 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
READIN: A Chinese Multi-Task Benchmark with Realistic and Diverse Input Noises
Feb 14, 2023


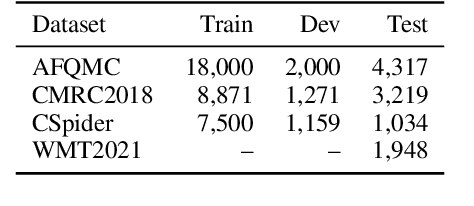
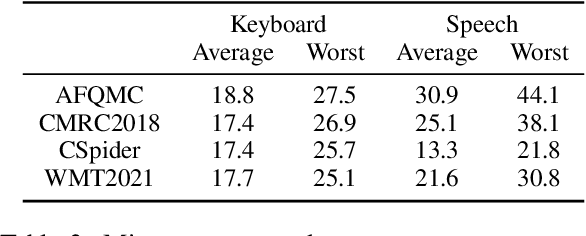
For many real-world applications, the user-generated inputs usually contain various noises due to speech recognition errors caused by linguistic variations1 or typographical errors (typos). Thus, it is crucial to test model performance on data with realistic input noises to ensure robustness and fairness. However, little study has been done to construct such benchmarks for Chinese, where various language-specific input noises happen in the real world. In order to fill this important gap, we construct READIN: a Chinese multi-task benchmark with REalistic And Diverse Input Noises. READIN contains four diverse tasks and requests annotators to re-enter the original test data with two commonly used Chinese input methods: Pinyin input and speech input. We designed our annotation pipeline to maximize diversity, for example by instructing the annotators to use diverse input method editors (IMEs) for keyboard noises and recruiting speakers from diverse dialectical groups for speech noises. We experiment with a series of strong pretrained language models as well as robust training methods, we find that these models often suffer significant performance drops on READIN even with robustness methods like data augmentation. As the first large-scale attempt in creating a benchmark with noises geared towards user-generated inputs, we believe that READIN serves as an important complement to existing Chinese NLP benchmarks. The source code and dataset can be obtained from https://github.com/thunlp/READIN.
Speaker Normalization for Self-supervised Speech Emotion Recognition
Feb 02, 2022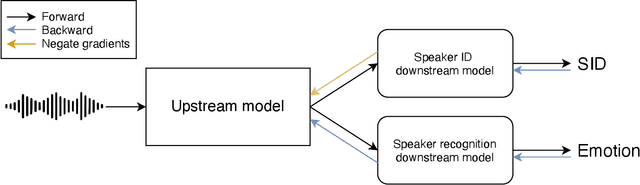
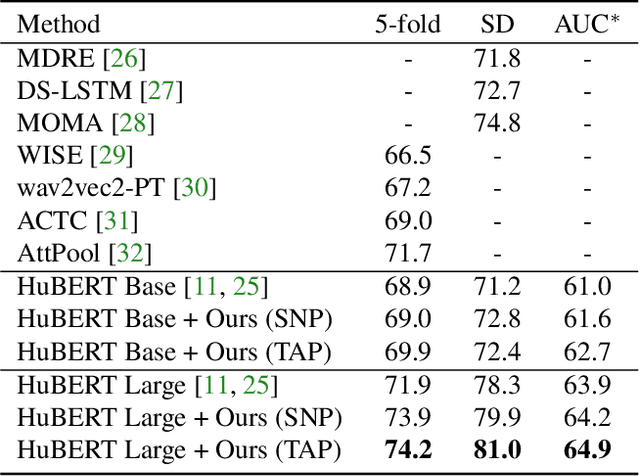
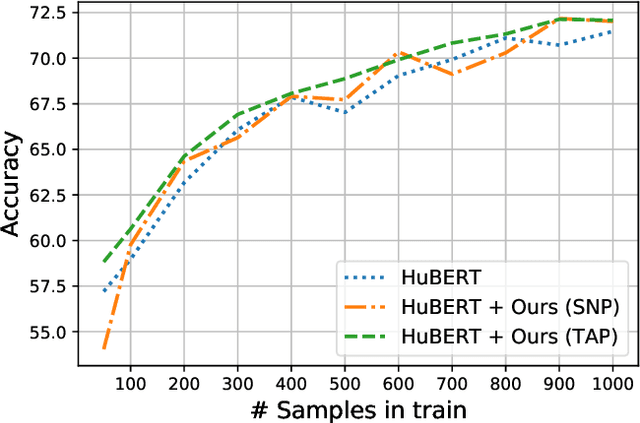
Large speech emotion recognition datasets are hard to obtain, and small datasets may contain biases. Deep-net-based classifiers, in turn, are prone to exploit those biases and find shortcuts such as speaker characteristics. These shortcuts usually harm a model's ability to generalize. To address this challenge, we propose a gradient-based adversary learning framework that learns a speech emotion recognition task while normalizing speaker characteristics from the feature representation. We demonstrate the efficacy of our method on both speaker-independent and speaker-dependent settings and obtain new state-of-the-art results on the challenging IEMOCAP dataset.
