 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Performance Evaluation of Deep Convolutional Maxout Neural Network in Speech Recognition
May 04, 2021
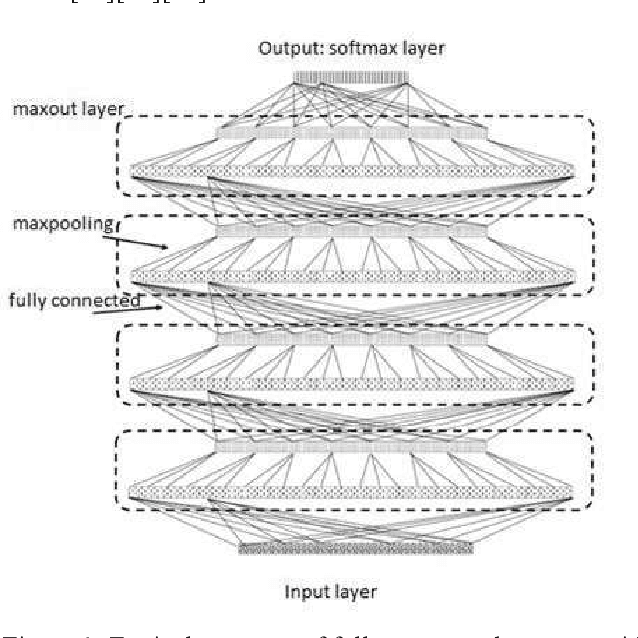
In this paper, various structures and methods of Deep Artificial Neural Networks (DNN) will be evaluated and compared for the purpose of continuous Persian speech recognition. One of the first models of neural networks used in speech recognition applications were fully connected Neural Networks (FCNNs) and, consequently, Deep Neural Networks (DNNs). Although these models have better performance compared to GMM / HMM models, they do not have the proper structure to model local speech information. Convolutional Neural Network (CNN) is a good option for modeling the local structure of biological signals, including speech signals. Another issue that Deep Artificial Neural Networks face, is the convergence of networks on training data. The main inhibitor of convergence is the presence of local minima in the process of training. Deep Neural Network Pre-training methods, despite a large amount of computing, are powerful tools for crossing the local minima. But the use of appropriate neuronal models in the network structure seems to be a better solution to this problem. The Rectified Linear Unit neuronal model and the Maxout model are the most suitable neuronal models presented to this date. Several experiments were carried out to evaluate the performance of the methods and structures mentioned. After verifying the proper functioning of these methods, a combination of all models was implemented on FARSDAT speech database for continuous speech recognition. The results obtained from the experiments show that the combined model (CMDNN) improves the performance of ANNs in speech recognition versus the pre-trained fully connected NNs with sigmoid neurons by about 3%.
* 6 pages, 2 figures, conference paper submitted to 2018 25th National and 3rd International Iranian Conference on Biomedical Engineering (ICBME)
Streaming Multi-talker Speech Recognition with Joint Speaker Identification
Apr 05, 2021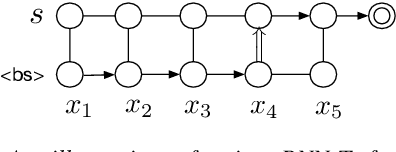
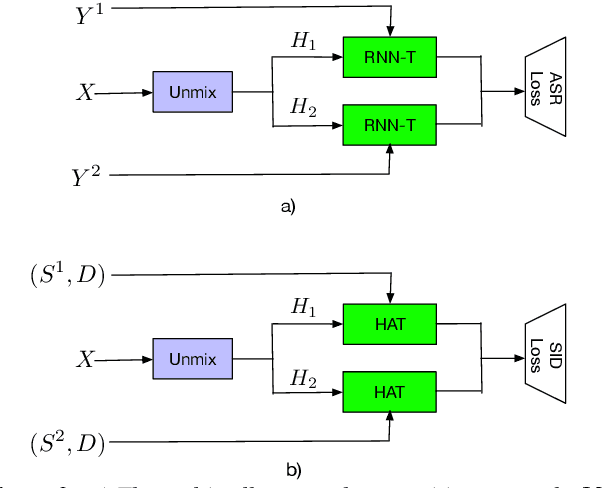
In multi-talker scenarios such as meetings and conversations, speech processing systems are usually required to transcribe the audio as well as identify the speakers for downstream applications. Since overlapped speech is common in this case, conventional approaches usually address this problem in a cascaded fashion that involves speech separation, speech recognition and speaker identification that are trained independently. In this paper, we propose Streaming Unmixing, Recognition and Identification Transducer (SURIT) -- a new framework that deals with this problem in an end-to-end streaming fashion. SURIT employs the recurrent neural network transducer (RNN-T) as the backbone for both speech recognition and speaker identification. We validate our idea on the LibrispeechMix dataset -- a multi-talker dataset derived from Librispeech, and present encouraging results.
