 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Improving Medical Speech-to-Text Accuracy with Vision-Language Pre-training Model
Feb 27, 2023
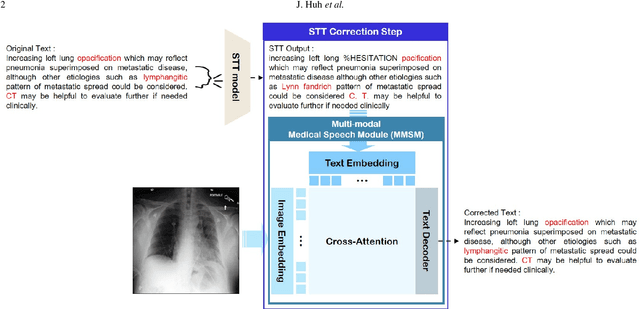

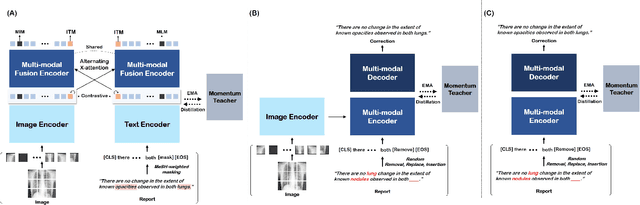
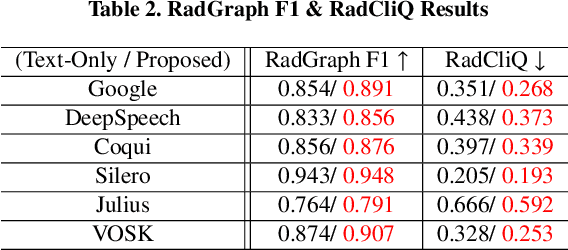
Automatic Speech Recognition (ASR) is a technology that converts spoken words into text, facilitating interaction between humans and machines. One of the most common applications of ASR is Speech-To-Text (STT) technology, which simplifies user workflows by transcribing spoken words into text. In the medical field, STT has the potential to significantly reduce the workload of clinicians who rely on typists to transcribe their voice recordings. However, developing an STT model for the medical domain is challenging due to the lack of sufficient speech and text datasets. To address this issue, we propose a medical-domain text correction method that modifies the output text of a general STT system using the Vision Language Pre-training (VLP) method. VLP combines textual and visual information to correct text based on image knowledge. Our extensive experiments demonstrate that the proposed method offers quantitatively and clinically significant improvements in STT performance in the medical field. We further show that multi-modal understanding of image and text information outperforms single-modal understanding using only text information.
TinySpeech: Attention Condensers for Deep Speech Recognition Neural Networks on Edge Devices
Aug 23, 2020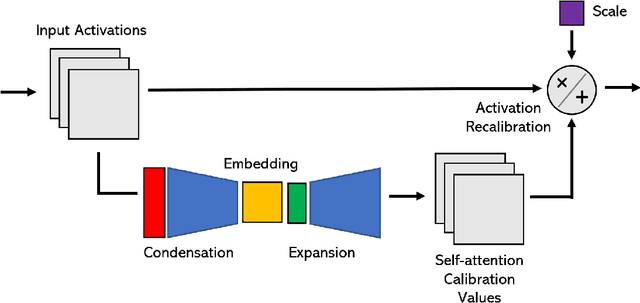

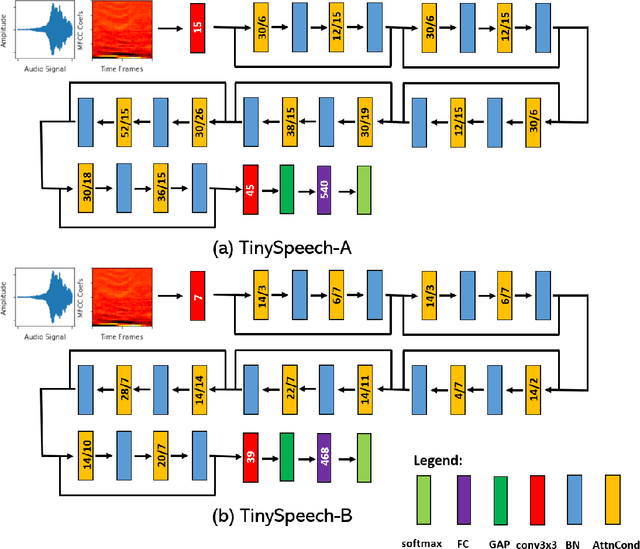
