 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Impact of Dataset on Acoustic Models for Automatic Speech Recognition
Mar 25, 2022
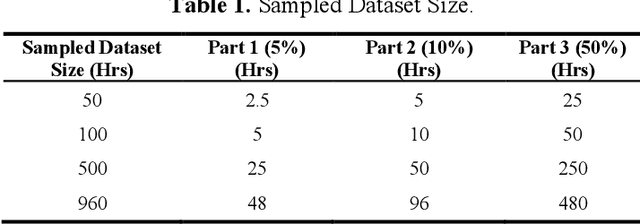
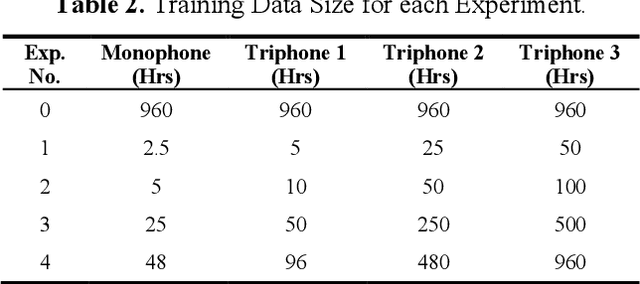
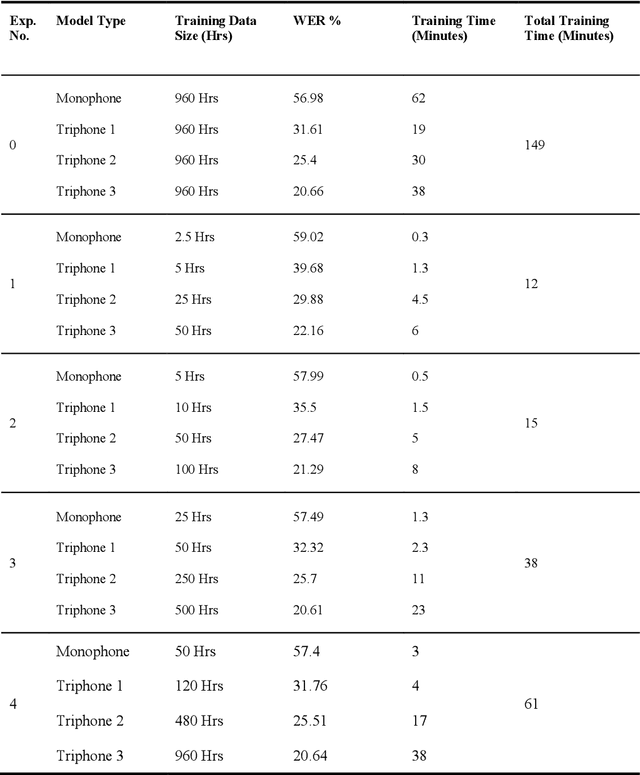
In Automatic Speech Recognition, GMM-HMM had been widely used for acoustic modelling. With the current advancement of deep learning, the Gaussian Mixture Model (GMM) from acoustic models has been replaced with Deep Neural Network, namely DNN-HMM Acoustic Models. The GMM models are widely used to create the alignments of the training data for the hybrid deep neural network model, thus making it an important task to create accurate alignments. Many factors such as training dataset size, training data augmentation, model hyperparameters, etc., affect the model learning. Traditionally in machine learning, larger datasets tend to have better performance, while smaller datasets tend to trigger over-fitting. The collection of speech data and their accurate transcriptions is a significant challenge that varies over different languages, and in most cases, it might be limited to big organizations. Moreover, in the case of available large datasets, training a model using such data requires additional time and computing resources, which may not be available. While the data about the accuracy of state-of-the-art ASR models on open-source datasets are published, the study about the impact of the size of a dataset on acoustic models is not readily available. This work aims to investigate the impact of dataset size variations on the performance of various GMM-HMM Acoustic Models and their respective computational costs.