Exploiting Cross-domain And Cross-Lingual Ultrasound Tongue Imaging Features For Elderly And Dysarthric Speech Recognition
Jun 15, 2022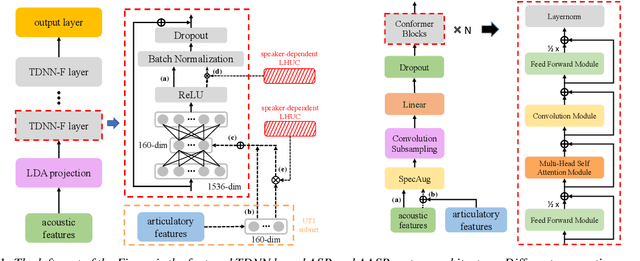
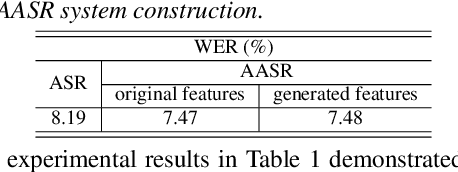
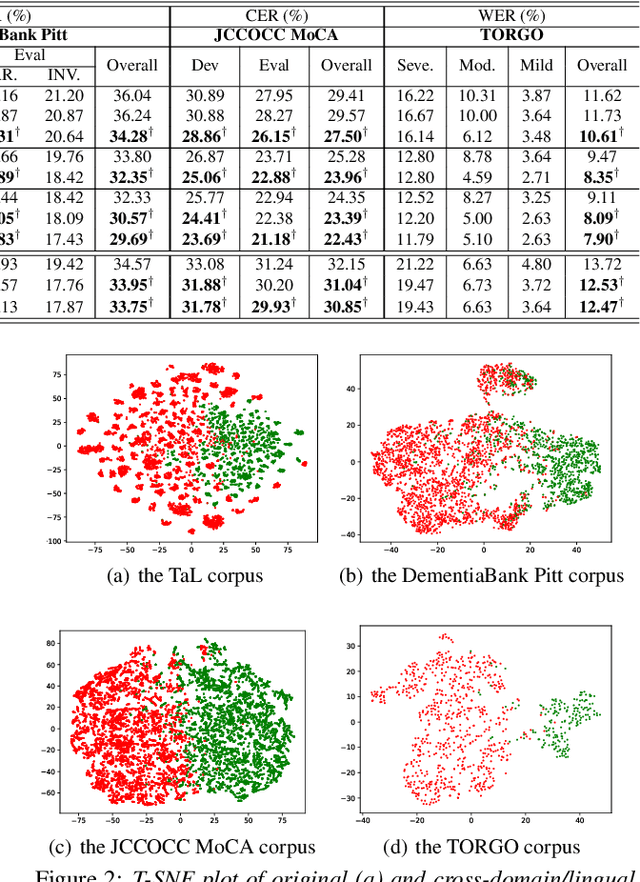
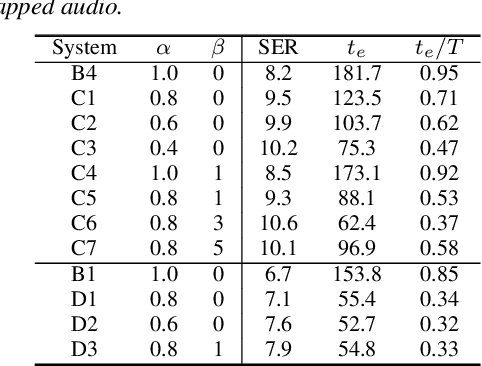
Articulatory features are inherently invariant to acoustic signal distortion and have been successfully incorporated into automatic speech recognition (ASR) systems designed for normal speech. Their practical application to atypical task domains such as elderly and disordered speech across languages is often limited by the difficulty in collecting such specialist data from target speakers. This paper presents a cross-domain and cross-lingual A2A inversion approach that utilizes the parallel audio, visual and ultrasound tongue imaging (UTI) data of the 24-hour TaL corpus in A2A model pre-training before being cross-domain and cross-lingual adapted to three datasets across two languages: the English DementiaBank Pitt and Cantonese JCCOCC MoCA elderly speech corpora; and the English TORGO dysarthric speech data, to produce UTI based articulatory features. Experiments conducted on three tasks suggested incorporating the generated articulatory features consistently outperformed the baseline hybrid TDNN and Conformer based end-to-end systems constructed using acoustic features only by statistically significant word error rate or character error rate reductions up to 2.64%, 1.92% and 1.21% absolute (8.17%, 7.89% and 13.28% relative) after data augmentation and speaker adaptation were applied.
