 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Lego-Features: Exporting modular encoder features for streaming and deliberation ASR
Mar 31, 2023
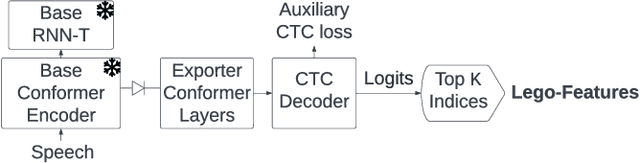
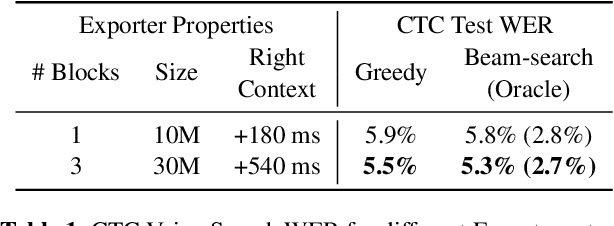
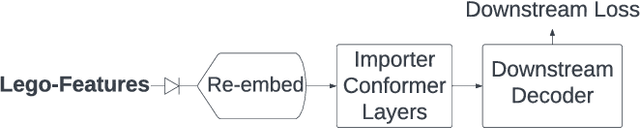

In end-to-end (E2E) speech recognition models, a representational tight-coupling inevitably emerges between the encoder and the decoder. We build upon recent work that has begun to explore building encoders with modular encoded representations, such that encoders and decoders from different models can be stitched together in a zero-shot manner without further fine-tuning. While previous research only addresses full-context speech models, we explore the problem in a streaming setting as well. Our framework builds on top of existing encoded representations, converting them to modular features, dubbed as Lego-Features, without modifying the pre-trained model. The features remain interchangeable when the model is retrained with distinct initializations. Though sparse, we show that the Lego-Features are powerful when tested with RNN-T or LAS decoders, maintaining high-quality downstream performance. They are also rich enough to represent the first-pass prediction during two-pass deliberation. In this scenario, they outperform the N-best hypotheses, since they do not need to be supplemented with acoustic features to deliver the best results. Moreover, generating the Lego-Features does not require beam search or auto-regressive computation. Overall, they present a modular, powerful and cheap alternative to the standard encoder output, as well as the N-best hypotheses.
Continuous Speech Recognition using EEG and Video
Dec 27, 2019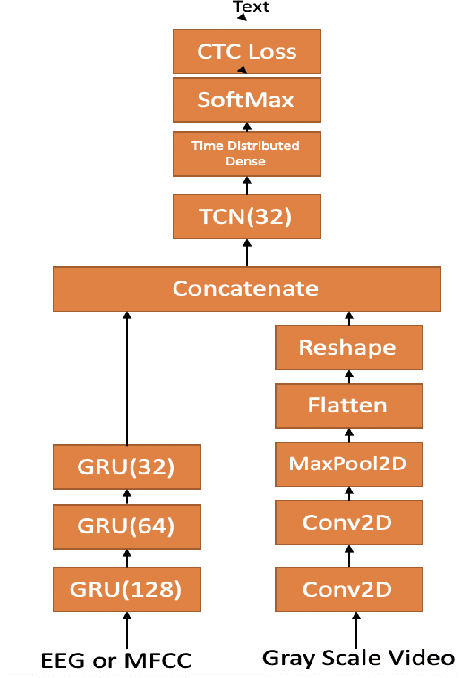
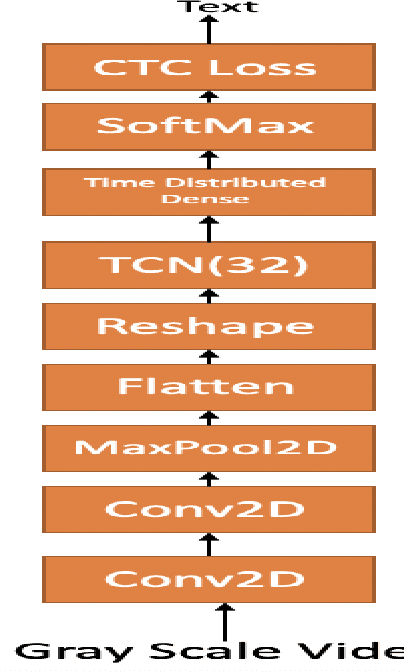
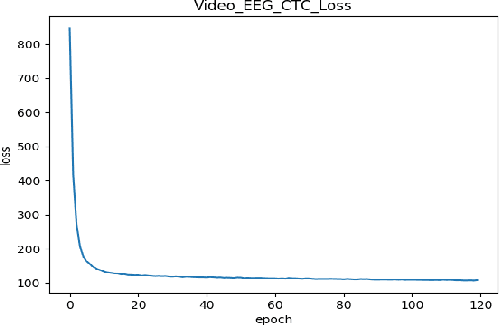
In this paper we investigate whether electroencephalography (EEG) features can be used to improve the performance of continuous visual speech recognition systems. We implemented a connectionist temporal classification (CTC) based end-to-end automatic speech recognition (ASR) model for performing recognition. Our results demonstrate that EEG features are helpful in enhancing the performance of continuous visual speech recognition systems.
