 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
RescoreBERT: Discriminative Speech Recognition Rescoring with BERT
Feb 07, 2022
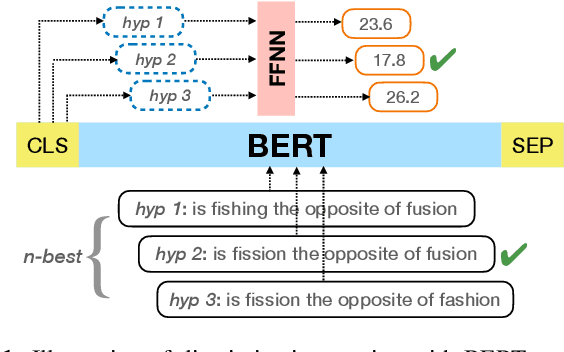
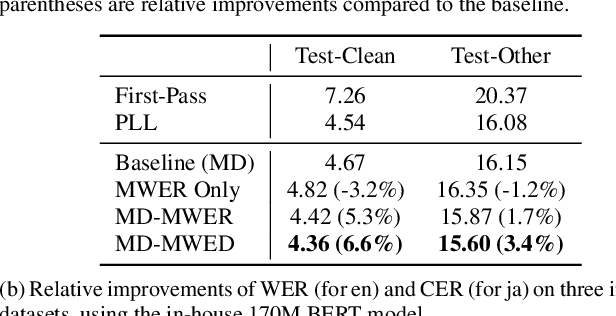

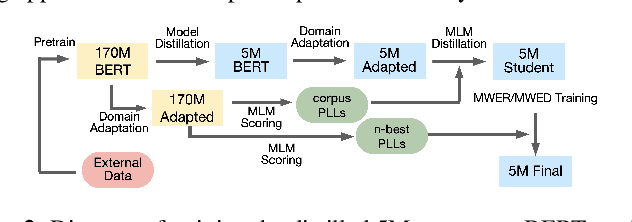
Second-pass rescoring is an important component in automatic speech recognition (ASR) systems that is used to improve the outputs from a first-pass decoder by implementing a lattice rescoring or $n$-best re-ranking. While pretraining with a masked language model (MLM) objective has received great success in various natural language understanding (NLU) tasks, it has not gained traction as a rescoring model for ASR. Specifically, training a bidirectional model like BERT on a discriminative objective such as minimum WER (MWER) has not been explored. Here we show how to train a BERT-based rescoring model with MWER loss, to incorporate the improvements of a discriminative loss into fine-tuning of deep bidirectional pretrained models for ASR. Specifically, we propose a fusion strategy that incorporates the MLM into the discriminative training process to effectively distill knowledge from a pretrained model. We further propose an alternative discriminative loss. We name this approach RescoreBERT. On the LibriSpeech corpus, it reduces WER by 6.6%/3.4% relative on clean/other test sets over a BERT baseline without discriminative objective. We also evaluate our method on an internal dataset from a conversational agent and find that it reduces both latency and WER (by 3 to 8% relative) over an LSTM rescoring model.
