 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Why does Self-Supervised Learning for Speech Recognition Benefit Speaker Recognition?
Apr 27, 2022
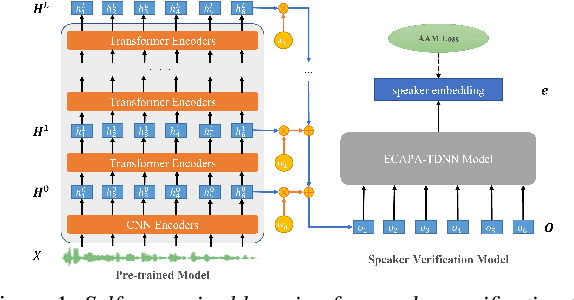
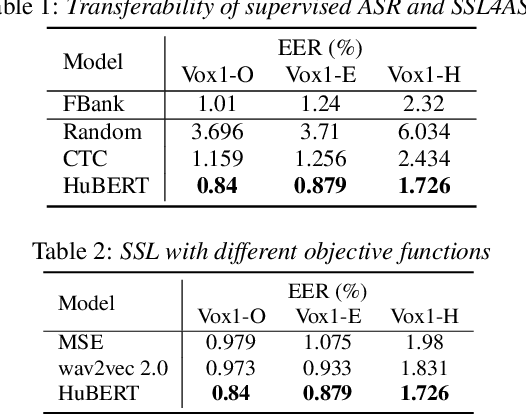
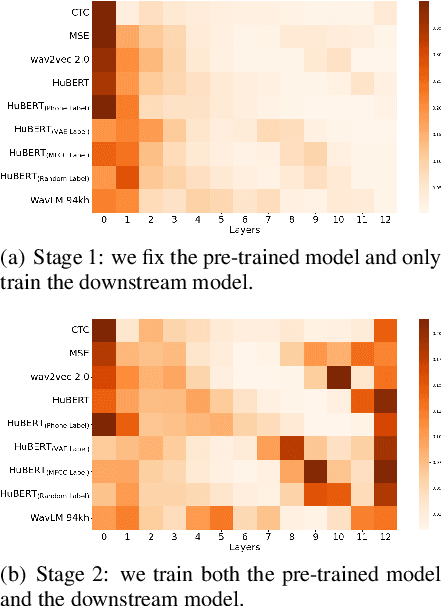
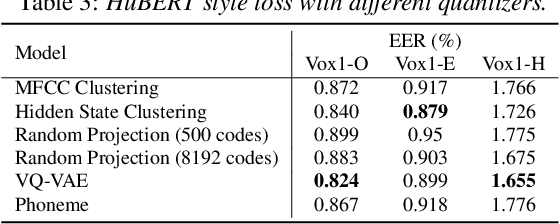
Recently, self-supervised learning (SSL) has demonstrated strong performance in speaker recognition, even if the pre-training objective is designed for speech recognition. In this paper, we study which factor leads to the success of self-supervised learning on speaker-related tasks, e.g. speaker verification (SV), through a series of carefully designed experiments. Our empirical results on the Voxceleb-1 dataset suggest that the benefit of SSL to SV task is from a combination of mask speech prediction loss, data scale, and model size, while the SSL quantizer has a minor impact. We further employ the integrated gradients attribution method and loss landscape visualization to understand the effectiveness of self-supervised learning for speaker recognition performance.
