 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Trustera: A Live Conversation Redaction System
Mar 16, 2023
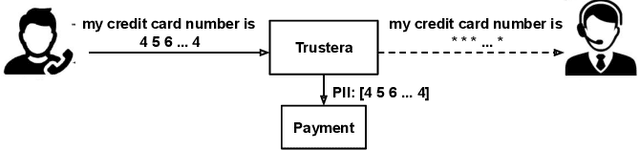

Trustera, the first functional system that redacts personally identifiable information (PII) in real-time spoken conversations to remove agents' need to hear sensitive information while preserving the naturalness of live customer-agent conversations. As opposed to post-call redaction, audio masking starts as soon as the customer begins speaking to a PII entity. This significantly reduces the risk of PII being intercepted or stored in insecure data storage. Trustera's architecture consists of a pipeline of automatic speech recognition, natural language understanding, and a live audio redactor module. The system's goal is three-fold: redact entities that are PII, mask the audio that goes to the agent, and at the same time capture the entity, so that the captured PII can be used for a payment transaction or caller identification. Trustera is currently being used by thousands of agents to secure customers' sensitive information.
Continuous Silent Speech Recognition using EEG
Feb 13, 2020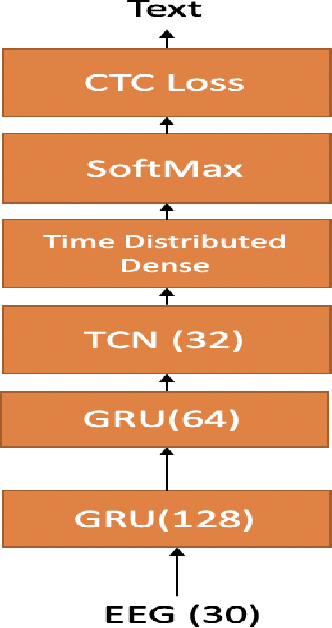
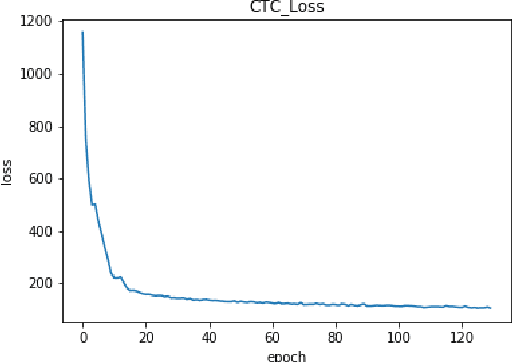
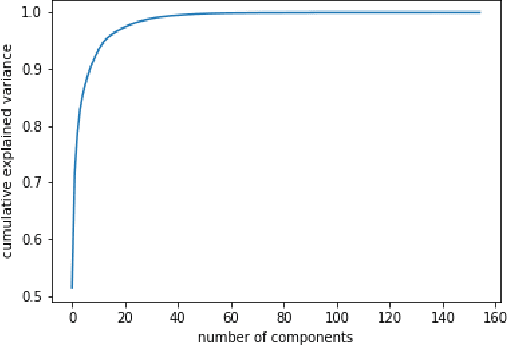
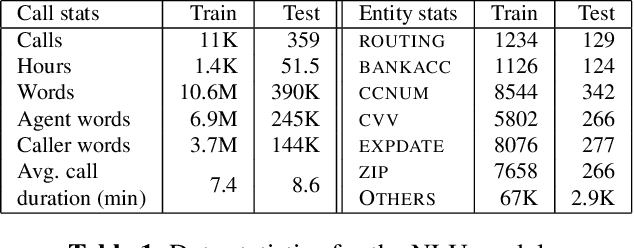
In this paper we explore continuous silent speech recognition using electroencephalograpgy (EEG) signals. We implemented a connectionist temporal classification (CTC) automatic speech recognition (ASR) model to translate EEG signals recorded in parallel while subjects were reading English sentences in their mind without producing any voice to text. Our results demonstrate the feasibility of using EEG signals for performing continuous silent speech recognition. We demonstrate our results for a limited English vocabulary consisting of 30 unique sentences.
