 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Exploring Transformers for Large-Scale Speech Recognition
May 19, 2020
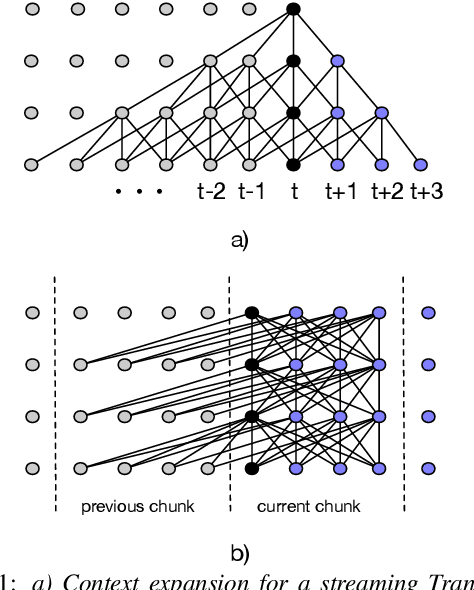
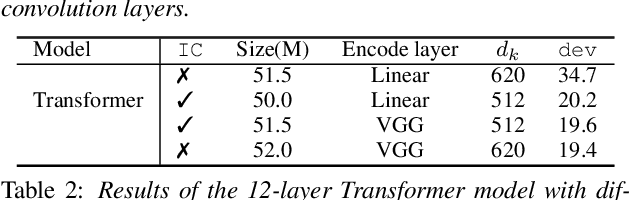
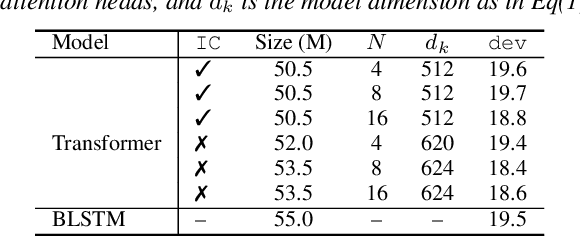
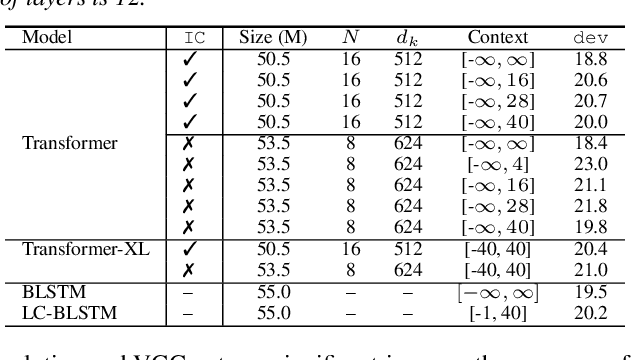
While recurrent neural networks still largely define state-of-the-art speech recognition systems, the Transformer network has been proven to be a competitive alternative, especially in the offline condition. Most studies with Transformers have been constrained in a relatively small scale setting, and some forms of data argumentation approaches are usually applied to combat the data sparsity issue. In this paper, we aim at understanding the behaviors of Transformers in the large-scale speech recognition setting, where we have used around 65,000 hours of training data. We investigated various aspects on scaling up Transformers, including model initialization, warmup training as well as different Layer Normalization strategies. In the streaming condition, we compared the widely used attention mask based future context lookahead approach to the Transformer-XL network. From our experiments, we show that Transformers can achieve around 6% relative word error rate (WER) reduction compared to the BLSTM baseline in the offline fashion, while in the streaming fashion, Transformer-XL is comparable to LC-BLSTM with 800 millisecond latency constraint.
