 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Fusing Wav2vec2.0 and BERT into End-to-end Model for Low-resource Speech Recognition
Jan 17, 2021
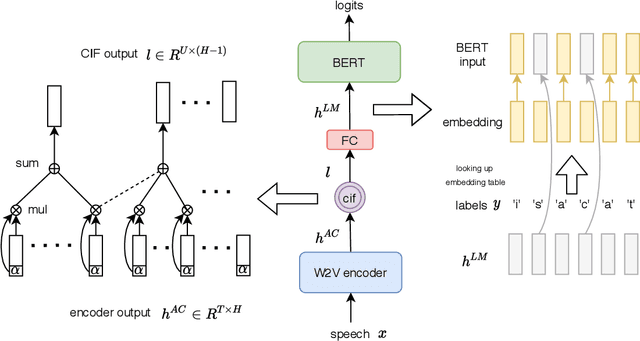
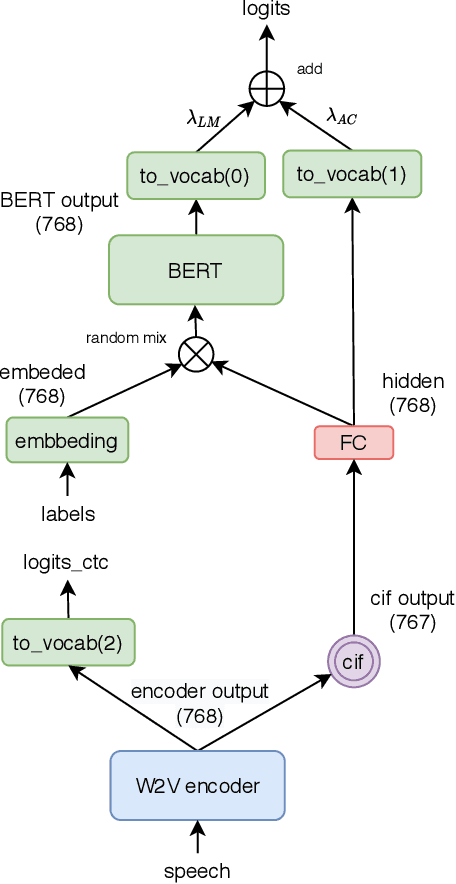
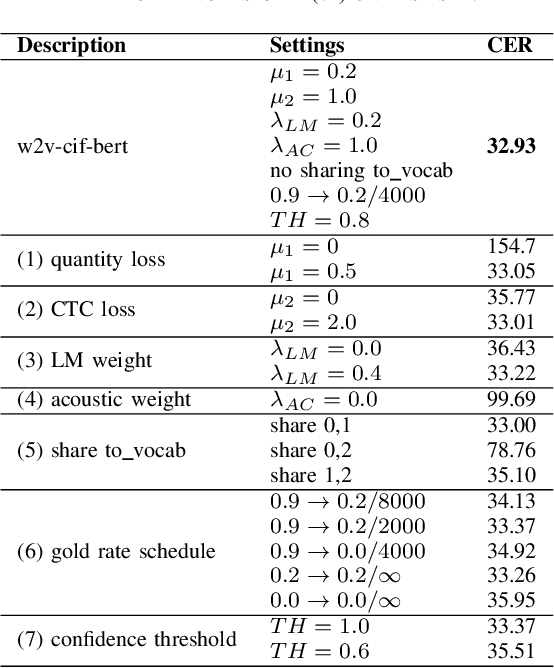
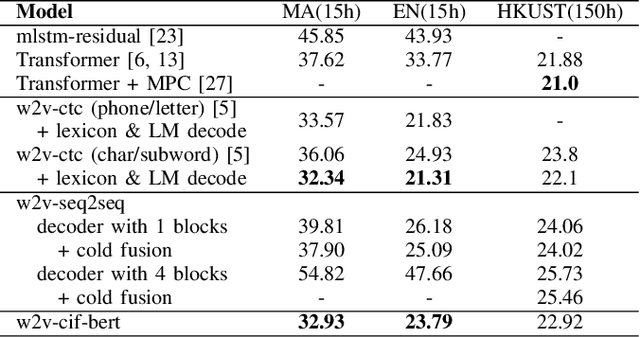
Self-supervised acoustic pre-training has achieved impressive results on low-resource speech recognition tasks. It indicates that the pretrain-and-finetune paradigm is a promising direction. In this work, we propose an end-to-end model for the low-resource speech recognition, which fuses a pre-trained audio encoder (wav2vec2.0) and a pre-trained text decoder (BERT). The two modules are connected by a linear attention mechanism without parameters. A fully connected layer is introduced for hidden mapping between speech and language modalities. Besides, we design an effective fine-tuning strategy to preserve and utilize the text context modeling ability of the pre-trained decoder. Armed with this strategy, our model exhibits distinct faster convergence and better performance. Our model achieves approaching recognition performance in CALLHOME corpus (15h) as the SOTA pipeline modeling.