Filter-based Discriminative Autoencoders for Children Speech Recognition
Apr 01, 2022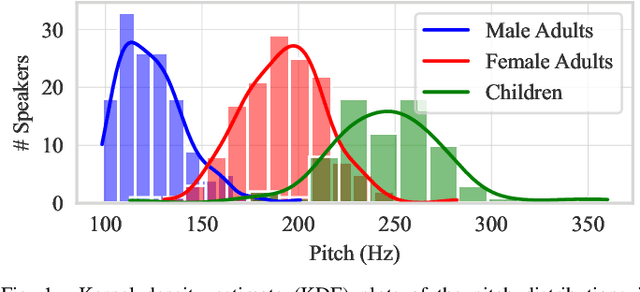
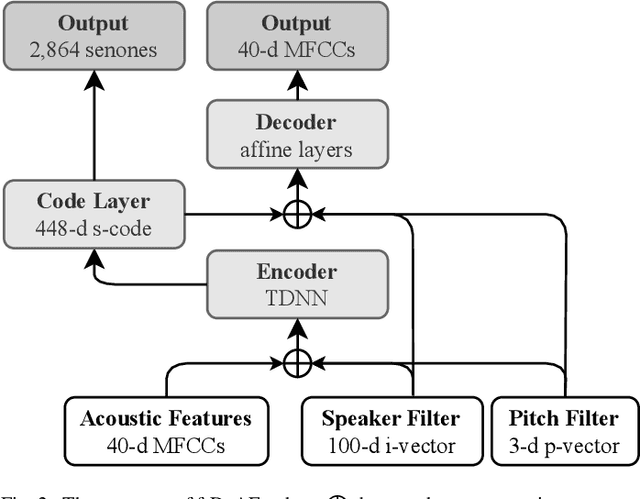
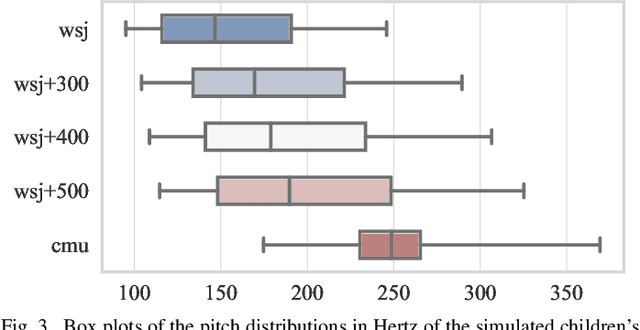
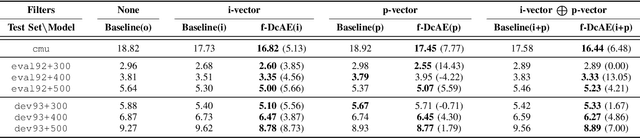
Children speech recognition is indispensable but challenging due to the diversity of children's speech. In this paper, we propose a filter-based discriminative autoencoder for acoustic modeling. To filter out the influence of various speaker types and pitches, auxiliary information of the speaker and pitch features is input into the encoder together with the acoustic features to generate phonetic embeddings. In the training phase, the decoder uses the auxiliary information and the phonetic embedding extracted by the encoder to reconstruct the input acoustic features. The autoencoder is trained by simultaneously minimizing the ASR loss and feature reconstruction error. The framework can make the phonetic embedding purer, resulting in more accurate senone (triphone-state) scores. Evaluated on the test set of the CMU Kids corpus, our system achieves a 7.8% relative WER reduction compared to the baseline system. In the domain adaptation experiment, our system also outperforms the baseline system on the British-accent PF-STAR task.
Joint unsupervised and supervised learning for context-aware language identification
Mar 29, 2023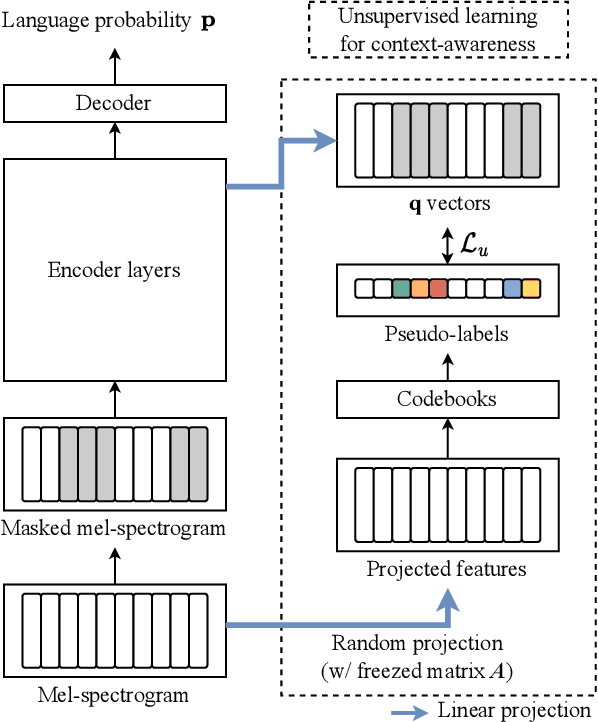
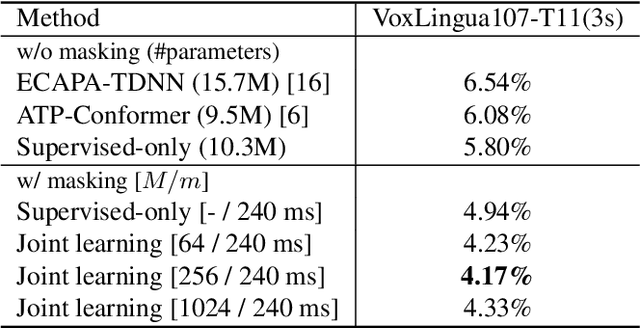
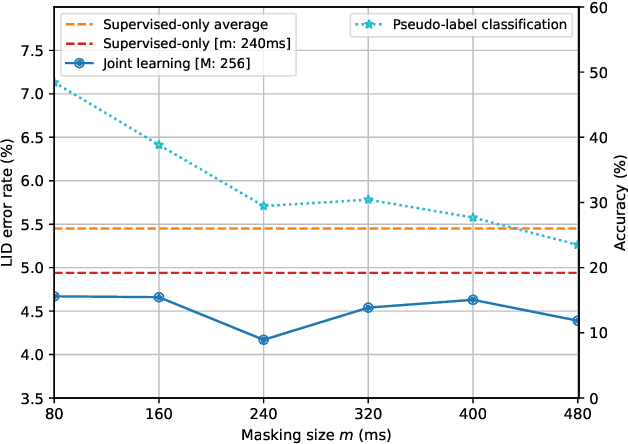
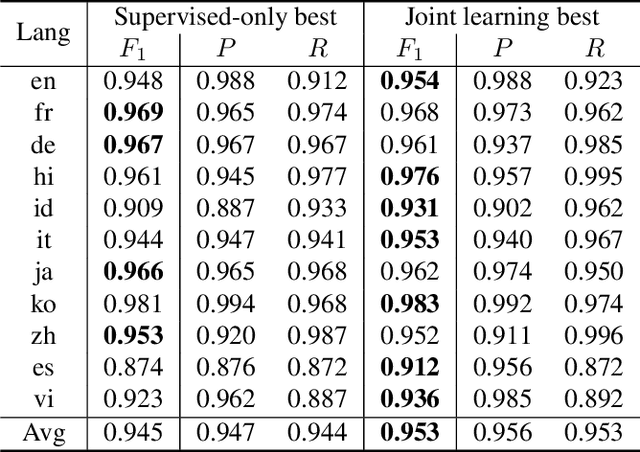
Language identification (LID) recognizes the language of a spoken utterance automatically. According to recent studies, LID models trained with an automatic speech recognition (ASR) task perform better than those trained with a LID task only. However, we need additional text labels to train the model to recognize speech, and acquiring the text labels is a cost