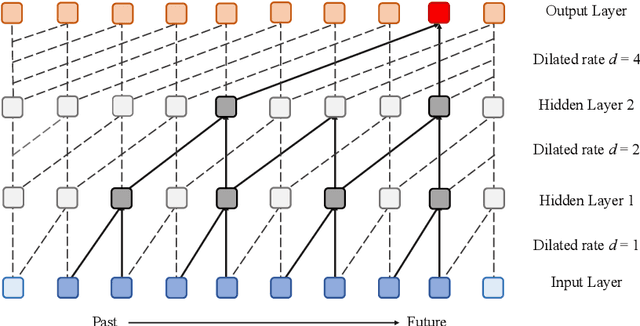
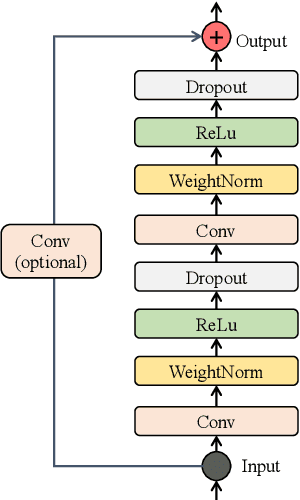
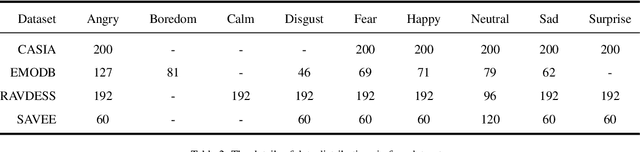
In human-computer interaction, Speech Emotion Recognition (SER) plays an essential role in understanding the user's intent and improving the interactive experience. While similar sentimental speeches own diverse speaker characteristics but share common antecedents and consequences, an essential challenge for SER is how to produce robust and discriminative representations through causality between speech emotions. In this paper, we propose a Gated Multi-scale Temporal Convolutional Network (GM-TCNet) to construct a novel emotional causality representation learning component with a multi-scale receptive field. GM-TCNet deploys a novel emotional causality representation learning component to capture the dynamics of emotion across the time domain, constructed with dilated causal convolution layer and gating mechanism. Besides, it utilizes skip connection fusing high-level features from different gated convolution blocks to capture abundant and subtle emotion changes in human speech. GM-TCNet first uses a single type of feature, mel-frequency cepstral coefficients, as inputs and then passes them through the gated temporal convolutional module to generate the high-level features. Finally, the features are fed to the emotion classifier to accomplish the SER task. The experimental results show that our model maintains the highest performance in most cases compared to state-of-the-art techniques.
* The source code is available at: https://github.com/Jiaxin-Ye/GM-TCNet
Adapting End-to-End Speech Recognition for Readable Subtitles
May 25, 2020

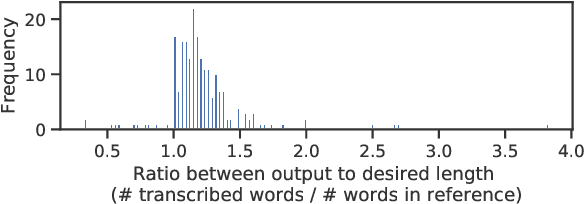
Automatic speech recognition (ASR) systems are primarily evaluated on transcription accuracy. However, in some use cases such as subtitling, verbatim transcription would reduce output readability given limited screen size and reading time. Therefore, this work focuses on ASR with output compression, a task challenging for supervised approaches due to the scarcity of training data. We first investigate a cascaded system, where an unsupervised compression model is used to post-edit the transcribed speech. We then compare several methods of end-to-end speech recognition under output length constraints. The experiments show that with limited data far less than needed for training a model from scratch, we can adapt a Transformer-based ASR model to incorporate both transcription and compression capabilities. Furthermore, the best performance in terms of WER and ROUGE scores is achieved by explicitly modeling the length constraints within the end-to-end ASR system.
Adapt-and-Adjust: Overcoming the Long-Tail Problem of Multilingual Speech Recognition
Dec 03, 2020
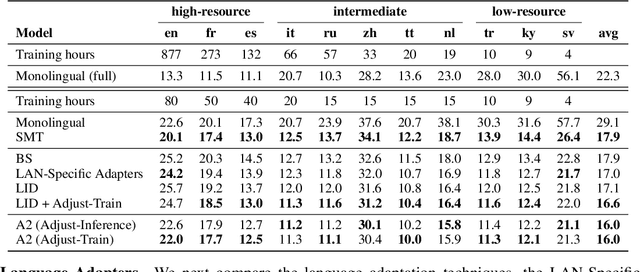
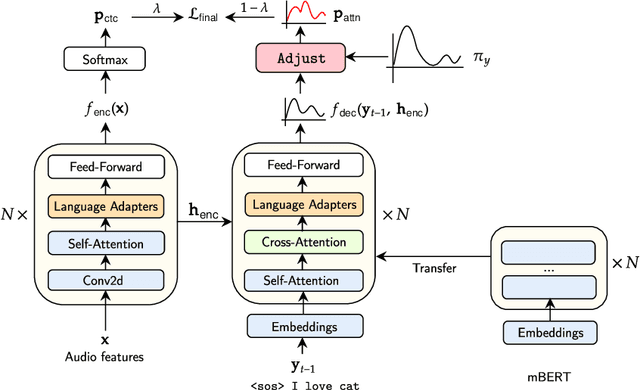
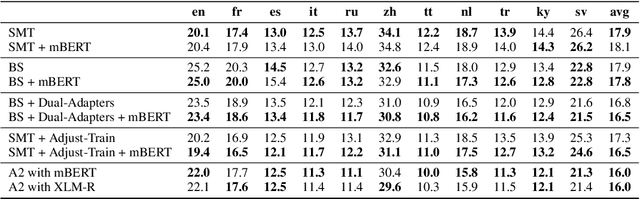
One crucial challenge of real-world multilingual speech recognition is the long-tailed distribution problem, where some resource-rich languages like English have abundant training data, but a long tail of low-resource languages have varying amounts of limited training data. To overcome the long-tail problem, in this paper, we propose Adapt-and-Adjust (A2), a transformer-based multi-task learning framework for end-to-end multilingual speech recognition. The A2 framework overcomes the long-tail problem via three techniques: (1) exploiting a pretrained multilingual language model (mBERT) to improve the performance of low-resource languages; (2) proposing dual adapters consisting of both language-specific and language-agnostic adaptation with minimal additional parameters; and (3) overcoming the class imbalance, either by imposing class priors in the loss during training or adjusting the logits of the softmax output during inference. Extensive experiments on the CommonVoice corpus show that A2 significantly outperforms conventional approaches.
