 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
An ASR-free Fluency Scoring Approach with Self-Supervised Learning
Mar 13, 2023
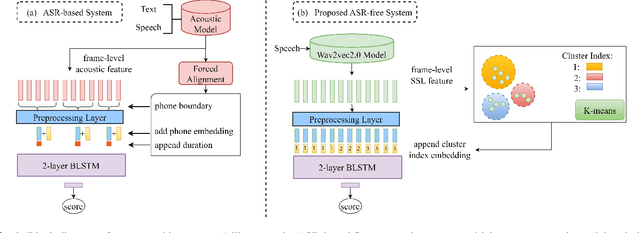
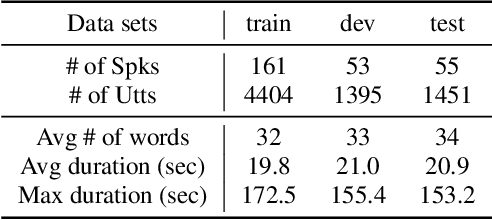
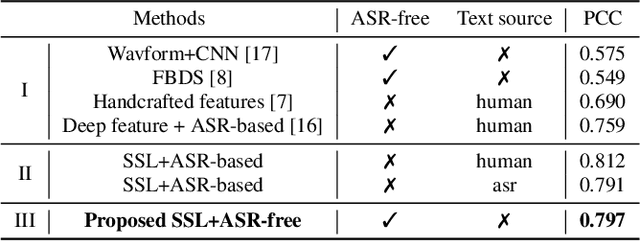
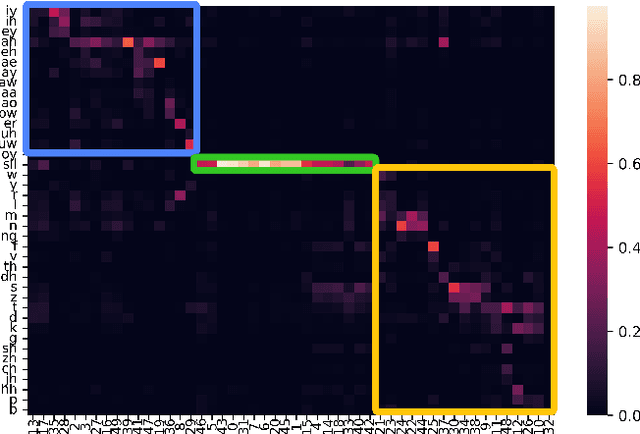
A typical fluency scoring system generally relies on an automatic speech recognition (ASR) system to obtain time stamps in input speech for either the subsequent calculation of fluency-related features or directly modeling speech fluency with an end-to-end approach. This paper describes a novel ASR-free approach for automatic fluency assessment using self-supervised learning (SSL). Specifically, wav2vec2.0 is used to extract frame-level speech features, followed by K-means clustering to assign a pseudo label (cluster index) to each frame. A BLSTM-based model is trained to predict an utterance-level fluency score from frame-level SSL features and the corresponding cluster indexes. Neither speech transcription nor time stamp information is required in the proposed system. It is ASR-free and can potentially avoid the ASR errors effect in practice. Experimental results carried out on non-native English databases show that the proposed approach significantly improves the performance in the "open response" scenario as compared to previous methods and matches the recently reported performance in the "read aloud" scenario.
