 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Fast Classification Learning with Neural Networks and Conceptors for Speech Recognition and Car Driving Maneuvers
Feb 10, 2021
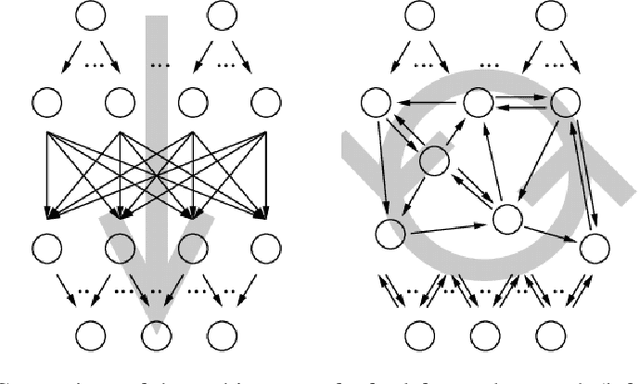
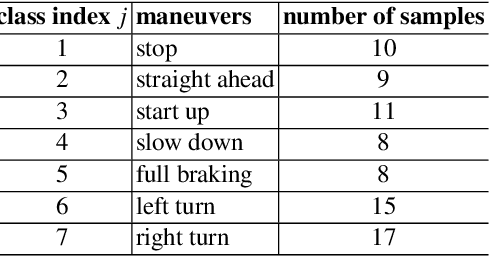
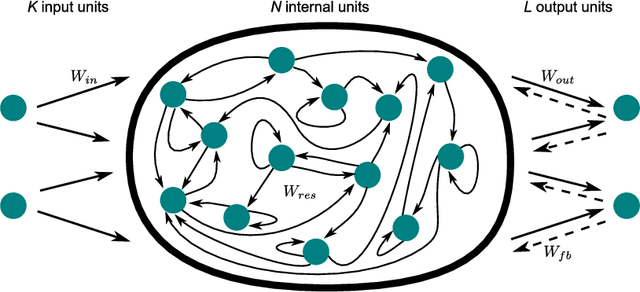
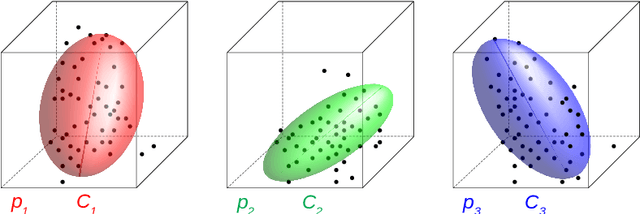
Recurrent neural networks are a powerful means in diverse applications. We show that, together with so-called conceptors, they also allow fast learning, in contrast to other deep learning methods. In addition, a relatively small number of examples suffices to train neural networks with high accuracy. We demonstrate this with two applications, namely speech recognition and detecting car driving maneuvers. We improve the state-of-the art by application-specific preparation techniques: For speech recognition, we use mel frequency cepstral coefficients leading to a compact representation of the frequency spectra, and detecting car driving maneuvers can be done without the commonly used polynomial interpolation, as our evaluation suggests.
Neural Architecture Search for Speech Recognition
Jul 17, 2020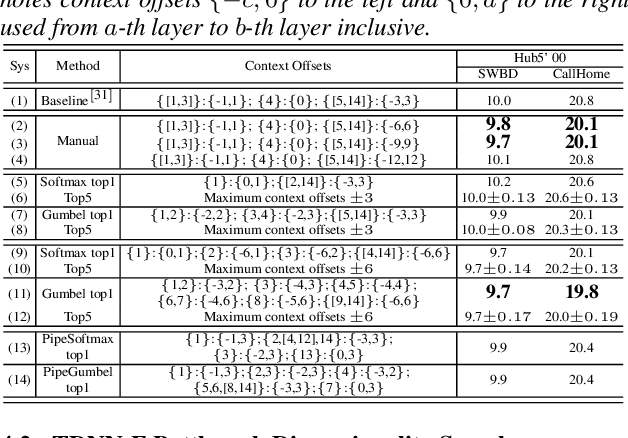
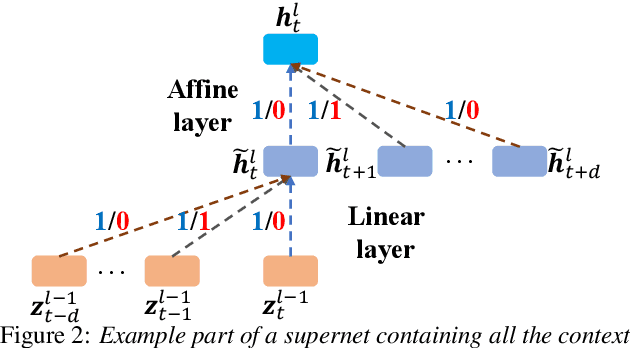
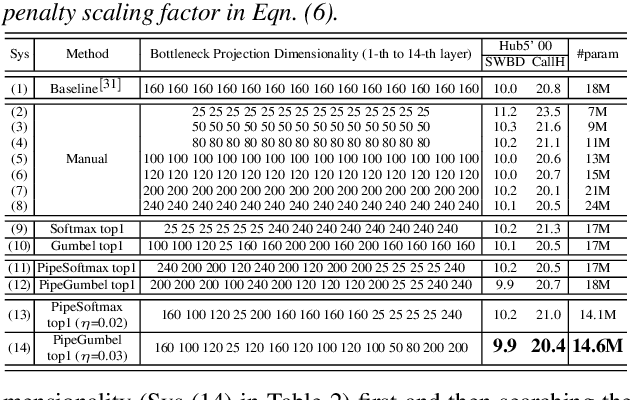
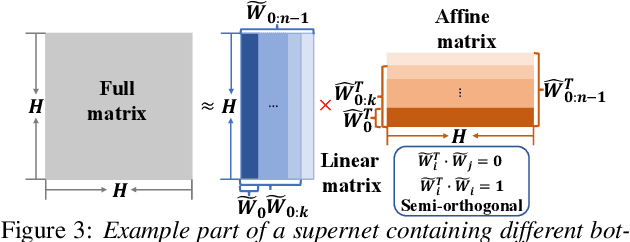
Deep neural networks (DNNs) based automatic speech recognition (ASR) systems are often designed using expert knowledge and empirical evaluation. In this paper, a range of neural architecture search (NAS) techniques are used to automatically learn two hyper-parameters that heavily affect the performance and model complexity of state-of-the-art factored time delay neural network (TDNN-F) acoustic models: i) the left and right splicing context offsets; and ii) the dimensionality of the bottleneck linear projection at each hidden layer. These include the standard DARTS method fully integrating the estimation of architecture weights and TDNN parameters in