 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Improving CTC-based speech recognition via knowledge transferring from pre-trained language models
Feb 22, 2022
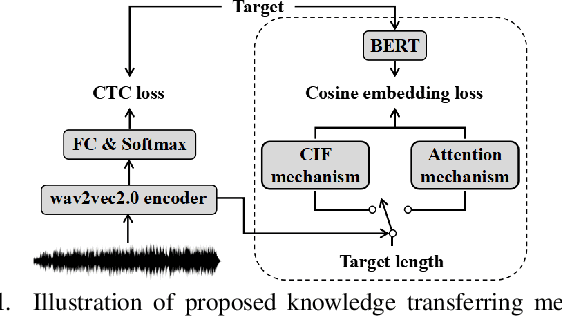
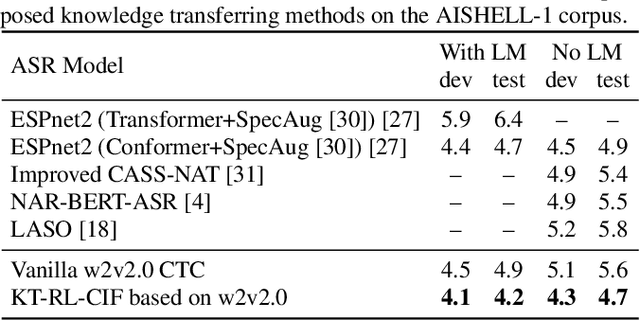
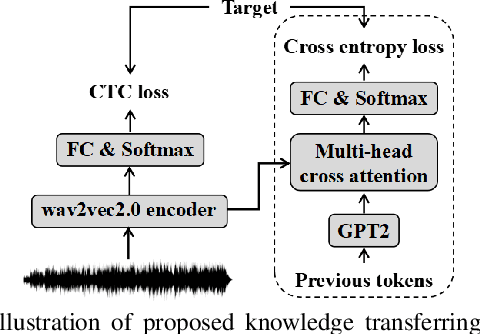
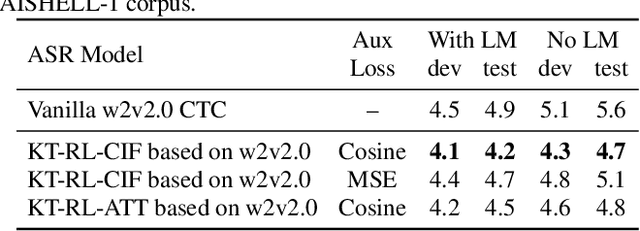
Recently, end-to-end automatic speech recognition models based on connectionist temporal classification (CTC) have achieved impressive results, especially when fine-tuned from wav2vec2.0 models. Due to the conditional independence assumption, CTC-based models are always weaker than attention-based encoder-decoder models and require the assistance of external language models (LMs). To solve this issue, we propose two knowledge transferring methods that leverage pre-trained LMs, such as BERT and GPT2, to improve CTC-based models. The first method is based on representation learning, in which the CTC-based models use the representation produced by BERT as an auxiliary learning target. The second method is based on joint classification learning, which combines GPT2 for text modeling with a hybrid CTC/attention architecture. Experiment on AISHELL-1 corpus yields a character error rate (CER) of 4.2% on the test set. When compared to the vanilla CTC-based models fine-tuned from the wav2vec2.0 models, our knowledge transferring method reduces CER by 16.1% relatively without external LMs.
