 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Speaker Adaptation Using Spectro-Temporal Deep Features for Dysarthric and Elderly Speech Recognition
Mar 17, 2022
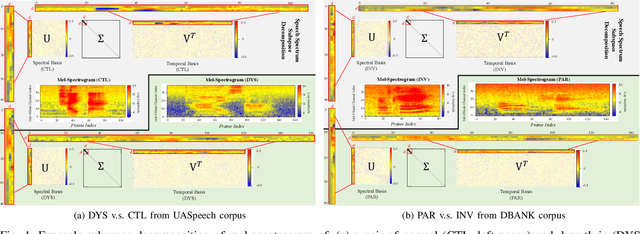
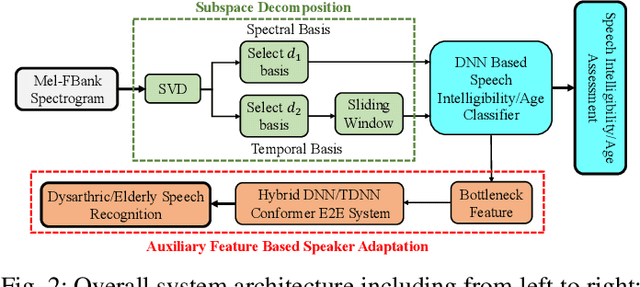
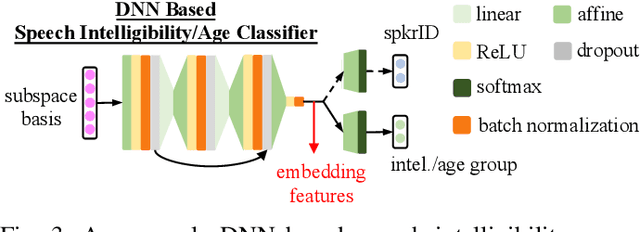
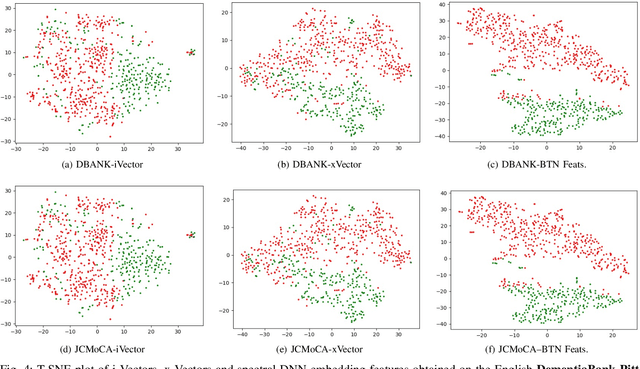
Despite the rapid progress of automatic speech recognition (ASR) technologies targeting normal speech in recent decades, accurate recognition of dysarthric and elderly speech remains highly challenging tasks to date. Sources of heterogeneity commonly found in normal speech including accent or gender, when further compounded with the variability over age and speech pathology severity level, create large diversity among speakers. To this end, speaker adaptation techniques play a key role in personalization of ASR systems for such users. Motivated by the spectro-temporal level differences between dysarthric, elderly and normal speech that systematically manifest in articulatory imprecision, decreased volume and clarity, slower speaking rates and increased dysfluencies, novel spectrotemporal subspace basis deep embedding features derived using SVD speech spectrum decomposition are proposed in this paper to facilitate auxiliary feature based speaker adaptation of state-of-the-art hybrid DNN/TDNN and end-to-end Conformer speech recognition systems. Experiments were conducted on four tasks: the English UASpeech and TORGO dysarthric speech corpora; the English DementiaBank Pitt and Cantonese JCCOCC MoCA elderly speech datasets. The proposed spectro-temporal deep feature adapted systems outperformed baseline i-Vector and xVector adaptation by up to 2.63% absolute (8.63% relative) reduction in word error rate (WER). Consistent performance improvements were retained after model based speaker adaptation using learning hidden unit contributions (LHUC) was further applied. The best speaker adapted system using the proposed spectral basis embedding features produced the lowest published WER of 25.05% on the UASpeech test set of 16 dysarthric speakers.
