 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
MSAT: Biologically Inspired Multi-Stage Adaptive Threshold for Conversion of Spiking Neural Networks
Mar 23, 2023
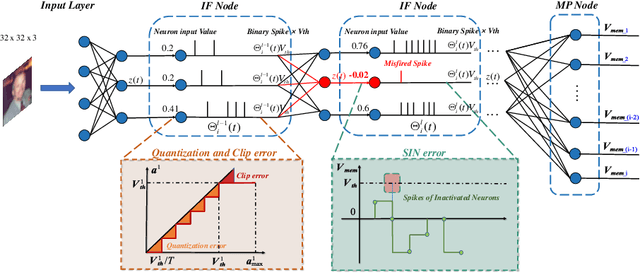
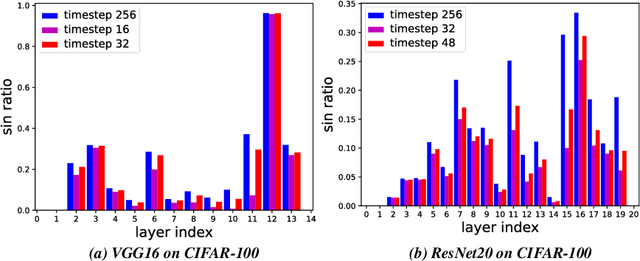
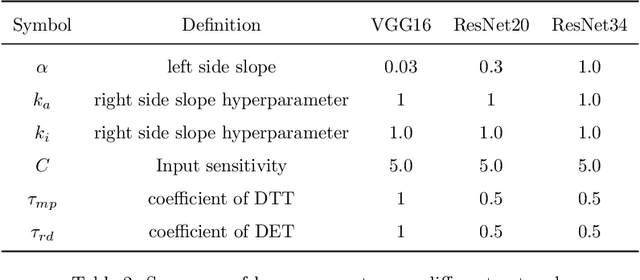
Spiking Neural Networks (SNNs) can do inference with low power consumption due to their spike sparsity. ANN-SNN conversion is an efficient way to achieve deep SNNs by converting well-trained Artificial Neural Networks (ANNs). However, the existing methods commonly use constant threshold for conversion, which prevents neurons from rapidly delivering spikes to deeper layers and causes high time delay. In addition, the same response for different inputs may result in information loss during the information transmission. Inspired by the biological model mechanism, we propose a multi-stage adaptive threshold (MSAT). Specifically, for each neuron, the dynamic threshold varies with firing history and input properties and is positively correlated with the average membrane potential and negatively correlated with the rate of depolarization. The self-adaptation to membrane potential and input allows a timely adjustment of the threshold to fire spike faster and transmit more information. Moreover, we analyze the Spikes of Inactivated Neurons error which is pervasive in early time steps and propose spike confidence accordingly as a measurement of confidence about the neurons that correctly deliver spikes. We use such spike confidence in early time steps to determine whether to elicit spike to alleviate this error. Combined with the proposed method, we examine the performance on non-trivial datasets CIFAR-10, CIFAR-100, and ImageNet. We also conduct sentiment classification and speech recognition experiments on the IDBM and Google speech commands datasets respectively. Experiments show near-lossless and lower latency ANN-SNN conversion. To the best of our knowledge, this is the first time to build a biologically inspired multi-stage adaptive threshold for converted SNN, with comparable performance to state-of-the-art methods while improving energy efficiency.
