 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
X-LLM: Bootstrapping Advanced Large Language Models by Treating Multi-Modalities as Foreign Languages
May 10, 2023
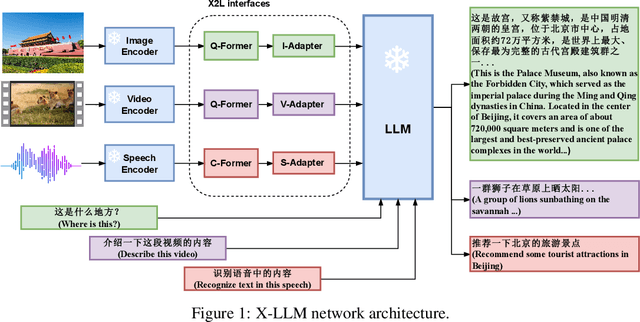
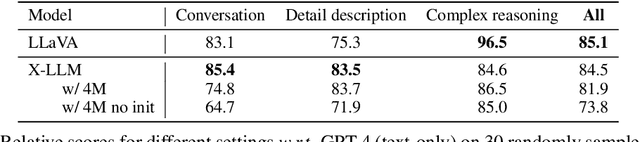


Large language models (LLMs) have demonstrated remarkable language abilities. GPT-4, based on advanced LLMs, exhibits extraordinary multimodal capabilities beyond previous visual language models. We attribute this to the use of more advanced LLMs compared with previous multimodal models. Unfortunately, the model architecture and training strategies of GPT-4 are unknown. To endow LLMs with multimodal capabilities, we propose X-LLM, which converts Multi-modalities (images, speech, videos) into foreign languages using X2L interfaces and inputs them into a large Language model (ChatGLM). Specifically, X-LLM aligns multiple frozen single-modal encoders and a frozen LLM using X2L interfaces, where ``X'' denotes multi-modalities such as image, speech, and videos, and ``L'' denotes languages. X-LLM's training consists of three stages: (1) Converting Multimodal Information: The first stage trains each X2L interface to align with its respective single-modal encoder separately to convert multimodal information into languages. (2) Aligning X2L representations with the LLM: single-modal encoders are aligned with the LLM through X2L interfaces independently. (3) Integrating multiple modalities: all single-modal encoders are aligned with the LLM through X2L interfaces to integrate multimodal capabilities into the LLM. Our experiments show that X-LLM demonstrates impressive multimodel chat abilities, sometimes exhibiting the behaviors of multimodal GPT-4 on unseen images/instructions, and yields a 84.5\% relative score compared with GPT-4 on a synthetic multimodal instruction-following dataset. And we also conduct quantitative tests on using LLM for ASR and multimodal ASR, hoping to promote the era of LLM-based speech recognition.
DST: Deformable Speech Transformer for Emotion Recognition
Feb 27, 2023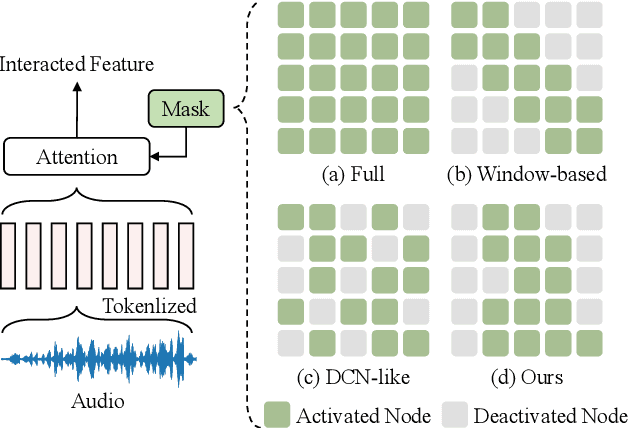