Knowledge Transfer and Distillation from Autoregressive to Non-Autoregressive Speech Recognition
Jul 15, 2022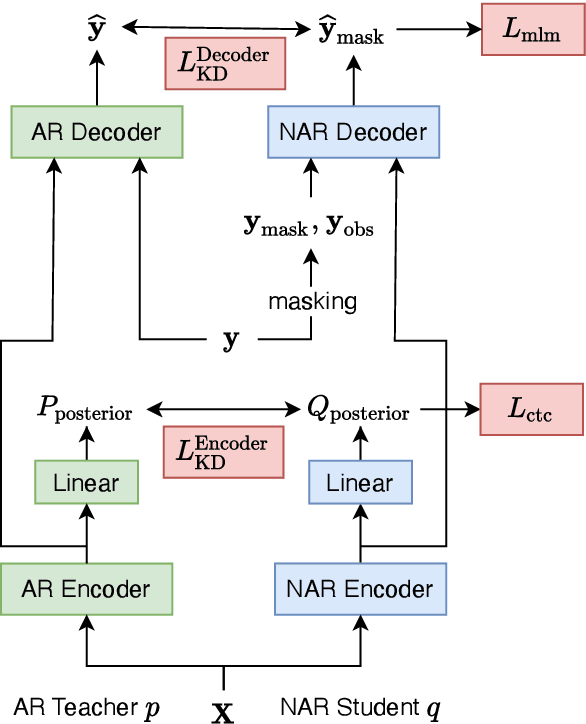
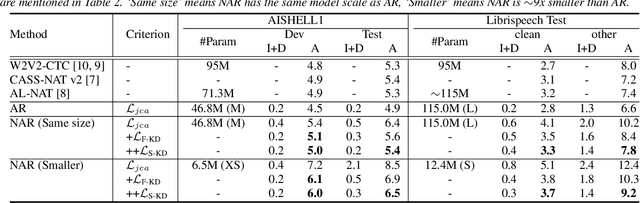
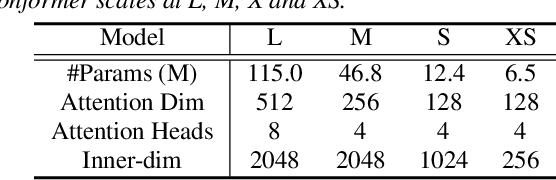
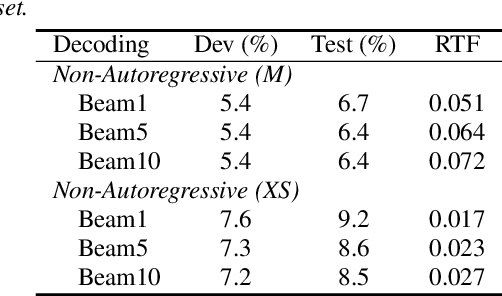
Modern non-autoregressive~(NAR) speech recognition systems aim to accelerate the inference speed; however, they suffer from performance degradation compared with autoregressive~(AR) models as well as the huge model size issue. We propose a novel knowledge transfer and distillation architecture that leverages knowledge from AR models to improve the NAR performance while reducing the model's size. Frame- and sequence-level objectives are well-designed for transfer learning. To further boost the performance of NAR, a beam search method on Mask-CTC is developed to enlarge the search space during the inference stage. Experiments show that the proposed NAR beam search relatively reduces CER by over 5% on AISHELL-1 benchmark with a tolerable real-time-factor~(RTF) increment. By knowledge transfer, the NAR student who has the same size as the AR teacher obtains relative CER reductions of 8/16% on AISHELL-1 dev/test sets, and over 25% relative WER reductions on LibriSpeech test-clean/other sets. Moreover, the ~9x smaller NAR models achieve ~25% relative CER/WER reductions on both AISHELL-1 and LibriSpeech benchmarks with the proposed knowledge transfer and distillation.