A Token-Wise Beam Search Algorithm for RNN-T
Feb 28, 2023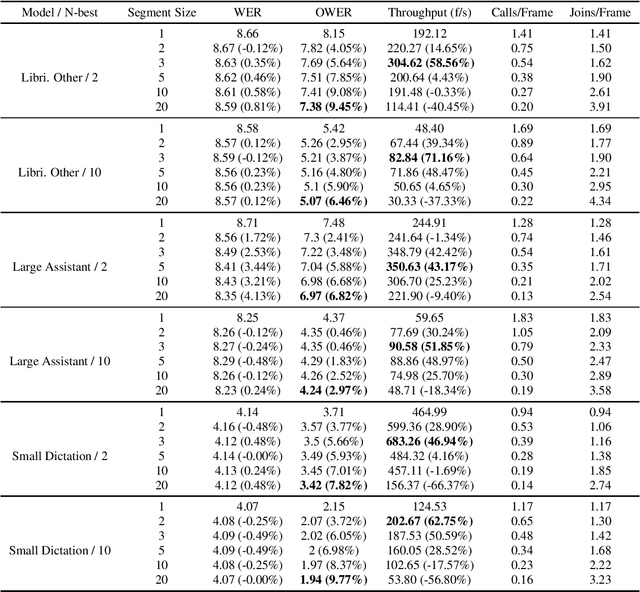
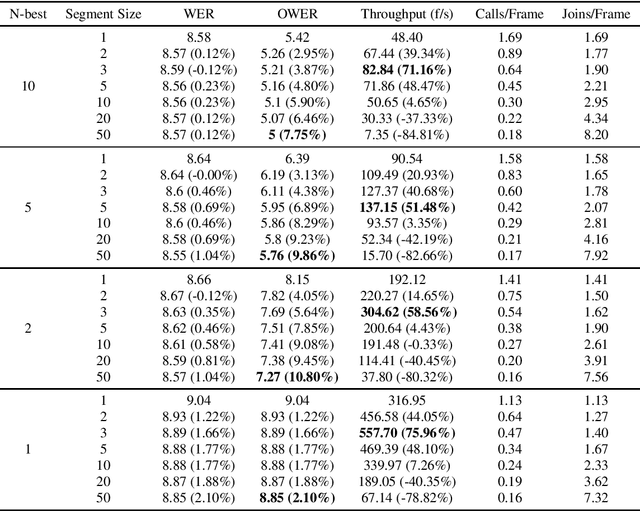
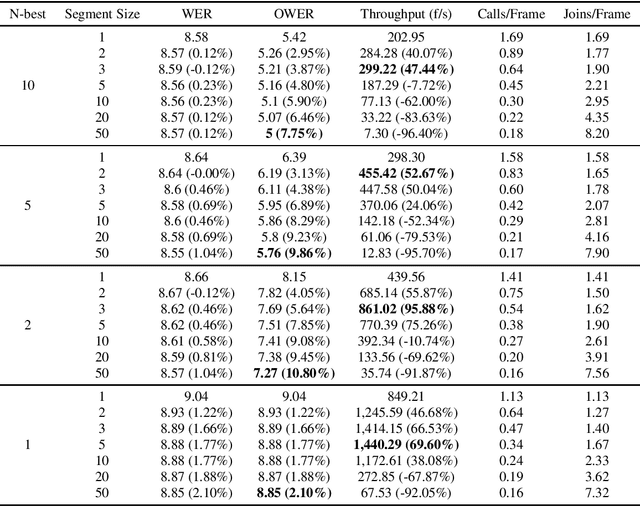
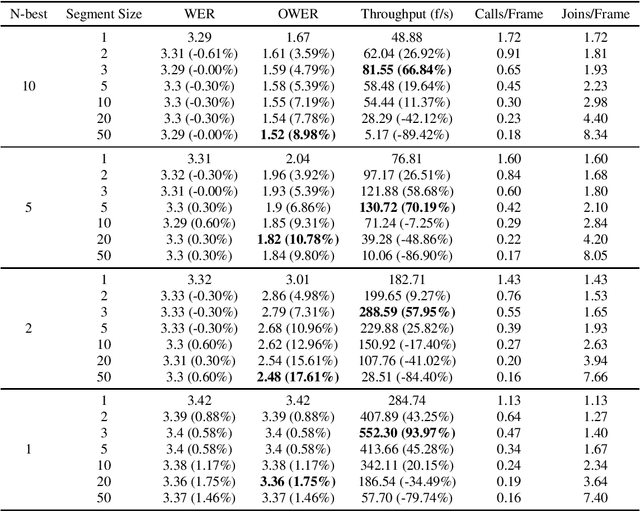
Standard Recurrent Neural Network Transducers (RNN-T) decoding algorithms for speech recognition are iterating over the time axis, such that one time step is decoded before moving on to the next time step. Those algorithms result in a large number of calls to the joint network, that were shown in previous work to be an important factor that reduces decoding speed. We present a decoding beam search algorithm that batches the joint network calls across a segment of time steps, which results in 40%-70% decoding speedups, consistently across all models and settings experimented with. In addition, aggregating emission probabilities over a segment may be seen as a better approximation to finding the most likely model output, causing our algorithm to improve oracle word error rate by up to 10% relative as the segment size increases, and to slightly improve general word error rate.
A Multimodal Dynamical Variational Autoencoder for Audiovisual Speech Representation Learning
May 05, 2023In this paper, we present a multimodal \textit{and} dynamical VAE (MDVAE) applied to unsupervised audio-visual speech representation learning. The latent space is structured to dissociate the latent dynamical factors that are shared between the modalities from those that are specific to each modality. A static latent variable is also introduced to encode the information that is constant over time within an audiovisual speech sequence. The model is trained in an unsupervised manner on an audiovisual emotional speech dataset, in two stages. In the first stage, a vector quantized VAE (VQ-VAE) is learned independently for each modality, without temporal modeling. The second stage consists in learning the MDVAE model on the intermediate representation of the VQ-VAEs before quantization. The disentanglement between static versus dynamical and modality-specific versus modality-common information occurs during this second training stage. Extensive