 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Investigating Training Strategies and Model Robustness of Low-Rank Adaptation for Language Modeling in Speech Recognition
Jan 19, 2024
The use of low-rank adaptation (LoRA) with frozen pretrained language models (PLMs) has become increasing popular as a mainstream, resource-efficient modeling approach for memory-constrained hardware. In this study, we first explore how to enhance model performance by introducing various LoRA training strategies, achieving relative word error rate reductions of 3.50\% on the public Librispeech dataset and of 3.67\% on an internal dataset in the messaging domain. To further characterize the stability of LoRA-based second-pass speech recognition models, we examine robustness against input perturbations. These perturbations are rooted in homophone replacements and a novel metric called N-best Perturbation-based Rescoring Robustness (NPRR), both designed to measure the relative degradation in the performance of rescoring models. Our experimental results indicate that while advanced variants of LoRA, such as dynamic rank-allocated LoRA, lead to performance degradation in $1$-best perturbation, they alleviate the degradation in $N$-best perturbation. This finding is in comparison to fully-tuned models and vanilla LoRA tuning baselines, suggesting that a comprehensive selection is needed when using LoRA-based adaptation for compute-cost savings and robust language modeling.
On Robustness to Missing Video for Audiovisual Speech Recognition
Dec 19, 2023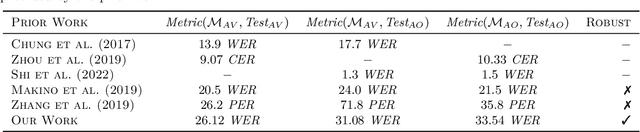
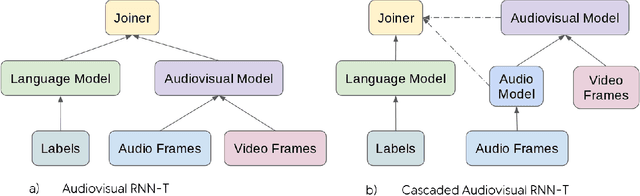
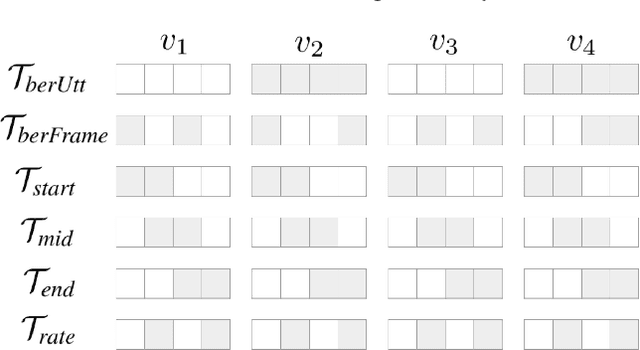
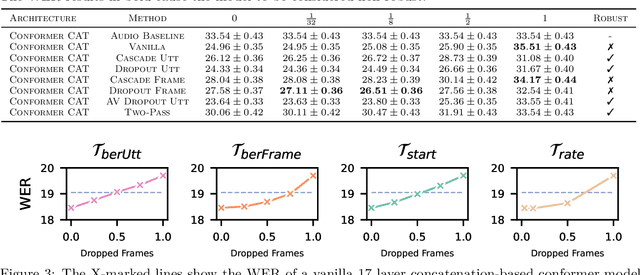
It has been shown that learning audiovisual features can lead to improved speech recognition performance over audio-only features, especially for noisy speech. However, in many common applications, the visual features are partially or entirely missing, e.g.~the speaker might move off screen. Multi-modal models need to be robust: missing video frames should not degrade the performance of an audiovisual model to be worse than that of a single-modality audio-only model. While there have been many attempts at building robust models, there is little consensus on how robustness should be evaluated. To address this, we introduce a framework that allows claims about robustness to be evaluated in a precise and testable way. We also conduct a systematic empirical study of the robustness of common audiovisual speech recognition architectures on a range of acoustic noise conditions and test suites. Finally, we show that an architecture-agnostic solution based on cascades can consistently achieve robustness to missing video, even in settings where existing techniques for robustness like dropout fall short.