Variational Auto-Encoder Based Variability Encoding for Dysarthric Speech Recognition
Jan 24, 2022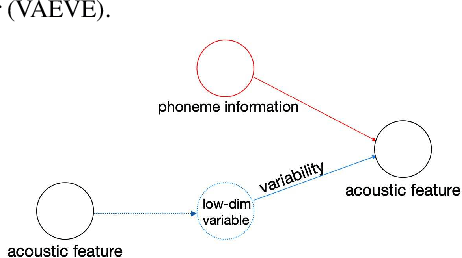
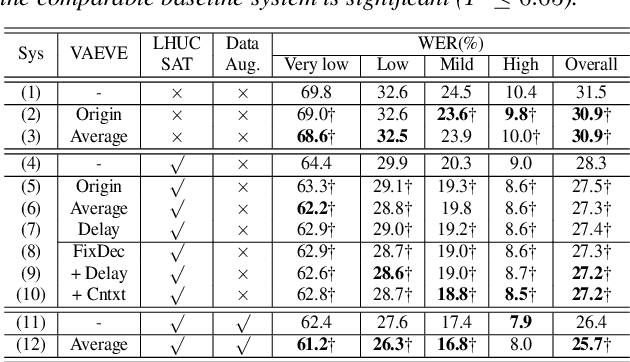
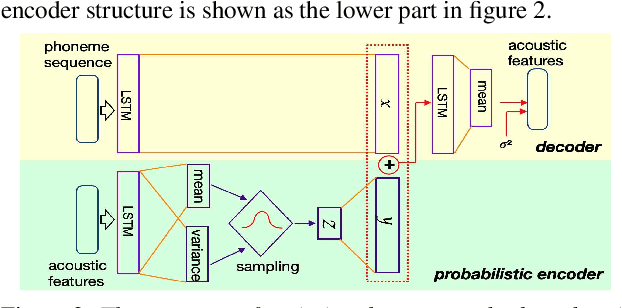
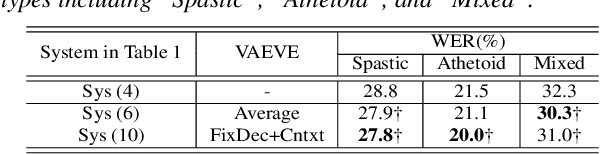
Dysarthric speech recognition is a challenging task due to acoustic variability and limited amount of available data. Diverse conditions of dysarthric speakers account for the acoustic variability, which make the variability difficult to be modeled precisely. This paper presents a variational auto-encoder based variability encoder (VAEVE) to explicitly encode such variability for dysarthric speech. The VAEVE makes use of both phoneme information and low-dimensional latent variable to reconstruct the input acoustic features, thereby the latent variable is forced to encode the phoneme-independent variability. Stochastic gradient variational Bayes algorithm is applied to model the distribution for generating variability encodings, which are further used as auxiliary features for DNN acoustic modeling. Experiment results conducted on the UASpeech corpus show that the VAEVE based variability encodings have complementary effect to the learning hidden unit contributions (LHUC) speaker adaptation. The systems using variability encodings consistently outperform the comparable baseline systems without using them, and" obtain absolute word error rate (WER) reduction by up to 2.2% on dysarthric speech with "Very lowintelligibility level, and up to 2% on the "Mixed" type of dysarthric speech with diverse or uncertain conditions.
Supplementary Features of BiLSTM for Enhanced Sequence Labeling
Jun 08, 2023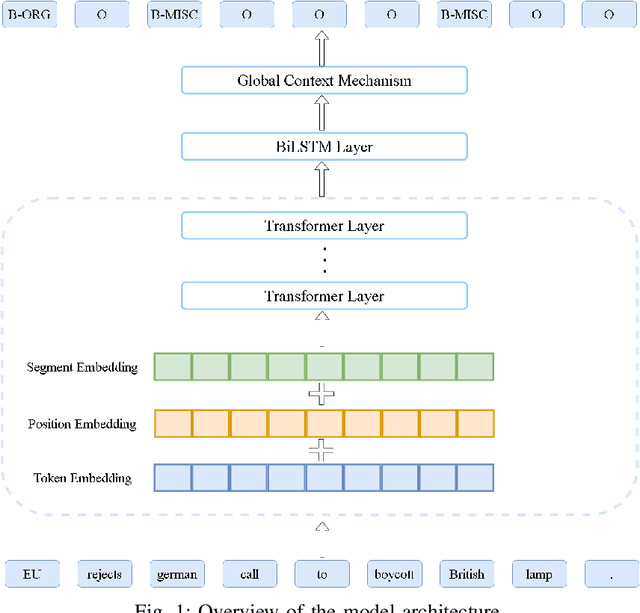
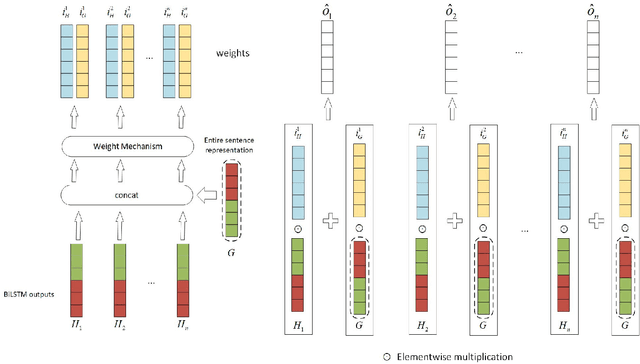
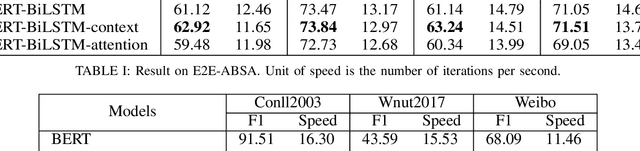
