 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Don't Be So Sure! Boosting ASR Decoding via Confidence Relaxation
Dec 27, 2022
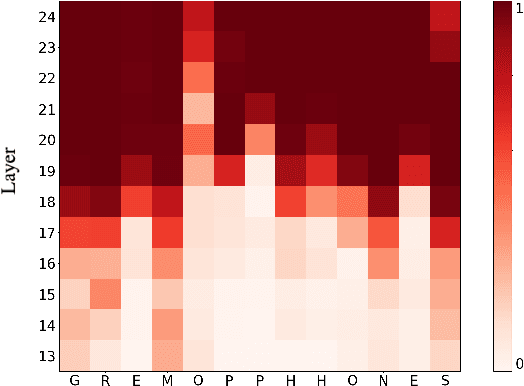

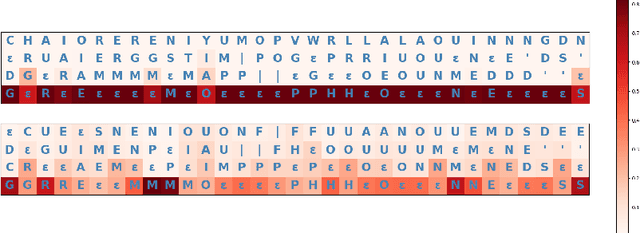
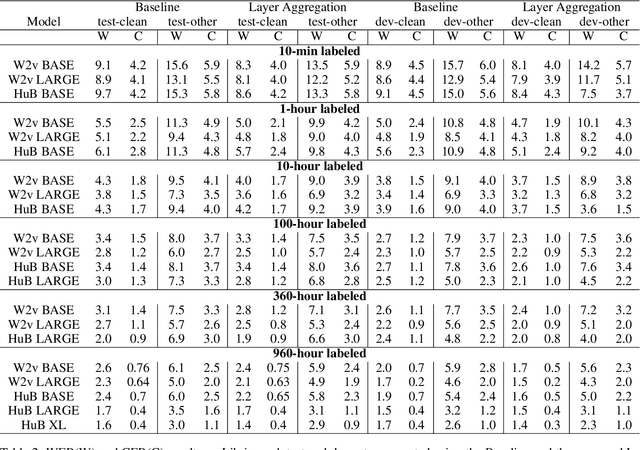
Automatic Speech Recognition (ASR) systems frequently use a search-based decoding strategy aiming to find the best attainable transcript by considering multiple candidates. One prominent speech recognition decoding heuristic is beam search, which seeks the transcript with the greatest likelihood computed using the predicted distribution. While showing substantial performance gains in various tasks, beam search loses some of its effectiveness when the predicted probabilities are highly confident, i.e., the predicted distribution is massed for a single or very few classes. We show that recently proposed Self-Supervised Learning (SSL)-based ASR models tend to yield exceptionally confident predictions that may hamper beam search from truly considering a diverse set of candidates. We perform a layer analysis to reveal and visualize how predictions evolve, and propose a decoding procedure that improves the performance of fine-tuned ASR models. Our proposed approach does not require further training beyond the original fine-tuning, nor additional model parameters. In fact, we find that our proposed method requires significantly less inference computation than current approaches. We propose aggregating the top M layers, potentially leveraging useful information encoded in intermediate layers, and relaxing model confidence. We demonstrate the effectiveness of our approach by conducting an empirical study on varying amounts of labeled resources and different model sizes, showing consistent improvements in particular when applied to low-resource scenarios.
