 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Integrated Semantic and Phonetic Post-correction for Chinese Speech Recognition
Nov 16, 2021
Due to the recent advances of natural language processing, several works have applied the pre-trained masked language model (MLM) of BERT to the post-correction of speech recognition. However, existing pre-trained models only consider the semantic correction while the phonetic features of words is neglected. The semantic-only post-correction will consequently decrease the performance since homophonic errors are fairly common in Chinese ASR. In this paper, we proposed a novel approach to collectively exploit the contextualized representation and the phonetic information between the error and its replacing candidates to alleviate the error rate of Chinese ASR. Our experiment results on real world speech recognition datasets showed that our proposed method has evidently lower CER than the baseline model, which utilized a pre-trained BERT MLM as the corrector.
Synthetic Cross-accent Data Augmentation for Automatic Speech Recognition
Mar 01, 2023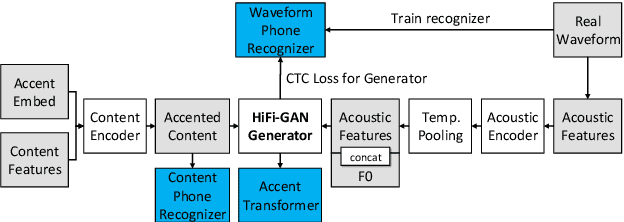
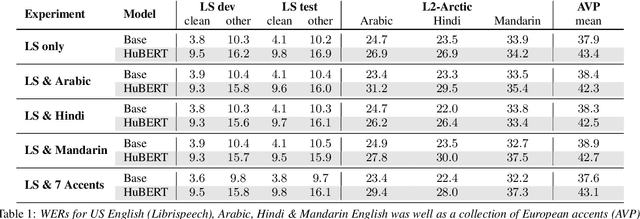
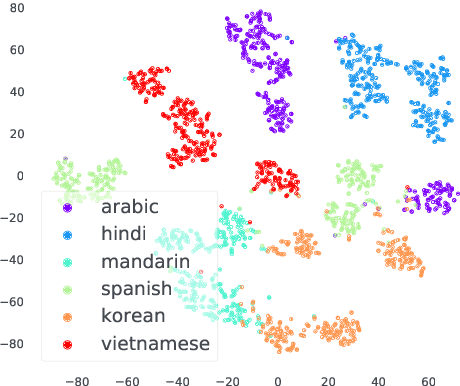
The awareness for biased ASR datasets or models has increased notably in recent years. Even for English, despite a vast amount of available training data, systems perform worse for non-native speakers. In this work, we improve an accent-conversion model (ACM) which transforms native US-English speech into accented pronunciation. We include phonetic knowledge in the ACM training to provide accurate feedback about how well certain pronunciation patterns were recovered in the synthesized waveform. Furthermore, we investigate the feasibility of learned accent representations instead of static embeddings. Generated data was then used to train two state-of-the-art ASR systems. We evaluated our approach on native and non-native English datasets and found that synthetically accented data helped the ASR to better understand speech from seen accents. This observation did not translate to unseen accents, and it was not observed for a model that had been pre-trained exclusively with native speech.