Evaluating User Perception of Speech Recognition System Quality with Semantic Distance Metric
Oct 11, 2021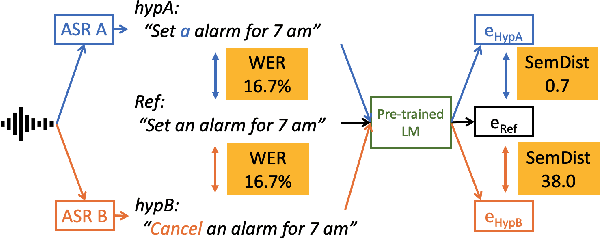
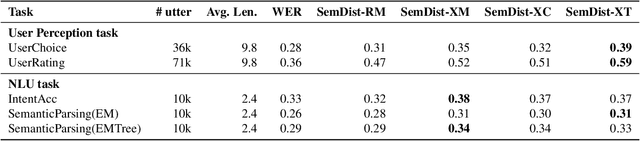
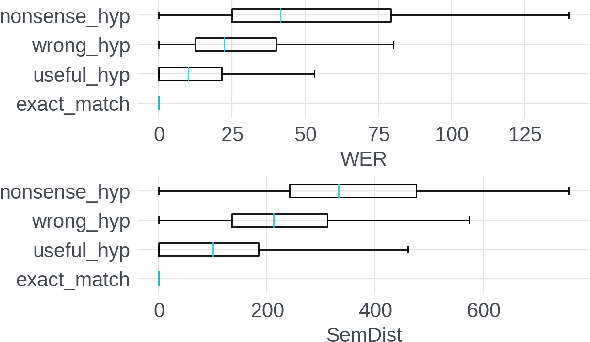
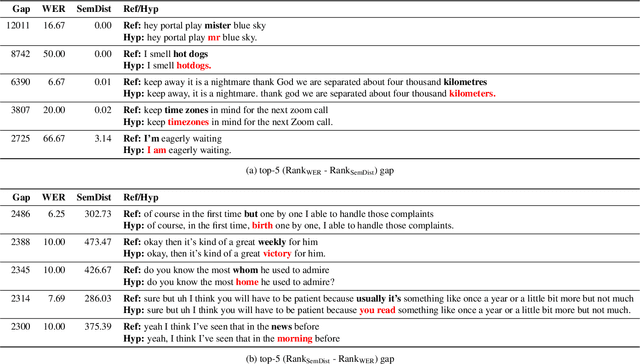
Measuring automatic speech recognition (ASR) system quality is critical for creating user-satisfying voice-driven applications. Word Error Rate (WER) has been traditionally used to evaluate ASR system quality; however, it sometimes correlates poorly with user perception of transcription quality. This is because WER weighs every word equally and does not consider semantic correctness which has a higher impact on user perception. In this work, we propose evaluating ASR output hypotheses quality with SemDist that can measure semantic correctness by using the distance between the semantic vectors of the reference and hypothesis extracted from a pre-trained language model. Our experimental results of 71K and 36K user annotated ASR output quality show that SemDist achieves higher correlation with user perception than WER. We also show that SemDist has higher correlation with downstream NLU tasks than WER.
Improved disentangled speech representations using contrastive learning in factorized hierarchical variational autoencoder
Nov 15, 2022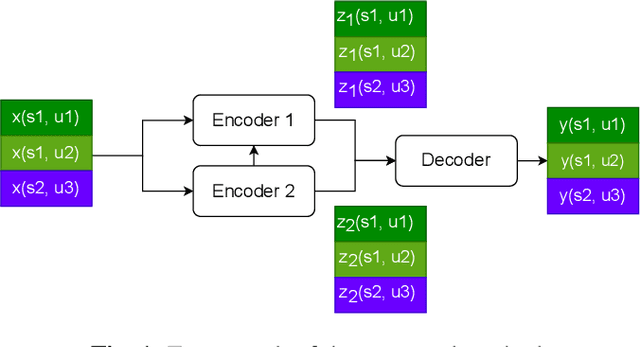
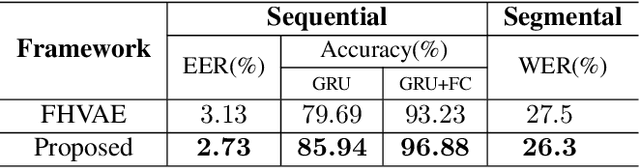
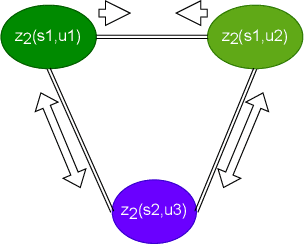
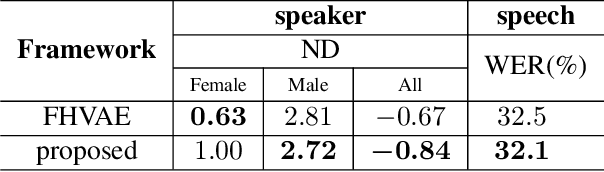
By utilizing the fact that speaker identity and content vary on different time scales, \acrlong{fhvae} (\acrshort{fhvae}) uses a sequential latent variable and a segmental latent variable to symbolize these two attributes. Disentanglement is carried out by assuming the latent variables representing speaker and content follow sequence-dependent and sequence-independent priors. For