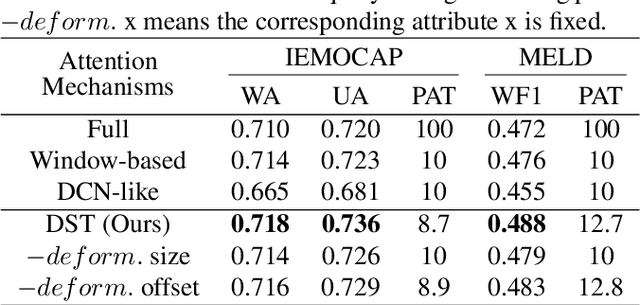
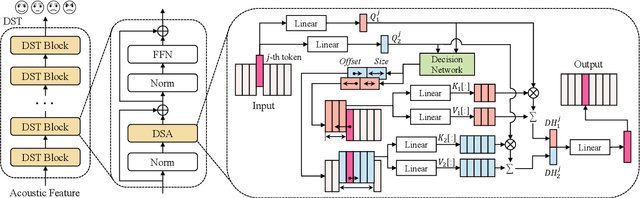
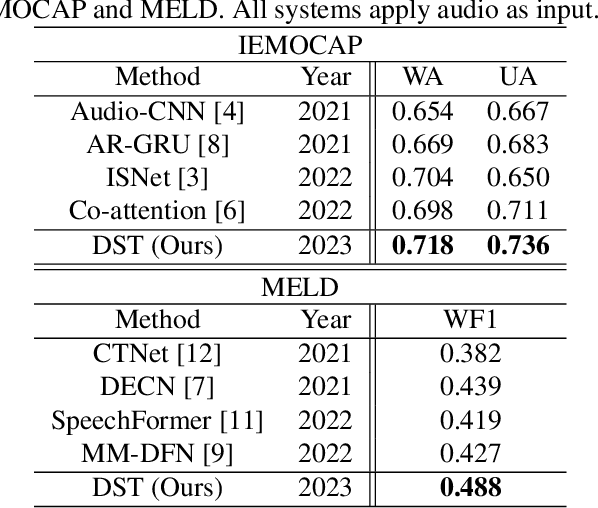
Enabled by multi-head self-attention, Transformer has exhibited remarkable results in speech emotion recognition (SER). Compared to the original full attention mechanism, window-based attention is more effective in learning fine-grained features while greatly reducing model redundancy. However, emotional cues are present in a multi-granularity manner such that the pre-defined fixed window can severely degrade the model flexibility. In addition, it is difficult to obtain the optimal window settings manually. In this paper, we propose a Deformable Speech Transformer, named DST, for SER task. DST determines the usage of window sizes conditioned on input speech via a light-weight decision network. Meanwhile, data-dependent offsets derived from acoustic features are utilized to adjust the positions of the attention windows, allowing DST to adaptively discover and attend to the valuable information embedded in the speech. Extensive experiments on IEMOCAP and MELD demonstrate the superiority of DST.
Stabilizing Transformer Training by Preventing Attention Entropy Collapse
Mar 11, 2023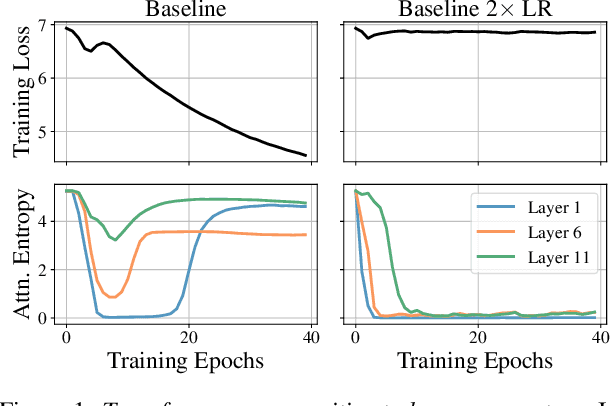
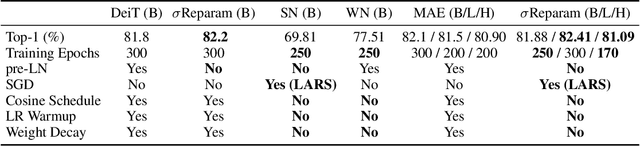
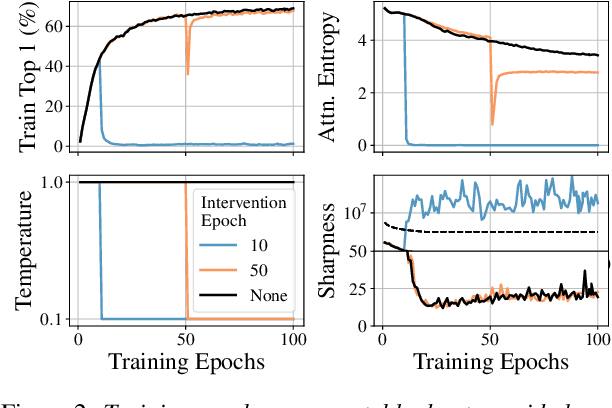
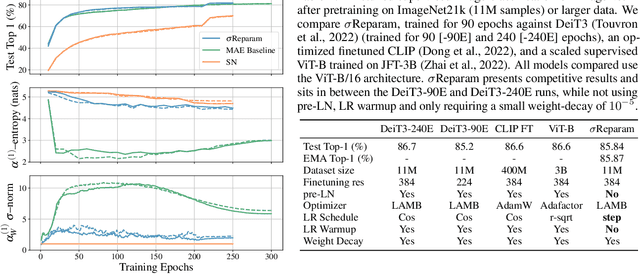
Training stability is of great importance to Transformers. In this work, we investigate the training dynamics of Transformers by examining the evolution of the attention layers. In particular, we track the attention entropy for each attention head during the course of training, which is a proxy for model sharpness. We identify a common pattern across different architectures and tasks, where low attention entropy is accompanied by high training instability, which can take the form of oscillating loss or divergence. We denote the pathologically low attention entropy, corresponding to highly concentrated attention scores, as $\textit{entropy collapse}$. As a remedy, we propose $\sigma$Reparam, a simple and efficient solution where we