Adding Connectionist Temporal Summarization into Conformer to Improve Its Decoder Efficiency For Speech Recognition
Apr 08, 2022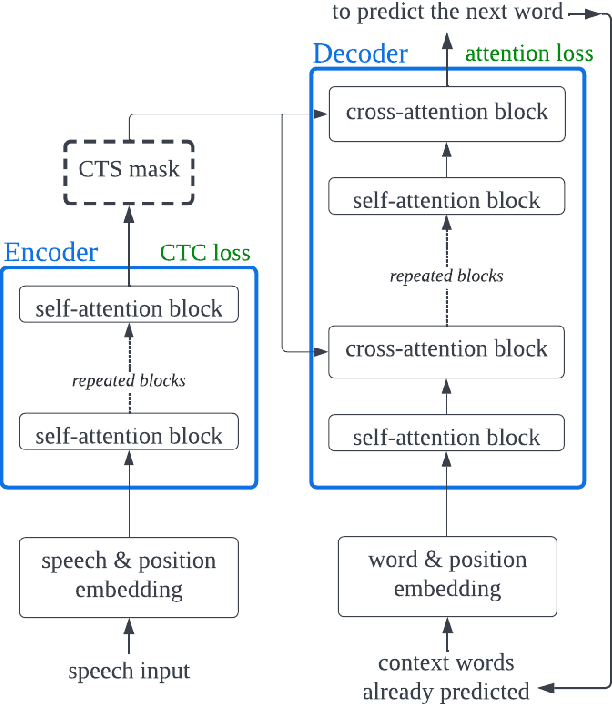
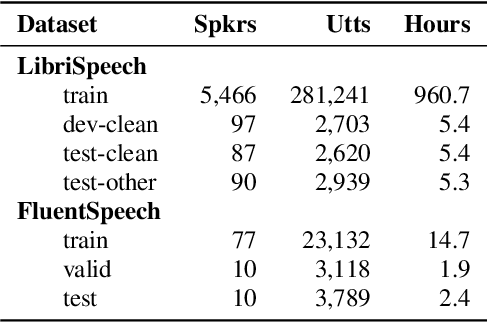
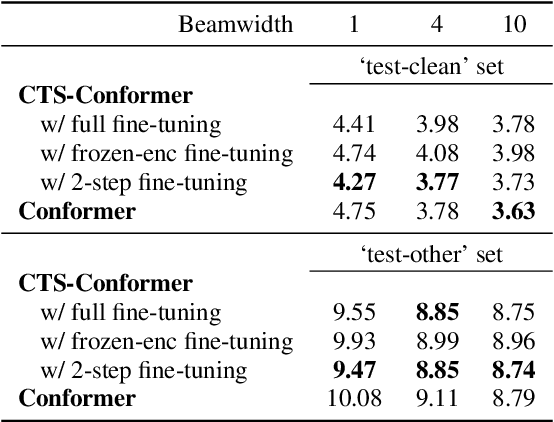

The Conformer model is an excellent architecture for speech recognition modeling that effectively utilizes the hybrid losses of connectionist temporal classification (CTC) and attention to train model parameters. To improve the decoding efficiency of Conformer, we propose a novel connectionist temporal summarization (CTS) method that reduces the number of frames required for the attention decoder fed from the acoustic sequences generated by the encoder, thus reducing operations. However, to achieve such decoding improvements, we must fine-tune model parameters, as cross-attention observations are changed and thus require corresponding refinements. Our final experiments show that, with a beamwidth of 4, the LibriSpeech's decoding budget can be reduced by up to 20% and for FluentSpeech data it can be reduced by 11%, without losing ASR accuracy. An improvement in accuracy is even found for the LibriSpeech "test-other" set. The word error rate (WER) is reduced by 6\% relative at the beam width of 1 and by 3% relative at the beam width of 4.