Self-Supervised Learning-Based Source Separation for Meeting Data
Apr 03, 2023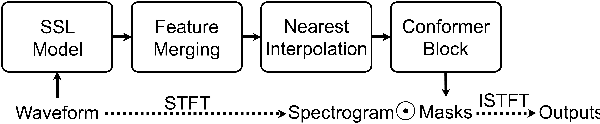
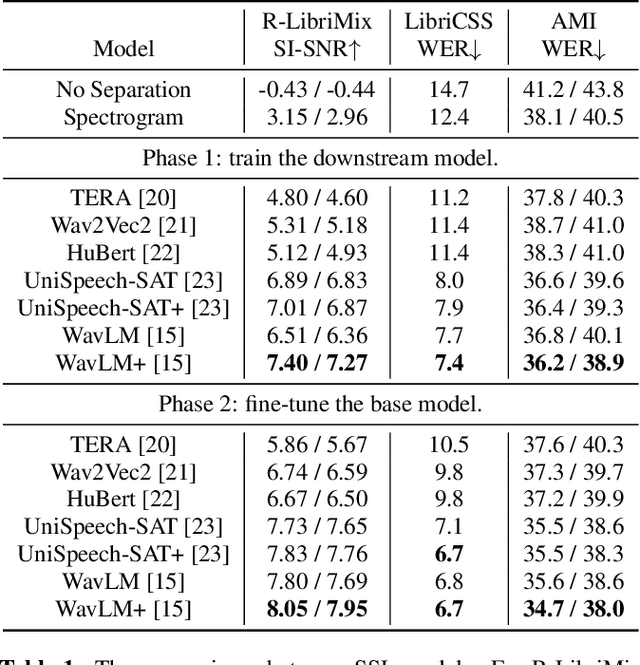

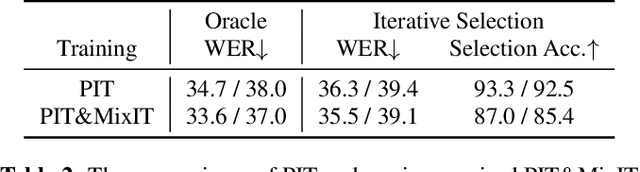
Source separation can improve automatic speech recognition (ASR) under multi-party meeting scenarios by extracting single-speaker signals from overlapped speech. Despite the success of self-supervised learning models in single-channel source separation, most studies have focused on simulated setups. In this paper, seven SSL models were compared on both simulated and real-world corpora. Then, we propose to integrate the best-performing model WavLM into an automatic transcription system through a novel iterative source selection method. To improve real-world performance, time-domain unsupervised mixture invariant training was adapted to the time-frequency domain. Experiments showed that in the transcription system when source separation was inserted before an ASR model fine-tuned on separated speech, absolute reductions of 1.9% and 1.5% in concatenated minimum-permutation word error rate for an unknown number of speakers (cpWER-us) were observed on the AMI dev and test sets.
Improving Speech Recognition for Indic Languages using Language Model
Mar 30, 2022
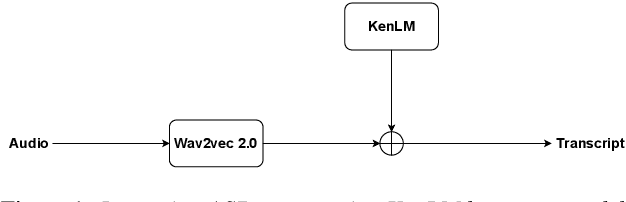
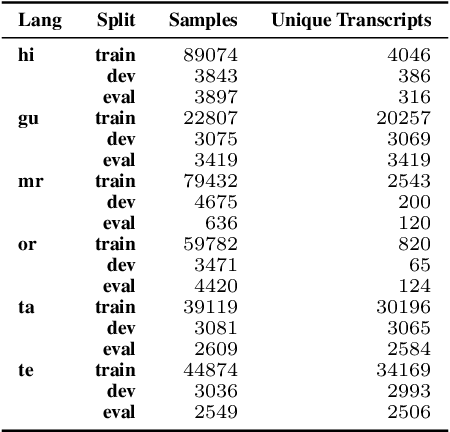
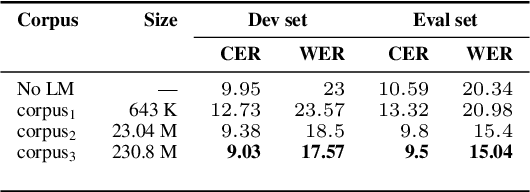
We study the effect of applying a language model (LM) on the output of Automatic Speech Recognition (ASR) systems for Indic languages. We fine-tune wav2vec $2.0$ models for $18$ Indic languages and adjust the results with language models trained on text derived from a variety of sources. Our findings demonstrate that the average Character Error Rate (CER) decreases by over $28$ \% and the average Word Error Rate (WER) decreases by about $36$ \% after decoding with LM. We show that a large LM may not provide a substantial improvement as compared to a diverse one. We also demonstrate that high quality transcriptions can be obtained on domain-specific data without retraining the ASR model and show results on biomedical domain.