lattice-free MMI (LF-MMI) training; Gumbel-Softmax DARTS that reduces the confusion between candidate architectures; Pipelined DARTS that circumvents the overfitting of architecture weights using held-out data; and Penalized DARTS that further incorporates resource constraints to adjust the trade-off between performance and system complexity. Parameter sharing among candidate architectures was also used to facilitate efficient search over up to $7^{28}$ different TDNN systems. Experiments conducted on a 300-hour Switchboard conversational telephone speech recognition task suggest the NAS auto-configured TDNN-F systems consistently outperform the baseline LF-MMI trained TDNN-F systems using manual expert configurations. Absolute word error rate reductions up to 1.0% and relative model size reduction of 28% were obtained.
SpeechStew: Simply Mix All Available Speech Recognition Data to Train One Large Neural Network
Apr 12, 2021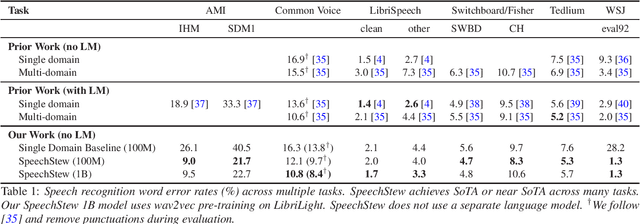
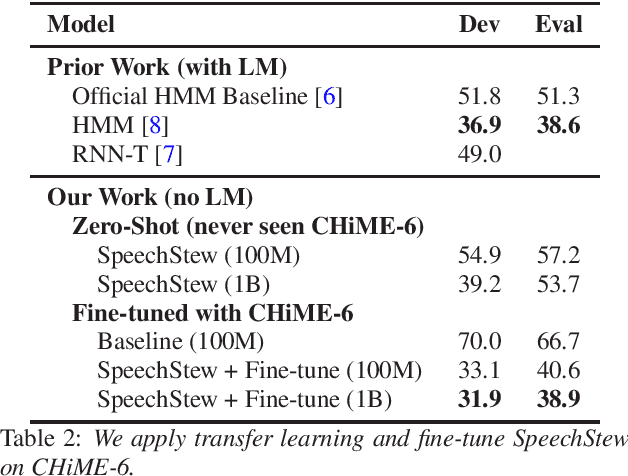
We present SpeechStew, a speech recognition model that is trained on a combination of various publicly available speech recognition datasets: AMI, Broadcast News, Common Voice, LibriSpeech, Switchboard/Fisher, Tedlium, and Wall Street Journal. SpeechStew simply mixes all of these datasets together, without any special re-weighting or re-balancing of the datasets. SpeechStew achieves SoTA or near SoTA results across a variety of tasks, without the use of an external language model. Our results include 9.0\% WER on AMI-IHM, 4.7\% WER on Switchboard, 8.3\% WER on CallHome, and 1.3\% on WSJ, which significantly outperforms prior work with strong external language models. We also demonstrate that SpeechStew learns powerful transfer learning representations. We fine-tune SpeechStew on a noisy low resource speech dataset, CHiME-6. We achieve 38.9\% WER without a language model, which compares to 38.6\% WER to a strong HMM baseline with a language model.
