 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Minimizing Sequential Confusion Error in Speech Command Recognition
Jul 04, 2022
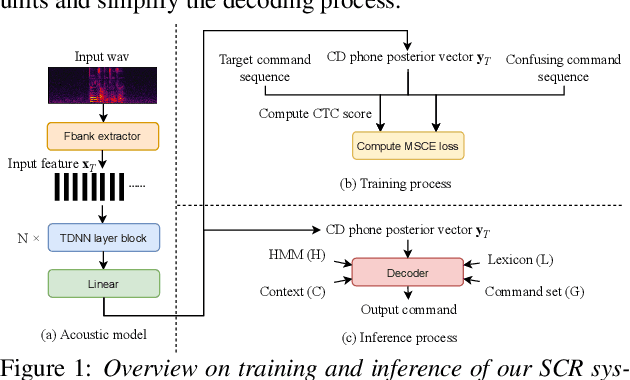
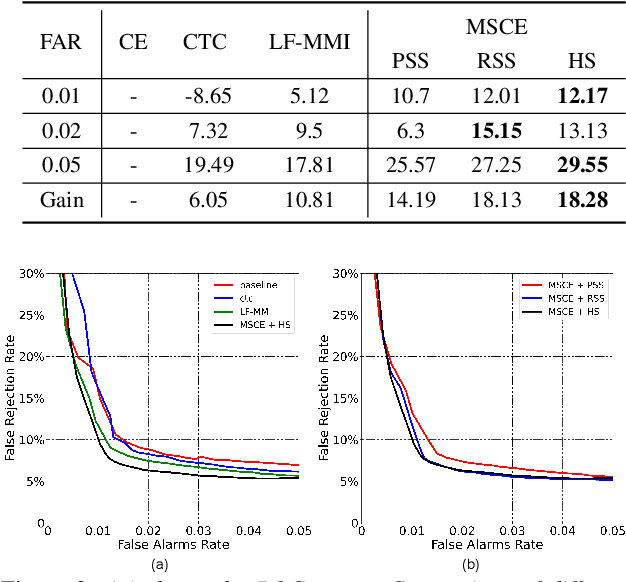
Speech command recognition (SCR) has been commonly used on resource constrained devices to achieve hands-free user experience. However, in real applications, confusion among commands with similar pronunciations often happens due to the limited capacity of small models deployed on edge devices, which drastically affects the user experience. In this paper, inspired by the advances of discriminative training in speech recognition, we propose a novel minimize sequential confusion error (MSCE) training criterion particularly for SCR, aiming to alleviate the command confusion problem. Specifically, we aim to improve the ability of discriminating the target command from other commands on the basis of MCE discriminative criteria. We define the likelihood of different commands through connectionist temporal classification (CTC). During training, we propose several strategies to use prior knowledge creating a confusing sequence set for similar-sounding command instead of creating the whole non-target command set, which can better save the training resources and effectively reduce command confusion errors. Specifically, we design and compare three different strategies for confusing set construction. By using our proposed method, we can relatively reduce the False Reject Rate~(FRR) by 33.7% at 0.01 False Alarm Rate~(FAR) and confusion errors by 18.28% on our collected speech command set.