Enhancing Cross-lingual Transfer via Phonemic Transcription Integration
Jul 10, 2023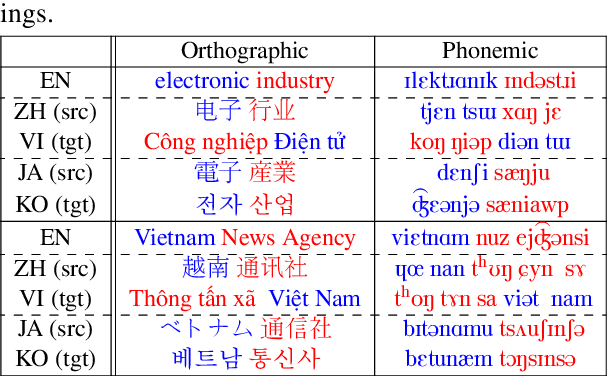
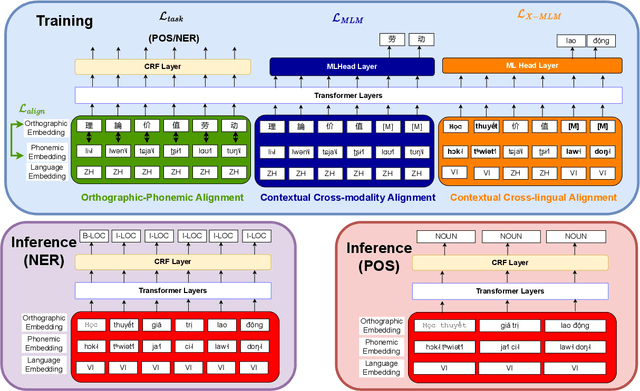
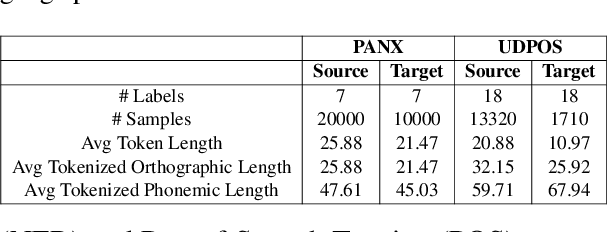
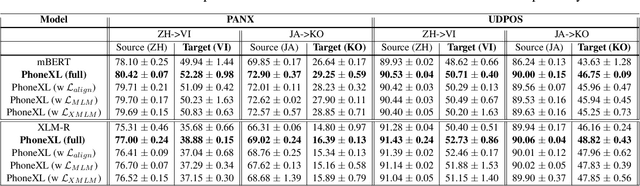
Previous cross-lingual transfer methods are restricted to orthographic representation learning via textual scripts. This limitation hampers cross-lingual transfer and is biased towards languages sharing similar well-known scripts. To alleviate the gap between languages from different writing scripts, we propose PhoneXL, a framework incorporating phonemic transcriptions as an additional linguistic modality beyond the traditional orthographic transcriptions for cross-lingual transfer. Particularly, we propose unsupervised alignment objectives to capture (1) local one-to-one alignment between the two different modalities, (2) alignment via multi-modality contexts to leverage information from additional modalities, and (3) alignment via multilingual contexts where additional bilingual dictionaries are incorporated. We also release the first phonemic-orthographic alignment dataset on two token-level tasks (Named Entity Recognition and Part-of-Speech Tagging) among the understudied but interconnected Chinese-Japanese-Korean-Vietnamese (CJKV) languages. Our pilot study reveals phonemic transcription provides essential information beyond the orthography to enhance cross-lingual transfer and bridge the gap among CJKV languages, leading to consistent improvements on cross-lingual token-level tasks over orthographic-based multilingual PLMs.