A Dataset for Speech Emotion Recognition in Greek Theatrical Plays
Mar 27, 2022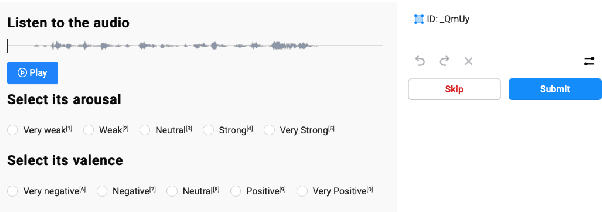
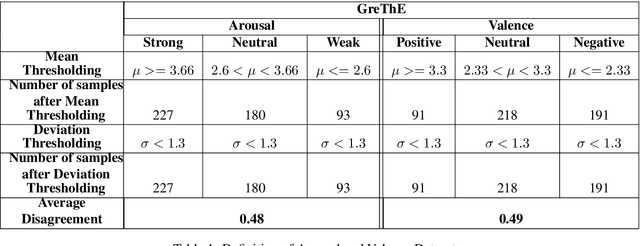
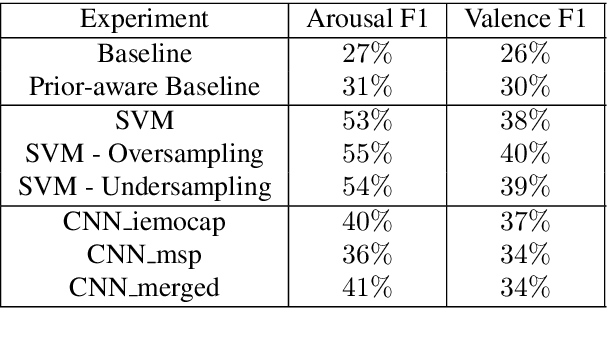
Machine learning methodologies can be adopted in cultural applications and propose new ways to distribute or even present the cultural content to the public. For instance, speech analytics can be adopted to automatically generate subtitles in theatrical plays, in order to (among other purposes) help people with hearing loss. Apart from a typical speech-to-text transcription with Automatic Speech Recognition (ASR), Speech Emotion Recognition (SER) can be used to automatically predict the underlying emotional content of speech dialogues in theatrical plays, and thus to provide a deeper understanding how the actors utter their lines. However, real-world datasets from theatrical plays are not available in the literature. In this work we present GreThE, the Greek Theatrical Emotion dataset, a new publicly available data collection for speech emotion recognition in Greek theatrical plays. The dataset contains utterances from various actors and plays, along with respective valence and arousal annotations. Towards this end, multiple annotators have been asked to provide their input for each speech recording and inter-annotator agreement is taken into account in the final ground truth generation. In addition, we discuss the results of some indicative experiments that have been conducted with machine and deep learning frameworks, using the dataset, along with some widely used databases in the field of speech emotion recognition.
A review of on-device fully neural end-to-end automatic speech recognition algorithms
Dec 19, 2020
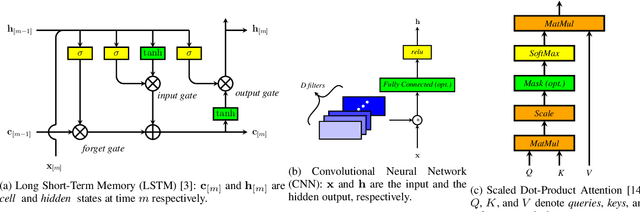
