 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Domain Adversarial Neural Networks for Dysarthric Speech Recognition
Oct 07, 2020
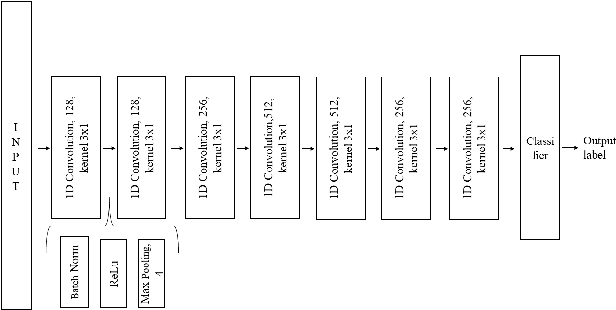
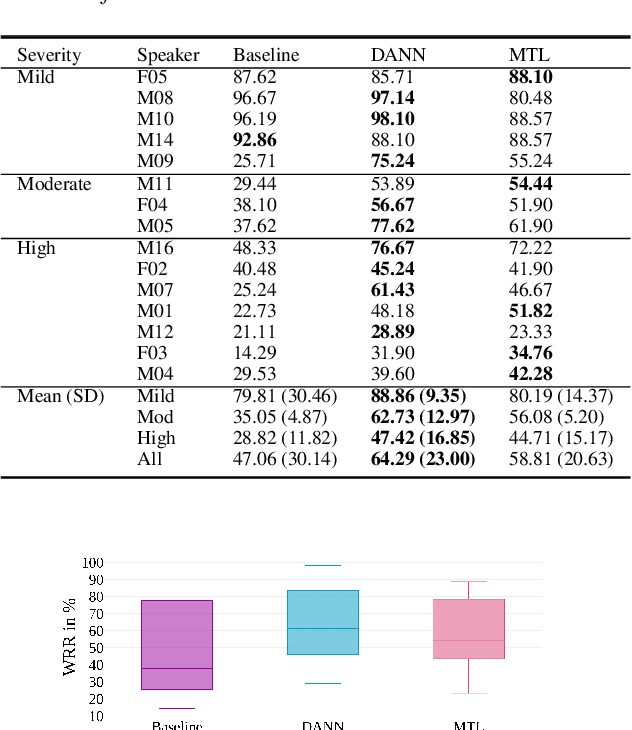
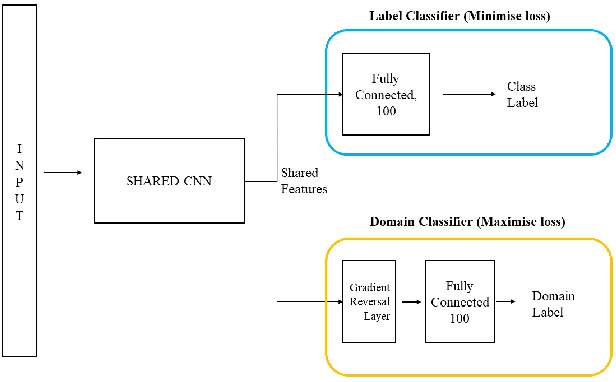
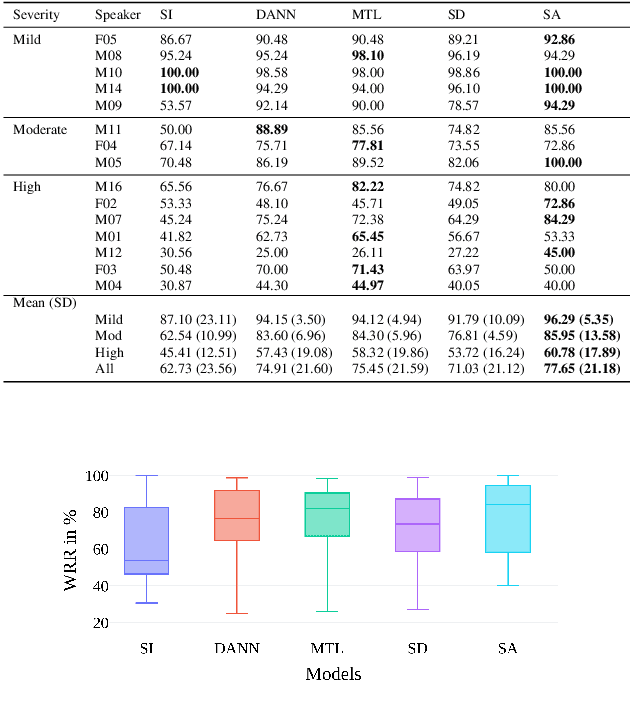
Speech recognition systems have improved dramatically over the last few years, however, their performance is significantly degraded for the cases of accented or impaired speech. This work explores domain adversarial neural networks (DANN) for speaker-independent speech recognition on the UAS dataset of dysarthric speech. The classification task on 10 spoken digits is performed using an end-to-end CNN taking raw audio as input. The results are compared to a speaker-adaptive (SA) model as well as speaker-dependent (SD) and multi-task learning models (MTL). The experiments conducted in this paper show that DANN achieves an absolute recognition rate of 74.91% and outperforms the baseline by 12.18%. Additionally, the DANN model achieves comparable results to the SA model's recognition rate of 77.65%. We also observe that when labelled dysarthric speech data is available DANN and MTL perform similarly, but when they are not DANN performs better than MTL.
Transformer-Transducers for Code-Switched Speech Recognition
