 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
SCaLa: Supervised Contrastive Learning for End-to-End Automatic Speech Recognition
Oct 08, 2021
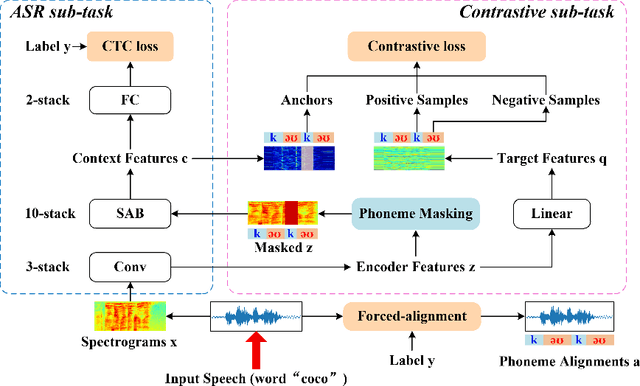
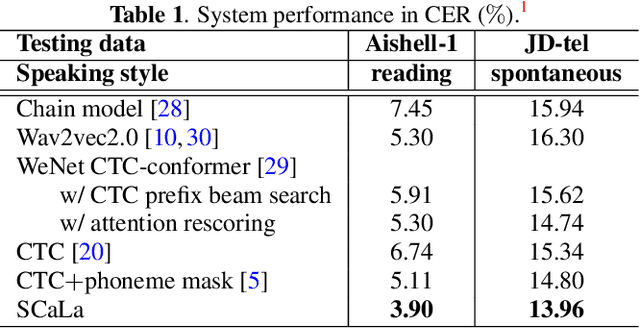
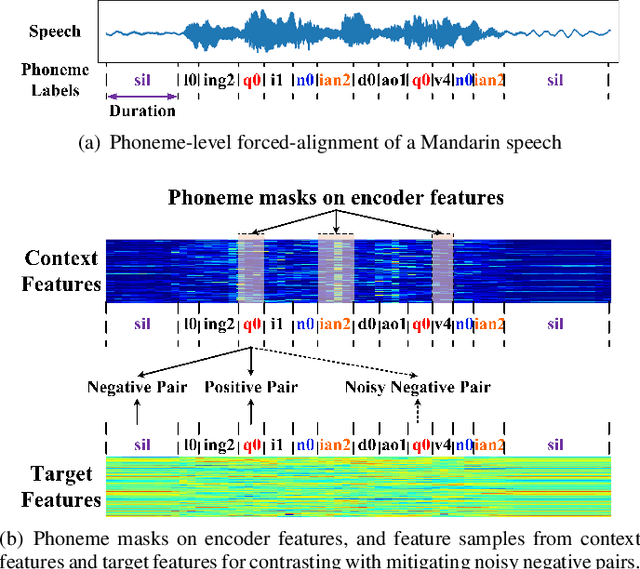
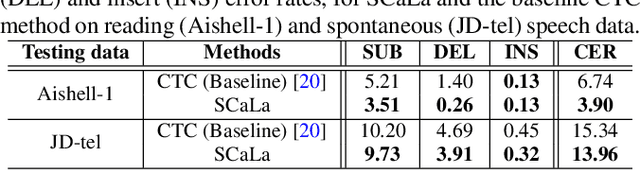
End-to-end Automatic Speech Recognition (ASR) models are usually trained to reduce the losses of the whole token sequences, while neglecting explicit phonemic-granularity supervision. This could lead to recognition errors due to similar-phoneme confusion or phoneme reduction. To alleviate this problem, this paper proposes a novel framework of Supervised Contrastive Learning (SCaLa) to enhance phonemic information learning for end-to-end ASR systems. Specifically, we introduce the self-supervised Masked Contrastive Predictive Coding (MCPC) into the fully-supervised setting. To supervise phoneme learning explicitly, SCaLa first masks the variable-length encoder features corresponding to phonemes given phoneme forced-alignment extracted from a pre-trained acoustic model, and then predicts the masked phonemes via contrastive learning. The phoneme forced-alignment can mitigate the noise of positive-negative pairs in self-supervised MCPC. Experimental results conducted on reading and spontaneous speech datasets show that the proposed approach achieves 2.84% and 1.38% Character Error Rate (CER) reductions compared to the baseline, respectively.
