 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Semi-supervised cross-lingual speech emotion recognition
Jul 14, 2022
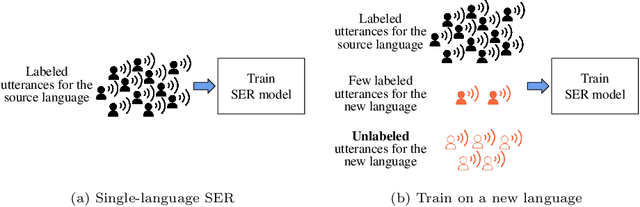
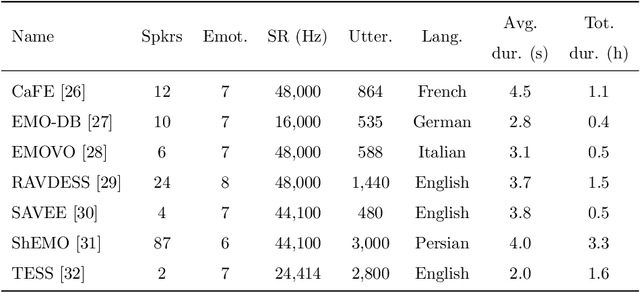
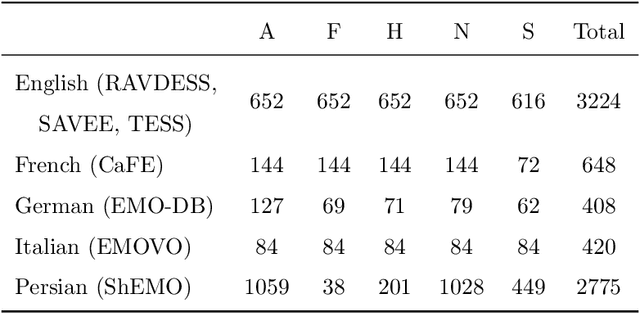
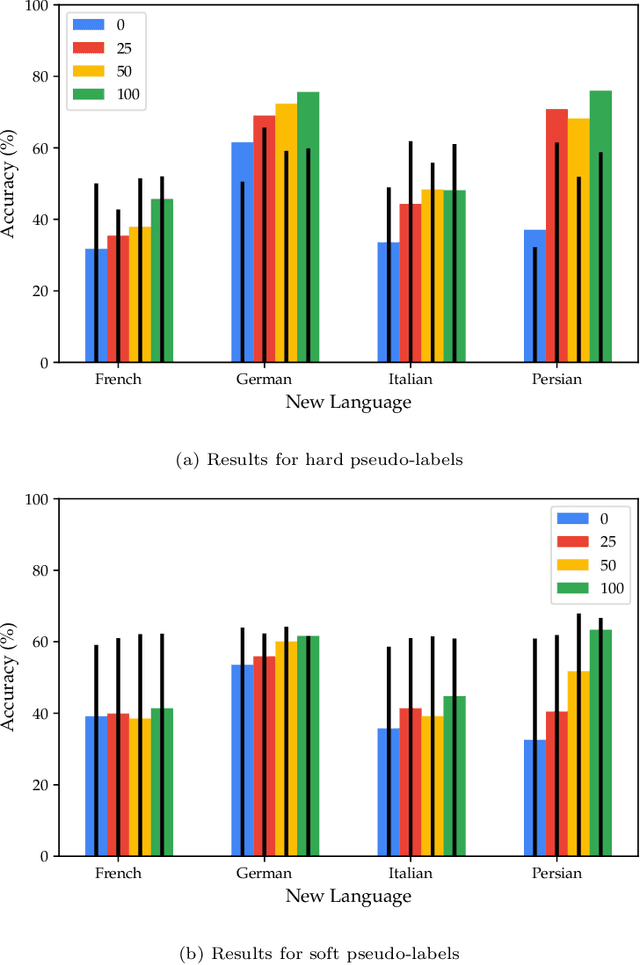
Speech emotion recognition (SER) on a single language has achieved remarkable results through deep learning approaches over the last decade. However, cross-lingual SER remains a challenge in real-world applications due to (i) a large difference between the source and target domain distributions, (ii) the availability of few labeled and many unlabeled utterances for the new language. Taking into account previous aspects, we propose a Semi-Supervised Learning (SSL) method for cross-lingual emotion recognition when a few labels from the new language are available. Based on a Convolutional Neural Network (CNN), our method adapts to a new language by exploiting a pseudo-labeling strategy for the unlabeled utterances. In particular, the use of a hard and soft pseudo-labels approach is investigated. We thoroughly evaluate the performance of the method in a speaker-independent setup on both the source and the new language and show its robustness across five languages belonging to different linguistic strains.
