 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
On monoaural speech enhancement for automatic recognition of real noisy speech using mixture invariant training
May 03, 2022
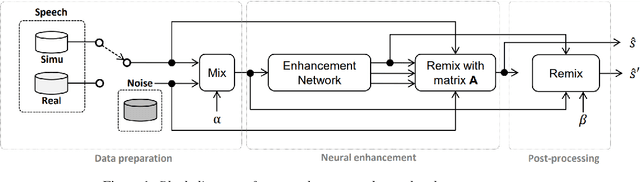
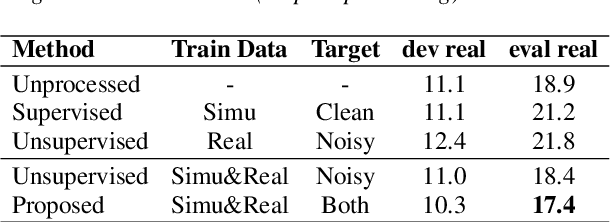
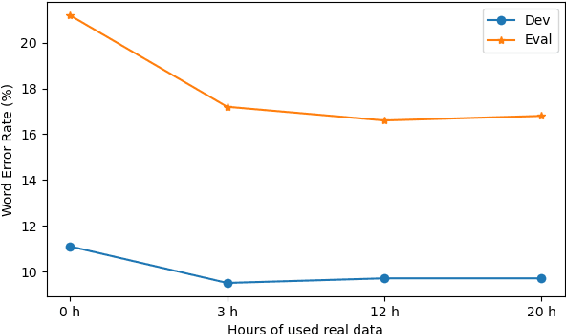
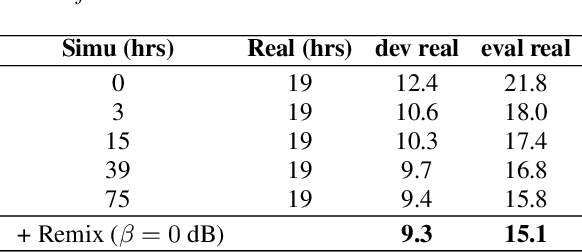
In this paper, we explore an improved framework to train a monoaural neural enhancement model for robust speech recognition. The designed training framework extends the existing mixture invariant training criterion to exploit both unpaired clean speech and real noisy data. It is found that the unpaired clean speech is crucial to improve quality of separated speech from real noisy speech. The proposed method also performs remixing of processed and unprocessed signals to alleviate the processing artifacts. Experiments on the single-channel CHiME-3 real test sets show that the proposed method improves significantly in terms of speech recognition performance over the enhancement system trained either on the mismatched simulated data in a supervised fashion or on the matched real data in an unsupervised fashion. Between 16% and 39% relative WER reduction has been achieved by the proposed system compared to the unprocessed signal using end-to-end and hybrid acoustic models without retraining on distorted data.
Streaming end-to-end multi-talker speech recognition
Nov 26, 2020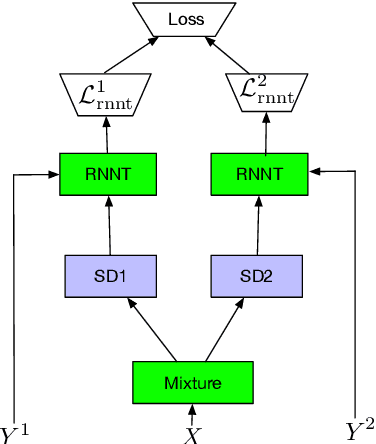

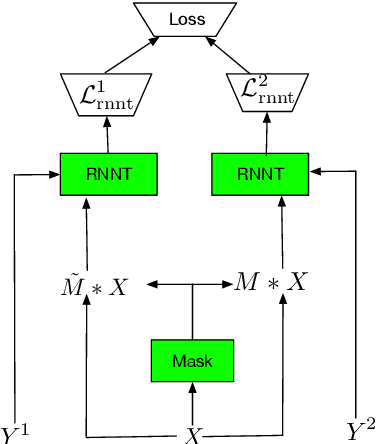

End-to-end multi-talker speech recognition is an emerging research trend in the speech community due to its vast potential in applications such as conversation and meeting transcriptions. To the best of our knowledge, all existing research works are constrained in the offline scenario. In this work, we propose the Streaming Unmixing and Recognition Transducer (SURT) for end-to-end multi-talker speech recognition. Our model employs the Recurrent Neural Network Transducer as the backbone that can meet various latency constraints. We study two different model architectures that are based on a speaker-differentiator encoder and a mask encoder respectively. To train this model, we investigate the widely used Permutation Invariant Training (PIT) approach and the recently introduced Heuristic Error Assignment Training (HEAT) approach. Based on experiments on the publicly available LibriSpeechMix dataset, we show that HEAT can achieve better accuracy compared with PIT, and the SURT model with 120 milliseconds algorithmic latency constraint compares favorably with the offline sequence-to-sequence based baseline model in terms of accuracy.
