 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Graph Meets LLM: A Novel Approach to Collaborative Filtering for Robust Conversational Understanding
May 23, 2023
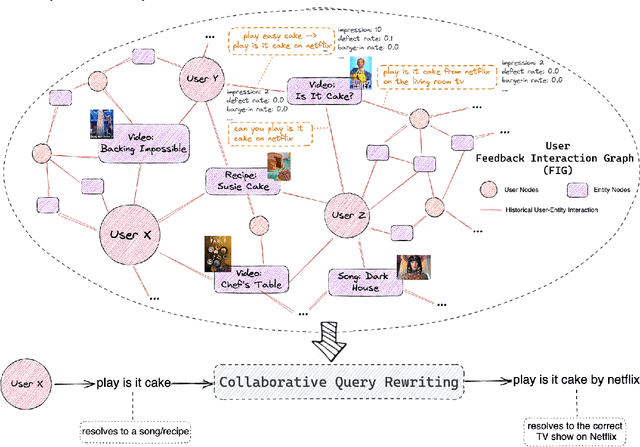
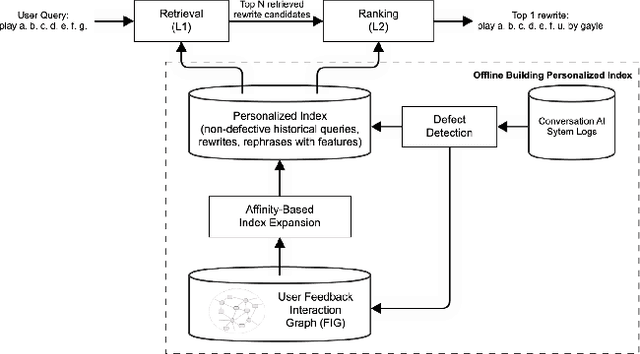


Conversational AI systems (e.g. Alexa, Siri, Google Assistant, etc.) need to understand queries with defects to ensure robust conversational understanding and reduce user frictions. The defective queries are often induced by user ambiguities and mistakes, or errors in the automatic speech recognition (ASR) and natural language understanding (NLU). Personalized query rewriting (personalized QR) targets reducing defects in the torso and tail user query traffic, and it typically relies on an index of past successful user interactions with the conversational AI. This paper presents our "Collaborative Query Rewriting" approach that focuses on rewriting novel user interactions unseen in the user history. This approach builds a "user Feedback Interaction Graph" (FIG) consisting of historical user-entity interactions, and leverages multi-hop customer affinity to enrich each user's index (i.e. the Collaborative User Index) that would help cover future unseen defective queries. To counteract the precision degradation from the enlarged index, we introduced additional transformer layers to the L1 retrieval model and added multi-hop affinity and guardrail features to the L2 re-ranking model. Given the production constraints of storage cost and runtime retrieval latency, managing the size of the Collaborative User Index is important. As the user index can be pre-computed, we explored using a Large Language Model (LLM) for multi-hop customer affinity retrieval on the Video/Music domains. In particular, this paper looked into the Dolly-V2 7B model. Given limited user index size, We found the user index derived from fine-tuned Dolly-V2 generation significantly enhanced coverage of unseen user interactions. Consequently, this boosted QR performance on unseen user interactions compared to the graph traversal based user index.