A Comparison of Temporal Encoders for Neuromorphic Keyword Spotting with Few Neurons
Jan 24, 2023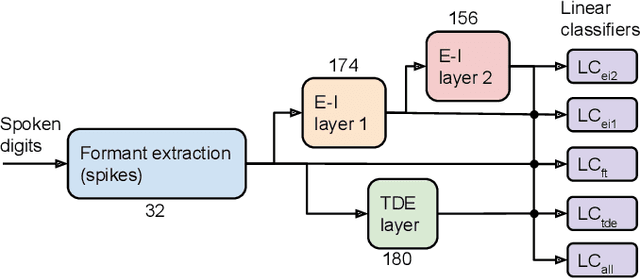
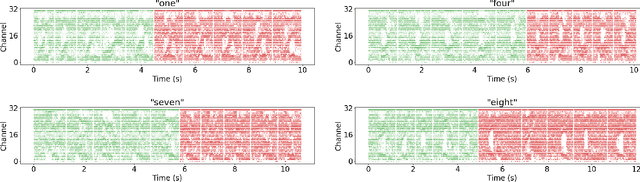
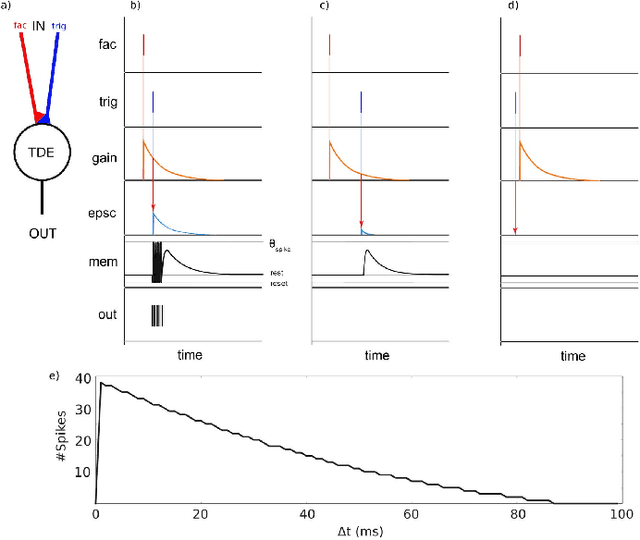
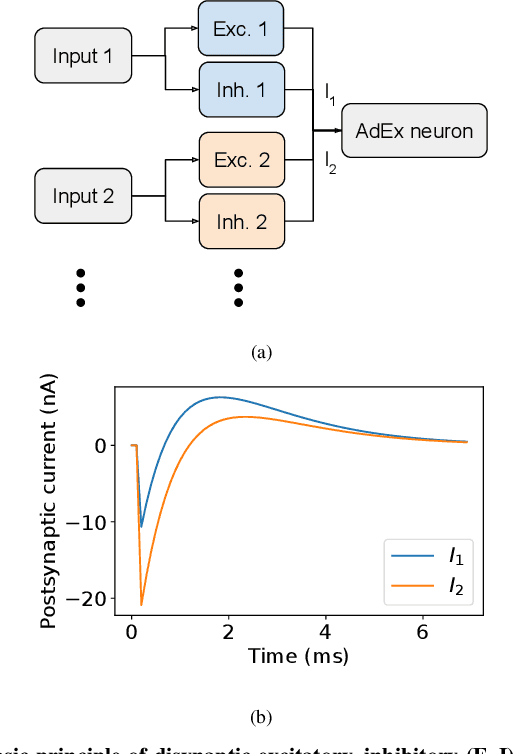
With the expansion of AI-powered virtual assistants, there is a need for low-power keyword spotting systems providing a "wake-up" mechanism for subsequent computationally expensive speech recognition. One promising approach is the use of neuromorphic sensors and spiking neural networks (SNNs) implemented in neuromorphic processors for sparse event-driven sensing. However, this requires resource-efficient SNN mechanisms for temporal encoding, which need to consider that these systems process information in a streaming manner, with physical time being an intrinsic property of their operation. In this work, two candidate neurocomputational elements for temporal encoding and feature extraction in SNNs described in recent literature - the spiking time-difference encoder (TDE) and disynaptic excitatory-inhibitory (E-I) elements - are comparatively investigated in a keyword-spotting task on formants computed from spoken digits in the TIDIGITS dataset. While both encoders improve performance over direct classification of the formant features in the training data, enabling a complete binary classification with a logistic regression model, they show no clear improvements