Automatic Speech Recognition in Sanskrit: A New Speech Corpus and Modelling Insights
Jun 02, 2021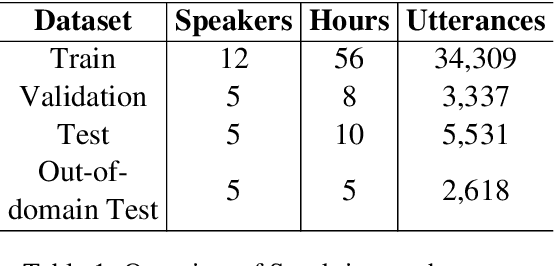
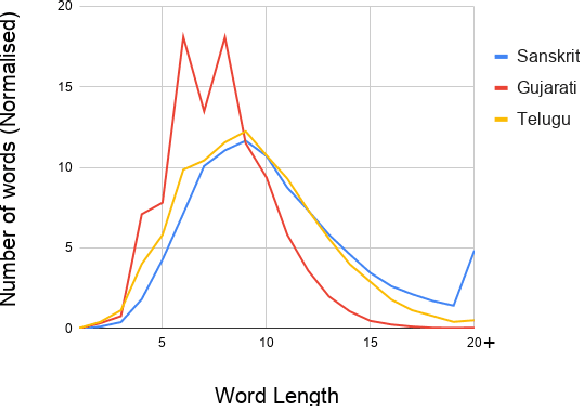
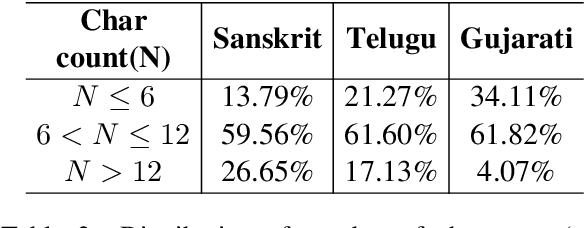

Automatic speech recognition (ASR) in Sanskrit is interesting, owing to the various linguistic peculiarities present in the language. The Sanskrit language is lexically productive, undergoes euphonic assimilation of phones at the word boundaries and exhibits variations in spelling conventions and in pronunciations. In this work, we propose the first large scale study of automatic speech recognition (ASR) in Sanskrit, with an emphasis on the impact of unit selection in Sanskrit ASR. In this work, we release a 78 hour ASR dataset for Sanskrit, which faithfully captures several of the linguistic characteristics expressed by the language. We investigate the role of different acoustic model and language model units in ASR systems for Sanskrit. We also propose a new modelling unit, inspired by the syllable level unit selection, that captures character sequences from one vowel in the word to the next vowel. We also highlight the importance of choosing graphemic representations for Sanskrit and show the impact of this choice on word error rates (WER). Finally, we extend these insights from Sanskrit ASR for building ASR systems in two other Indic languages, Gujarati and Telugu. For both these languages, our experimental results show that the use of phonetic based graphemic representations in ASR results in performance improvements as compared to ASR systems that use native scripts.
