 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Accented Speech Recognition Inspired by Human Perception
Apr 09, 2021
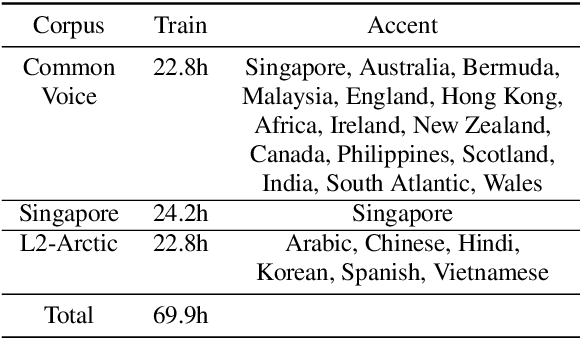
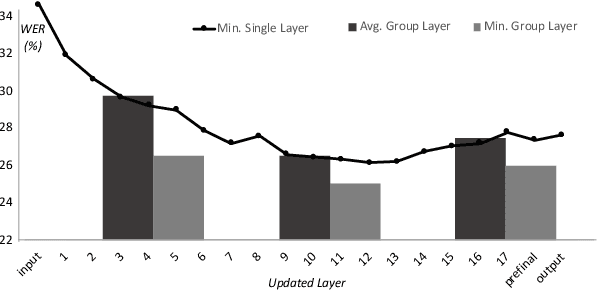
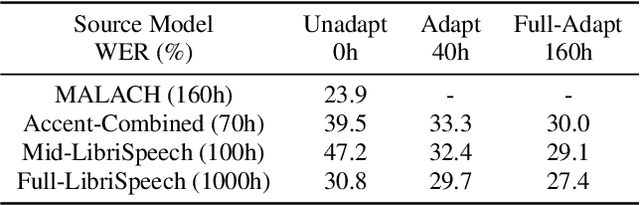
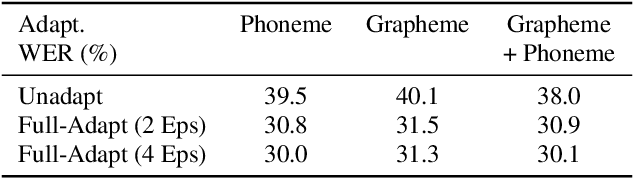
While improvements have been made in automatic speech recognition performance over the last several years, machines continue to have significantly lower performance on accented speech than humans. In addition, the most significant improvements on accented speech primarily arise by overwhelming the problem with hundreds or even thousands of hours of data. Humans typically require much less data to adapt to a new accent. This paper explores methods that are inspired by human perception to evaluate possible performance improvements for recognition of accented speech, with a specific focus on recognizing speech with a novel accent relative to that of the training data. Our experiments are run on small, accessible datasets that are available to the research community. We explore four methodologies: pre-exposure to multiple accents, grapheme and phoneme-based pronunciations, dropout (to improve generalization to a novel accent), and the identification of the layers in the neural network that can specifically be associated with accent modeling. Our results indicate that methods based on human perception are promising in reducing WER and understanding how accented speech is modeled in neural networks for novel accents.