Discovering Phonetic Inventories with Crosslingual Automatic Speech Recognition
Jan 26, 2022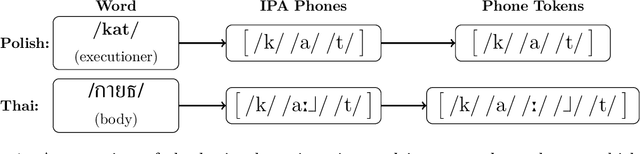
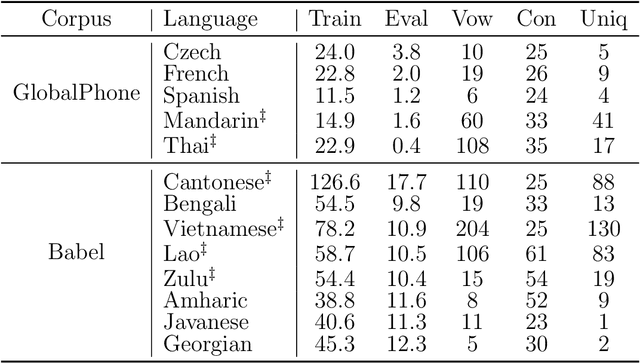
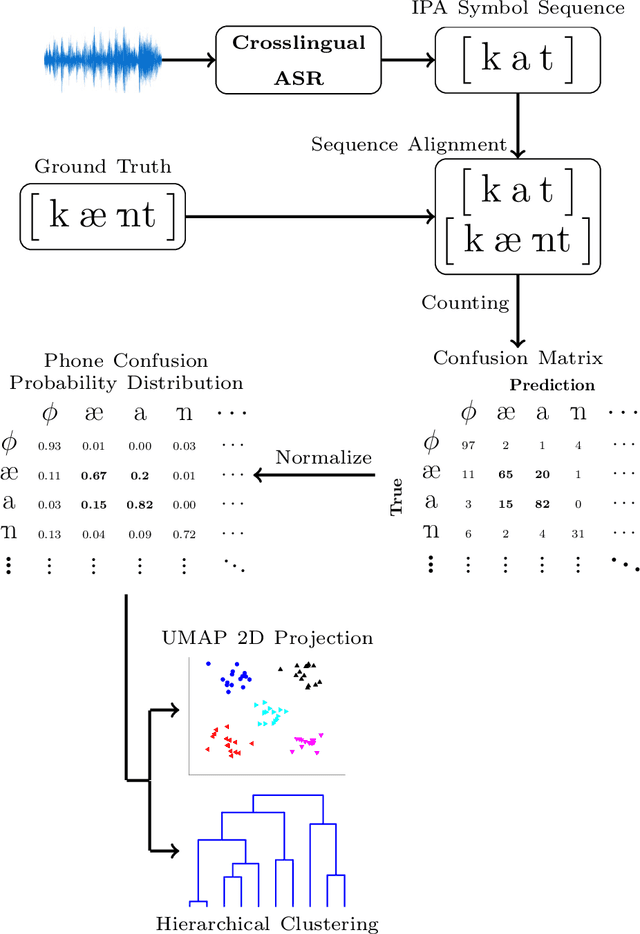
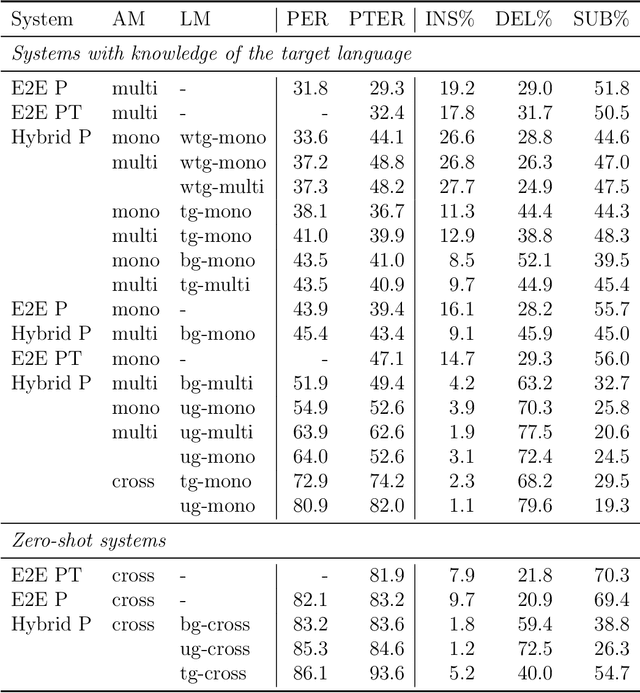
The high cost of data acquisition makes Automatic Speech Recognition (ASR) model training problematic for most existing languages, including languages that do not even have a written script, or for which the phone inventories remain unknown. Past works explored multilingual training, transfer learning, as well as zero-shot learning in order to build ASR systems for these low-resource languages. While it has been shown that the pooling of resources from multiple languages is helpful, we have not yet seen a successful application of an ASR model to a language unseen during training. A crucial step in the adaptation of ASR from seen to unseen languages is the creation of the phone inventory of the unseen language. The ultimate goal of our work is to build the phone inventory of a language unseen during training in an unsupervised way without any knowledge about the language. In this paper, we 1) investigate the influence of different factors (i.e., model architecture, phonotactic model, type of speech representation) on phone recognition in an unknown language; 2) provide an analysis of which phones transfer well across languages and which do not in order to understand the limitations of and areas for further improvement for automatic phone inventory creation; and 3) present different methods to build a phone inventory of an unseen language in an unsupervised way. To that end, we conducted mono-, multi-, and crosslingual experiments on a set of 13 phonetically diverse languages and several in-depth analyses. We found a number of universal phone tokens (IPA symbols) that are well-recognized cross-linguistically. Through a detailed analysis of results, we conclude that unique sounds, similar sounds, and tone languages remain a major challenge for phonetic inventory discovery.