Successes and critical failures of neural networks in capturing human-like speech recognition
Apr 06, 2022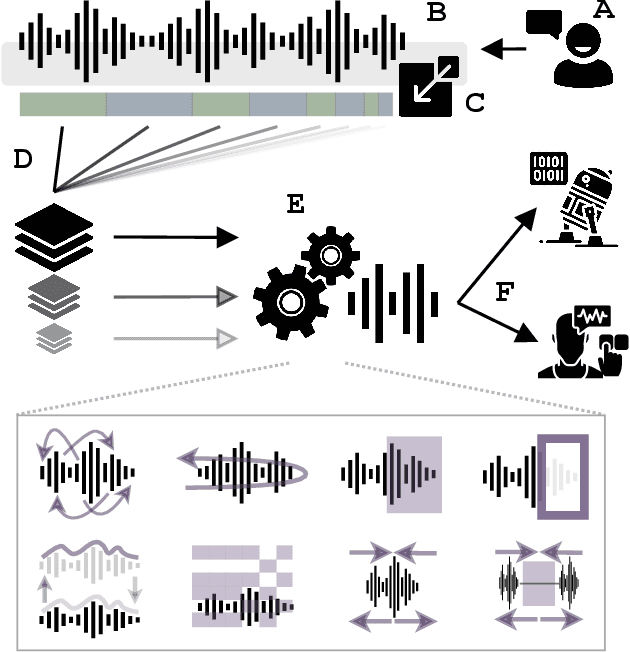
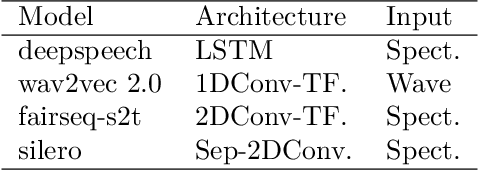
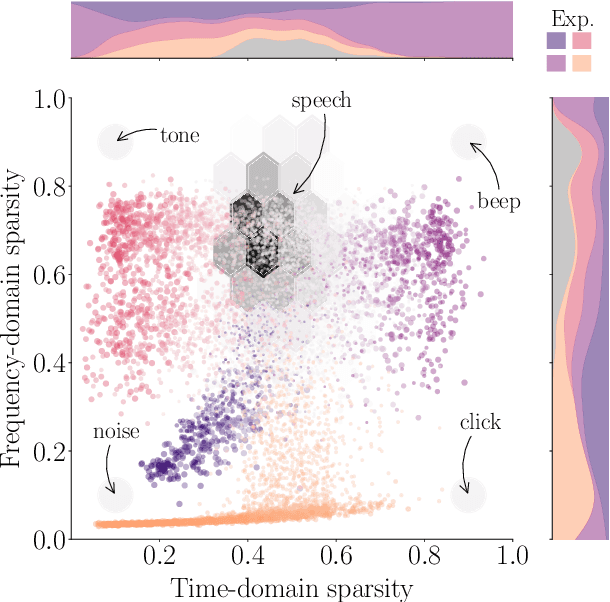
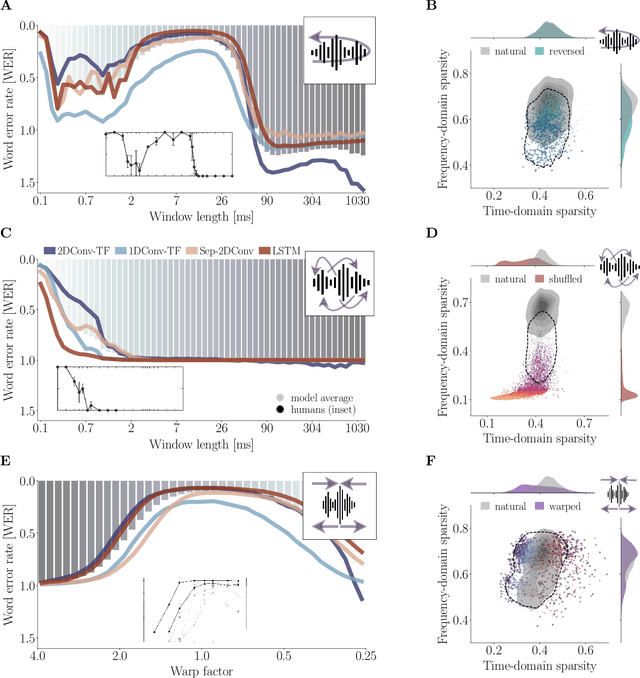
Natural and artificial audition can in principle evolve different solutions to a given problem. The constraints of the task, however, can nudge the cognitive science and engineering of audition to qualitatively converge, suggesting that a closer mutual examination would improve artificial hearing systems and process models of the mind and brain. Speech recognition - an area ripe for such exploration - is inherently robust in humans to a number transformations at various spectrotemporal granularities. To what extent are these robustness profiles accounted for by high-performing neural network systems? We bring together experiments in speech recognition under a single synthesis framework to evaluate state-of-the-art neural networks as stimulus-computable, optimized observers. In a series of experiments, we (1) clarify how influential speech manipulations in the literature relate to each other and to natural speech, (2) show the granularities at which machines exhibit out-of-distribution robustness, reproducing classical perceptual phenomena in humans, (3) identify the specific conditions where model predictions of human performance differ, and (4) demonstrate a crucial failure of all artificial systems to perceptually recover where humans do, suggesting a key specification for theory and model building. These findings encourage a tighter synergy between the cognitive science and engineering of audition.