Personal VAD 2.0: Optimizing Personal Voice Activity Detection for On-Device Speech Recognition
Apr 13, 2022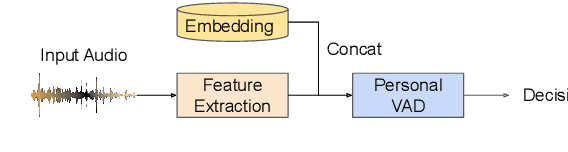
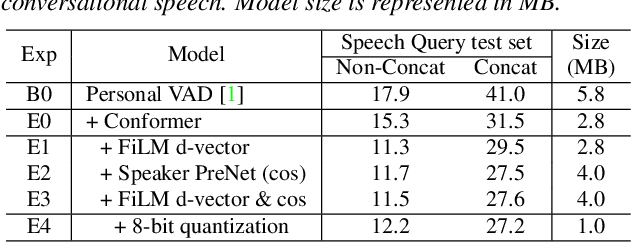
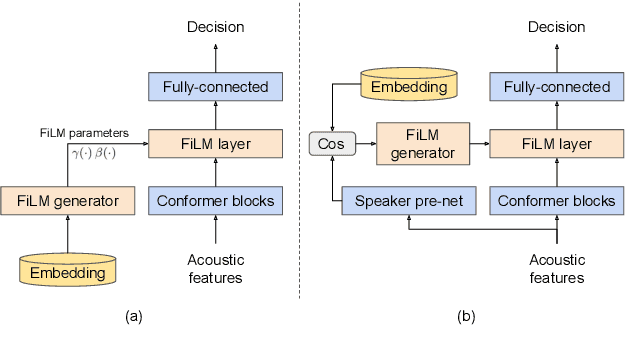
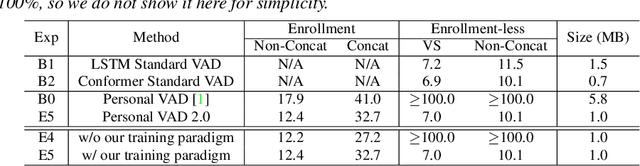
Personalization of on-device speech recognition (ASR) has seen explosive growth in recent years, largely due to the increasing popularity of personal assistant features on mobile devices and smart home speakers. In this work, we present Personal VAD 2.0, a personalized voice activity detector that detects the voice activity of a target speaker, as part of a streaming on-device ASR system. Although previous proof-of-concept studies have validated the effectiveness of Personal VAD, there are still several critical challenges to address before this model can be used in production: first, the quality must be satisfactory in both enrollment and enrollment-less scenarios; second, it should operate in a streaming fashion; and finally, the model size should be small enough to fit a limited latency and CPU/Memory budget. To meet the multi-faceted requirements, we propose a series of novel designs: 1) advanced speaker embedding modulation methods; 2) a new training paradigm to generalize to enrollment-less conditions; 3) architecture and runtime optimizations for latency and resource restrictions. Extensive experiments on a realistic speech recognition system demonstrated the state-of-the-art performance of our proposed method.
Dynamic Chunk Convolution for Unified Streaming and Non-Streaming Conformer ASR
Apr 25, 2023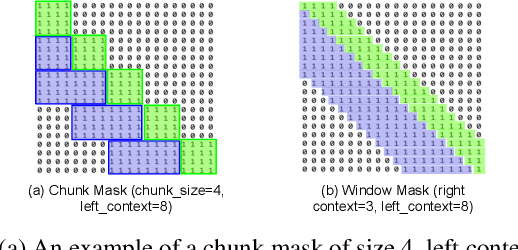
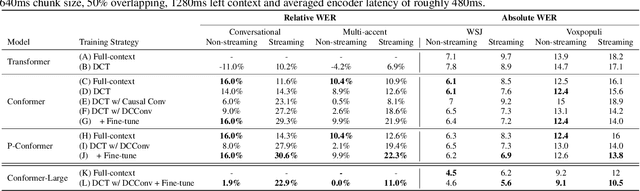
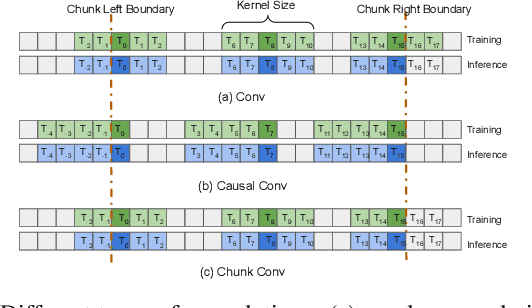
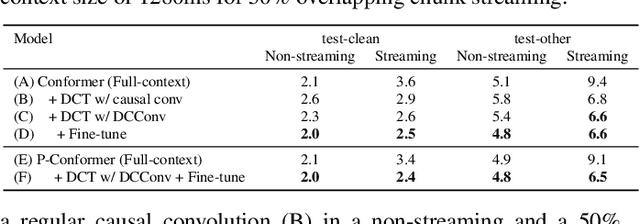
Recently, there has been an increasing interest in unifying streaming and non-streaming speech recognition models to reduce development, training and deployment cost. The best-known approaches rely on either window-based or dynamic chunk-based attention strategy and causal convolutions to minimize the degradation due to streaming. However, the performance gap still remains relatively large between non-streaming and a full-contextual model trained independently. To address this, we propose a dynamic chunk-based convolution replacing the causal convolution in a hybrid Connectionist Temporal Classification (CTC)-Attention Conformer architecture. Additionally, we demonstrate further improvements through initialization of weights from a full-contextual model and parallelization of the convolution and self-attention modules. We evaluate our models on the open-source Voxpopuli, LibriSpeech and in-house conversational datasets. Overall, our proposed model reduces the degradation of the streaming mode over the non-streaming full-contextual model from 41.7% and 45.7% to 16.7% and 26.2% on the LibriSpeech test-clean and test-other datasets respectively, while improving by a relative 15.5% WER over the previous state-of-the-art unified model.