Sequence labeling tasks require the computation of sentence representations for each word within a given sentence. With the rise of advanced pretrained language models; one common approach involves incorporating a BiLSTM layer to enhance the sequence structure information at the output level. Nevertheless, it has been empirically demonstrated (P.-H. Li, 2020) that BiLSTM's potential for generating sentence representations for sequence labeling tasks is constrained, primarily due to the integration of fragments from past and future sentence representations to form a complete sentence representation. In this study, we observed that the entire sentence representation, found in both the first and last cells of BiLSTM, can supplement each cell's sentence representation. Accordingly, we devised a global context mechanism to integrate entire future and past sentence representations into each cell's sentence representation within BiLSTM, leading to a significant improvement in both F1 score and accuracy. By embedding the BERT model within BiLSTM as a demonstration, and conducting exhaustive experiments on nine datasets for sequence labeling tasks, including named entity recognition (NER), part of speech (POS) tagging and End-to-End Aspect-Based sentiment analysis (E2E-ABSA). We noted significant improvements in F1 scores and accuracy across all examined datasets.
Improving EEG based Continuous Speech Recognition
Nov 24, 2019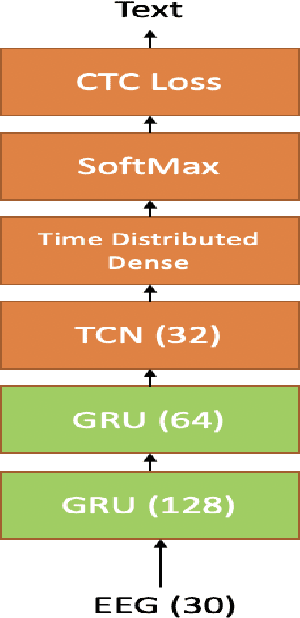
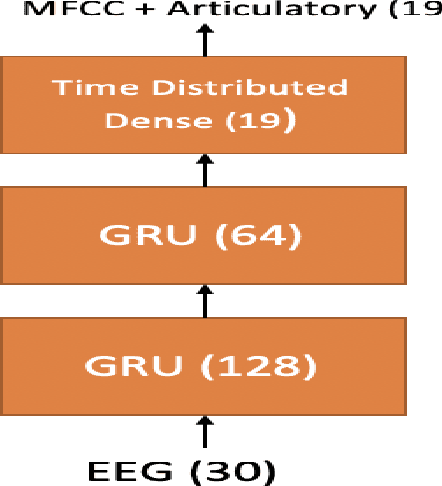
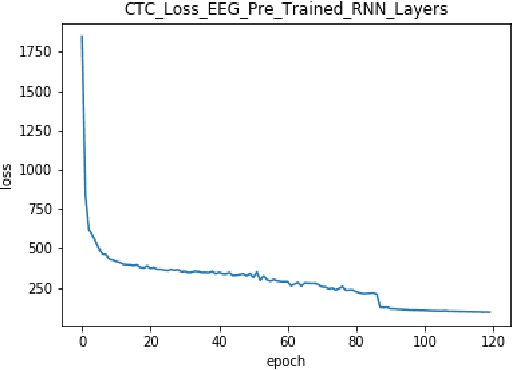
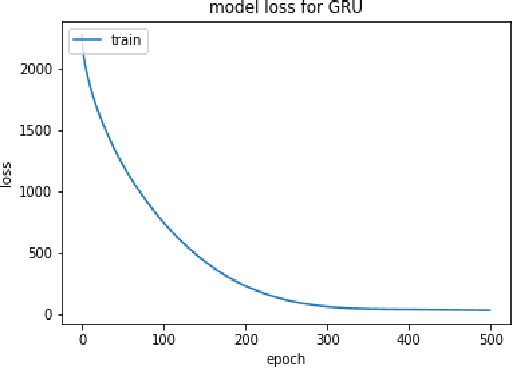
In this paper we introduce various techniques to improve the performance of electroencephalography (EEG) features based continuous speech recognition (CSR) systems. A connectionist temporal classification (CTC) based automatic speech recognition (ASR) system was implemented for performing recognition. We introduce techniques to initialize the weights of the recurrent layers in the encoder of the CTC model with more meaningful weights rather than with random weights and we make use of an external language model to improve the beam search during decoding time. We finally study the problem of predicting articulatory features from EEG features in this paper.