QuickVC: Many-to-any Voice Conversion Using Inverse Short-time Fourier Transform for Faster Conversion
Feb 20, 2023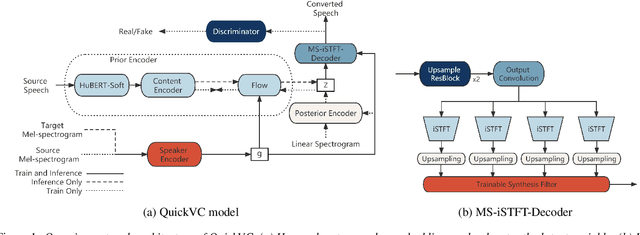
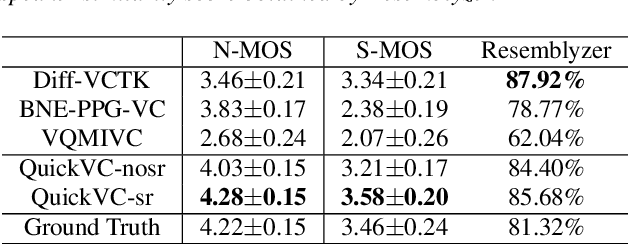

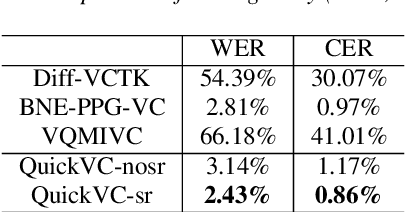
With the development of automatic speech recognition (ASR) and text-to-speech (TTS) technology, high-quality voice conversion (VC) can be achieved by extracting source content information and target speaker information to reconstruct waveforms. However, current methods still require improvement in terms of inference speed. In this study, we propose a lightweight VITS-based VC model that uses the HuBERT-Soft model to extract content information features without speaker information. Through subjective and objective experiments on synthesized speech, the proposed model demonstrates competitive results in terms of naturalness and similarity. Importantly, unlike the original VITS model, we use the inverse short-time Fourier transform (iSTFT) to replace the most computationally expensive part. Experimental results show that our model can generate samples at over 5000 kHz on the 3090 GPU and over 250 kHz on the i9-10900K CPU, achieving competitive speed for the same hardware configuration.
EmoSpeech: Guiding FastSpeech2 Towards Emotional Text to Speech
Jun 28, 2023State-of-the-art speech synthesis models try to get as close as possible to the human voice. Hence, modelling emotions is an essential part of Text-To-Speech (TTS) research. In our work, we selected FastSpeech2 as the starting point and proposed a series of modifications for synthesizing emotional speech. According to automatic and human evaluation, our model, EmoSpeech, surpasses existing models regarding both MOS score and emotion recognition accuracy in generated speech. We provided a detailed ablation study for every extension to FastSpeech2 architecture that forms EmoSpeech. The uneven distribution of emotions in the text is crucial for better, synthesized speech and intonation perception. Our model includes a conditioning mechanism that effectively handles this issue by allowing emotions to contribute to each phone with varying intensity levels. The human assessment indicates that proposed modifications generate audio with higher MOS and emotional expressiveness.
Revisiting joint decoding based multi-talker speech recognition with DNN acoustic model
Oct 31, 2021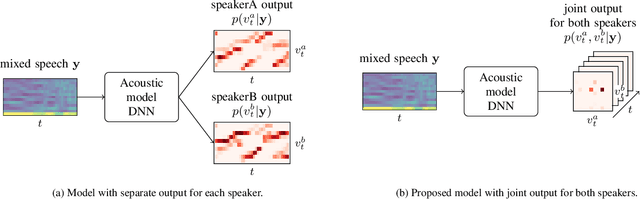
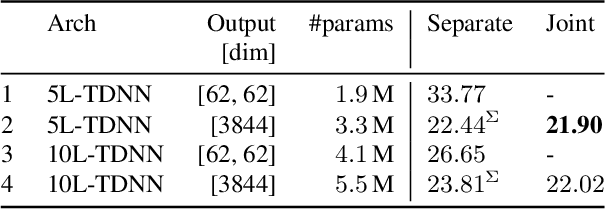
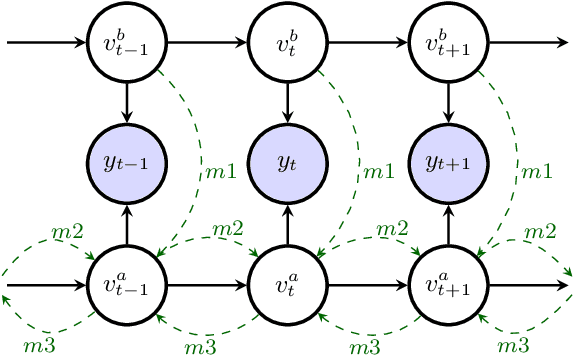
In typical multi-talker speech recognition systems, a neural network-based acoustic model predicts senone state posteriors for each speaker. These are later used by a single-talker decoder which is applied on each speaker-specific output stream separately. In this work, we argue that such a scheme is sub-optimal and propose a principled solution that decodes all speakers jointly. We modify the acoustic model to predict joint state posteriors for all speakers, enabling the network to express uncertainty about the attribution of parts of the speech signal to the speakers. We employ a joint decoder that can make use of this uncertainty together with higher-level language information. For this, we revisit decoding algorithms used in factorial generative models in early multi-talker speech recognition systems. In contrast with these early works, we replace the GMM acoustic model with DNN, which provides greater modeling power and simplifies part of the inference. We demonstrate the advantage of joint decoding in proof of concept experiments on a mixed-TIDIGITS dataset.