Macro-block dropout for improved regularization in training end-to-end speech recognition models
Dec 29, 2022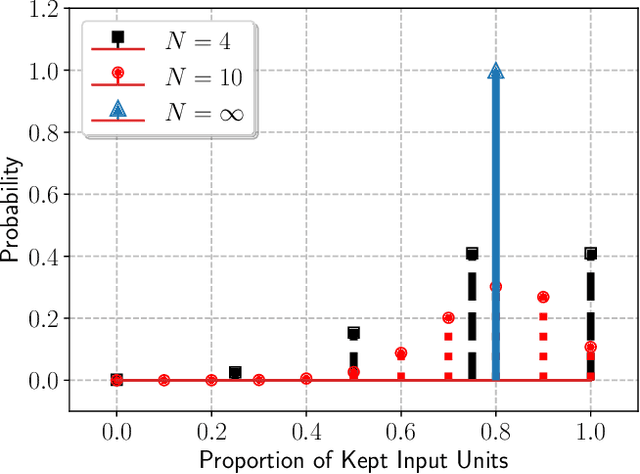


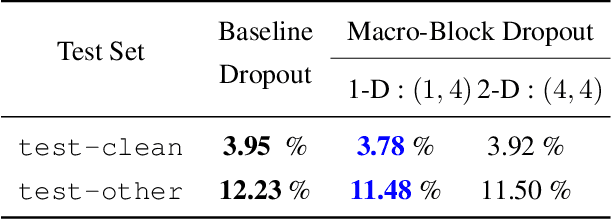
This paper proposes a new regularization algorithm referred to as macro-block dropout. The overfitting issue has been a difficult problem in training large neural network models. The dropout technique has proven to be simple yet very effective for regularization by preventing complex co-adaptations during training. In our work, we define a macro-block that contains a large number of units from the input to a Recurrent Neural Network (RNN). Rather than applying dropout to each unit, we apply random dropout to each macro-block. This algorithm has the effect of applying different drop out rates for each layer even if we keep a constant average dropout rate, which has better regularization effects. In our experiments using Recurrent Neural Network-Transducer (RNN-T), this algorithm shows relatively 4.30 % and 6.13 % Word Error Rates (WERs) improvement over the conventional dropout on LibriSpeech test-clean and test-other. With an Attention-based Encoder-Decoder (AED) model, this algorithm shows relatively 4.36 % and 5.85 % WERs improvement over the conventional dropout on the same test sets.
Privacy attacks for automatic speech recognition acoustic models in a federated learning framework
Nov 06, 2021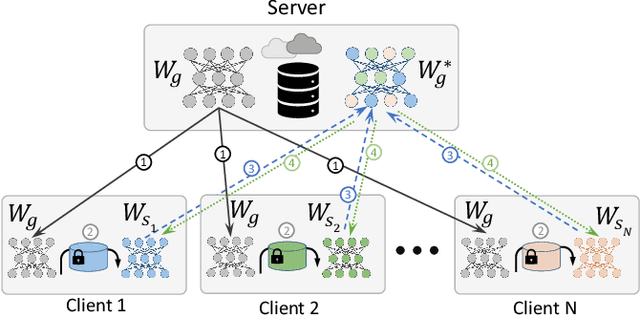
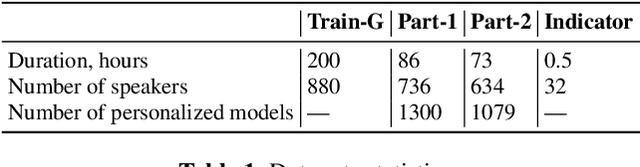
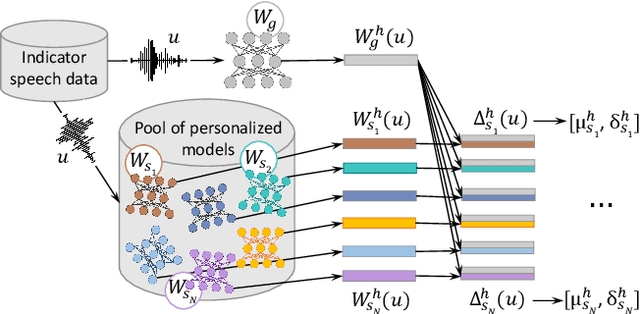

This paper investigates methods to effectively retrieve speaker information from the personalized speaker adapted neural network acoustic models (AMs) in automatic speech recognition (ASR). This problem is especially important in the context of federated learning of ASR acoustic models where a global model is learnt on the server based on the updates received from multiple clients. We propose an approach to analyze information in neural network AMs based on a neural network footprint on the so-called Indicator dataset. Using this method, we develop two attack models that aim to infer speaker identity from the updated personalized models without access to the actual users' speech data. Experiments on the TED-LIUM 3 corpus demonstrate that the proposed approaches are very effective and can provide equal error rate (EER) of 1-2%.