Investigation of Densely Connected Convolutional Networks with Domain Adversarial Learning for Noise Robust Speech Recognition
Dec 19, 2021
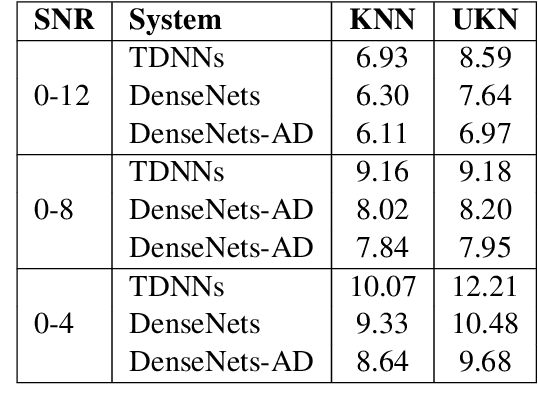

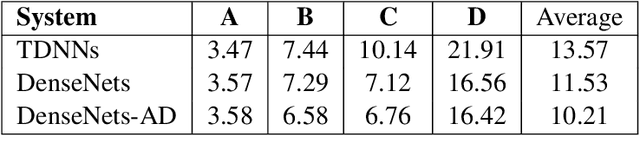
We investigate densely connected convolutional networks (DenseNets) and their extension with domain adversarial training for noise robust speech recognition. DenseNets are very deep, compact convolutional neural networks which have demonstrated incredible improvements over the state-of-the-art results in computer vision. Our experimental results reveal that DenseNets are more robust against noise than other neural network based models such as deep feed forward neural networks and convolutional neural networks. Moreover, domain adversarial learning can further improve the robustness of DenseNets against both, known and unknown noise conditions.
Efficient End-to-End Speech Recognition Using Performers in Conformers
Nov 11, 2020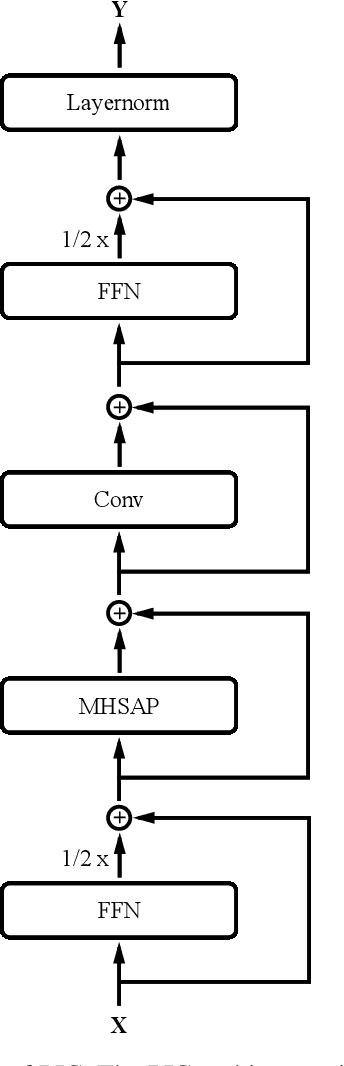
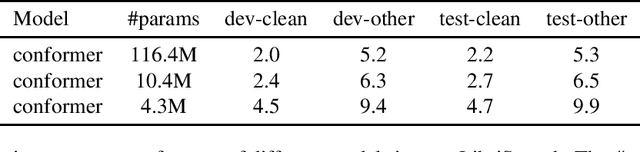

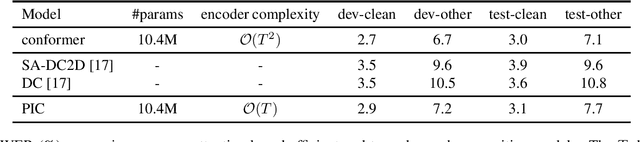
On-device end-to-end speech recognition poses a high requirement on model efficiency. Most prior works improve the efficiency by reducing model sizes. We propose to reduce the complexity of model architectures in addition to model sizes. More specifically, we reduce the floating-point operations in conformer by replacing the transformer module with a performer. The proposed attention-based efficient end-to-end speech recognition model yields competitive performance on the LibriSpeech corpus with 10 millions of parameters and linear computation complexity. The proposed model also outperforms previous lightweight end-to-end models by about 20% relatively in word error rate.