Summary on the ISCSLP 2022 Chinese-English Code-Switching ASR Challenge
Oct 13, 2022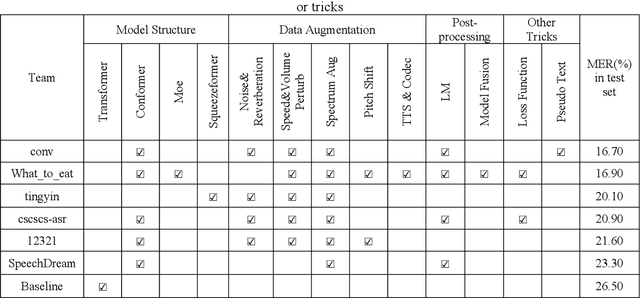
Code-switching automatic speech recognition becomes one of the most challenging and the most valuable scenarios of automatic speech recognition, due to the code-switching phenomenon between multilingual language and the frequent occurrence of code-switching phenomenon in daily life. The ISCSLP 2022 Chinese-English Code-Switching Automatic Speech Recognition (CSASR) Challenge aims to promote the development of code-switching automatic speech recognition. The ISCSLP 2022 CSASR challenge provided two training sets, TAL_CSASR corpus and MagicData-RAMC corpus, a development and a test set for participants, which are used for CSASR model training and evaluation. Along with the challenge, we also provide the baseline system performance for reference. As a result, more than 40 teams participated in this challenge, and the winner team achieved 16.70% Mixture Error Rate (MER) performance on the test set and has achieved 9.8% MER absolute improvement compared with the baseline system. In this paper, we will describe the datasets, the associated baselines system and the requirements, and summarize the CSASR challenge results and major techniques and tricks used in the submitted systems.
Mel Frequency Spectral Domain Defenses against Adversarial Attacks on Speech Recognition Systems
Mar 29, 2022
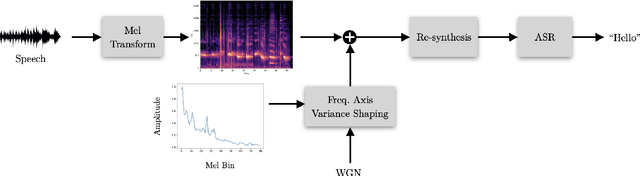

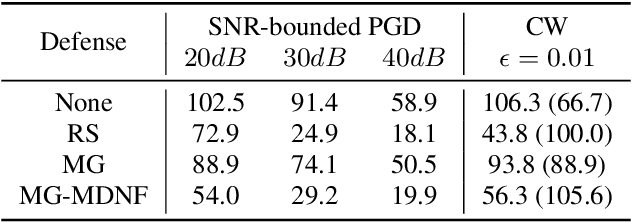
A variety of recent works have looked into defenses for deep neural networks against adversarial attacks particularly within the image processing domain. Speech processing applications such as automatic speech recognition (ASR) are increasingly relying on deep learning models, and so are also prone to adversarial attacks. However, many of the defenses explored for ASR simply adapt the image-domain defenses, which may not provide optimal robustness. This paper explores speech specific defenses using the mel spectral domain, and introduces a novel defense method called 'mel domain noise flooding' (MDNF). MDNF applies additive noise to the mel spectrogram of a speech utterance prior to re-synthesising the audio signal. We test the defenses against strong white-box adversarial attacks such as projected gradient descent (PGD) and Carlini-Wagner (CW) attacks, and show better robustness compared to a randomized smoothing baseline across strong threat models.