Contextual Adapters for Personalized Speech Recognition in Neural Transducers
May 26, 2022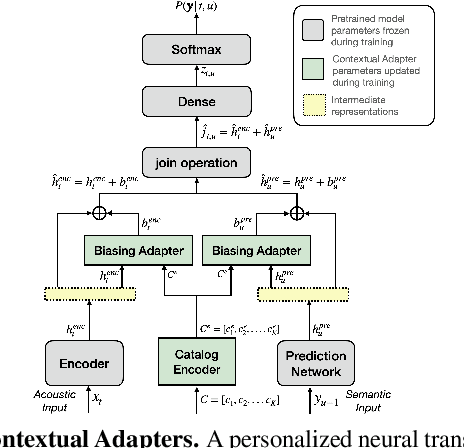
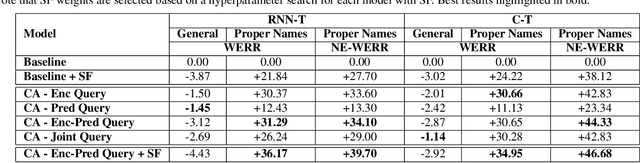
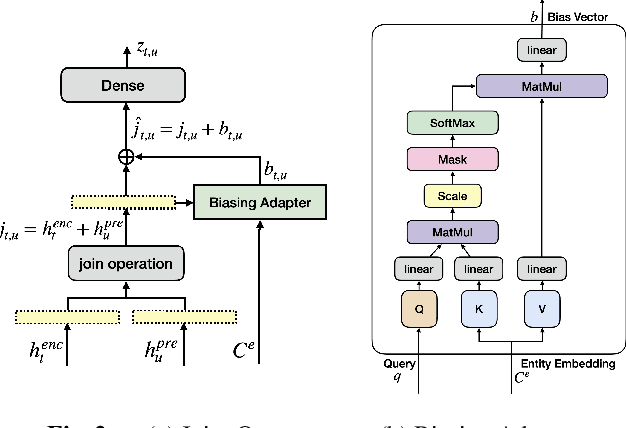
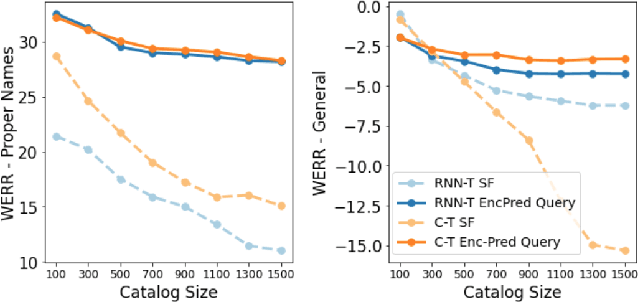
Personal rare word recognition in end-to-end Automatic Speech Recognition (E2E ASR) models is a challenge due to the lack of training data. A standard way to address this issue is with shallow fusion methods at inference time. However, due to their dependence on external language models and the deterministic approach to weight boosting, their performance is limited. In this paper, we propose training neural contextual adapters for personalization in neural transducer based ASR models. Our approach can not only bias towards user-defined words, but also has the flexibility to work with pretrained ASR models. Using an in-house dataset, we demonstrate that contextual adapters can be applied to any general purpose pretrained ASR model to improve personalization. Our method outperforms shallow fusion, while retaining functionality of the pretrained models by not altering any of the model weights. We further show that the adapter style training is superior to full-fine-tuning of the ASR models on datasets with user-defined content.