Context-Aware Transformer Transducer for Speech Recognition
Nov 05, 2021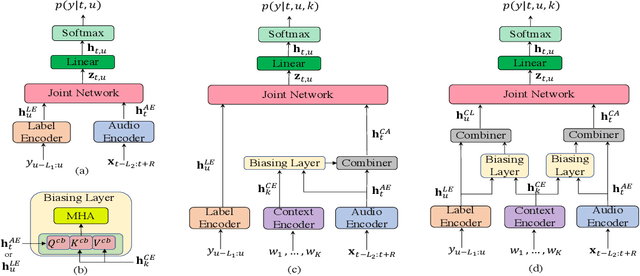

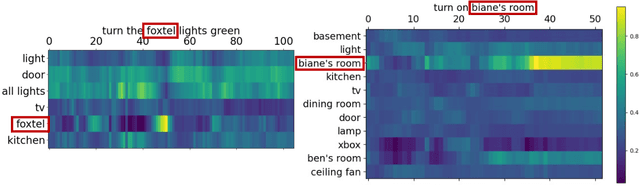
End-to-end (E2E) automatic speech recognition (ASR) systems often have difficulty recognizing uncommon words, that appear infrequently in the training data. One promising method, to improve the recognition accuracy on such rare words, is to latch onto personalized/contextual information at inference. In this work, we present a novel context-aware transformer transducer (CATT) network that improves the state-of-the-art transformer-based ASR system by taking advantage of such contextual signals. Specifically, we propose a multi-head attention-based context-biasing network, which is jointly trained with the rest of the ASR sub-networks. We explore different techniques to encode contextual data and to create the final attention context vectors. We also leverage both BLSTM and pretrained BERT based models to encode contextual data and guide the network training. Using an in-house far-field dataset, we show that CATT, using a BERT based context encoder, improves the word error rate of the baseline transformer transducer and outperforms an existing deep contextual model by 24.2% and 19.4% respectively.
WeNet: Production First and Production Ready End-to-End Speech Recognition Toolkit
Feb 02, 2021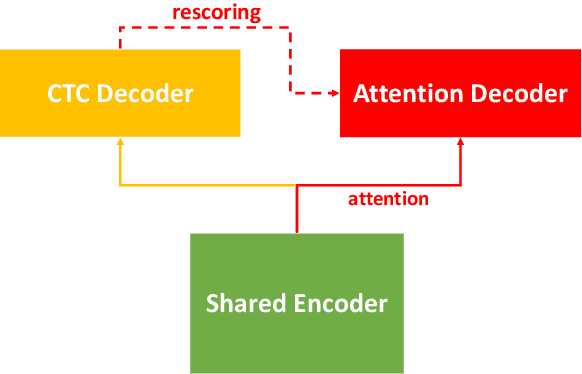
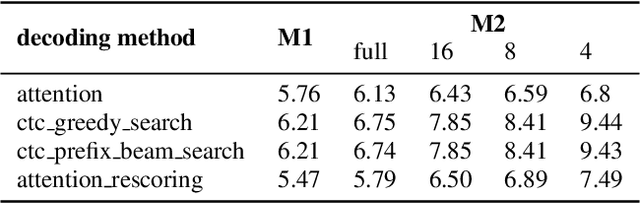
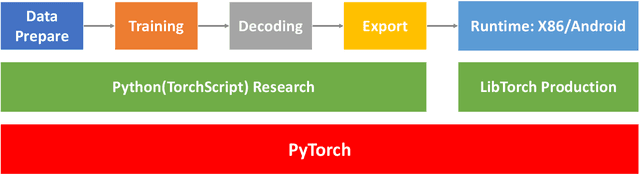
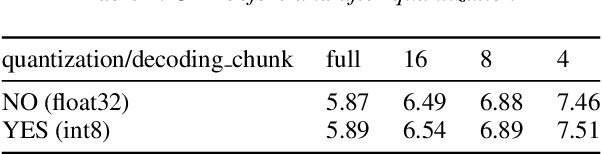
In this paper, we present a new open source, production first and production ready end-to-end (E2E) speech recognition toolkit named WeNet. The main motivation of WeNet is to close the gap between the research and the production of E2E speech recognition models. WeNet provides an efficient way to ship ASR applications in several real-world scenarios, which is the main difference and advantage to other open source E2E speech recognition toolkits. This paper introduces WeNet from three aspects, including model architecture, framework design and performance metrics. Our experiments on AISHELL-1 using WeNet, not only give a promising character error rate (CER) on a unified streaming and non-streaming two pass (U2) E2E model but also show reasonable RTF and latency, both of these aspects are favored for production adoption. The toolkit is publicly available at https://github.com/mobvoi/wenet.