Exploring CTC Based End-to-End Techniques for Myanmar Speech Recognition
May 14, 2021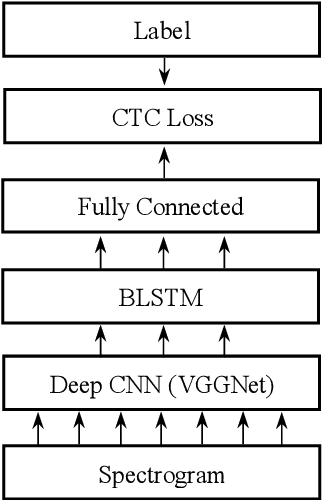
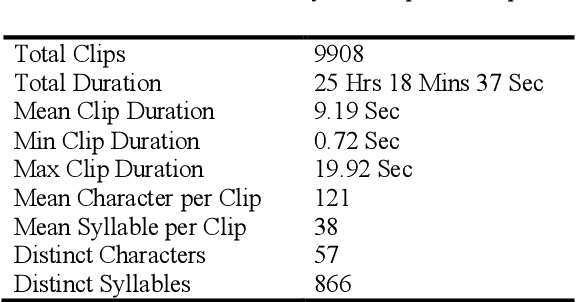
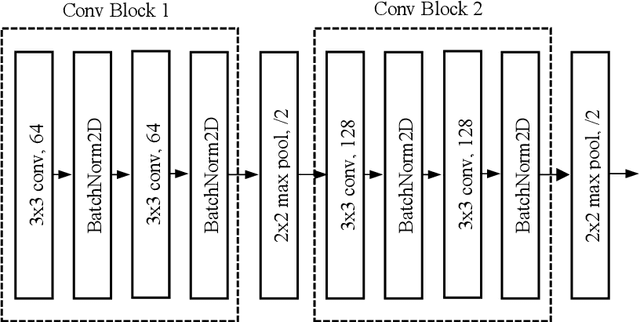
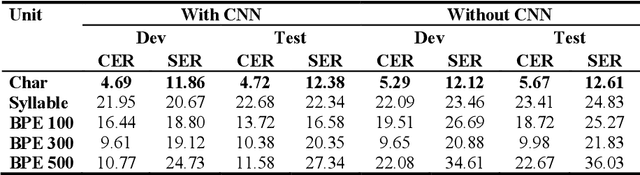
In this work, we explore a Connectionist Temporal Classification (CTC) based end-to-end Automatic Speech Recognition (ASR) model for the Myanmar language. A series of experiments is presented on the topology of the model in which the convolutional layers are added and dropped, different depths of bidirectional long short-term memory (BLSTM) layers are used and different label encoding methods are investigated. The experiments are carried out in low-resource scenarios using our recorded Myanmar speech corpus of nearly 26 hours. The best model achieves character error rate (CER) of 4.72% and syllable error rate (SER) of 12.38% on the test set.
