 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
GujiBERT and GujiGPT: Construction of Intelligent Information Processing Foundation Language Models for Ancient Texts
Jul 11, 2023


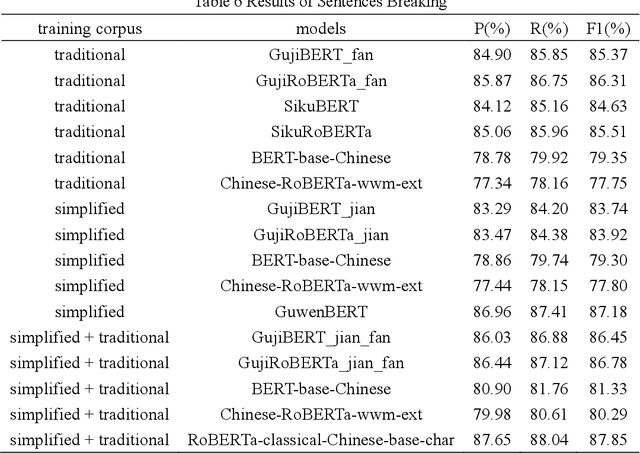
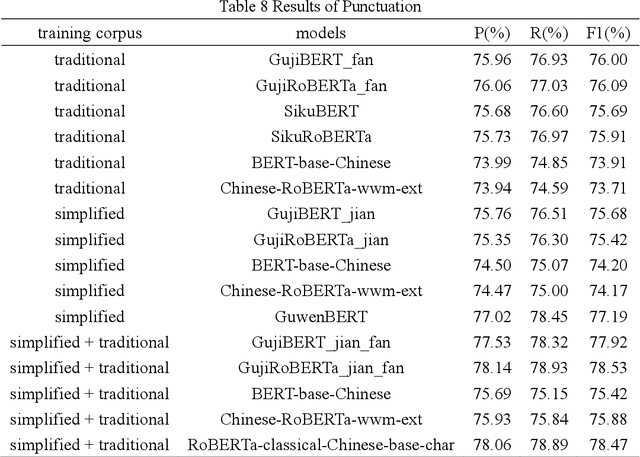
In the context of the rapid development of large language models, we have meticulously trained and introduced the GujiBERT and GujiGPT language models, which are foundational models specifically designed for intelligent information processing of ancient texts. These models have been trained on an extensive dataset that encompasses both simplified and traditional Chinese characters, allowing them to effectively handle various natural language processing tasks related to ancient books, including but not limited to automatic sentence segmentation, punctuation, word segmentation, part-of-speech tagging, entity recognition, and automatic translation. Notably, these models have exhibited exceptional performance across a range of validation tasks using publicly available datasets. Our research findings highlight the efficacy of employing self-supervised methods to further train the models using classical text corpora, thus enhancing their capability to tackle downstream tasks. Moreover, it is worth emphasizing that the choice of font, the scale of the corpus, and the initial model selection all exert significant influence over the ultimate experimental outcomes. To cater to the diverse text processing preferences of researchers in digital humanities and linguistics, we have developed three distinct categories comprising a total of nine model variations. We believe that by sharing these foundational language models specialized in the domain of ancient texts, we can facilitate the intelligent processing and scholarly exploration of ancient literary works and, consequently, contribute to the global dissemination of China's rich and esteemed traditional culture in this new era.