Supplementary Features of BiLSTM for Enhanced Sequence Labeling
Jun 08, 2023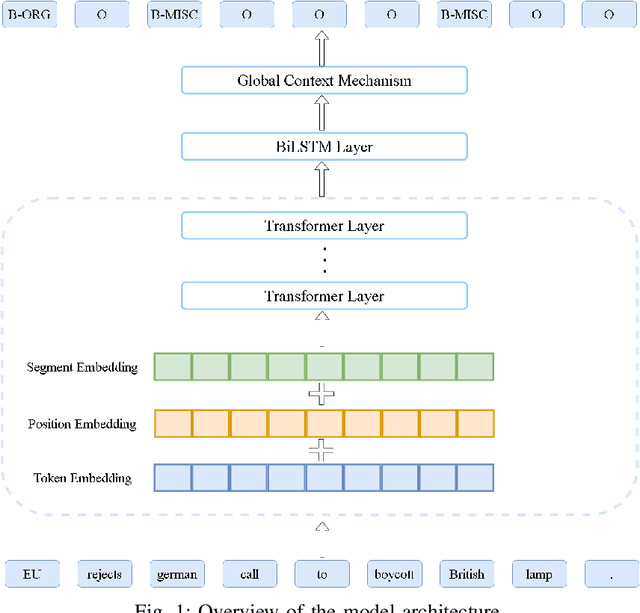
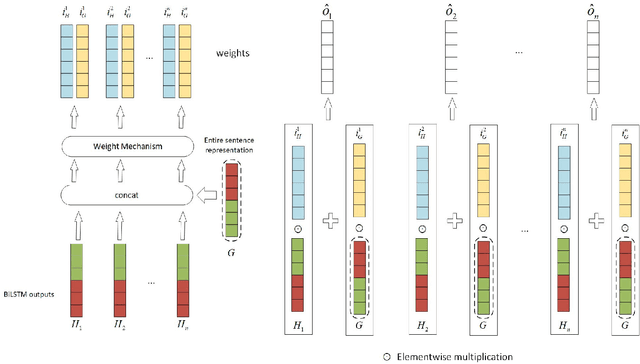
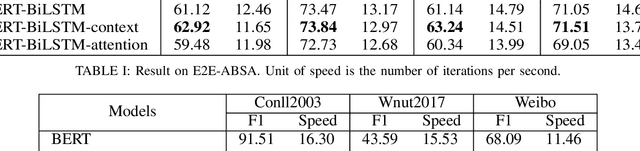
Sequence labeling tasks require the computation of sentence representations for each word within a given sentence. With the rise of advanced pretrained language models; one common approach involves incorporating a BiLSTM layer to enhance the sequence structure information at the output level. Nevertheless, it has been empirically demonstrated (P.-H. Li, 2020) that BiLSTM's potential for generating sentence representations for sequence labeling tasks is constrained, primarily due to the integration of fragments from past and future sentence representations to form a complete sentence representation. In this study, we observed that the entire sentence representation, found in both the first and last cells of BiLSTM, can supplement each cell's sentence representation. Accordingly, we devised a global context mechanism to integrate entire future and past sentence representations into each cell's sentence representation within BiLSTM, leading to a significant improvement in both F1 score and accuracy. By embedding the BERT model within BiLSTM as a demonstration, and conducting exhaustive experiments on nine datasets for sequence labeling tasks, including named entity recognition (NER), part of speech (POS) tagging and End-to-End Aspect-Based sentiment analysis (E2E-ABSA). We noted significant improvements in F1 scores and accuracy across all examined datasets.
Neural Architecture Search: Insights from 1000 Papers
Jan 25, 2023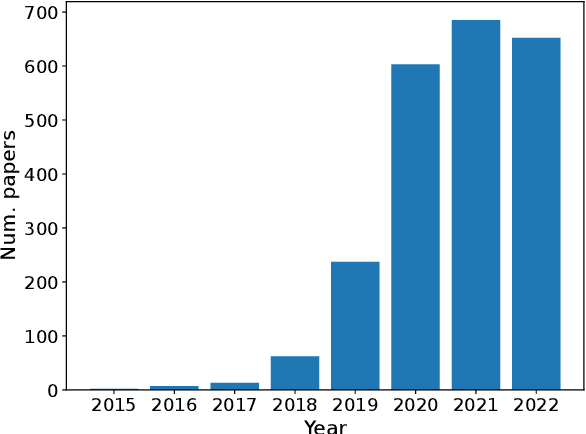
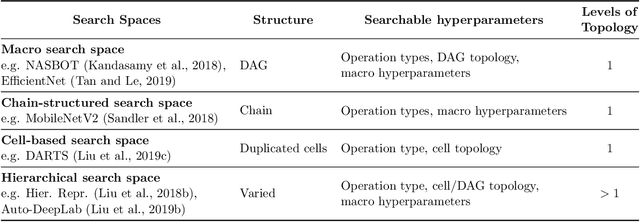
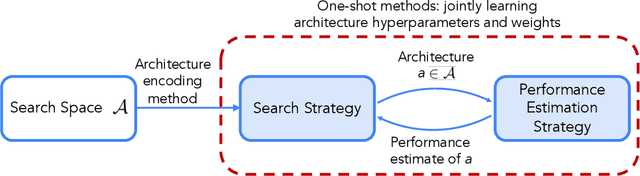
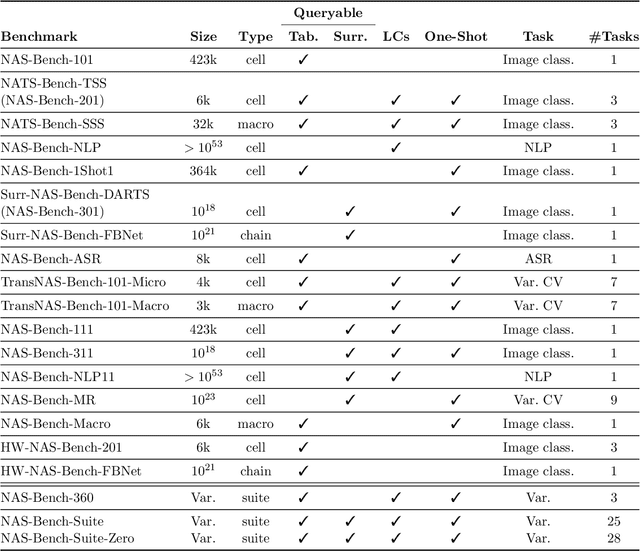