Transformer-based End-to-End Speech Recognition with Local Dense Synthesizer Attention
Oct 23, 2020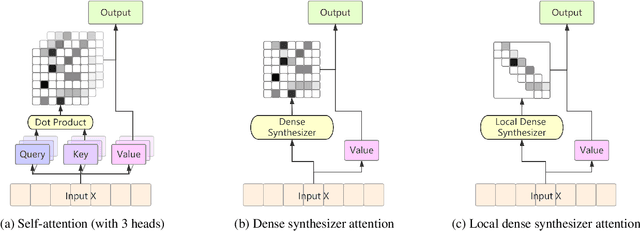

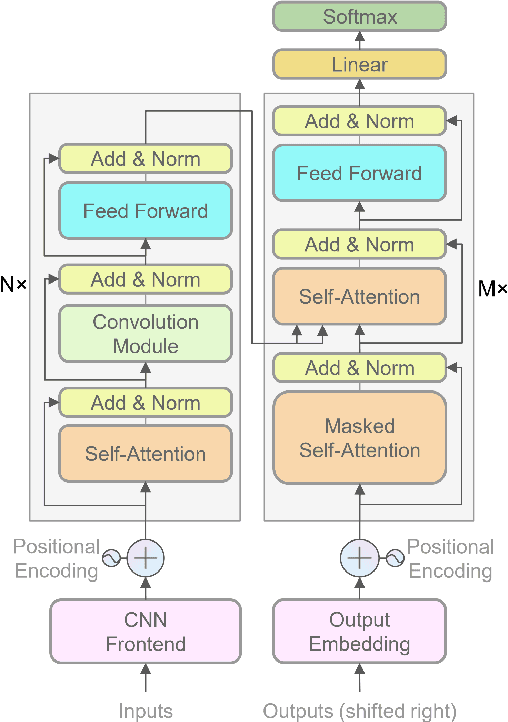
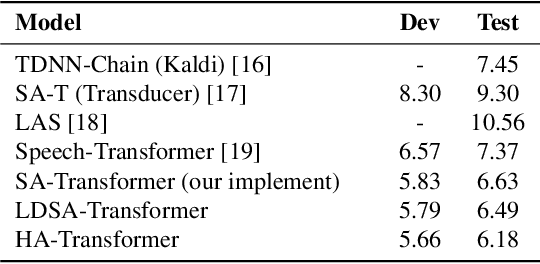
Recently, several studies reported that dot-product selfattention (SA) may not be indispensable to the state-of-theart Transformer models. Motivated by the fact that dense synthesizer attention (DSA), which dispenses with dot products and pairwise interactions, achieved competitive results in many language processing tasks, in this paper, we first propose a DSA-based speech recognition, as an alternative to SA. To reduce the computational complexity and improve the performance, we further propose local DSA (LDSA) to restrict the attention scope of DSA to a local range around the current central frame for speech recognition. Finally, we combine LDSA with SA to extract the local and global information simultaneously. Experimental results on the Ai-shell1 Mandarine speech recognition corpus show that the proposed LDSA-Transformer achieves a character error rate (CER) of 6.49%, which is slightly better than that of the SA-Transformer. Meanwhile, the LDSA-Transformer requires less computation than the SATransformer. The proposed combination method not only achieves a CER of 6.18%, which significantly outperforms the SA-Transformer, but also has roughly the same number of parameters and computational complexity as the latter. The implementation of the multi-head LDSA is available at https://github.com/mlxu995/multihead-LDSA.