reparametrize all linear layers with spectral normalization and an additional learned scalar. We demonstrate that the proposed reparameterization successfully prevents entropy collapse in the attention layers, promoting more stable training. Additionally, we prove a tight lower bound of the attention entropy, which decreases exponentially fast with the spectral norm of the attention logits, providing additional motivation for our approach. We conduct experiments with $\sigma$Reparam on image classification, image self-supervised learning, machine translation, automatic speech recognition, and language modeling tasks, across Transformer architectures. We show that $\sigma$Reparam provides stability and robustness with respect to the choice of hyperparameters, going so far as enabling training (a) a Vision Transformer to competitive performance without warmup, weight decay, layer normalization or adaptive optimizers; (b) deep architectures in machine translation and (c) speech recognition to competitive performance without warmup and adaptive optimizers.
HuBERT-EE: Early Exiting HuBERT for Efficient Speech Recognition
Apr 13, 2022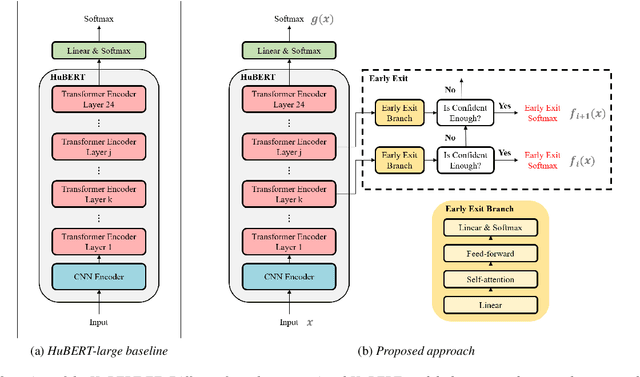
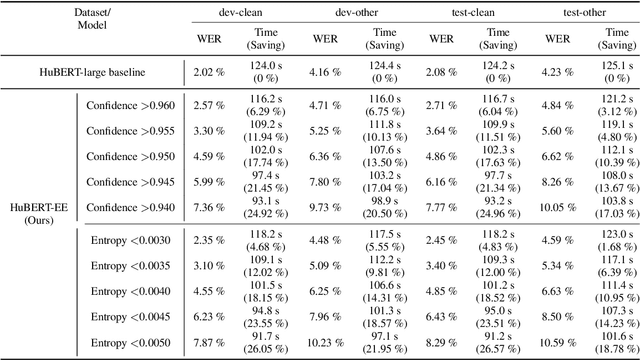

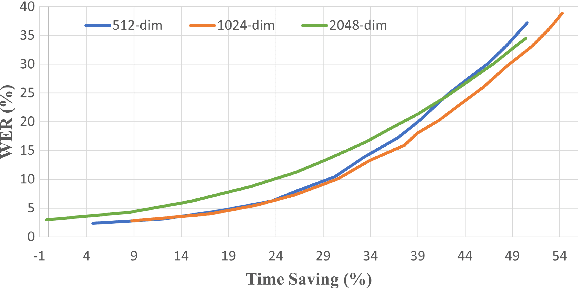
Pre-training with self-supervised models, such as Hidden-unit BERT (HuBERT) and wav2vec 2.0, has brought significant improvements in automatic speech recognition (ASR). However, these models usually require an expensive computational cost to achieve outstanding performance, slowing down the inference speed. To improve the model efficiency, we propose an early exit scheme for ASR, namely HuBERT-EE, that allows the model to stop the inference dynamically. In HuBERT-EE, multiple early exit branches are added at the intermediate layers, and each branch is used to decide whether a prediction can be exited early. Experimental results on the LibriSpeech dataset show that HuBERT-EE can accelerate the inference of a large-scale HuBERT model while simultaneously balancing the trade-off between the word error rate (WER) performance and the latency.