In the past decade, advances in deep learning have resulted in breakthroughs in a variety of areas, including computer vision, natural language understanding, speech recognition, and reinforcement learning. Specialized, high-performing neural architectures are crucial to the success of deep learning in these areas. Neural architecture search (NAS), the process of automating the design of neural architectures for a given task, is an inevitable next step in automating machine learning and has already outpaced the best human-designed architectures on many tasks. In the past few years, research in NAS has been progressing rapidly, with over 1000 papers released since 2020 (Deng and Lindauer, 2021). In this survey, we provide an organized and comprehensive guide to neural architecture search. We give a taxonomy of search spaces, algorithms, and speedup techniques, and we discuss resources such as benchmarks, best practices, other surveys, and open-source libraries.
Understanding the Tradeoffs in Client-Side Privacy for Speech Recognition
Jan 22, 2021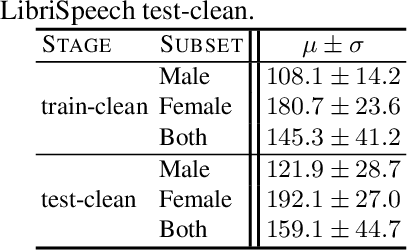
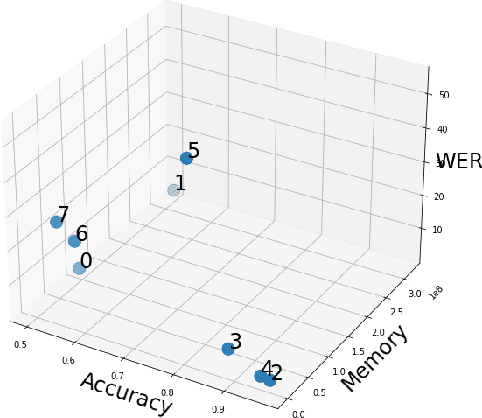
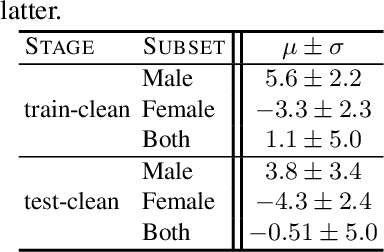
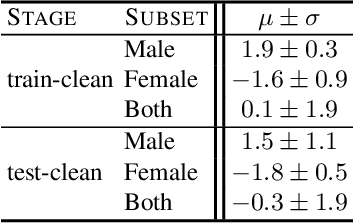
Existing approaches to ensuring privacy of user speech data primarily focus on server-side approaches. While improving server-side privacy reduces certain security concerns, users still do not retain control over whether privacy is ensured on the client-side. In this paper, we define, evaluate, and explore techniques for client-side privacy in speech recognition, where the goal is to preserve privacy on raw speech data before leaving the client's device. We first formalize several tradeoffs in ensuring client-side privacy between performance, compute requirements, and privacy. Using our tradeoff analysis, we perform a large-scale empirical study on existing approaches and find that they fall short on at least one metric. Our results call for more research in this crucial area as a step towards safer real-world deployment of speech recognition systems at scale across mobile devices.