Personalized Adversarial Data Augmentation for Dysarthric and Elderly Speech Recognition
May 13, 2022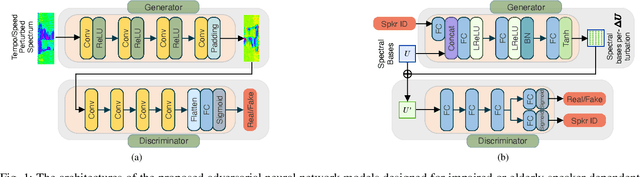
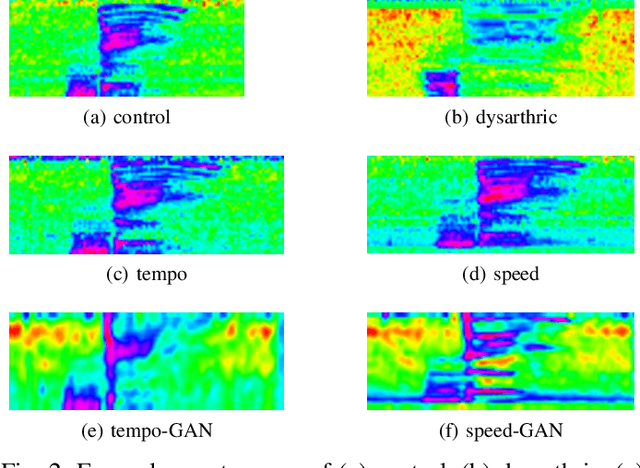
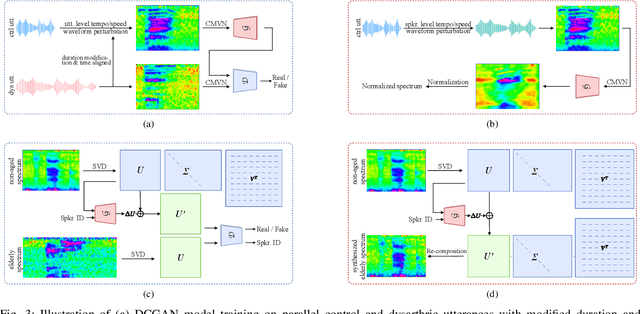
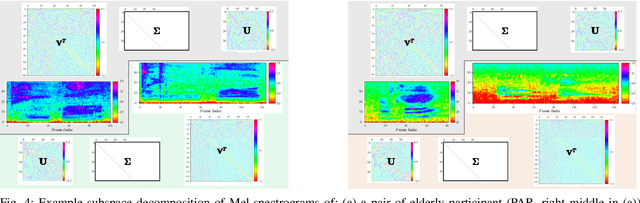
Despite the rapid progress of automatic speech recognition (ASR) technologies targeting normal speech, accurate recognition of dysarthric and elderly speech remains highly challenging tasks to date. It is difficult to collect large quantities of such data for ASR system development due to the mobility issues often found among these users. To this end, data augmentation techniques play a vital role. In contrast to existing data augmentation techniques only modifying the speaking rate or overall shape of spectral contour, fine-grained spectro-temporal differences between dysarthric, elderly and normal speech are modelled using a novel set of speaker dependent (SD) generative adversarial networks (GAN) based data augmentation approaches in this paper. These flexibly allow both: a) temporal or speed perturbed normal speech spectra to be modified and closer to those of an impaired speaker when parallel speech data is available; and b) for non-parallel data, the SVD decomposed normal speech spectral basis features to be transformed into those of a target elderly speaker before being re-composed with the temporal bases to produce the augmented data for state-of-the-art TDNN and Conformer ASR system training. Experiments are conducted on four tasks: the English UASpeech and TORGO dysarthric speech corpora; the English DementiaBank Pitt and Cantonese JCCOCC MoCA elderly speech datasets. The proposed GAN based data augmentation approaches consistently outperform the baseline speed perturbation method by up to 0.91% and 3.0% absolute (9.61% and 6.4% relative) WER reduction on the TORGO and DementiaBank data respectively. Consistent performance improvements are retained after applying LHUC based speaker adaptation.