Retrieving Speaker Information from Personalized Acoustic Models for Speech Recognition
Nov 07, 2021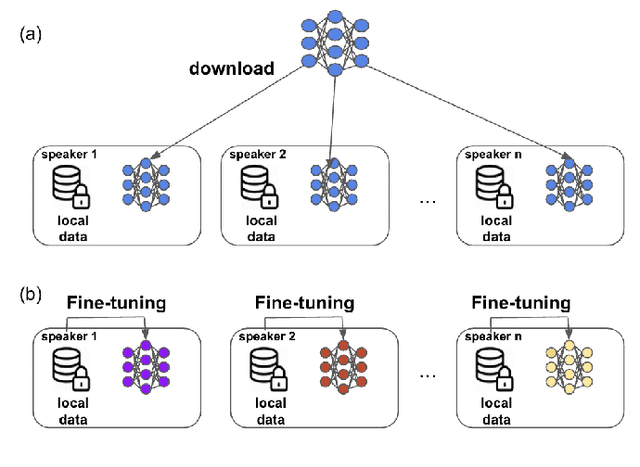

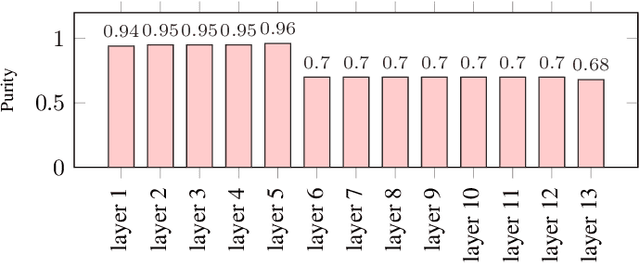
The widespread of powerful personal devices capable of collecting voice of their users has opened the opportunity to build speaker adapted speech recognition system (ASR) or to participate to collaborative learning of ASR. In both cases, personalized acoustic models (AM), i.e. fine-tuned AM with specific speaker data, can be built. A question that naturally arises is whether the dissemination of personalized acoustic models can leak personal information. In this paper, we show that it is possible to retrieve the gender of the speaker, but also his identity, by just exploiting the weight matrix changes of a neural acoustic model locally adapted to this speaker. Incidentally we observe phenomena that may be useful towards explainability of deep neural networks in the context of speech processing. Gender can be identified almost surely using only the first layers and speaker verification performs well when using middle-up layers. Our experimental study on the TED-LIUM 3 dataset with HMM/TDNN models shows an accuracy of 95% for gender detection, and an Equal Error Rate of 9.07% for a speaker verification task by only exploiting the weights from personalized models that could be exchanged instead of user data.
Improved disentangled speech representations using contrastive learning in factorized hierarchical variational autoencoder
Nov 15, 2022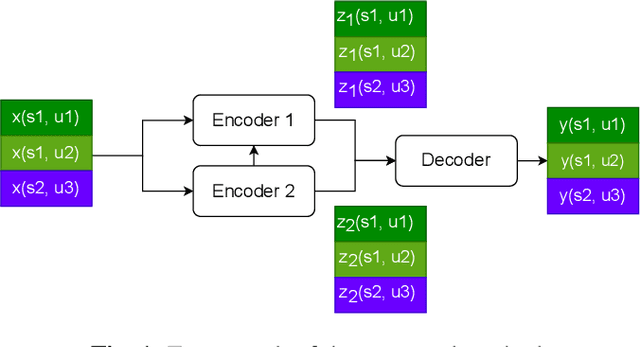
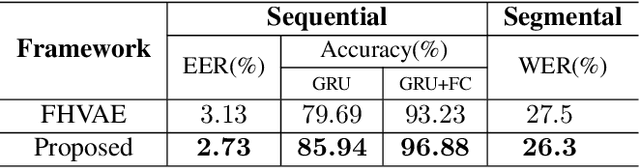
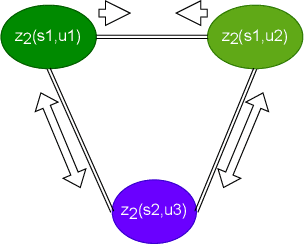
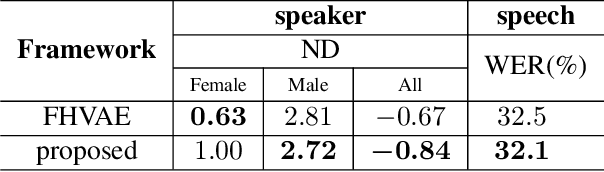
By utilizing the fact that speaker identity and content vary on different time scales, \acrlong{fhvae} (\acrshort{fhvae}) uses a sequential latent variable and a segmental latent variable to symbolize these two attributes. Disentanglement is carried out by assuming the latent variables representing speaker and content follow sequence-dependent and sequence-independent priors. For the sequence-dependent prior, \acrshort{fhvae} assumes a Gaussian distribution with an utterance-scale