Who Needs Words? Lexicon-Free Speech Recognition
Apr 09, 2019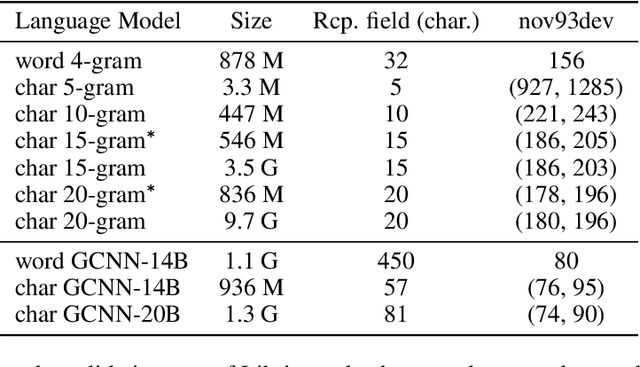
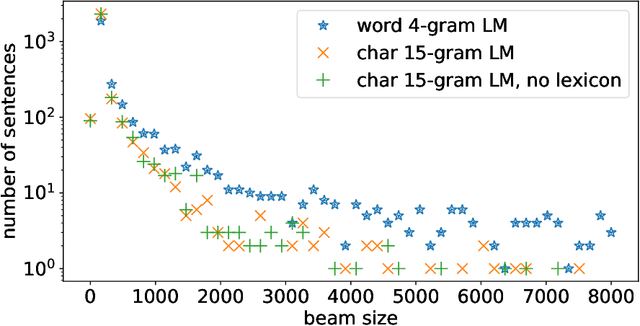
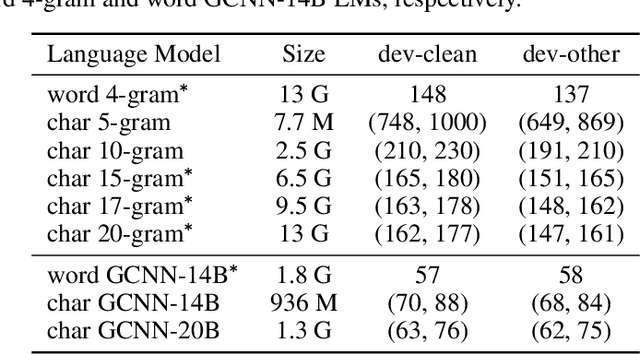
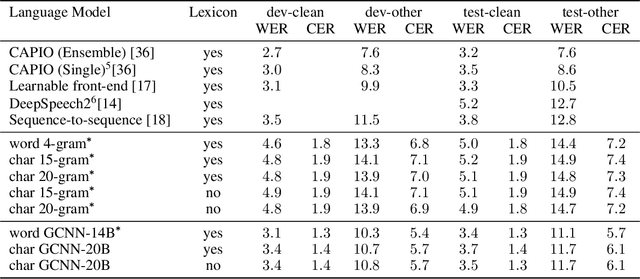
Lexicon-free speech recognition naturally deals with the problem of out-of-vocabulary (OOV) words. In this paper, we show that character-based language models (LM) can perform as well as word-based LMs for speech recognition, in word error rates (WER), even without restricting the decoding to a lexicon. We study character-based LMs and show that convolutional LMs can effectively leverage large (character) contexts, which is key for good speech recognition performance downstream. We specifically show that the lexicon-free decoding performance (WER) on utterances with OOV words using character-based LMs is better than lexicon-based decoding, both with character or word-based LMs.