Synthesizing Dysarthric Speech Using Multi-talker TTS for Dysarthric Speech Recognition
Jan 27, 2022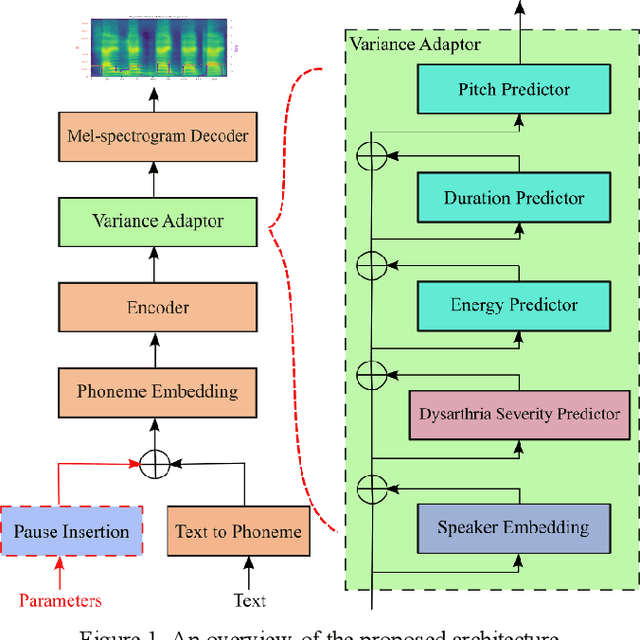
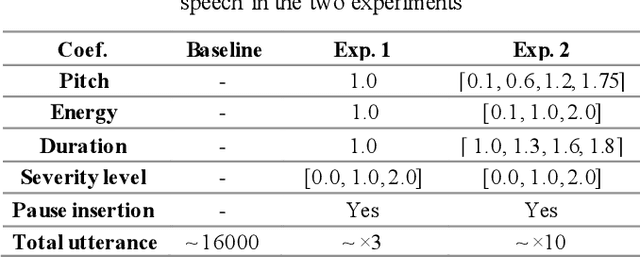
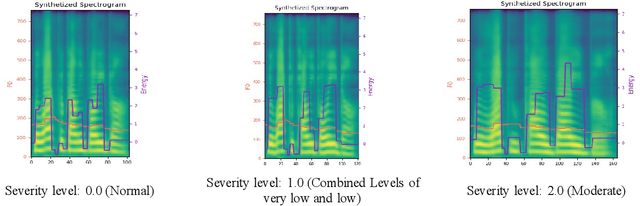
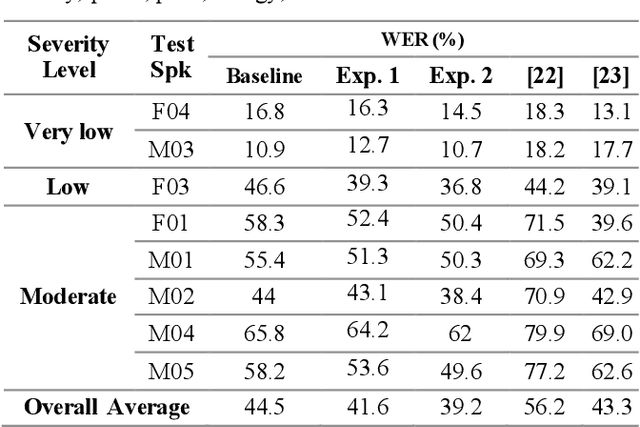
Dysarthria is a motor speech disorder often characterized by reduced speech intelligibility through slow, uncoordinated control of speech production muscles. Automatic Speech recognition (ASR) systems may help dysarthric talkers communicate more effectively. To have robust dysarthria-specific ASR, sufficient training speech is required, which is not readily available. Recent advances in Text-To-Speech (TTS) synthesis multi-speaker end-to-end TTS systems suggest the possibility of using synthesis for data augmentation. In this paper, we aim to improve multi-speaker end-to-end TTS systems to synthesize dysarthric speech for improved training of a dysarthria-specific DNN-HMM ASR. In the synthesized speech, we add dysarthria severity level and pause insertion mechanisms to other control parameters such as pitch, energy, and duration. Results show that a DNN-HMM model trained on additional synthetic dysarthric speech achieves WER improvement of 12.2% compared to the baseline, the addition of the severity level and pause insertion controls decrease WER by 6.5%, showing the effectiveness of adding these parameters. Audio samples are available at