DEFORMER: Coupling Deformed Localized Patterns with Global Context for Robust End-to-end Speech Recognition
Jul 06, 2022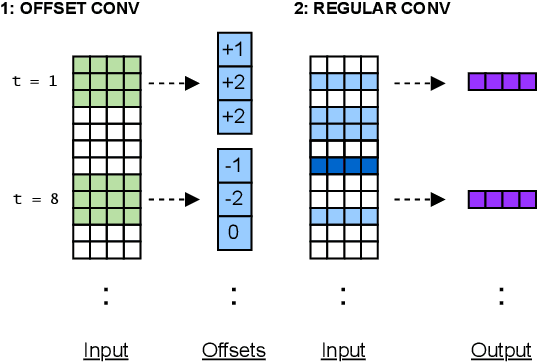


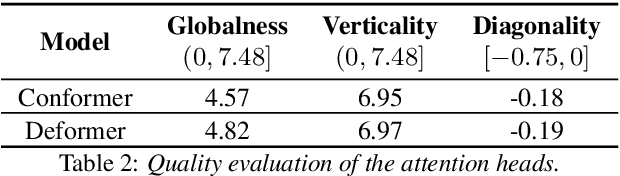
Convolutional neural networks (CNN) have improved speech recognition performance greatly by exploiting localized time-frequency patterns. But these patterns are assumed to appear in symmetric and rigid kernels by the conventional CNN operation. It motivates the question: What about asymmetric kernels? In this study, we illustrate adaptive views can discover local features which couple better with attention than fixed views of the input. We replace depthwise CNNs in the Conformer architecture with a deformable counterpart, dubbed this "Deformer". By analyzing our best-performing model, we visualize both local receptive fields and global attention maps learned by the Deformer and show increased feature associations on the utterance level. The statistical analysis of learned kernel offsets provides an insight into the change of information in features with the network depth. Finally, replacing only half of the layers in the encoder, the Deformer improves +5.6% relative WER without a LM and +6.4% relative WER with a LM over the Conformer baseline on the WSJ eval92 set.
A Conformer Based Acoustic Model for Robust Automatic Speech Recognition
Mar 01, 2022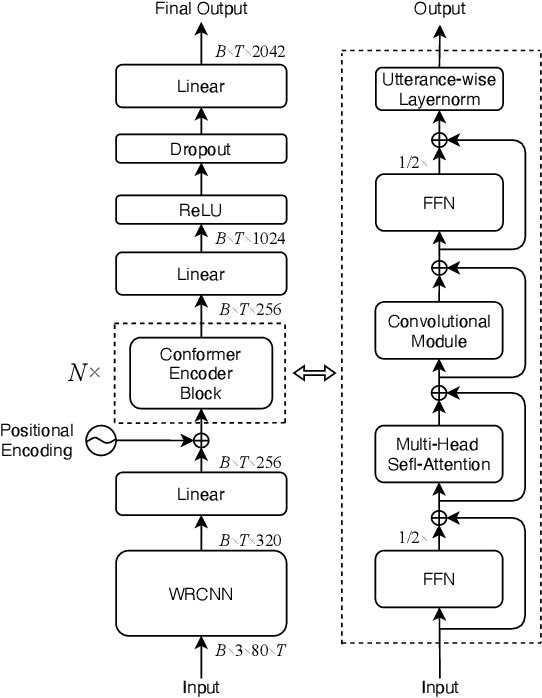
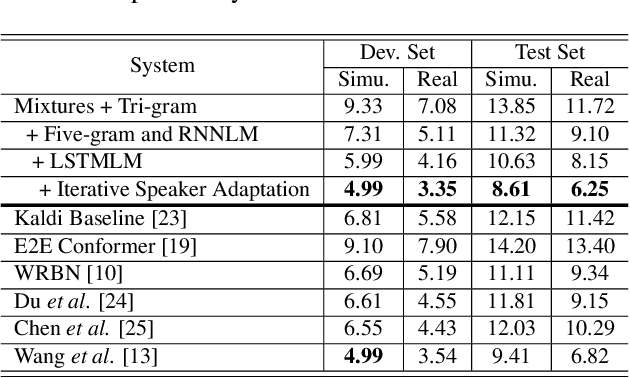
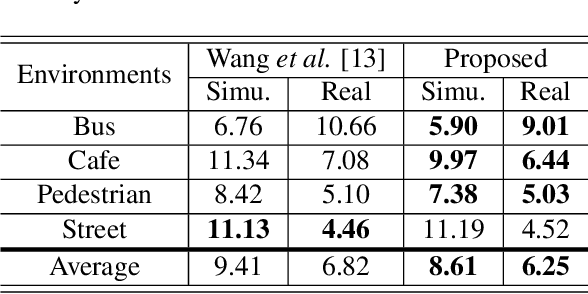
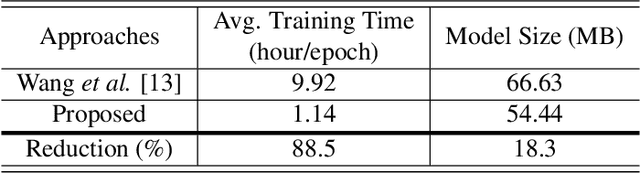