Speech Reconstruction from Silent Tongue and Lip Articulation By Pseudo Target Generation and Domain Adversarial Training
Apr 12, 2023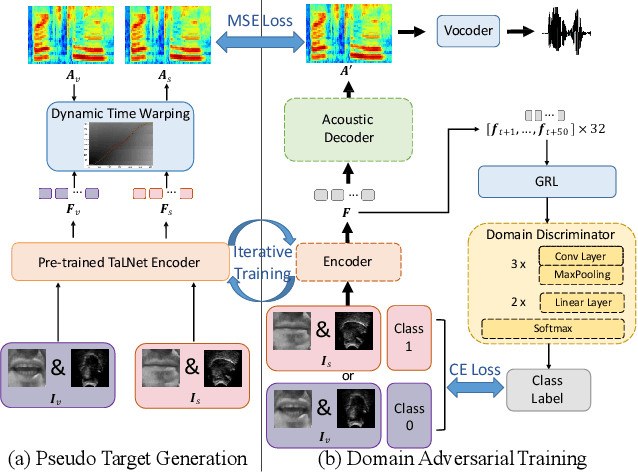
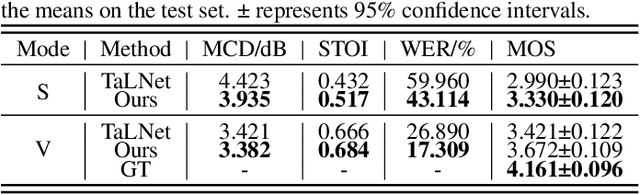
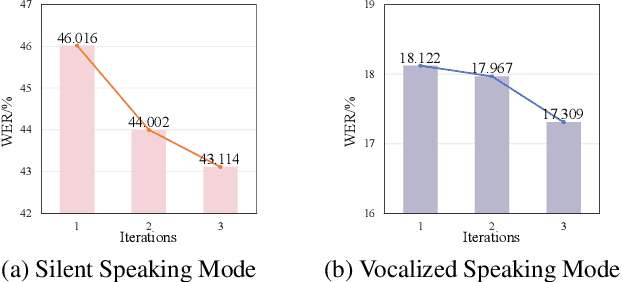
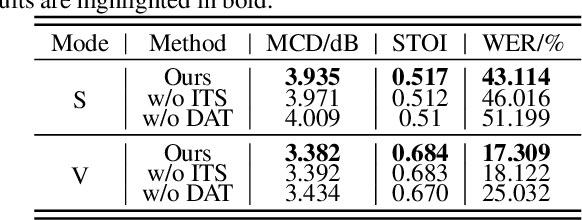
This paper studies the task of speech reconstruction from ultrasound tongue images and optical lip videos recorded in a silent speaking mode, where people only activate their intra-oral and extra-oral articulators without producing sound. This task falls under the umbrella of articulatory-to-acoustic conversion, and may also be refered to as a silent speech interface. We propose to employ a method built on pseudo target generation and domain adversarial training with an iterative training strategy to improve the intelligibility and naturalness of the speech recovered from silent tongue and lip articulation. Experiments show that our proposed method significantly improves the intelligibility and naturalness of the reconstructed speech in silent speaking mode compared to the baseline TaLNet model. When using an automatic speech recognition (ASR) model to measure intelligibility, the word error rate (WER) of our proposed method decreases by over 15% compared to the baseline. In addition, our proposed method also outperforms the baseline on the intelligibility of the speech reconstructed in vocalized articulating mode, reducing the WER by approximately 10%.