Thank you for Attention: A survey on Attention-based Artificial Neural Networks for Automatic Speech Recognition
Feb 14, 2021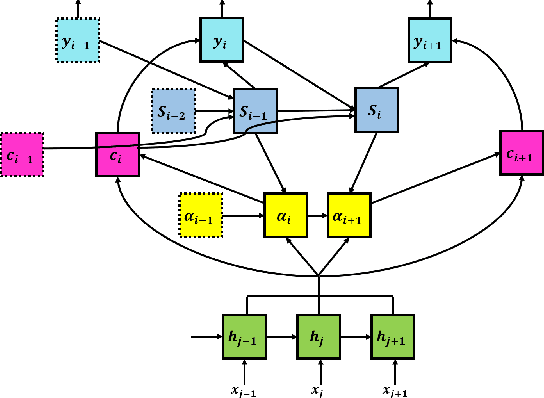
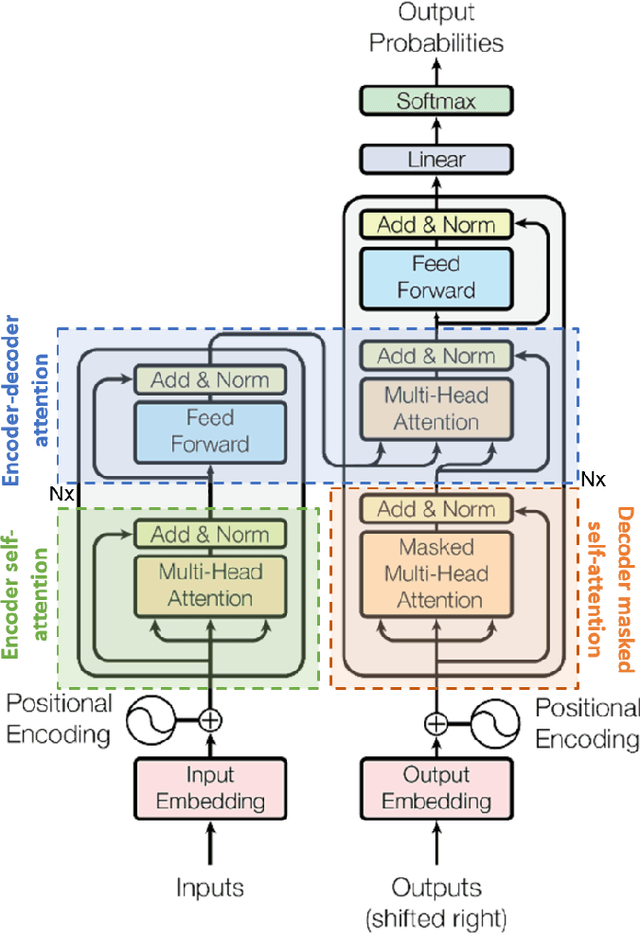
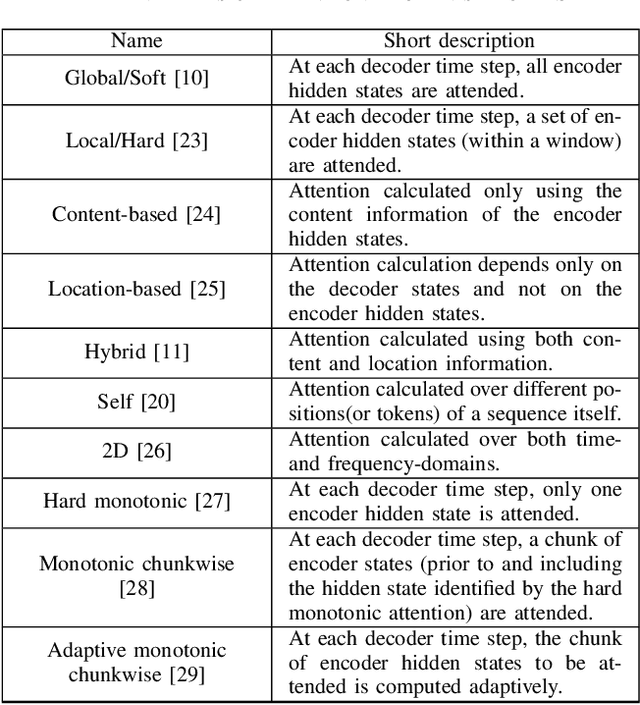
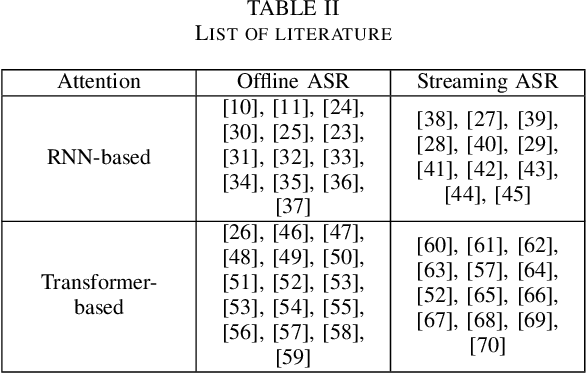
Attention is a very popular and effective mechanism in artificial neural network-based sequence-to-sequence models. In this survey paper, a comprehensive review of the different attention models used in developing automatic speech recognition systems is provided. The paper focuses on the development and evolution of attention models for offline and streaming speech recognition within recurrent neural network- and Transformer- based architectures.
Romanian Speech Recognition Experiments from the ROBIN Project
Nov 23, 2021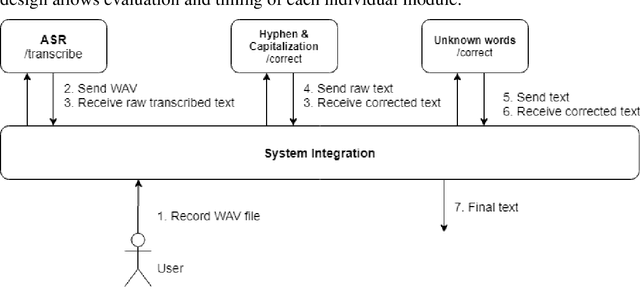
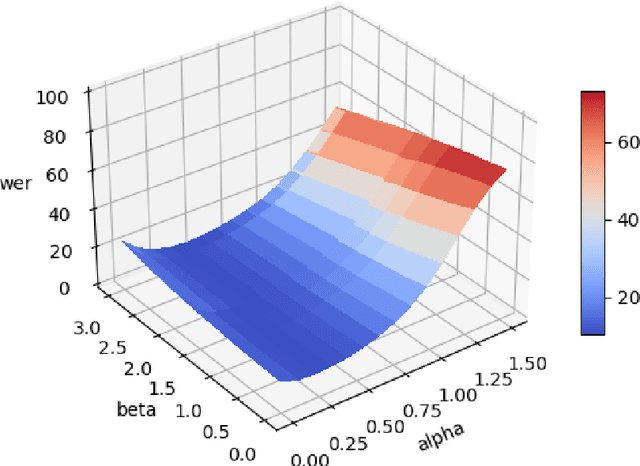
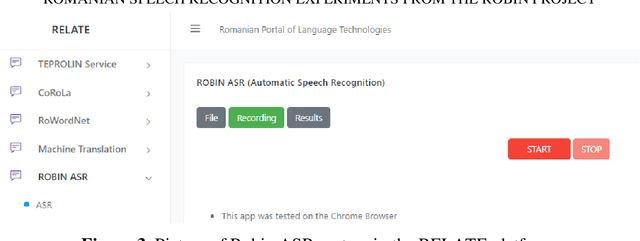
One of the fundamental functionalities for accepting a socially assistive robot is its communication capabilities with other agents in the environment. In the context of the ROBIN project, situational dialogue through voice interaction with a robot was investigated. This paper presents different speech recognition experiments with deep neural networks focusing on producing fast (under 100ms latency from the network itself), while still reliable models. Even though one of the key desired characteristics is low latency, the final deep neural network model achieves state of the art results for recognizing Romanian language, obtaining a 9.91% word error rate (WER), when combined with a language model, thus improving over the previous results while offering at the same time an improved runtime performance. Additionally, we explore two modules for correcting the ASR output (hyphen and capitalization restoration and unknown words correction), targeting the ROBIN project's goals (dialogue in closed micro-worlds). We design a modular architecture based on APIs allowing an integration engine (either in the robot or external) to chain together the available modules as needed. Finally, we test the proposed design by integrating it in the RELATE platform and making the ASR service available to web users by either uploading a file or recording new speech.