the sequence-dependent prior, \acrshort{fhvae} assumes a Gaussian distribution with an utterance-scale varying mean and a fixed small variance. The training process promotes sequential variables getting close to the mean of its prior with small variance. However, this constraint is relatively weak. Therefore, we introduce contrastive learning in the \acrshort{fhvae} framework. The proposed method aims to make the sequential variables clustering when representing the same speaker, while distancing themselves as far as possible from those of other speakers. The structure of the framework has not been changed in the proposed method but only the training process, thus no more cost is needed during test. Voice conversion has been chosen as the application in this paper. Latent variable evaluations include speakerincrease verification and identification for the sequential latent variable, and speech recognition for the segmental latent variable. Furthermore, assessments of voice conversion performance are on the grounds of speaker verification and speech recognition experiments. Experiment results show that the proposed method improves both sequential and segmental feature extraction compared with \acrshort{fhvae}, and moderately improved voice conversion performance.
On the limit of English conversational speech recognition
May 03, 2021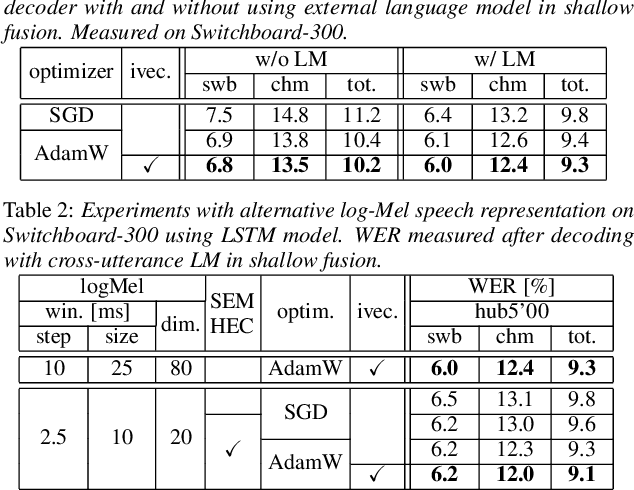
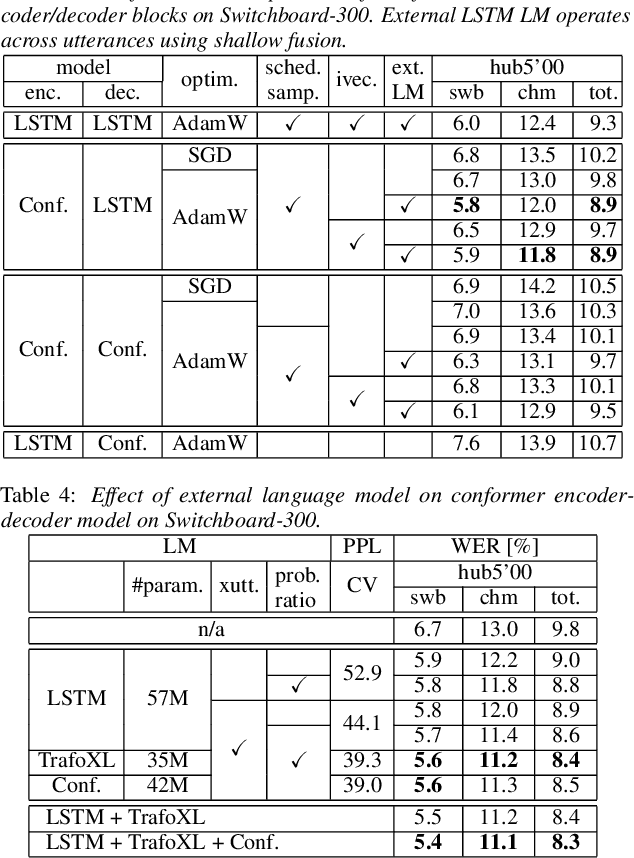
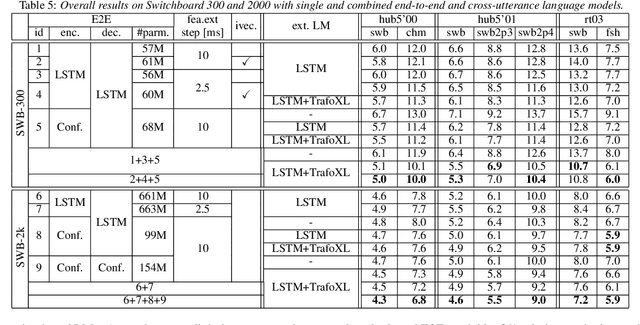
In our previous work we demonstrated that a single headed attention encoder-decoder model is able to reach state-of-the-art results in conversational speech recognition. In this paper, we further improve the results for both Switchboard 300 and 2000. Through use of an improved optimizer, speaker vector embeddings, and alternative speech representations we reduce the recognition errors