Conversational Speech Recognition By Learning Conversation-level Characteristics
Feb 17, 2022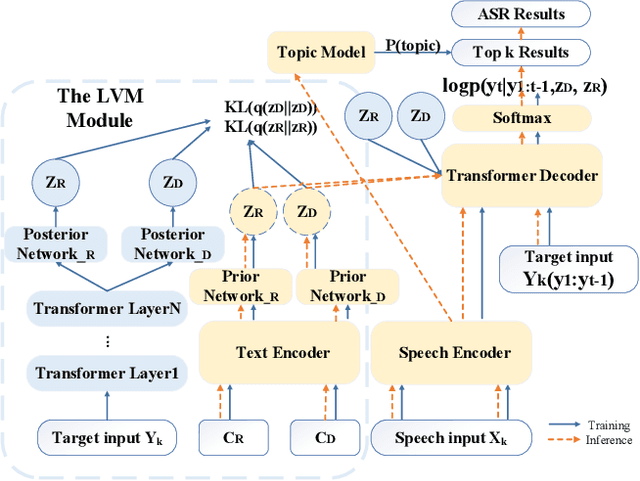

Conversational automatic speech recognition (ASR) is a task to recognize conversational speech including multiple speakers. Unlike sentence-level ASR, conversational ASR can naturally take advantages from specific characteristics of conversation, such as role preference and topical coherence. This paper proposes a conversational ASR model which explicitly learns conversation-level characteristics under the prevalent end-to-end neural framework. The highlights of the proposed model are twofold. First, a latent variational module (LVM) is attached to a conformer-based encoder-decoder ASR backbone to learn role preference and topical coherence. Second, a topic model is specifically adopted to bias the outputs of the decoder to words in the predicted topics. Experiments on two Mandarin conversational ASR tasks show that the proposed model achieves a maximum 12% relative character error rate (CER) reduction.
Nextformer: A ConvNeXt Augmented Conformer For End-To-End Speech Recognition
Jun 30, 2022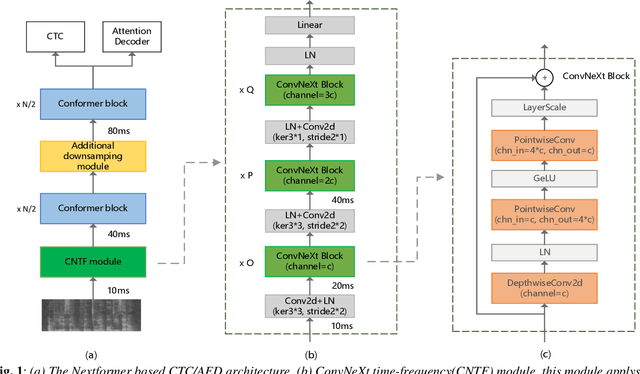
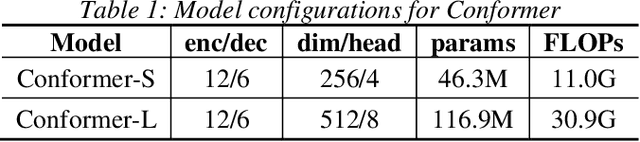
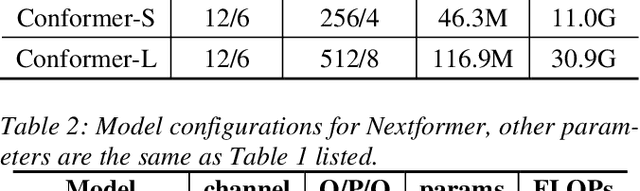
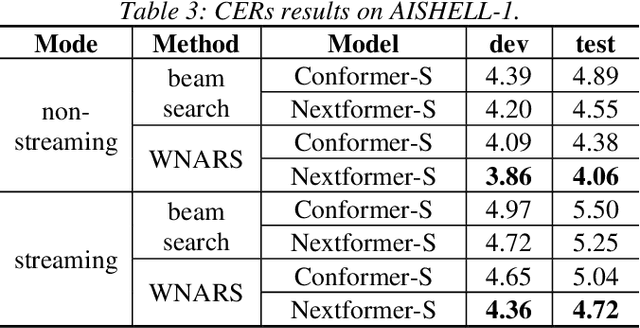
Conformer models have achieved state-of-the-art(SOTA) results in end-to-end speech recognition. However Conformer mainly focuses on temporal modeling while pays less attention on time-frequency property of speech feature. In this paper we augment Conformer with ConvNeXt and propose Nextformer structure. We use stacks of ConvNeXt block to replace the commonly used subsampling module in Conformer for utilizing the information contained in time-frequency speech feature. Besides, we insert an additional downsampling module in middle of Conformer layers to make our model more efficient and accurate. We conduct experiments on two opening datasets, AISHELL-1 and WenetSpeech. On AISHELL-1, compared to Conformer baselines, Nextformer obtains 7.3% and 6.3% relative CER reduction in non-streaming and streaming mode respectively, and on a much larger WenetSpeech dataset, Nextformer gives 5.0%~6.5% and 7.5%~14.6% relative CER reduction in non-streaming and streaming mode, while keep the computational cost FLOPs comparable to Conformer. To the best of our knowledge, the proposed Nextformer model achieves SOTA results on AISHELL-1(CER 4.06%) and WenetSpeech(CER 7.56%/11.29%).