End-to-End Speech Recognition With Joint Dereverberation Of Sub-Band Autoregressive Envelopes
Aug 09, 2021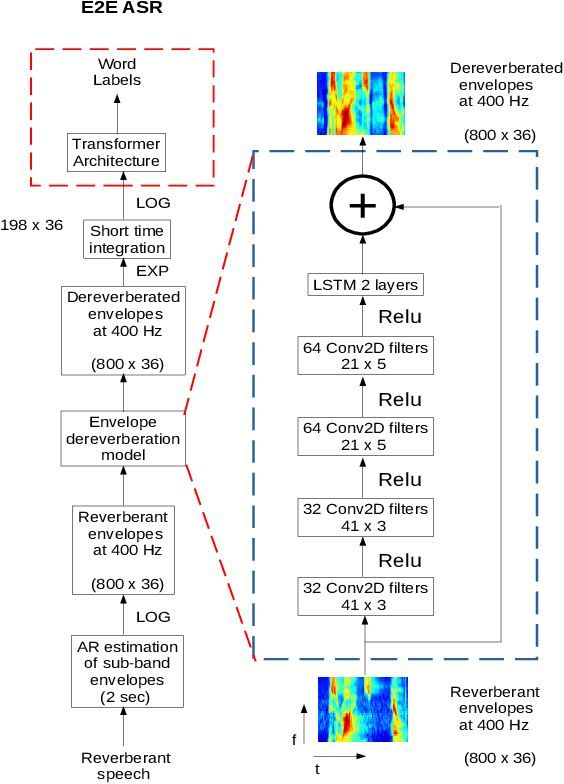
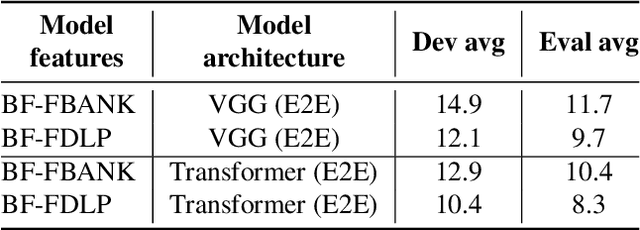
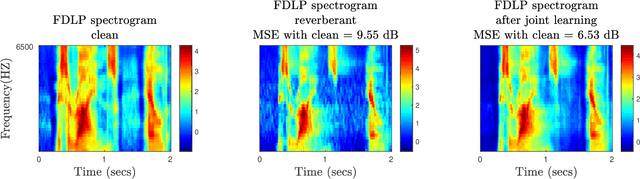
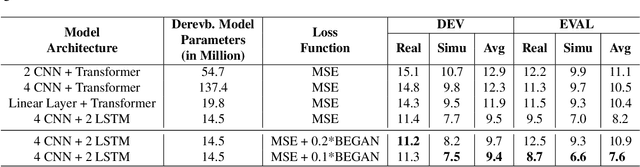
The end-to-end (E2E) automatic speech recognition (ASR) offers several advantages over previous efforts for recognizing speech. However, in reverberant conditions, E2E ASR is a challenging task as the long-term sub-band envelopes of the reverberant speech are temporally smeared. In this paper, we develop a feature enhancement approach using a neural model operating on sub-band temporal envelopes. The temporal envelopes are modeled using the framework of frequency domain linear prediction (FDLP). The neural enhancement model proposed in this paper performs an envelope gain based enhancement of temporal envelopes. The model architecture consists of a combination of convolutional and long short term memory (LSTM) neural network layers. Further, the envelope dereverberation, feature extraction and acoustic modeling using transformer based E2E ASR can all be jointly optimized for the speech recognition task. The joint optimization ensures that the dereverberation model targets the ASR cost function. We perform E2E speech recognition experiments on the REVERB challenge dataset as well as on the VOiCES dataset. In these experiments, the proposed joint modeling approach yields significant improvements compared to baseline E2E ASR system (average relative improvements of 21% on the REVERB challenge dataset and about 10% on the VOiCES dataset).