Subword Dictionary Learning and Segmentation Techniques for Automatic Speech Recognition in Tamil and Kannada
Jul 27, 2022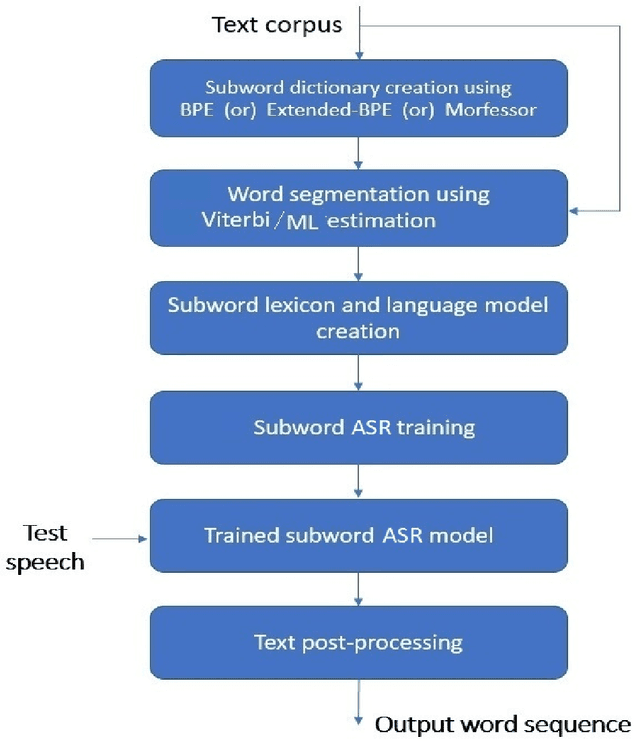
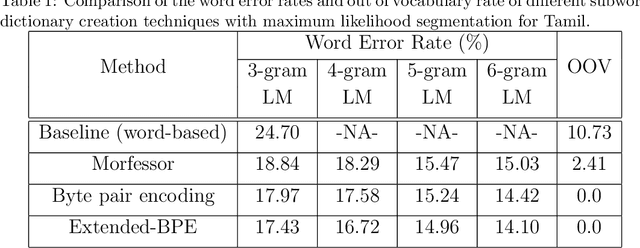
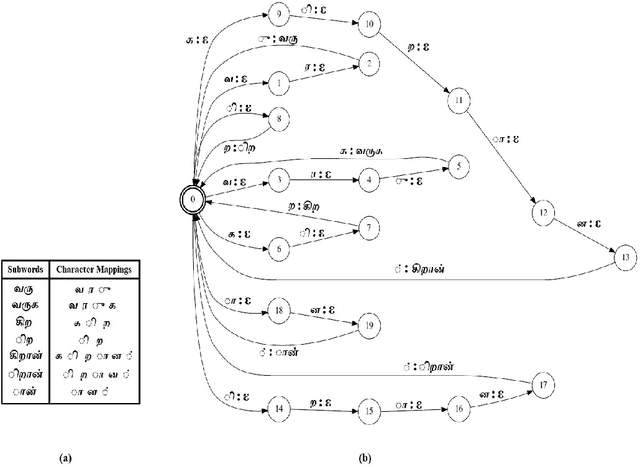
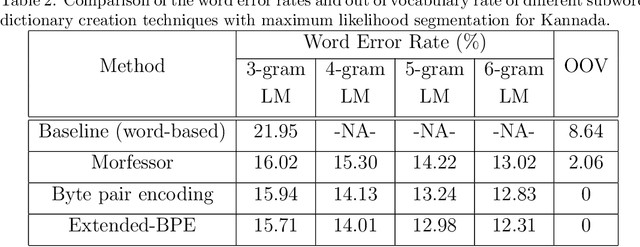
We present automatic speech recognition (ASR) systems for Tamil and Kannada based on subword modeling to effectively handle unlimited vocabulary due to the highly agglutinative nature of the languages. We explore byte pair encoding (BPE), and proposed a variant of this algorithm named extended-BPE, and Morfessor tool to segment each word as subwords. We have effectively incorporated maximum likelihood (ML) and Viterbi estimation techniques with weighted finite state transducers (WFST) framework in these algorithms to learn the subword dictionary from a large text corpus. Using the learnt subword dictionary, the words in training data transcriptions are segmented to subwords and we train deep neural network ASR systems which recognize subword sequence for any given test speech utterance. The output subword sequence is then post-processed using deterministic rules to get the final word sequence such that the actual number of words that can be recognized is much larger. For Tamil ASR, We use 152 hours of data for training and 65 hours for testing, whereas for Kannada ASR, we use 275 hours for training and 72 hours for testing. Upon experimenting with different combination of segmentation and estimation techniques, we find that the word error rate (WER) reduces drastically when compared to the baseline word-level ASR, achieving a maximum absolute WER reduction of 6.24% and 6.63% for Tamil and Kannada respectively.