Nov 30, 2020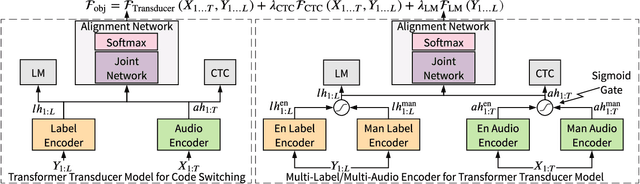
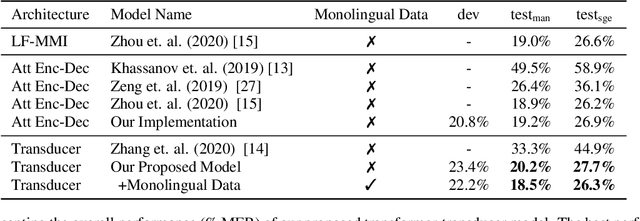


We live in a world where 60% of the population can speak two or more languages fluently. Members of these communities constantly switch between languages when having a conversation. As automatic speech recognition (ASR) systems are being deployed to the real-world, there is a need for practical systems that can handle multiple languages both within an utterance or across utterances. In this paper, we present an end-to-end ASR system using a transformer-transducer model architecture for code-switched speech recognition. We propose three modifications over the vanilla model in order to handle various aspects of code-switching. First, we introduce two auxiliary loss functions to handle the low-resource scenario of code-switching. Second, we propose a novel mask-based training strategy with language ID information to improve the label encoder training towards intra-sentential code-switching. Finally, we propose a multi-label/multi-audio encoder structure to leverage the vast monolingual speech corpora towards code-switching. We demonstrate the efficacy of our proposed approaches on the SEAME dataset, a public Mandarin-English code-switching corpus, achieving a mixed error rate of 18.5% and 26.3% on test_man and test_sge sets respectively.