This study addresses robust automatic speech recognition (ASR) by introducing a Conformer-based acoustic model. The proposed model builds on a state-of-the-art recognition system using a bi-directional long short-term memory (BLSTM) model with utterance-wise dropout and iterative speaker adaptation, but employs a Conformer encoder instead of the BLSTM network. The Conformer encoder uses a convolution-augmented attention mechanism for acoustic modeling. The proposed system is evaluated on the monaural ASR task of the CHiME-4 corpus. Coupled with utterance-wise normalization and speaker adaptation, our model achieves $6.25\%$ word error rate, which outperforms the previous best system by $8.4\%$ relatively. In addition, the proposed Conformer-based model is $18.3\%$ smaller in model size and reduces training time by $88.5\%$.
Language Dependencies in Adversarial Attacks on Speech Recognition Systems
Feb 02, 2022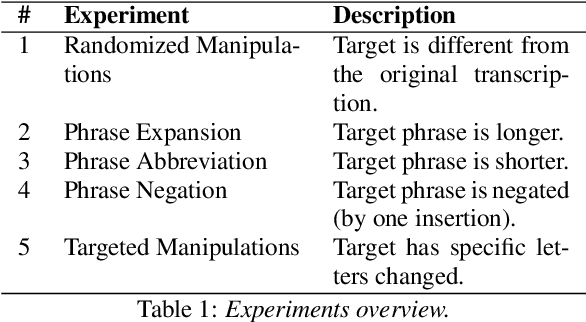
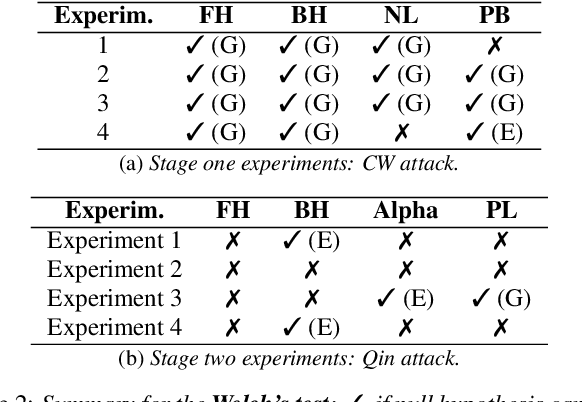

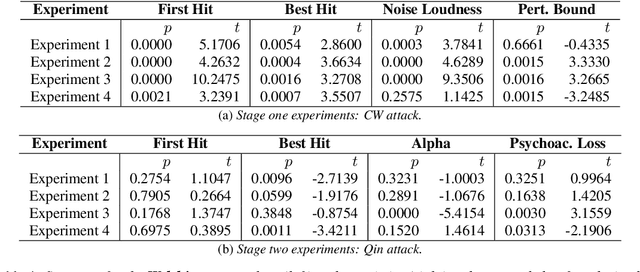
Automatic speech recognition (ASR) systems are ubiquitously present in our daily devices. They are vulnerable to adversarial attacks, where manipulated input samples fool the ASR system's recognition. While adversarial examples for various English ASR systems have already been analyzed, there exists no inter-language comparative vulnerability analysis. We compare the attackability of a German and an English ASR system, taking Deepspeech as an example. We investigate if one of the language models is more susceptible to manipulations than the other. The results of our experiments suggest statistically significant differences between English and German in terms of computational effort necessary for the successful generation of adversarial examples. This result encourages further research in language-dependent characteristics in the robustness analysis of ASR.