Speaker Change Detection for Transformer Transducer ASR
Feb 16, 2023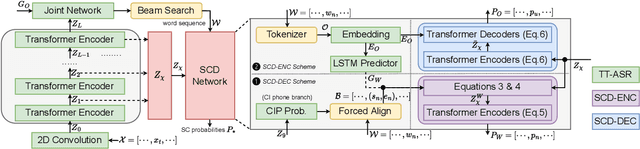
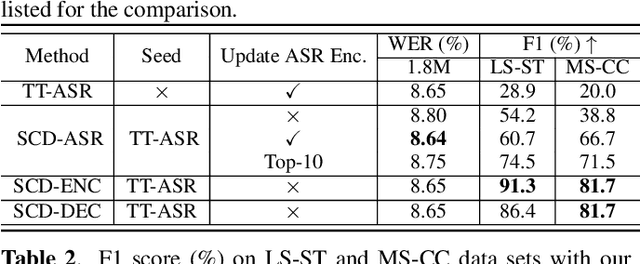
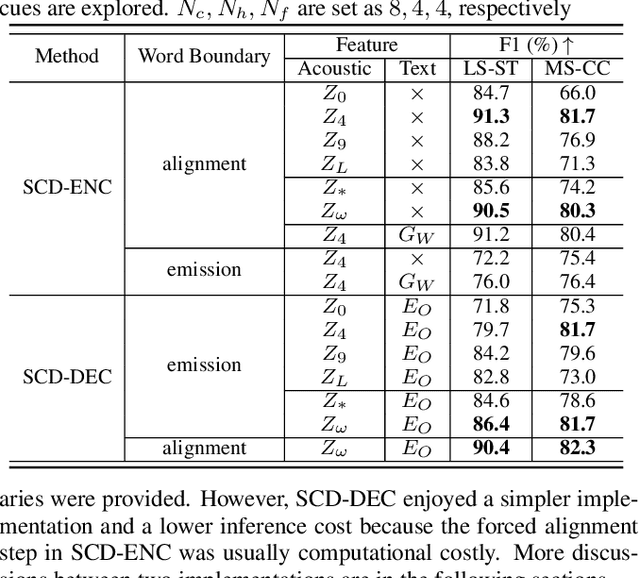
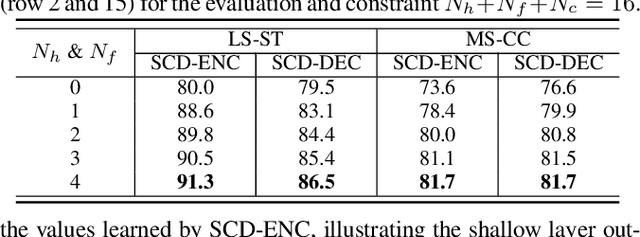
Speaker change detection (SCD) is an important feature that improves the readability of the recognized words from an automatic speech recognition (ASR) system by breaking the word sequence into paragraphs at speaker change points. Existing SCD solutions either require additional ensemble for the time based decisions and recognized word sequences, or implement a tight integration between ASR and SCD, limiting the potential optimum performance for both tasks. To address these issues, we propose a novel framework for the SCD task, where an additional SCD module is built on top of an existing Transformer Transducer ASR (TT-ASR) network. Two variants of the SCD network are explored in this framework that naturally estimate speaker change probability for each word, while allowing the ASR and SCD to have independent optimization scheme for the best performance. Experiments show that our methods can significantly improve the F1 score on LibriCSS and Microsoft call center data sets without ASR degradation, compared with a joint SCD and ASR baseline.
