 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Regeneration Learning: A Learning Paradigm for Data Generation
Jan 21, 2023
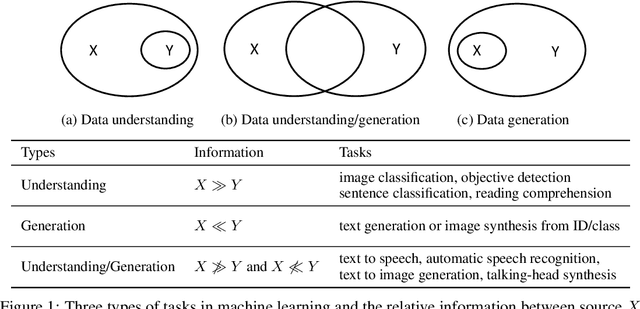
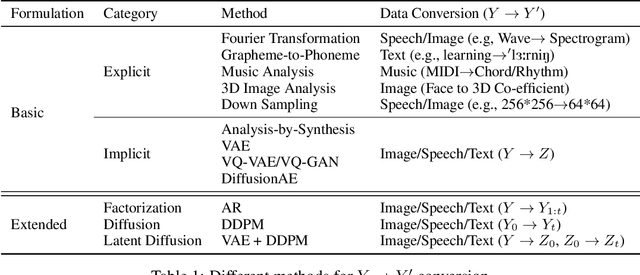


Machine learning methods for conditional data generation usually build a mapping from source conditional data X to target data Y. The target Y (e.g., text, speech, music, image, video) is usually high-dimensional and complex, and contains information that does not exist in source data, which hinders effective and efficient learning on the source-target mapping. In this paper, we present a learning paradigm called regeneration learning for data generation, which first generates Y' (an abstraction/representation of Y) from X and then generates Y from Y'. During training, Y' is obtained from Y through either handcrafted rules or self-supervised learning and is used to learn X-->Y' and Y'-->Y. Regeneration learning extends the concept of representation learning to data generation tasks, and can be regarded as a counterpart of traditional representation learning, since 1) regeneration learning handles the abstraction (Y') of the target data Y for data generation while traditional representation learning handles the abstraction (X') of source data X for data understanding; 2) both the processes of Y'-->Y in regeneration learning and X-->X' in representation learning can be learned in a self-supervised way (e.g., pre-training); 3) both the mappings from X to Y' in regeneration learning and from X' to Y in representation learning are simpler than the direct mapping from X to Y. We show that regeneration learning can be a widely-used paradigm for data generation (e.g., text generation, speech recognition, speech synthesis, music composition, image generation, and video generation) and can provide valuable insights into developing data generation methods.
Configurable Privacy-Preserving Automatic Speech Recognition
Apr 01, 2021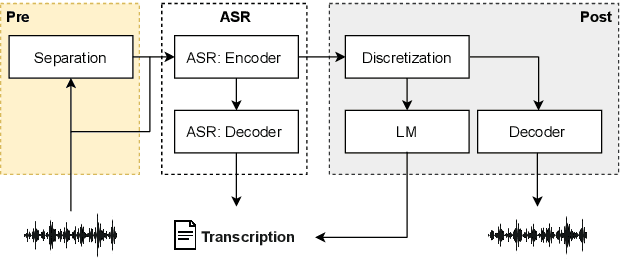

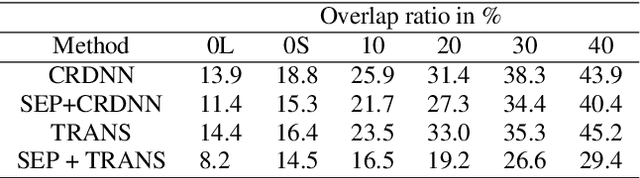
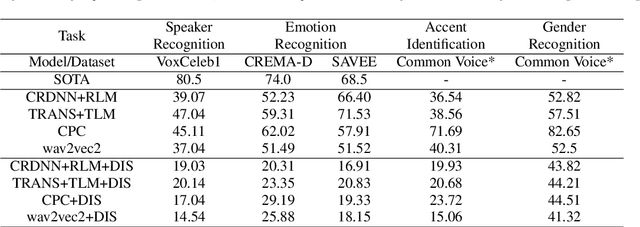
Voice assistive technologies have given rise to far-reaching privacy and security concerns. In this paper we investigate whether modular automatic speech recognition (ASR) can improve privacy in voice assistive systems by combining independently trained separation, recognition, and discretization modules to design configurable privacy-preserving ASR systems. We evaluate privacy concerns and the effects of applying various state-of-the-art techniques at each stage of the system, and report results using task-specific metrics (i.e. WER, ABX, and accuracy). We show that overlapping speech inputs to ASR systems present further privacy concerns, and how these may be mitigated using speech separation and optimization techniques. Our discretization module is shown to minimize paralinguistics privacy leakage from ASR acoustic models to levels commensurate with random guessing. We show that voice privacy can be configurable, and argue this presents new opportunities for privacy-preserving applications incorporating ASR.