Advances in deep learning have led to state-of-the-art performance across a multitude of speech recognition tasks. Nevertheless, the widespread deployment of deep neural networks for on-device speech recognition remains a challenge, particularly in edge scenarios where the memory and computing resources are highly constrained (e.g., low-power embedded devices) or where the memory and computing budget dedicated to speech recognition is low (e.g., mobile devices performing numerous tasks besides speech recognition). In this study, we introduce the concept of attention condensers for building low-footprint, highly-efficient deep neural networks for on-device speech recognition on the edge. More specifically, an attention condenser is a self-attention mechanism that learns and produces a condensed embedding characterizing joint local and cross-channel activation relationships, and performs selective attention accordingly. To illustrate its efficacy, we introduce TinySpeech, low-precision deep neural networks comprising largely of attention condensers tailored for on-device speech recognition using a machine-driven design exploration strategy. Experimental results on the Google Speech Commands benchmark dataset for limited-vocabulary speech recognition showed that TinySpeech networks achieved significantly lower architectural complexity (as much as $207\times$ fewer parameters) and lower computational complexity (as much as $21\times$ fewer multiply-add operations) when compared to previous deep neural networks in research literature. These results not only demonstrate the efficacy of attention condensers for building highly efficient deep neural networks for on-device speech recognition, but also illuminate its potential for accelerating deep learning on the edge and empowering a wide range of TinyML applications.
Speech Corpora Divergence Based Unsupervised Data Selection for ASR
Feb 26, 2023