varying mean and a fixed small variance. The training process promotes sequential variables getting close to the mean of its prior with small variance. However, this constraint is relatively weak. Therefore, we introduce contrastive learning in the \acrshort{fhvae} framework. The proposed method aims to make the sequential variables clustering when representing the same speaker, while distancing themselves as far as possible from those of other speakers. The structure of the framework has not been changed in the proposed method but only the training process, thus no more cost is needed during test. Voice conversion has been chosen as the application in this paper. Latent variable evaluations include speakerincrease verification and identification for the sequential latent variable, and speech recognition for the segmental latent variable. Furthermore, assessments of voice conversion performance are on the grounds of speaker verification and speech recognition experiments. Experiment results show that the proposed method improves both sequential and segmental feature extraction compared with \acrshort{fhvae}, and moderately improved voice conversion performance.
AdaTranS: Adapting with Boundary-based Shrinking for End-to-End Speech Translation
Dec 17, 2022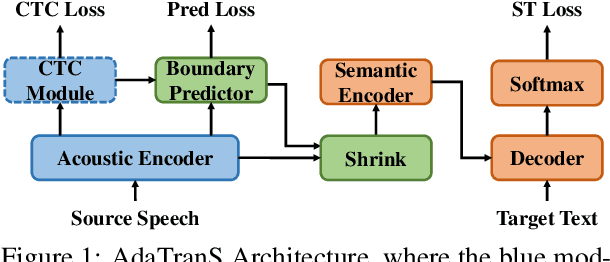


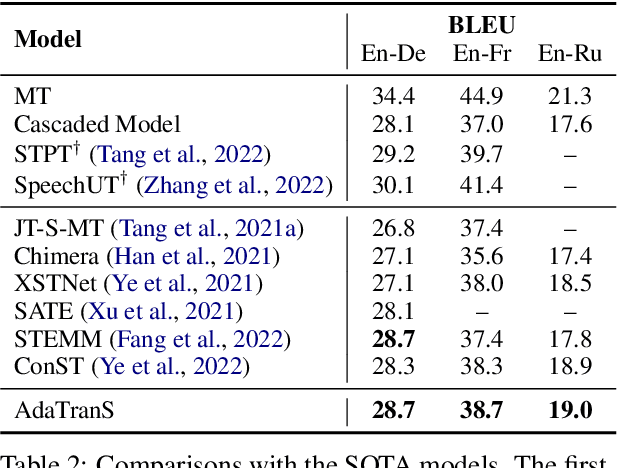
To alleviate the data scarcity problem in End-to-end speech translation (ST), pre-training on data for speech recognition and machine translation is considered as an important technique. However, the modality gap between speech and text prevents the ST model from efficiently inheriting knowledge from the pre-trained models. In this work, we propose AdaTranS for end-to-end ST. It adapts the speech features with a new shrinking mechanism to mitigate the length mismatch between speech and text features by predicting word boundaries. Experiments on the MUST-C dataset demonstrate that AdaTranS achieves better performance than the other shrinking-based methods, with higher inference speed and lower memory usage. Further experiments also show that AdaTranS can be equipped with additional alignment losses to further improve performance.