End-to-end speech recognition modeling from de-identified data
Jul 12, 2022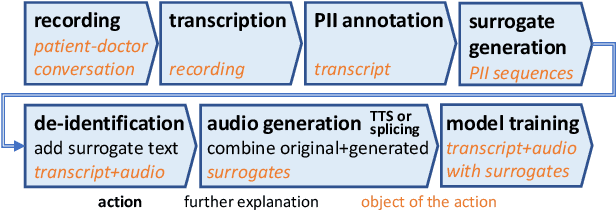
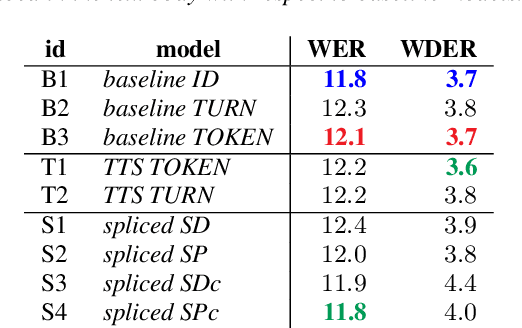
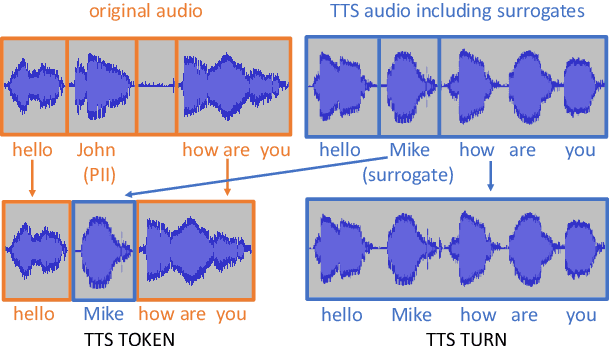
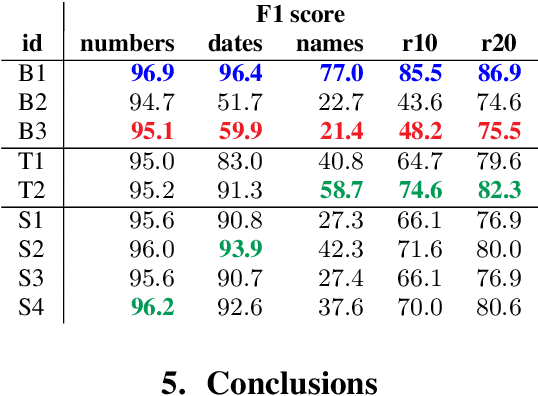
De-identification of data used for automatic speech recognition modeling is a critical component in protecting privacy, especially in the medical domain. However, simply removing all personally identifiable information (PII) from end-to-end model training data leads to a significant performance degradation in particular for the recognition of names, dates, locations, and words from similar categories. We propose and evaluate a two-step method for partially recovering this loss. First, PII is identified, and each occurrence is replaced with a random word sequence of the same category. Then, corresponding audio is produced via text-to-speech or by splicing together matching audio fragments extracted from the corpus. These artificial audio/label pairs, together with speaker turns from the original data without PII, are used to train models. We evaluate the performance of this method on in-house data of medical conversations and observe a recovery of almost the entire performance degradation in the general word error rate while still maintaining a strong diarization performance. Our main focus is the improvement of recall and precision in the recognition of PII-related words. Depending on the PII category, between $50\% - 90\%$ of the performance degradation can be recovered using our proposed method.