A two-step approach to leverage contextual data: speech recognition in air-traffic communications
Feb 08, 2022

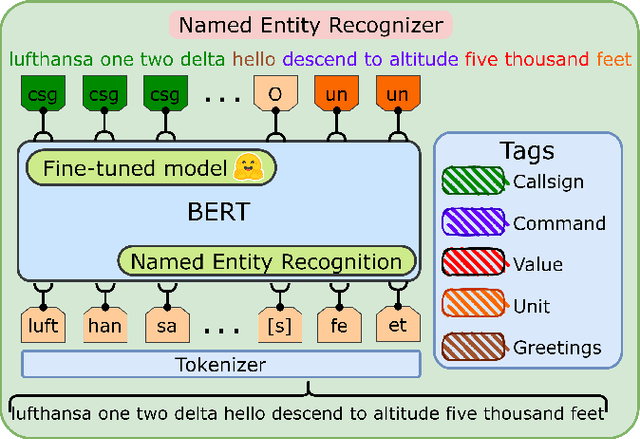
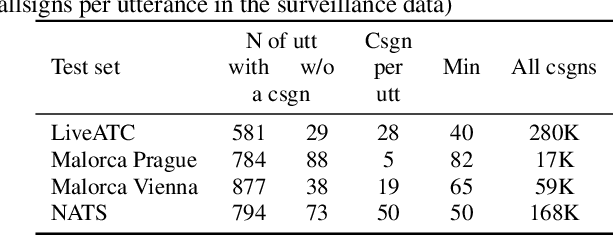
Automatic Speech Recognition (ASR), as the assistance of speech communication between pilots and air-traffic controllers, can significantly reduce the complexity of the task and increase the reliability of transmitted information. ASR application can lead to a lower number of incidents caused by misunderstanding and improve air traffic management (ATM) efficiency. Evidently, high accuracy predictions, especially, of key information, i.e., callsigns and commands, are required to minimize the risk of errors. We prove that combining the benefits of ASR and Natural Language Processing (NLP) methods to make use of surveillance data (i.e. additional modality) helps to considerably improve the recognition of callsigns (named entity). In this paper, we investigate a two-step callsign boosting approach: (1) at the 1 step (ASR), weights of probable callsign n-grams are reduced in G.fst and/or in the decoding FST (lattices), (2) at the 2 step (NLP), callsigns extracted from the improved recognition outputs with Named Entity Recognition (NER) are correlated with the surveillance data to select the most suitable one. Boosting callsign n-grams with the combination of ASR and NLP methods eventually leads up to 53.7% of an absolute, or 60.4% of a relative, improvement in callsign recognition.
* 20XX IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works. arXiv admin note: text overlap with arXiv:2108.12156
Amortized Neural Networks for Low-Latency Speech Recognition
Aug 03, 2021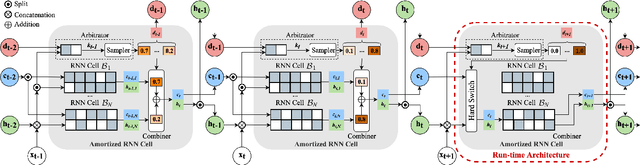
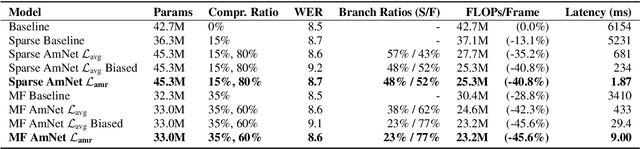
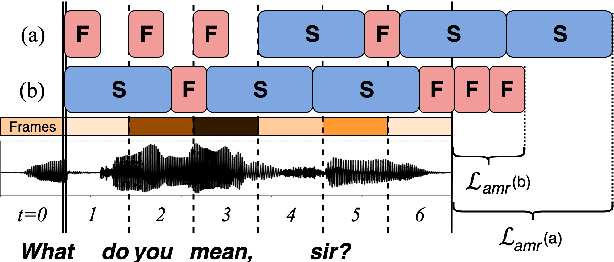
We introduce Amortized Neural Networks (AmNets), a compute cost- and latency-aware network architecture particularly well-suited for sequence modeling tasks. We apply AmNets to the Recurrent Neural Network Transducer (RNN-T) to reduce compute cost and latency for an automatic speech recognition (ASR) task. The AmNets RNN-T architecture enables the network to dynamically switch between encoder branches on a frame-by-frame basis. Branches are constructed with variable levels of compute cost and model capacity. Here, we achieve variable compute for two well-known candidate techniques: one using sparse pruning and the other using matrix factorization. Frame-by-frame switching is determined by an arbitrator network that requires negligible compute overhead. We present results using both architectures on LibriSpeech data and show that our proposed architecture can reduce inference cost by up to 45\% and latency to nearly real-time without incurring a loss in accuracy.