Exploiting Cross Domain Acoustic-to-articulatory Inverted Features For Disordered Speech Recognition
Mar 19, 2022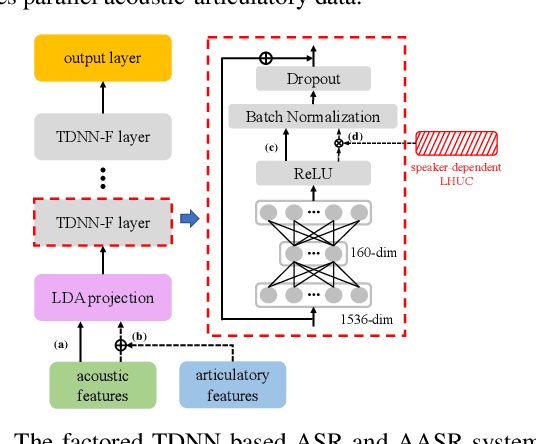
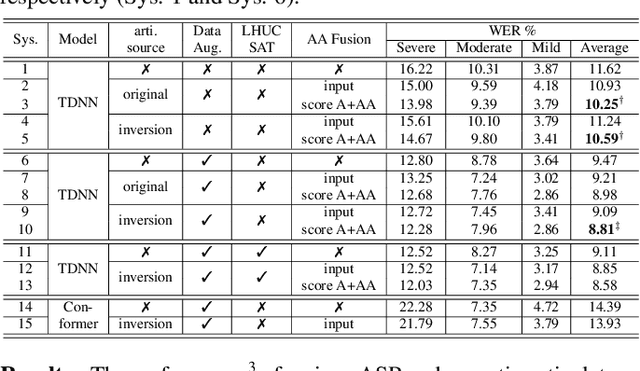
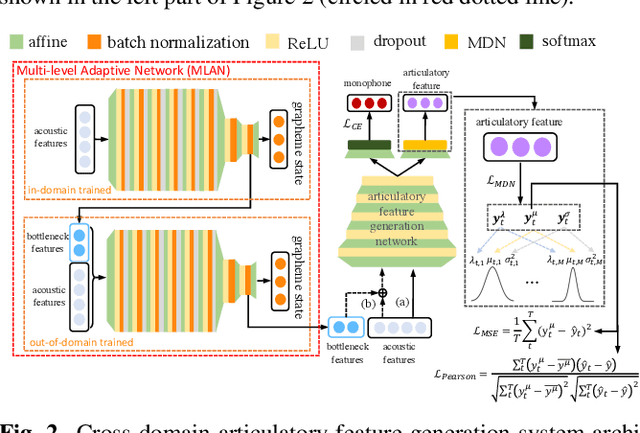
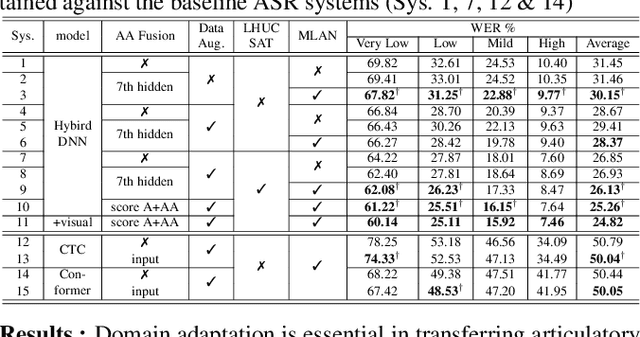
Articulatory features are inherently invariant to acoustic signal distortion and have been successfully incorporated into automatic speech recognition (ASR) systems for normal speech. Their practical application to disordered speech recognition is often limited by the difficulty in collecting such specialist data from impaired speakers. This paper presents a cross-domain acoustic-to-articulatory (A2A) inversion approach that utilizes the parallel acoustic-articulatory data of the 15-hour TORGO corpus in model training before being cross-domain adapted to the 102.7-hour UASpeech corpus and to produce articulatory features. Mixture density networks based neural A2A inversion models were used. A cross-domain feature adaptation network was also used to reduce the acoustic mismatch between the TORGO and UASpeech data. On both tasks, incorporating the A2A generated articulatory features consistently outperformed the baseline hybrid DNN/TDNN, CTC and Conformer based end-to-end systems constructed using acoustic features only. The best multi-modal system incorporating video modality and the cross-domain articulatory features as well as data augmentation and learning hidden unit contributions (LHUC) speaker adaptation produced the lowest published word error rate (WER) of 24.82% on the 16 dysarthric speakers of the benchmark UASpeech task.