high. In order to overcome this problem, we propose context-aware language identification using a combination of unsupervised and supervised learning without any text labels. The proposed method learns the context of speech through masked language modeling (MLM) loss and simultaneously trains to determine the language of the utterance with supervised learning loss. The proposed joint learning was found to reduce the error rate by 15.6% compared to the same structure model trained by supervised-only learning on a subset of the VoxLingua107 dataset consisting of sub-three-second utterances in 11 languages.
Unsupervised Uncertainty Measures of Automatic Speech Recognition for Non-intrusive Speech Intelligibility Prediction
Apr 08, 2022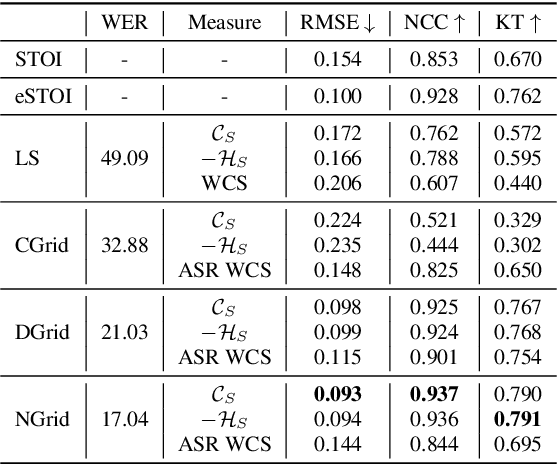
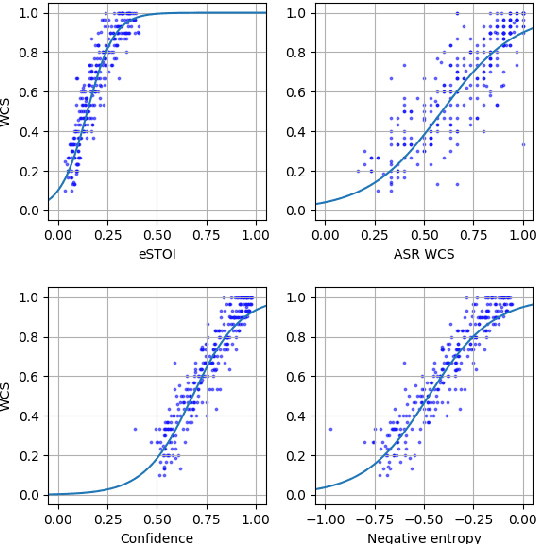
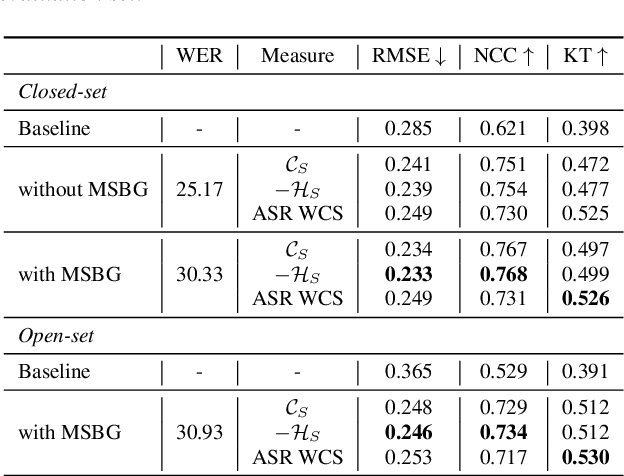
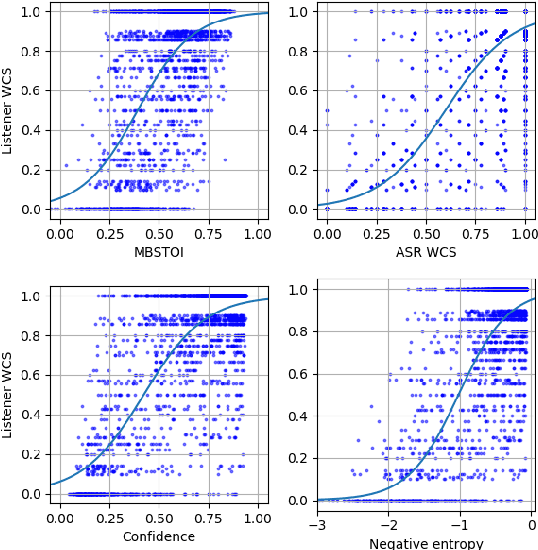
Non-intrusive intelligibility prediction is important for its application in realistic scenarios, where a clean reference signal is difficult to access. The construction of many non-intrusive predictors require either ground truth intelligibility labels or clean reference signals for supervised learning. In this work, we leverage an unsupervised uncertainty estimation method for predicting speech intelligibility, which does not require intelligibility labels or reference signals to train the predictor. Our experiments demonstrate that the uncertainty from state-of-the-art end-to-end automatic speech recognition (ASR) models is highly correlated with speech intelligibility. The proposed method is evaluated on two databases and the results show that the unsupervised uncertainty measures of ASR models are more correlated with speech intelligibility from listening results than the predictions made by widely used intrusive methods.
Towards Better Domain Adaptation for Self-supervised Models: A Case Study of Child ASR