Impact of Dataset on Acoustic Models for Automatic Speech Recognition
Mar 25, 2022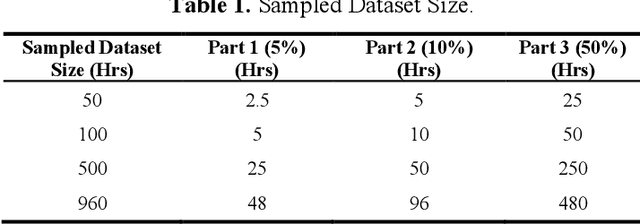
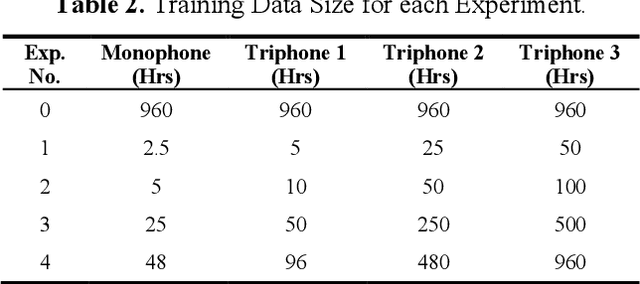
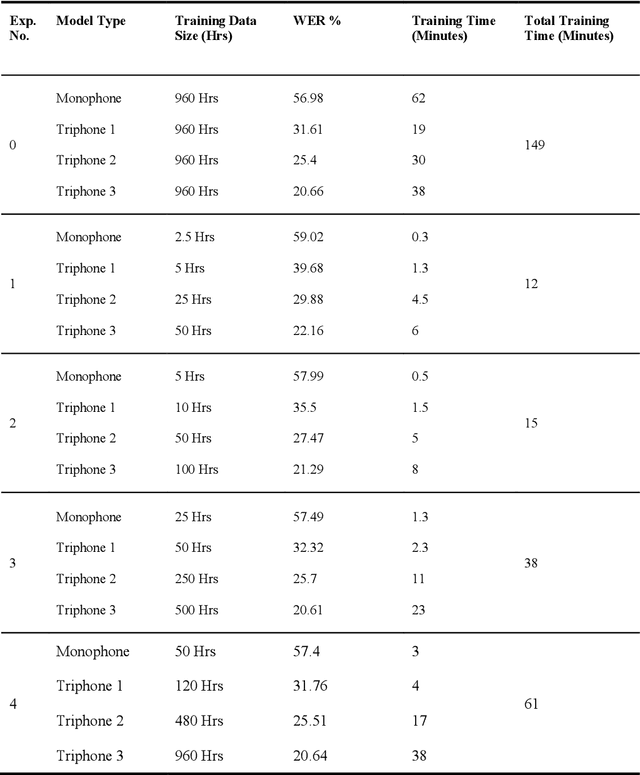
In Automatic Speech Recognition, GMM-HMM had been widely used for acoustic modelling. With the current advancement of deep learning, the Gaussian Mixture Model (GMM) from acoustic models has been replaced with Deep Neural Network, namely DNN-HMM Acoustic Models. The GMM models are widely used to create the alignments of the training data for the hybrid deep neural network model, thus making it an important task to create accurate alignments. Many factors such as training dataset size, training data augmentation, model hyperparameters, etc., affect the model learning. Traditionally in machine learning, larger datasets tend to have better performance, while smaller datasets tend to trigger over-fitting. The collection of speech data and their accurate transcriptions is a significant challenge that varies over different languages, and in most cases, it might be limited to big organizations. Moreover, in the case of available large datasets, training a model using such data requires additional time and computing resources, which may not be available. While the data about the accuracy of state-of-the-art ASR models on open-source datasets are published, the study about the impact of the size of a dataset on acoustic models is not readily available. This work aims to investigate the impact of dataset size variations on the performance of various GMM-HMM Acoustic Models and their respective computational costs.