An Overview on Language Models: Recent Developments and Outlook
Mar 10, 2023

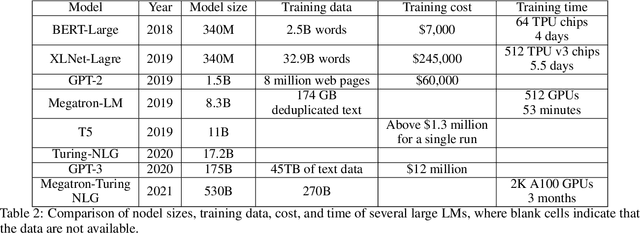
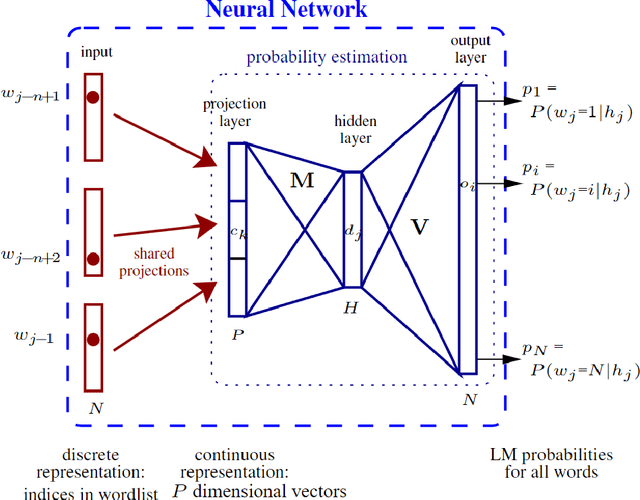
Language modeling studies the probability distributions over strings of texts. It is one of the most fundamental tasks in natural language processing (NLP). It has been widely used in text generation, speech recognition, machine translation, etc. Conventional language models (CLMs) aim to predict the probability of linguistic sequences in a causal manner. In contrast, pre-trained language models (PLMs) cover broader concepts and can be used in both causal sequential modeling and fine-tuning for downstream applications. PLMs have their own training paradigms (usually self-supervised) and serve as foundation models in modern NLP systems. This overview paper provides an introduction to both CLMs and PLMs from five aspects, i.e., linguistic units, structures, training methods, evaluation methods, and applications. Furthermore, we discuss the relationship between CLMs and PLMs and shed light on the future directions of language modeling in the pre-trained era.
Continuous Speech Recognition using EEG and Video
Dec 27, 2019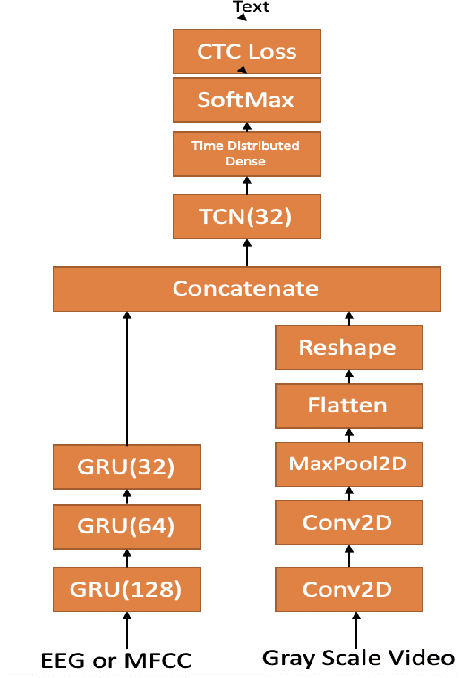
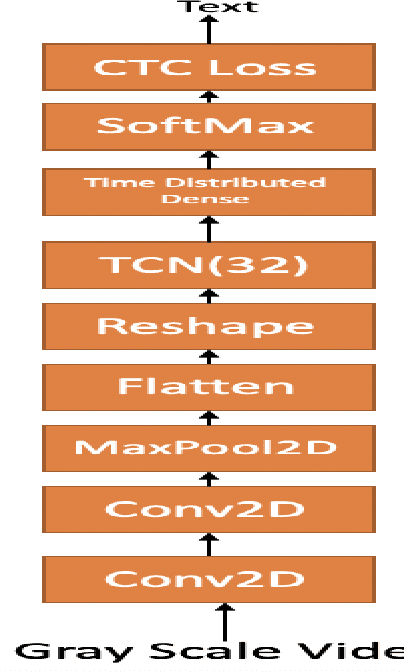
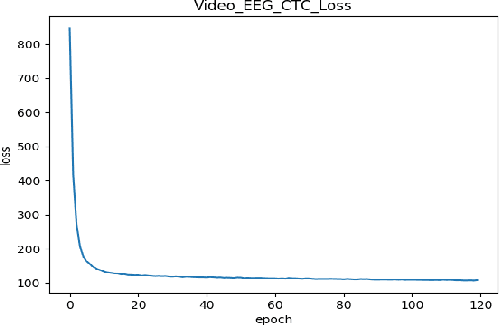
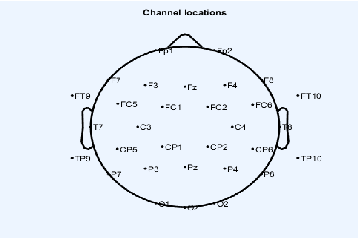
In this paper we investigate whether electroencephalography (EEG) features can be used to improve the performance of continuous visual speech recognition systems. We implemented a connectionist temporal classification (CTC) based end-to-end automatic speech recognition (ASR) model for performing recognition. Our results demonstrate that EEG features are helpful in enhancing the performance of continuous visual speech recognition systems.