Apr 28, 2023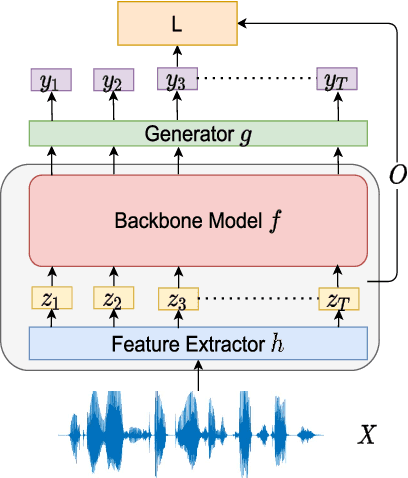
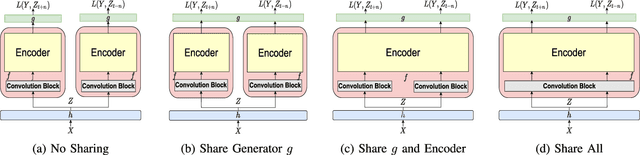
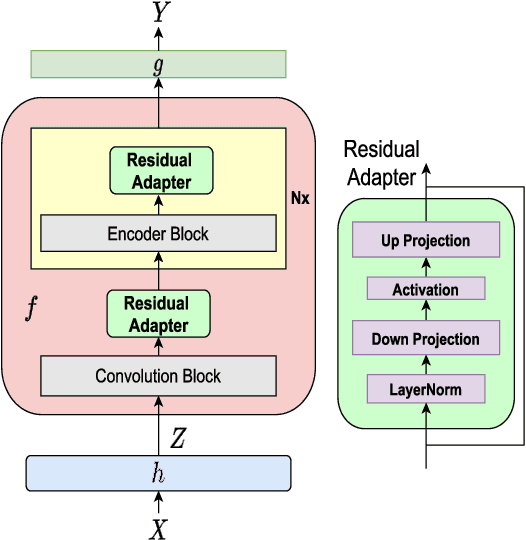
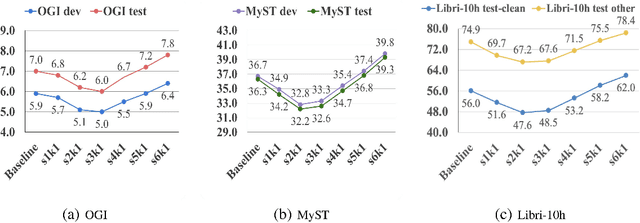
Recently, self-supervised learning (SSL) from unlabelled speech data has gained increased attention in the automatic speech recognition (ASR) community. Typical SSL methods include autoregressive predictive coding (APC), Wav2vec2.0, and hidden unit BERT (HuBERT). However, SSL models are biased to the pretraining data. When SSL models are finetuned with data from another domain, domain shifting occurs and might cause limited knowledge transfer for downstream tasks. In this paper, we propose a novel framework, domain responsible adaptation and finetuning (DRAFT), to reduce domain shifting in pretrained speech models, and evaluate it for a causal and non-causal transformer. For the causal transformer, an extension of APC (E-APC) is proposed to learn richer information from unlabelled data by using multiple temporally-shifted sequences to perform prediction. For the non-causal transformer, various solutions for using the bidirectional APC (Bi-APC) are investigated. In addition, the DRAFT framework is examined for Wav2vec2.0 and HuBERT methods, which use non-causal transformers as the backbone. The experiments are conducted on child ASR (using the OGI and MyST databases) using SSL models trained with unlabelled adult speech data from Librispeech. The relative WER improvements of up to 19.7% on the two child tasks are observed when compared to the pretrained models without adaptation. With the proposed methods (E-APC and DRAFT), the relative WER improvements are even larger (30% and 19% on the OGI and MyST data, respectively) when compared to the models without using pretraining methods.
Speaker Adaptation Using Spectro-Temporal Deep Features for Dysarthric and Elderly Speech Recognition