experiments are conducted to investigate how audiovisual speech latent factors are encoded in the latent space of MDVAE. These experiments include manipulating audiovisual speech, audiovisual facial image denoising, and audiovisual speech emotion recognition. The results show that MDVAE effectively combines the audio and visual information in its latent space. They also show that the learned static representation of audiovisual speech can be used for emotion recognition with few labeled data, and with better accuracy compared with unimodal baselines and a state-of-the-art supervised model based on an audiovisual transformer architecture.
L2 proficiency assessment using self-supervised speech representations
Nov 16, 2022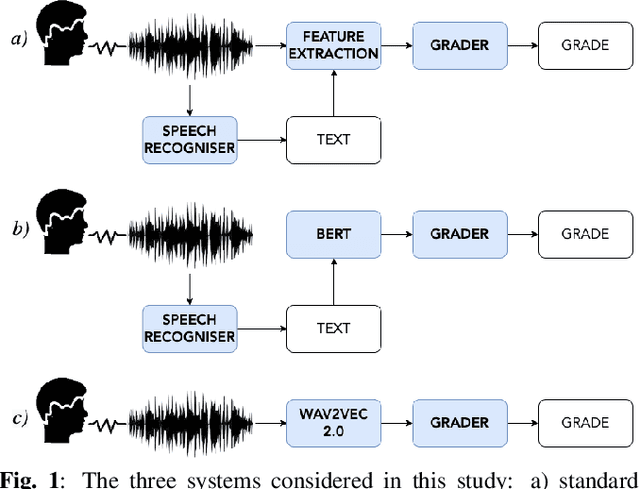
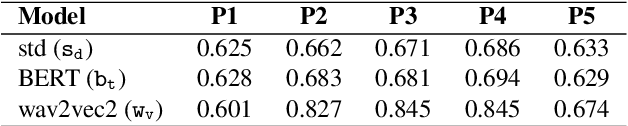
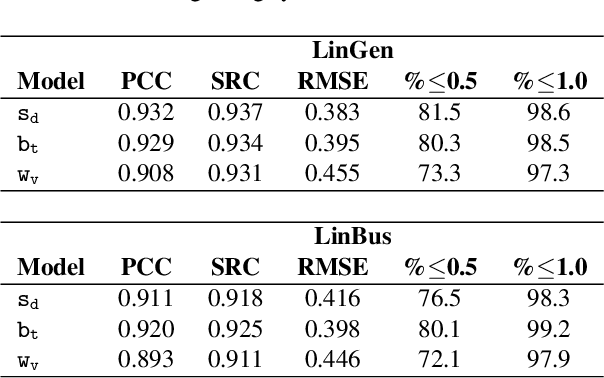
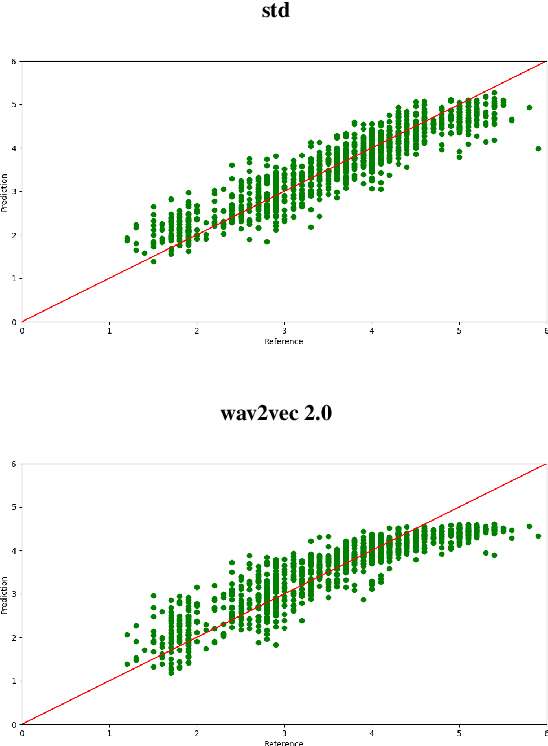
There has been a growing demand for automated spoken language assessment systems in recent years. A standard pipeline for this process is to start with a speech recognition system and derive features, either hand-crafted or based on deep-learning, that exploit the transcription and audio. Though these approaches can yield high performance systems, they require speech recognition systems that can be used for L2 speakers, and preferably tuned to the specific form of test being deployed. Recently a self-supervised speech representation based scheme, requiring no speech recognition, was proposed. This work extends the initial analysis conducted on this approach to a large scale proficiency test, Linguaskill, that comprises multiple parts, each designed to assess different attributes of a candidate's speaking proficiency. The performance of the self-supervised, wav2vec 2.0, system is compared to a high performance hand-crafted assessment system and a BERT-based text system both of which use speech transcriptions. Though the wav2vec 2.0 based system is found to be sensitive to the nature of the response, it can be configured to yield comparable performance to systems requiring a speech transcription, and yields gains when appropriately combined with standard approaches.