Hear No Evil: Towards Adversarial Robustness of Automatic Speech Recognition via Multi-Task Learning
Apr 05, 2022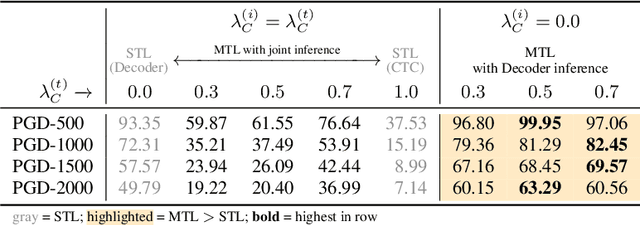
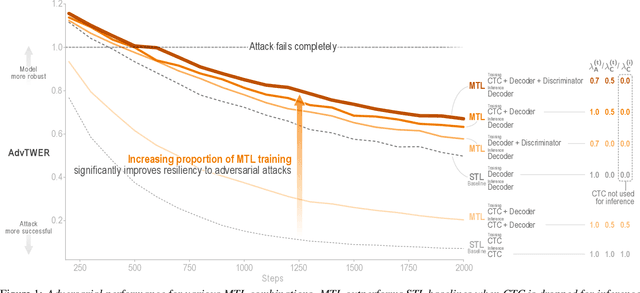
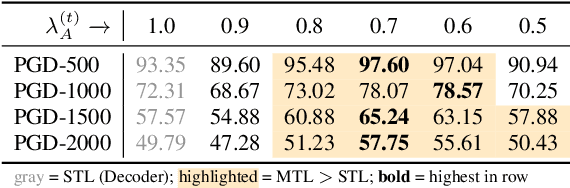
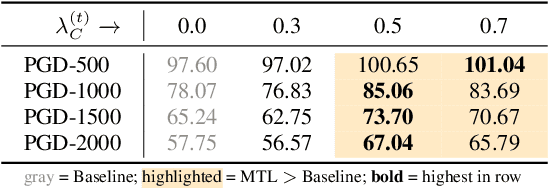
As automatic speech recognition (ASR) systems are now being widely deployed in the wild, the increasing threat of adversarial attacks raises serious questions about the security and reliability of using such systems. On the other hand, multi-task learning (MTL) has shown success in training models that can resist adversarial attacks in the computer vision domain. In this work, we investigate the impact of performing such multi-task learning on the adversarial robustness of ASR models in the speech domain. We conduct extensive MTL experimentation by combining semantically diverse tasks such as accent classification and ASR, and evaluate a wide range of adversarial settings. Our thorough analysis reveals that performing MTL with semantically diverse tasks consistently makes it harder for an adversarial attack to succeed. We also discuss in detail the serious pitfalls and their related remedies that have a significant impact on the robustness of MTL models. Our proposed MTL approach shows considerable absolute improvements in adversarially targeted WER ranging from 17.25 up to 59.90 compared to single-task learning baselines (attention decoder and CTC respectively). Ours is the first in-depth study that uncovers adversarial robustness gains from multi-task learning for ASR.
Improving EEG based continuous speech recognition using GAN
May 29, 2020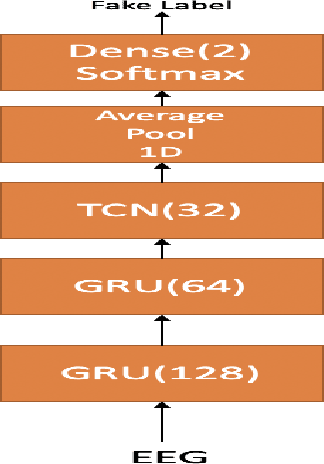