Simple and Effective Unsupervised Speech Translation
Oct 18, 2022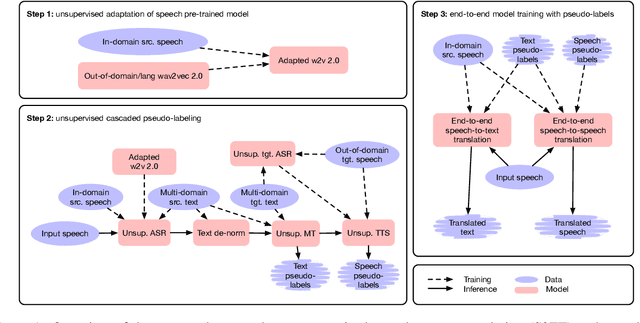
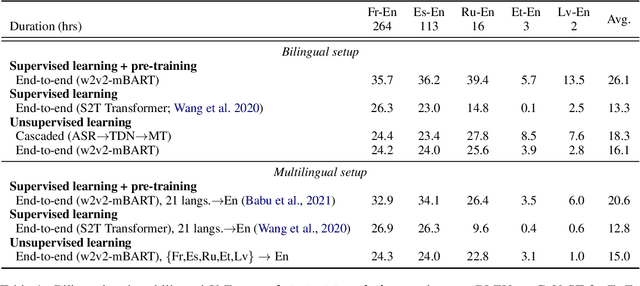
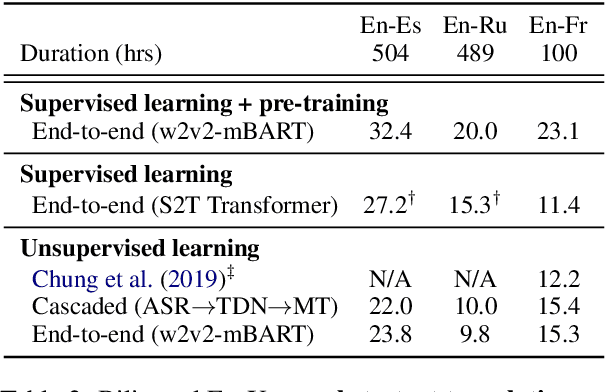
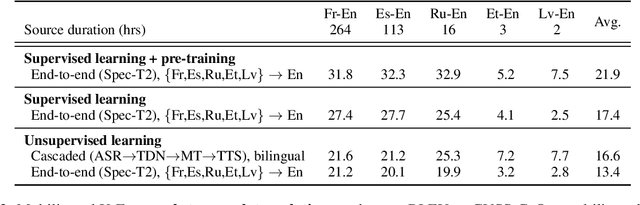
The amount of labeled data to train models for speech tasks is limited for most languages, however, the data scarcity is exacerbated for speech translation which requires labeled data covering two different languages. To address this issue, we study a simple and effective approach to build speech translation systems without labeled data by leveraging recent advances in unsupervised speech recognition, machine translation and speech synthesis, either in a pipeline approach, or to generate pseudo-labels for training end-to-end speech translation models. Furthermore, we present an unsupervised domain adaptation technique for pre-trained speech models which improves the performance of downstream unsupervised speech recognition, especially for low-resource settings. Experiments show that unsupervised speech-to-text translation outperforms the previous unsupervised state of the art by 3.2 BLEU on the Libri-Trans benchmark, on CoVoST 2, our best systems outperform the best supervised end-to-end models (without pre-training) from only two years ago by an average of 5.0 BLEU over five X-En directions. We also report competitive results on MuST-C and CVSS benchmarks.