Word Order Does Not Matter For Speech Recognition
Oct 18, 2021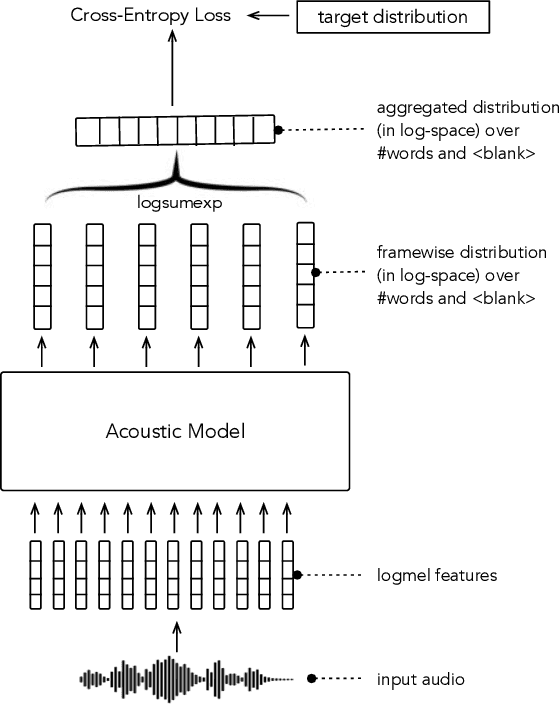
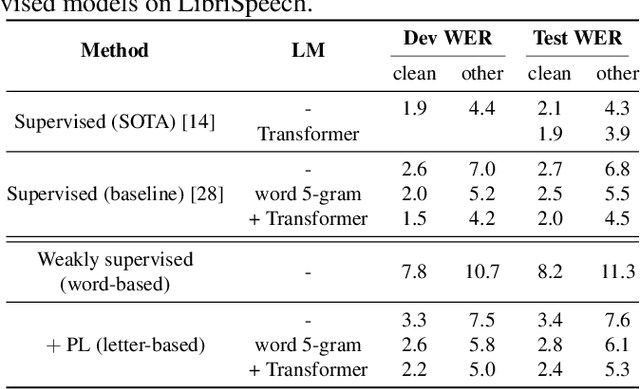
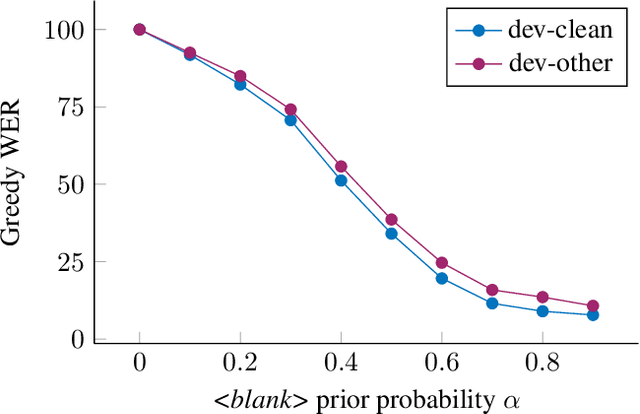

In this paper, we study training of automatic speech recognition system in a weakly supervised setting where the order of words in transcript labels of the audio training data is not known. We train a word-level acoustic model which aggregates the distribution of all output frames using LogSumExp operation and uses a cross-entropy loss to match with the ground-truth words distribution. Using the pseudo-labels generated from this model on the training set, we then train a letter-based acoustic model using Connectionist Temporal Classification loss. Our system achieves 2.3%/4.6% on test-clean/test-other subsets of LibriSpeech, which closely matches with the supervised baseline's performance.