Adding Connectionist Temporal Summarization into Conformer to Improve Its Decoder Efficiency For Speech Recognition
Apr 08, 2022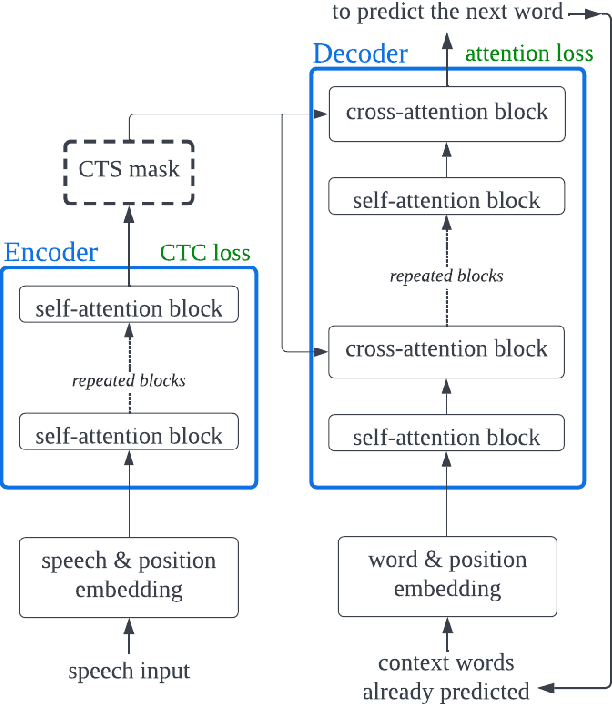
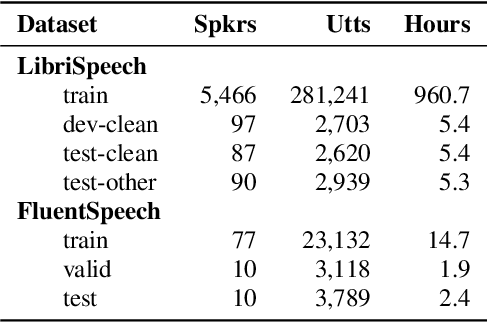
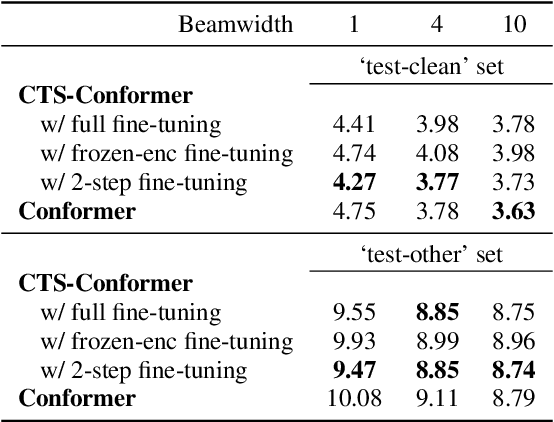

The Conformer model is an excellent architecture for speech recognition modeling that effectively utilizes the hybrid losses of connectionist temporal classification (CTC) and attention to train model parameters. To improve the decoding efficiency of Conformer, we propose a novel connectionist temporal summarization (CTS) method that reduces the number of frames required for the attention decoder fed from the acoustic sequences generated by the encoder, thus reducing operations. However, to achieve such decoding improvements, we must fine-tune model parameters, as cross-attention observations are changed and thus require corresponding refinements. Our final experiments show that, with a beamwidth of 4, the LibriSpeech's decoding budget can be reduced by up to 20% and for FluentSpeech data it can be reduced by 11%, without losing ASR accuracy. An improvement in accuracy is even found for the LibriSpeech "test-other" set. The word error rate (WER) is reduced by 6\% relative at the beam width of 1 and by 3% relative at the beam width of 4.