Continual-wav2vec2: an Application of Continual Learning for Self-Supervised Automatic Speech Recognition
Jul 26, 2021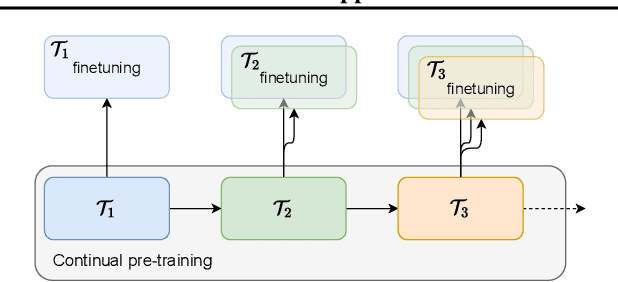
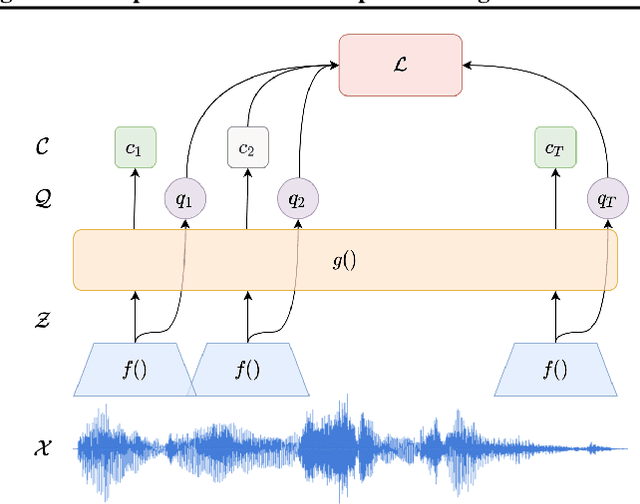
We present a method for continual learning of speech representations for multiple languages using self-supervised learning (SSL) and applying these for automatic speech recognition. There is an abundance of unannotated speech, so creating self-supervised representations from raw audio and finetuning on a small annotated datasets is a promising direction to build speech recognition systems. Wav2vec models perform SSL on raw audio in a pretraining phase and then finetune on a small fraction of annotated data. SSL models have produced state of the art results for ASR. However, these models are very expensive to pretrain with self-supervision. We tackle the problem of learning new language representations continually from audio without forgetting a previous language representation. We use ideas from continual learning to transfer knowledge from a previous task to speed up pretraining a new language task. Our continual-wav2vec2 model can decrease pretraining times by 32% when learning a new language task, and learn this new audio-language representation without forgetting previous language representation.
BrainBERT: Self-supervised representation learning for intracranial recordings
Feb 28, 2023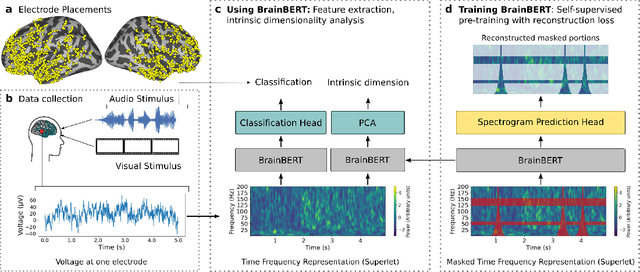
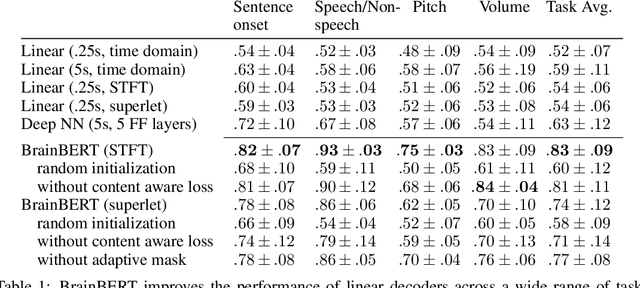
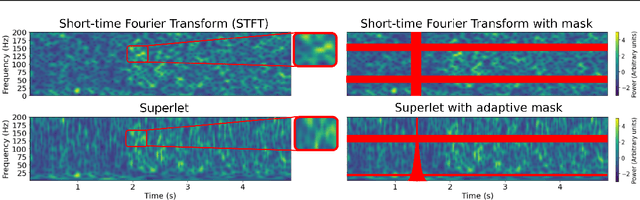
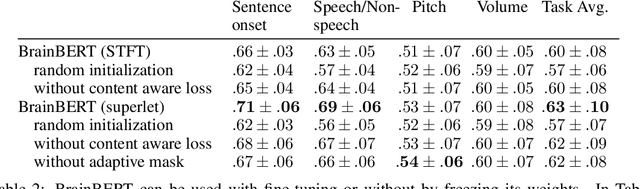
We create a reusable Transformer, BrainBERT, for intracranial recordings bringing modern representation learning approaches to neuroscience. Much like in NLP and speech recognition, this Transformer enables classifying complex concepts, i.e., decoding neural data, with higher accuracy and with much less data by being pretrained in an unsupervised manner on a large corpus of unannotated neural recordings. Our approach generalizes to new subjects with electrodes in new positions and to unrelated tasks showing that the representations robustly disentangle the neural signal. Just like in NLP where one can study language by investigating what a language model learns, this approach opens the door to investigating the brain by what a model of the brain learns. As a first step along this path, we demonstrate a new analysis of the intrinsic dimensionality of the computations in different areas of the brain. To construct these representations, we combine a technique for producing super-resolution spectrograms of neural data with an approach designed for generating contextual representations of audio by masking. In the future, far more concepts will be decodable from neural recordings by using representation learning, potentially unlocking the brain like language models unlocked language.