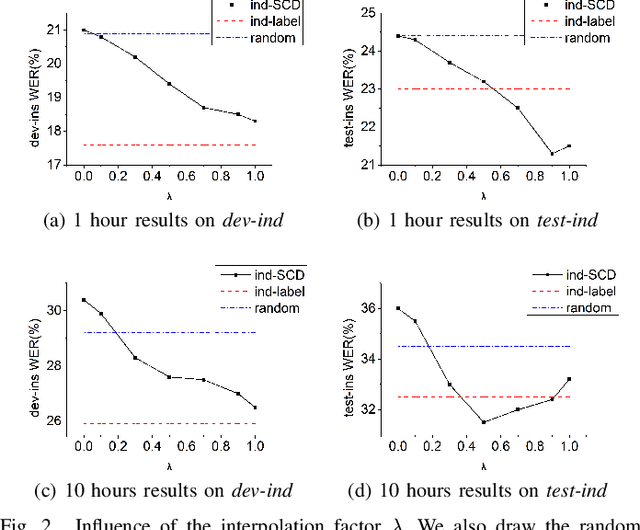
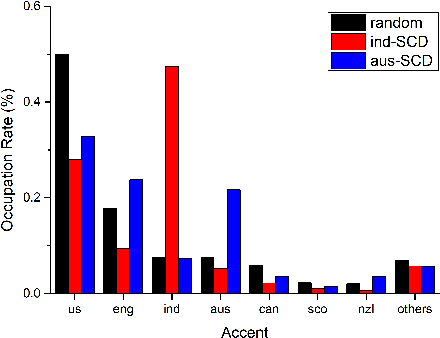
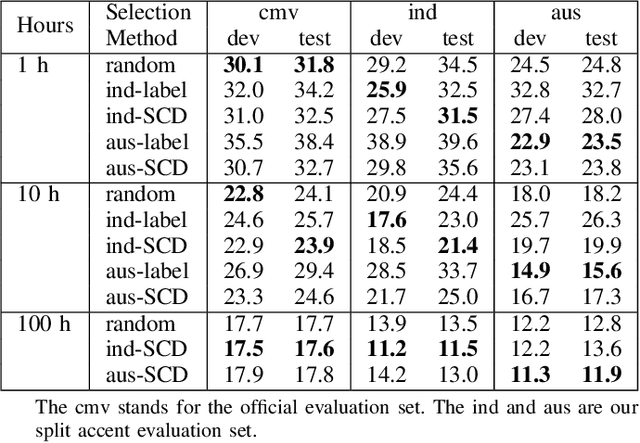
Selecting application scenarios matching data is important for the automatic speech recognition (ASR) training, but it is difficult to measure the matching degree of the training corpus. This study proposes a unsupervised target-aware data selection method based on speech corpora divergence (SCD), which can measure the similarity between two speech corpora. We first use the self-supervised Hubert model to discretize the speech corpora into label sequence and calculate the N-gram probability distribution. Then we calculate the Kullback-Leibler divergence between the N-grams as the SCD. Finally, we can choose the subset which has minimum SCD to the target corpus for annotation and training. Compared to previous data selection method, the SCD data selection method can focus on more acoustic details and guarantee the diversity of the selected set. We evaluate our method on different accents from Common Voice. Experiments show that the proposed SCD data selection can realize 14.8% relative improvements to the random selection, comparable or even superior to the result of supervised selection.
4-bit Conformer with Native Quantization Aware Training for Speech Recognition
Mar 29, 2022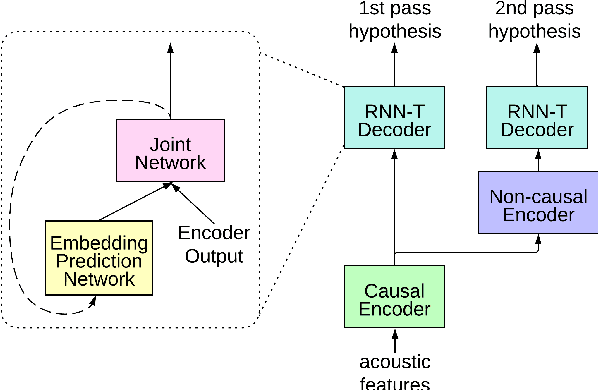
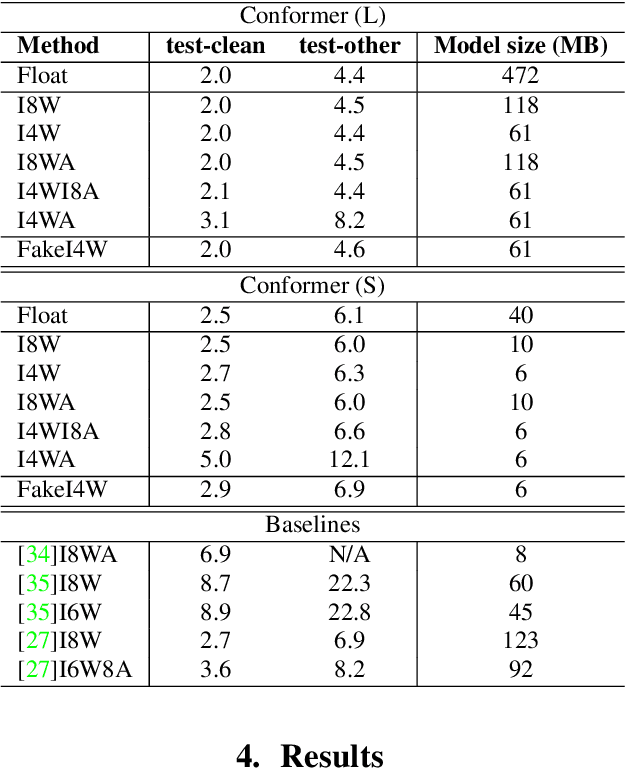

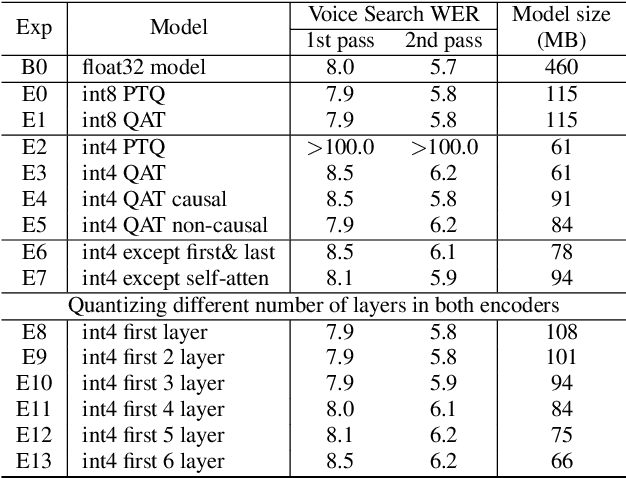
Reducing the latency and model size has always been a significant research problem for live Automatic Speech Recognition (ASR) application scenarios. Along this direction, model quantization has become an increasingly popular approach to compress neural networks and reduce computation cost. Most of the existing practical ASR systems apply