HINT: High-quality INPainting Transformer with Mask-Aware Encoding and Enhanced Attention
Feb 22, 2024Existing image inpainting methods leverage convolution-based downsampling approaches to reduce spatial dimensions. This may result in information loss from corrupted images where the available information is inherently sparse, especially for the scenario of large missing regions. Recent advances in self-attention mechanisms within transformers have led to significant improvements in many computer vision tasks including inpainting. However, limited by the computational costs, existing methods cannot fully exploit the efficacy of long-range modelling capabilities of such models. In this paper, we propose an end-to-end High-quality INpainting Transformer, abbreviated as HINT, which consists of a novel mask-aware pixel-shuffle downsampling module (MPD) to preserve the visible information extracted from the corrupted image while maintaining the integrity of the information available for high-level inferences made within the model. Moreover, we propose a Spatially-activated Channel Attention Layer (SCAL), an efficient self-attention mechanism interpreting spatial awareness to model the corrupted image at multiple scales. To further enhance the effectiveness of SCAL, motivated by recent advanced in speech recognition, we introduce a sandwich structure that places feed-forward networks before and after the SCAL module. We demonstrate the superior performance of HINT compared to contemporary state-of-the-art models on four datasets, CelebA, CelebA-HQ, Places2, and Dunhuang.
Attention-Guided Adaptation for Code-Switching Speech Recognition
Dec 14, 2023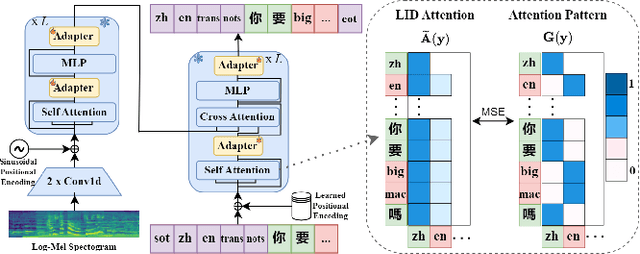
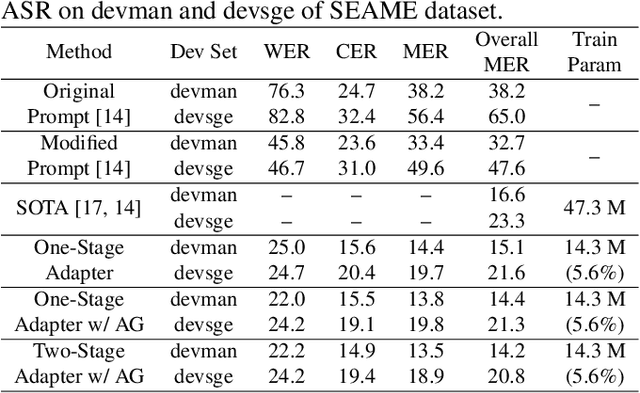
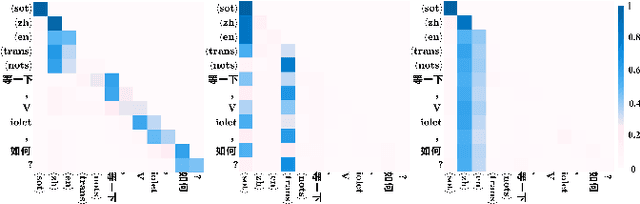
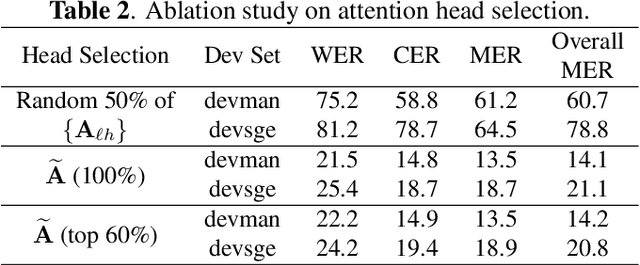
The prevalence of the powerful multilingual models, such as Whisper, has significantly advanced the researches on speech recognition. However, these models often struggle with handling the code-switching setting, which is essential in multilingual speech recognition. Recent studies have attempted to address this setting by separating the modules for different languages to ensure distinct latent representations for languages. Some other methods considered the switching mechanism based on language identification. In this study, a new attention-guided adaptation is proposed to conduct parameter-efficient learning for bilingual ASR. This method selects those attention heads in a model which closely express language identities and then guided those heads to be correctly attended with their corresponding languages. The experiments on the Mandarin-English code-switching speech corpus show that the proposed approach achieves a 14.2% mixed error rate, surpassing state-of-the-art method, where only 5.6% additional parameters over Whisper are trained.