Sneaky Spikes: Uncovering Stealthy Backdoor Attacks in Spiking Neural Networks with Neuromorphic Data
Feb 13, 2023


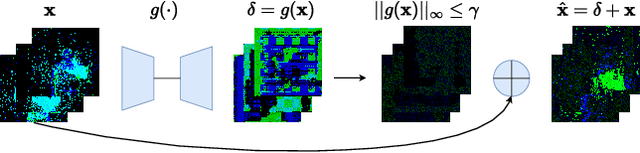
Deep neural networks (DNNs) have achieved excellent results in various tasks, including image and speech recognition. However, optimizing the performance of DNNs requires careful tuning of multiple hyperparameters and network parameters via training. High-performance DNNs utilize a large number of parameters, corresponding to high energy consumption during training. To address these limitations, researchers have developed spiking neural networks (SNNs), which are more energy-efficient and can process data in a biologically plausible manner, making them well-suited for tasks involving sensory data processing, i.e., neuromorphic data. Like DNNs, SNNs are vulnerable to various threats, such as adversarial examples and backdoor attacks. Yet, the attacks and countermeasures for SNNs have been almost fully unexplored. This paper investigates the application of backdoor attacks in SNNs using neuromorphic datasets and different triggers. More precisely, backdoor triggers in neuromorphic data can change their position and color, allowing a larger range of possibilities than common triggers in, e.g., the image domain. We propose different attacks achieving up to 100\% attack success rate without noticeable clean accuracy degradation. We also evaluate the stealthiness of the attacks via the structural similarity metric, showing our most powerful attacks being also stealthy. Finally, we adapt the state-of-the-art defenses from the image domain, demonstrating they are not necessarily effective for neuromorphic data resulting in inaccurate performance.
Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition
Sep 14, 2021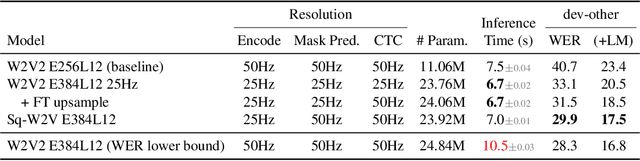
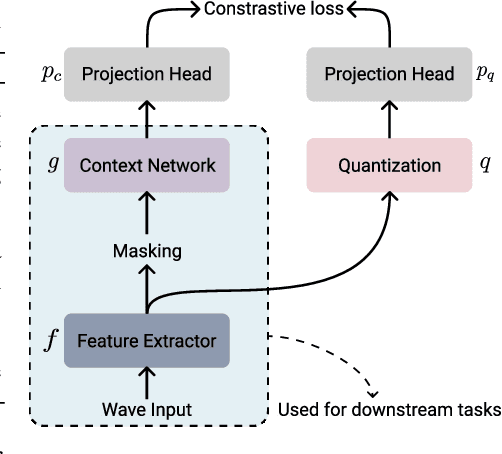
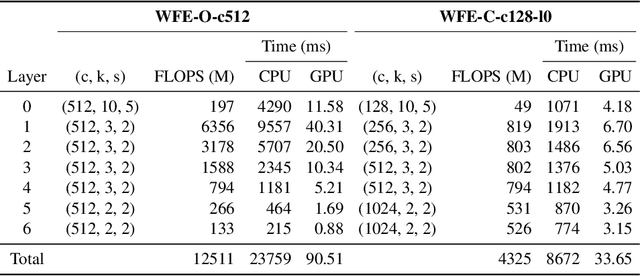
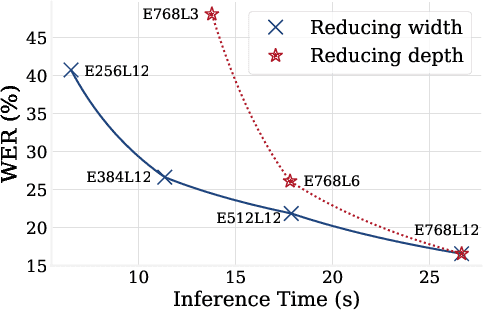
This paper is a study of performance-efficiency trade-offs in pre-trained models for automatic speech recognition (ASR). We focus on wav2vec 2.0, and formalize several architecture designs that influence both the model performance and its efficiency. Putting together all our observations, we introduce SEW (Squeezed and Efficient Wav2vec), a pre-trained model architecture with significant improvements along both performance and efficiency dimensions across a variety of training setups. For example, under the 100h-960h semi-supervised setup on LibriSpeech, SEW achieves a 1.9x inference speedup compared to wav2vec 2.0, with a 13.5% relative reduction in word error rate. With a similar inference time, SEW reduces word error rate by 25-50% across different model sizes.