Exploiting Single-Channel Speech for Multi-Channel End-to-End Speech Recognition: A Comparative Study
Mar 31, 2022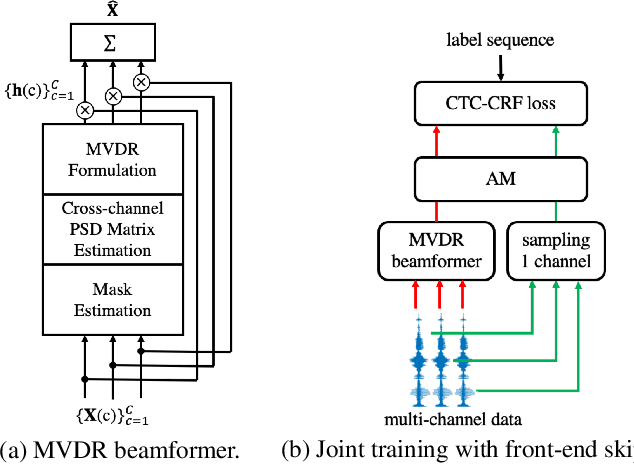

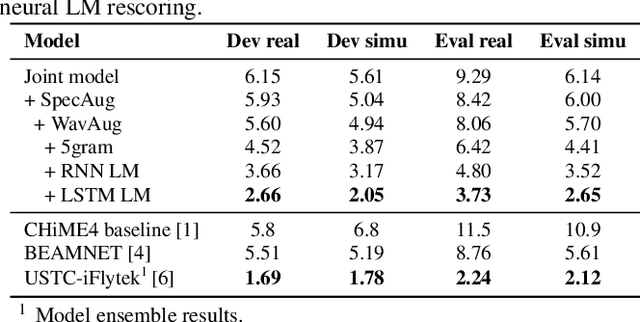
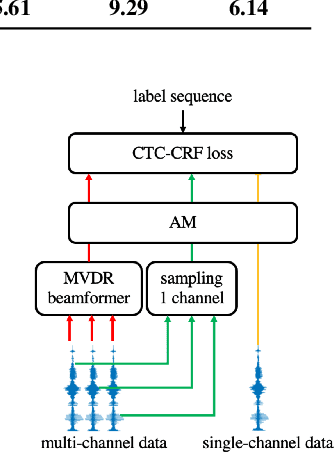
Recently, the end-to-end training approach for multi-channel ASR has shown its effectiveness, which usually consists of a beamforming front-end and a recognition back-end. However, the end-to-end training becomes more difficult due to the integration of multiple modules, particularly considering that multi-channel speech data recorded in real environments are limited in size. This raises the demand to exploit the single-channel data for multi-channel end-to-end ASR. In this paper, we systematically compare the performance of three schemes to exploit external single-channel data for multi-channel end-to-end ASR, namely back-end pre-training, data scheduling, and data simulation, under different settings such as the sizes of the single-channel data and the choices of the front-end. Extensive experiments on CHiME-4 and AISHELL-4 datasets demonstrate that while all three methods improve the multi-channel end-to-end speech recognition performance, data simulation outperforms the other two, at the cost of longer training time. Data scheduling outperforms back-end pre-training marginally but nearly consistently, presumably because that in the pre-training stage, the back-end tends to overfit on the single-channel data, especially when the single-channel data size is small.