on the test set. Resource-efficient keyword spotting applications may benefit from the use of these encoders, but further work on methods for learning the time constants and weights is required to investigate their full potential.
Building a great multi-lingual teacher with sparsely-gated mixture of experts for speech recognition
Dec 10, 2021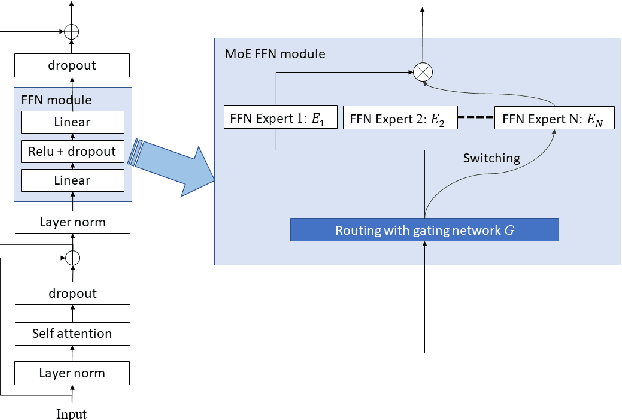
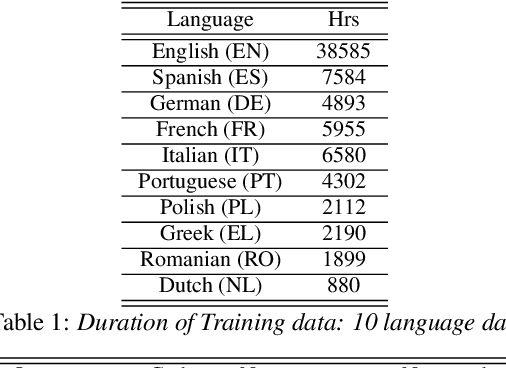
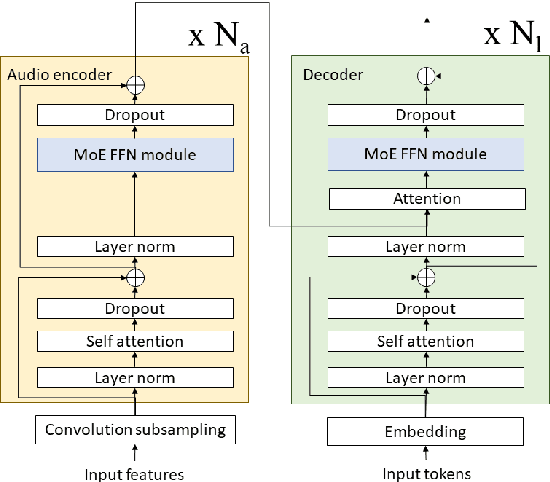
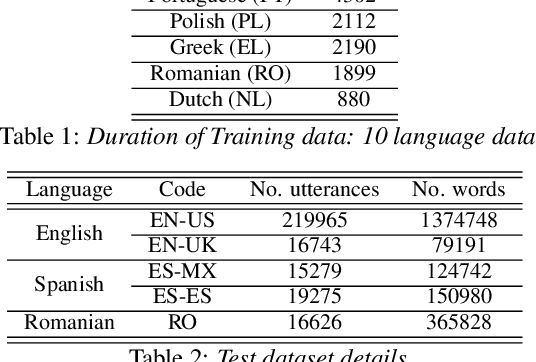
The sparsely-gated Mixture of Experts (MoE) can magnify a network capacity with a little computational complexity. In this work, we investigate how multi-lingual Automatic Speech Recognition (ASR) networks can be scaled up with a simple routing algorithm in order to achieve better accuracy. More specifically, we apply the sparsely-gated MoE technique to two types of networks: Sequence-to-Sequence Transformer (S2S-T) and Transformer Transducer (T-T). We demonstrate through a set of ASR experiments on multiple language data that the MoE networks can reduce the relative word error rates by 16.5\% and 4.7\% with the S2S-T and T-T, respectively. Moreover, we thoroughly investigate the effect of the MoE on the T-T architecture in various conditions: streaming mode, non-streaming mode, the use of language ID and the label decoder with the MoE.
Attention-based Neural Beamforming Layers for Multi-channel Speech Recognition