Enabling On-Device Training of Speech Recognition Models with Federated Dropout
Oct 07, 2021
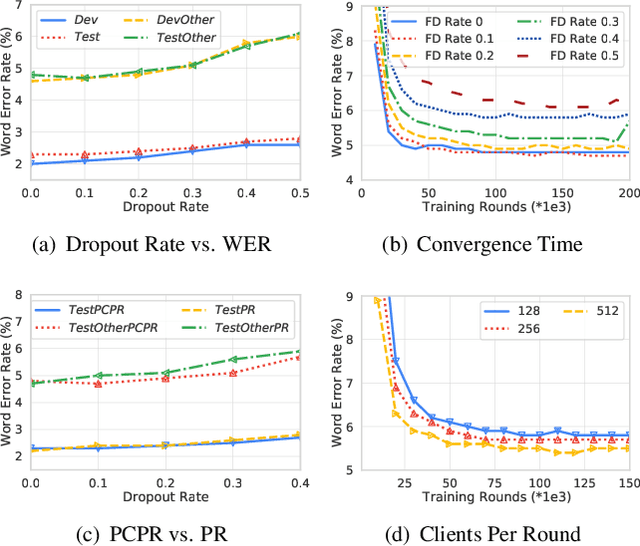

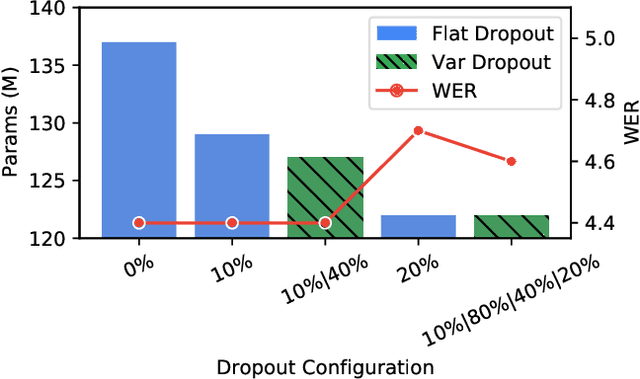
Federated learning can be used to train machine learning models on the edge on local data that never leave devices, providing privacy by default. This presents a challenge pertaining to the communication and computation costs associated with clients' devices. These costs are strongly correlated with the size of the model being trained, and are significant for state-of-the-art automatic speech recognition models. We propose using federated dropout to reduce the size of client models while training a full-size model server-side. We provide empirical evidence of the effectiveness of federated dropout, and propose a novel approach to vary the dropout rate applied at each layer. Furthermore, we find that federated dropout enables a set of smaller sub-models within the larger model to independently have low word error rates, making it easier to dynamically adjust the size of the model deployed for inference.
Neural Architecture Search for Speech Recognition
Jul 27, 2020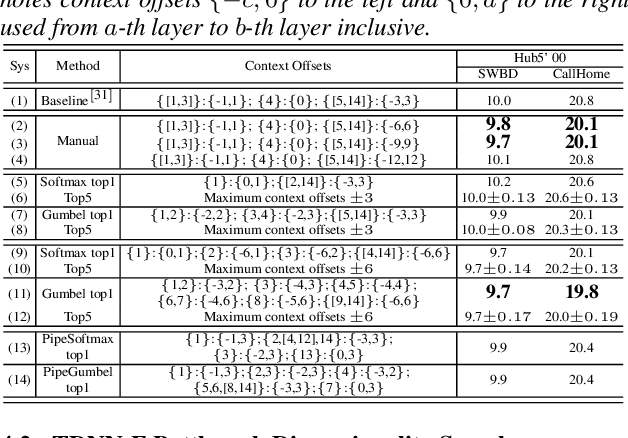
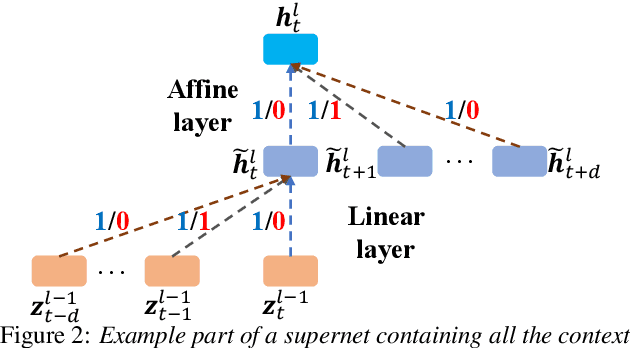
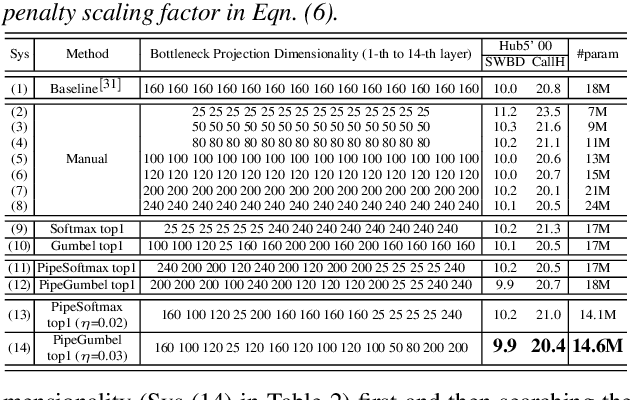
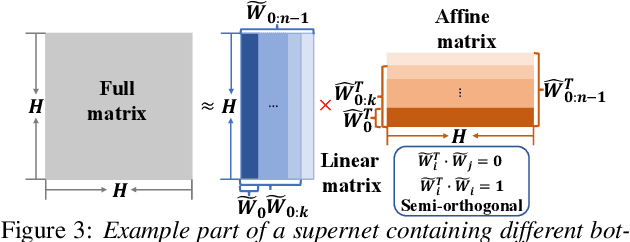
Deep neural networks (DNNs) based automatic speech recognition (ASR) systems are often designed using expert knowledge and empirical evaluation. In this paper, a range of neural architecture search (NAS) techniques are used to automatically learn two hyper-parameters that heavily affect the performance and model complexity of state-of-the-art factored time delay neural network (TDNN-F) acoustic models: i) the left and right splicing context offsets; and ii) the dimensionality of the bottleneck linear projection at each hidden layer. These include the standard DARTS method fully integrating the estimation of architecture weights and TDNN parameters in lattice-free MMI (LF-MMI) training; Gumbel-Softmax DARTS that reduces the confusion between candidate architectures; Pipelined DARTS that circumvents the overfitting of architecture weights using held-out data; and Penalized DARTS that further incorporates resource constraints to adjust the trade-off between performance and system complexity. Parameter sharing among candidate architectures was also used to facilitate efficient search over up to $7^{28}$ different TDNN systems. Experiments conducted on a 300-hour Switchboard conversational telephone speech recognition task suggest the NAS auto-configured TDNN-F systems consistently outperform the baseline LF-MMI trained TDNN-F systems using manual expert configurations. Absolute word error rate reductions up to 1.0% and relative model size reduction of 28% were obtained.