Pronunciation Modeling of Foreign Words for Mandarin ASR by Considering the Effect of Language Transfer
Oct 07, 2022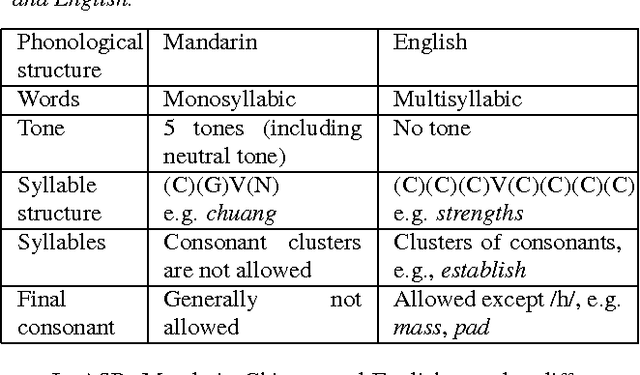
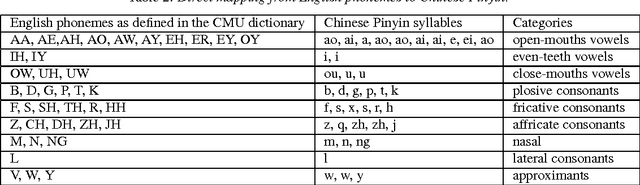

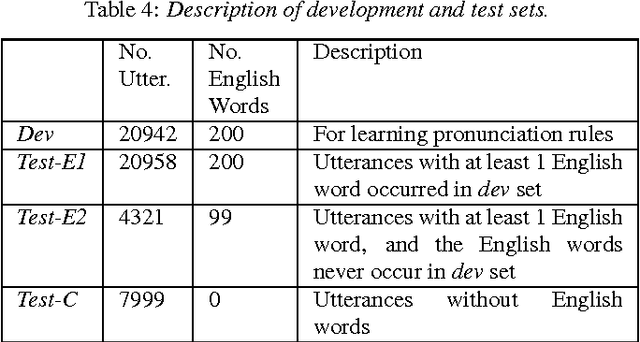
One of the challenges in automatic speech recognition is foreign words recognition. It is observed that a speaker's pronunciation of a foreign word is influenced by his native language knowledge, and such phenomenon is known as the effect of language transfer. This paper focuses on examining the phonetic effect of language transfer in automatic speech recognition. A set of lexical rules is proposed to convert an English word into Mandarin phonetic representation. In this way, a Mandarin lexicon can be augmented by including English words. Hence, the Mandarin ASR system becomes capable to recognize English words without retraining or re-estimation of the acoustic model parameters. Using the lexicon that derived from the proposed rules, the ASR performance of Mandarin English mixed speech is improved without harming the accuracy of Mandarin only speech. The proposed lexical rules are generalized and they can be directly applied to unseen English words.