Deep Implicit Distribution Alignment Networks for Cross-Corpus Speech Emotion Recognition
Feb 17, 2023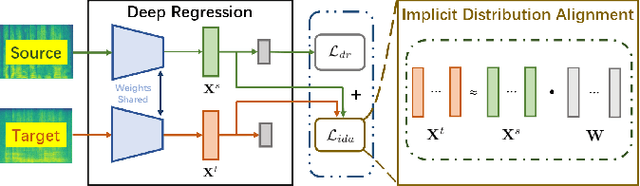
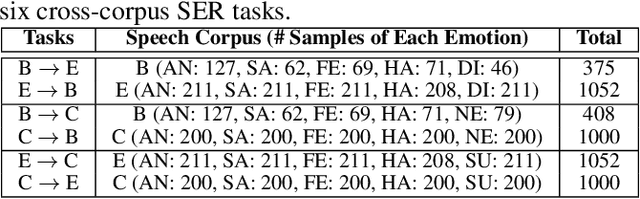
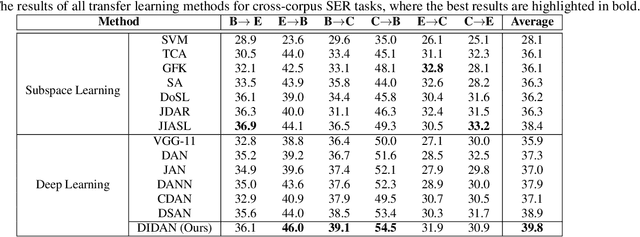
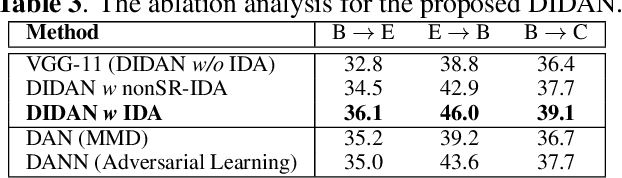
In this paper, we propose a novel deep transfer learning method called deep implicit distribution alignment networks (DIDAN) to deal with cross-corpus speech emotion recognition (SER) problem, in which the labeled training (source) and unlabeled testing (target) speech signals come from different corpora. Specifically, DIDAN first adopts a simple deep regression network consisting of a set of convolutional and fully connected layers to directly regress the source speech spectrums into the emotional labels such that the proposed DIDAN can own the emotion discriminative ability. Then, such ability is transferred to be also applicable to the target speech samples regardless of corpus variance by resorting to a well-designed regularization term called implicit distribution alignment (IDA). Unlike widely-used maximum mean discrepancy (MMD) and its variants, the proposed IDA absorbs the idea of sample reconstruction to implicitly align the distribution gap, which enables DIDAN to learn both emotion discriminative and corpus invariant features from speech spectrums. To evaluate the proposed DIDAN, extensive cross-corpus SER experiments on widely-used speech emotion corpora are carried out. Experimental results show that the proposed DIDAN can outperform lots of recent state-of-the-art methods in coping with the cross-corpus SER tasks.
Multilingual Word Error Rate Estimation: e-WER3
Apr 02, 2023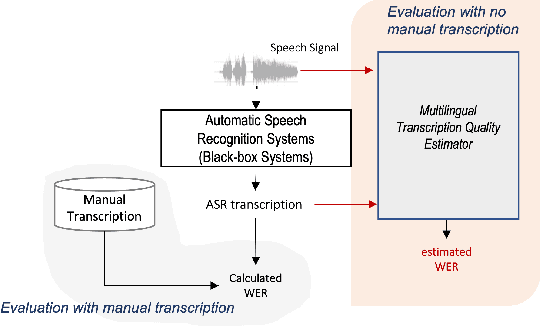

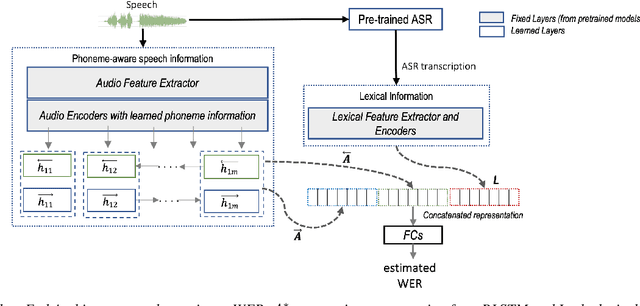
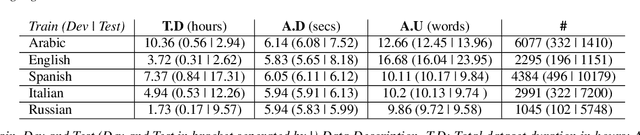
The success of the multilingual automatic speech recognition systems empowered many voice-driven applications. However, measuring the performance of such systems remains a major challenge, due to its dependency on manually transcribed speech data in both mono- and multilingual scenarios. In this paper, we propose a novel multilingual framework -- eWER3 -- jointly trained on acoustic and lexical representation to estimate word error rate. We demonstrate the effectiveness of eWER3 to (i) predict WER without using any internal states from the ASR and (ii) use the multilingual shared latent space to push the performance of the close-related languages. We show our proposed multilingual model outperforms the previous monolingual word error rate estimation method (eWER2) by an absolute 9\% increase in Pearson correlation coefficient (PCC), with better overall estimation between the predicted and reference WER.