Robustifying automatic speech recognition by extracting slowly varying features
Dec 14, 2021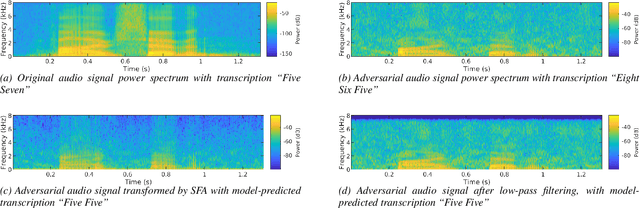
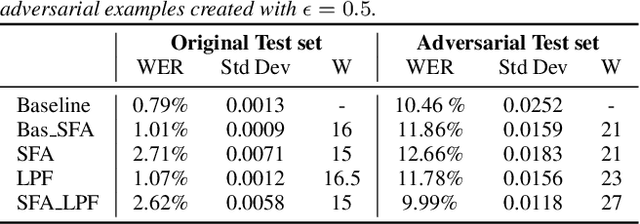
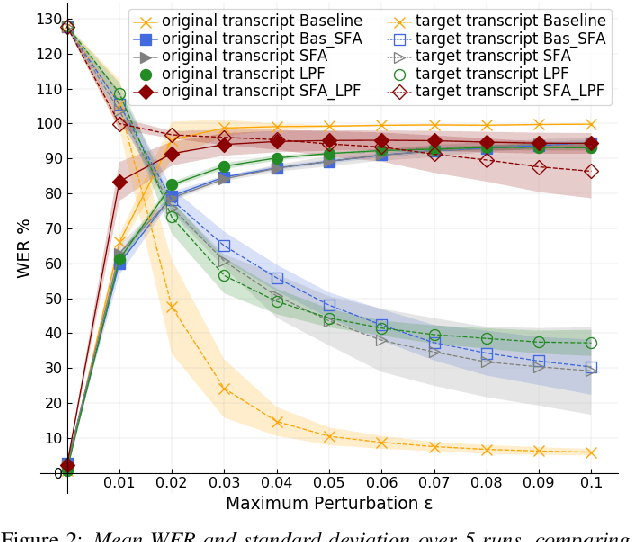
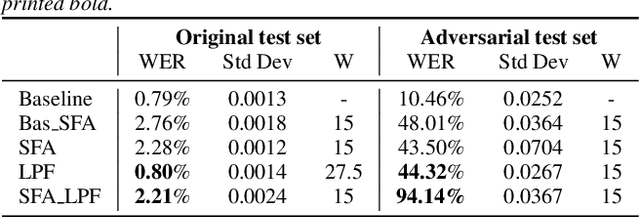
In the past few years, it has been shown that deep learning systems are highly vulnerable under attacks with adversarial examples. Neural-network-based automatic speech recognition (ASR) systems are no exception. Targeted and untargeted attacks can modify an audio input signal in such a way that humans still recognise the same words, while ASR systems are steered to predict a different transcription. In this paper, we propose a defense mechanism against targeted adversarial attacks consisting in removing fast-changing features from the audio signals, either by applying slow feature analysis, a low-pass filter, or both, before feeding the input to the ASR system. We perform an empirical analysis of hybrid ASR models trained on data pre-processed in such a way. While the resulting models perform quite well on benign data, they are significantly more robust against targeted adversarial attacks: Our final, proposed model shows a performance on clean data similar to the baseline model, while being more than four times more robust.
MixSpeech: Data Augmentation for Low-resource Automatic Speech Recognition
Feb 25, 2021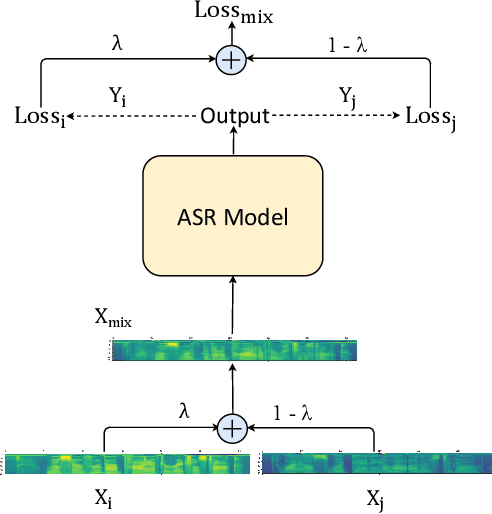

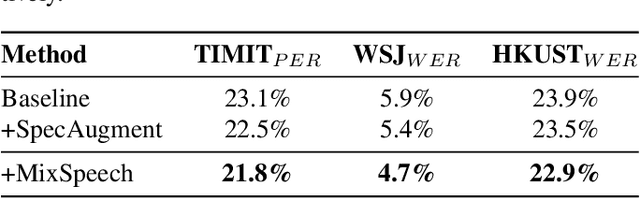
In this paper, we propose MixSpeech, a simple yet effective data augmentation method based on mixup for automatic speech recognition (ASR). MixSpeech trains an ASR model by taking a weighted combination of two different speech features (e.g., mel-spectrograms or MFCC) as the input, and recognizing both text sequences, where the two recognition losses use the same combination weight. We apply MixSpeech on two popular end-to-end speech recognition models including LAS (Listen, Attend and Spell) and Transformer, and conduct experiments on several low-resource datasets including TIMIT, WSJ, and HKUST. Experimental results show that MixSpeech achieves better accuracy than the baseline models without data augmentation, and outperforms a strong data augmentation method SpecAugment on these recognition tasks. Specifically, MixSpeech outperforms SpecAugment with a relative PER improvement of 10.6$\%$ on TIMIT dataset, and achieves a strong WER of 4.7$\%$ on WSJ dataset.