Practical Speech Recognition with HTK
Aug 06, 2019

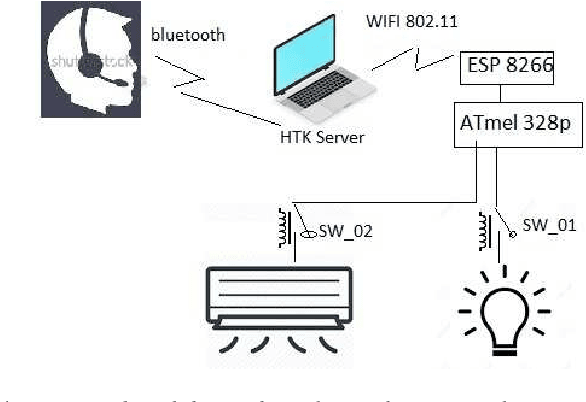

The practical aspects of developing an Automatic Speech Recognition System (ASR) with HTK are reviewed. Steps are explained concerning hardware, software, libraries, applications and computer programs used. The common procedure to rapidly apply speech recognition system is summarized. The procedure is illustrated, to implement a speech based electrical switch in home automation for the Indonesian language. The main key of the procedure is to match the environment for training and testing using the training data recorded from the testing program, HVite. Often the silence detector of HTK is wrongly triggered by noises because the microphone is too sensitive. This problem is mitigated by simply scaling down the volume. In this sub-word phone-based speech recognition, noise is included in the training database and labelled particularly. Illustration of the procedure is applied to a home automation application. Electrical switches are controlled by Indonesian speech recognizer. The results show 100% command completion rate.
SLUE Phase-2: A Benchmark Suite of Diverse Spoken Language Understanding Tasks
Dec 20, 2022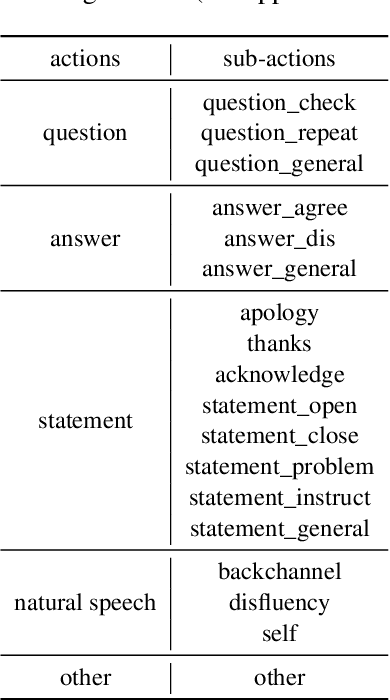
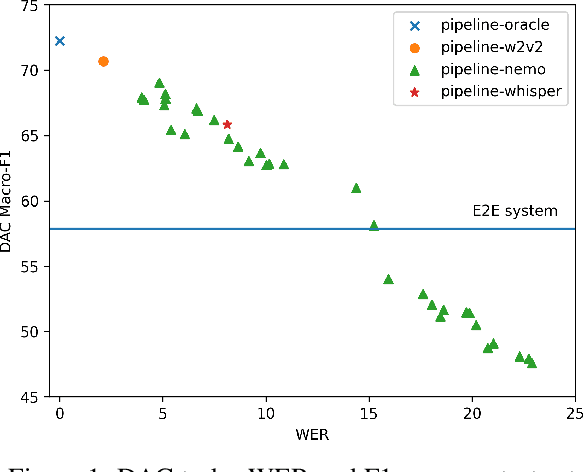
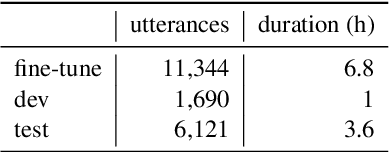
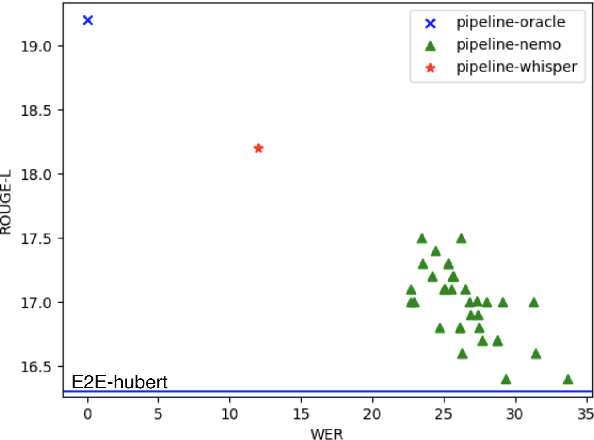
Spoken language understanding (SLU) tasks have been studied for many decades in the speech research community, but have not received as much attention as lower-level tasks like speech and speaker recognition. In particular, there are not nearly as many SLU task benchmarks, and many of the existing ones use data that is not freely available to all researchers. Recent work has begun to introduce such benchmark datasets for several tasks. In this work, we introduce several new annotated SLU benchmark tasks based on freely available speech data, which complement existing benchmarks and address gaps in the SLU evaluation landscape. We contribute four tasks: question answering and summarization involve inference over longer