Discovering Phonetic Inventories with Crosslingual Automatic Speech Recognition
Jan 28, 2022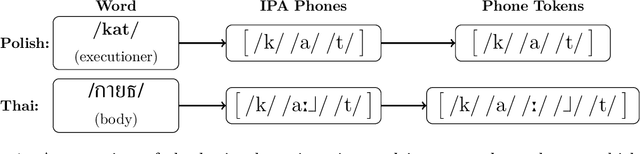
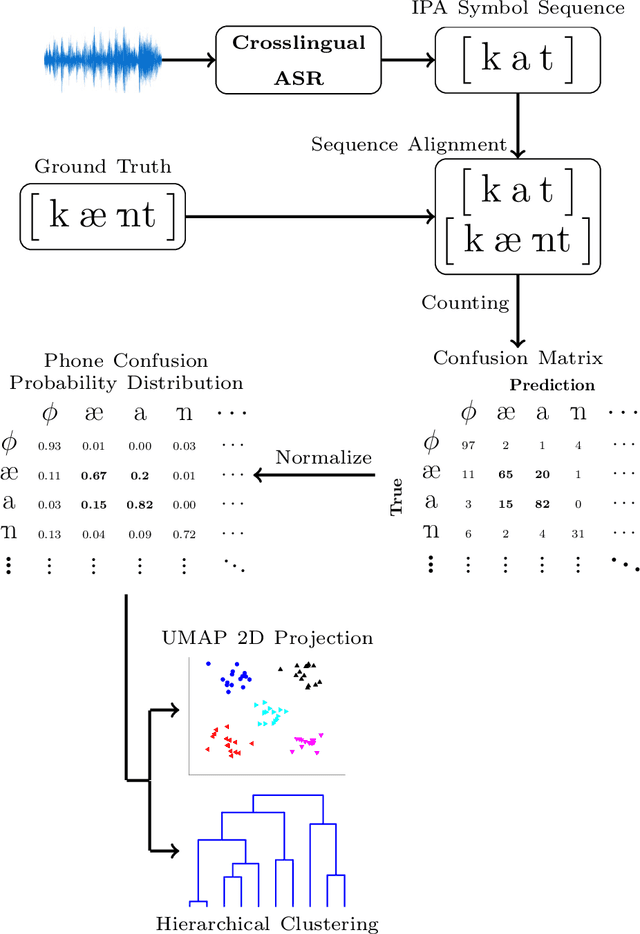
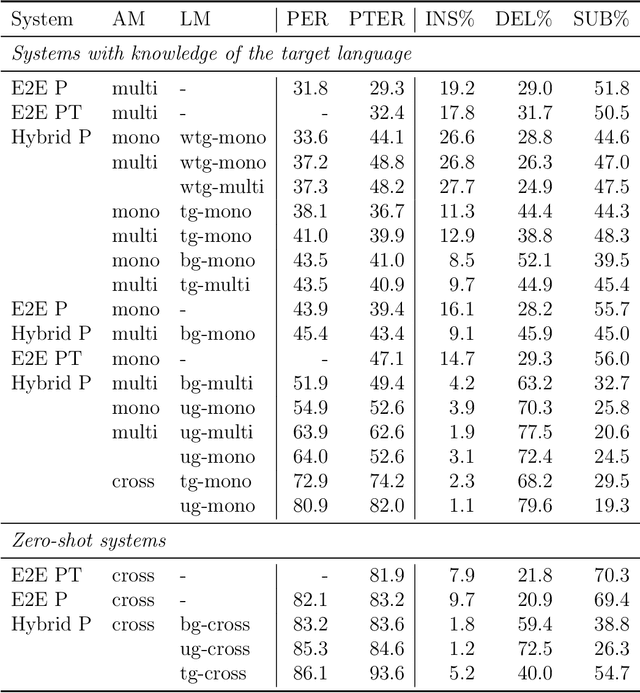
The high cost of data acquisition makes Automatic Speech Recognition (ASR) model training problematic for most existing languages, including languages that do not even have a written script, or for which the phone inventories remain unknown. Past works explored multilingual training, transfer learning, as well as zero-shot learning in order to build ASR systems for these low-resource languages. While it has been shown that the pooling of resources from multiple languages is helpful, we have not yet seen a successful application of an ASR model to a language unseen during training. A crucial step in the adaptation of ASR from seen to unseen languages is the creation of the phone inventory of the unseen language. The ultimate goal of our work is to build the phone inventory of a language unseen during training in an unsupervised way without any knowledge about the language. In this paper, we 1) investigate the influence of different factors (i.e., model architecture, phonotactic model, type of speech representation) on phone recognition in an unknown language; 2) provide an analysis of which phones transfer well across languages and which do not in order to understand the limitations of and areas for further improvement for automatic phone inventory creation; and 3) present different methods to build a phone inventory of an unseen language in an unsupervised way. To that end, we conducted mono-, multi-, and crosslingual experiments on a set of 13 phonetically diverse languages and several in-depth analyses. We found a number of universal phone tokens (IPA symbols) that are well-recognized cross-linguistically. Through a detailed analysis of results, we conclude that unique sounds, similar sounds, and tone languages remain a major challenge for phonetic inventory discovery.