Recent Advances in End-to-End Automatic Speech Recognition
Nov 02, 2021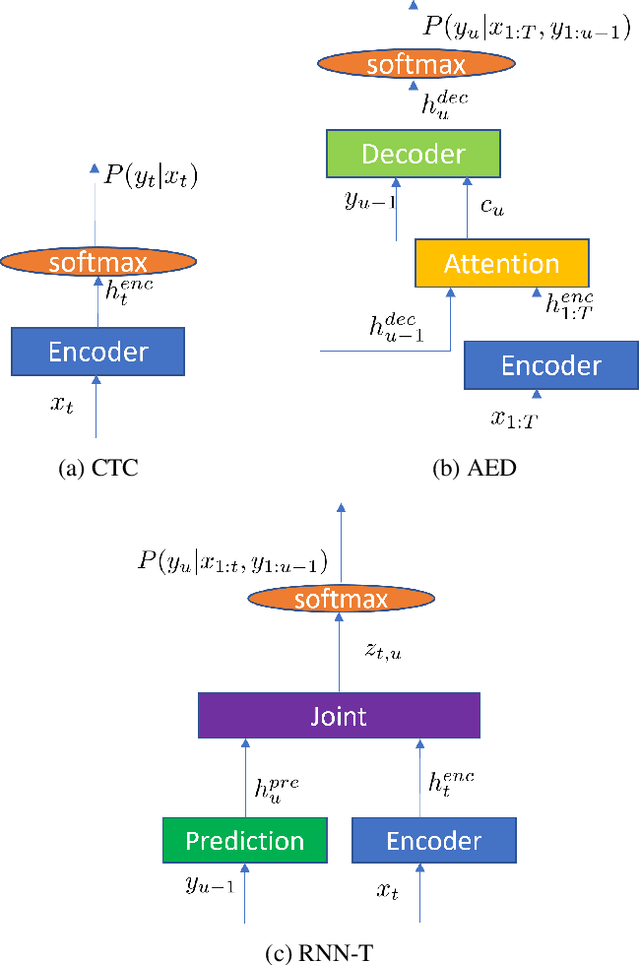
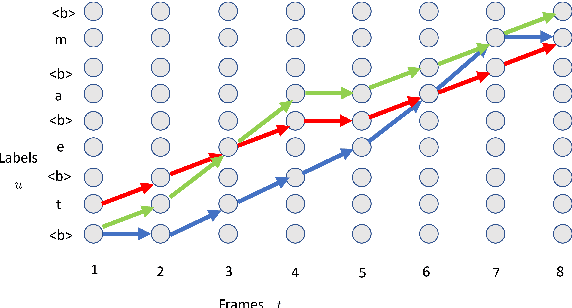

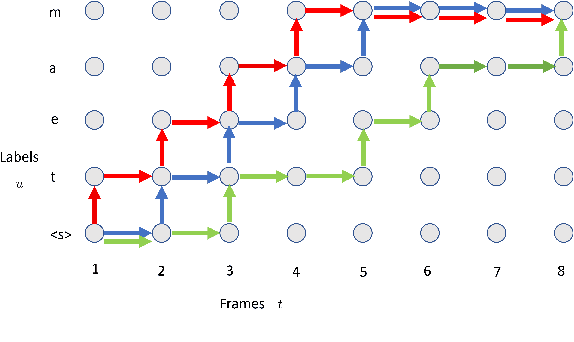
Recently, the speech community is seeing a significant trend of moving from deep neural network based hybrid modeling to end-to-end (E2E) modeling for automatic speech recognition (ASR). While E2E models achieve the state-of-the-art results in most benchmarks in terms of ASR accuracy, hybrid models are still used in a large proportion of commercial ASR systems at the current time. There are lots of practical factors that affect the production model deployment decision. Traditional hybrid models, being optimized for production for decades, are usually good at these factors. Without providing excellent solutions to all these factors, it is hard for E2E models to be widely commercialized. In this paper, we will overview the recent advances in E2E models, focusing on technologies addressing those challenges from the industry's perspective.