Towards the Universal Defense for Query-Based Audio Adversarial Attacks
Apr 20, 2023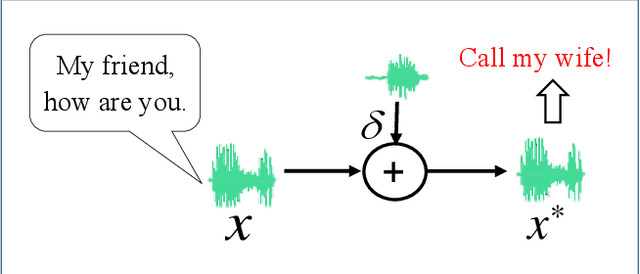

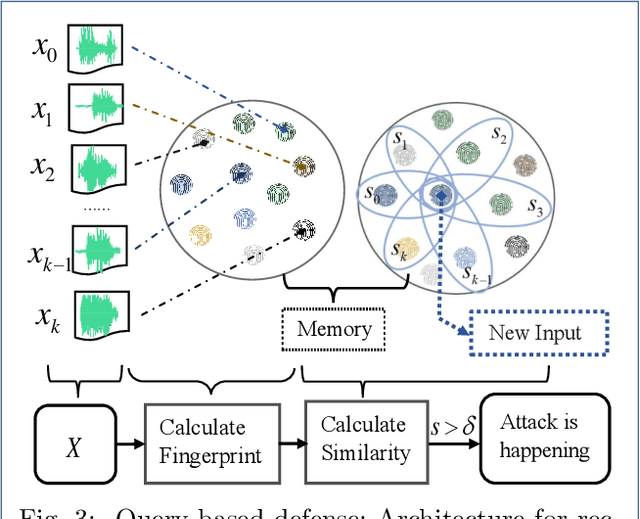
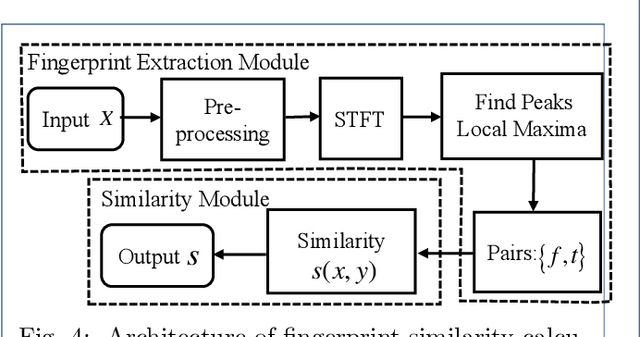
Recently, studies show that deep learning-based automatic speech recognition (ASR) systems are vulnerable to adversarial examples (AEs), which add a small amount of noise to the original audio examples. These AE attacks pose new challenges to deep learning security and have raised significant concerns about deploying ASR systems and devices. The existing defense methods are either limited in application or only defend on results, but not on process. In this work, we propose a novel method to infer the adversary intent and discover audio adversarial examples based on the AEs generation process. The insight of this method is based on the observation: many existing audio AE attacks utilize query-based methods, which means the adversary must send continuous and similar queries to target ASR models during the audio AE generation process. Inspired by this observation, We propose a memory mechanism by adopting audio fingerprint technology to analyze the similarity of the current query with a certain length of memory query. Thus, we can identify when a sequence of queries appears to be suspectable to generate audio AEs. Through extensive evaluation on four state-of-the-art audio AE attacks, we demonstrate that on average our defense identify the adversary intent with over 90% accuracy. With careful regard for robustness evaluations, we also analyze our proposed defense and its strength to withstand two adaptive attacks. Finally, our scheme is available out-of-the-box and directly compatible with any ensemble of ASR defense models to uncover audio AE attacks effectively without model retraining.