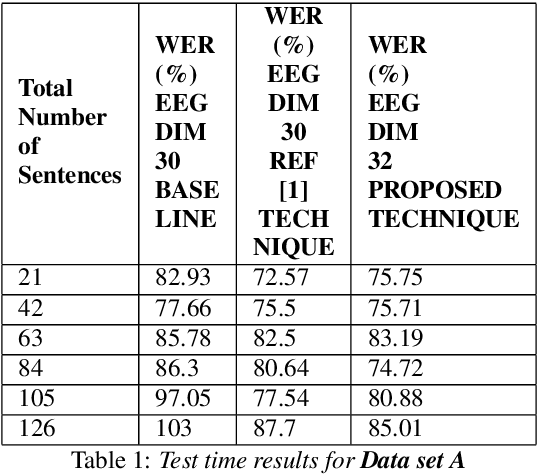
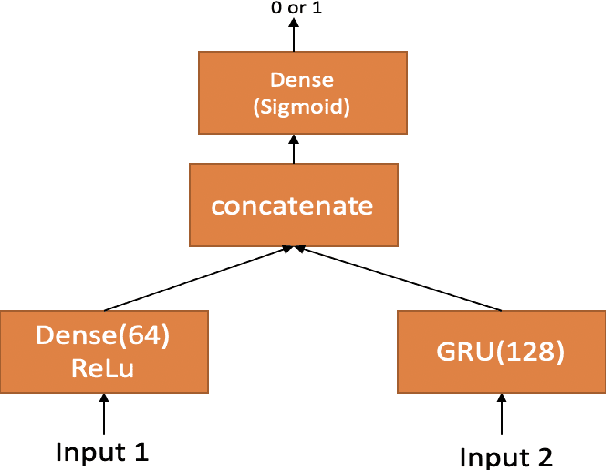
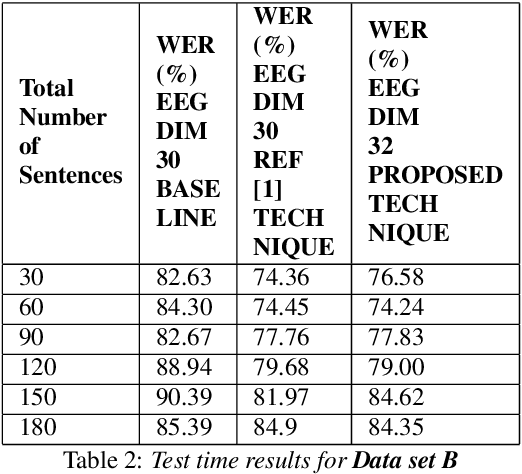
In this paper we demonstrate that it is possible to generate more meaningful electroencephalography (EEG) features from raw EEG features using generative adversarial networks (GAN) to improve the performance of EEG based continuous speech recognition systems. We improve the results demonstrated by authors in [1] using their data sets for for some of the test time experiments and for other cases our results were comparable with theirs. Our proposed approach can be implemented without using any additional sensor information, whereas in [1] authors used additional features like acoustic or articulatory information to improve the performance of EEG based continuous speech recognition systems.
A Novel Scheme to classify Read and Spontaneous Speech
Jun 13, 2023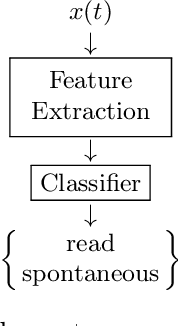
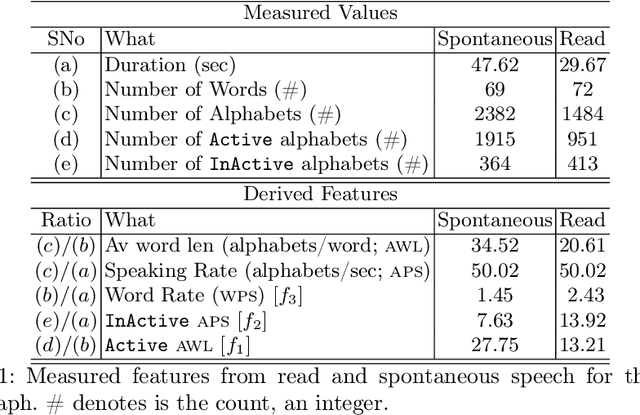
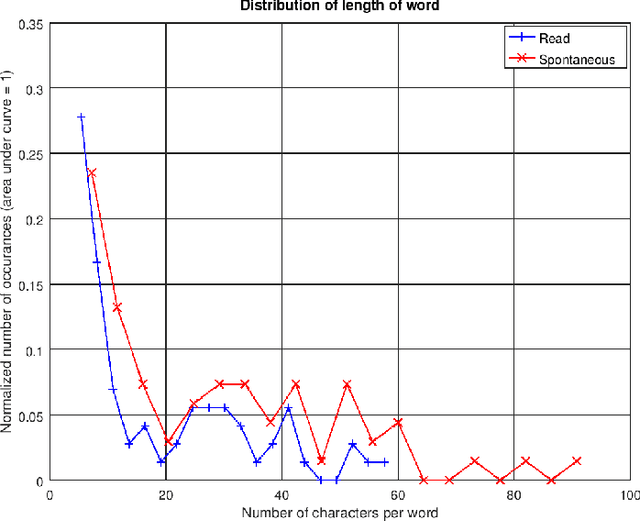
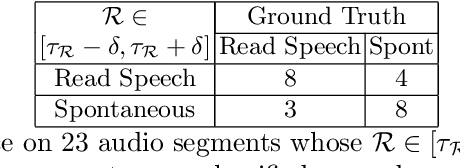
The COVID-19 pandemic has led to an increased use of remote telephonic interviews, making it important to distinguish between scripted and spontaneous speech in audio recordings. In this paper, we propose a novel scheme for identifying read and spontaneous speech. Our approach uses a pre-trained DeepSpeech audio-to-alphabet recognition engine to generate a sequence of alphabets from the audio. From these alphabets, we derive features that allow us to discriminate between read and spontaneous speech. Our experimental results show that even a small set of self-explanatory features can effectively classify the two types of speech very effectively.