May 14, 2021

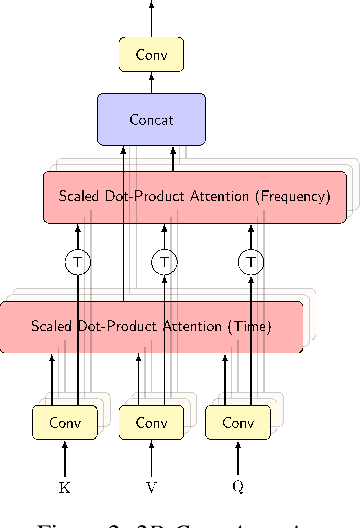

Attention-based beamformers have recently been shown to be effective for multi-channel speech recognition. However, they are less capable at capturing local information. In this work, we propose a 2D Conv-Attention module which combines convolution neural networks with attention for beamforming. We apply self- and cross-attention to explicitly model the correlations within and between the input channels. The end-to-end 2D Conv-Attention model is compared with a multi-head self-attention and superdirective-based neural beamformers. We train and evaluate on an in-house multi-channel dataset. The results show a relative improvement of 3.8% in WER by the proposed model over the baseline neural beamformer.
Exploring Effective Fusion Algorithms for Speech Based Self-Supervised Learning Models
Dec 20, 2022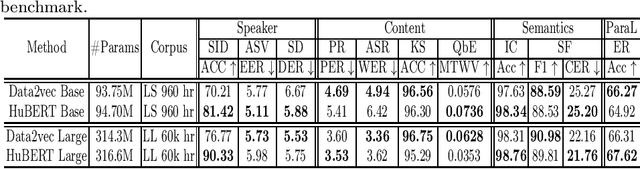
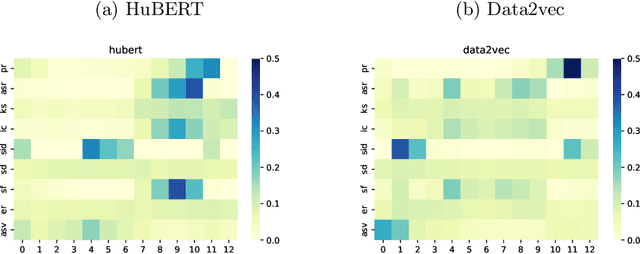
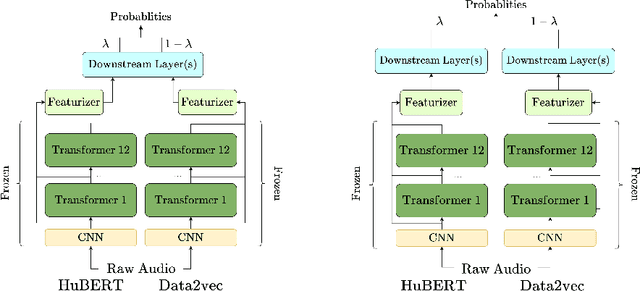
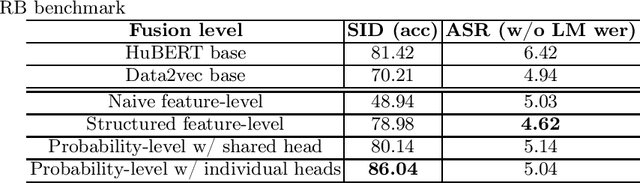
Self-supervised learning (SSL) has achieved great success in various areas including speech processing. Recently, it is proven that speech based SSL models are able to extract superior universal representations on a range of downstream tasks compared to traditional hand-craft feature (e.g. FBank, MFCC) in the SUPERB benchmark. However, different types of SSL models might exhibit distinct strengths on different