Flowchase: a Mobile Application for Pronunciation Training
Jul 05, 2023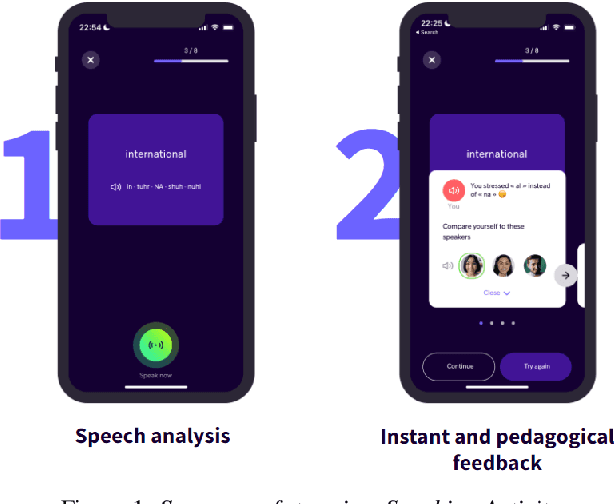
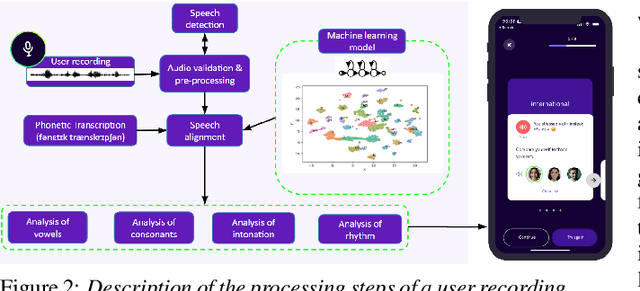

In this paper, we present a solution for providing personalized and instant feedback to English learners through a mobile application, called Flowchase, that is connected to a speech technology able to segment and analyze speech segmental and supra-segmental features. The speech processing pipeline receives linguistic information corresponding to an utterance to analyze along with a speech sample. After validation of the speech sample, a joint forced-alignment and phonetic recognition is performed thanks to a combination of machine learning models based on speech representation learning that provides necessary information for designing a feedback on a series of segmental and supra-segmental pronunciation aspects.
Visual Speech Recognition for Multiple Languages in the Wild
Feb 26, 2022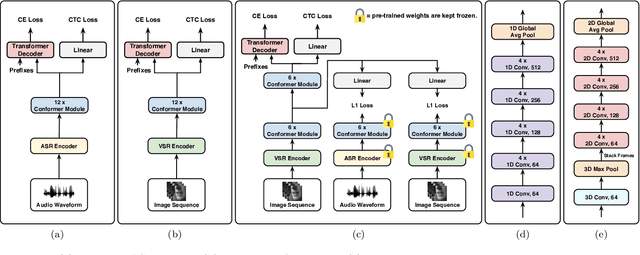
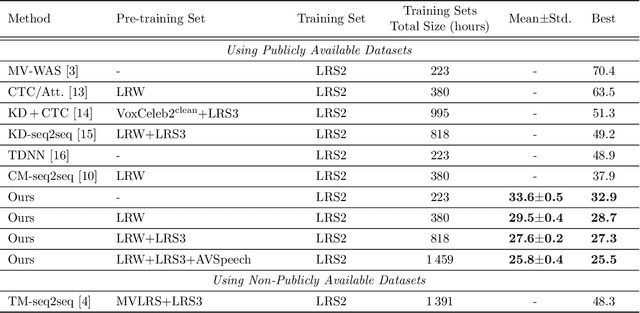
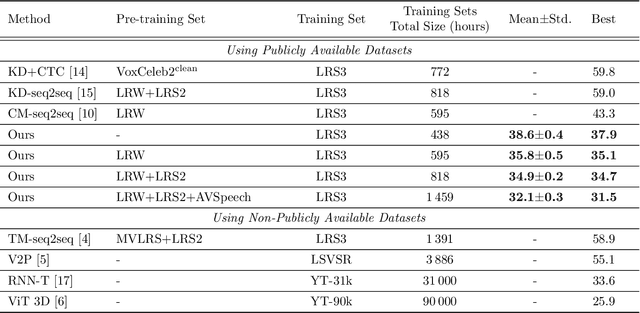
Visual speech recognition (VSR) aims to recognise the content of speech based on the lip movements without relying on the audio stream. Advances in deep learning and the availability of large audio-visual datasets have led to the development of much more accurate and robust VSR models than ever before. However, these advances are usually due to larger training sets rather than the model design. In this work, we demonstrate that designing better models is equally important to using larger training sets. We propose the addition of prediction-based auxiliary tasks to a VSR model and highlight the importance of hyper-parameter optimisation and appropriate data augmentations. We show that such model works for different languages and outperforms all previous methods trained on publicly available datasets by a large margin. It even outperforms models that were trained on non-publicly available datasets containing up to to 21 times more data. We show furthermore that using additional training data, even in other languages or with automatically generated transcriptions, results in further improvement.