Learning to Detect Noisy Labels Using Model-Based Features
Dec 28, 2022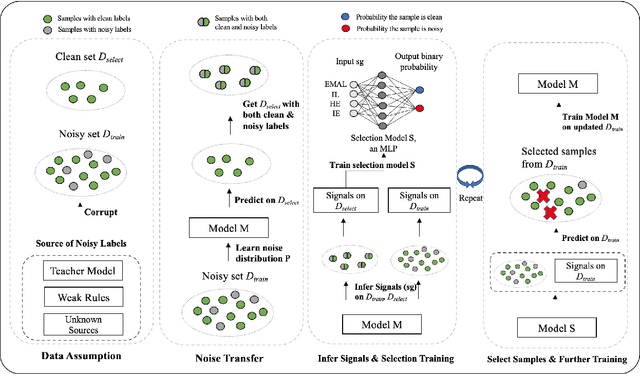
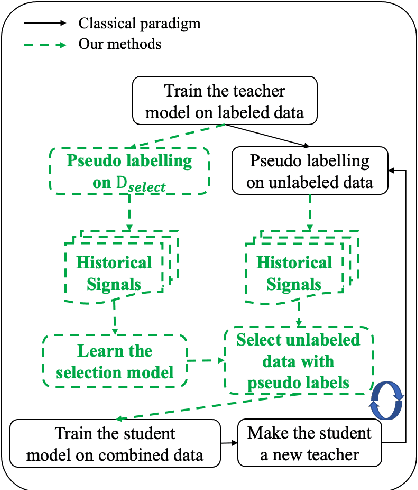
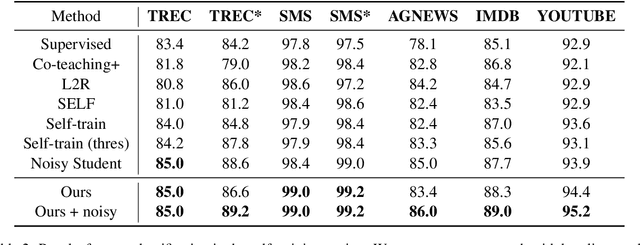
Label noise is ubiquitous in various machine learning scenarios such as self-labeling with model predictions and erroneous data annotation. Many existing approaches are based on heuristics such as sample losses, which might not be flexible enough to achieve optimal solutions. Meta learning based methods address this issue by learning a data selection function, but can be hard to optimize. In light of these pros and cons, we propose Selection-Enhanced Noisy label Training (SENT) that does not rely on meta learning while having the flexibility of being data-driven. SENT transfers the noise distribution to a clean set and trains a model to distinguish noisy labels from clean ones using model-based features. Empirically, on a wide range of tasks including text classification and speech recognition, SENT improves performance over strong baselines under the settings of self-training and label corruption.