of our LSTM system on Switchboard-300 by 4% relative. Compensation of the decoder model with the probability ratio approach allows more efficient integration of an external language model, and we report 5.9% and 11.5% WER on the SWB and CHM parts of Hub5'00 with very simple LSTM models. Our study also considers the recently proposed conformer, and more advanced self-attention based language models. Overall, the conformer shows similar performance to the LSTM; nevertheless, their combination and decoding with an improved LM reaches a new record on Switchboard-300, 5.0% and 10.0% WER on SWB and CHM. Our findings are also confirmed on Switchboard-2000, and a new state of the art is reported, practically reaching the limit of the benchmark.
SCaLa: Supervised Contrastive Learning for End-to-End Automatic Speech Recognition
Oct 08, 2021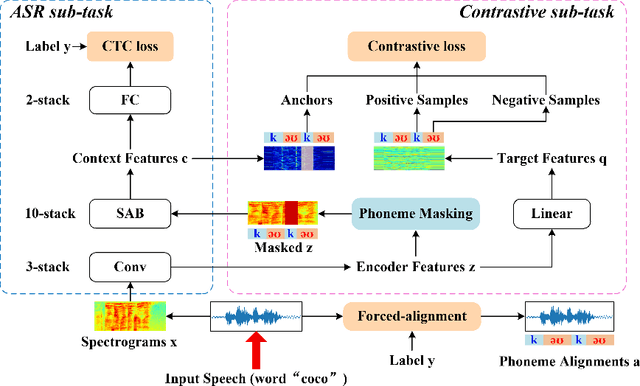
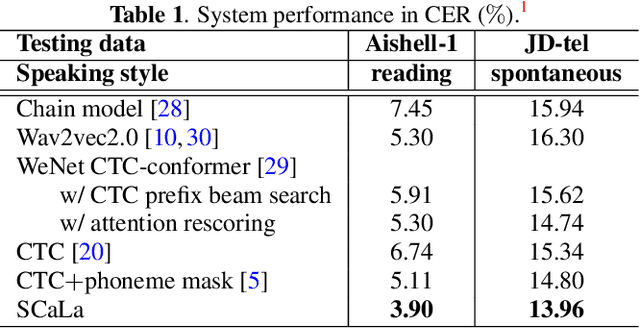
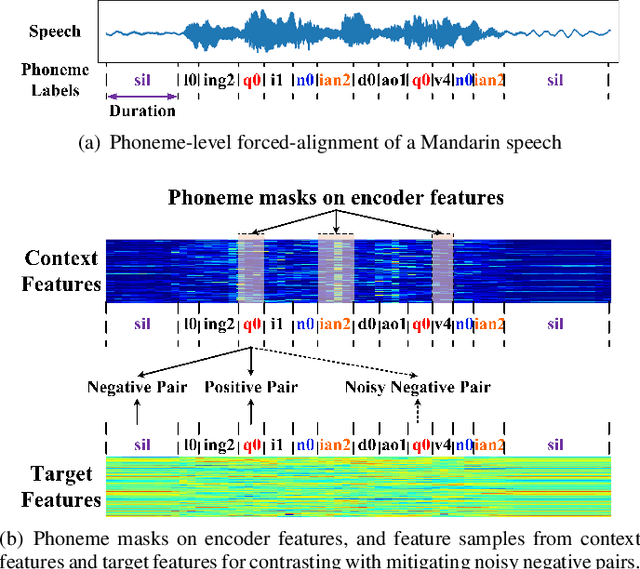
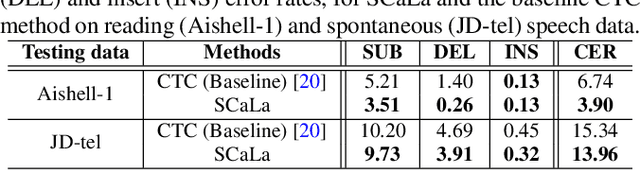
End-to-end Automatic Speech Recognition (ASR) models are usually trained to reduce the losses of the whole token sequences, while neglecting explicit phonemic-granularity supervision. This could lead to recognition errors due to similar-phoneme confusion or phoneme reduction. To alleviate this problem, this paper proposes a novel framework of Supervised Contrastive Learning (SCaLa) to enhance phonemic information learning for end-to-end ASR systems. Specifically, we introduce the self-supervised Masked Contrastive Predictive Coding (MCPC) into the fully-supervised setting. To supervise phoneme learning explicitly, SCaLa first masks the variable-length encoder features corresponding to phonemes given phoneme forced-alignment extracted from a pre-trained acoustic model, and then predicts the masked phonemes via contrastive learning. The phoneme