 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Hey ASR System! Why Aren't You More Inclusive? Automatic Speech Recognition Systems' Bias and Proposed Bias Mitigation Techniques. A Literature Review
Nov 17, 2022
Speech is the fundamental means of communication between humans. The advent of AI and sophisticated speech technologies have led to the rapid proliferation of human-to-computer-based interactions, fueled primarily by Automatic Speech Recognition (ASR) systems. ASR systems normally take human speech in the form of audio and convert it into words, but for some users, it cannot decode the speech, and any output text is filled with errors that are incomprehensible to the human reader. These systems do not work equally for everyone and actually hinder the productivity of some users. In this paper, we present research that addresses ASR biases against gender, race, and the sick and disabled, while exploring studies that propose ASR debiasing techniques for mitigating these discriminations. We also discuss techniques for designing a more accessible and inclusive ASR technology. For each approach surveyed, we also provide a summary of the investigation and methods applied, the ASR systems and corpora used, and the research findings, and highlight their strengths and/or weaknesses. Finally, we propose future opportunities for Natural Language Processing researchers to explore in the next level creation of ASR technologies.
An Experimental Study on Private Aggregation of Teacher Ensemble Learning for End-to-End Speech Recognition
Oct 13, 2022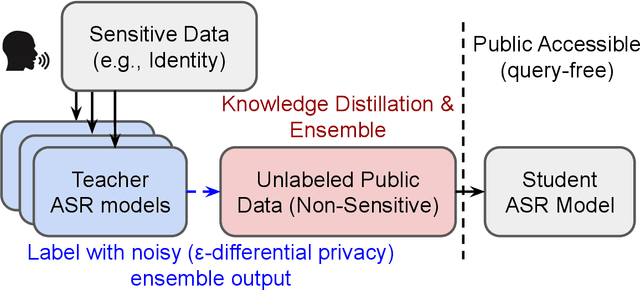
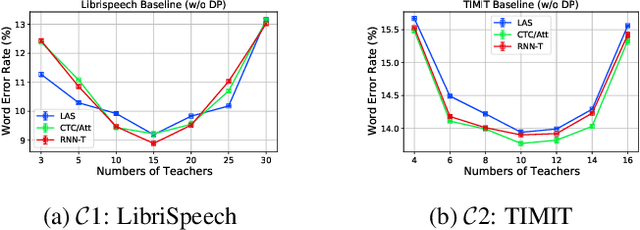
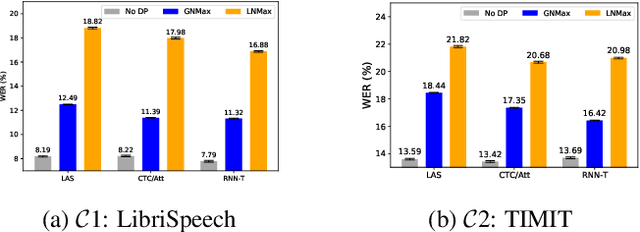
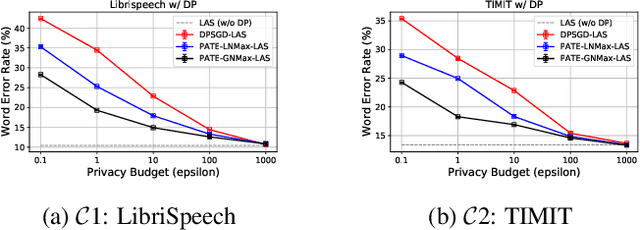
Differential privacy (DP) is one data protection avenue to safeguard user information used for training deep models by imposing noisy distortion on privacy data. Such a noise perturbation often results in a severe performance degradation in automatic speech recognition (ASR) in order to meet a privacy budget $\varepsilon$. Private aggregation of teacher ensemble (PATE) utilizes ensemble probabilities to improve ASR accuracy when dealing with the noise effects controlled by small values of $\varepsilon$. We extend PATE learning to work with dynamic patterns, namely speech utterances, and perform a first experimental demonstration that it prevents acoustic data leakage in ASR training. We evaluate three end-to-end deep models, including LAS, hybrid CTC/attention, and RNN transducer, on the open-source LibriSpeech and TIMIT corpora. PATE learning-enhanced ASR models outperform the benchmark DP-SGD mechanisms, especially under strict DP budgets, giving relative word error rate reductions between 26.2% and 27.5% for an RNN transducer model evaluated with LibriSpeech. We also introduce a DP-preserving ASR solution for pretraining on public speech corpora.