Disentangling Prosody Representations with Unsupervised Speech Reconstruction
Dec 14, 2022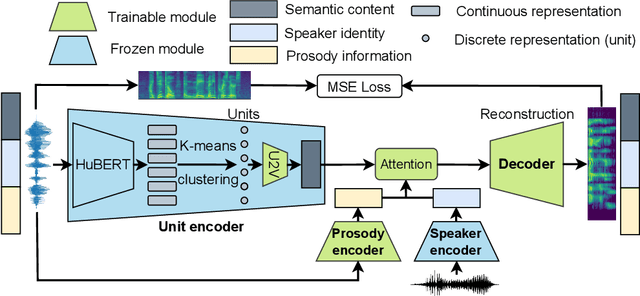
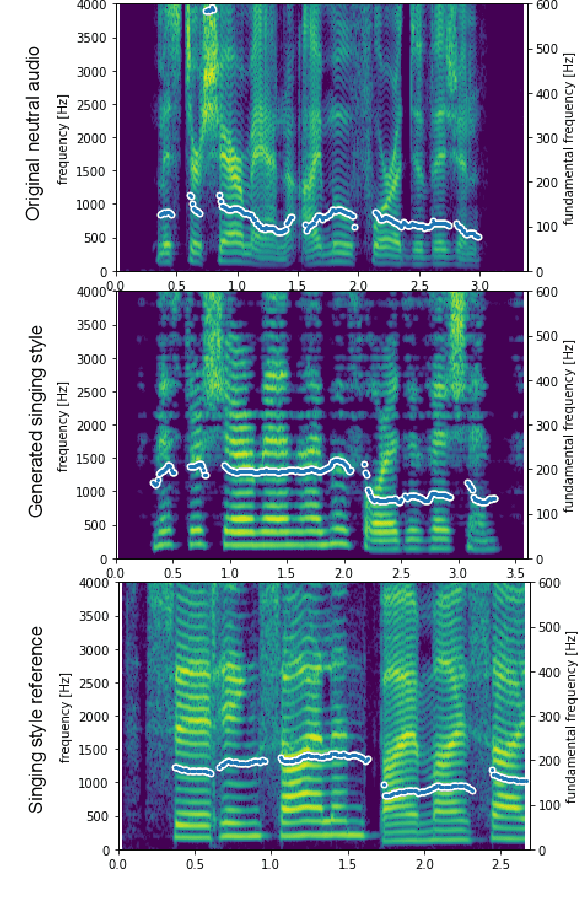
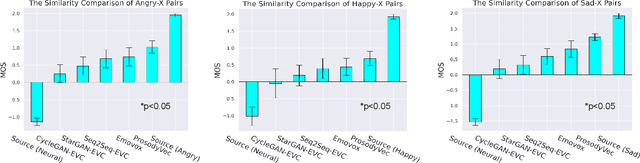
Human speech can be characterized by different components, including semantic content, speaker identity and prosodic information. Significant progress has been made in disentangling representations for semantic content and speaker identity in Automatic Speech Recognition (ASR) and speaker verification tasks respectively. However, it is still an open challenging research question to extract prosodic information because of the intrinsic association of different attributes, such as timbre and rhythm, and because of the need for unsupervised training schemes to achieve robust large-scale and speaker-independent ASR. The aim of this paper is to address the disentanglement of emotional prosody from speech based on unsupervised reconstruction. Specifically, we identify, design, implement and integrate three crucial components in our proposed speech reconstruction model Prosody2Vec: (1) a unit encoder that transforms speech signals into discrete units for semantic content, (2) a pretrained speaker verification model to generate speaker identity embeddings, and (3) a trainable prosody encoder to learn prosody representations. We first pretrain the Prosody2Vec representations on unlabelled emotional speech corpora, then fine-tune the model on specific datasets to perform Speech Emotion Recognition (SER) and Emotional Voice Conversion (EVC) tasks. Both objective and subjective evaluations on the EVC task suggest that Prosody2Vec effectively captures general prosodic features that can be smoothly transferred to other emotional speech. In addition, our SER experiments on the IEMOCAP dataset reveal that the prosody features learned by Prosody2Vec are complementary and beneficial for the performance of widely used speech pretraining models and surpass the state-of-the-art methods when combining Prosody2Vec with HuBERT representations. Some audio samples can be found on our demo website.