MSAT: Biologically Inspired Multi-Stage Adaptive Threshold for Conversion of Spiking Neural Networks
Mar 23, 2023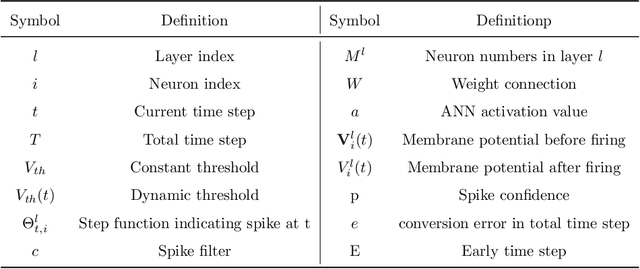
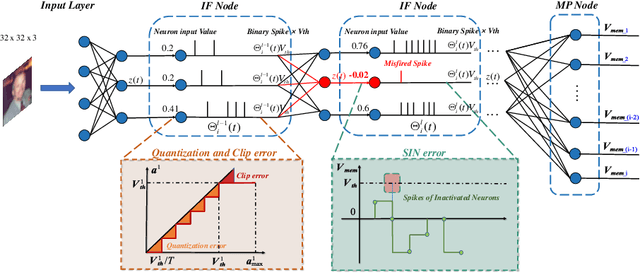
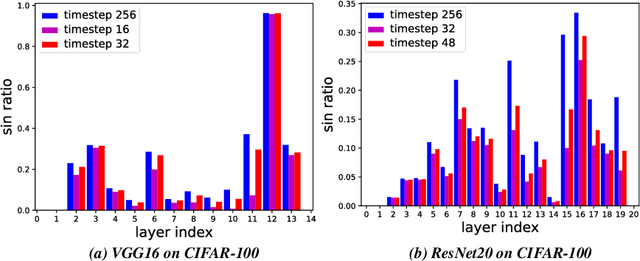
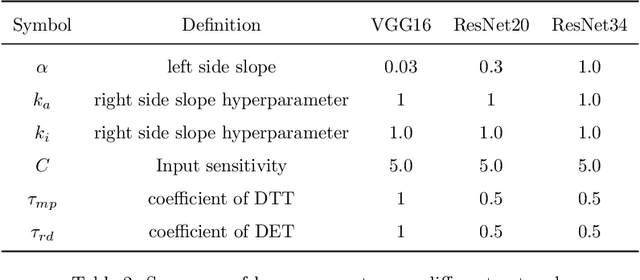
Spiking Neural Networks (SNNs) can do inference with low power consumption due to their spike sparsity. ANN-SNN conversion is an efficient way to achieve deep SNNs by converting well-trained Artificial Neural Networks (ANNs). However, the existing methods commonly use constant threshold for conversion, which prevents neurons from rapidly delivering spikes to deeper layers and causes high time delay. In addition, the same response for different inputs may result in information loss during the information transmission. Inspired by the biological model mechanism, we propose a multi-stage adaptive threshold (MSAT). Specifically, for each neuron, the dynamic threshold varies with firing history and input properties and is positively correlated with the average membrane potential and negatively correlated with the rate of depolarization. The self-adaptation to membrane potential and input allows a timely adjustment of the threshold to fire spike faster and transmit more information. Moreover, we analyze the Spikes of Inactivated Neurons error which is pervasive in early time steps and propose spike confidence accordingly as a measurement of confidence about the neurons that correctly deliver spikes. We use such spike confidence in early time steps to determine whether to elicit spike to alleviate this error. Combined with the proposed method, we examine the performance on non-trivial datasets CIFAR-10, CIFAR-100, and ImageNet. We also conduct sentiment classification and speech recognition experiments on the IDBM and Google speech commands datasets respectively. Experiments show near-lossless and lower latency ANN-SNN conversion. To the best of our knowledge, this is the first time to build a biologically inspired multi-stage adaptive threshold for converted SNN, with comparable performance to state-of-the-art methods while improving energy efficiency.