Dyn-ASR: Compact, Multilingual Speech Recognition via Spoken Language and Accent Identification
Aug 04, 2021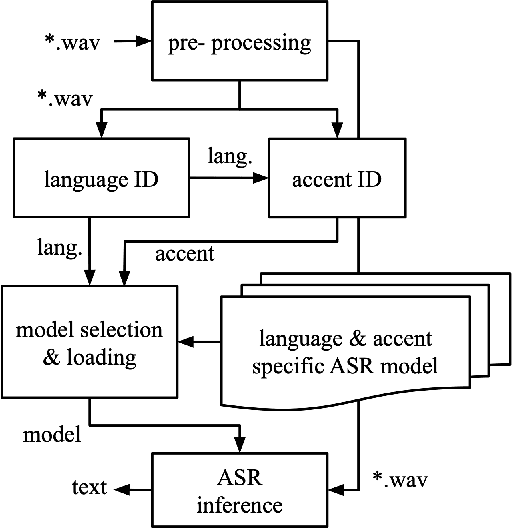
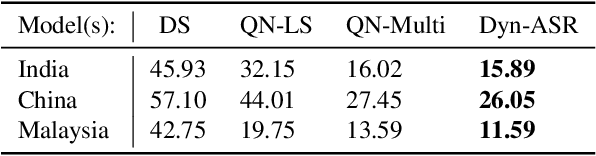

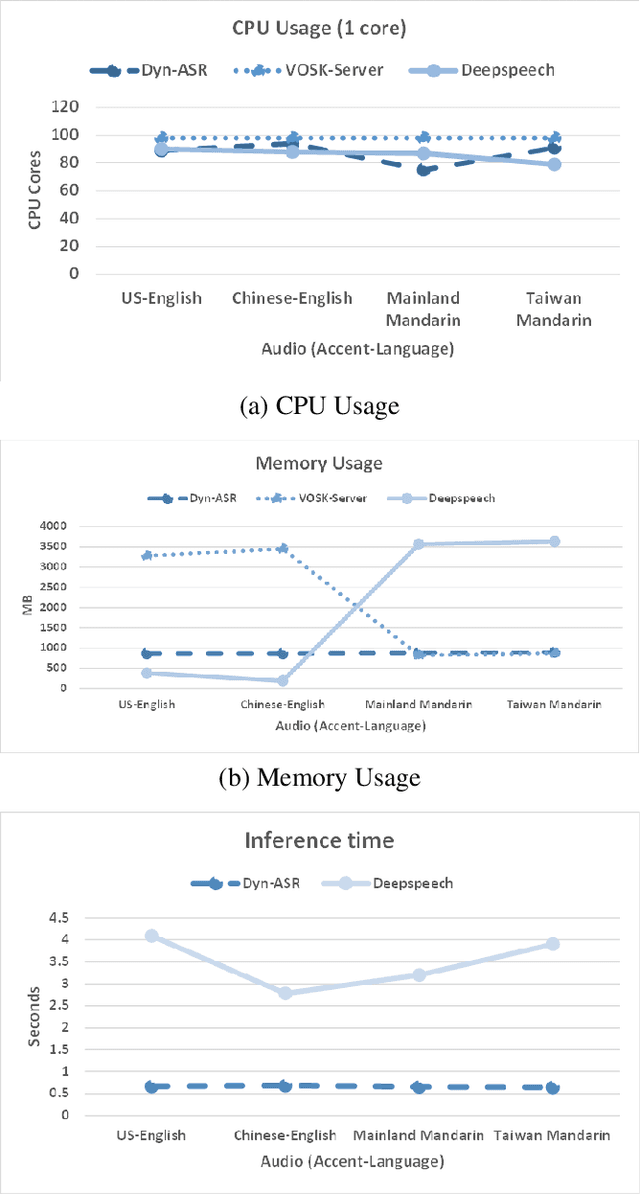
Running automatic speech recognition (ASR) on edge devices is non-trivial due to resource constraints, especially in scenarios that require supporting multiple languages. We propose a new approach to enable multilingual speech recognition on edge devices. This approach uses both language identification and accent identification to select one of multiple monolingual ASR models on-the-fly, each fine-tuned for a particular accent. Initial results for both recognition performance and resource usage are promising with our approach using less than 1/12th of the memory consumed by other solutions.