Boosting Cross-Domain Speech Recognition with Self-Supervision
Jun 20, 2022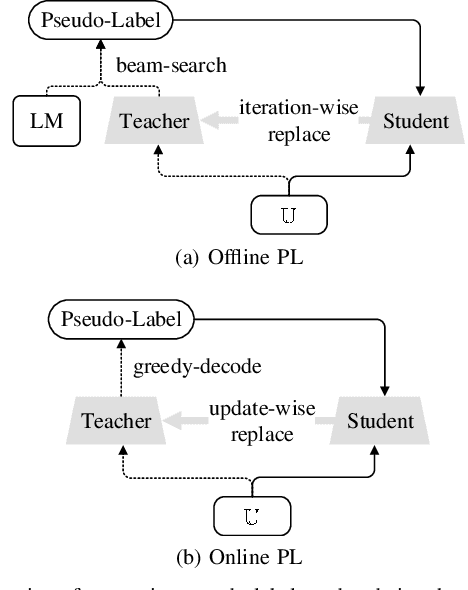
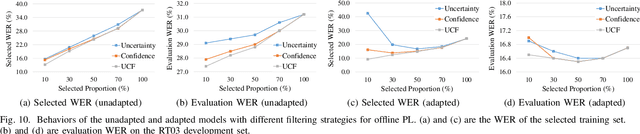
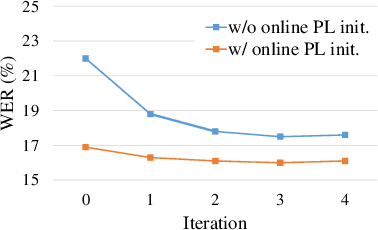
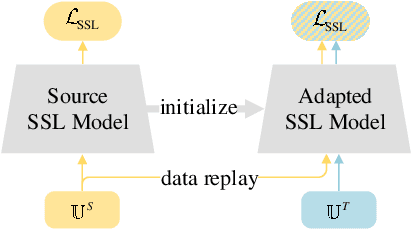
The cross-domain performance of automatic speech recognition (ASR) could be severely hampered due to the mismatch between training and testing distributions. Since the target domain usually lacks labeled data, and domain shifts exist at acoustic and linguistic levels, it is challenging to perform unsupervised domain adaptation (UDA) for ASR. Previous work has shown that self-supervised learning (SSL) or pseudo-labeling (PL) is effective in UDA by exploiting the self-supervisions of unlabeled data. However, these self-supervisions also face performance degradation in mismatched domain distributions, which previous work fails to address. This work presents a systematic UDA framework to fully utilize the unlabeled data with self-supervision in the pre-training and fine-tuning paradigm. On the one hand, we apply continued pre-training and data replay techniques to mitigate the domain mismatch of the SSL pre-trained model. On the other hand, we propose a domain-adaptive fine-tuning approach based on the PL technique with three unique modifications: Firstly, we design a dual-branch PL method to decrease the sensitivity to the erroneous pseudo-labels; Secondly, we devise an uncertainty-aware confidence filtering strategy to improve pseudo-label correctness; Thirdly, we introduce a two-step PL approach to incorporate target domain linguistic knowledge, thus generating more accurate target domain pseudo-labels. Experimental results on various cross-domain scenarios demonstrate that the proposed approach could effectively boost the cross-domain performance and significantly outperform previous approaches.