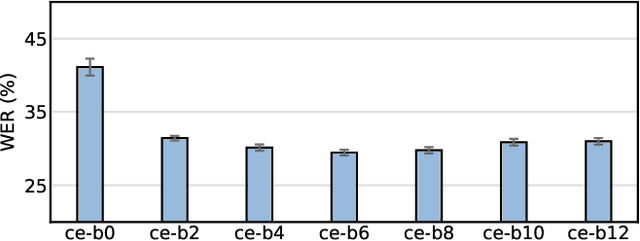
Modulation spectral features for speech emotion recognition using deep neural networks
Jan 14, 2023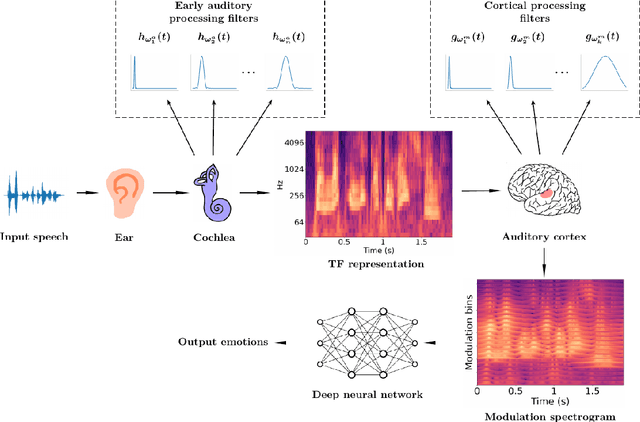
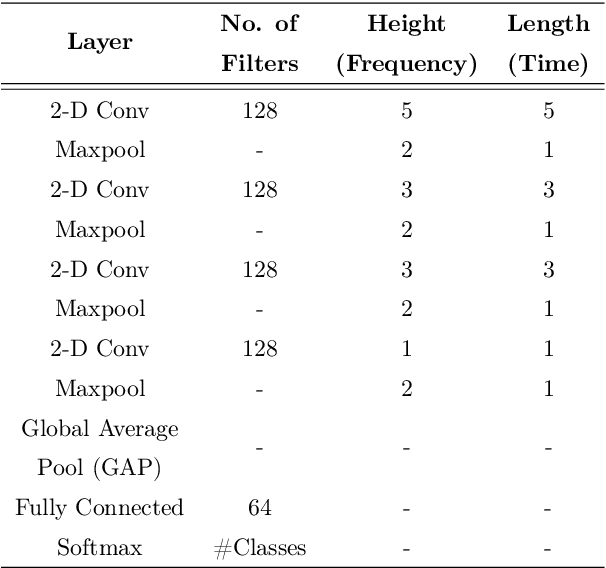


This work explores the use of constant-Q transform based modulation spectral features (CQT-MSF) for speech emotion recognition (SER). The human perception and analysis of sound comprise of two important cognitive parts: early auditory analysis and cortex-based processing. The early auditory analysis considers spectrogram-based representation whereas cortex-based analysis includes extraction of temporal modulations from the spectrogram. This temporal modulation representation of spectrogram is called modulation spectral feature (MSF). As the constant-Q transform (CQT) provides higher resolution at emotion salient low-frequency regions of speech, we find that CQT-based spectrogram, together with its temporal modulations, provides a representation enriched with emotion-specific information. We argue that CQT-MSF when used with a 2-dimensional convolutional network can provide a time-shift invariant and deformation insensitive representation for SER. Our results show that CQT-MSF outperforms standard mel-scale based spectrogram and its modulation features on two popular SER databases, Berlin EmoDB and RAVDESS. We also show that our proposed feature outperforms the shift and deformation invariant scattering transform coefficients, hence, showing the importance of joint hand-crafted and self-learned feature extraction instead of reliance on complete hand-crafted features. Finally, we perform Grad-CAM analysis to visually inspect the contribution of constant-Q modulation features over SER.