downstream tasks. In order to better utilize the potential power of SSL models, in this work, we explore the effective fusion on multiple SSL models. A series of model fusion algorithms are investigated and compared by combining two types of SSL models, Hubert and Data2vec, on two representative tasks from SUPERB benchmark, which are speaker identification (SID) and automatic speech recognition (ASR) tasks. The experimental results demonstrate that our proposed fusion algorithms can further boost the individual model significantly.
BART based semantic correction for Mandarin automatic speech recognition system
Mar 26, 2021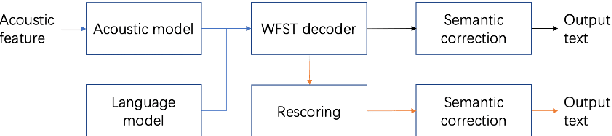
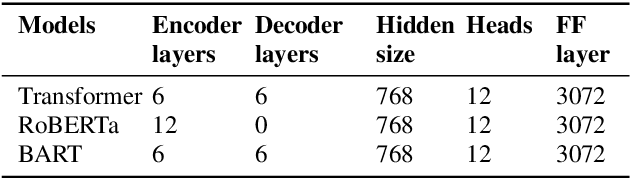
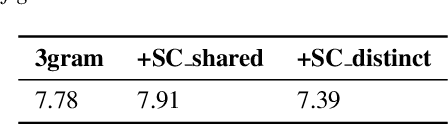

Although automatic speech recognition (ASR) systems achieved significantly improvements in recent years, spoken language recognition error occurs which can be easily spotted by human beings. Various language modeling techniques have been developed on post recognition tasks like semantic correction. In this paper, we propose a Transformer based semantic correction method with pretrained BART initialization, Experiments on 10000 hours Mandarin speech dataset show that character error rate (CER) can be effectively reduced by 21.7% relatively compared to our baseline ASR system. Expert evaluation demonstrates that actual improvement of our model surpasses what CER indicates.