On-Device Personalization of Automatic Speech Recognition Models for Disordered Speech
Jun 18, 2021
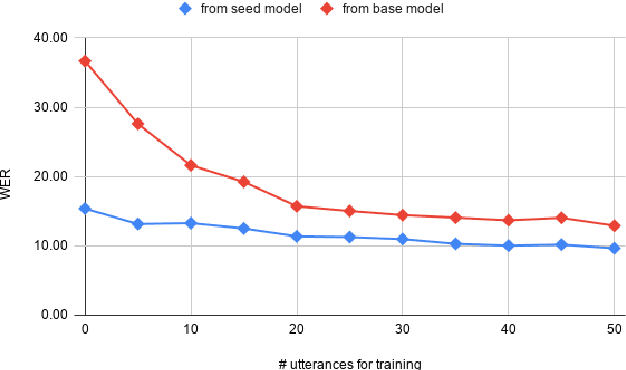
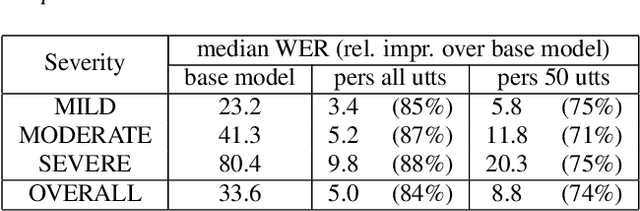
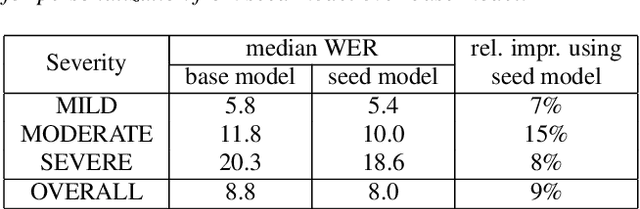
While current state-of-the-art Automatic Speech Recognition (ASR) systems achieve high accuracy on typical speech, they suffer from significant performance degradation on disordered speech and other atypical speech patterns. Personalization of ASR models, a commonly applied solution to this problem, is usually performed in a server-based training environment posing problems around data privacy, delayed model-update times, and communication cost for copying data and models between mobile device and server infrastructure. In this paper, we present an approach to on-device based ASR personalization with very small amounts of speaker-specific data. We test our approach on a diverse set of 100 speakers with disordered speech and find median relative word error rate improvement of 71% with only 50 short utterances required per speaker. When tested on a voice-controlled home automation platform, on-device personalized models show a median task success rate of 81%, compared to only 40% of the unadapted models.
The Multilingual TEDx Corpus for Speech Recognition and Translation
Feb 02, 2021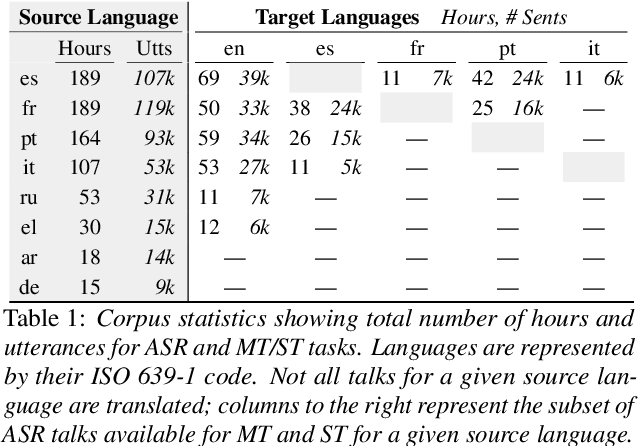
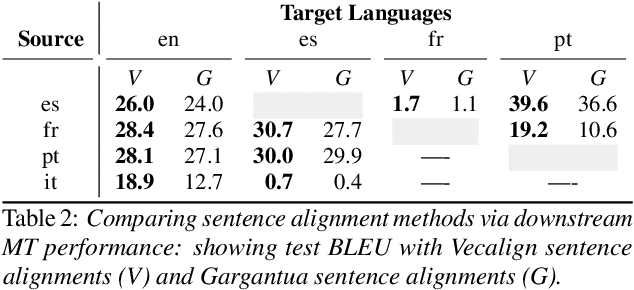
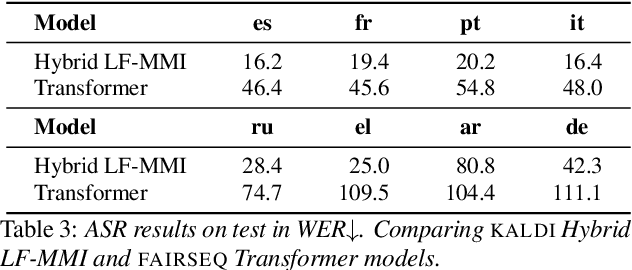
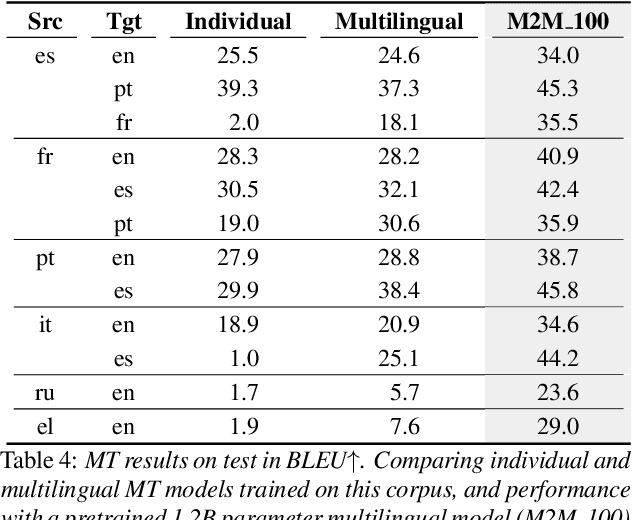