post-training 8-bit quantization. To achieve a higher compression rate without introducing additional performance regression, in this study, we propose to develop 4-bit ASR models with native quantization aware training, which leverages native integer operations to effectively optimize both training and inference. We conducted two experiments on state-of-the-art Conformer-based ASR models to evaluate our proposed quantization technique. First, we explored the impact of different precisions for both weight and activation quantization on the LibriSpeech dataset, and obtained a lossless 4-bit Conformer model with 7.7x size reduction compared to the float32 model. Following this, we for the first time investigated and revealed the viability of 4-bit quantization on a practical ASR system that is trained with large-scale datasets, and produced a lossless Conformer ASR model with mixed 4-bit and 8-bit weights that has 5x size reduction compared to the float32 model.
Locality Matters: A Locality-Biased Linear Attention for Automatic Speech Recognition
Mar 29, 2022
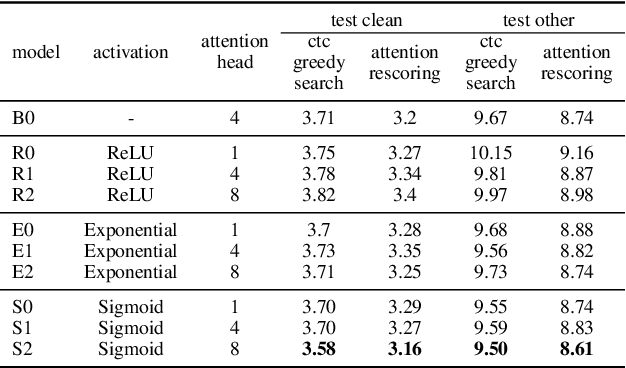
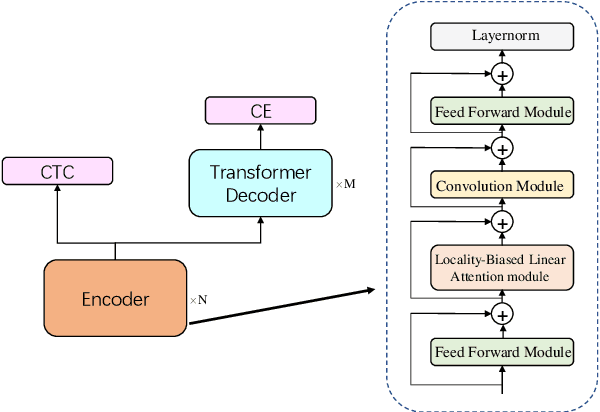
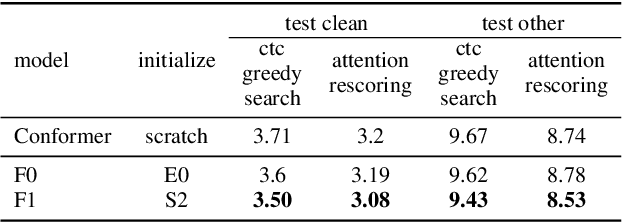
Conformer has shown a great success in automatic speech recognition (ASR) on many public benchmarks. One of its crucial drawbacks is the quadratic time-space complexity with respect to the input sequence length, which prohibits the model to scale-up as well as process longer input audio sequences. To solve this issue, numerous linear attention methods have been proposed. However, these methods often have limited performance on ASR as they treat tokens equally in modeling, neglecting the fact that the neighbouring tokens are often more connected than the distanced tokens. In