Don't Be So Sure! Boosting ASR Decoding via Confidence Relaxation
Dec 27, 2022

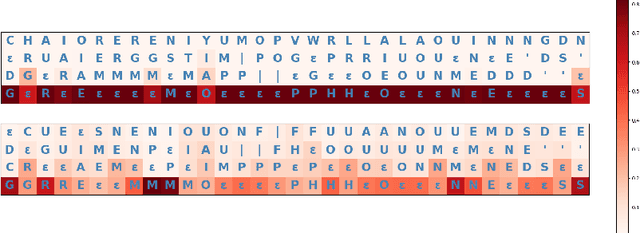
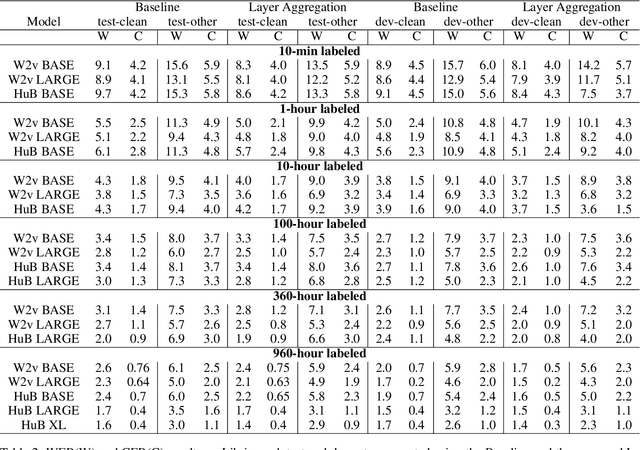
Automatic Speech Recognition (ASR) systems frequently use a search-based decoding strategy aiming to find the best attainable transcript by considering multiple candidates. One prominent speech recognition decoding heuristic is beam search, which seeks the transcript with the greatest likelihood computed using the predicted distribution. While showing substantial performance gains in various tasks, beam search loses some of its effectiveness when the predicted probabilities are highly confident, i.e., the predicted distribution is massed for a single or very few classes. We show that recently proposed Self-Supervised Learning (SSL)-based ASR models tend to yield exceptionally confident predictions that may hamper beam search from truly considering a diverse set of candidates. We perform a layer analysis to reveal and visualize how predictions evolve, and propose a decoding procedure that improves the performance of fine-tuned ASR models. Our proposed approach does not require further training beyond the original fine-tuning, nor additional model parameters. In fact, we find that our proposed method requires significantly less inference computation than current approaches. We propose aggregating the top M layers, potentially leveraging useful information encoded in intermediate layers, and relaxing model confidence. We demonstrate the effectiveness of our approach by conducting an empirical study on varying amounts of labeled resources and different model sizes, showing consistent improvements in particular when applied to low-resource scenarios.
Leveraging Unimodal Self-Supervised Learning for Multimodal Audio-Visual Speech Recognition
Mar 26, 2022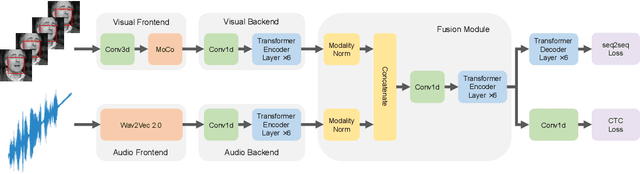
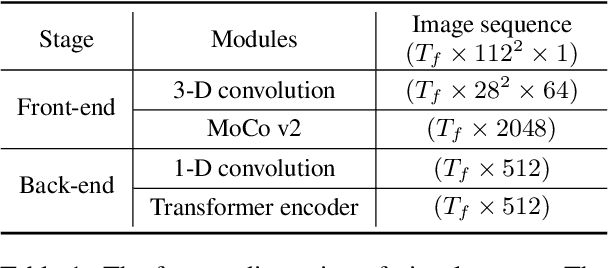


Training Transformer-based models demands a large amount of data, while obtaining aligned and labelled data in multimodality is rather cost-demanding, especially for audio-visual speech recognition (AVSR). Thus it makes a lot of sense to make use of unlabelled unimodal data. On the other side, although the effectiveness of large-scale self-supervised learning is well established in both audio and visual modalities, how to integrate those pre-trained models into a multimodal scenario remains underexplored. In this work, we successfully leverage unimodal self-supervised learning to promote the multimodal AVSR. In particular, audio and visual front-ends are trained on large-scale unimodal datasets, then we integrate components of both front-ends into a larger multimodal framework which learns to recognize parallel audio-visual data into characters through a combination of CTC and seq2seq decoding. We show that both components inherited from unimodal self-supervised learning cooperate well, resulting in that the multimodal framework yields competitive results through fine-tuning. Our model is experimentally validated on both word-level and sentence-level tasks. Especially, even without an external language model, our proposed model raises the state-of-the-art performances on the widely accepted Lip Reading Sentences 2 (LRS2) dataset by a large margin, with a relative improvement of 30%.