TransFusion: Transcribing Speech with Multinomial Diffusion
Oct 14, 2022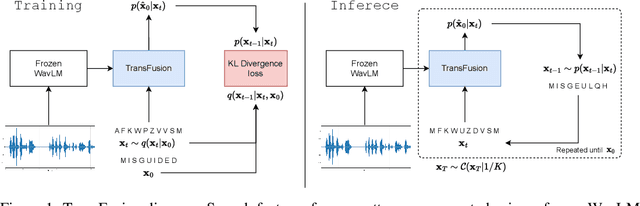
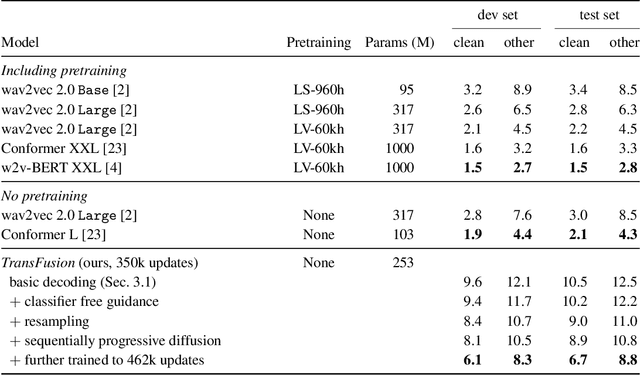
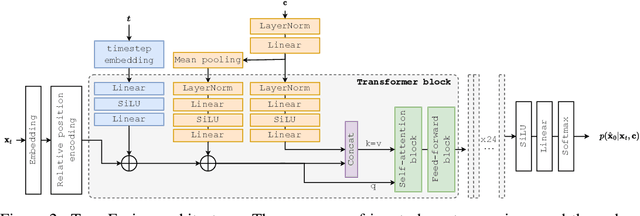
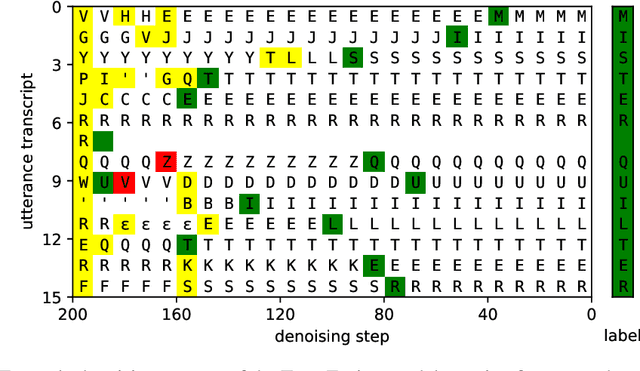
Diffusion models have shown exceptional scaling properties in the image synthesis domain, and initial attempts have shown similar benefits for applying diffusion to unconditional text synthesis. Denoising diffusion models attempt to iteratively refine a sampled noise signal until it resembles a coherent signal (such as an image or written sentence). In this work we aim to see whether the benefits of diffusion models can also be realized for speech recognition. To this end, we propose a new way to perform speech recognition using a diffusion model conditioned on pretrained speech features. Specifically, we propose TransFusion: a transcribing diffusion model which iteratively denoises a random character sequence into coherent text corresponding to the transcript of a conditioning utterance. We demonstrate comparable performance to existing high-performing contrastive models on the LibriSpeech speech recognition benchmark. To the best of our knowledge, we are the first to apply denoising diffusion to speech recognition. We also propose new techniques for effectively sampling and decoding multinomial diffusion models. These are required because traditional methods of sampling from acoustic models are not possible with our new discrete diffusion approach. Code and trained models are available: https://github.com/RF5/transfusion-asr