* Accepted for publication in Elsevier's Speech Communication Journal
Calibrating Transformers via Sparse Gaussian Processes
Mar 04, 2023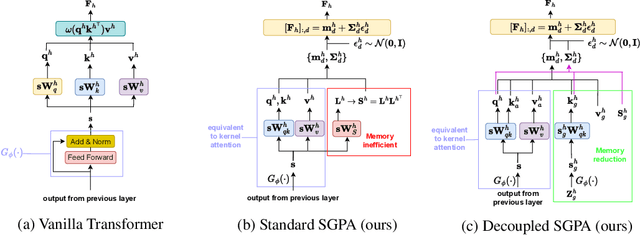
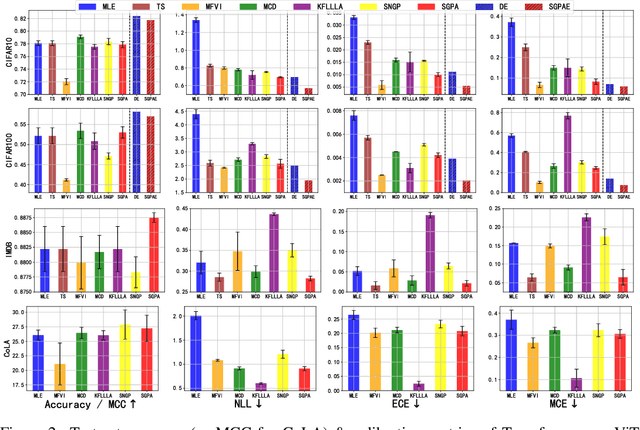
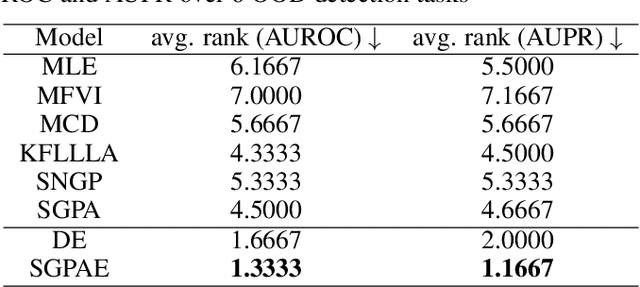
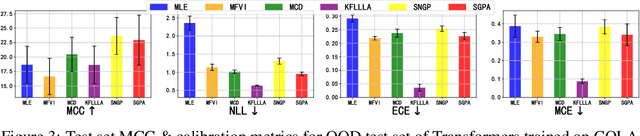
Transformer models have achieved profound success in prediction tasks in a wide range of applications in natural language processing, speech recognition and computer vision. Extending Transformer's success to safety-critical domains requires calibrated uncertainty estimation which remains under-explored. To address this, we propose Sparse Gaussian Process attention (SGPA), which performs Bayesian inference directly in the output space of multi-head attention blocks (MHAs) in transformer to calibrate its uncertainty. It replaces the scaled dot-product operation with a valid symmetric kernel and uses sparse Gaussian processes (SGP) techniques to approximate the posterior processes of MHA outputs. Empirically, on a suite of prediction tasks on text, images and graphs, SGPA-based Transformers achieve competitive predictive accuracy, while noticeably improving both in-distribution calibration and out-of-distribution robustness and detection.