Speaker Adaptation Using Spectro-Temporal Deep Features for Dysarthric and Elderly Speech Recognition
Mar 17, 2022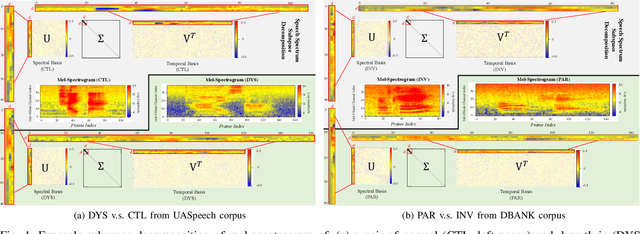
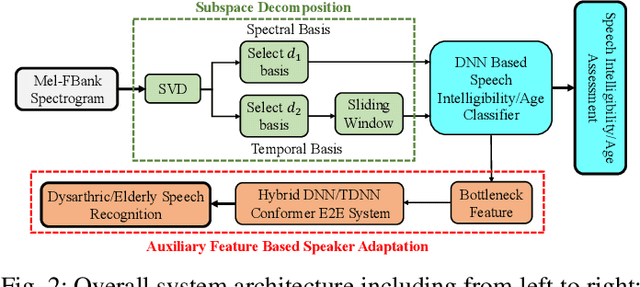
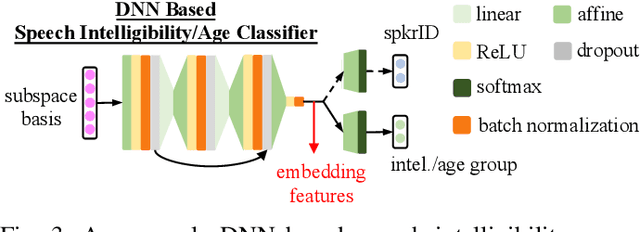
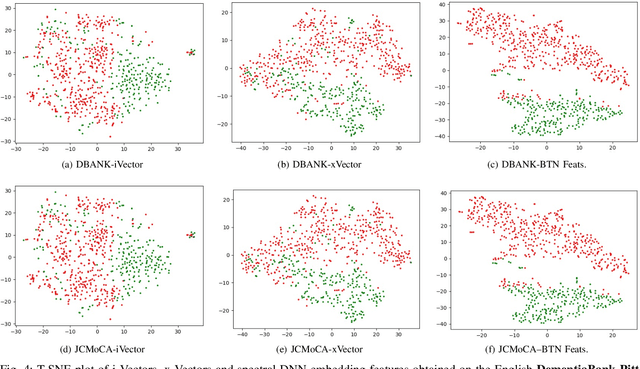
Despite the rapid progress of automatic speech recognition (ASR) technologies targeting normal speech in recent decades, accurate recognition of dysarthric and elderly speech remains highly challenging tasks to date. Sources of heterogeneity commonly found in normal speech including accent or gender, when further compounded with the variability over age and speech pathology severity level, create large diversity among speakers. To this end, speaker adaptation techniques play a key role in personalization of ASR systems for such users. Motivated by the spectro-temporal level differences between dysarthric, elderly and normal speech that systematically manifest in articulatory imprecision, decreased volume and clarity, slower speaking rates and increased dysfluencies, novel spectrotemporal subspace basis deep embedding features derived using SVD speech spectrum decomposition are proposed in this paper to facilitate auxiliary feature based speaker adaptation of state-of-the-art hybrid DNN/TDNN and end-to-end Conformer speech recognition systems. Experiments were conducted on four tasks: the English UASpeech and TORGO dysarthric speech corpora; the English DementiaBank Pitt and Cantonese JCCOCC MoCA elderly speech datasets. The proposed spectro-temporal deep feature adapted systems outperformed baseline i-Vector and xVector adaptation by up to 2.63% absolute (8.63% relative) reduction in word error rate (WER). Consistent performance improvements were retained after model based speaker adaptation using learning hidden unit contributions (LHUC) was further applied. The best speaker adapted system using the proposed spectral basis embedding features produced the lowest published WER of 25.05% on the UASpeech test set of 16 dysarthric speakers.