Disappeared Command: Spoofing Attack On Automatic Speech Recognition Systems with Sound Masking
Apr 19, 2022

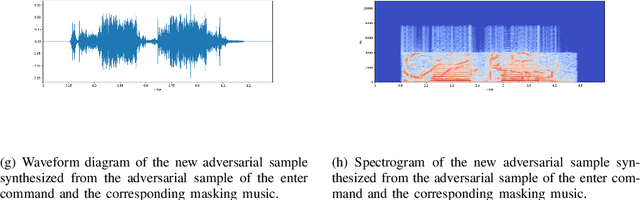
The development of deep learning technology has greatly promoted the performance improvement of automatic speech recognition (ASR) technology, which has demonstrated an ability comparable to human hearing in many tasks. Voice interfaces are becoming more and more widely used as input for many applications and smart devices. However, existing research has shown that DNN is easily disturbed by slight disturbances and makes false recognition, which is extremely dangerous for intelligent voice applications controlled by voice.
EmoMix: Emotion Mixing via Diffusion Models for Emotional Speech Synthesis
Jun 01, 2023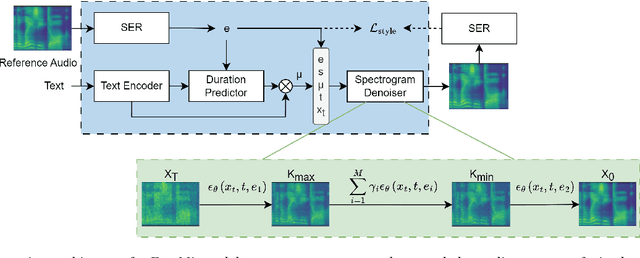
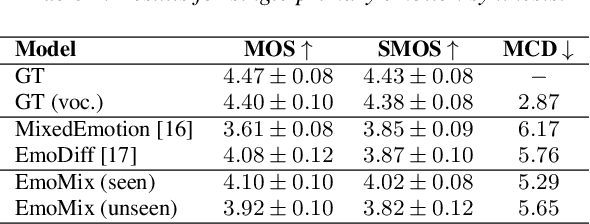

There has been significant progress in emotional Text-To-Speech (TTS) synthesis technology in recent years. However, existing methods primarily focus on the synthesis of a limited number of emotion types and have achieved unsatisfactory performance in intensity control. To address these limitations, we propose EmoMix, which can generate emotional speech with specified intensity or a mixture of emotions. Specifically, EmoMix is a controllable emotional TTS model based on a diffusion probabilistic model and a pre-trained speech emotion recognition (SER) model used to extract emotion embedding. Mixed emotion synthesis is achieved by combining the noises predicted by diffusion model conditioned on different emotions during only one sampling process at the run-time. We further apply the Neutral and specific primary emotion mixed in varying degrees to control intensity. Experimental results validate the effectiveness of EmoMix for synthesizing mixed emotion and intensity control.
deep learning of segment-level feature representation for speech emotion recognition in conversations
Feb 05, 2023
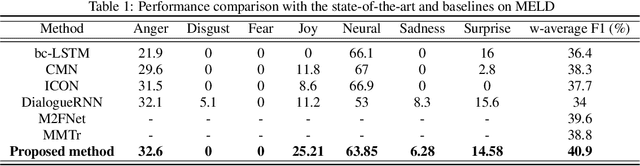
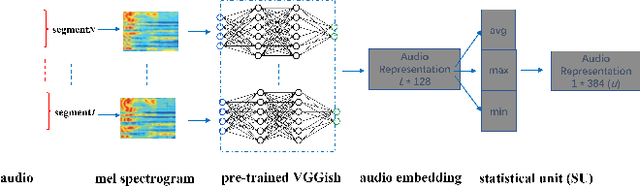

Accurately detecting emotions in conversation is a necessary yet challenging task due to the complexity of emotions and dynamics in dialogues. The emotional state of a speaker can be influenced by many different factors, such as interlocutor stimulus, dialogue scene, and topic. In this work, we propose a conversational speech emotion recognition method to deal with capturing attentive contextual dependency and speaker-sensitive interactions. First, we use a pretrained VGGish model to extract segment-based audio representation in individual utterances. Second, an attentive bi-directional gated recurrent unit (GRU) models contextual-sensitive information and explores intra- and inter-speaker dependencies jointly in a dynamic manner. The experiments conducted on the standard conversational dataset MELD demonstrate the effectiveness of the proposed method when compared against state-of the-art methods.