Representation Learning with Graph Neural Networks for Speech Emotion Recognition
Aug 21, 2022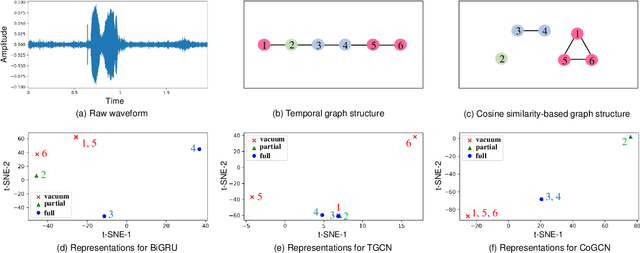
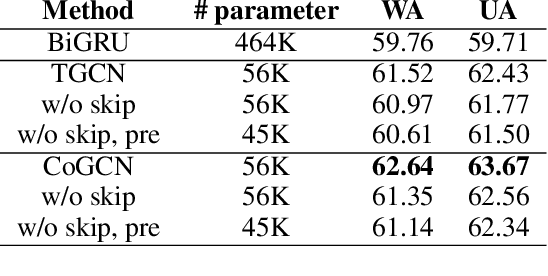
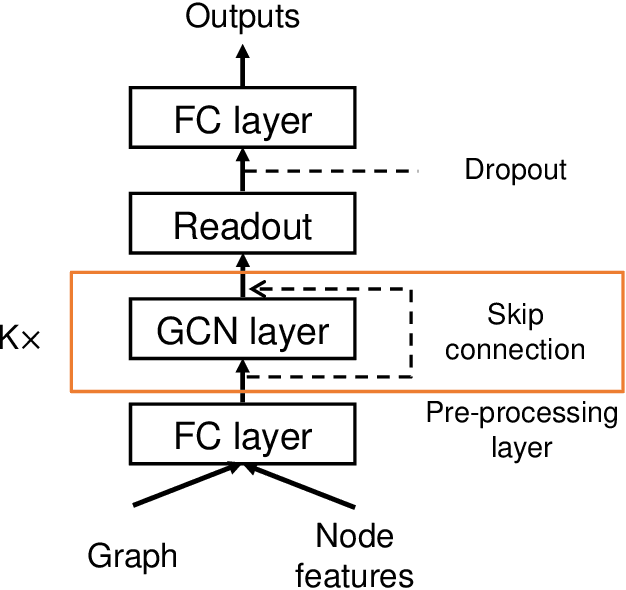
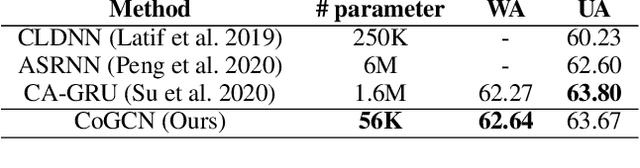
Learning expressive representation is crucial in deep learning. In speech emotion recognition (SER), vacuum regions or noises in the speech interfere with expressive representation learning. However, traditional RNN-based models are susceptible to such noise. Recently, Graph Neural Network (GNN) has demonstrated its effectiveness for representation learning, and we adopt this framework for SER. In particular, we propose a cosine similarity-based graph as an ideal graph structure for representation learning in SER. We present a Cosine similarity-based Graph Convolutional Network (CoGCN) that is robust to perturbation and noise. Experimental results show that our method outperforms state-of-the-art methods or provides competitive results with a significant model size reduction with only 1/30 parameters.