* This is a preprint of the chapter: Chit K.M.M., Lin L.L., Exploring CTC Based End-To-End Techniques for Myanmar Speech Recognition, published in Advances in Intelligent Systems and Computing, vol 1324, edited by Vasant P., Zelinka I., Weber GW., 2021, Springer, Cham reproduced with permission of Springer. The final authenticated version is available at https://doi.org/10.1007/978-3-030-68154-8_87
Improving Speech Emotion Recognition Through Focus and Calibration Attention Mechanisms
Aug 21, 2022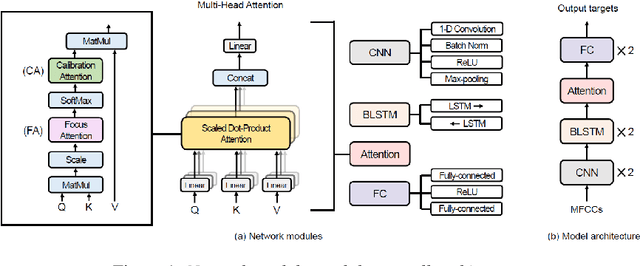
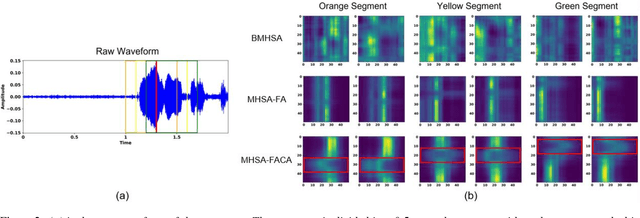
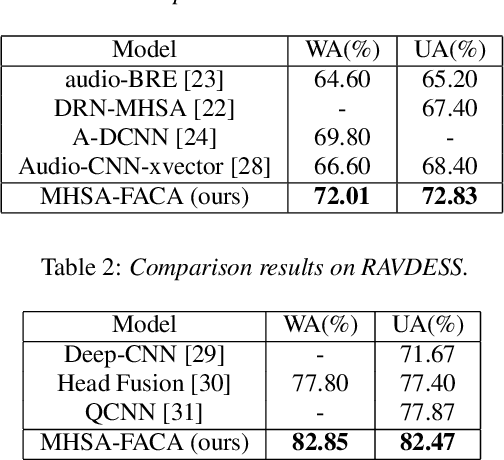
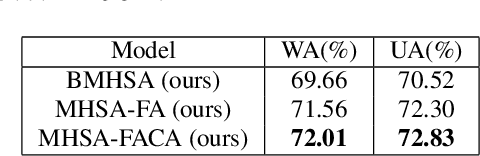
Attention has become one of the most commonly used mechanisms in deep learning approaches. The attention mechanism can help the system focus more on the feature space's critical regions. For example, high amplitude regions can play an important role for Speech Emotion Recognition (SER). In this paper, we identify misalignments between the attention and the signal amplitude in the existing multi-head self-attention. To improve the attention area, we propose to use a Focus-Attention (FA) mechanism and a novel Calibration-Attention (CA) mechanism in combination with the multi-head self-attention. Through the FA mechanism, the network can detect the largest amplitude part in the segment. By employing the CA mechanism, the network can modulate the information flow by assigning different weights to each attention head and improve the utilization of surrounding contexts. To evaluate the proposed method, experiments are performed with the IEMOCAP and RAVDESS datasets. Experimental results show that the proposed framework significantly outperforms the state-of-the-art approaches on both datasets.