speech sequences; named entity localization addresses the speech-specific task of locating the targeted content in the signal; dialog act classification identifies the function of a given speech utterance. We follow the blueprint of the Spoken Language Understanding Evaluation (SLUE) benchmark suite. In order to facilitate the development of SLU models that leverage the success of pre-trained speech representations, we will be publishing for each task (i) annotations for a relatively small fine-tuning set, (ii) annotated development and test sets, and (iii) baseline models for easy reproducibility and comparisons. In this work, we present the details of data collection and annotation and the performance of the baseline models. We also perform sensitivity analysis of pipeline models' performance (speech recognizer + text model) to the speech recognition accuracy, using more than 20 state-of-the-art speech recognition models.
CiCo: Domain-Aware Sign Language Retrieval via Cross-Lingual Contrastive Learning
Mar 22, 2023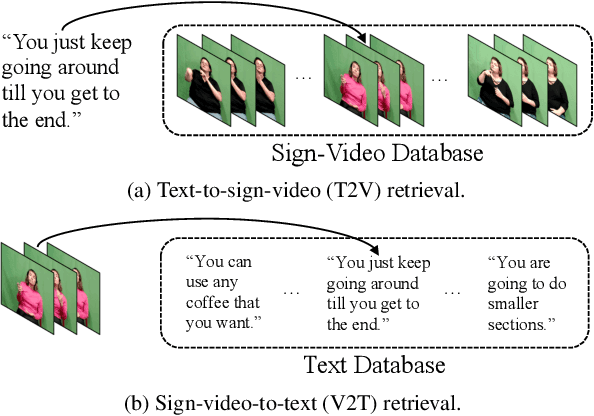
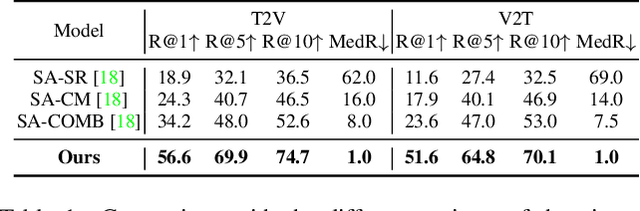


This work focuses on sign language retrieval-a recently proposed task for sign language understanding. Sign language retrieval consists of two sub-tasks: text-to-sign-video (T2V) retrieval and sign-video-to-text (V2T) retrieval. Different from traditional video-text retrieval, sign language videos, not only contain visual signals but also carry abundant semantic meanings by themselves due to the fact that sign languages are also natural languages. Considering this character, we formulate sign language retrieval as a cross-lingual retrieval problem as well as a video-text retrieval task. Concretely, we take into account the linguistic properties of both sign languages and natural languages, and simultaneously identify the fine-grained cross-lingual (i.e., sign-to-word) mappings while contrasting the texts and the sign videos in a joint embedding space. This process is termed as cross-lingual contrastive learning. Another challenge is raised by the data scarcity issue-sign language