Better Transcription of UK Supreme Court Hearings
Dec 22, 2022
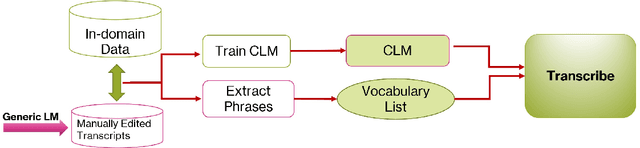
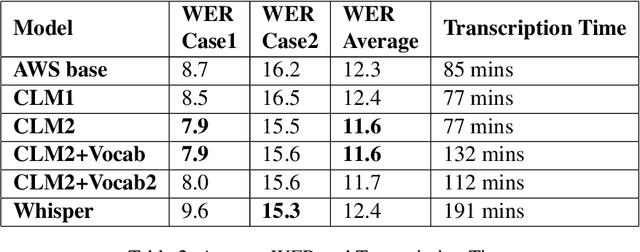
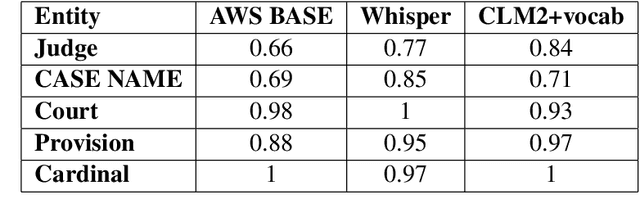
Transcription of legal proceedings is very important to enable access to justice. However, speech transcription is an expensive and slow process. In this paper we describe part of a combined research and industrial project for building an automated transcription tool designed specifically for the Justice sector in the UK. We explain the challenges involved in transcribing court room hearings and the Natural Language Processing (NLP) techniques we employ to tackle these challenges. We will show that fine-tuning a generic off-the-shelf pre-trained Automatic Speech Recognition (ASR) system with an in-domain language model as well as infusing common phrases extracted with a collocation detection model can improve not only the Word Error Rate (WER) of the transcribed hearings but avoid critical errors that are specific of the legal jargon and terminology commonly used in British courts.
Audio-visual multi-channel speech separation, dereverberation and recognition
Apr 08, 2022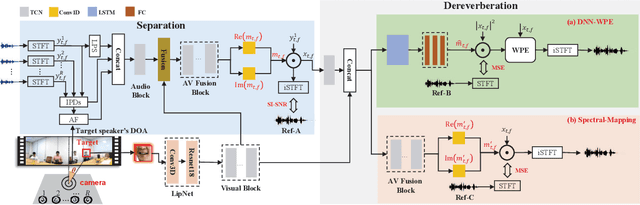

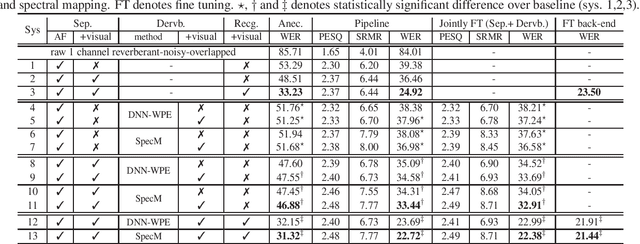
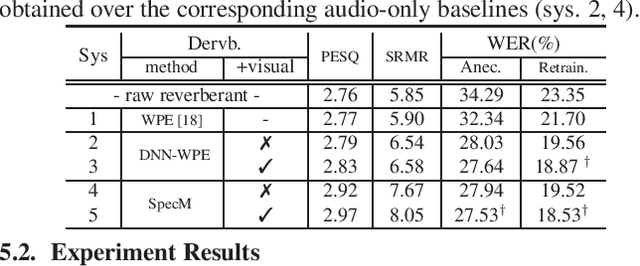
Despite the rapid advance of automatic speech recognition (ASR) technologies, accurate recognition of cocktail party speech characterised by the interference from overlapping speakers, background noise and room reverberation remains a highly challenging task to date. Motivated by the invariance of visual modality to acoustic signal corruption, audio-visual speech enhancement techniques have been developed, although predominantly targeting overlapping speech separation and recognition tasks. In this paper, an audio-visual multi-channel speech separation, dereverberation and recognition approach featuring a full incorporation of visual information into all three stages of the system is proposed. The advantage of the additional visual modality over using audio only is demonstrated on two neural dereverberation approaches based on DNN-WPE and spectral mapping respectively. The learning cost function mismatch between the separation and dereverberation models and their integration with the back-end recognition system is minimised using fine-tuning on the MSE and LF-MMI criteria. Experiments conducted on the LRS2 dataset suggest that the proposed audio-visual multi-channel speech separation, dereverberation and recognition system outperforms the baseline audio-visual multi-channel speech separation and recognition system containing no dereverberation module by a statistically significant word error rate (WER) reduction of 2.06% absolute (8.77% relative).