SoftCTC $\unicode{x2013}$ Semi-Supervised Learning for Text Recognition using Soft Pseudo-Labels
Dec 05, 2022

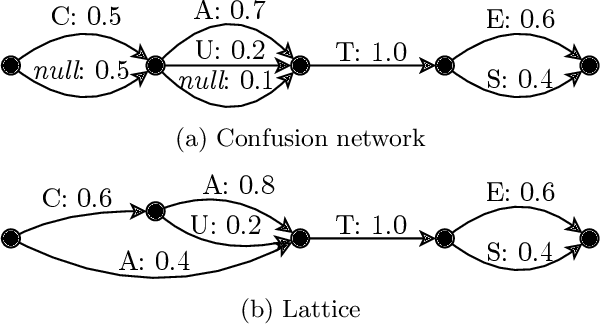
This paper explores semi-supervised training for sequence tasks, such as Optical Character Recognition or Automatic Speech Recognition. We propose a novel loss function $\unicode{x2013}$ SoftCTC $\unicode{x2013}$ which is an extension of CTC allowing to consider multiple transcription variants at the same time. This allows to omit the confidence based filtering step which is otherwise a crucial component of pseudo-labeling approaches to semi-supervised learning. We demonstrate the effectiveness of our method on a challenging handwriting recognition task and conclude that SoftCTC matches the performance of a finely-tuned filtering based pipeline. We also evaluated SoftCTC in terms of computational efficiency, concluding that it is significantly more efficient than a na\"ive CTC-based approach for training on multiple transcription variants, and we make our GPU implementation public.
Dual-Decoder Transformer For end-to-end Mandarin Chinese Speech Recognition with Pinyin and Character
Jan 26, 2022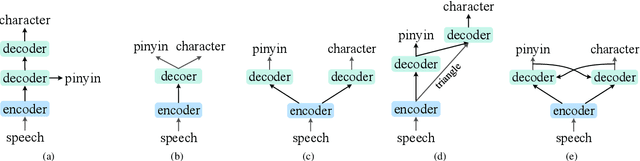
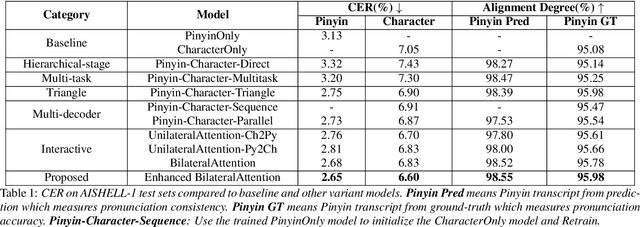
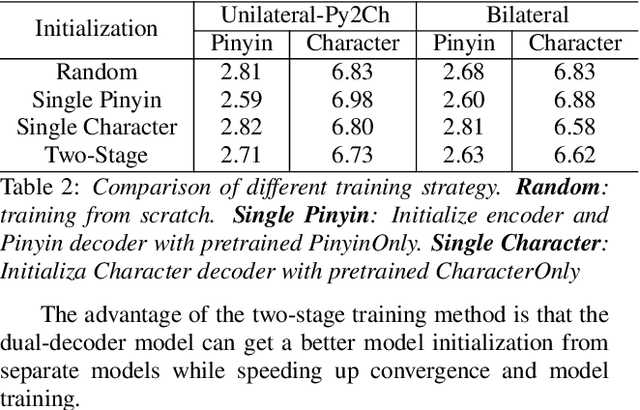
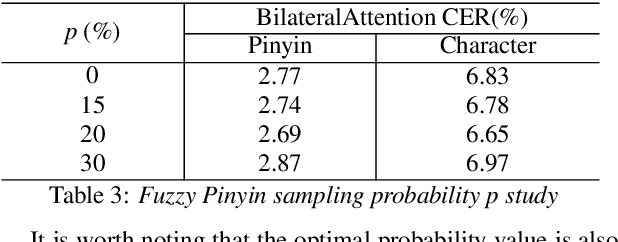
End-to-end automatic speech recognition (ASR) has achieved promising results. However, most existing end-to-end ASR methods neglect the use of specific language characteristics. For Mandarin Chinese ASR tasks, pinyin and character as writing and spelling systems respectively are mutual promotion in the Mandarin Chinese language. Based on the above intuition, we investigate types of related models that are suitable but not for joint pinyin-character ASR and propose a novel Mandarin Chinese ASR model with dual-decoder Transformer according to the characteristics of the pinyin transcripts and character transcripts. Specifically, the joint pinyin-character layer-wise linear interactive (LWLI) module and phonetic posteriorgrams adapter (PPGA) are proposed to achieve inter-layer multi-level interaction by adaptively fusing pinyin and character information. Furthermore, a two-stage training strategy is proposed to make training more stable and faster convergence. The results on the test sets of AISHELL-1 dataset show that the proposed Speech-Pinyin-Character-Interaction (SPCI) model without a language model achieves 9.85% character error rate (CER) on the test set, which is 17.71% relative reduction compared to baseline models based on Transformer.