Combining Multiple Views for Visual Speech Recognition
Jun 28, 2018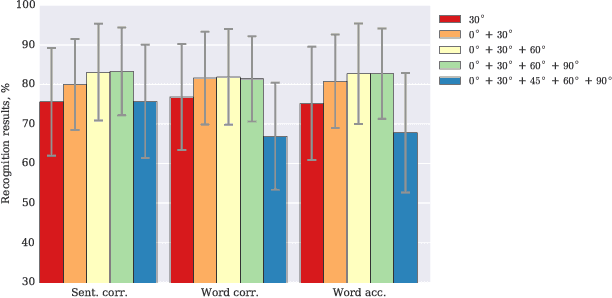
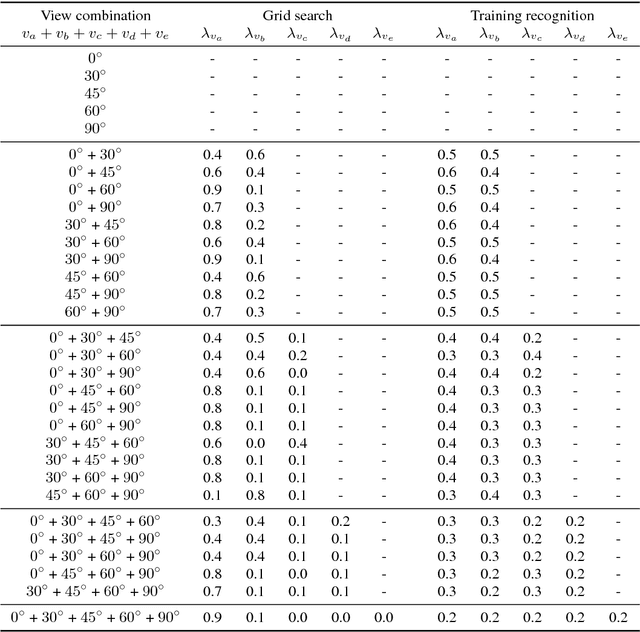
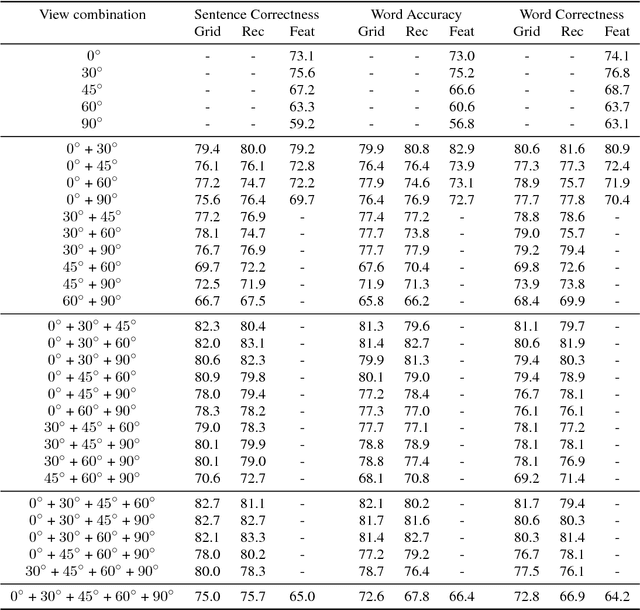
Visual speech recognition is a challenging research problem with a particular practical application of aiding audio speech recognition in noisy scenarios. Multiple camera setups can be beneficial for the visual speech recognition systems in terms of improved performance and robustness. In this paper, we explore this aspect and provide a comprehensive study on combining multiple views for visual speech recognition. The thorough analysis covers fusion of all possible view angle combinations both at feature level and decision level. The employed visual speech recognition system in this study extracts features through a PCA-based convolutional neural network, followed by an LSTM network. Finally, these features are processed in a tandem system, being fed into a GMM-HMM scheme. The decision fusion acts after this point by combining the Viterbi path log-likelihoods. The results show that the complementary information contained in recordings from different view angles improves the results significantly. For example, the sentence correctness on the test set is increased from 76% for the highest performing single view ($30^\circ$) to up to 83% when combining this view with the frontal and $60^\circ$ view angles.