Significance of Data Augmentation for Improving Cleft Lip and Palate Speech Recognition
Oct 02, 2021
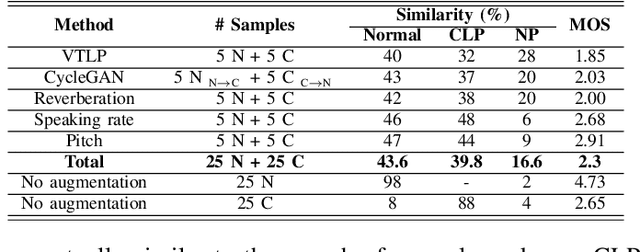
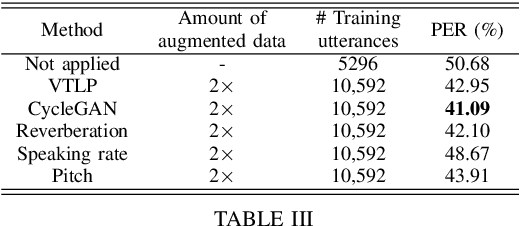
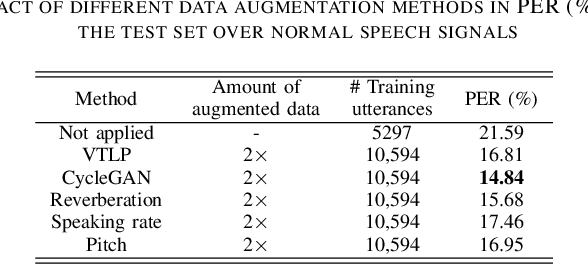
The automatic recognition of pathological speech, particularly from children with any articulatory impairment, is a challenging task due to various reasons. The lack of available domain specific data is one such obstacle that hinders its usage for different speech-based applications targeting pathological speakers. In line with the challenge, in this work, we investigate a few data augmentation techniques to simulate training data for improving the children speech recognition considering the case of cleft lip and palate (CLP) speech. The augmentation techniques explored in this study, include vocal tract length perturbation (VTLP), reverberation, speaking rate, pitch modification, and speech feature modification using cycle consistent adversarial networks (CycleGAN). Our study finds that the data augmentation methods significantly improve the CLP speech recognition performance, which is more evident when we used feature modification using CycleGAN, VTLP and reverberation based methods. More specifically, the results from this study show that our systems produce an improved phone error rate compared to the systems without data augmentation.