Speech Emotion Recognition Using Quaternion Convolutional Neural Networks
Oct 31, 2021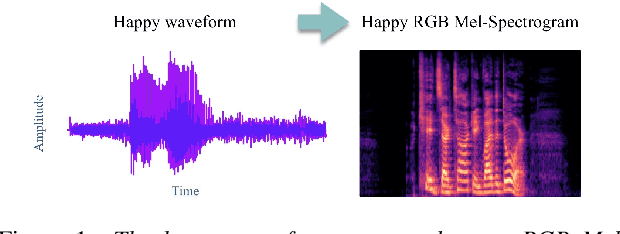
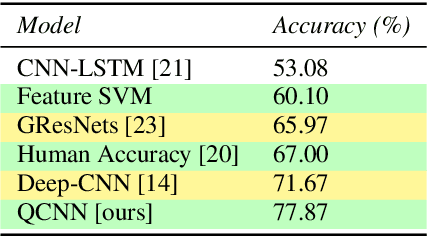
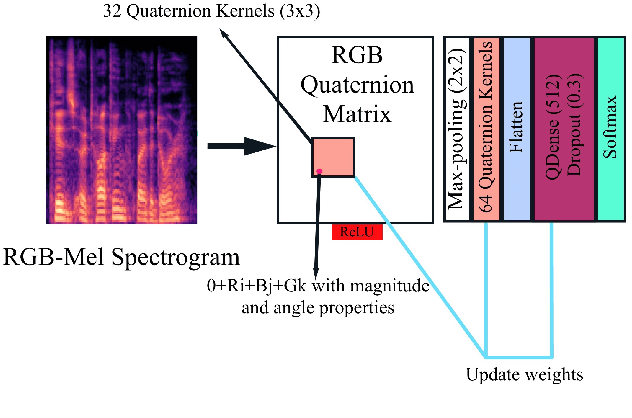
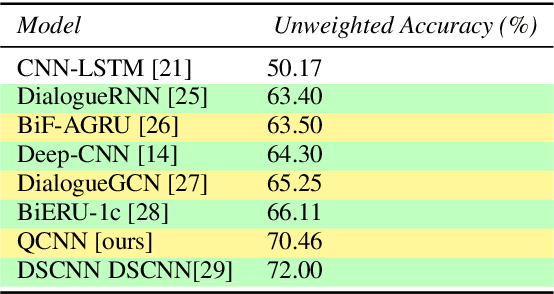
Although speech recognition has become a widespread technology, inferring emotion from speech signals still remains a challenge. To address this problem, this paper proposes a quaternion convolutional neural network (QCNN) based speech emotion recognition (SER) model in which Mel-spectrogram features of speech signals are encoded in an RGB quaternion domain. We show that our QCNN based SER model outperforms other real-valued methods in the Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS, 8-classes) dataset, achieving, to the best of our knowledge, state-of-the-art results. The QCNN also achieves comparable results with the state-of-the-art methods in the Interactive Emotional Dyadic Motion Capture (IEMOCAP 4-classes) and Berlin EMO-DB (7-classes) datasets. Specifically, the model achieves an accuracy of 77.87\%, 70.46\%, and 88.78\% for the RAVDESS, IEMOCAP, and EMO-DB datasets, respectively. In addition, our results show that the quaternion unit structure is better able to encode internal dependencies to reduce its model size significantly compared to other methods.
ElectrodeNet -- A Deep Learning Based Sound Coding Strategy for Cochlear Implants
May 26, 2023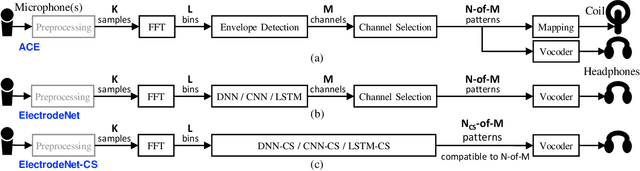
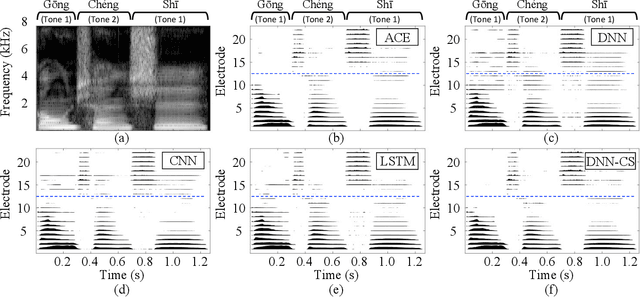