Confidence Score Based Conformer Speaker Adaptation for Speech Recognition
Jun 24, 2022
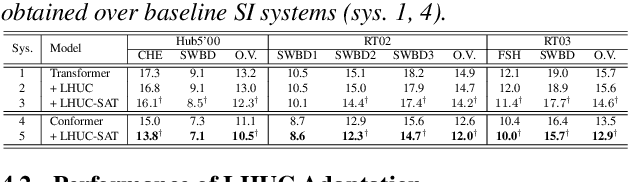
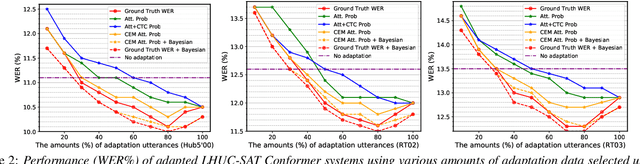

A key challenge for automatic speech recognition (ASR) systems is to model the speaker level variability. In this paper, compact speaker dependent learning hidden unit contributions (LHUC) are used to facilitate both speaker adaptive training (SAT) and test time unsupervised speaker adaptation for state-of-the-art Conformer based end-to-end ASR systems. The sensitivity during adaptation to supervision error rate is reduced using confidence score based selection of the more "trustworthy" subset of speaker specific data. A confidence estimation module is used to smooth the over-confident Conformer decoder output probabilities before serving as confidence scores. The increased data sparsity due to speaker level data selection is addressed using Bayesian estimation of LHUC parameters. Experiments on the 300-hour Switchboard corpus suggest that the proposed LHUC-SAT Conformer with confidence score based test time unsupervised adaptation outperformed the baseline speaker independent and i-vector adapted Conformer systems by up to 1.0%, 1.0%, and 1.2% absolute (9.0%, 7.9%, and 8.9% relative) word error rate (WER) reductions on the NIST Hub5'00, RT02, and RT03 evaluation sets respectively. Consistent performance improvements were retained after external Transformer and LSTM language models were used for rescoring.
Improving Pseudo-label Training For End-to-end Speech Recognition Using Gradient Mask
Oct 08, 2021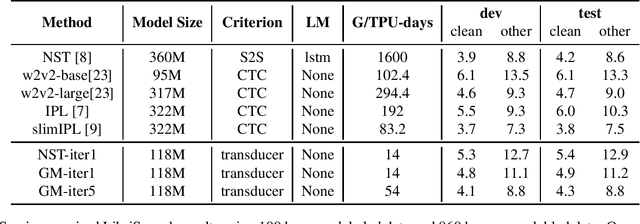
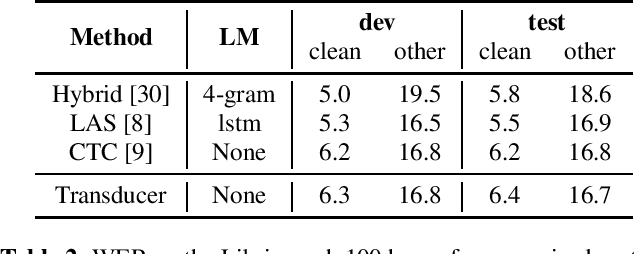
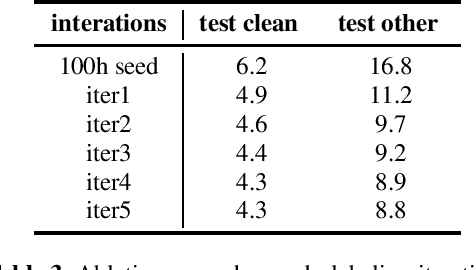
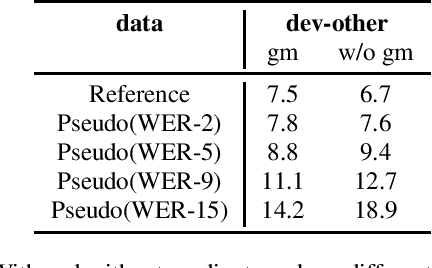
In the recent trend of semi-supervised speech recognition, both self-supervised representation learning and pseudo-labeling have shown promising results. In this paper, we propose a novel approach to combine their ideas for end-to-end speech recognition model. Without any extra loss function, we utilize the Gradient Mask to optimize the model when training on pseudo-label. This method forces the speech recognition model to predict from the masked input to learn strong acoustic representation and make training robust to label noise. In our semi-supervised experiments, the method can improve the model performance when training on pseudo-label and our method achieved competitive results comparing with other semi-supervised approaches on the Librispeech 100 hours experiments.