Representation Learning For Speech Recognition Using Feedback Based Relevance Weighting
Feb 15, 2021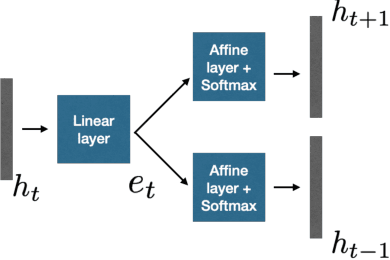

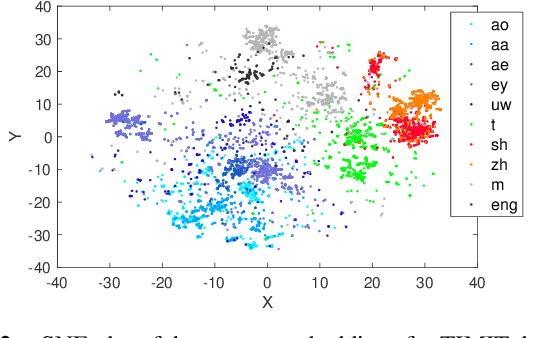
In this work, we propose an acoustic embedding based approach for representation learning in speech recognition. The proposed approach involves two stages comprising of acoustic filterbank learning from raw waveform, followed by modulation filterbank learning. In each stage, a relevance weighting operation is employed that acts as a feature selection module. In particular, the relevance weighting network receives embeddings of the model outputs from the previous time instants as feedback. The proposed relevance weighting scheme allows the respective feature representations to be adaptively selected before propagation to the higher layers. The application of the proposed approach for the task of speech recognition on Aurora-4 and CHiME-3 datasets gives significant performance improvements over baseline systems on raw waveform signal as well as those based on mel representations (average relative improvement of 15% over the mel baseline on Aurora-4 dataset and 7% on CHiME-3 dataset).
* arXiv admin note: substantial text overlap with arXiv:2011.00721, arXiv:2011.02136, arXiv:2001.07067
Right the docs: Characterising voice dataset documentation practices used in machine learning
Mar 19, 2023
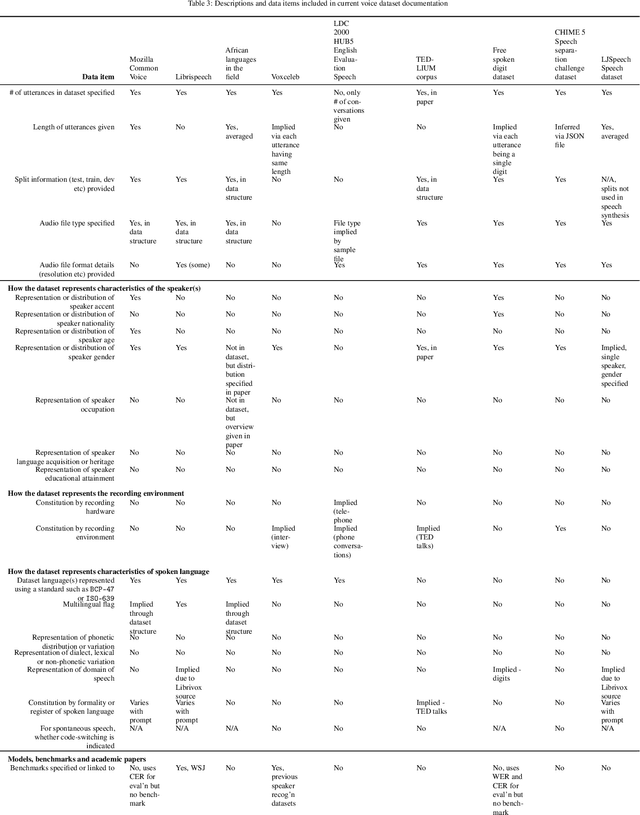
Voice-enabled technology is quickly becoming ubiquitous, and is constituted from machine learning (ML)-enabled components such as speech recognition and voice activity detection. However, these systems don't yet work well for everyone. They exhibit bias - the systematic and unfair discrimination against individuals or cohorts of individuals in favour of others (Friedman & Nissembaum, 1996) - across axes such as age, gender and accent. ML is reliant on large datasets for training. Dataset documentation is designed to give ML Practitioners (MLPs) a better understanding of a dataset's characteristics. However, there is a lack of empirical research on voice dataset documentation specifically. Additionally, while MLPs are frequent participants