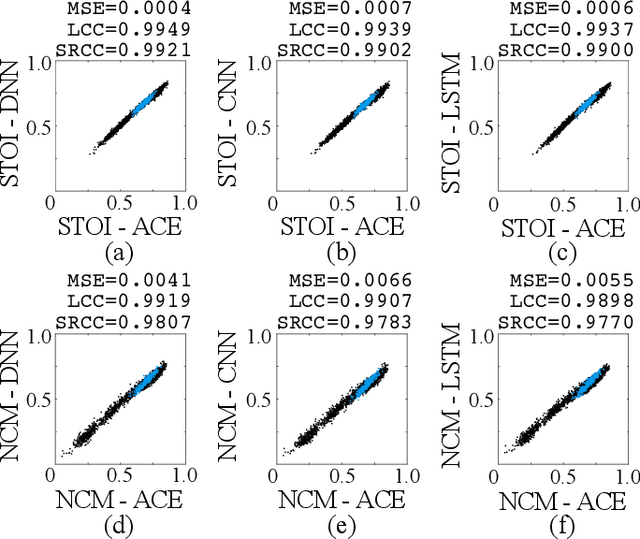
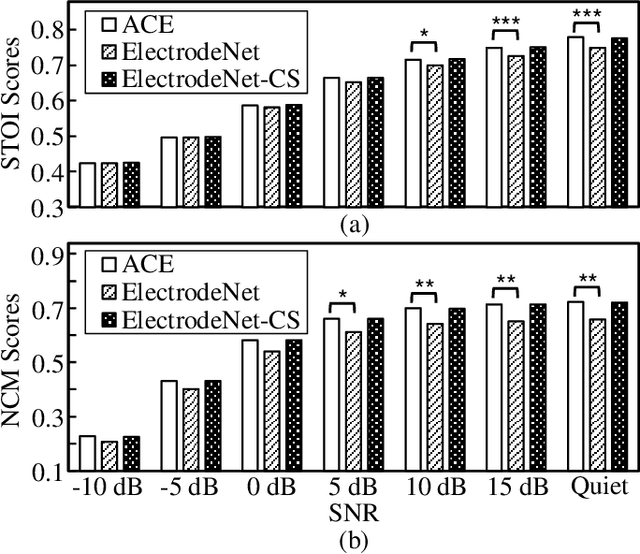
ElectrodeNet, a deep learning based sound coding strategy for the cochlear implant (CI), is proposed to emulate the advanced combination encoder (ACE) strategy by replacing the conventional envelope detection using various artificial neural networks. The extended ElectrodeNet-CS strategy further incorporates the channel selection (CS). Network models of deep neural network (DNN), convolutional neural network (CNN), and long short-term memory (LSTM) were trained using the Fast Fourier Transformed bins and channel envelopes obtained from the processing of clean speech by the ACE strategy. Objective speech understanding using short-time objective intelligibility (STOI) and normalized covariance metric (NCM) was estimated for ElectrodeNet using CI simulations. Sentence recognition tests for vocoded Mandarin speech were conducted with normal-hearing listeners. DNN, CNN, and LSTM based ElectrodeNets exhibited strong correlations to ACE in objective and subjective scores using mean squared error (MSE), linear correlation coefficient (LCC) and Spearman's rank correlation coefficient (SRCC). The ElectrodeNet-CS strategy was capable of producing N-of-M compatible electrode patterns using a modified DNN network to embed maxima selection, and to perform in similar or even slightly higher average in STOI and sentence recognition compared to ACE. The methods and findings demonstrated the feasibility and potential of using deep learning in CI coding strategy.