Loss Prediction: End-to-End Active Learning Approach For Speech Recognition
Jul 09, 2021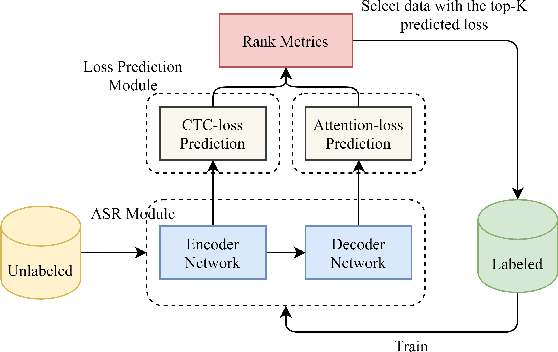
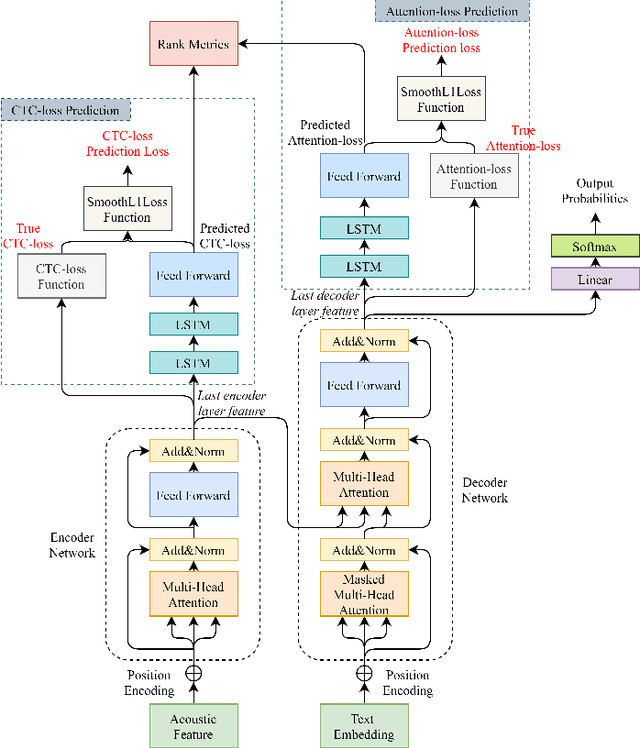
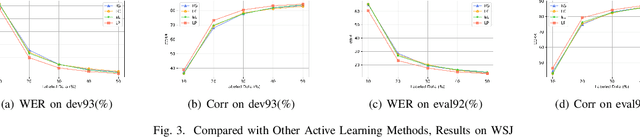

End-to-end speech recognition systems usually require huge amounts of labeling resource, while annotating the speech data is complicated and expensive. Active learning is the solution by selecting the most valuable samples for annotation. In this paper, we proposed to use a predicted loss that estimates the uncertainty of the sample. The CTC (Connectionist Temporal Classification) and attention loss are informative for speech recognition since they are computed based on all decoding paths and alignments. We defined an end-to-end active learning pipeline, training an ASR/LP (Automatic Speech Recognition/Loss Prediction) joint model. The proposed approach was validated on an English and a Chinese speech recognition task. The experiments show that our approach achieves competitive results, outperforming random selection, least confidence, and estimated loss method.