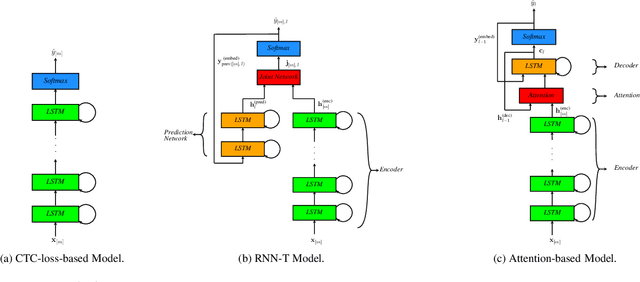
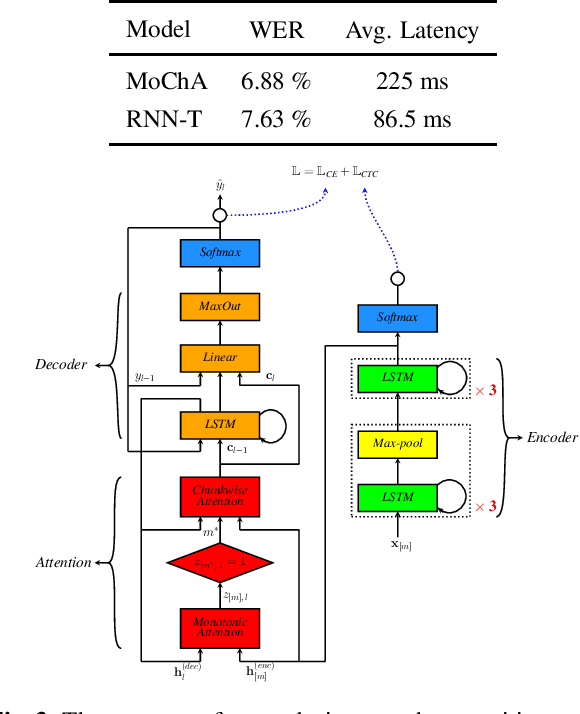
In this paper, we review various end-to-end automatic speech recognition algorithms and their optimization techniques for on-device applications. Conventional speech recognition systems comprise a large number of discrete components such as an acoustic model, a language model, a pronunciation model, a text-normalizer, an inverse-text normalizer, a decoder based on a Weighted Finite State Transducer (WFST), and so on. To obtain sufficiently high speech recognition accuracy with such conventional speech recognition systems, a very large language model (up to 100 GB) is usually needed. Hence, the corresponding WFST size becomes enormous, which prohibits their on-device implementation. Recently, fully neural network end-to-end speech recognition algorithms have been proposed. Examples include speech recognition systems based on Connectionist Temporal Classification (CTC), Recurrent Neural Network Transducer (RNN-T), Attention-based Encoder-Decoder models (AED), Monotonic Chunk-wise Attention (MoChA), transformer-based speech recognition systems, and so on. These fully neural network-based systems require much smaller memory footprints compared to conventional algorithms, therefore their on-device implementation has become feasible. In this paper, we review such end-to-end speech recognition models. We extensively discuss their structures, performance, and advantages compared to conventional algorithms.
Attention-based Contextual Language Model Adaptation for Speech Recognition
Jun 02, 2021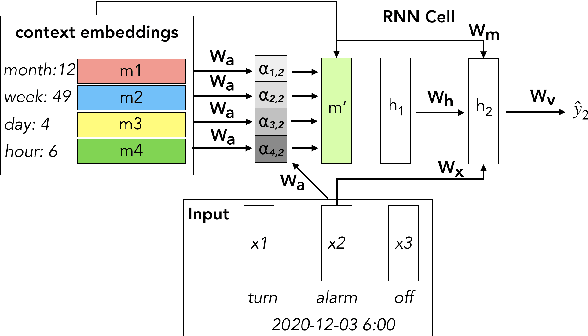
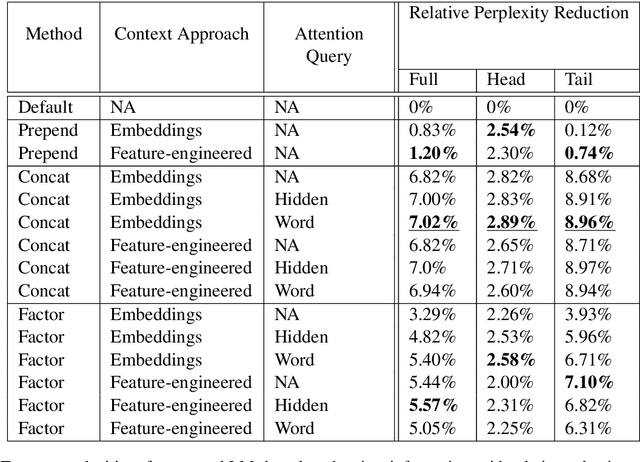
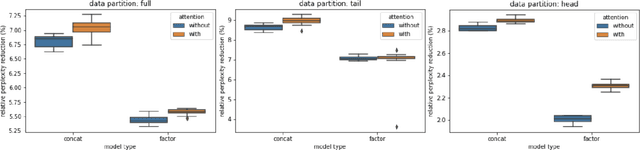
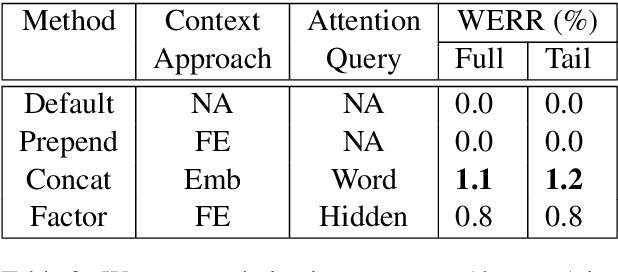