forced-alignment can mitigate the noise of positive-negative pairs in self-supervised MCPC. Experimental results conducted on reading and spontaneous speech datasets show that the proposed approach achieves 2.84% and 1.38% Character Error Rate (CER) reductions compared to the baseline, respectively.
Transformer-based End-to-End Speech Recognition with Local Dense Synthesizer Attention
Oct 23, 2020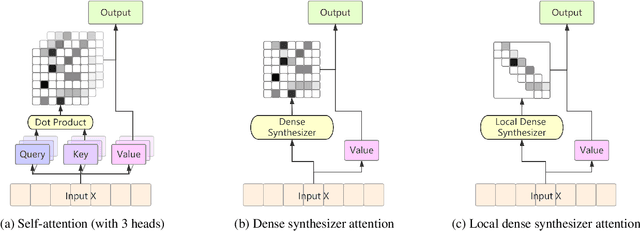

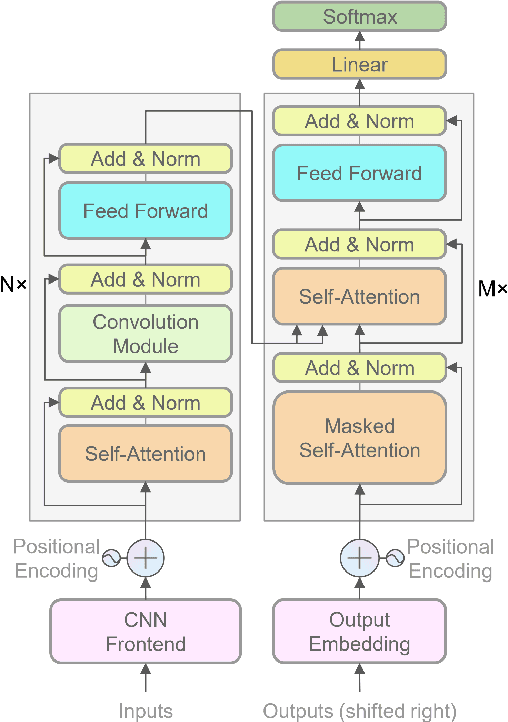
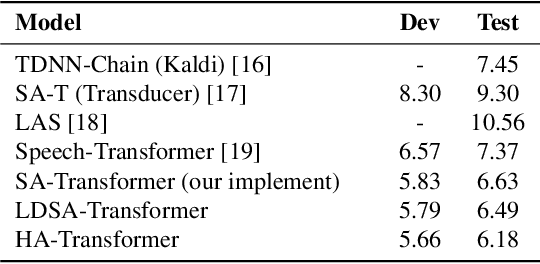
Recently, several studies reported that dot-product selfattention (SA) may not be indispensable to the state-of-theart Transformer models. Motivated by the fact that dense synthesizer attention (DSA), which dispenses with dot products and pairwise interactions, achieved competitive results in many language processing tasks, in this paper, we first propose a DSA-based speech recognition, as an alternative to SA. To reduce the computational complexity and improve the performance, we further propose local DSA (LDSA) to restrict the attention scope of DSA to a local range around the current central frame for speech recognition. Finally, we combine LDSA with SA to extract the local and global information simultaneously. Experimental results on the Ai-shell1 Mandarine speech recognition corpus show that the proposed LDSA-Transformer achieves a character error rate (CER) of 6.49%, which is slightly better than that of the SA-Transformer. Meanwhile, the LDSA-Transformer requires less computation than the SATransformer. The proposed combination method not only achieves a CER of 6.18%, which significantly outperforms the SA-Transformer, but also has roughly the same number of parameters and computational complexity as the latter. The implementation of the multi-head LDSA is available at https://github.com/mlxu995/multihead-LDSA.