Right the docs: Characterising voice dataset documentation practices used in machine learning
Mar 19, 2023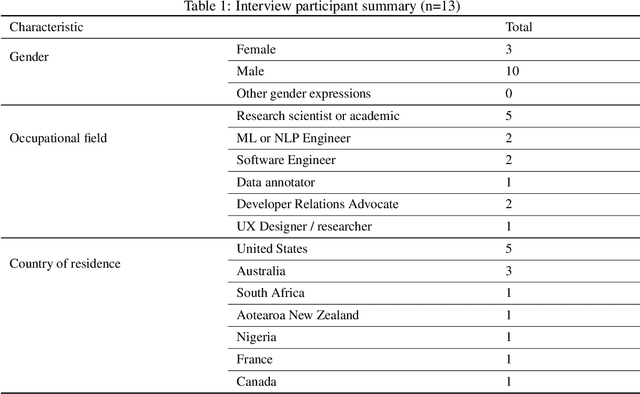
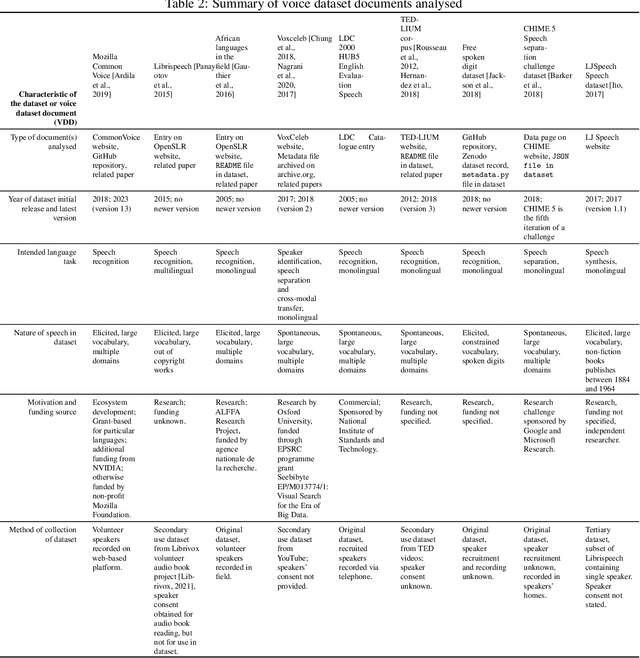
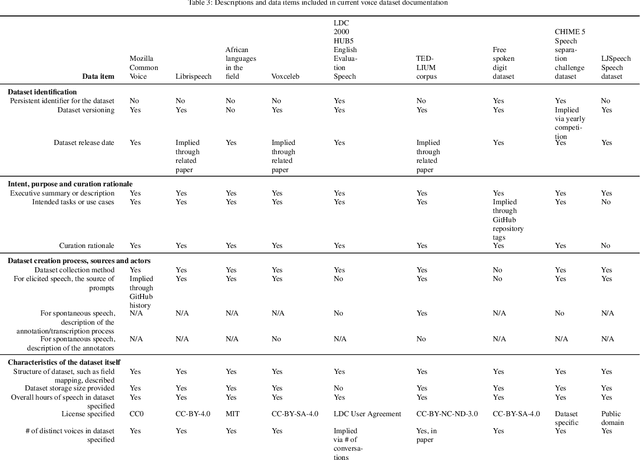
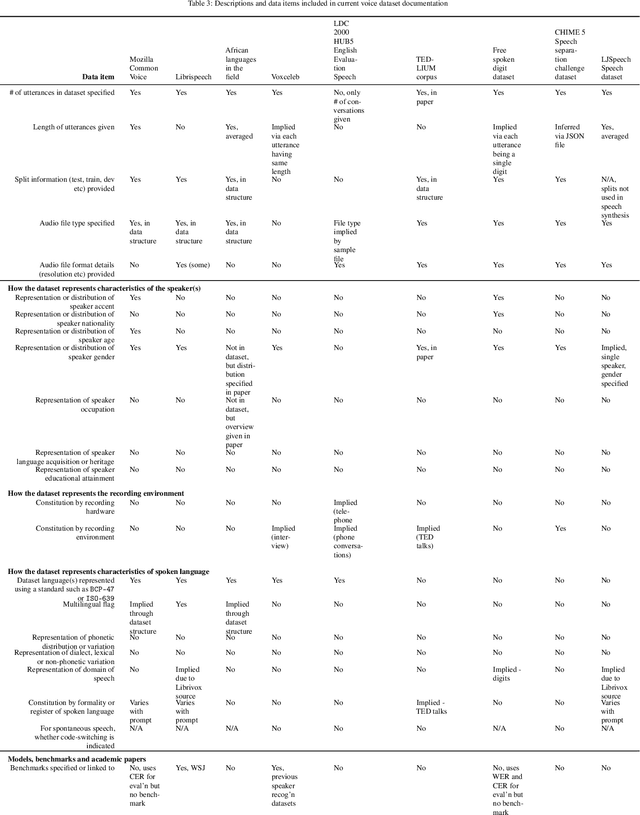
Voice-enabled technology is quickly becoming ubiquitous, and is constituted from machine learning (ML)-enabled components such as speech recognition and voice activity detection. However, these systems don't yet work well for everyone. They exhibit bias - the systematic and unfair discrimination against individuals or cohorts of individuals in favour of others (Friedman & Nissembaum, 1996) - across axes such as age, gender and accent. ML is reliant on large datasets for training. Dataset documentation is designed to give ML Practitioners (MLPs) a better understanding of a dataset's characteristics. However, there is a lack of empirical research on voice dataset documentation specifically. Additionally, while MLPs are frequent participants in fairness research, little work focuses on those who work with voice data. Our work makes an empirical contribution to this gap. Here, we combine two methods to form an exploratory study. First, we undertake 13 semi-structured interviews, exploring multiple perspectives of voice dataset documentation practice. Using open and axial coding methods, we explore MLPs' practices through the lenses of roles and tradeoffs. Drawing from this work, we then purposively sample voice dataset documents (VDDs) for 9 voice datasets. Our findings then triangulate these two methods, using the lenses of MLP roles and trade-offs. We find that current VDD practices are inchoate, inadequate and incommensurate. The characteristics of voice