datasets are orders of magnitude smaller in scale than that of speech recognition. We alleviate this issue by adopting a domain-agnostic sign encoder pre-trained on large-scale sign videos into the target domain via pseudo-labeling. Our framework, termed as domain-aware sign language retrieval via Cross-lingual Contrastive learning or CiCo for short, outperforms the pioneering method by large margins on various datasets, e.g., +22.4 T2V and +28.0 V2T R@1 improvements on How2Sign dataset, and +13.7 T2V and +17.1 V2T R@1 improvements on PHOENIX-2014T dataset. Code and models are available at: https://github.com/FangyunWei/SLRT.
ASRPU: A Programmable Accelerator for Low-Power Automatic Speech Recognition
Feb 10, 2022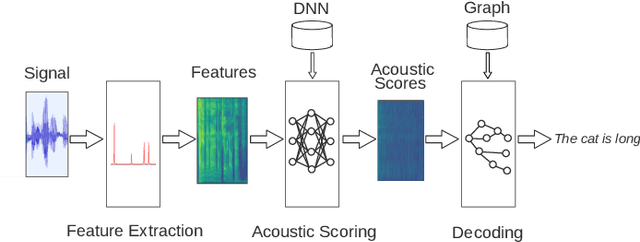

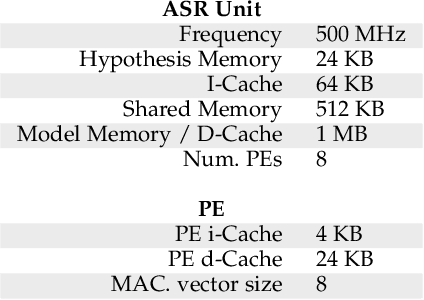
The outstanding accuracy achieved by modern Automatic Speech Recognition (ASR) systems is enabling them to quickly become a mainstream technology. ASR is essential for many applications, such as speech-based assistants, dictation systems and real-time language translation. However, highly accurate ASR systems are computationally expensive, requiring on the order of billions of arithmetic operations to decode each second of audio, which conflicts with a growing interest in deploying ASR on edge devices. On these devices, hardware acceleration is key for achieving acceptable performance. However, ASR is a rich and fast-changing field, and thus, any overly specialized hardware accelerator may quickly become obsolete. In this paper, we tackle those challenges by proposing ASRPU, a programmable accelerator for on-edge ASR. ASRPU contains a pool of general-purpose cores that execute small pieces of parallel code. Each of these programs computes one part of the overall decoder (e.g. a layer in a neural network). The accelerator automates some carefully chosen parts of the decoder to simplify the programming without sacrificing generality. We provide an analysis of a modern ASR system implemented on ASRPU and show that this architecture can achieve real-time decoding with a very low power budget.