this paper, we take this fact into account and propose a new locality-biased linear attention for Conformer. It not only achieves higher accuracy than the vanilla Conformer, but also enjoys linear space-time computational complexity. To be specific, we replace the softmax attention with a locality-biased linear attention (LBLA) mechanism in Conformer blocks. The LBLA contains a kernel function to ensure the linear complexities and a cosine reweighing matrix to impose more weights on neighbouring tokens. Extensive experiments on the LibriSpeech corpus show that by introducing this locality bias to the Conformer, our method achieves a lower word error rate with more than 22% inference speed.
Dereverberation of Autoregressive Envelopes for Far-field Speech Recognition
Aug 13, 2021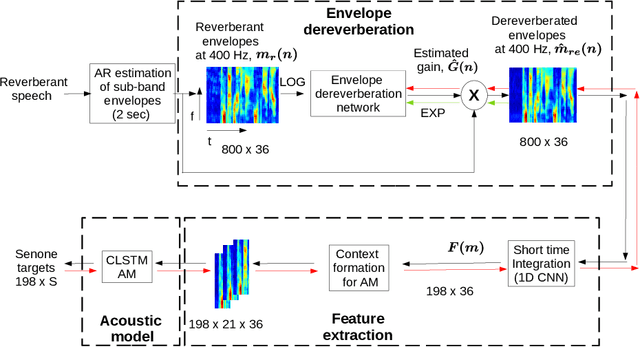
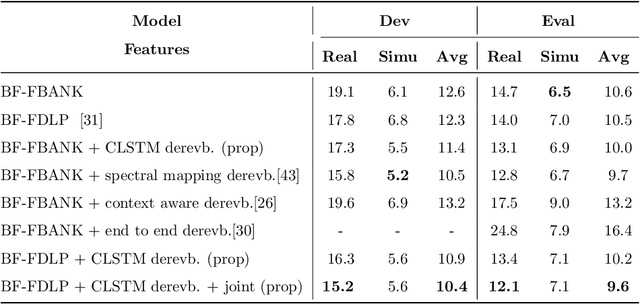
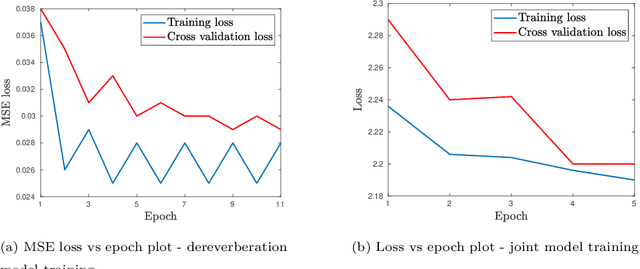
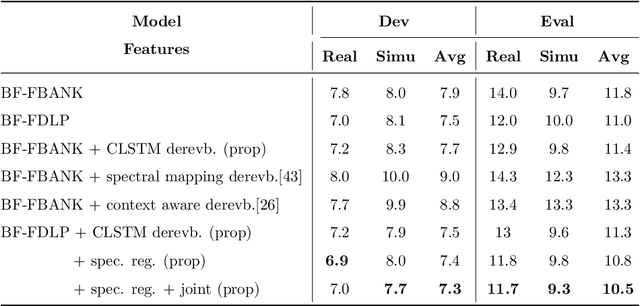
The task of speech recognition in far-field environments is adversely affected by the reverberant artifacts that elicit as the temporal smearing of the sub-band envelopes. In this paper, we develop a neural model for speech dereverberation using the long-term sub-band envelopes of speech. The sub-band envelopes are derived using frequency domain linear prediction (FDLP) which performs an autoregressive estimation of the Hilbert envelopes. The neural dereverberation model estimates the envelope gain which when applied to reverberant signals suppresses the late reflection components in the far-field signal. The dereverberated envelopes are used for feature extraction in speech recognition. Further, the sequence of steps involved in envelope dereverberation, feature extraction and acoustic modeling for ASR can