Data Augmentation with Locally-time Reversed Speech for Automatic Speech Recognition
Oct 09, 2021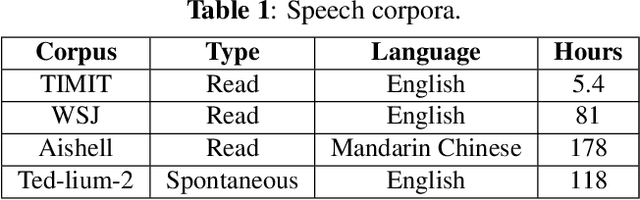
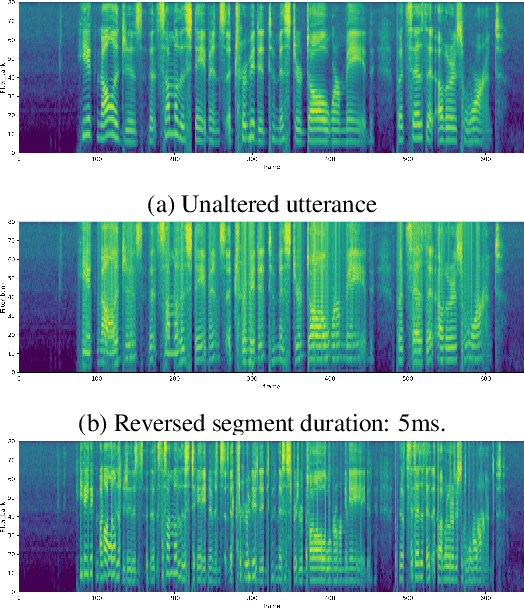
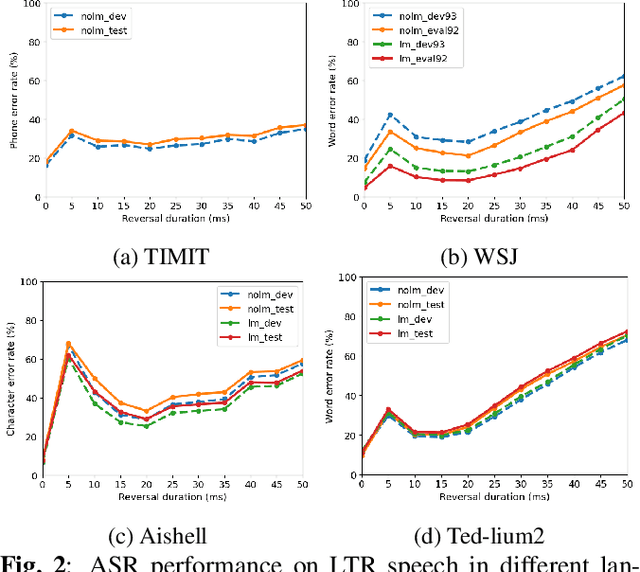
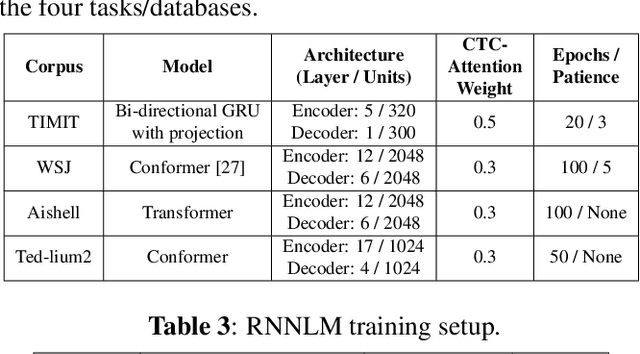
Psychoacoustic studies have shown that locally-time reversed (LTR) speech, i.e., signal samples time-reversed within a short segment, can be accurately recognised by human listeners. This study addresses the question of how well a state-of-the-art automatic speech recognition (ASR) system would perform on LTR speech. The underlying objective is to explore the feasibility of deploying LTR speech in the training of end-to-end (E2E) ASR models, as an attempt to data augmentation for improving the recognition performance. The investigation starts with experiments to understand the effect of LTR speech on general-purpose ASR. LTR speech with reversed segment duration of 5 ms - 50 ms is rendered and evaluated. For ASR training data augmentation with LTR speech, training sets are created by combining natural speech with different partitions of LTR speech. The efficacy of data augmentation is confirmed by ASR results on speech corpora in various languages and speaking styles. ASR on LTR speech with reversed segment duration of 15 ms - 30 ms is found to have lower error rate than with other segment duration. Data augmentation with these LTR speech achieves satisfactory and consistent improvement on ASR performance.