Mask the Correct Tokens: An Embarrassingly Simple Approach for Error Correction
Nov 23, 2022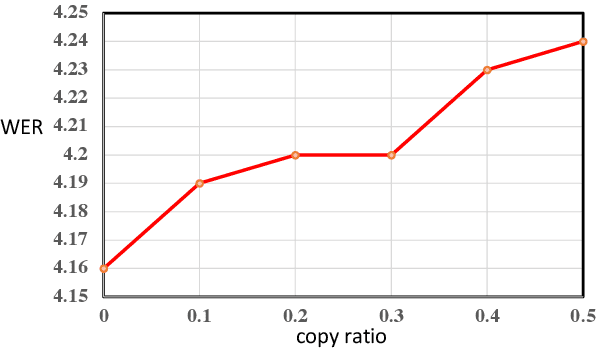
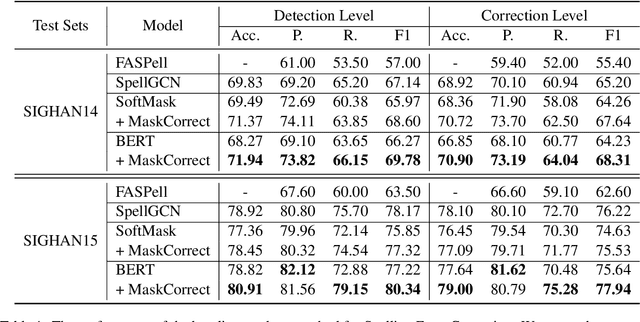
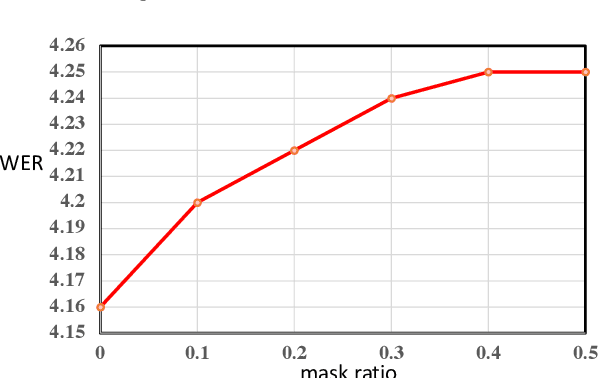
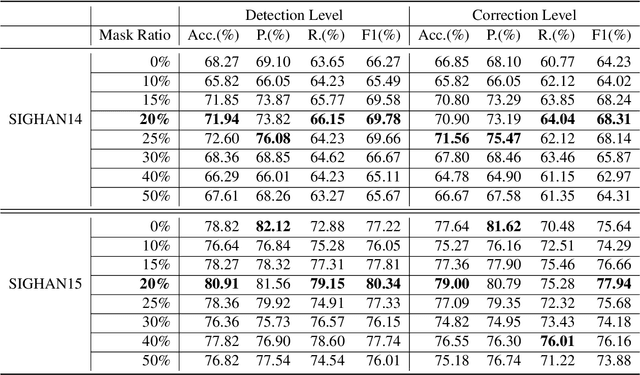
Text error correction aims to correct the errors in text sequences such as those typed by humans or generated by speech recognition models. Previous error correction methods usually take the source (incorrect) sentence as encoder input and generate the target (correct) sentence through the decoder. Since the error rate of the incorrect sentence is usually low (e.g., 10\%), the correction model can only learn to correct on limited error tokens but trivially copy on most tokens (correct tokens), which harms the effective training of error correction. In this paper, we argue that the correct tokens should be better utilized to facilitate effective training and then propose a simple yet effective masking strategy to achieve this goal. Specifically, we randomly mask out a part of the correct tokens in the source sentence and let the model learn to not only correct the original error tokens but also predict the masked tokens based on their context information. Our method enjoys several advantages: 1) it alleviates trivial copy; 2) it leverages effective training signals from correct tokens; 3) it is a plug-and-play module and can be applied to different models and tasks. Experiments on spelling error correction and speech recognition error correction on Mandarin datasets and grammar error correction on English datasets with both autoregressive and non-autoregressive generation models show that our method improves the correction accuracy consistently.