Security and Privacy Problems in Voice Assistant Applications: A Survey
Apr 19, 2023
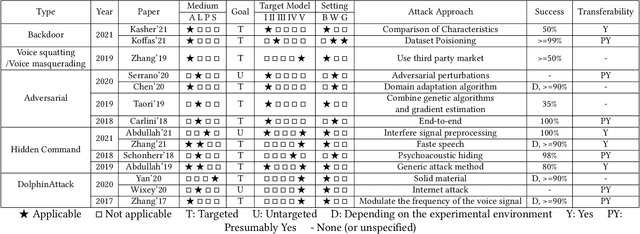
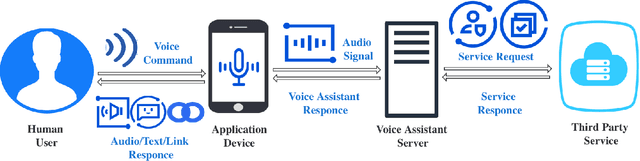
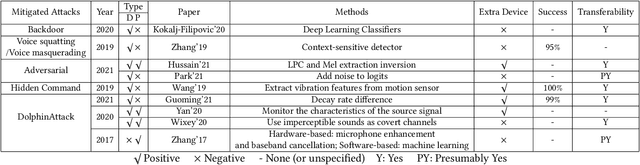
Voice assistant applications have become omniscient nowadays. Two models that provide the two most important functions for real-life applications (i.e., Google Home, Amazon Alexa, Siri, etc.) are Automatic Speech Recognition (ASR) models and Speaker Identification (SI) models. According to recent studies, security and privacy threats have also emerged with the rapid development of the Internet of Things (IoT). The security issues researched include attack techniques toward machine learning models and other hardware components widely used in voice assistant applications. The privacy issues include technical-wise information stealing and policy-wise privacy breaches. The voice assistant application takes a steadily growing market share every year, but their privacy and security issues never stopped causing huge economic losses and endangering users' personal sensitive information. Thus, it is important to have a comprehensive survey to outline the categorization of the current research regarding the security and privacy problems of voice assistant applications. This paper concludes and assesses five kinds of security attacks and three types of privacy threats in the papers published in the top-tier conferences of cyber security and voice domain.