We present the Multilingual TEDx corpus, built to support speech recognition (ASR) and speech translation (ST) research across many non-English source languages. The corpus is a collection of audio recordings from TEDx talks in 8 source languages. We segment transcripts into sentences and align them to the source-language audio and target-language translations. The corpus is released along with open-sourced code enabling extension to new talks and languages as they become available. Our corpus creation methodology can be applied to more languages than previous work, and creates multi-way parallel evaluation sets. We provide baselines in multiple ASR and ST settings, including multilingual models to improve translation performance for low-resource language pairs.
AdaTranS: Adapting with Boundary-based Shrinking for End-to-End Speech Translation
Dec 17, 2022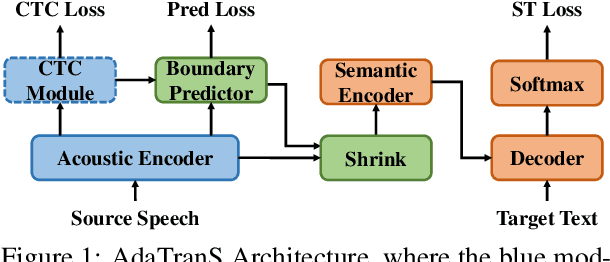


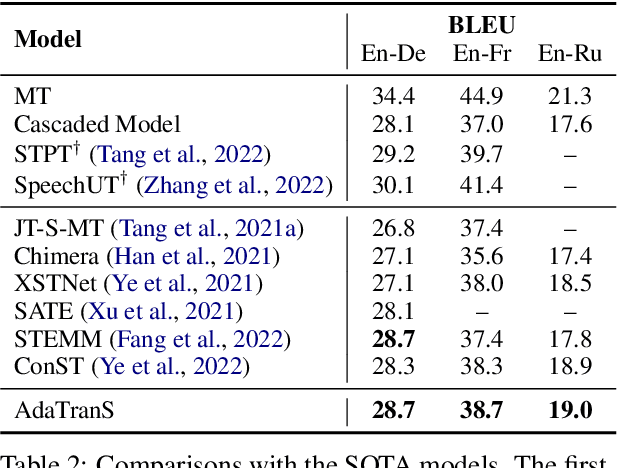
To alleviate the data scarcity problem in End-to-end speech translation (ST), pre-training on data for speech recognition and machine translation is considered as an important technique. However, the modality gap between speech and text prevents the ST model from efficiently inheriting knowledge from the pre-trained models. In this work, we propose AdaTranS for end-to-end ST. It adapts the speech features with a new shrinking mechanism to mitigate the length mismatch between speech and text features by predicting word boundaries. Experiments on the MUST-C dataset demonstrate that AdaTranS achieves better performance than the other shrinking-based methods, with higher inference speed and lower memory usage. Further experiments also show that AdaTranS can be equipped with additional alignment losses to further improve performance.