Visualizing Automatic Speech Recognition -- Means for a Better Understanding?
Feb 01, 2022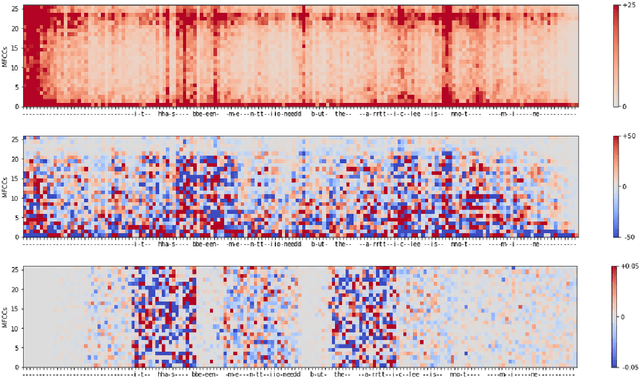
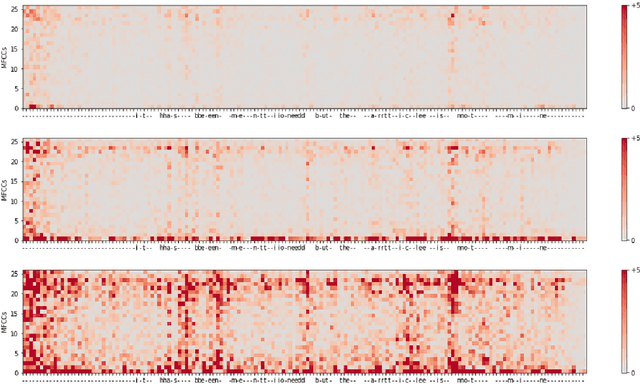
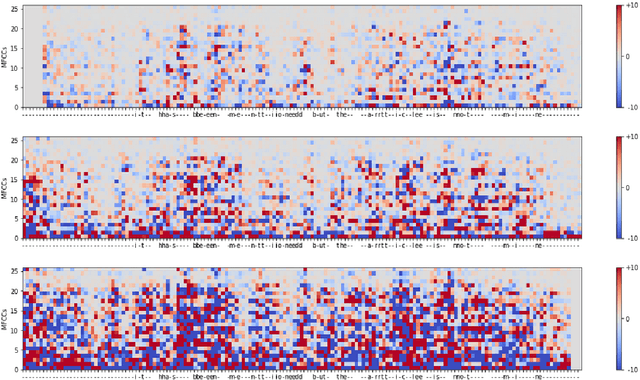
Automatic speech recognition (ASR) is improving ever more at mimicking human speech processing. The functioning of ASR, however, remains to a large extent obfuscated by the complex structure of the deep neural networks (DNNs) they are based on. In this paper, we show how so-called attribution methods, that we import from image recognition and suitably adapt to handle audio data, can help to clarify the working of ASR. Taking DeepSpeech, an end-to-end model for ASR, as a case study, we show how these techniques help to visualize which features of the input are the most influential in determining the output. We focus on three visualization techniques: Layer-wise Relevance Propagation (LRP), Saliency Maps, and Shapley Additive Explanations (SHAP). We compare these methods and discuss potential further applications, such as in the detection of adversarial examples.