Beyond Universal Transformer: block reusing with adaptor in Transformer for automatic speech recognit
Mar 23, 2023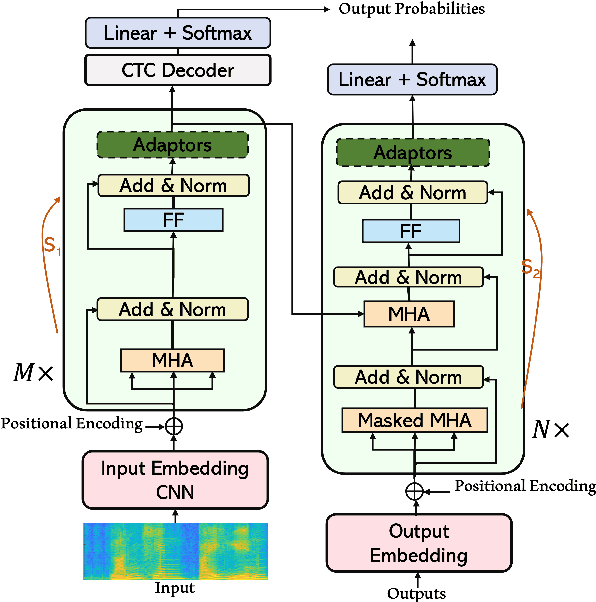
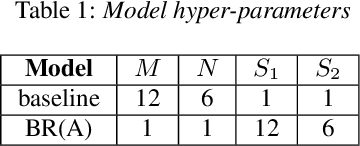
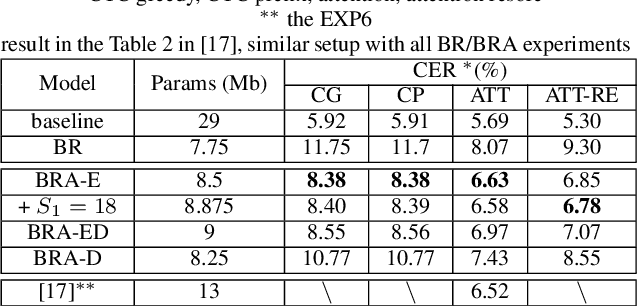
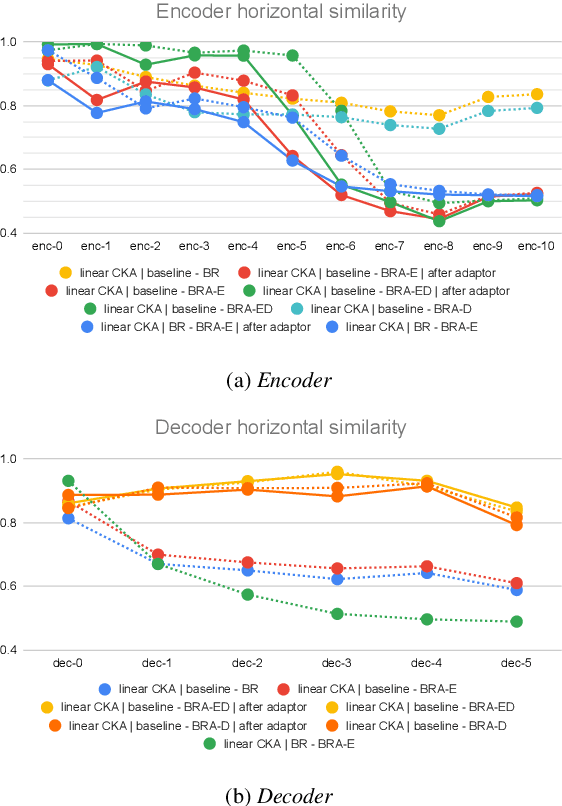
Transformer-based models have recently made significant achievements in the application of end-to-end (E2E) automatic speech recognition (ASR). It is possible to deploy the E2E ASR system on smart devices with the help of Transformer-based models. While these models still have the disadvantage of requiring a large number of model parameters. To overcome the drawback of universal Transformer models for the application of ASR on edge devices, we propose a solution that can reuse the block in Transformer models for the occasion of the small footprint ASR system, which meets the objective of accommodating resource limitations without compromising recognition accuracy. Specifically, we design a novel block-reusing strategy for speech Transformer (BRST) to enhance the effectiveness of parameters and propose an adapter module (ADM) that can produce a compact and adaptable model with only a few additional trainable parameters accompanying