Feb 26, 2022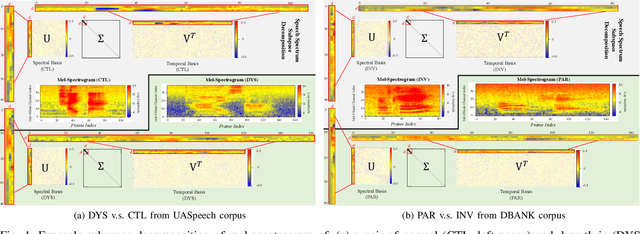
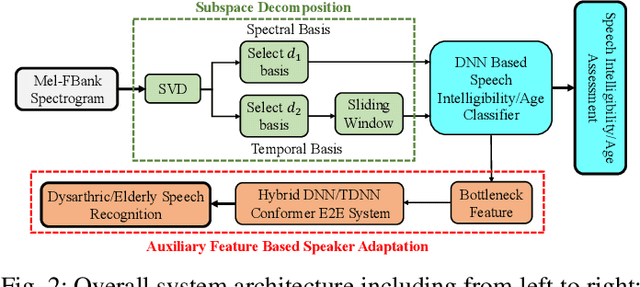
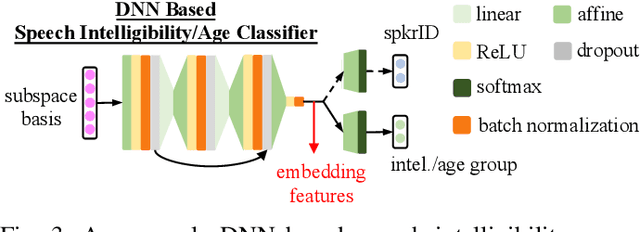
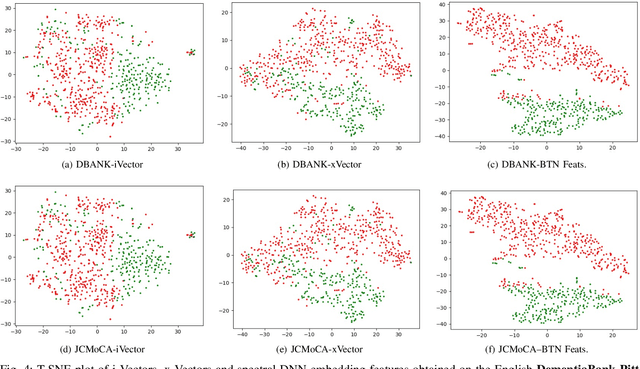
Despite the rapid progress of automatic speech recognition (ASR) technologies targeting normal speech in recent decades, accurate recognition of dysarthric and elderly speech remains highly challenging tasks to date. Sources of heterogeneity commonly found in normal speech including accent or gender, when further compounded with the variability over age and speech pathology severity level, create large diversity among speakers. To this end, speaker adaptation techniques play a key role in personalization of ASR systems for such users. Motivated by the spectro-temporal level differences between dysarthric, elderly and normal speech that systematically manifest in articulatory imprecision, decreased volume and clarity, slower speaking rates and increased dysfluencies, novel spectrotemporal subspace basis deep embedding features derived using SVD speech spectrum decomposition are proposed in this paper to facilitate auxiliary feature based speaker adaptation of state-of-the-art hybrid DNN/TDNN and end-to-end Conformer speech recognition systems. Experiments were conducted on four tasks: the English UASpeech and TORGO dysarthric speech corpora; the English DementiaBank Pitt and Cantonese JCCOCC MoCA elderly speech datasets. The proposed spectro-temporal deep feature adapted systems outperformed baseline i-Vector and xVector adaptation by up to 2.63% absolute (8.63% relative) reduction in word error rate (WER). Consistent performance improvements were retained after model based speaker adaptation using learning hidden unit contributions (LHUC) was further applied. The best speaker adapted system using the proposed spectral basis embedding features produced the lowest published WER of 25.05% on the UASpeech test set of 16 dysarthric speakers.