Efficient Training of Neural Transducer for Speech Recognition
Apr 22, 2022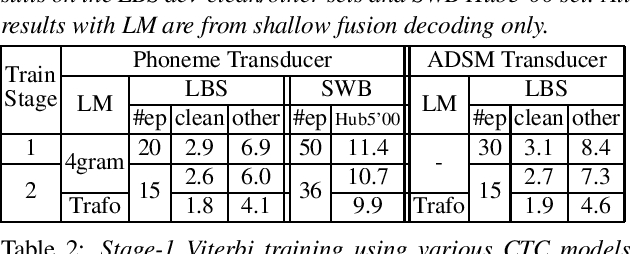
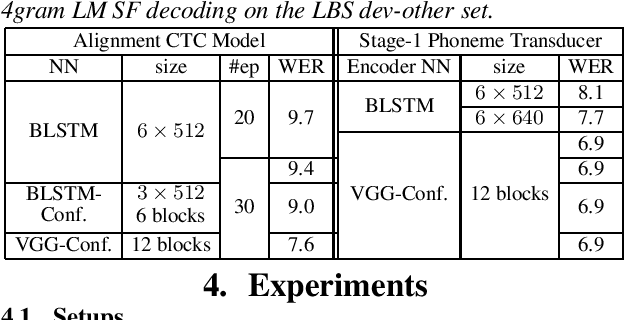
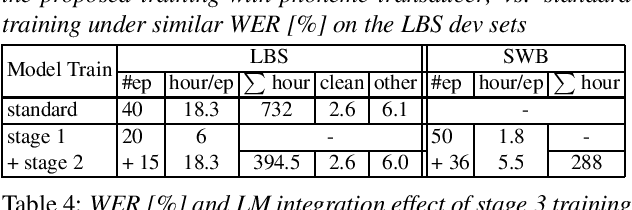
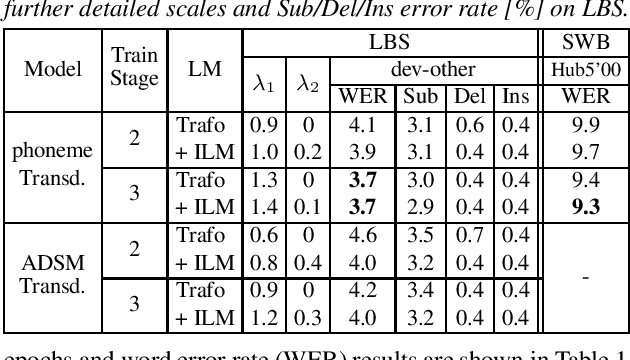
As one of the most popular sequence-to-sequence modeling approaches for speech recognition, the RNN-Transducer has achieved evolving performance with more and more sophisticated neural network models of growing size and increasing training epochs. While strong computation resources seem to be the prerequisite of training superior models, we try to overcome it by carefully designing a more efficient training pipeline. In this work, we propose an efficient 3-stage progressive training pipeline to build highly-performing neural transducer models from scratch with very limited computation resources in a reasonable short time period. The effectiveness of each stage is experimentally verified on both Librispeech and Switchboard corpora. The proposed pipeline is able to train transducer models approaching state-of-the-art performance with a single GPU in just 2-3 weeks. Our best conformer transducer achieves 4.1% WER on Librispeech test-other with only 35 epochs of training.