in fairness research, little work focuses on those who work with voice data. Our work makes an empirical contribution to this gap. Here, we combine two methods to form an exploratory study. First, we undertake 13 semi-structured interviews, exploring multiple perspectives of voice dataset documentation practice. Using open and axial coding methods, we explore MLPs' practices through the lenses of roles and tradeoffs. Drawing from this work, we then purposively sample voice dataset documents (VDDs) for 9 voice datasets. Our findings then triangulate these two methods, using the lenses of MLP roles and trade-offs. We find that current VDD practices are inchoate, inadequate and incommensurate. The characteristics of voice datasets are codified in fragmented, disjoint ways that often do not meet the needs of MLPs. Moreover, they cannot be readily compared, presenting a barrier to practitioners' bias reduction efforts. We then discuss the implications of these findings for bias practices in voice data and speech technologies. We conclude by setting out a program of future work to address these findings -- that is, how we may "right the docs".
Towards Better Meta-Initialization with Task Augmentation for Kindergarten-aged Speech Recognition
Feb 24, 2022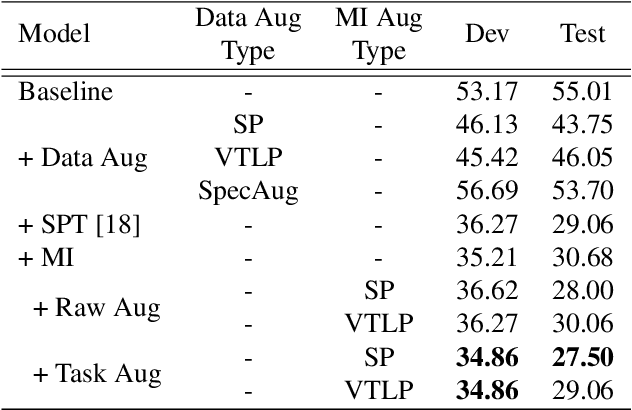
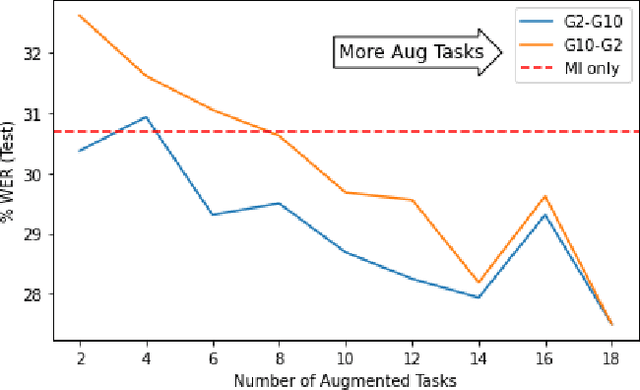
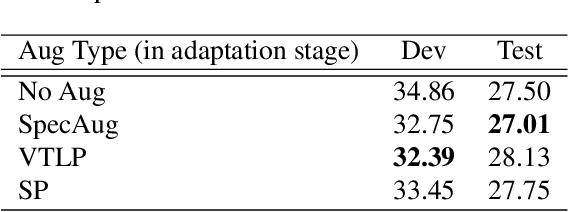
Children's automatic speech recognition (ASR) is always difficult due to, in part, the data scarcity problem, especially for kindergarten-aged kids. When data are scarce, the model might overfit to the training data, and hence good starting points for training are essential. Recently, meta-learning was proposed to learn model initialization (MI) for ASR tasks of different languages. This method leads to good performance when the model is adapted to an unseen language. However, MI is vulnerable to overfitting on training tasks (learner overfitting). It is also unknown whether MI generalizes to other low-resource tasks. In this paper, we validate the effectiveness of MI in children's ASR and attempt to alleviate the problem of learner overfitting. To achieve model-agnostic