Supervised Attention in Sequence-to-Sequence Models for Speech Recognition
Apr 25, 2022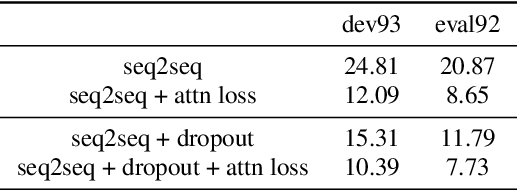
Attention mechanism in sequence-to-sequence models is designed to model the alignments between acoustic features and output tokens in speech recognition. However, attention weights produced by models trained end to end do not always correspond well with actual alignments, and several studies have further argued that attention weights might not even correspond well with the relevance attribution of frames. Regardless, visual similarity between attention weights and alignments is widely used during training as an indicator of the models quality. In this paper, we treat the correspondence between attention weights and alignments as a learning problem by imposing a supervised attention loss. Experiments have shown significant improved performance, suggesting that learning the alignments well during training critically determines the performance of sequence-to-sequence models.
Investigating the effect of domain selection on automatic speech recognition performance: a case study on Bangladeshi Bangla
Oct 24, 2022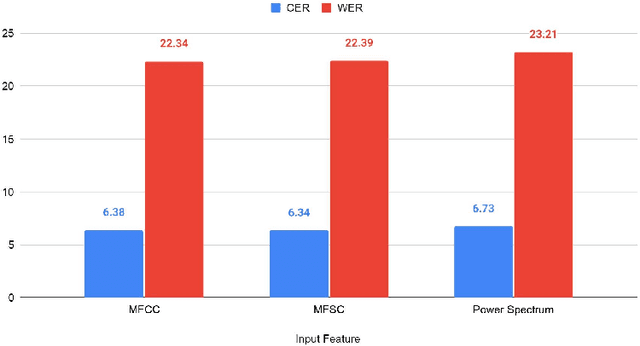
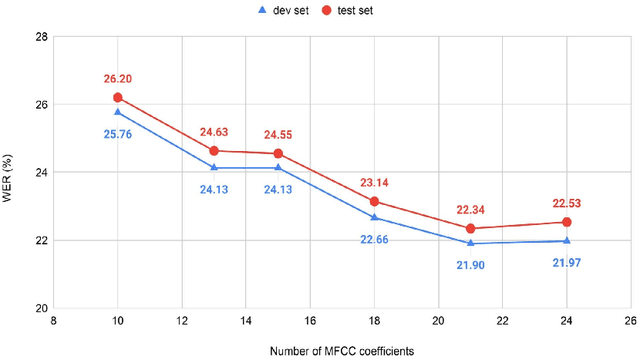
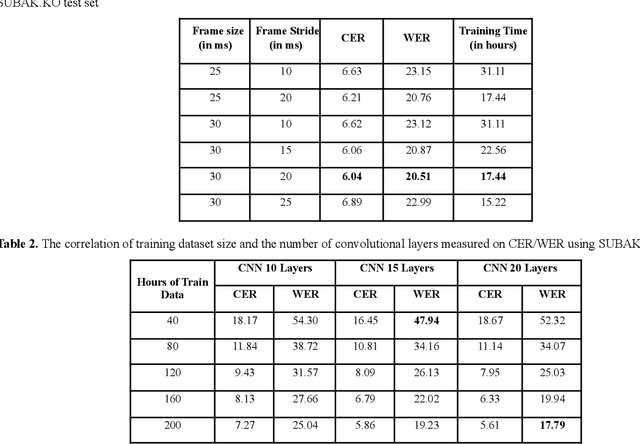
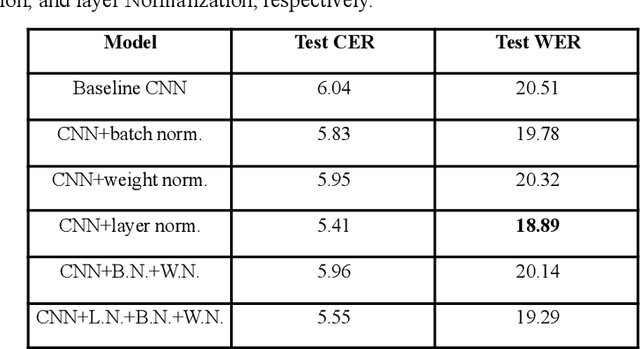
The performance of data-driven natural language processing systems is contingent upon the quality of corpora. However, principal corpus design criteria are often not identified and examined adequately, particularly in the speech processing discipline. Speech corpora development requires additional attention with regard to clean/noisy, read/spontaneous, multi-talker speech, accents/dialects, etc. Domain selection is also a crucial decision point in speech corpus development. In this study, we demonstrate the significance of domain selection by assessing a state-of-the-art Bangla automatic speech recognition (ASR) model on a novel multi-domain Bangladeshi Bangla ASR evaluation benchmark - BanSpeech, which contains 7.2 hours of speech and 9802 utterances from 19 distinct domains. The ASR model has been trained with