AdaTranS: Adapting with Boundary-based Shrinking for End-to-End Speech Translation
Dec 17, 2022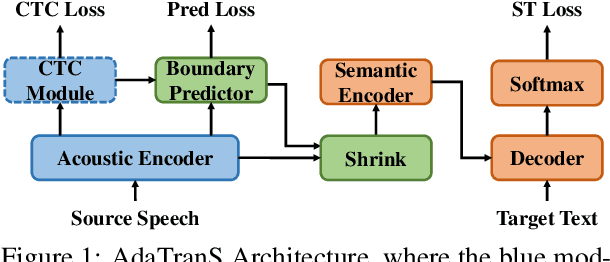


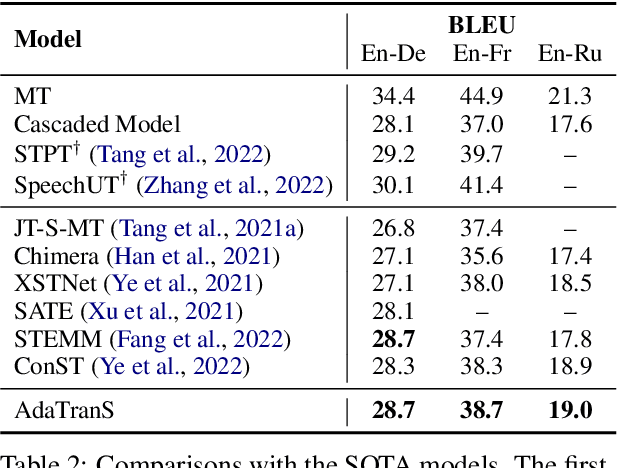
To alleviate the data scarcity problem in End-to-end speech translation (ST), pre-training on data for speech recognition and machine translation is considered as an important technique. However, the modality gap between speech and text prevents the ST model from efficiently inheriting knowledge from the pre-trained models. In this work, we propose AdaTranS for end-to-end ST. It adapts the speech features with a new shrinking mechanism to mitigate the length mismatch between speech and text features by predicting word boundaries. Experiments on the MUST-C dataset demonstrate that AdaTranS achieves better performance than the other shrinking-based methods, with higher inference speed and lower memory usage. Further experiments also show that AdaTranS can be equipped with additional alignment losses to further improve performance.