Zero-Shot Cross-lingual Aphasia Detection using Automatic Speech Recognition
Apr 01, 2022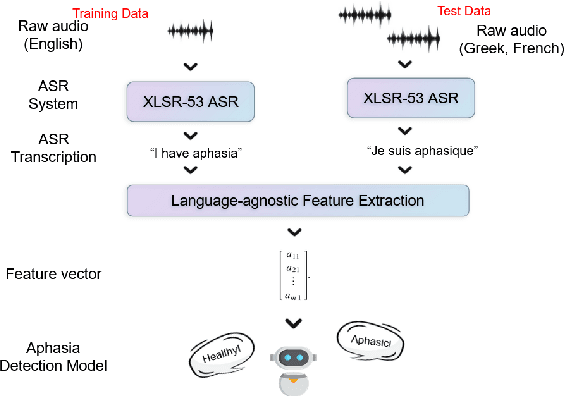
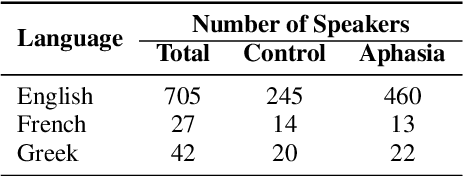
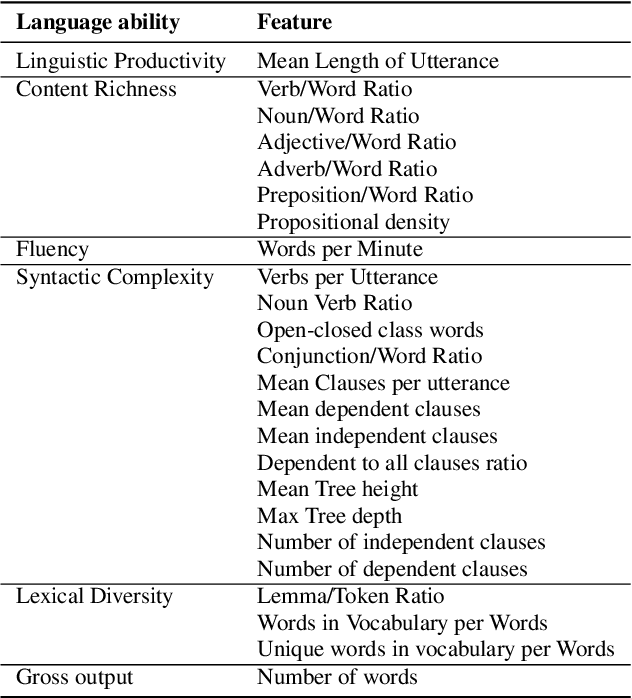
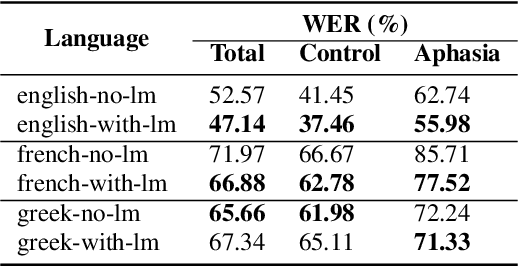
Aphasia is a common speech and language disorder, typically caused by a brain injury or a stroke, that affects millions of people worldwide. Detecting and assessing Aphasia in patients is a difficult, time-consuming process, and numerous attempts to automate it have been made, the most successful using machine learning models trained on aphasic speech data. Like in many medical applications, aphasic speech data is scarce and the problem is exacerbated in so-called "low resource" languages, which are, for this task, most languages excluding English. We attempt to leverage available data in English and achieve zero-shot aphasia detection in low-resource languages such as Greek and French, by using language-agnostic linguistic features. Current cross-lingual aphasia detection approaches rely on manually extracted transcripts. We propose an end-to-end pipeline using pre-trained Automatic Speech Recognition (ASR) models that share cross-lingual speech representations and are fine-tuned for our desired low-resource languages. To further boost our ASR model's performance, we also combine it with a language model. We show that our ASR-based end-to-end pipeline offers comparable results to previous setups using human-annotated transcripts.
Adaptive Feature Fusion: Enhancing Generalization in Deep Learning Models
Apr 04, 2023In recent years, deep learning models have demonstrated remarkable success in various domains, such as computer vision, natural language processing, and speech recognition. However, the generalization capabilities of these models can be negatively impacted by the limitations of their feature fusion techniques. This paper introduces an innovative approach, Adaptive Feature Fusion (AFF), to enhance the generalization of deep learning models by dynamically adapting the fusion process of feature representations. The proposed AFF framework is designed to incorporate fusion layers into existing deep learning architectures, enabling seamless integration and improved performance. By leveraging a combination of data-driven and model-based fusion strategies, AFF is able to adaptively fuse features based on the underlying data characteristics and model requirements. This paper presents a detailed description of the AFF framework, including the design and implementation of fusion layers for various architectures. Extensive experiments are conducted on multiple benchmark datasets, with the results demonstrating the superiority of the AFF approach in comparison to traditional feature fusion techniques. The analysis showcases the effectiveness of AFF in enhancing generalization capabilities, leading to improved performance across different tasks and applications. Finally, the paper discusses various real-world use cases where AFF can be employed, providing insights into its practical applicability. The conclusion highlights the potential for future research directions, including the exploration of advanced fusion strategies and the extension of AFF to other machine learning paradigms.