DENT-DDSP: Data-efficient noisy speech generator using differentiable digital signal processors for explicit distortion modelling and noise-robust speech recognition
Aug 01, 2022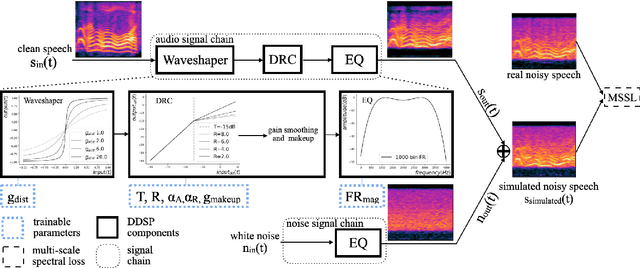
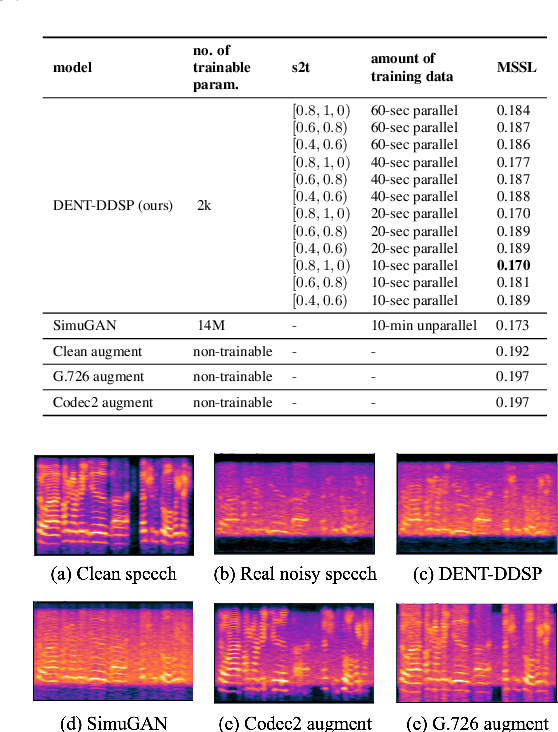
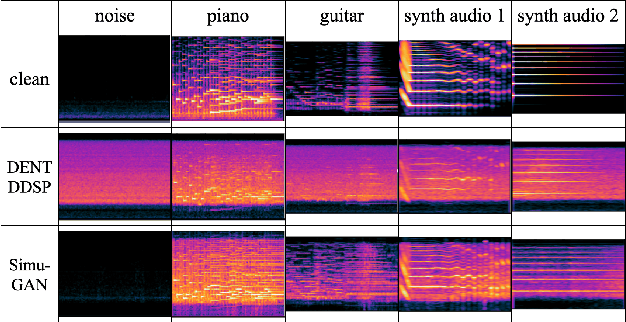
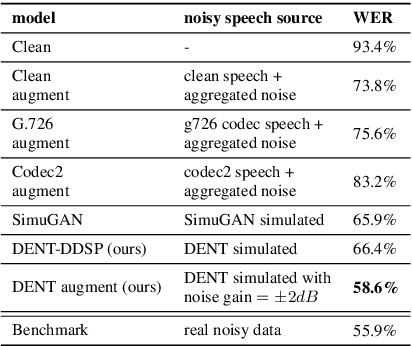
The performances of automatic speech recognition (ASR) systems degrade drastically under noisy conditions. Explicit distortion modelling (EDM), as a feature compensation step, is able to enhance ASR systems under such conditions by simulating the in-domain noisy speeches from the clean counterparts. Yet, existing distortion models are either non-trainable or unexplainable and often lack controllability and generalization ability. In this paper, we propose a fully explainable and controllable model: DENT-DDSP to achieve EDM. DENT-DDSP utilizes novel differentiable digital signal processing (DDSP) components and requires only 10 seconds of training data to achieve high fidelity. The experiment shows that the simulated noisy data from DENT-DDSP achieves the highest simulation fidelity compared to other baseline models in terms of multi-scale spectral loss (MSSL). Moreover, to validate whether the data simulated by DENT-DDSP are able to replace the scarce in-domain noisy data in the noise-robust ASR tasks, several downstream ASR models with the same architecture are trained using the simulated data and the real data. The experiment shows that the model trained with the simulated noisy data from DENT-DDSP achieves similar performances to the benchmark with a 2.7\% difference in terms of word error rate (WER). The code of the model is released online.