BrainBERT: Self-supervised representation learning for intracranial recordings
Feb 28, 2023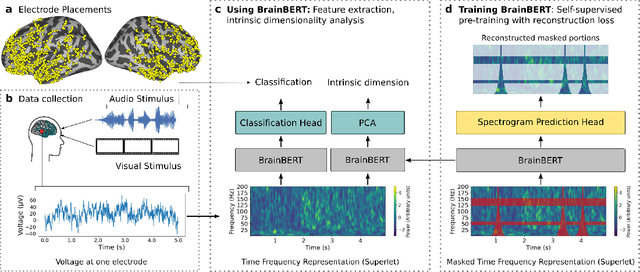
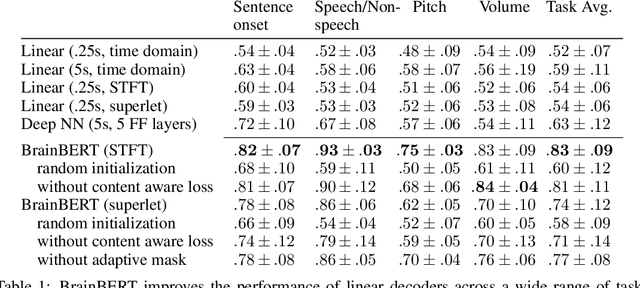
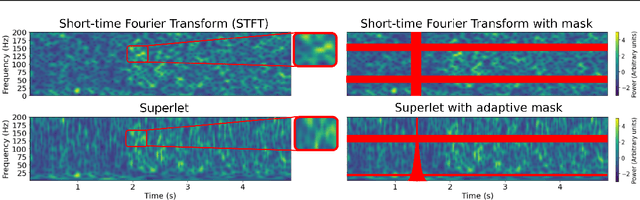
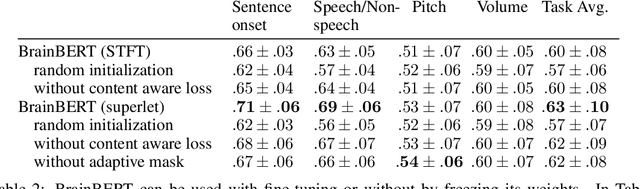
We create a reusable Transformer, BrainBERT, for intracranial recordings bringing modern representation learning approaches to neuroscience. Much like in NLP and speech recognition, this Transformer enables classifying complex concepts, i.e., decoding neural data, with higher accuracy and with much less data by being pretrained in an unsupervised manner on a large corpus of unannotated neural recordings. Our approach generalizes to new subjects with electrodes in new positions and to unrelated tasks showing that the representations robustly disentangle the neural signal. Just like in NLP where one can study language by investigating what a language model learns, this approach opens the door to investigating the brain by what a model of the brain learns. As a first step along this path, we demonstrate a new analysis of the intrinsic dimensionality of the computations in different areas of the brain. To construct these representations, we combine a technique for producing super-resolution spectrograms of neural data with an approach designed for generating contextual representations of audio by masking. In the future, far more concepts will be decodable from neural recordings by using representation learning, potentially unlocking the brain like language models unlocked language.