Audio-visual multi-channel speech separation, dereverberation and recognition
Apr 08, 2022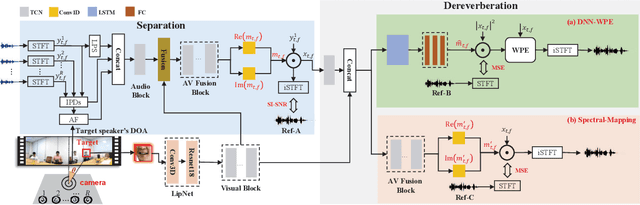

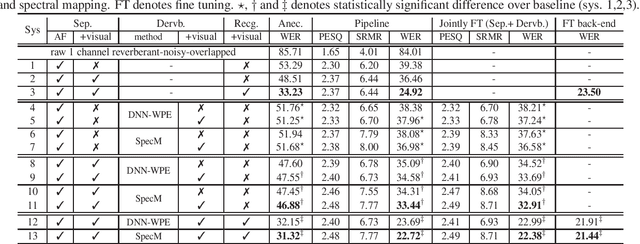
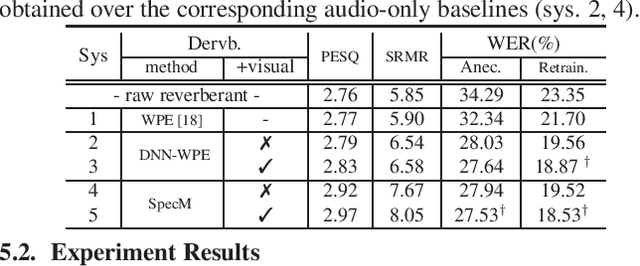
Despite the rapid advance of automatic speech recognition (ASR) technologies, accurate recognition of cocktail party speech characterised by the interference from overlapping speakers, background noise and room reverberation remains a highly challenging task to date. Motivated by the invariance of visual modality to acoustic signal corruption, audio-visual speech enhancement techniques have been developed, although predominantly targeting overlapping speech separation and recognition tasks. In this paper, an audio-visual multi-channel speech separation, dereverberation and recognition approach featuring a full incorporation of visual information into all three stages of the system is proposed. The advantage of the additional visual modality over using audio only is demonstrated on two neural dereverberation approaches based on DNN-WPE and spectral mapping respectively. The learning cost function mismatch between the separation and dereverberation models and their integration with the back-end recognition system is minimised using fine-tuning on the MSE and LF-MMI criteria. Experiments conducted on the LRS2 dataset suggest that the proposed audio-visual multi-channel speech separation, dereverberation and recognition system outperforms the baseline audio-visual multi-channel speech separation and recognition system containing no dereverberation module by a statistically significant word error rate (WER) reduction of 2.06% absolute (8.77% relative).
Contextual Biasing of Language Models for Speech Recognition in Goal-Oriented Conversational Agents
Mar 19, 2021
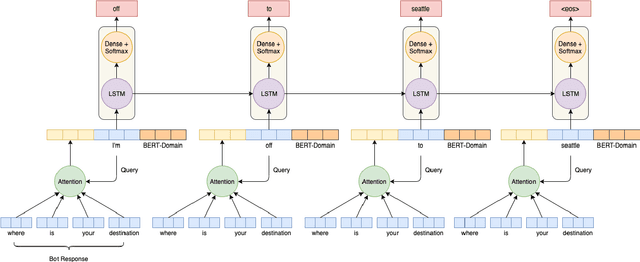
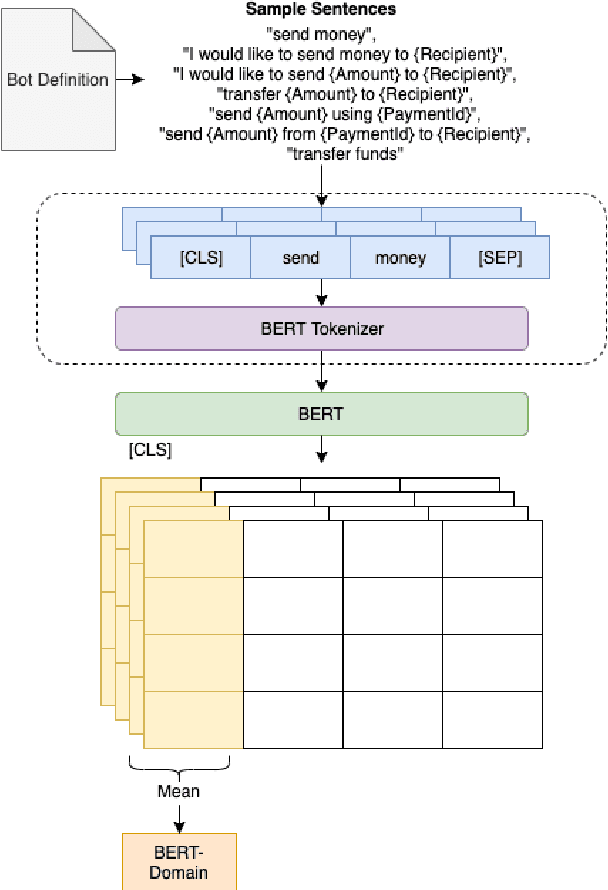
Goal-oriented conversational interfaces are designed to accomplish specific tasks and typically have interactions that tend to span multiple turns adhering to a pre-defined structure and a goal. However, conventional neural language models (NLM) in Automatic Speech Recognition (ASR) systems are mostly trained sentence-wise with limited context. In this paper, we explore different ways to incorporate context into a LSTM based NLM in order to model long range dependencies and improve speech recognition. Specifically, we use context carry over across multiple turns and use lexical contextual cues such as system dialog act from Natural Language Understanding (NLU) models and the user provided structure of the chatbot. We also propose a new architecture that utilizes context embeddings derived from BERT on sample utterances provided during inference time. Our experiments show a word error rate (WER) relative reduction of 7% over non-contextual utterance-level NLM rescorers on goal-oriented audio datasets.