OkwuGbé: End-to-End Speech Recognition for Fon and Igbo
Mar 16, 2021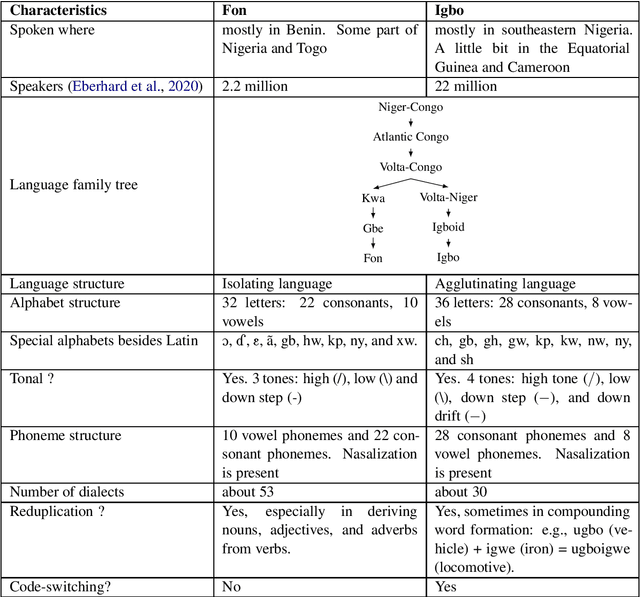
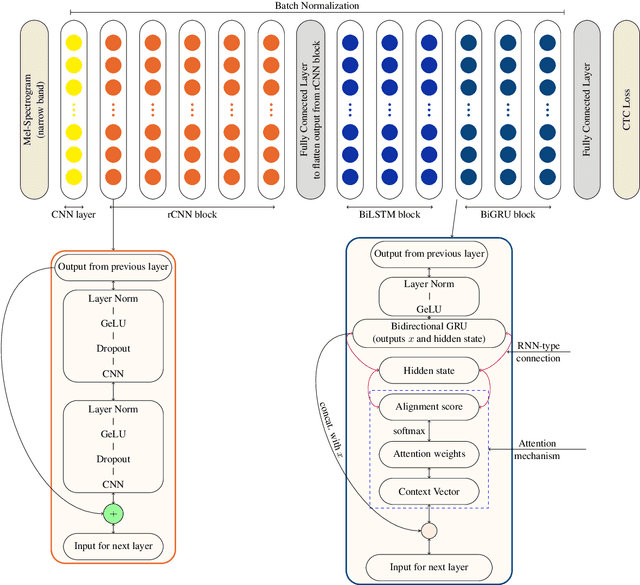
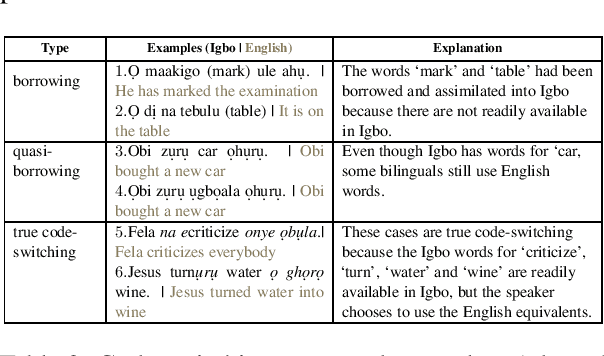
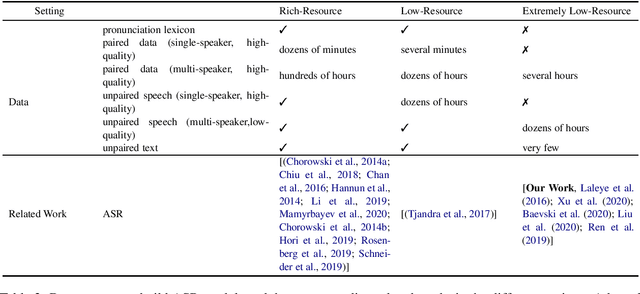
Language is inherent and compulsory for human communication. Whether expressed in a written or spoken way, it ensures understanding between people of the same and different regions. With the growing awareness and effort to include more low-resourced languages in NLP research, African languages have recently been a major subject of research in machine translation, and other text-based areas of NLP. However, there is still very little comparable research in speech recognition for African languages. Interestingly, some of the unique properties of African languages affecting NLP, like their diacritical and tonal complexities, have a major root in their speech, suggesting that careful speech interpretation could provide more intuition on how to deal with the linguistic complexities of African languages for text-based NLP. OkwuGb\'e is a step towards building speech recognition systems for African low-resourced languages. Using Fon and Igbo as our case study, we conduct a comprehensive linguistic analysis of each language and describe the creation of end-to-end, deep neural network-based speech recognition models for both languages. We present a state-of-art ASR model for Fon, as well as benchmark ASR model results for Igbo. Our linguistic analyses (for Fon and Igbo) provide valuable insights and guidance into the creation of speech recognition models for other African low-resourced languages, as well as guide future NLP research for Fon and Igbo. The Fon and Igbo models source code have been made publicly available.