Hierarchical Softmax for End-to-End Low-resource Multilingual Speech Recognition
Apr 08, 2022
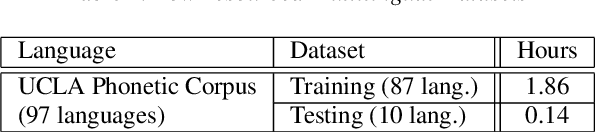
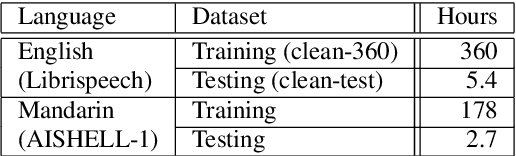
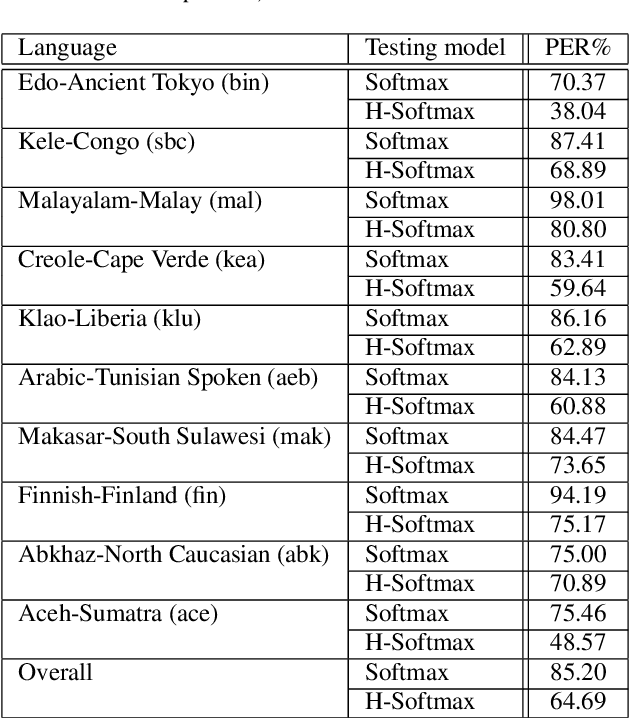
Low resource speech recognition has been long-suffering from insufficient training data. While neighbour languages are often used as assistant training data, it would be difficult for the model to induct similar units (character, subword, etc.) across the languages. In this paper, we assume similar units in neighbour language share similar term frequency and form a Huffman tree to perform multi-lingual hierarchical Softmax decoding. During decoding, the hierarchical structure can benefit the training of low-resource languages. Experimental results show the effectiveness of our method.
Joint unsupervised and supervised learning for context-aware language identification
Apr 14, 2023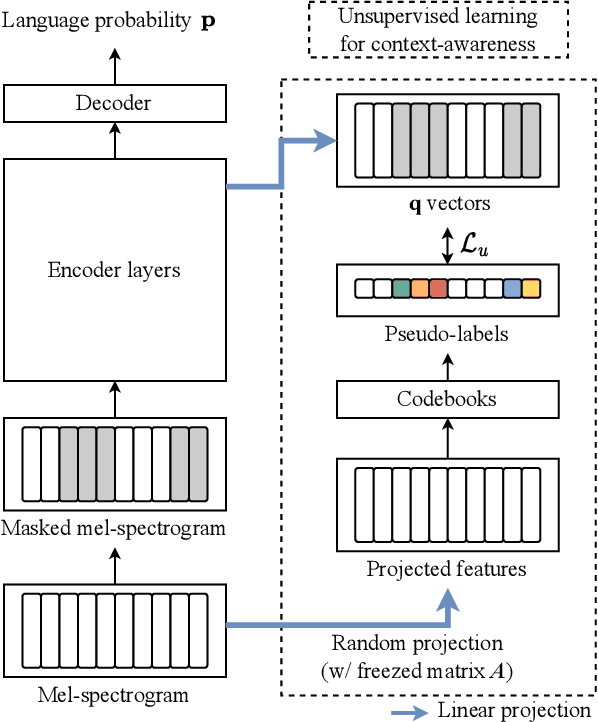
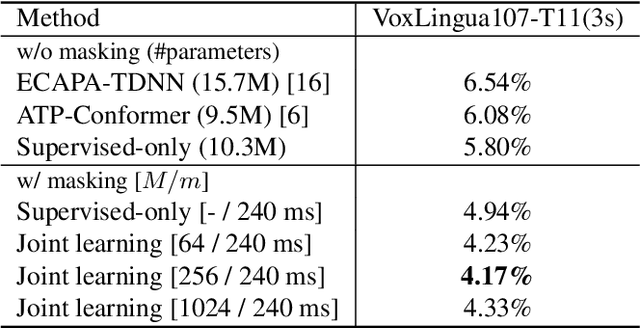
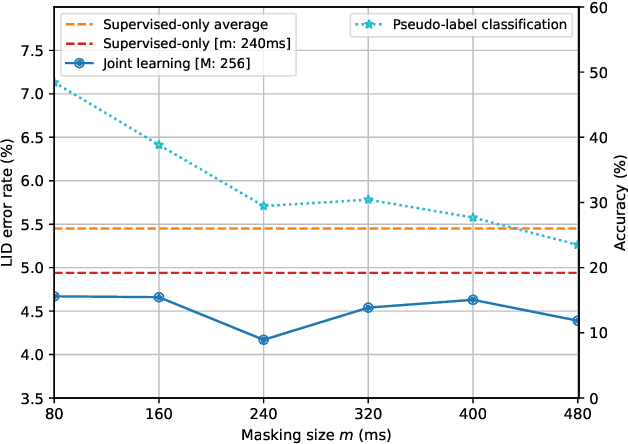
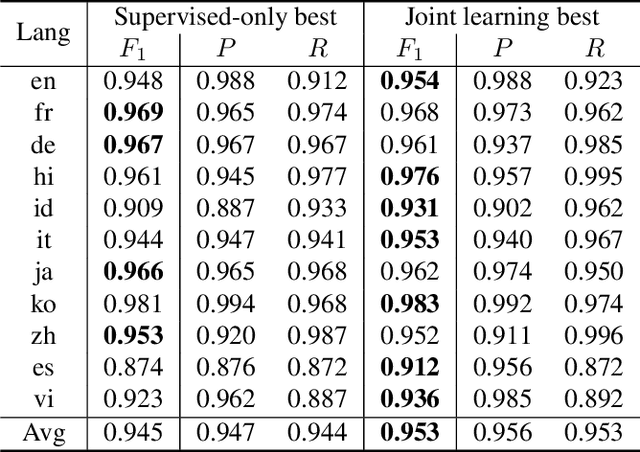
Language identification (LID) recognizes the language of a spoken utterance automatically. According to recent studies, LID models trained with an automatic speech recognition (ASR) task perform better than those trained with a LID task only. However, we need additional text labels to train the model to recognize speech, and acquiring the text labels is a cost high. In order to overcome this problem, we propose context-aware language identification using a combination of unsupervised and supervised learning without any