Language modeling (LM) for automatic speech recognition (ASR) does not usually incorporate utterance level contextual information. For some domains like voice assistants, however, additional context, such as the time at which an utterance was spoken, provides a rich input signal. We introduce an attention mechanism for training neural speech recognition language models on both text and non-linguistic contextual data. When applied to a large de-identified dataset of utterances collected by a popular voice assistant platform, our method reduces perplexity by 7.0% relative over a standard LM that does not incorporate contextual information. When evaluated on utterances extracted from the long tail of the dataset, our method improves perplexity by 9.0% relative over a standard LM and by over 2.8% relative when compared to a state-of-the-art model for contextual LM.
Speech Recognition by Simply Fine-tuning BERT
Jan 30, 2021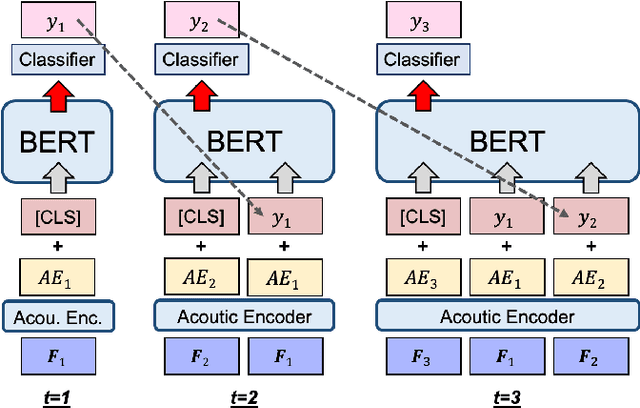
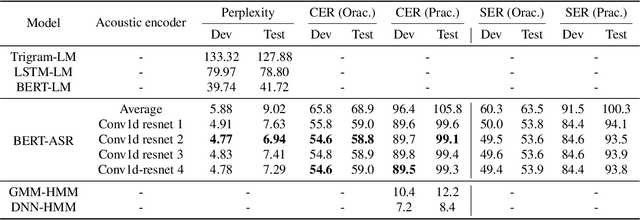
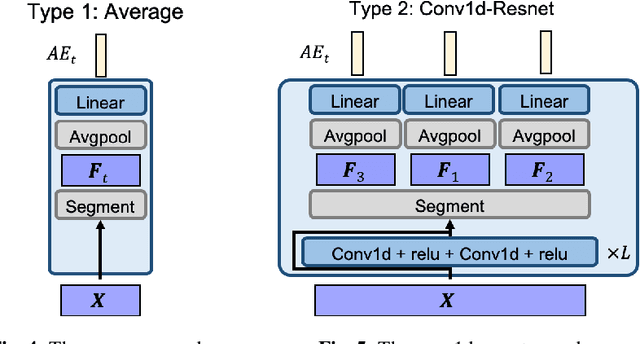
We propose a simple method for automatic speech recognition (ASR) by fine-tuning BERT, which is a language model (LM) trained on large-scale unlabeled text data and can generate rich contextual representations. Our assumption is that given a history context sequence, a powerful LM can narrow the range of possible choices and the speech signal can be used as a simple clue. Hence, comparing to conventional ASR systems that train a powerful acoustic model (AM) from scratch, we believe that speech recognition is possible by simply fine-tuning a BERT model. As an initial study, we demonstrate the effectiveness of the proposed idea on the AISHELL dataset and show that stacking a very simple AM on top of BERT can yield reasonable performance.