MF-AED-AEC: Speech Emotion Recognition by Leveraging Multimodal Fusion, ASR Error Detection, and ASR Error Correction
Jan 24, 2024The prevalent approach in speech emotion recognition (SER) involves integrating both audio and textual information to comprehensively identify the speaker's emotion, with the text generally obtained through automatic speech recognition (ASR). An essential issue of this approach is that ASR errors from the text modality can worsen the performance of SER. Previous studies have proposed using an auxiliary ASR error detection task to adaptively assign weights of each word in ASR hypotheses. However, this approach has limited improvement potential because it does not address the coherence of semantic information in the text. Additionally, the inherent heterogeneity of different modalities leads to distribution gaps between their representations, making their fusion challenging. Therefore, in this paper, we incorporate two auxiliary tasks, ASR error detection (AED) and ASR error correction (AEC), to enhance the semantic coherence of ASR text, and further introduce a novel multi-modal fusion (MF) method to learn shared representations across modalities. We refer to our method as MF-AED-AEC. Experimental results indicate that MF-AED-AEC significantly outperforms the baseline model by a margin of 4.1\%.
Deep Photonic Reservoir Computer for Speech Recognition
Dec 11, 2023Speech recognition is a critical task in the field of artificial intelligence and has witnessed remarkable advancements thanks to large and complex neural networks, whose training process typically requires massive amounts of labeled data and computationally intensive operations. An alternative paradigm, reservoir computing, is energy efficient and is well adapted to implementation in physical substrates, but exhibits limitations in performance when compared to more resource-intensive machine learning algorithms. In this work we address this challenge by investigating different architectures of interconnected reservoirs, all falling under the umbrella of deep reservoir computing. We propose a photonic-based deep reservoir computer and evaluate its effectiveness on different speech recognition tasks. We show specific design choices that aim to simplify the practical implementation of a reservoir computer while simultaneously achieving high-speed processing of high-dimensional audio signals. Overall, with the present work we hope to help the advancement of low-power and high-performance neuromorphic hardware.
Revisiting the Entropy Semiring for Neural Speech Recognition
Dec 19, 2023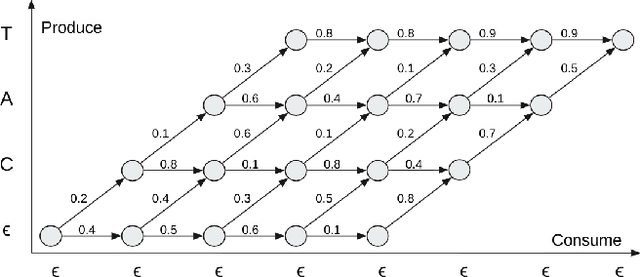
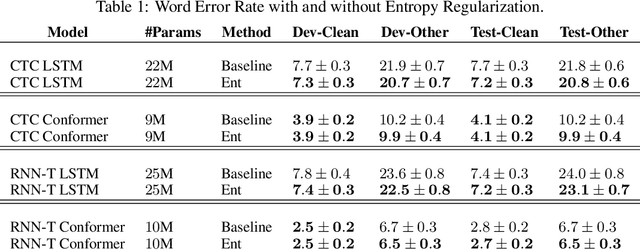

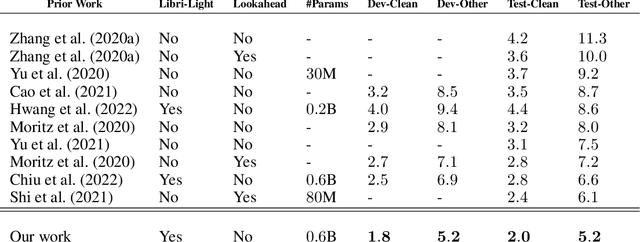
In streaming settings, speech recognition models have to map sub-sequences of speech to text before the full audio stream becomes available. However, since alignment information between speech and text is rarely available during training, models need to learn it in a completely self-supervised way. In practice, the exponential number of possible alignments makes this extremely challenging, with models often learning peaky or sub-optimal alignments. Prima facie, the exponential nature of the alignment space makes it difficult to even quantify the uncertainty of a model's alignment distribution. Fortunately, it has been known for decades that the entropy of a probabilistic finite state transducer can be computed in time linear to the size of the transducer via a dynamic programming reduction based on semirings. In this work, we revisit the entropy semiring for neural speech recognition models, and show how alignment entropy can be used to supervise models through regularization or distillation. We also contribute an open-source implementation of CTC and RNN-T in the semiring framework that includes numerically stable and highly parallel variants of the entropy semiring. Empirically, we observe that the addition of alignment distillation improves the accuracy and latency of an already well-optimized teacher-student distillation model, achieving state-of-the-art performance on the Librispeech dataset in the streaming scenario.