each reusing block. We conducted an experiment with the proposed method on the public AISHELL-1 corpus, and the results show that the proposed approach achieves the character error rate (CER) of 9.3%/6.63% with only 7.6M/8.3M parameters without and with the ADM, respectively. In addition, we also make a deeper analysis to show the effect of ADM in the general block-reusing method.
Neural-FST Class Language Model for End-to-End Speech Recognition
Jan 31, 2022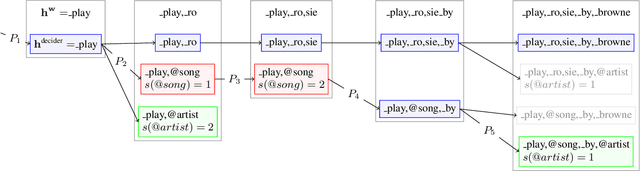
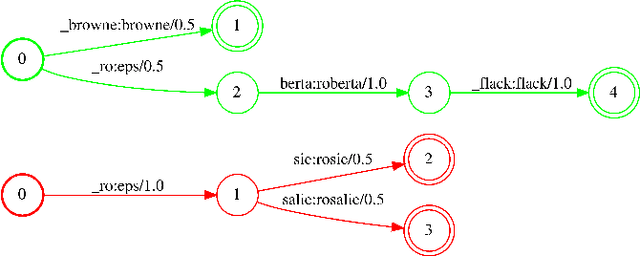
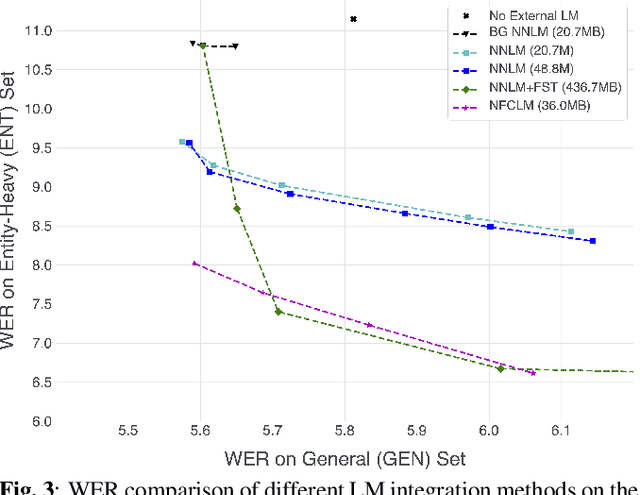
We propose Neural-FST Class Language Model (NFCLM) for end-to-end speech recognition, a novel method that combines neural network language models (NNLMs) and finite state transducers (FSTs) in a mathematically consistent framework. Our method utilizes a background NNLM which models generic background text together with a collection of domain-specific entities modeled as individual FSTs. Each output token is generated by a mixture of these components; the mixture weights are estimated with a separately trained neural decider. We show that NFCLM significantly outperforms NNLM by 15.8% relative in terms of Word Error Rate. NFCLM achieves similar performance as traditional NNLM and FST shallow fusion while being less prone to overbiasing and 12 times more compact, making it more suitable for on-device usage.