Investigating Self-supervised Pretraining Frameworks for Pathological Speech Recognition
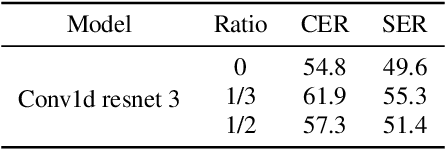
Mar 30, 2022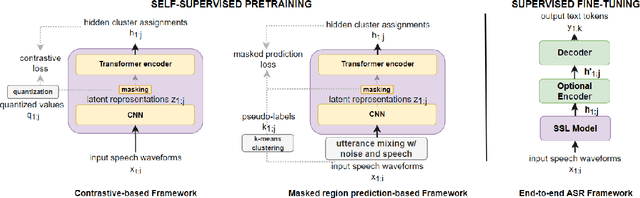
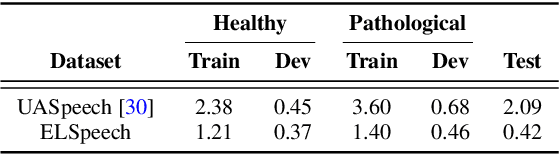
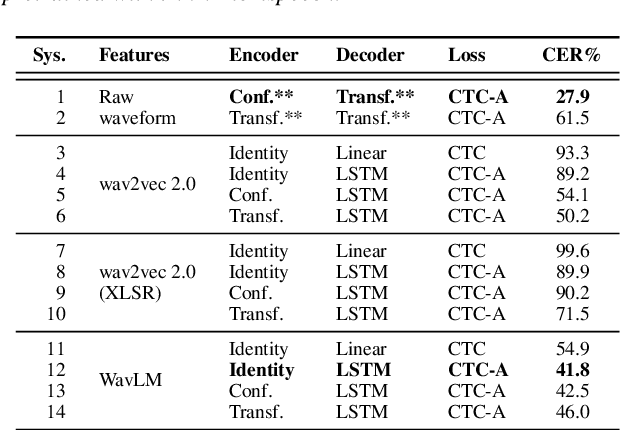
We investigate the performance of self-supervised pretraining frameworks on pathological speech datasets used for automatic speech recognition (ASR). Modern end-to-end models require thousands of hours of data to train well, but only a small number of pathological speech datasets are publicly available. A proven solution to this problem is by first pretraining the model on a huge number of healthy speech datasets and then fine-tuning it on the pathological speech datasets. One new pretraining framework called self-supervised learning (SSL) trains a network using only speech data, providing more flexibility in training data requirements and allowing more speech data to be used in pretraining. We investigate SSL frameworks such as the wav2vec 2.0 and WavLM models using different setups and compare their performance with different supervised pretraining setups, using two types of pathological speech, namely, Japanese electrolaryngeal and English dysarthric. Although the SSL setup is promising against Transformer-based supervised setups, other supervised setups such as the Conformer still outperform SSL pretraining. Our results show that the best supervised setup outperforms the best SSL setup by 13.9% character error rate in electrolaryngeal speech and 16.8% word error rate in dysarthric speech.