meta-learning (MAML), we regard children's speech at each age as a different task. In terms of learner overfitting, we propose a task-level augmentation method by simulating new ages using frequency warping techniques. Detailed experiments are conducted to show the impact of task augmentation on each age for kindergarten-aged speech. As a result, our approach achieves a relative word error rate (WER) improvement of 51% over the baseline system with no augmentation or initialization.
A Comparative Study on Speaker-attributed Automatic Speech Recognition in Multi-party Meetings
Apr 01, 2022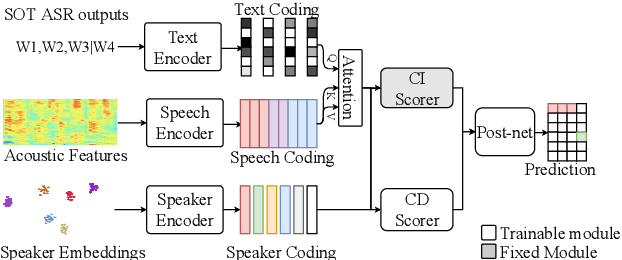
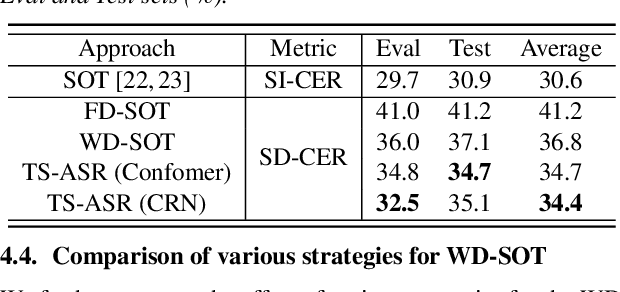
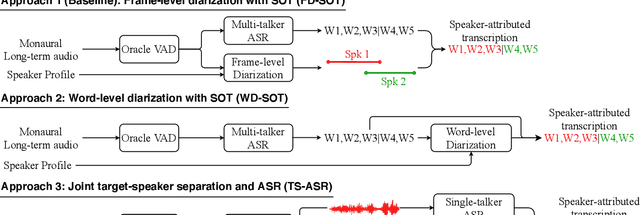
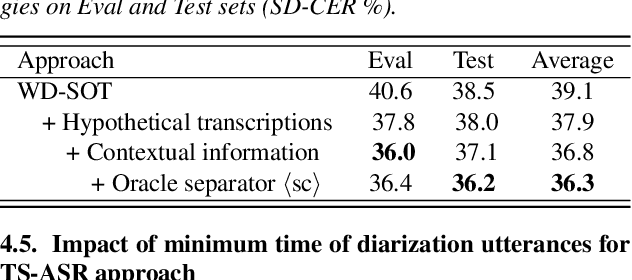
In this paper, we conduct a comparative study on speaker-attributed automatic speech recognition (SA-ASR) in the multi-party meeting scenario, a topic with increasing attention in meeting rich transcription. Specifically, three approaches are evaluated in this study. The first approach, FD-SOT, consists of a frame-level diarization model to identify speakers and a multi-talker ASR to recognize utterances. The speaker-attributed transcriptions are obtained by aligning the diarization results and recognized hypotheses. However, such an alignment strategy may suffer from erroneous timestamps due to the modular independence, severely hindering the model performance. Therefore, we propose the second approach, WD-SOT, to address alignment errors by introducing a word-level diarization model, which can get rid of such timestamp alignment dependency. To further mitigate the alignment issues, we propose the third approach, TS-ASR, which trains a target-speaker separation module and an ASR module jointly. By comparing various strategies for each SA-ASR approach, experimental results on a real meeting scenario corpus, AliMeeting, reveal that the WD-SOT approach achieves 10.7% relative reduction on averaged speaker-dependent character error rate (SD-CER), compared with the FD-SOT approach. In addition, the TS-ASR approach also outperforms the FD-SOT approach and brings 16.5% relative average SD-CER reduction.