Topic Model Robustness to Automatic Speech Recognition Errors in Podcast Transcripts
Sep 25, 2021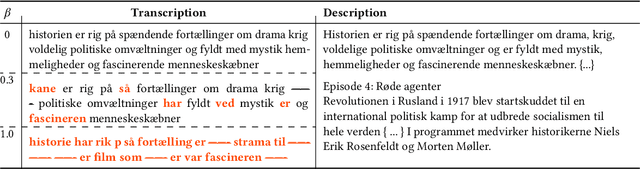
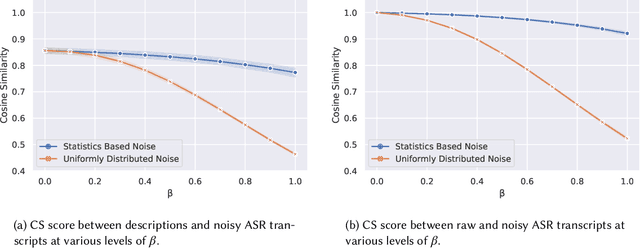

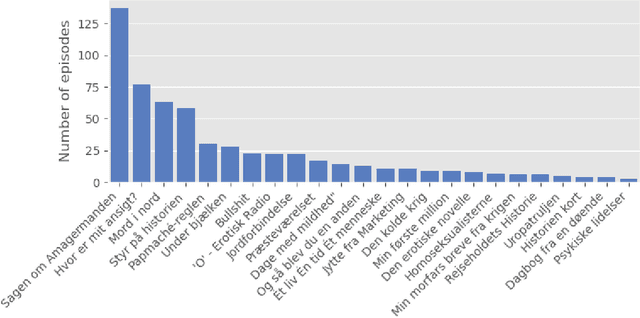
For a multilingual podcast streaming service, it is critical to be able to deliver relevant content to all users independent of language. Podcast content relevance is conventionally determined using various metadata sources. However, with the increasing quality of speech recognition in many languages, utilizing automatic transcriptions to provide better content recommendations becomes possible. In this work, we explore the robustness of a Latent Dirichlet Allocation topic model when applied to transcripts created by an automatic speech recognition engine. Specifically, we explore how increasing transcription noise influences topics obtained from transcriptions in Danish; a low resource language. First, we observe a baseline of cosine similarity scores between topic embeddings from automatic transcriptions and the descriptions of the podcasts written by the podcast creators. We then observe how the cosine similarities decrease as transcription noise increases and conclude that even when automatic speech recognition transcripts are erroneous, it is still possible to obtain high-quality topic embeddings from the transcriptions.
Speaker Reinforcement Using Target Source Extraction for Robust Automatic Speech Recognition
May 09, 2022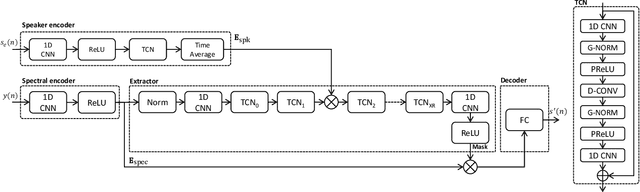

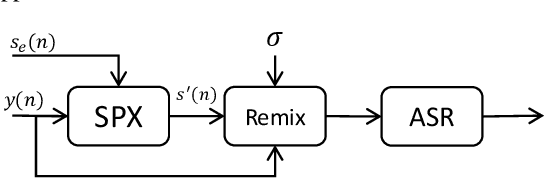
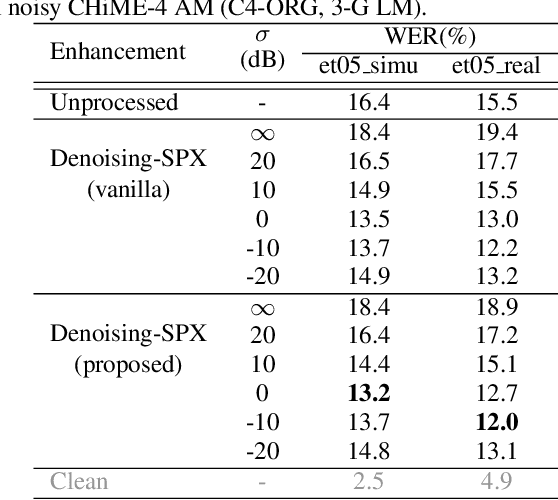
Improving the accuracy of single-channel automatic speech recognition (ASR) in noisy conditions is challenging. Strong speech enhancement front-ends are available, however, they typically require that the ASR model is retrained to cope with the processing artifacts. In this paper we explore a speaker reinforcement strategy for improving recognition performance without retraining the acoustic model (AM). This is achieved by remixing the enhanced signal with the unprocessed input to alleviate the processing artifacts. We evaluate the proposed approach using a DNN speaker extraction based speech denoiser trained with a perceptually motivated loss function. Results show that (without AM retraining) our method yields about 23% and 25% relative accuracy gains compared with the unprocessed for the monoaural simulated and real CHiME-4 evaluation sets, respectively, and outperforms a state-of-the-art reference method.