datasets are codified in fragmented, disjoint ways that often do not meet the needs of MLPs. Moreover, they cannot be readily compared, presenting a barrier to practitioners' bias reduction efforts. We then discuss the implications of these findings for bias practices in voice data and speech technologies. We conclude by setting out a program of future work to address these findings -- that is, how we may "right the docs".
Directed Speech Separation for Automatic Speech Recognition of Long Form Conversational Speech
Dec 10, 2021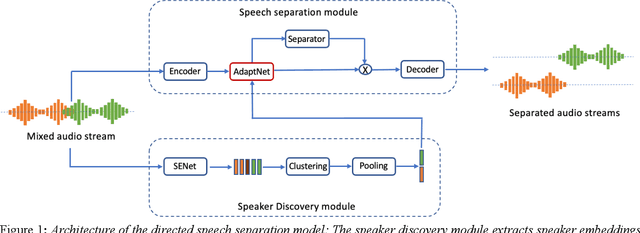
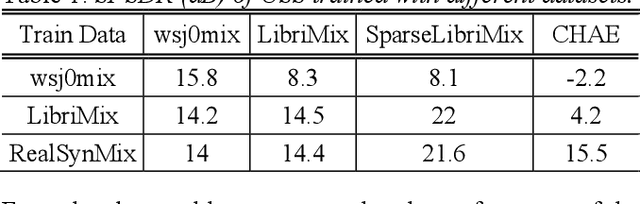
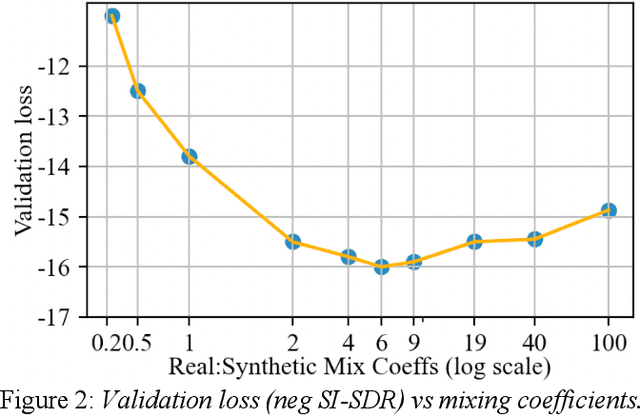

Many of the recent advances in speech separation are primarily aimed at synthetic mixtures of short audio utterances with high degrees of overlap. These datasets significantly differ from the real conversational data and hence, the models trained and evaluated on these datasets do not generalize to real conversational scenarios. Another issue with using most of these models for long form speech is the nondeterministic ordering of separated speech segments due to either unsupervised clustering for time-frequency masks or Permutation Invariant training (PIT) loss. This leads to difficulty in accurately stitching homogenous speaker segments for downstream tasks like Automatic Speech Recognition (ASR). In this paper, we propose a speaker conditioned separator trained on speaker embeddings extracted directly from the mixed signal. We train this model using a directed loss which regulates the order of the separated segments. With this model, we achieve significant improvements on Word error rate (WER) for real conversational data without the need for an additional re-stitching step.