On-Device Personalization of Automatic Speech Recognition Models for Disordered Speech
Jun 18, 2021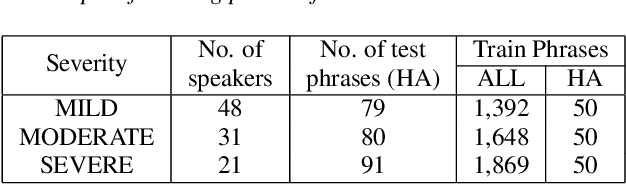
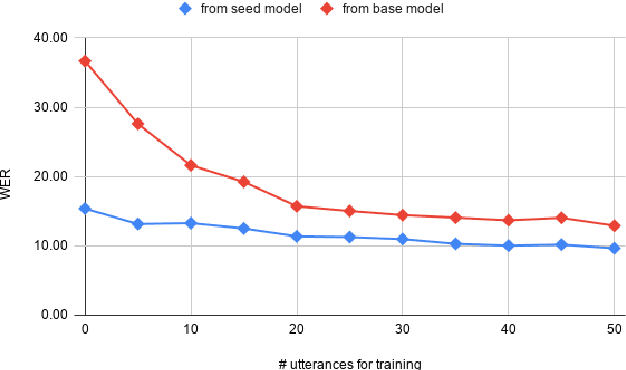
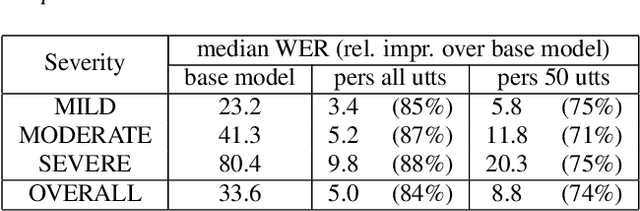
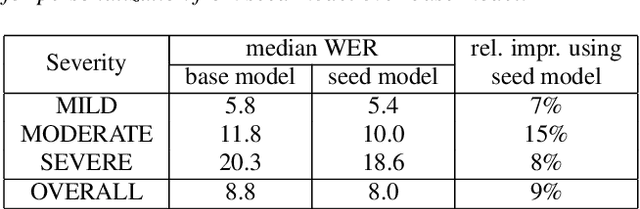
While current state-of-the-art Automatic Speech Recognition (ASR) systems achieve high accuracy on typical speech, they suffer from significant performance degradation on disordered speech and other atypical speech patterns. Personalization of ASR models, a commonly applied solution to this problem, is usually performed in a server-based training environment posing problems around data privacy, delayed model-update times, and communication cost for copying data and models between mobile device and server infrastructure. In this paper, we present an approach to on-device based ASR personalization with very small amounts of speaker-specific data. We test our approach on a diverse set of 100 speakers with disordered speech and find median relative word error rate improvement of 71% with only 50 short utterances required per speaker. When tested on a voice-controlled home automation platform, on-device personalized models show a median task success rate of 81%, compared to only 40% of the unadapted models.
Better Transcription of UK Supreme Court Hearings
Dec 22, 2022
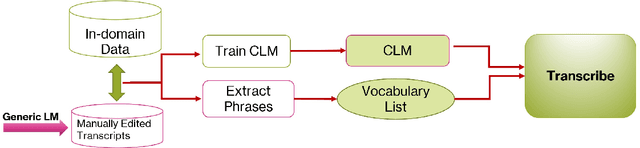
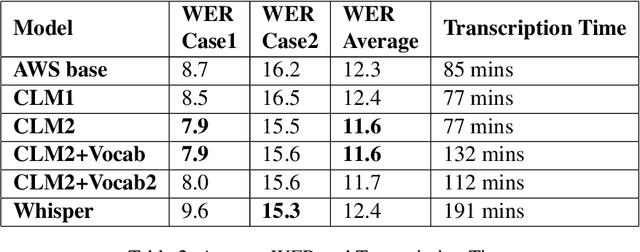
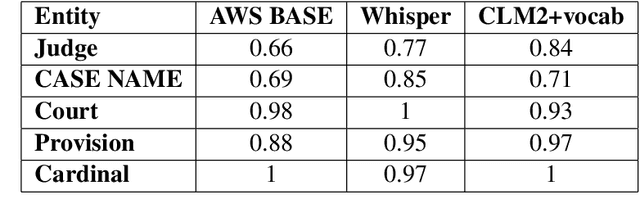
Transcription of legal proceedings is very important to enable access to justice. However, speech transcription is an expensive and slow process. In this paper we describe part of a combined research and industrial project for building an automated transcription tool designed specifically for the Justice sector in the UK. We explain the challenges involved in transcribing court room hearings and the Natural Language Processing (NLP) techniques we employ to tackle these challenges. We will show that fine-tuning a generic off-the-shelf pre-trained Automatic Speech Recognition (ASR) system with an in-domain language model as well as infusing common phrases extracted with a collocation detection model can improve not only the Word Error Rate (WER) of the transcribed hearings but avoid critical errors that are specific of the legal jargon and terminology commonly used in British courts.