Quantifying Bias in Automatic Speech Recognition
Apr 01, 2021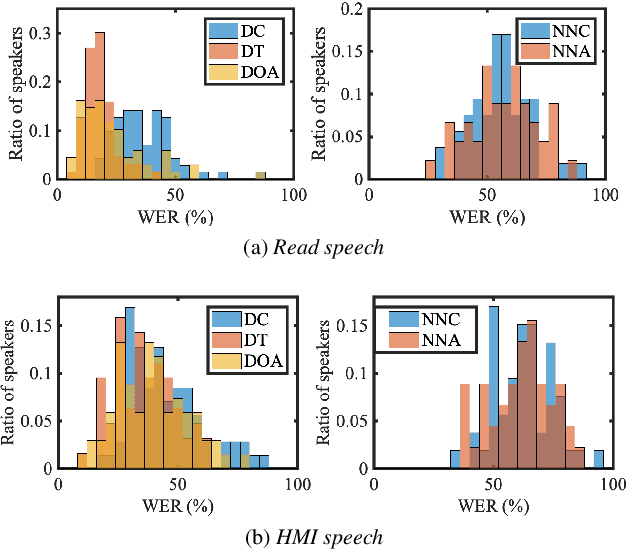
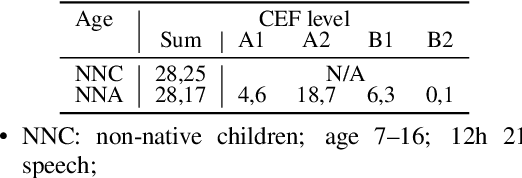
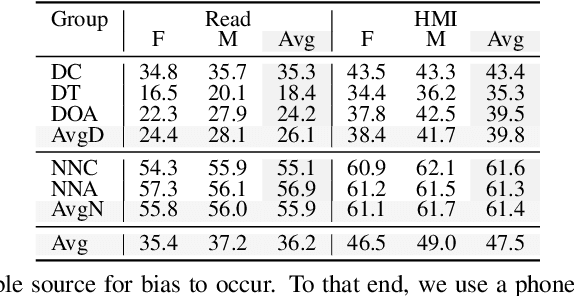
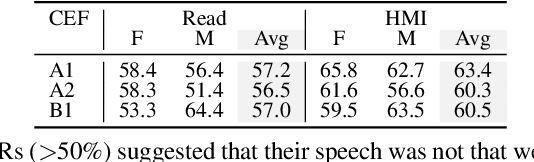
Automatic speech recognition (ASR) systems promise to deliver objective interpretation of human speech. Practice and recent evidence suggests that the state-of-the-art (SotA) ASRs struggle with the large variation in speech due to e.g., gender, age, speech impairment, race, and accents. Many factors can cause the bias of an ASR system. Our overarching goal is to uncover bias in ASR systems to work towards proactive bias mitigation in ASR. This paper is a first step towards this goal and systematically quantifies the bias of a Dutch SotA ASR system against gender, age, regional accents and non-native accents. Word error rates are compared, and an in-depth phoneme-level error analysis is conducted to understand where bias is occurring. We primarily focus on bias due to articulation differences in the dataset. Based on our findings, we suggest bias mitigation strategies for ASR development.
Conformer: Convolution-augmented Transformer for Speech Recognition
May 16, 2020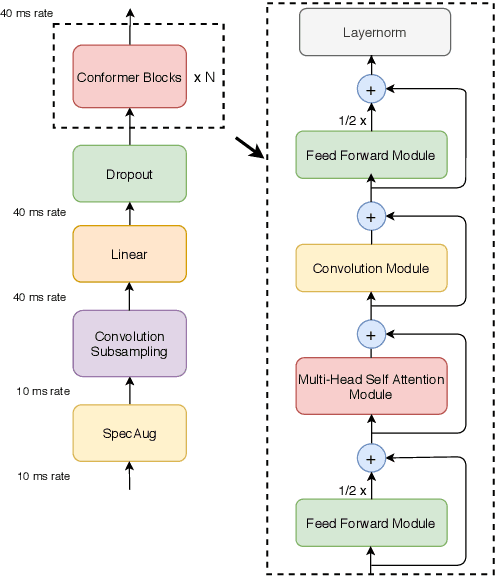
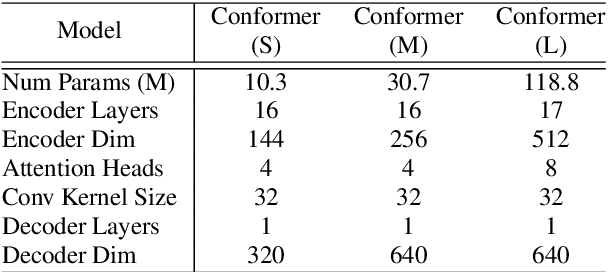

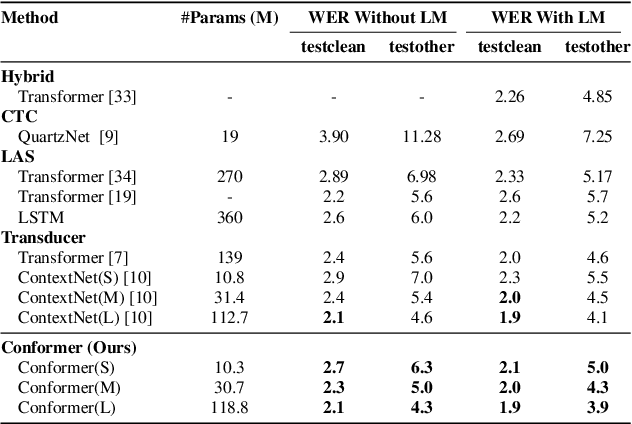
Recently Transformer and Convolution neural network (CNN) based models have shown promising results in Automatic Speech Recognition (ASR), outperforming Recurrent neural networks (RNNs). Transformer models are good at capturing content-based global interactions, while CNNs exploit local features effectively. In this work, we achieve the best of both worlds by studying how to combine convolution neural