Continuous Speech Recognition using EEG and Video
Dec 19, 2019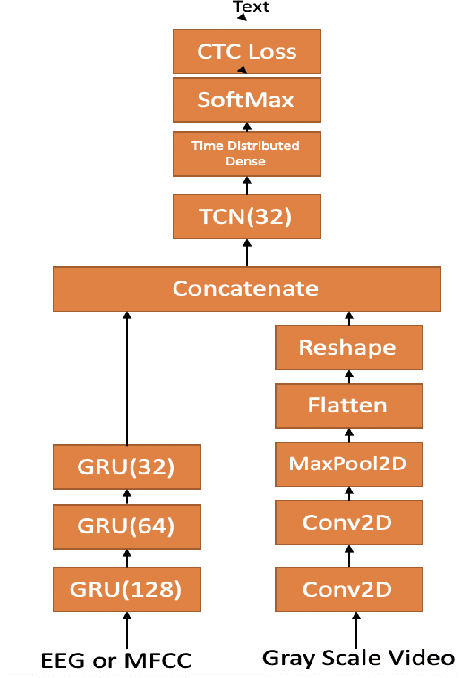
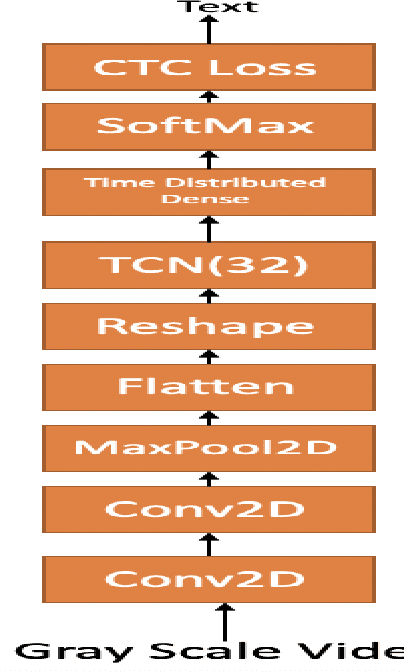
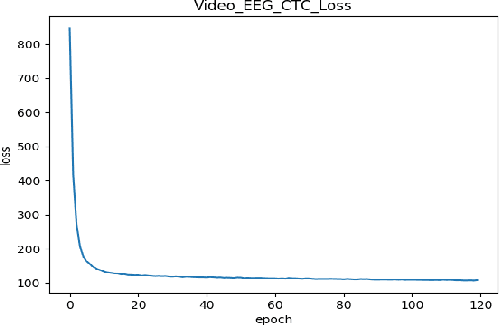
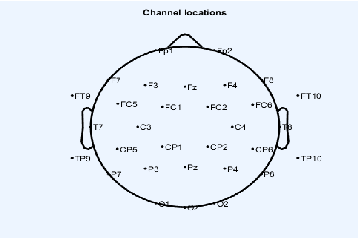
In this paper we investigate whether electroencephalography (EEG) features can be used to improve the performance of continuous visual speech recognition systems. We implemented a connectionist temporal classification (CTC) based end-to-end automatic speech recognition (ASR) model for performing recognition.