TransAudio: Towards the Transferable Adversarial Audio Attack via Learning Contextualized Perturbations
Mar 28, 2023
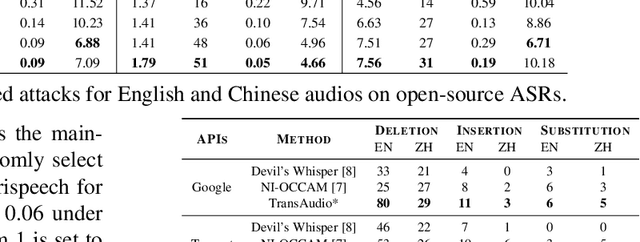
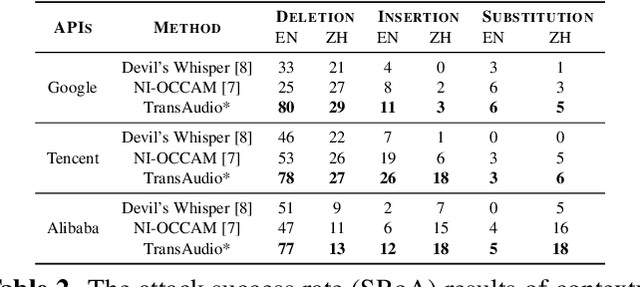
In a transfer-based attack against Automatic Speech Recognition (ASR) systems, attacks are unable to access the architecture and parameters of the target model. Existing attack methods are mostly investigated in voice assistant scenarios with restricted voice commands, prohibiting their applicability to more general ASR related applications. To tackle this challenge, we propose a novel contextualized attack with deletion, insertion, and substitution adversarial behaviors, namely TransAudio, which achieves arbitrary word-level attacks based on the proposed two-stage framework. To strengthen the attack transferability, we further introduce an audio score-matching optimization strategy to regularize the training process, which mitigates adversarial example over-fitting to the surrogate model. Extensive experiments and analysis demonstrate the effectiveness of TransAudio against open-source ASR models and commercial APIs.
Dynamic Chuck Convolution For Unified Streaming And Non-streaming Conformer ASR
Apr 18, 2023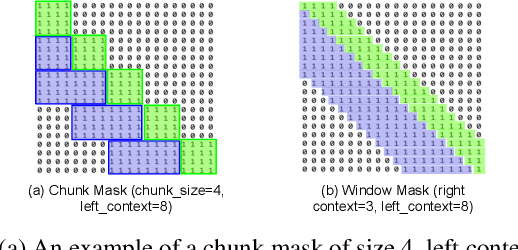
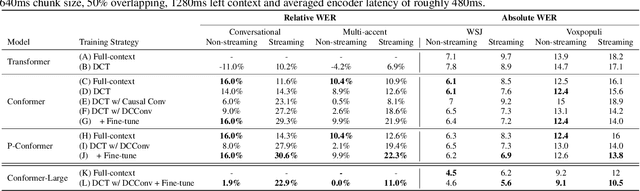
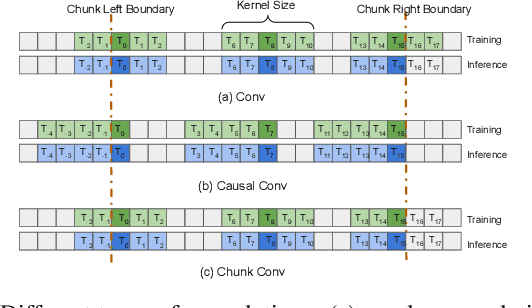
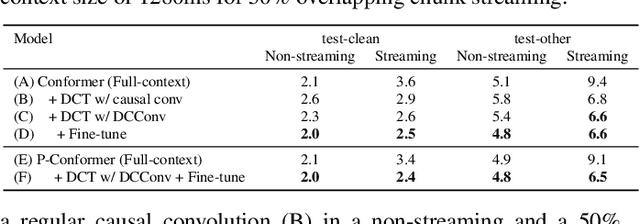
Recently, there has been an increasing interest in unifying streaming and non-streaming speech recognition models to reduce development, training and deployment cost. The best-known approaches rely on either window-based or dynamic chunk-based attention strategy and causal convolutions to minimize the degradation due to streaming. However, the performance gap still remains relatively large between non-streaming and a full-contextual model trained independently. To address this, we propose a dynamic chunk-based convolution replacing the causal convolution in a hybrid Connectionist