networks and transformers to model both local and global dependencies of an audio sequence in a parameter-efficient way. To this regard, we propose the convolution-augmented transformer for speech recognition, named Conformer. Conformer significantly outperforms the previous Transformer and CNN based models achieving state-of-the-art accuracies. On the widely used LibriSpeech benchmark, our model achieves WER of 2.1%/4.3% without using a language model and 1.9%/3.9% with an external language model on test/testother. We also observe competitive performance of 2.7%/6.3% with a small model of only 10M parameters.
Array Configuration-Agnostic Personal Voice Activity Detection Based on Spatial Coherence
Apr 18, 2023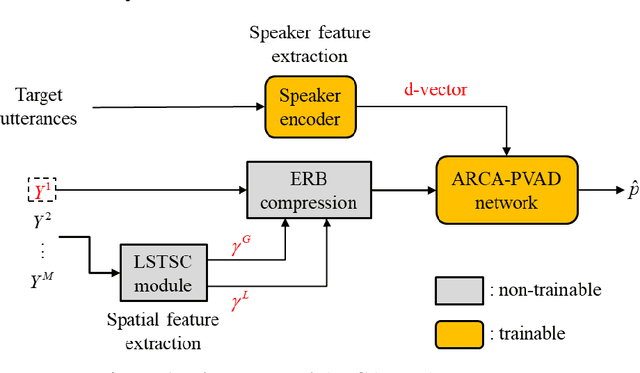
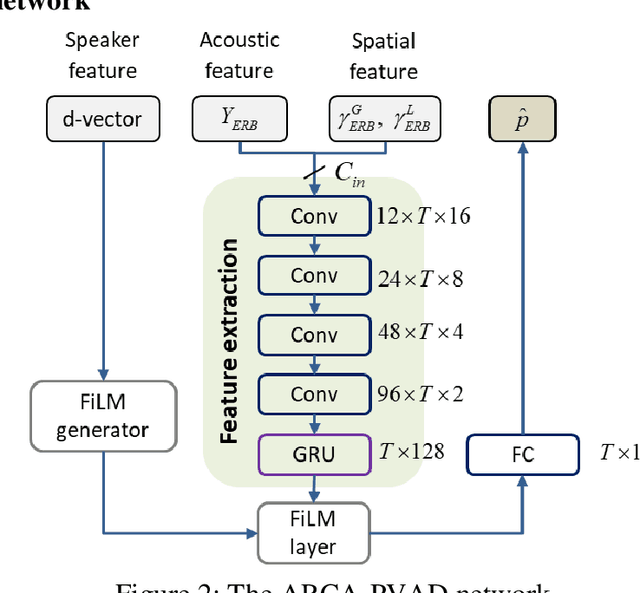

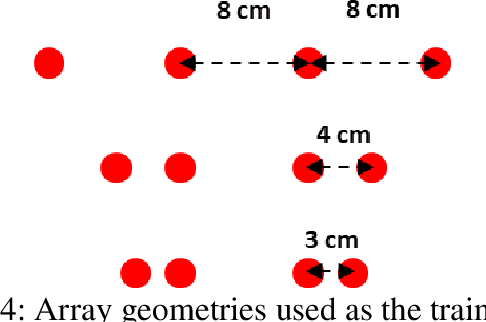
Personal voice activity detection has received increased attention due to the growing popularity of personal mobile devices and smart speakers. PVAD is often an integral element to speech enhancement and recognition for these applications in which lightweight signal processing is only enabled for the target user. However, in real-world scenarios, the detection performance may degrade because of competing speakers, background noise, and reverberation. To address this problem, we proposed to use equivalent rectangular bandwidth ERB-scaled spatial coherence as the input feature to train an array configuration-agnostic PVAD network. Whereas the network model requires only 112k parameters, it exhibits excellent detection performance and robustness in adverse acoustic conditions. Notably, the proposed ARCA-PVAD system is scalable to array configurations. Experimental results have demonstrated the superior performance achieved by the proposed ARCA-PVAD system over a baseline in terms of the area under receiver operating characteristic curve and equal error rate.