be implemented as a single neural processing pipeline which allows the joint learning of the dereverberation network and the acoustic model. Several experiments are performed on the REVERB challenge dataset, CHiME-3 dataset and VOiCES dataset. In these experiments, the joint learning of envelope dereverberation and acoustic model yields significant performance improvements over the baseline ASR system based on log-mel spectrogram as well as other past approaches for dereverberation (average relative improvements of 10-24% over the baseline system). A detailed analysis on the choice of hyper-parameters and the cost function involved in envelope dereverberation is also provided.
Visual Information Matters for ASR Error Correction
Mar 16, 2023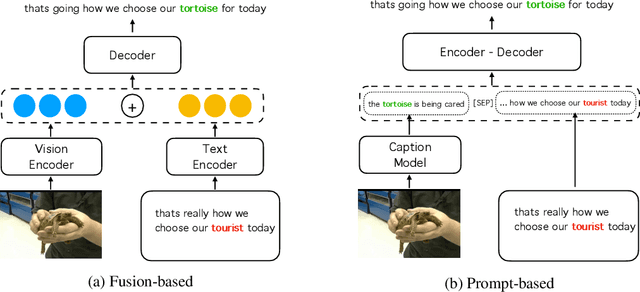
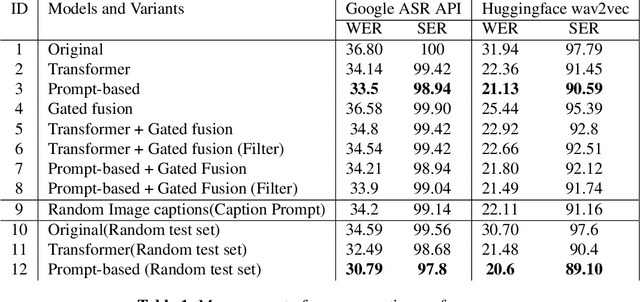


Aiming to improve the Automatic Speech Recognition (ASR) outputs with a post-processing step, ASR error correction (EC) techniques have been widely developed due to their efficiency in using parallel text data. Previous works mainly focus on using text or/ and speech data, which hinders the performance gain when not only text and speech information, but other modalities, such as visual information are critical for EC. The challenges are mainly two folds: one is that previous work fails to emphasize visual information, thus rare exploration has been studied. The other is that the community lacks a high-quality benchmark where visual information matters for the EC models. Therefore, this paper provides 1) simple yet effective methods, namely gated fusion and image captions as prompts to incorporate visual information to help EC; 2) large-scale benchmark datasets, namely Visual-ASR-EC, where each item in the training data consists