text labels. The proposed method learns the context of speech through masked language modeling (MLM) loss and simultaneously trains to determine the language of the utterance with supervised learning loss. The proposed joint learning was found to reduce the error rate by 15.6% compared to the same structure model trained by supervised-only learning on a subset of the VoxLingua107 dataset consisting of sub-three-second utterances in 11 languages.
deep learning of segment-level feature representation for speech emotion recognition in conversations
Feb 05, 2023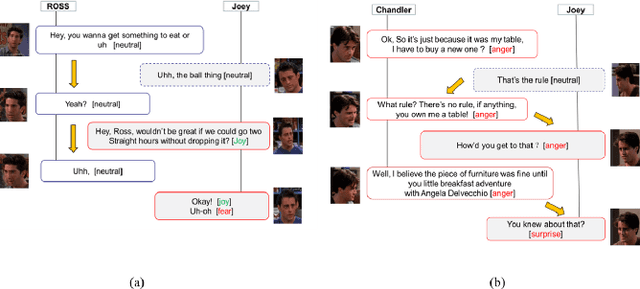
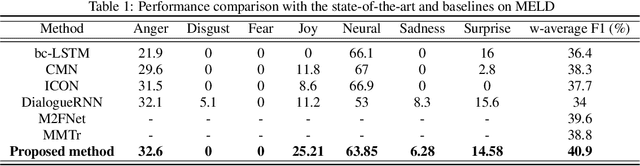
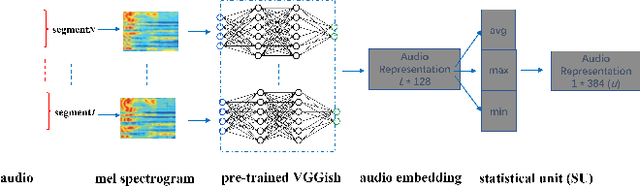

Accurately detecting emotions in conversation is a necessary yet challenging task due to the complexity of emotions and dynamics in dialogues. The emotional state of a speaker can be influenced by many different factors, such as interlocutor stimulus, dialogue scene, and topic. In this work, we propose a conversational speech emotion recognition method to deal with capturing attentive contextual dependency and speaker-sensitive interactions. First, we use a pretrained VGGish model to extract segment-based audio representation in individual utterances. Second, an attentive bi-directional gated recurrent unit (GRU) models contextual-sensitive information and explores intra- and inter-speaker dependencies jointly in a dynamic manner. The experiments conducted on the standard conversational dataset MELD demonstrate the effectiveness of the proposed method when compared against state-of the-art methods.