CiCo: Domain-Aware Sign Language Retrieval via Cross-Lingual Contrastive Learning
Mar 22, 2023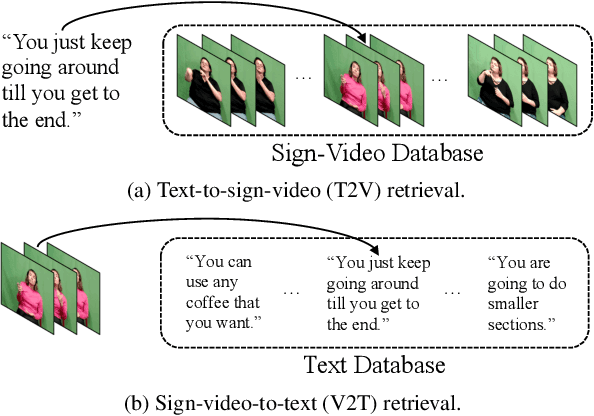
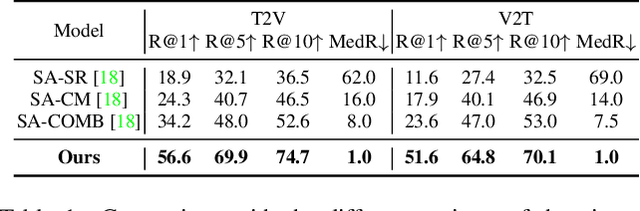


This work focuses on sign language retrieval-a recently proposed task for sign language understanding. Sign language retrieval consists of two sub-tasks: text-to-sign-video (T2V) retrieval and sign-video-to-text (V2T) retrieval. Different from traditional video-text retrieval, sign language videos, not only contain visual signals but also carry abundant semantic meanings by themselves due to the fact that sign languages are also natural languages. Considering this character, we formulate sign language retrieval as a cross-lingual retrieval problem as well as a video-text retrieval task. Concretely, we take into account the linguistic properties of both sign languages and natural languages, and simultaneously identify the fine-grained cross-lingual (i.e., sign-to-word) mappings while contrasting the texts and the sign videos in a joint embedding space. This process is termed as cross-lingual contrastive learning. Another challenge is raised by the data scarcity issue-sign language datasets are orders of magnitude smaller in scale than that of speech recognition. We alleviate this issue by adopting a domain-agnostic sign encoder pre-trained on large-scale sign videos into the target domain via pseudo-labeling. Our framework, termed as domain-aware sign language retrieval via Cross-lingual Contrastive learning or CiCo for short, outperforms the pioneering method by large margins on various datasets, e.g., +22.4 T2V and +28.0 V2T R@1 improvements on How2Sign dataset, and +13.7 T2V and +17.1 V2T R@1 improvements on PHOENIX-2014T dataset. Code and models are available at: https://github.com/FangyunWei/SLRT.
Don't Be So Sure! Boosting ASR Decoding via Confidence Relaxation
Dec 27, 2022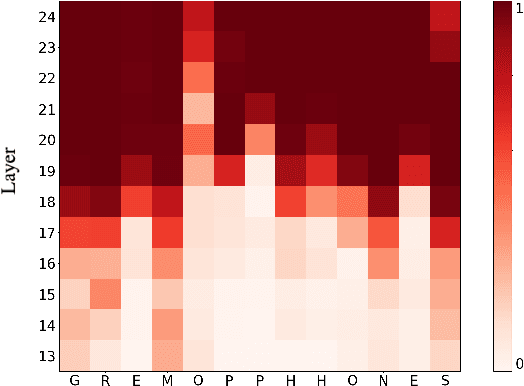

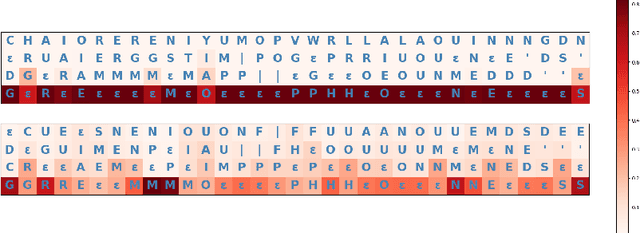
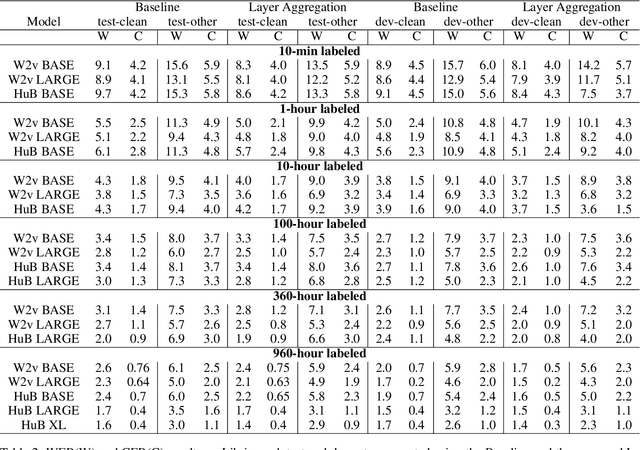
Automatic Speech Recognition (ASR) systems frequently use a search-based decoding strategy aiming to find the best attainable transcript by considering multiple candidates. One prominent speech recognition decoding heuristic is beam search, which seeks the transcript with the greatest likelihood computed using the predicted distribution. While showing substantial performance gains in various