The Multilingual TEDx Corpus for Speech Recognition and Translation
Feb 02, 2021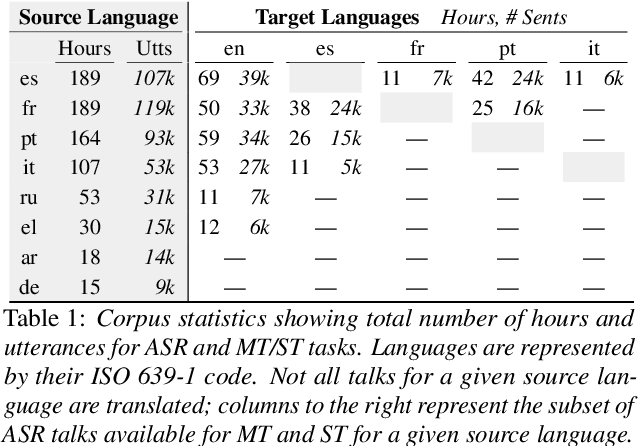
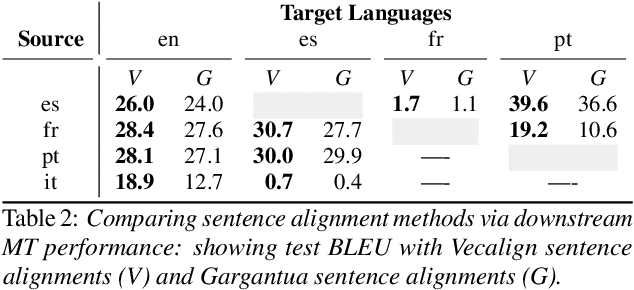
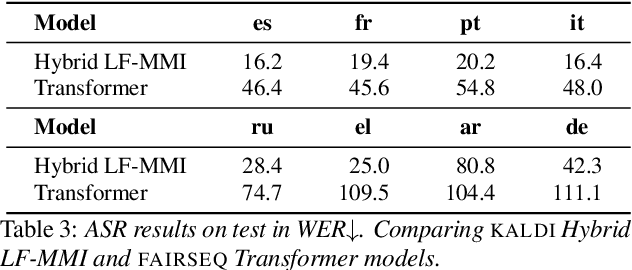
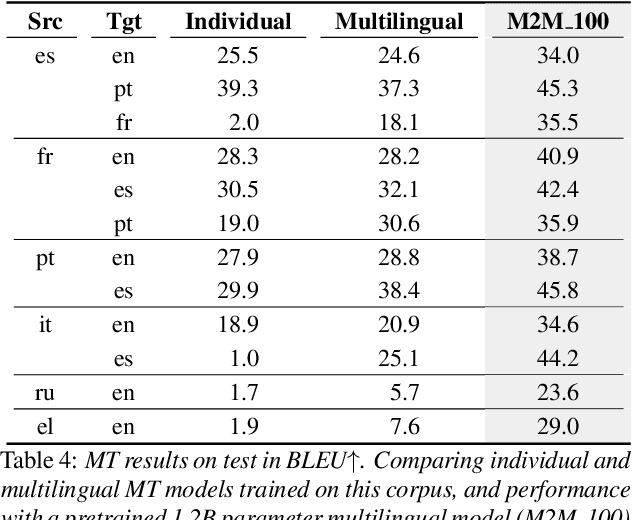
We present the Multilingual TEDx corpus, built to support speech recognition (ASR) and speech translation (ST) research across many non-English source languages. The corpus is a collection of audio recordings from TEDx talks in 8 source languages. We segment transcripts into sentences and align them to the source-language audio and target-language translations. The corpus is released along with open-sourced code enabling extension to new talks and languages as they become available. Our corpus creation methodology can be applied to more languages than previous work, and creates multi-way parallel evaluation sets. We provide baselines in multiple ASR and ST settings, including multilingual models to improve translation performance for low-resource language pairs.