Temporal Classification (CTC)-Attention Conformer architecture. Additionally, we demonstrate further improvements through initialization of weights from a full-contextual model and parallelization of the convolution and self-attention modules. We evaluate our models on the open-source Voxpopuli, LibriSpeech and in-house conversational datasets. Overall, our proposed model reduces the degradation of the streaming mode over the non-streaming full-contextual model from 41.7% and 45.7% to 16.7% and 26.2% on the LibriSpeech test-clean and test-other datasets respectively, while improving by a relative 15.5% WER over the previous state-of-the-art unified model.
Low latency transformers for speech processing
Feb 27, 2023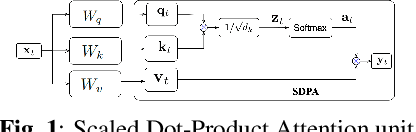

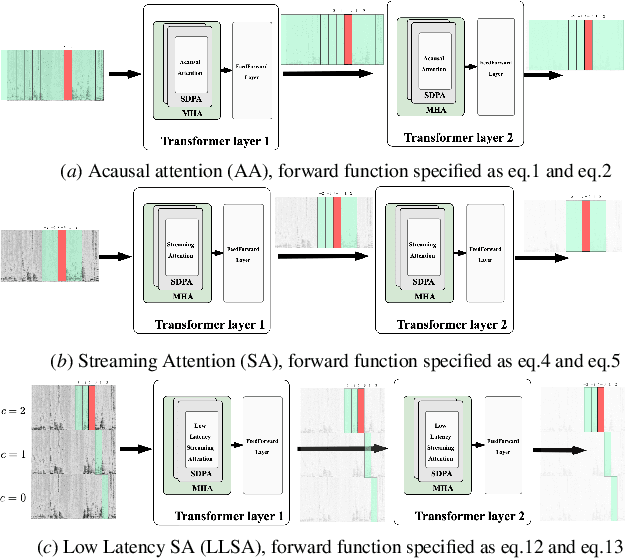
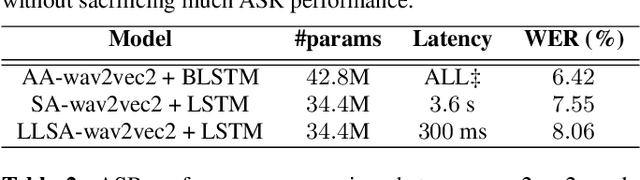
The transformer is a widely-used building block in modern neural networks. However, when applied to audio data, the transformer's acausal behaviour, which we term Acausal Attention (AA), has generally limited its application to offline tasks. In this paper we introduce Streaming Attention (SA), which operates causally with fixed latency, and requires lower compute and memory resources than AA to train. Next, we introduce Low Latency Streaming Attention (LLSA), a method which combines multiple SA layers without latency build-up proportional to the layer count. Comparative analysis between AA, SA and LLSA on Automatic Speech Recognition (ASR) and Speech Emotion Recognition (SER) tasks are presented. The results show that causal SA-based networks with fixed latencies of a few seconds (e.g. 1.8 seconds) and LLSA networks with latencies as short as 300 ms can perform comparably with acausal (AA) networks. We conclude that SA and LLSA methods retain many of the benefits of conventional acausal transformers, but with latency characteristics that make them practical to run in real-time streaming applications.