deep convolutional neural network (CNN), layer normalization technique, and Connectionist Temporal Classification (CTC) loss criterion on SUBAK.KO, a mostly read speech corpus for the low-resource and morphologically rich language Bangla. Experimental evaluation reveals the ASR model on SUBAK.KO faces difficulty recognizing speech from domains with mostly spontaneous speech and has a high number of out-of-vocabulary (OOV) words. The same ASR model, on the other hand, performs better in read speech domains and contains fewer OOV words. In addition, we report the outcomes of our experiments with layer normalization, input feature extraction, number of convolutional layers, etc., and set a baseline on SUBAK.KO. The BanSpeech will be publicly available to meet the need for a challenging evaluation benchmark for Bangla ASR.
OLKAVS: An Open Large-Scale Korean Audio-Visual Speech Dataset
Jan 16, 2023
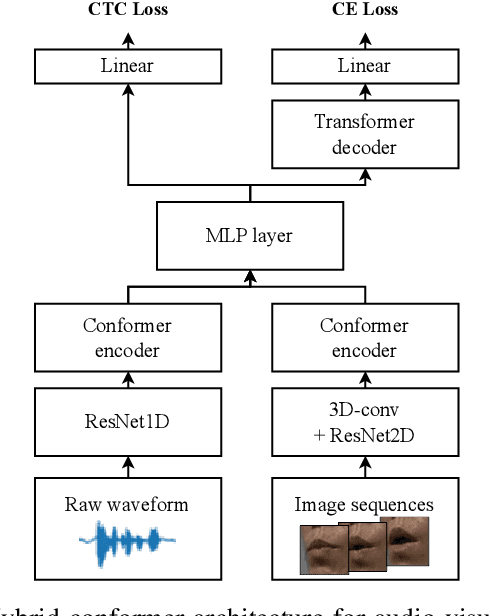
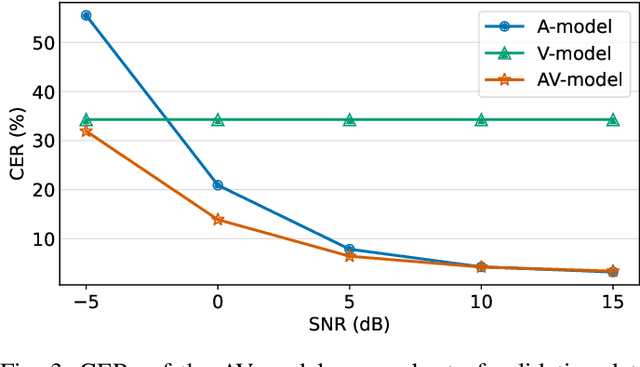
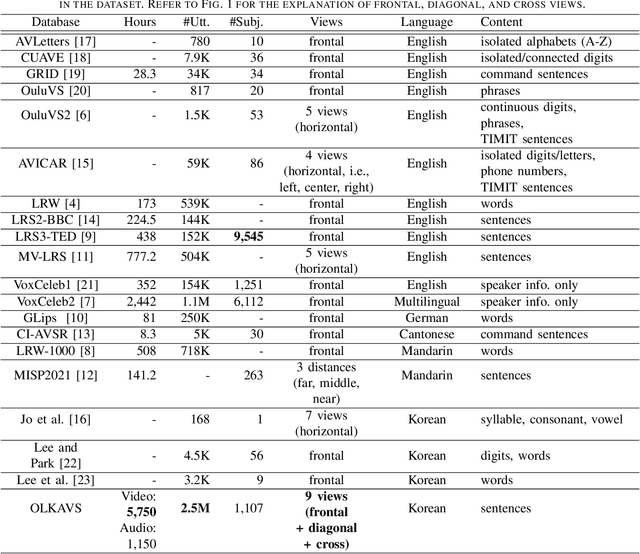
Inspired by humans comprehending speech in a multi-modal manner, various audio-visual datasets have been constructed. However, most existing datasets focus on English, induce dependencies with various prediction models during dataset preparation, and have only a small number of multi-view videos. To mitigate the limitations, we recently developed the Open Large-scale Korean Audio-Visual Speech (OLKAVS) dataset, which is the largest among publicly available audio-visual speech datasets. The dataset contains 1,150 hours of transcribed audio from 1,107 Korean speakers in a studio setup with nine different viewpoints and various noise situations. We also provide the pre-trained baseline models for two tasks, audio-visual speech recognition and lip reading. We conducted experiments based on the models to verify the effectiveness of multi-modal and multi-view training over uni-modal and frontal-view-only training. We expect the OLKAVS dataset to facilitate multi-modal research in broader areas such as Korean speech recognition, speaker recognition, pronunciation level classification, and mouth motion analysis.