Building a great multi-lingual teacher with sparsely-gated mixture of experts for speech recognition
Dec 15, 2021
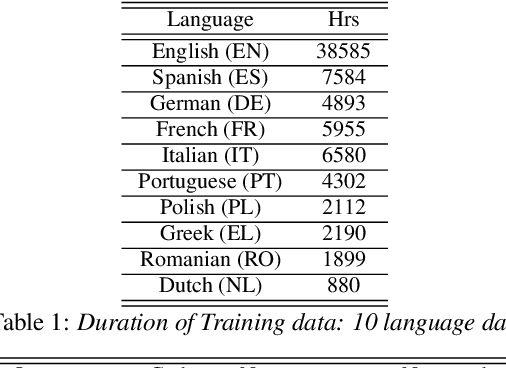
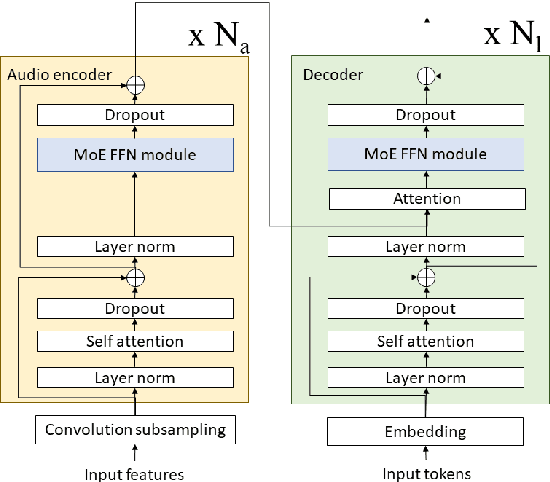
The sparsely-gated Mixture of Experts (MoE) can magnify a network capacity with a little computational complexity. In this work, we investigate how multi-lingual Automatic Speech Recognition (ASR) networks can be scaled up with a simple routing algorithm in order to achieve better accuracy. More specifically, we apply the sparsely-gated MoE technique to two types of networks: Sequence-to-Sequence Transformer (S2S-T) and Transformer Transducer (T-T). We demonstrate through a set of ASR experiments on multiple language data that the MoE networks can reduce the relative word error rates by 16.5% and 4.7% with the S2S-T and T-T, respectively. Moreover, we thoroughly investigate the effect of the MoE on the T-T architecture in various conditions: streaming mode, non-streaming mode, the use of language ID and the label decoder with the MoE.