Connecting Humanities and Social Sciences: Applying Language and Speech Technology to Online Panel Surveys
Feb 21, 2023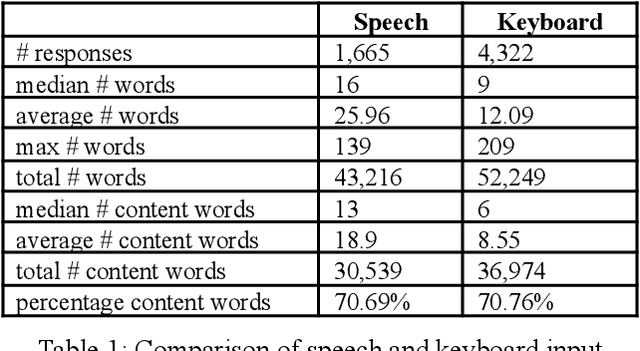
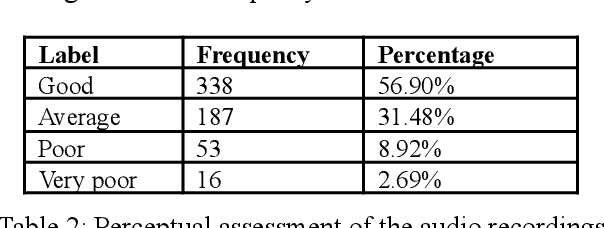
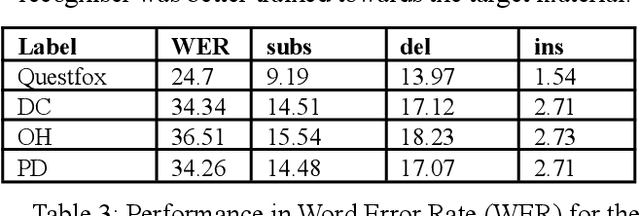
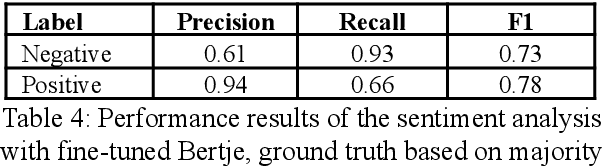
In this paper, we explore the application of language and speech technology to open-ended questions in a Dutch panel survey. In an experimental wave respondents could choose to answer open questions via speech or keyboard. Automatic speech recognition (ASR) was used to process spoken responses. We evaluated answers from these input modalities to investigate differences between spoken and typed answers.We report the errors the ASR system produces and investigate the impact of these errors on downstream analyses. Open-ended questions give more freedom to answer for respondents, but entail a non-trivial amount of work to analyse. We evaluated the feasibility of using transformer-based models (e.g. BERT) to apply sentiment analysis and topic modelling on the answers of open questions. A big advantage of transformer-based models is that they are trained on a large amount of language materials and do not necessarily need training on the target materials. This is especially advantageous for survey data, which does not contain a lot of text materials. We tested the quality of automatic sentiment analysis by comparing automatic labeling with three human raters and tested the robustness of topic modelling by comparing the generated models based on automatic and manually transcribed spoken answers.