Anonymizing Speech: Evaluating and Designing Speaker Anonymization Techniques
Aug 05, 2023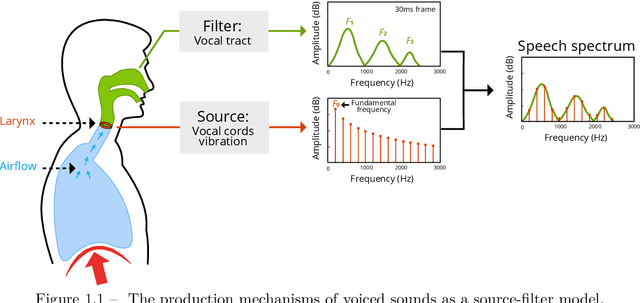
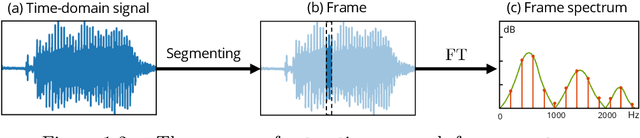
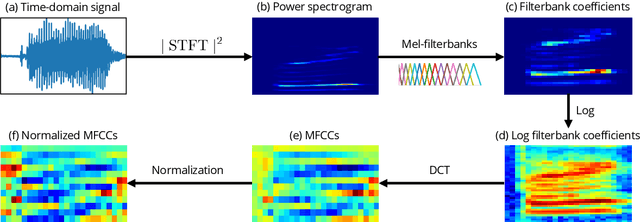
The growing use of voice user interfaces has led to a surge in the collection and storage of speech data. While data collection allows for the development of efficient tools powering most speech services, it also poses serious privacy issues for users as centralized storage makes private personal speech data vulnerable to cyber threats. With the increasing use of voice-based digital assistants like Amazon's Alexa, Google's Home, and Apple's Siri, and with the increasing ease with which personal speech data can be collected, the risk of malicious use of voice-cloning and speaker/gender/pathological/etc. recognition has increased. This thesis proposes solutions for anonymizing speech and evaluating the degree of the anonymization. In this work, anonymization refers to making personal speech data unlinkable to an identity while maintaining the usefulness (utility) of the speech signal (e.g., access to linguistic content). We start by identifying several challenges that evaluation protocols need to consider to evaluate the degree of privacy protection properly. We clarify how anonymization systems must be configured for evaluation purposes and highlight that many practical deployment configurations do not permit privacy evaluation. Furthermore, we study and examine the most common voice conversion-based anonymization system and identify its weak points before suggesting new methods to overcome some limitations. We isolate all components of the anonymization system to evaluate the degree of speaker PPI associated with each of them. Then, we propose several transformation methods for each component to reduce as much as possible speaker PPI while maintaining utility. We promote anonymization algorithms based on quantization-based transformation as an alternative to the most-used and well-known noise-based approach. Finally, we endeavor a new attack method to invert anonymization.