Exploiting Single-Channel Speech For Multi-channel End-to-end Speech Recognition
Jul 06, 2021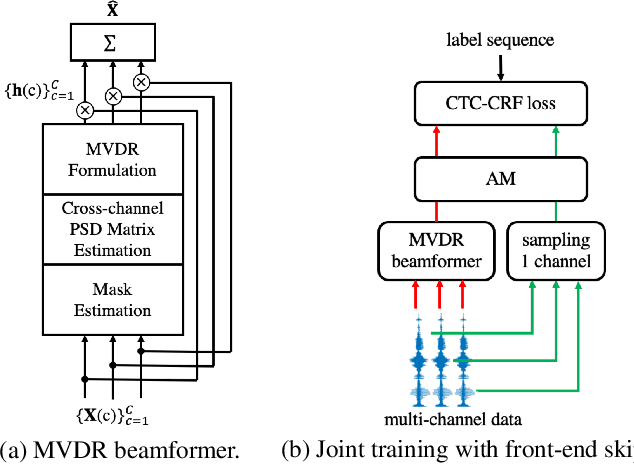

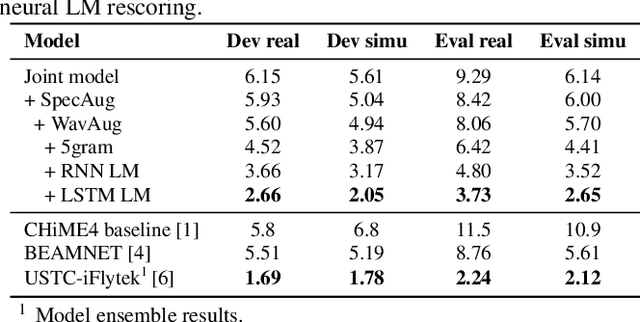
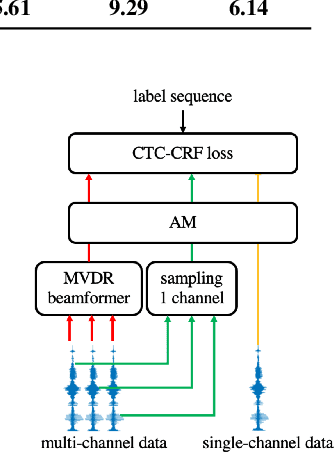
Recently, the end-to-end training approach for neural beamformer-supported multi-channel ASR has shown its effectiveness in multi-channel speech recognition. However, the integration of multiple modules makes it more difficult to perform end-to-end training, particularly given that the multi-channel speech corpus recorded in real environments with a sizeable data scale is relatively limited. This paper explores the usage of single-channel data to improve the multi-channel end-to-end speech recognition system. Specifically, we design three schemes to exploit the single-channel data, namely pre-training, data scheduling, and data simulation. Extensive experiments on CHiME4 and AISHELL-4 datasets demonstrate that all three methods improve the multi-channel end-to-end training stability and speech recognition performance, while the data scheduling approach keeps a much simpler pipeline (vs. pre-training) and less computation cost (vs. data simulation). Moreover, we give a thorough analysis of our systems, including how the performance is affected by the choice of front-end, the data augmentation, training strategy, and single-channel data size.
QuickVC: Any-to-many Voice Conversion Using Inverse Short-time Fourier Transform for Faster Conversion
Feb 23, 2023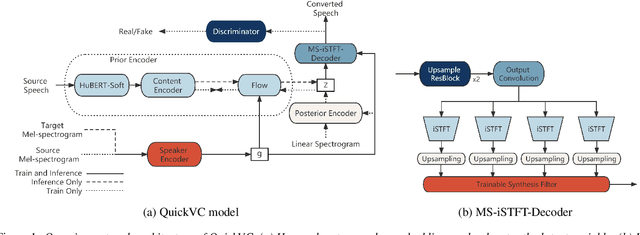
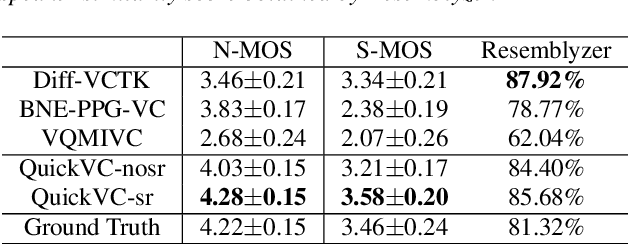

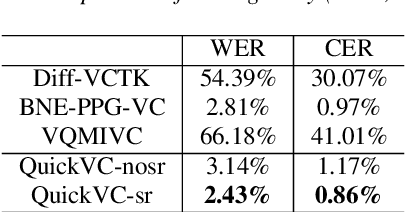
With the development of automatic speech recognition (ASR) and text-to-speech (TTS) technology, high-quality voice conversion (VC) can be achieved by extracting source content information and target speaker information to reconstruct waveforms. However, current methods still require improvement in terms of inference speed. In this study, we propose a lightweight VITS-based VC model that uses the HuBERT-Soft model to extract content information features without speaker information. Through subjective and objective experiments on synthesized speech, the proposed model demonstrates competitive results in terms of naturalness and similarity. Importantly, unlike the original VITS model, we use the inverse short-time Fourier transform (iSTFT) to replace the most computationally expensive part. Experimental results show that our model can generate samples at over 5000 kHz on the 3090 GPU and over 250 kHz on the i9-10900K CPU, achieving competitive speed for the same hardware configuration.