LiteG2P: A fast, light and high accuracy model for grapheme-to-phoneme conversion
Mar 02, 2023
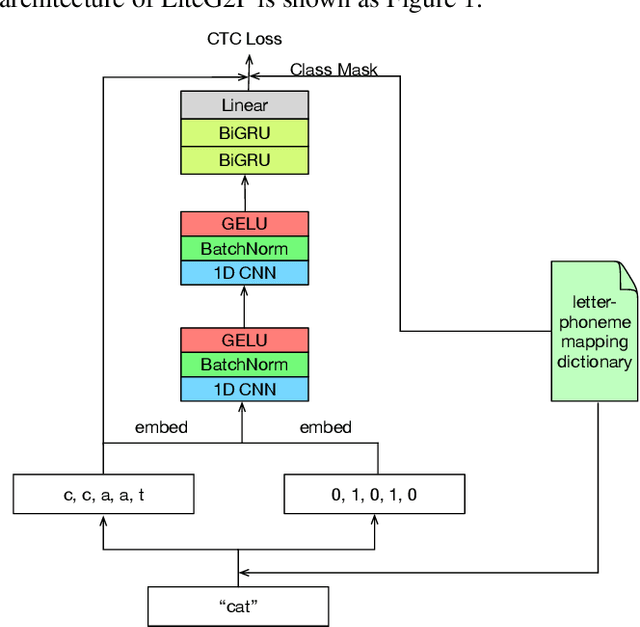
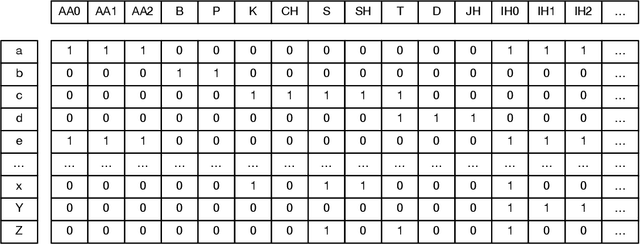
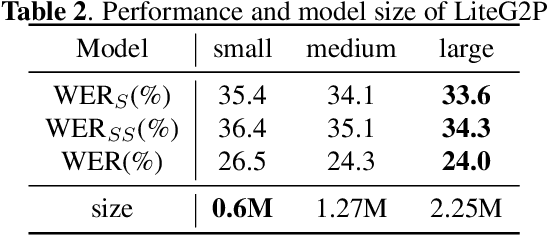
As a key component of automated speech recognition (ASR) and the front-end in text-to-speech (TTS), grapheme-to-phoneme (G2P) plays the role of converting letters to their corresponding pronunciations. Existing methods are either slow or poor in performance, and are limited in application scenarios, particularly in the process of on-device inference. In this paper, we integrate the advantages of both expert knowledge and connectionist temporal classification (CTC) based neural network and propose a novel method named LiteG2P which is fast, light and theoretically parallel. With the carefully leading design, LiteG2P can be applied both on cloud and on device. Experimental results on the CMU dataset show that the performance of the proposed method is superior to the state-of-the-art CTC based method with 10 times fewer parameters, and even comparable to the state-of-the-art Transformer-based sequence-to-sequence model with less parameters and 33 times less computation.
A Survey of Multilingual Models for Automatic Speech Recognition
Feb 25, 2022Although Automatic Speech Recognition (ASR) systems have achieved human-like performance for a few languages, the majority of the world's languages do not have usable systems due to the lack of large speech datasets to train these models. Cross-lingual transfer is an attractive solution to this problem, because low-resource languages can potentially benefit from higher-resource languages either through transfer learning, or being jointly trained in the same multilingual model. The problem of cross-lingual transfer has been well studied in ASR, however, recent advances in Self Supervised Learning are opening up avenues for unlabeled speech data to be used in multilingual ASR models, which can pave the way for improved performance on low-resource languages. In this paper, we survey the state of the art in multilingual ASR models that are built with cross-lingual transfer in mind. We present best practices for building multilingual models from research across diverse languages and techniques, discuss open questions and provide recommendations for future work.