Better Transcription of UK Supreme Court Hearings
Dec 22, 2022
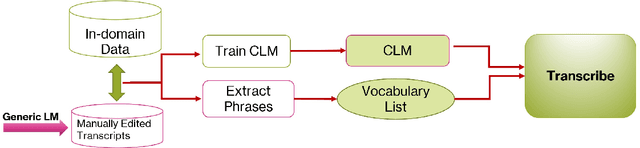
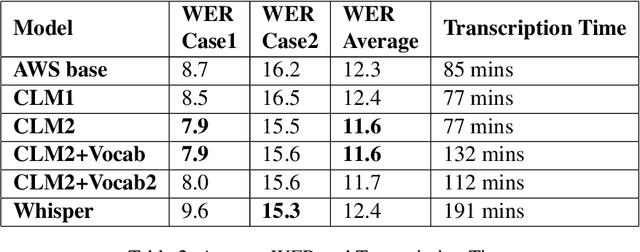
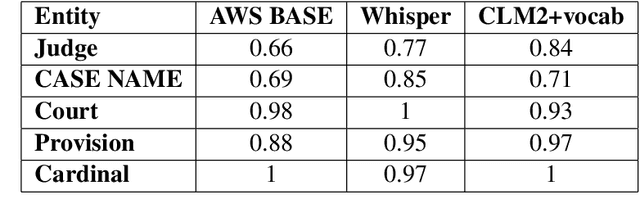
Transcription of legal proceedings is very important to enable access to justice. However, speech transcription is an expensive and slow process. In this paper we describe part of a combined research and industrial project for building an automated transcription tool designed specifically for the Justice sector in the UK. We explain the challenges involved in transcribing court room hearings and the Natural Language Processing (NLP) techniques we employ to tackle these challenges. We will show that fine-tuning a generic off-the-shelf pre-trained Automatic Speech Recognition (ASR) system with an in-domain language model as well as infusing common phrases extracted with a collocation detection model can improve not only the Word Error Rate (WER) of the transcribed hearings but avoid critical errors that are specific of the legal jargon and terminology commonly used in British courts.
Joint Speaker Counting, Speech Recognition, and Speaker Identification for Overlapped Speech of Any Number of Speakers
Jun 19, 2020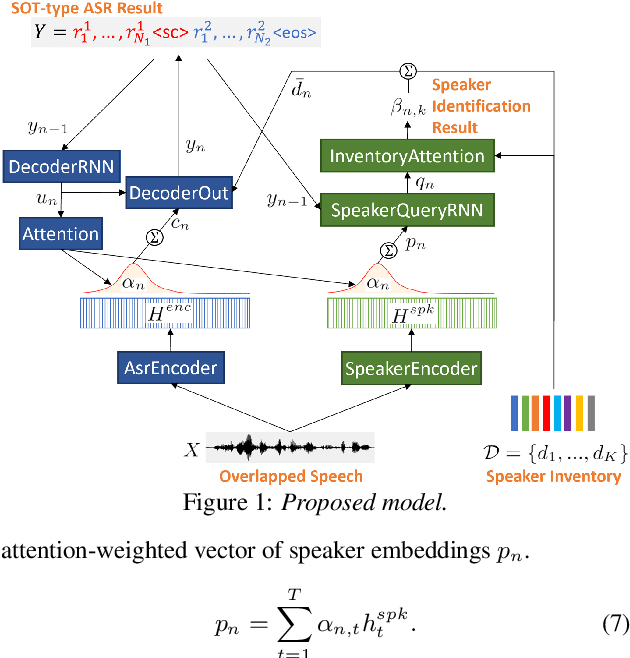
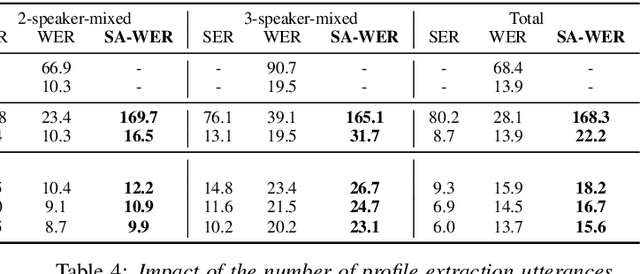
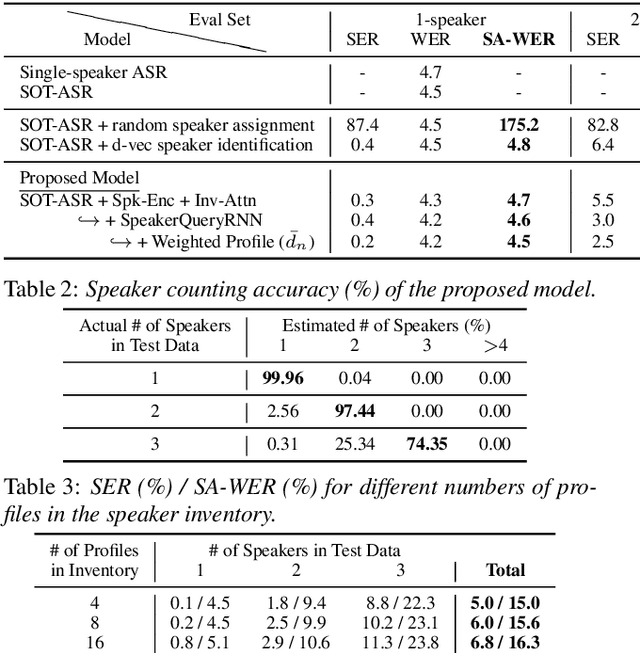
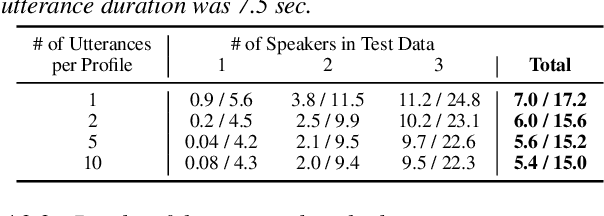
In this paper, we propose a joint model for simultaneous speaker counting, speech recognition, and speaker identification on monaural overlapped speech. Our model is built on serialized output training (SOT) with attention-based encoder-decoder, a recently proposed method for recognizing overlapped speech comprising an arbitrary