Speaker conditioning of acoustic models using affine transformation for multi-speaker speech recognition
Oct 30, 2021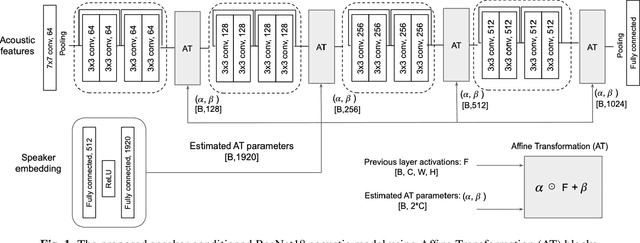
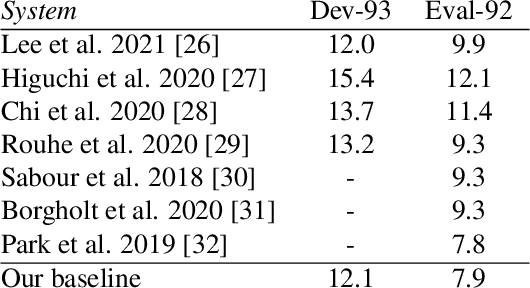
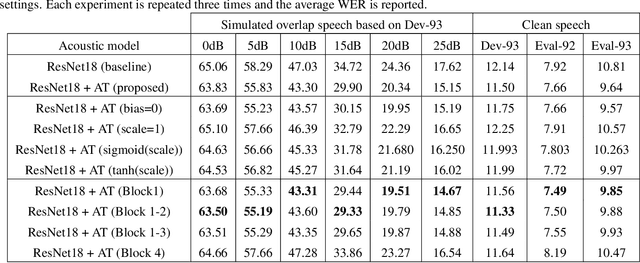
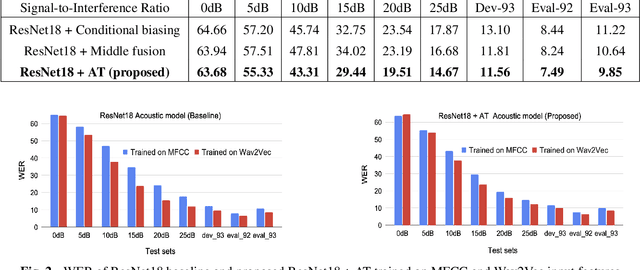
This study addresses the problem of single-channel Automatic Speech Recognition of a target speaker within an overlap speech scenario. In the proposed method, the hidden representations in the acoustic model are modulated by speaker auxiliary information to recognize only the desired speaker. Affine transformation layers are inserted into the acoustic model network to integrate speaker information with the acoustic features. The speaker conditioning process allows the acoustic model to perform computation in the context of target-speaker auxiliary information. The proposed speaker conditioning method is a general approach and can be applied to any acoustic model architecture. Here, we employ speaker conditioning on a ResNet acoustic model. Experiments on the WSJ corpus show that the proposed speaker conditioning method is an effective solution to fuse speaker auxiliary information with acoustic features for multi-speaker speech recognition, achieving +9% and +20% relative WER reduction for clean and overlap speech scenarios, respectively, compared to the original ResNet acoustic model baseline.