Transformer-Based Video Front-Ends for Audio-Visual Speech Recognition
Jan 25, 2022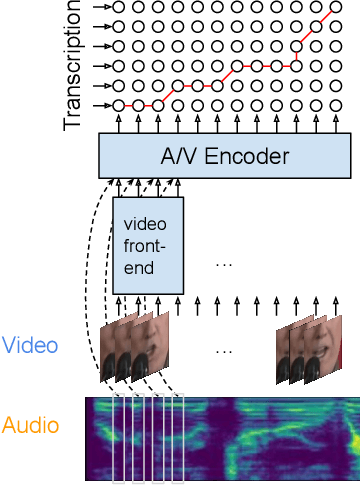
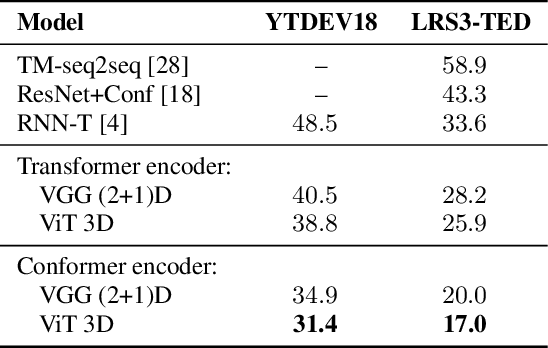
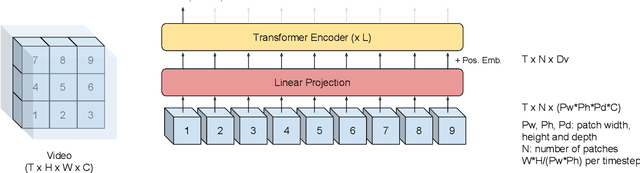
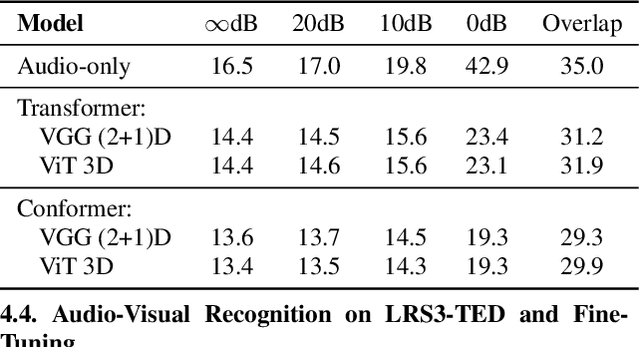
Audio-visual automatic speech recognition (AV-ASR) extends the speech recognition by introducing the video modality. In particular, the information contained in the motion of the speaker's mouth is used to augment the audio features. The video modality is traditionally processed with a 3D convolutional neural network (e.g. 3D version of VGG). Recently, image transformer networks arXiv:2010.11929 demonstrated the ability to extract rich visual features for the image classification task. In this work, we propose to replace the 3D convolution with a video transformer video feature extractor. We train our baselines and the proposed model on a large scale corpus of the YouTube videos. Then we evaluate the performance on a labeled subset of YouTube as well as on the public corpus LRS3-TED. Our best model video-only model achieves the performance of 34.9% WER on YTDEV18 and 19.3% on LRS3-TED which is a 10% and 9% relative improvements over the convolutional baseline. We achieve the state of the art performance of the audio-visual recognition on the LRS3-TED after fine-tuning our model (1.6% WER).
Echo State Speech Recognition
Feb 18, 2021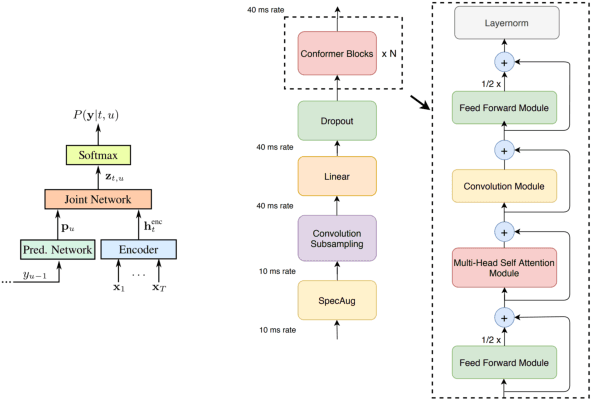
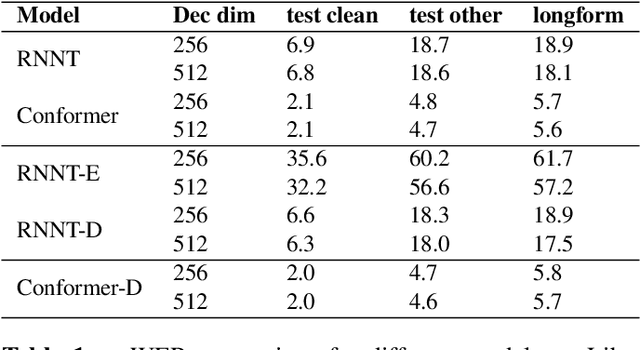

We propose automatic speech recognition (ASR) models inspired by echo state network (ESN), in which a subset of recurrent neural networks (RNN) layers in the models are randomly initialized and untrained. Our study focuses on RNN-T and Conformer models, and we show that model quality does not drop even when the decoder is fully randomized. Furthermore, such models can be trained more efficiently as the decoders do not require to be updated. By contrast, randomizing encoders hurts model quality, indicating that optimizing encoders and learn proper representations for acoustic inputs are more vital for speech recognition. Overall, we challenge the common practice of training ASR models for all components, and demonstrate that ESN-based models can perform equally well but enable more efficient training and storage than fully-trainable counterparts.