number of speakers. We extend the SOT model by introducing a speaker inventory as an auxiliary input to produce speaker labels as well as multi-speaker transcriptions. All model parameters are optimized by speaker-attributed maximum mutual information criterion, which represents a joint probability for overlapped speech recognition and speaker identification. Experiments on LibriSpeech corpus show that our proposed method achieves significantly better speaker-attributed word error rate than the baseline that separately performs overlapped speech recognition and speaker identification.
Consistent Training and Decoding For End-to-end Speech Recognition Using Lattice-free MMI
Dec 05, 2021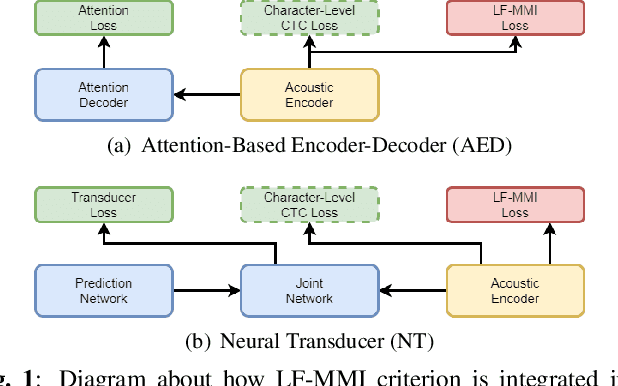
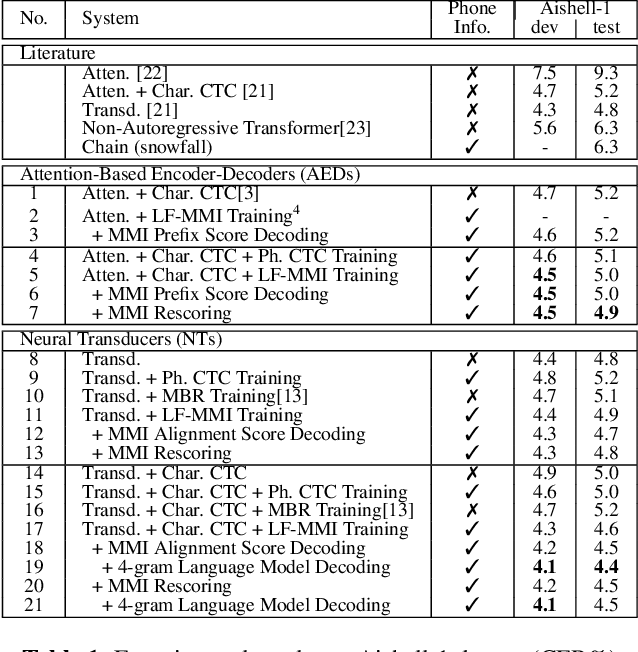
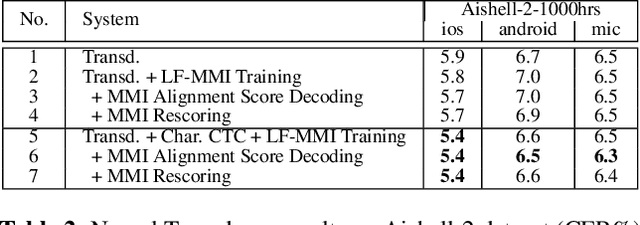
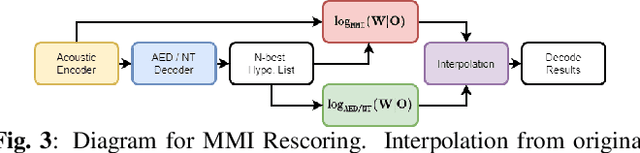
Recently, End-to-End (E2E) frameworks have achieved remarkable results on various Automatic Speech Recognition (ASR) tasks. However, Lattice-Free Maximum Mutual Information (LF-MMI), as one of the discriminative training criteria that show superior performance in hybrid ASR systems, is rarely adopted in E2E ASR frameworks. In this work, we propose a novel approach to integrate LF-MMI criterion into E2E ASR frameworks in both training and decoding stages. The proposed approach shows its effectiveness on two of the most widely used E2E frameworks including Attention-Based Encoder-Decoders (AEDs) and Neural Transducers (NTs). Experiments suggest that the introduction of the LF-MMI criterion consistently leads to significant performance improvements on various datasets and different E2E ASR frameworks. The best of our models achieves competitive CER of 4.1\% / 4.4\% on Aishell-1 dev/test set; we also achieve significant error reduction on Aishell-2 and Librispeech datasets over strong baselines.