Data Augmentation based Consistency Contrastive Pre-training for Automatic Speech Recognition
Dec 23, 2021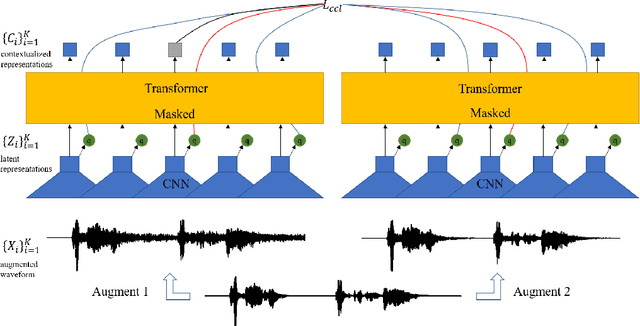
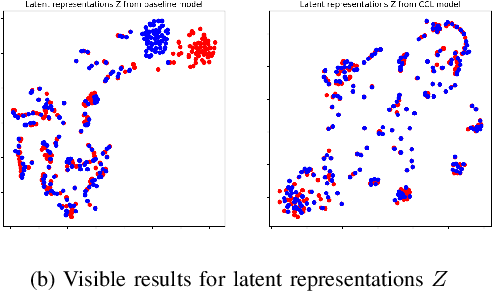
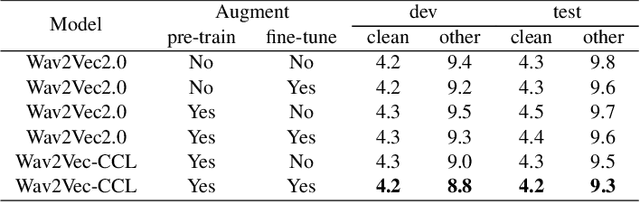
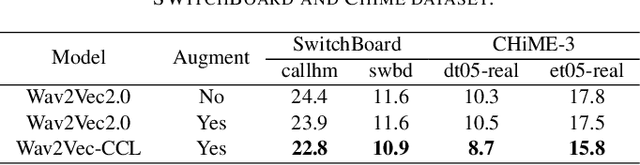
Self-supervised acoustic pre-training has achieved amazing results on the automatic speech recognition (ASR) task. Most of the successful acoustic pre-training methods use contrastive learning to learn the acoustic representations by distinguish the representations from different time steps, ignoring the speaker and environment robustness. As a result, the pre-trained model could show poor performance when meeting out-of-domain data during fine-tuning. In this letter, we design a novel consistency contrastive learning (CCL) method by utilizing data augmentation for acoustic pre-training. Different kinds of augmentation are applied on the original audios and then the augmented audios are fed into an encoder. The encoder should not only contrast the representations within one audio but also maximize the measurement of the representations across different augmented audios. By this way, the pre-trained model can learn a text-related representation method which is more robust with the change of the speaker or the environment.Experiments show that by applying the CCL method on the Wav2Vec2.0, better results can be realized both on the in-domain data and the out-of-domain data. Especially for noisy out-of-domain data, more than 15% relative improvement can be obtained.