Personal VAD 2.0: Optimizing Personal Voice Activity Detection for On-Device Speech Recognition
Apr 13, 2022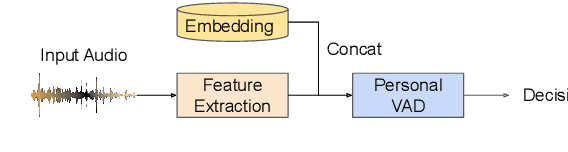
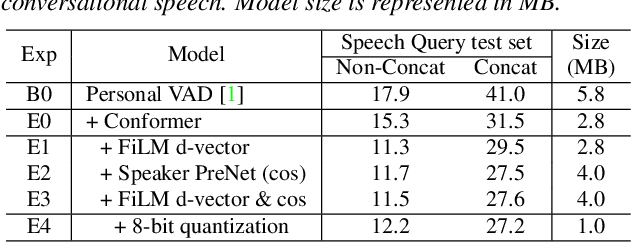
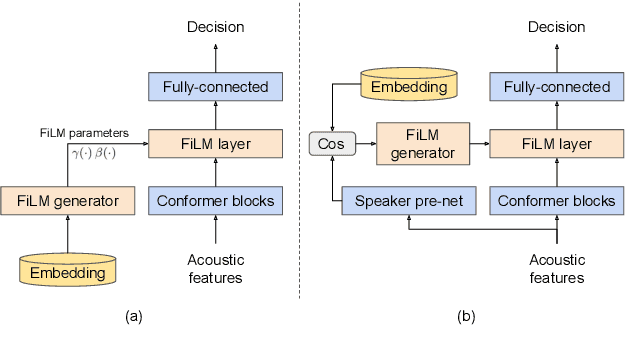
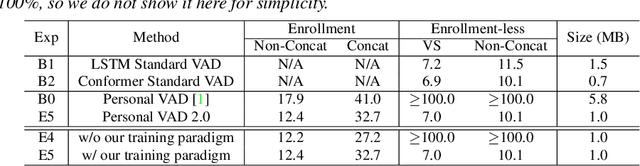
Personalization of on-device speech recognition (ASR) has seen explosive growth in recent years, largely due to the increasing popularity of personal assistant features on mobile devices and smart home speakers. In this work, we present Personal VAD 2.0, a personalized voice activity detector that detects the voice activity of a target speaker, as part of a streaming on-device ASR system. Although previous proof-of-concept studies have validated the effectiveness of Personal VAD, there are still several critical challenges to address before this model can be used in production: first, the quality must be satisfactory in both enrollment and enrollment-less scenarios; second, it should operate in a streaming fashion; and finally, the model size should be small enough to fit a limited latency and CPU/Memory budget. To meet the multi-faceted requirements, we propose a series of novel designs: 1) advanced speaker embedding modulation methods; 2) a new training paradigm to generalize to enrollment-less conditions; 3) architecture and runtime optimizations for latency and resource restrictions. Extensive experiments on a realistic speech recognition system demonstrated the state-of-the-art performance of our proposed method.