Integrating Knowledge in End-to-End Automatic Speech Recognition for Mandarin-English Code-Switching
Dec 19, 2021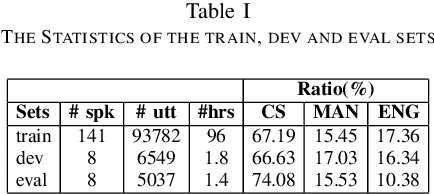
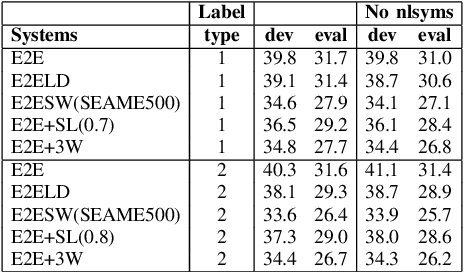

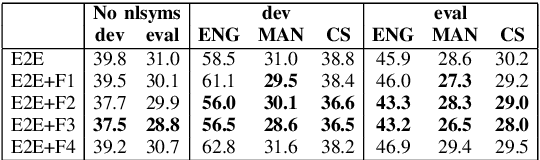
Code-Switching (CS) is a common linguistic phenomenon in multilingual communities that consists of switching between languages while speaking. This paper presents our investigations on end-to-end speech recognition for Mandarin-English CS speech. We analyse different CS specific issues such as the properties mismatches between languages in a CS language pair, the unpredictable nature of switching points, and the data scarcity problem. We exploit and improve the state-of-the-art end-to-end system by merging nonlinguistic symbols, by integrating language identification using hierarchical softmax, by modeling sub-word units, by artificially lowering the speaking rate, and by augmenting data using speed perturbed technique and several monolingual datasets to improve the final performance not only on CS speech but also on monolingual benchmarks in order to make the system more applicable on real life settings. Finally, we explore the effect of different language model integration methods on the performance of the proposed model. Our experimental results reveal that all the proposed techniques improve the recognition performance. The best combined system improves the baseline system by up to 35% relatively in terms of mixed error rate and delivers acceptable performance on monolingual benchmarks.