tasks, beam search loses some of its effectiveness when the predicted probabilities are highly confident, i.e., the predicted distribution is massed for a single or very few classes. We show that recently proposed Self-Supervised Learning (SSL)-based ASR models tend to yield exceptionally confident predictions that may hamper beam search from truly considering a diverse set of candidates. We perform a layer analysis to reveal and visualize how predictions evolve, and propose a decoding procedure that improves the performance of fine-tuned ASR models. Our proposed approach does not require further training beyond the original fine-tuning, nor additional model parameters. In fact, we find that our proposed method requires significantly less inference computation than current approaches. We propose aggregating the top M layers, potentially leveraging useful information encoded in intermediate layers, and relaxing model confidence. We demonstrate the effectiveness of our approach by conducting an empirical study on varying amounts of labeled resources and different model sizes, showing consistent improvements in particular when applied to low-resource scenarios.
Spell my name: keyword boosted speech recognition
Oct 06, 2021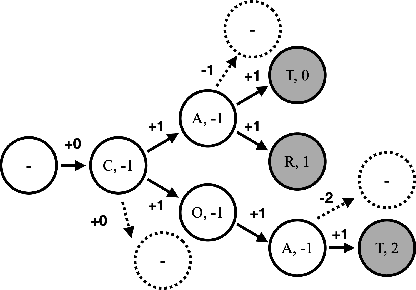

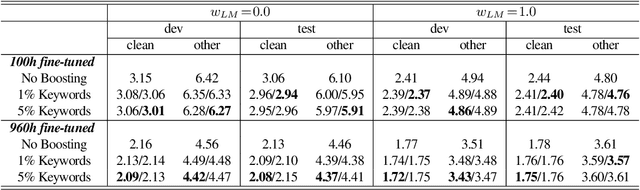
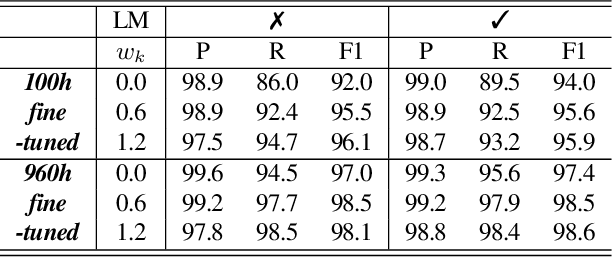
Recognition of uncommon words such as names and technical terminology is important to understanding conversations in context. However, the ability to recognise such words remains a challenge in modern automatic speech recognition (ASR) systems. In this paper, we propose a simple but powerful ASR decoding method that can better recognise these uncommon keywords, which in turn enables better readability of the results. The method boosts the probabilities of given keywords in a beam search based on acoustic model predictions. The method does not require any training in advance. We demonstrate the effectiveness of our method on the LibriSpeeech test sets and also internal data of real-world conversations. Our method significantly boosts keyword accuracy on the test sets, while maintaining the accuracy of the other words, and as well as providing significant qualitative improvements. This method is applicable to other tasks such as machine translation, or wherever unseen and difficult keywords need to be recognised in beam search.