wav2letter++: The Fastest Open-source Speech Recognition System
Dec 18, 2018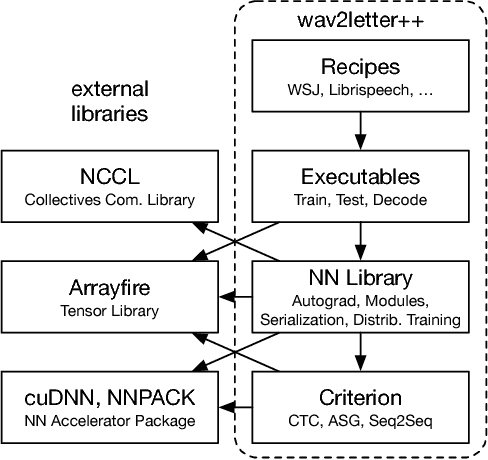
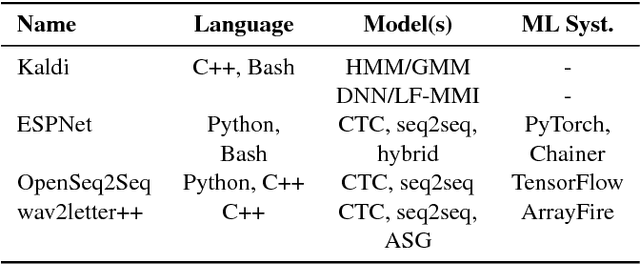

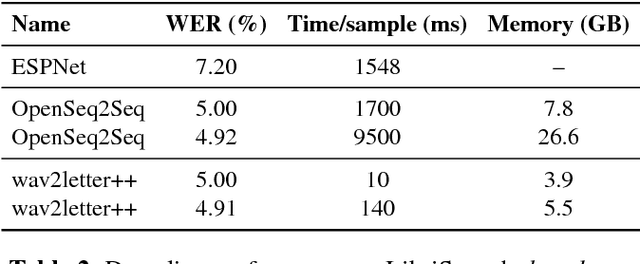
This paper introduces wav2letter++, the fastest open-source deep learning speech recognition framework. wav2letter++ is written entirely in C++, and uses the ArrayFire tensor library for maximum efficiency. Here we explain the architecture and design of the wav2letter++ system and compare it to other major open-source speech recognition systems. In some cases wav2letter++ is more than 2x faster than other optimized frameworks for training end-to-end neural networks for speech recognition. We also show that wav2letter++'s training times scale linearly to 64 GPUs, the highest we tested, for models with 100 million parameters. High-performance frameworks enable fast iteration, which is often a crucial factor in successful research and model tuning on new datasets and tasks.