Efficient Weight factorization for Multilingual Speech Recognition
May 07, 2021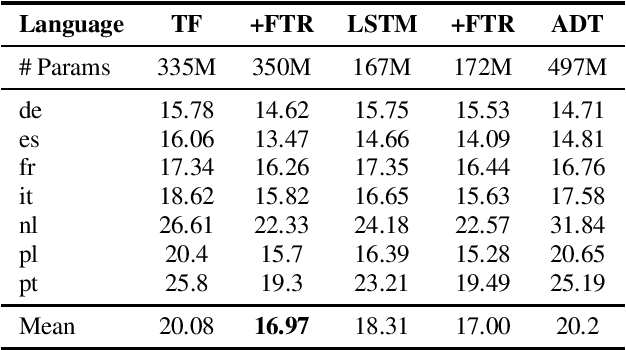
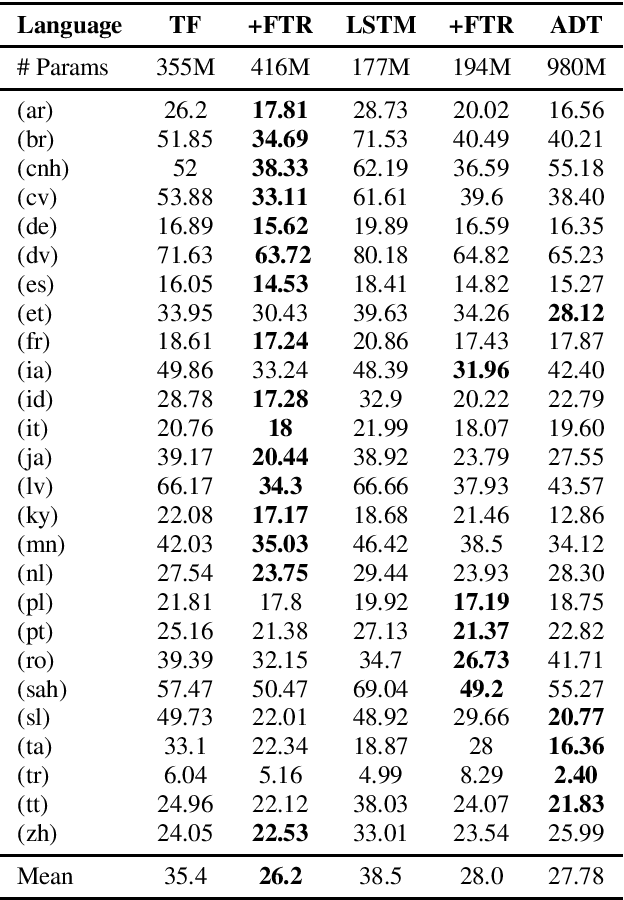
End-to-end multilingual speech recognition involves using a single model training on a compositional speech corpus including many languages, resulting in a single neural network to handle transcribing different languages. Due to the fact that each language in the training data has different characteristics, the shared network may struggle to optimize for all various languages simultaneously. In this paper we propose a novel multilingual architecture that targets the core operation in neural networks: linear transformation functions. The key idea of the method is to assign fast weight matrices for each language by decomposing each weight matrix into a shared component and a language dependent component. The latter is then factorized into vectors using rank-1 assumptions to reduce the number of parameters per language. This efficient factorization scheme is proved to be effective in two multilingual settings with $7$ and $27$ languages, reducing the word error rates by $26\%$ and $27\%$ rel. for two popular architectures LSTM and Transformer, respectively.