Fast Yet Effective Speech Emotion Recognition with Self-distillation
Oct 26, 2022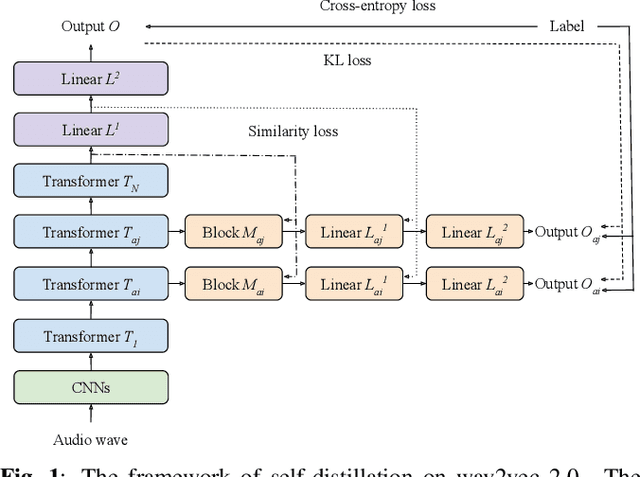
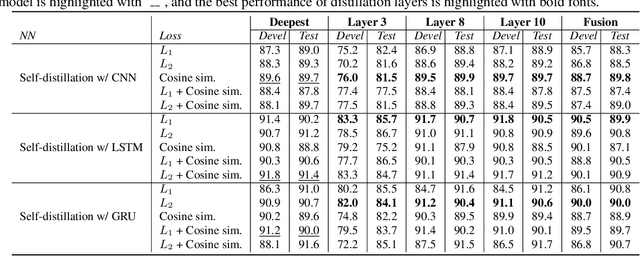
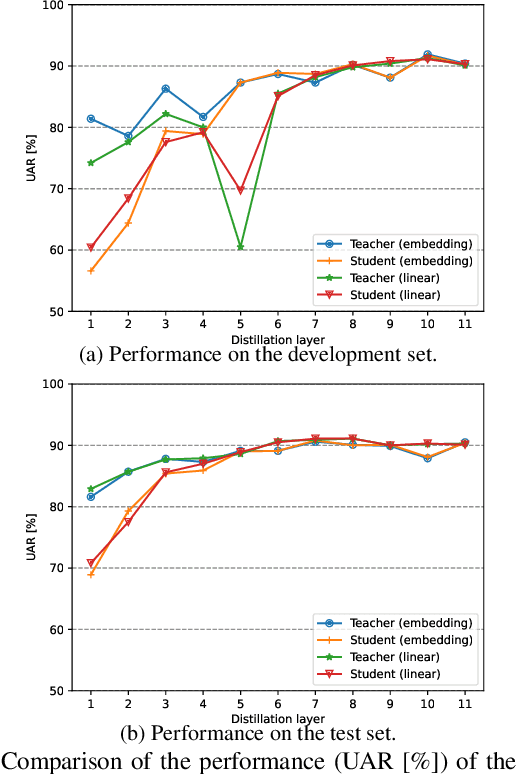
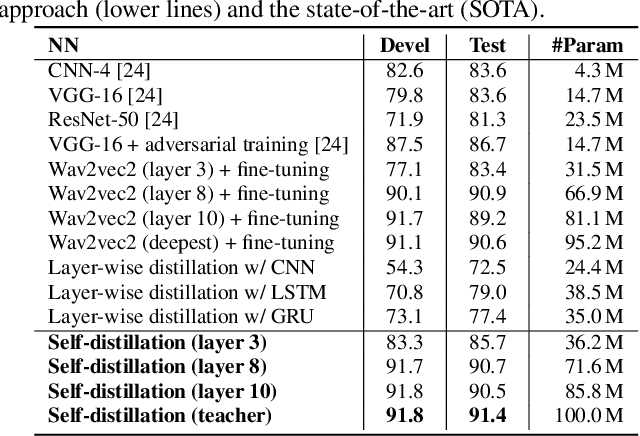
Speech emotion recognition (SER) is the task of recognising human's emotional states from speech. SER is extremely prevalent in helping dialogue systems to truly understand our emotions and become a trustworthy human conversational partner. Due to the lengthy nature of speech, SER also suffers from the lack of abundant labelled data for powerful models like deep neural networks. Pre-trained complex models on large-scale speech datasets have been successfully applied to SER via transfer learning. However, fine-tuning complex models still requires large memory space and results in low inference efficiency. In this paper, we argue achieving a fast yet effective SER is possible with self-distillation, a method of simultaneously fine-tuning a pretrained model and training shallower versions of itself. The benefits of our self-distillation framework are threefold: (1) the adoption of self-distillation method upon the acoustic modality breaks through the limited ground-truth of speech data, and outperforms the existing models' performance on an SER dataset; (2) executing powerful models at different depth can achieve adaptive accuracy-efficiency trade-offs on resource-limited edge devices; (3) a new fine-tuning process rather than training from scratch for self-distillation leads to faster learning time and the state-of-the-art accuracy on data with small quantities of label information.