Dynamic Alignment Mask CTC: Improved Mask-CTC with Aligned Cross Entropy
Mar 14, 2023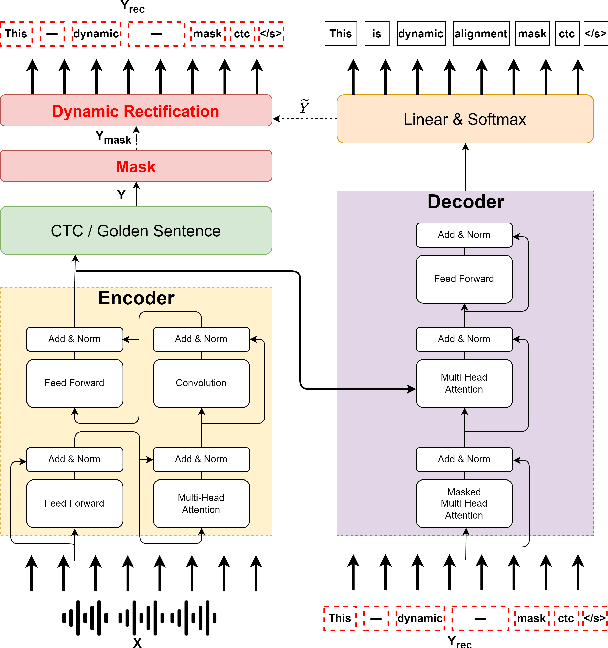

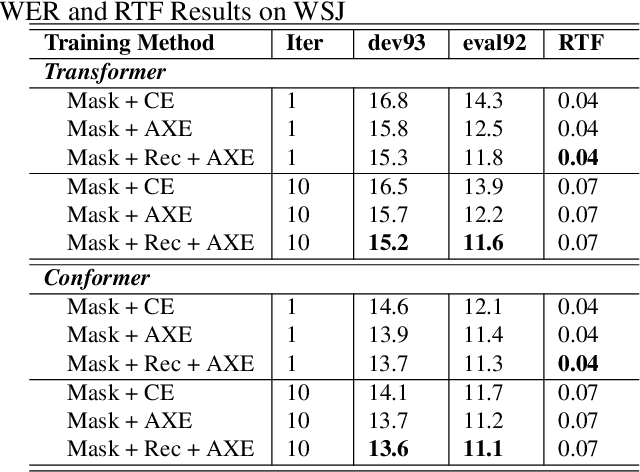
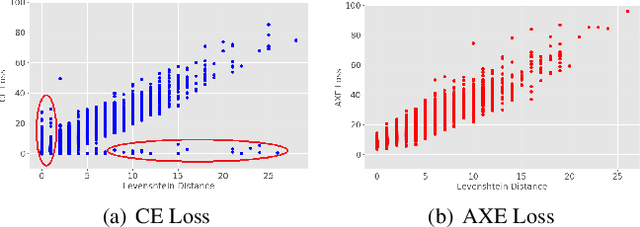
Because of predicting all the target tokens in parallel, the non-autoregressive models greatly improve the decoding efficiency of speech recognition compared with traditional autoregressive models. In this work, we present dynamic alignment Mask CTC, introducing two methods: (1) Aligned Cross Entropy (AXE), finding the monotonic alignment that minimizes the cross-entropy loss through dynamic programming, (2) Dynamic Rectification, creating new training samples by replacing some masks with model predicted tokens. The AXE ignores the absolute position alignment between prediction and ground truth sentence and focuses on tokens matching in relative order. The dynamic rectification method makes the model capable of simulating the non-mask but possible wrong tokens, even if they have high confidence. Our experiments on WSJ dataset demonstrated that not only AXE loss but also the rectification method could improve the WER performance of Mask CTC.
Investigation of Deep Neural Network Acoustic Modelling Approaches for Low Resource Accented Mandarin Speech Recognition
Jan 24, 2022The Mandarin Chinese language is known to be strongly influenced by a rich set of regional accents, while Mandarin speech with each accent is quite low resource. Hence, an important task in Mandarin speech recognition is to appropriately model the acoustic variabilities imposed by accents. In this paper, an investigation of implicit and explicit use of accent information on a range of deep neural network (DNN) based acoustic modelling techniques is conducted. Meanwhile, approaches of multi-accent modelling including multi-style training, multi-accent decision tree state tying, DNN tandem and multi-level adaptive network (MLAN) tandem hidden Markov model (HMM) modelling are combined and compared in this paper. On a low resource accented Mandarin speech recognition task consisting of four regional accents, an improved MLAN tandem HMM systems explicitly leveraging the accent information was proposed and significantly outperformed the baseline accent independent DNN tandem systems by 0.8%-1.5% absolute (6%-9% relative) in character error rate after sequence level discriminative training and adaptation.
* Published in JOURNAL OF INTEGRATION TECHNOLOGY CNKI:SUN:JCJI.0.2015-06-003