Towards Measuring Fairness in Speech Recognition: Casual Conversations Dataset Transcriptions
Nov 18, 2021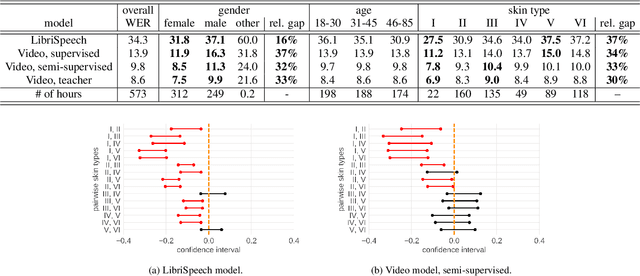

It is well known that many machine learning systems demonstrate bias towards specific groups of individuals. This problem has been studied extensively in the Facial Recognition area, but much less so in Automatic Speech Recognition (ASR). This paper presents initial Speech Recognition results on "Casual Conversations" -- a publicly released 846 hour corpus designed to help researchers evaluate their computer vision and audio models for accuracy across a diverse set of metadata, including age, gender, and skin tone. The entire corpus has been manually transcribed, allowing for detailed ASR evaluations across these metadata. Multiple ASR models are evaluated, including models trained on LibriSpeech, 14,000 hour transcribed, and over 2 million hour untranscribed social media videos. Significant differences in word error rate across gender and skin tone are observed at times for all models. We are releasing human transcripts from the Casual Conversations dataset to encourage the community to develop a variety of techniques to reduce these statistical biases.
Efficient Sequence Transduction by Jointly Predicting Tokens and Durations
Apr 13, 2023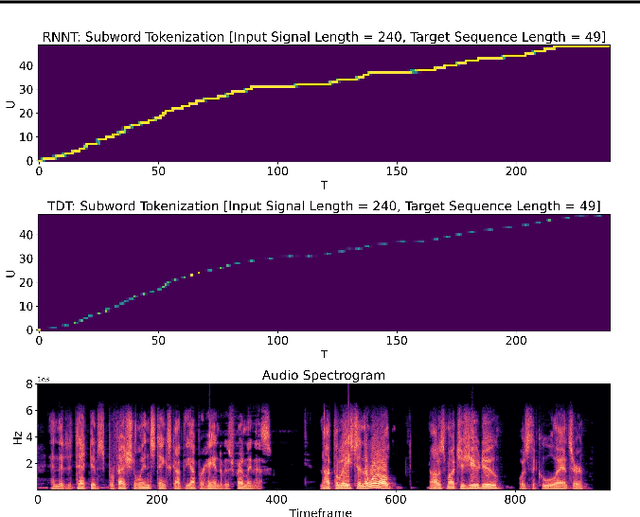
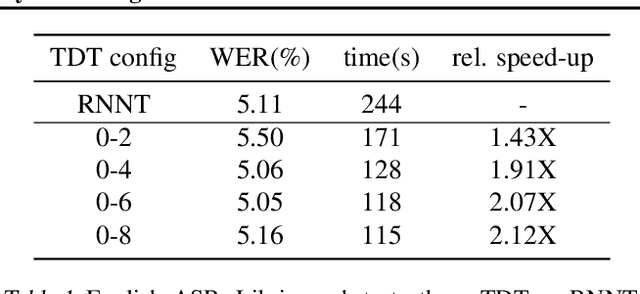
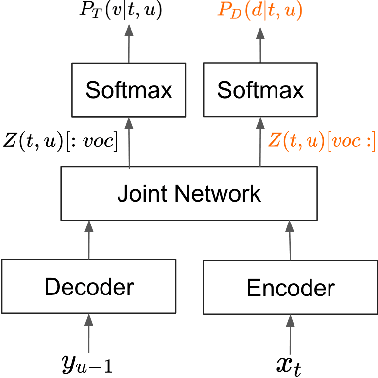
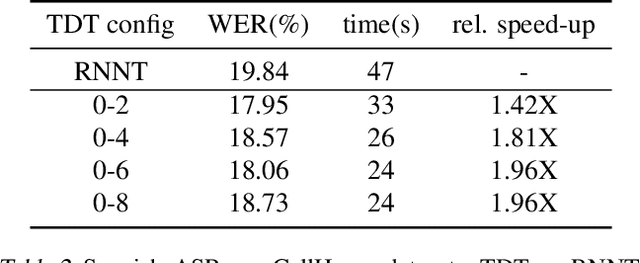