Tourist Guidance Robot Based on HyperCLOVA
Oct 19, 2022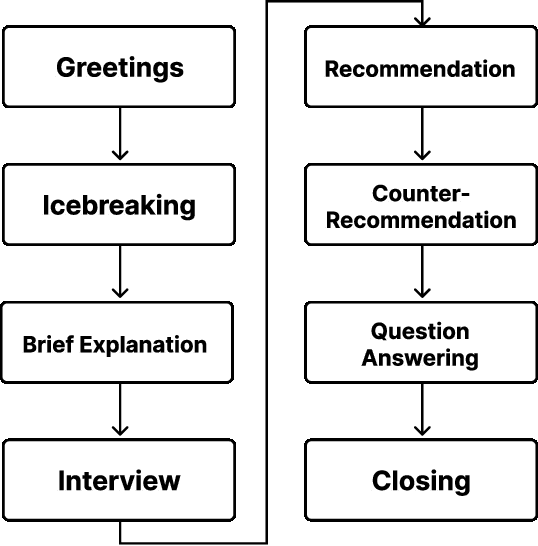



This paper describes our system submitted to Dialogue Robot Competition 2022. Our proposed system is a combined model of rule-based and generation-based dialog systems. The system utilizes HyperCLOVA, a Japanese foundation model, not only to generate responses but also summarization, search information, etc. We also used our original speech recognition system, which was fine-tuned for this dialog task. As a result, our system ranked second in the preliminary round and moved on to the finals.
Efficient Self-supervised Learning with Contextualized Target Representations for Vision, Speech and Language
Dec 14, 2022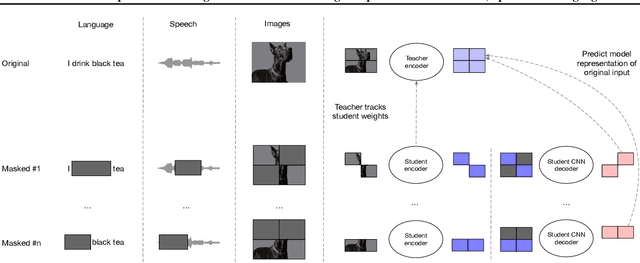
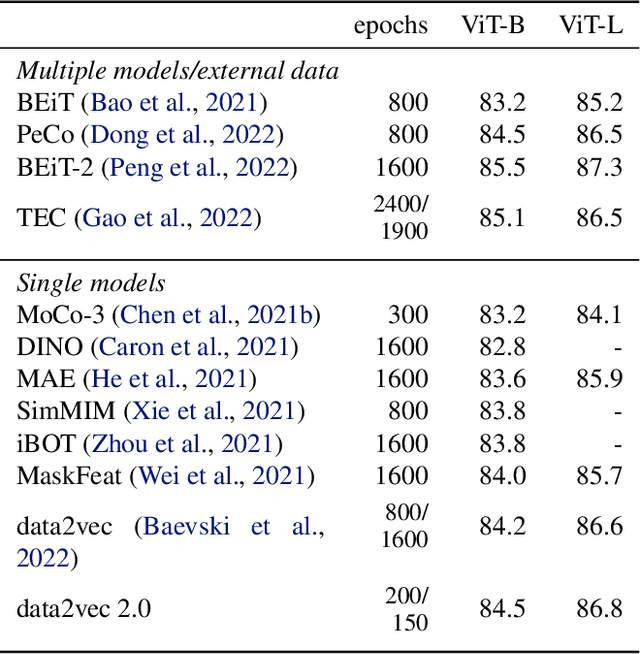
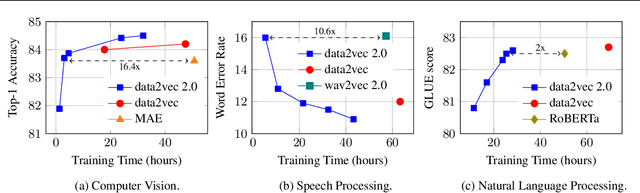

Current self-supervised learning algorithms are often modality-specific and require large amounts of computational resources. To address these issues, we increase the training efficiency of data2vec, a learning objective that generalizes across several modalities. We do not encode masked tokens, use a fast convolutional decoder and amortize the effort to build teacher representations. data2vec 2.0 benefits from the rich contextualized target representations introduced in data2vec which enable a fast self-supervised learner. Experiments on ImageNet-1K image classification show that data2vec 2.0 matches the accuracy of Masked Autoencoders in 16.4x lower pre-training time, on Librispeech speech recognition it performs as well as wav2vec 2.0 in 10.6x less time, and on GLUE natural language understanding it matches a retrained RoBERTa model in half the time. Trading some speed for accuracy results in ImageNet-1K top-1 accuracy of 86.8\% with a ViT-L model trained for 150 epochs.