Applying Wav2vec2.0 to Speech Recognition in Various Low-resource Languages
Jan 17, 2021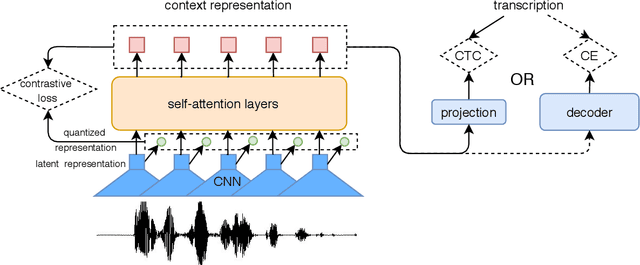
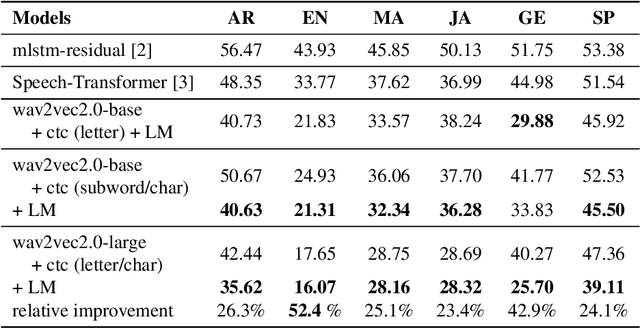
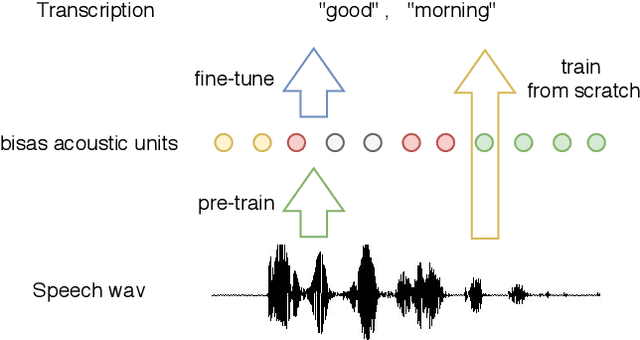
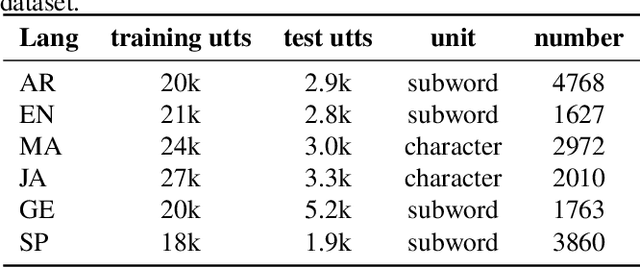
There are several domains that own corresponding widely used feature extractors, such as ResNet, BERT, and GPT-x. These models are usually pre-trained on large amounts of unlabeled data by self-supervision and can be effectively applied to downstream tasks. In the speech domain, wav2vec2.0 starts to show its powerful representation ability and feasibility of ultra-low resource speech recognition on the Librispeech corpus, which belongs to the audiobook domain. However, wav2vec2.0 has not been examined on real spoken scenarios and languages other than English. To verify its universality over languages, we apply pre-trained models to solve low-resource speech recognition tasks in various spoken languages. We achieve more than 20% relative improvements in six languages compared with previous work. Among these languages, English achieves a gain of 52.4%. Moreover, using coarse-grained modeling units, such as subword or character, achieves better results than fine-grained modeling units, such as phone or letter.