of visual, speech, and text information, and the test data are carefully selected by human annotators to ensure that even humans could make mistakes when visual information is missing. Experimental results show that using captions as prompts could effectively use the visual information and surpass state-of-the-art methods by upto 1.2% in Word Error Rate(WER), which also indicates that visual information is critical in our proposed Visual-ASR-EC dataset
An Empirical Study of Language Model Integration for Transducer based Speech Recognition
Mar 31, 2022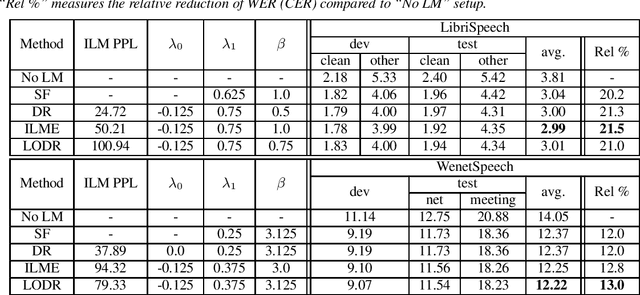
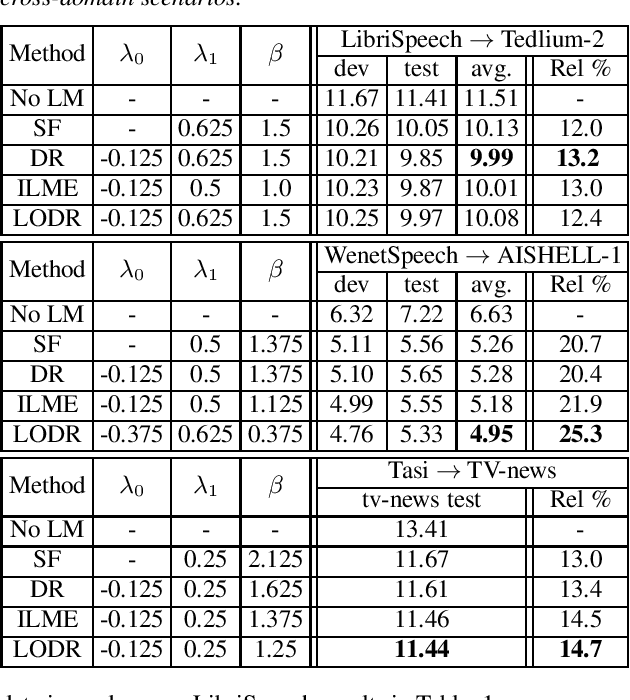
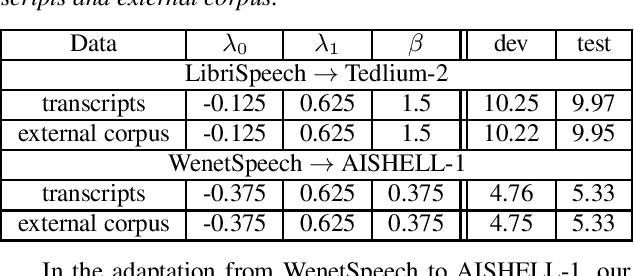
Utilizing text-only data with an external language model (LM) in end-to-end RNN-Transducer (RNN-T) for speech recognition is challenging. Recently, a class of methods such as density ratio (DR) and ILM estimation (ILME) have been developed, outperforming the classic shallow fusion (SF) method. The basic idea behind these methods is that RNN-T posterior should first subtract the implicitly learned ILM prior, in order to integrate the external LM. While recent studies suggest that RNN-T only learns some low-order language model information, the DR method uses a well-trained ILM. We hypothesize that this setting is appropriate and may deteriorate the performance of the DR method, and propose a low-order density ratio method (LODR) by training a low-order weak ILM for DR. Extensive empirical experiments are conducted on both in-domain and cross-domain scenarios on English LibriSpeech & Tedlium-2 and Chinese WenetSpeech & AISHELL-1 datasets. It is shown that LODR consistently outperforms SF in all tasks, while performing generally close to ILME and better than DR in most tests.