Conformer-Based Speech Recognition On Extreme Edge-Computing Devices
Dec 16, 2023With increasingly more powerful compute capabilities and resources in today's devices, traditionally compute-intensive automatic speech recognition (ASR) has been moving from the cloud to devices to better protect user privacy. However, it is still challenging to implement on-device ASR on resource-constrained devices, such as smartphones, smart wearables, and other small home automation devices. In this paper, we propose a series of model architecture adaptions, neural network graph transformations, and numerical optimizations to fit an advanced Conformer based end-to-end streaming ASR system on resource-constrained devices without accuracy degradation. We achieve over 5.26 times faster than realtime (0.19 RTF) speech recognition on small wearables while minimizing energy consumption and achieving state-of-the-art accuracy. The proposed methods are widely applicable to other transformer-based server-free AI applications. In addition, we provide a complete theory on optimal pre-normalizers that numerically stabilize layer normalization in any Lp-norm using any floating point precision.
UCorrect: An Unsupervised Framework for Automatic Speech Recognition Error Correction
Jan 11, 2024Error correction techniques have been used to refine the output sentences from automatic speech recognition (ASR) models and achieve a lower word error rate (WER). Previous works usually adopt end-to-end models and has strong dependency on Pseudo Paired Data and Original Paired Data. But when only pre-training on Pseudo Paired Data, previous models have negative effect on correction. While fine-tuning on Original Paired Data, the source side data must be transcribed by a well-trained ASR model, which takes a lot of time and not universal. In this paper, we propose UCorrect, an unsupervised Detector-Generator-Selector framework for ASR Error Correction. UCorrect has no dependency on the training data mentioned before. The whole procedure is first to detect whether the character is erroneous, then to generate some candidate characters and finally to select the most confident one to replace the error character. Experiments on the public AISHELL-1 dataset and WenetSpeech dataset show the effectiveness of UCorrect for ASR error correction: 1) it achieves significant WER reduction, achieves 6.83\% even without fine-tuning and 14.29\% after fine-tuning; 2) it outperforms the popular NAR correction models by a large margin with a competitive low latency; and 3) it is an universal method, as it reduces all WERs of the ASR model with different decoding strategies and reduces all WERs of ASR models trained on different scale datasets.
AccentFold: A Journey through African Accents for Zero-Shot ASR Adaptation to Target Accents
Feb 05, 2024Despite advancements in speech recognition, accented speech remains challenging. While previous approaches have focused on modeling techniques or creating accented speech datasets, gathering sufficient data for the multitude of accents, particularly in the African context, remains impractical due to their sheer diversity and associated budget constraints. To address these challenges, we propose AccentFold, a method that exploits spatial relationships between learned accent embeddings to improve downstream Automatic Speech Recognition (ASR). Our exploratory analysis of speech embeddings representing 100+ African accents reveals interesting spatial accent relationships highlighting geographic and genealogical similarities, capturing consistent phonological, and morphological regularities, all learned empirically from speech. Furthermore, we discover accent relationships previously uncharacterized by the Ethnologue. Through empirical evaluation, we demonstrate the effectiveness of AccentFold by showing that, for out-of-distribution (OOD) accents, sampling accent subsets for training based on AccentFold information outperforms strong baselines a relative WER improvement of 4.6%. AccentFold presents a promising approach for improving ASR performance on accented speech, particularly in the context of African accents, where data scarcity and budget constraints pose significant challenges. Our findings emphasize the potential of leveraging linguistic relationships to improve zero-shot ASR adaptation to target accents.