Attention based end to end Speech Recognition for Voice Search in Hindi and English
Nov 15, 2021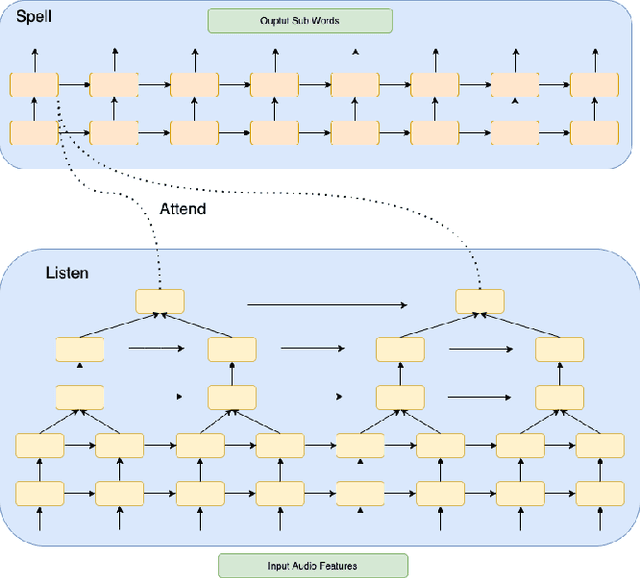
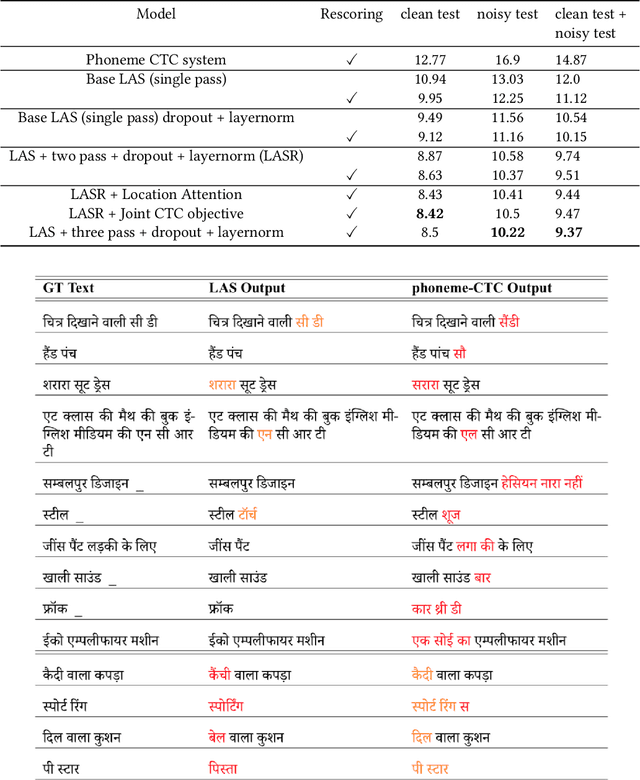
We describe here our work with automatic speech recognition (ASR) in the context of voice search functionality on the Flipkart e-Commerce platform. Starting with the deep learning architecture of Listen-Attend-Spell (LAS), we build upon and expand the model design and attention mechanisms to incorporate innovative approaches including multi-objective training, multi-pass training, and external rescoring using language models and phoneme based losses. We report a relative WER improvement of 15.7% on top of state-of-the-art LAS models using these modifications. Overall, we report an improvement of 36.9% over the phoneme-CTC system. The paper also provides an overview of different components that can be tuned in a LAS-based system.