Language Agnostic Data-Driven Inverse Text Normalization
Jan 24, 2023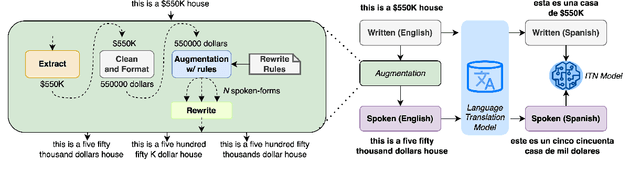
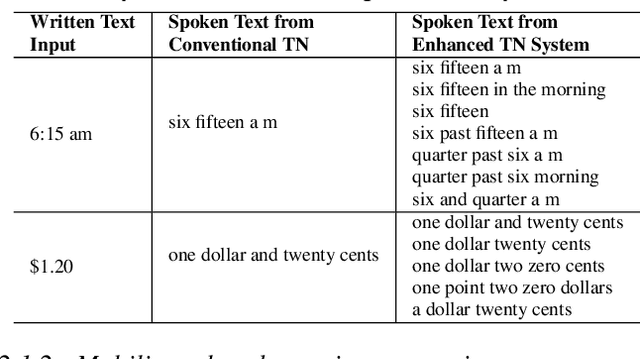
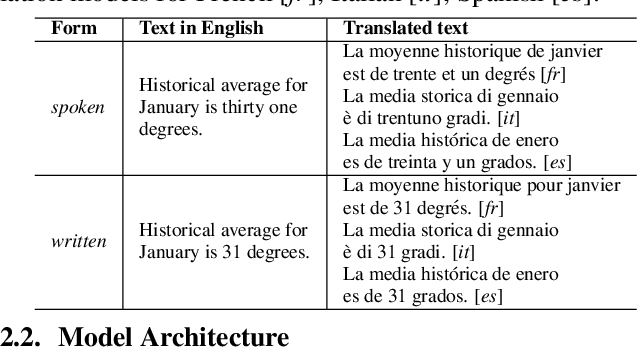
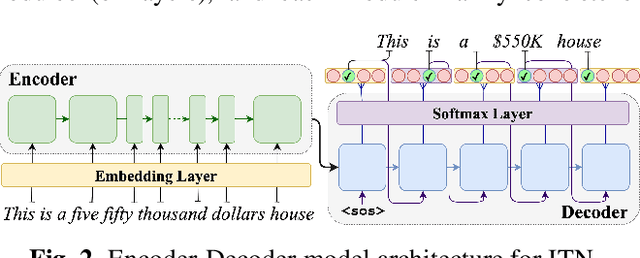
With the emergence of automatic speech recognition (ASR) models, converting the spoken form text (from ASR) to the written form is in urgent need. This inverse text normalization (ITN) problem attracts the attention of researchers from various fields. Recently, several works show that data-driven ITN methods can output high-quality written form text. Due to the scarcity of labeled spoken-written datasets, the studies on non-English data-driven ITN are quite limited. In this work, we propose a language-agnostic data-driven ITN framework to fill this gap. Specifically, we leverage the data augmentation in conjunction with neural machine translated data for low resource languages. Moreover, we design an evaluation method for language agnostic ITN model when only English data is available. Our empirical evaluation shows this language agnostic modeling approach is effective for low resource languages while preserving the performance for high resource languages.