A CTC Triggered Siamese Network with Spatial-Temporal Dropout for Speech Recognition
Jun 22, 2022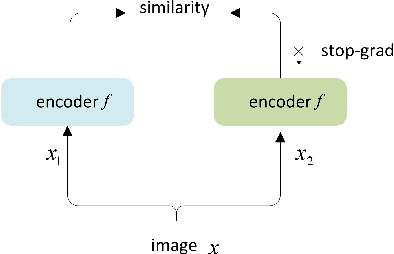
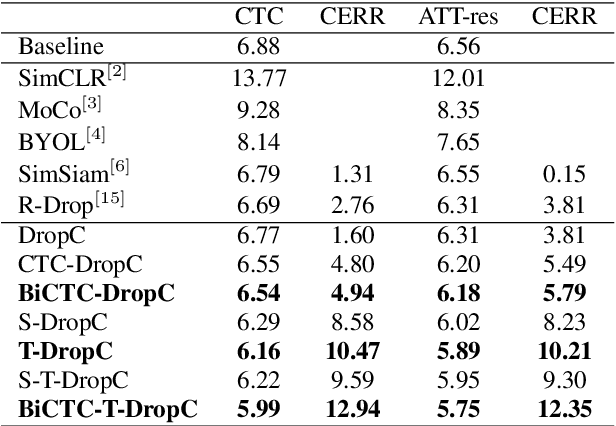
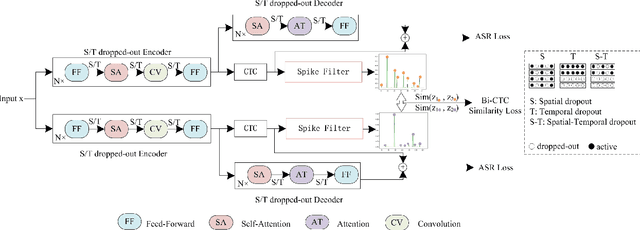
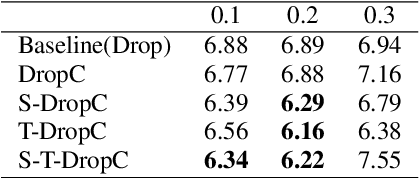
Siamese networks have shown effective results in unsupervised visual representation learning. These models are designed to learn an invariant representation of two augmentations for one input by maximizing their similarity. In this paper, we propose an effective Siamese network to improve the robustness of End-to-End automatic speech recognition (ASR). We introduce spatial-temporal dropout to support a more violent disturbance for Siamese-ASR framework. Besides, we also relax the similarity regularization to maximize the similarities of distributions on the frames that connectionist temporal classification (CTC) spikes occur rather than on all of them. The efficiency of the proposed architecture is evaluated on two benchmarks, AISHELL-1 and Librispeech, resulting in 7.13% and 6.59% relative character error rate (CER) and word error rate (WER) reductions respectively. Analysis shows that our proposed approach brings a better uniformity for the trained model and enlarges the CTC spikes obviously.