Blackbox Untargeted Adversarial Testing of Automatic Speech Recognition Systems
Dec 03, 2021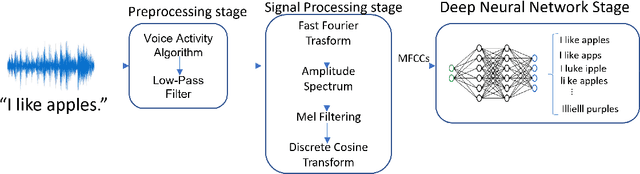
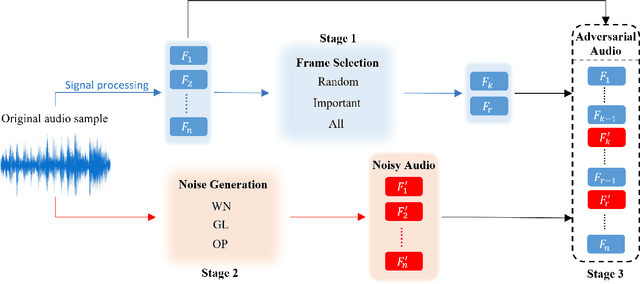
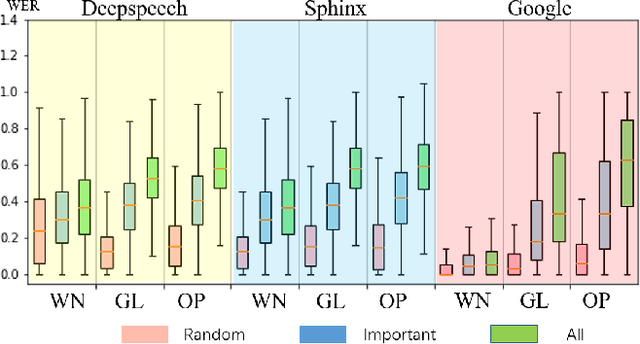
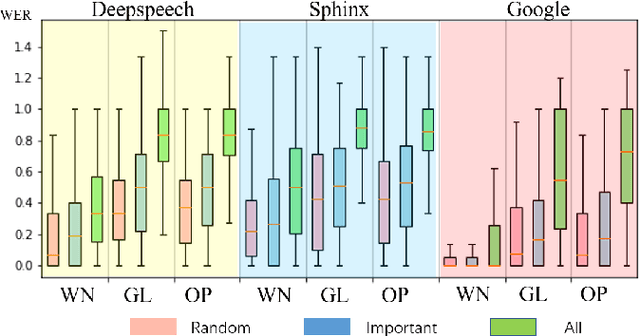
Automatic speech recognition (ASR) systems are prevalent, particularly in applications for voice navigation and voice control of domestic appliances. The computational core of ASRs are deep neural networks (DNNs) that have been shown to be susceptible to adversarial perturbations; easily misused by attackers to generate malicious outputs. To help test the correctness of ASRS, we propose techniques that automatically generate blackbox (agnostic to the DNN), untargeted adversarial attacks that are portable across ASRs. Much of the existing work on adversarial ASR testing focuses on targeted attacks, i.e generating audio samples given an output text. Targeted techniques are not portable, customised to the structure of DNNs (whitebox) within a specific ASR. In contrast, our method attacks the signal processing stage of the ASR pipeline that is shared across most ASRs. Additionally, we ensure the generated adversarial audio samples have no human audible difference by manipulating the acoustic signal using a psychoacoustic model that maintains the signal below the thresholds of human perception. We evaluate portability and effectiveness of our techniques using three popular ASRs and three input audio datasets using the metrics - WER of output text, Similarity to original audio and attack Success Rate on different ASRs. We found our testing techniques were portable across ASRs, with the adversarial audio samples producing high Success Rates, WERs and Similarities to the original audio.