This paper introduces a novel Token-and-Duration Transducer (TDT) architecture for sequence-to-sequence tasks. TDT extends conventional RNN-Transducer architectures by jointly predicting both a token and its duration, i.e. the number of input frames covered by the emitted token. This is achieved by using a joint network with two outputs which are independently normalized to generate distributions over tokens and durations. During inference, TDT models can skip input frames guided by the predicted duration output, which makes them significantly faster than conventional Transducers which process the encoder output frame by frame. TDT models achieve both better accuracy and significantly faster inference than conventional Transducers on different sequence transduction tasks. TDT models for Speech Recognition achieve better accuracy and up to 2.82X faster inference than RNN-Transducers. TDT models for Speech Translation achieve an absolute gain of over 1 BLEU on the MUST-C test compared with conventional Transducers, and its inference is 2.27X faster. In Speech Intent Classification and Slot Filling tasks, TDT models improve the intent accuracy up to over 1% (absolute) over conventional Transducers, while running up to 1.28X faster.
Improving Speech Recognition Accuracy of Local POI Using Geographical Models
Jul 07, 2021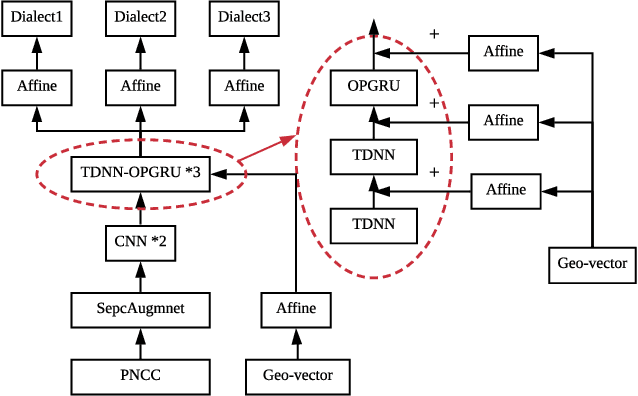
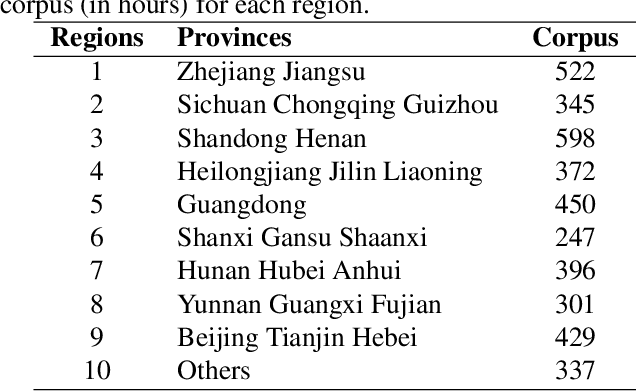
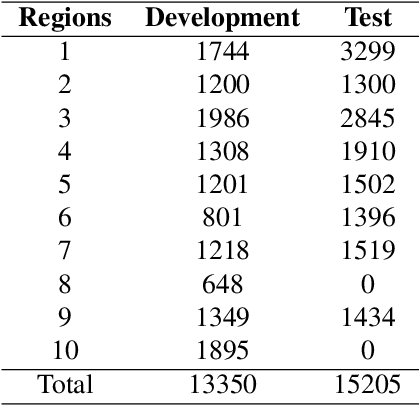
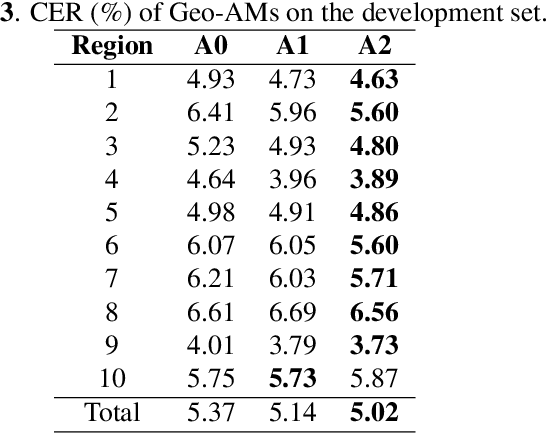
Nowadays voice search for points of interest (POI) is becoming increasingly popular. However, speech recognition for local POI has remained to be a challenge due to multi-dialect and massive POI. This paper improves speech recognition accuracy for local POI from two aspects. Firstly, a geographic acoustic model (Geo-AM) is proposed. The Geo-AM deals with multi-dialect problem using dialect-specific input feature and dialect-specific top