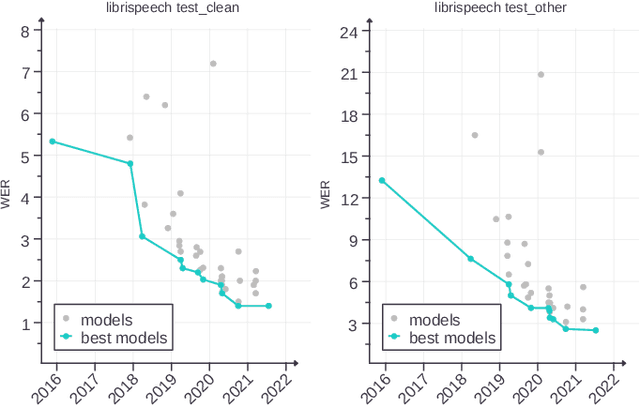
Robust Speech Recognition via Large-Scale Weak Supervision
Dec 06, 2022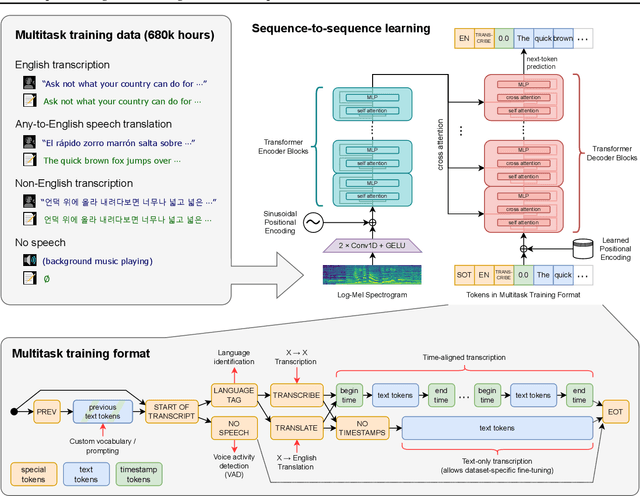
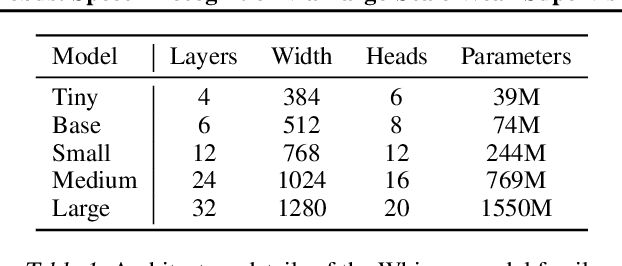
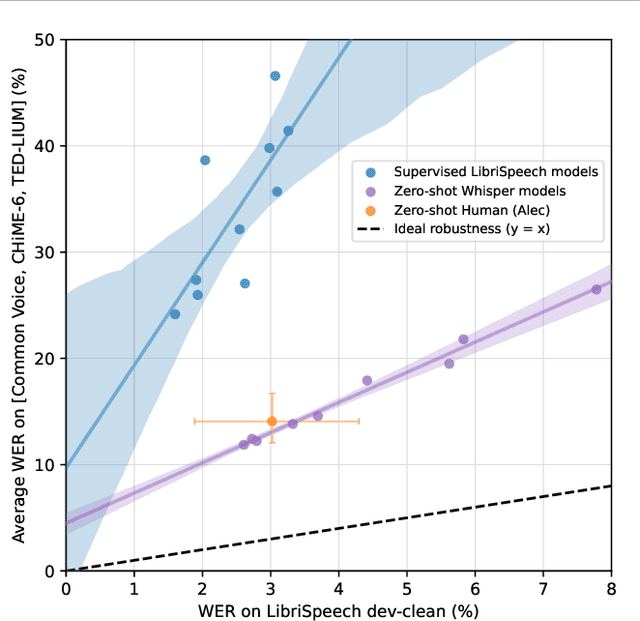
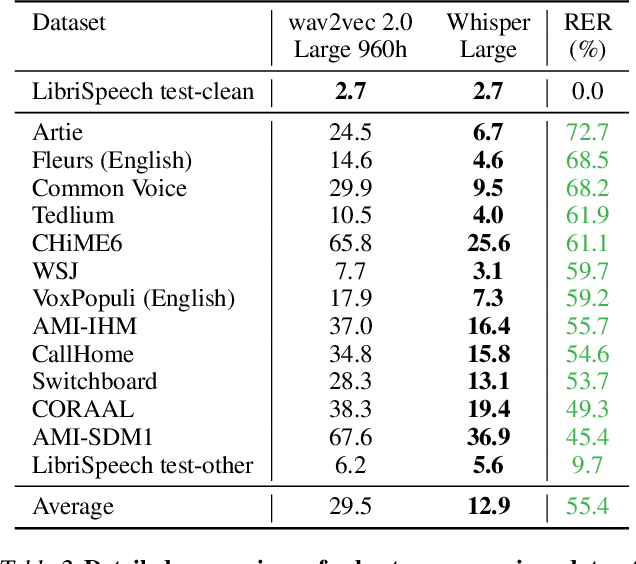
We study the capabilities of speech processing systems trained simply to predict large amounts of transcripts of audio on the internet. When scaled to 680,000 hours of multilingual and multitask supervision, the resulting models generalize well to standard benchmarks and are often competitive with prior fully supervised results but in a zero-shot transfer setting without the need for any fine-tuning. When compared to humans, the models approach their accuracy and robustness. We are releasing models and inference code to serve as a foundation for further work on robust speech processing.
Audio-Visual Speech Recognition is Worth 32$\times$32$\times$8 Voxels
Sep 20, 2021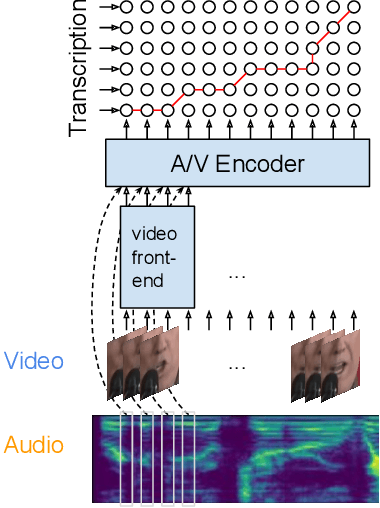

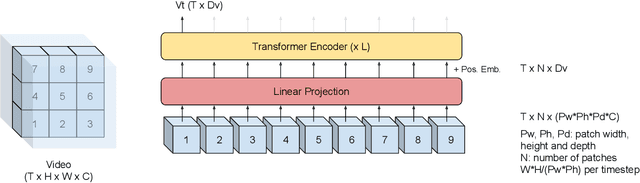
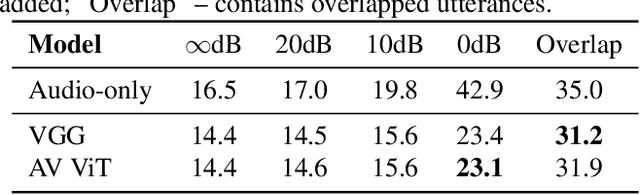
Audio-visual automatic speech recognition (AV-ASR) introduces the video modality into the speech recognition process, often by relying on information conveyed by the motion of the speaker's mouth. The use of the video signal requires extracting visual features, which are then combined with the acoustic features to build an AV-ASR system [1]. This is traditionally done with some form of 3D convolutional network (e.g. VGG) as widely used in the computer vision community. Recently, image transformers [2] have been introduced to extract visual features useful for image classification tasks. In this work, we propose to replace the 3D convolutional visual front-end with a video transformer front-end. We train our systems on a large-scale dataset composed of YouTube videos and evaluate performance on the publicly available LRS3-TED set, as well as on a large set of YouTube videos. On a lip-reading task, the transformer-based front-end shows superior performance compared to a strong convolutional baseline. On an AV-ASR task, the transformer front-end performs as well as (or better than) the convolutional baseline. Fine-tuning our model on the LRS3-TED training set matches previous state of the art. Thus, we experimentally show the viability of the convolution-free model for AV-ASR.