A Noise-Robust Self-supervised Pre-training Model Based Speech Representation Learning for Automatic Speech Recognition
Jan 22, 2022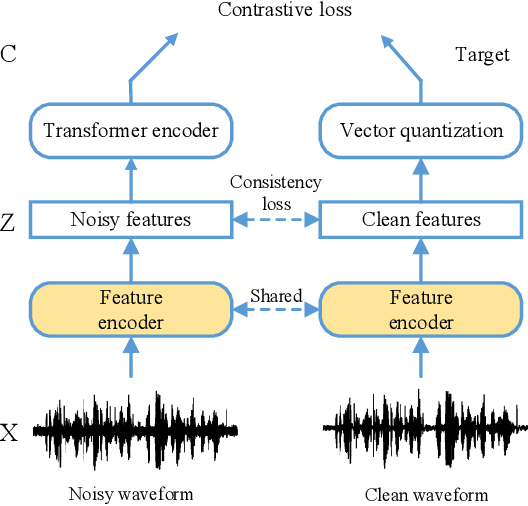
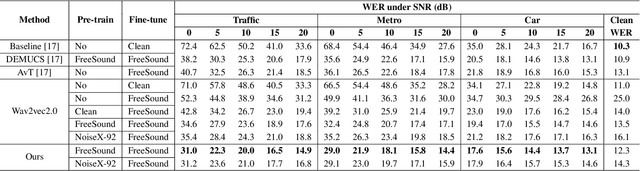
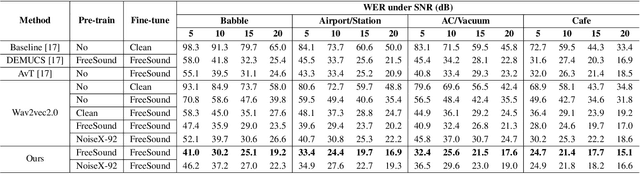
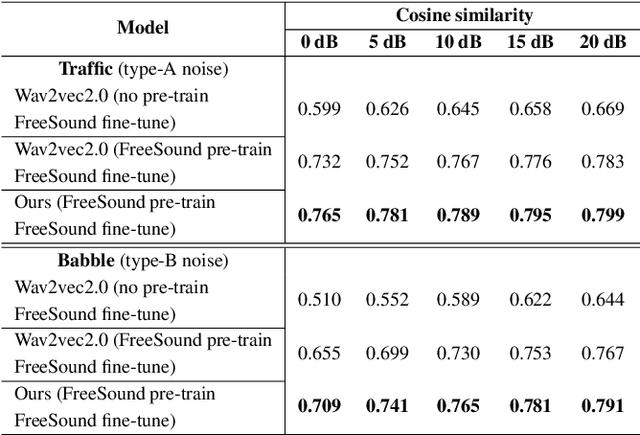
Wav2vec2.0 is a popular self-supervised pre-training framework for learning speech representations in the context of automatic speech recognition (ASR). It was shown that wav2vec2.0 has a good robustness against the domain shift, while the noise robustness is still unclear. In this work, we therefore first analyze the noise robustness of wav2vec2.0 via experiments. We observe that wav2vec2.0 pre-trained on noisy data can obtain good representations and thus improve the ASR performance on the noisy test set, which however brings a performance degradation on the clean test set. To avoid this issue, in this work we propose an enhanced wav2vec2.0 model. Specifically, the noisy speech and the corresponding clean version are fed into the same feature encoder, where the clean speech provides training targets for the model. Experimental results reveal that the proposed method can not only improve the ASR performance on the noisy test set which surpasses the original wav2vec2.0, but also ensure a tiny performance decrease on the clean test set. In addition, the effectiveness of the proposed method is demonstrated under different types of noise conditions.