layer. Secondly, a group of geo-specific language models (Geo-LMs) are integrated into our speech recognition system to improve recognition accuracy of long tail and homophone POI. During decoding, specific language models are selected on demand according to users' geographic location. Experiments show that the proposed Geo-AM achieves 6.5%$\sim$10.1% relative character error rate (CER) reduction on an accent testset and the proposed Geo-AM and Geo-LM totally achieve over 18.7% relative CER reduction on Tencent Map task.
Describing emotions with acoustic property prompts for speech emotion recognition
Nov 14, 2022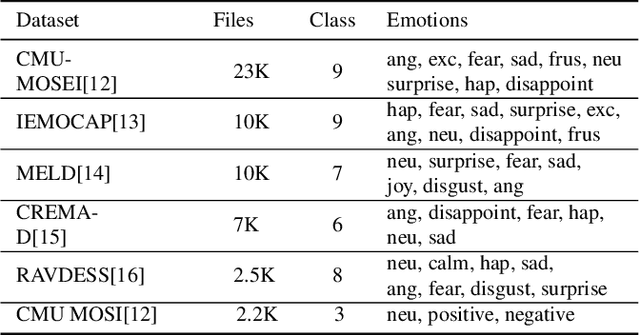
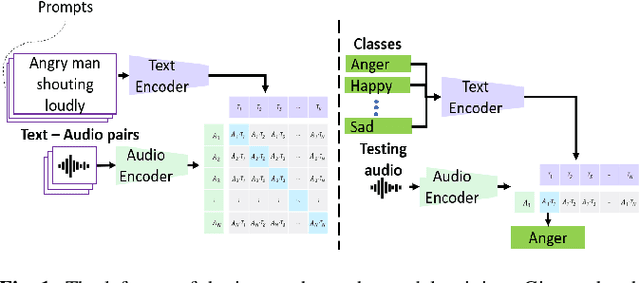
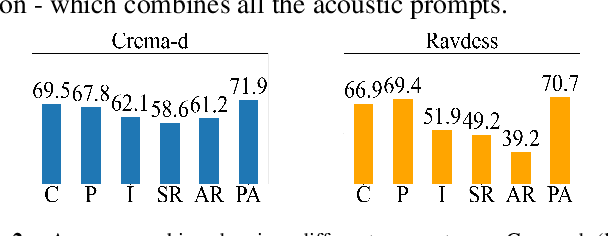
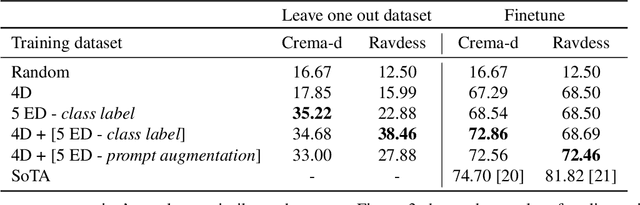
Emotions lie on a broad continuum and treating emotions as a discrete number of classes limits the ability of a model to capture the nuances in the continuum. The challenge is how to describe the nuances of emotions and how to enable a model to learn the descriptions. In this work, we devise a method to automatically create a description (or prompt) for a given audio by computing acoustic properties, such as pitch, loudness, speech rate, and articulation rate. We pair a prompt with its corresponding audio using 5 different emotion datasets. We trained a neural network model using these audio-text pairs. Then, we evaluate the model using one more dataset. We investigate how the model can learn to associate the audio with the descriptions, resulting in performance improvement of Speech Emotion Recognition and Speech Audio Retrieval. We expect our findings to motivate research describing the broad continuum of emotion