Improving Speech Recognition on Noisy Speech via Speech Enhancement with Multi-Discriminators CycleGAN
Dec 12, 2021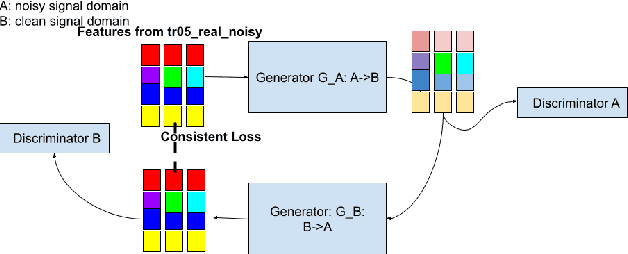
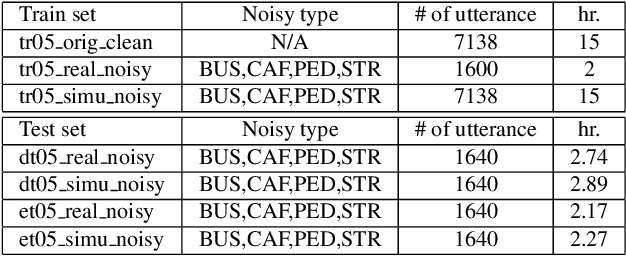
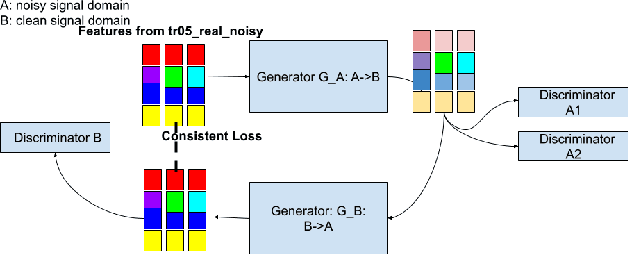
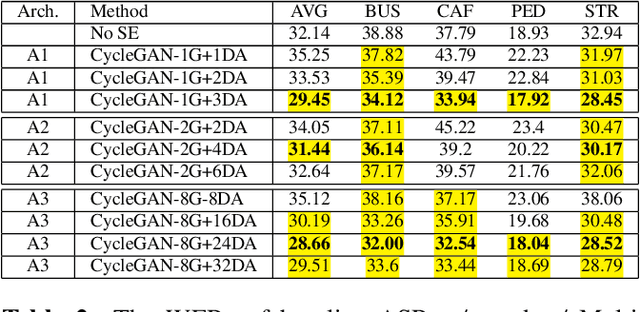
This paper presents our latest investigations on improving automatic speech recognition for noisy speech via speech enhancement. We propose a novel method named Multi-discriminators CycleGAN to reduce noise of input speech and therefore improve the automatic speech recognition performance. Our proposed method leverages the CycleGAN framework for speech enhancement without any parallel data and improve it by introducing multiple discriminators that check different frequency areas. Furthermore, we show that training multiple generators on homogeneous subset of the training data is better than training one generator on all the training data. We evaluate our method on CHiME-3 data set and observe up to 10.03% relatively WER improvement on the development set and up to 14.09% on the evaluation set.
An Ensemble Teacher-Student Learning Approach with Poisson Sub-sampling to Differential Privacy Preserving Speech Recognition
Oct 12, 2022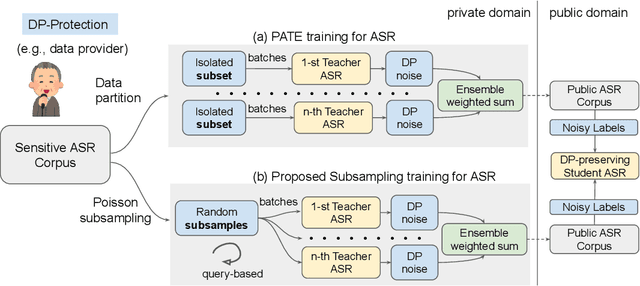


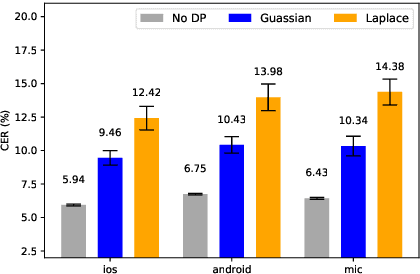
We propose an ensemble learning framework with Poisson sub-sampling to effectively train a collection of teacher models to issue some differential privacy (DP) guarantee for training data. Through boosting under DP, a student model derived from the training data suffers little model degradation from the models trained with no privacy protection. Our proposed solution leverages upon two mechanisms, namely: (i) a privacy budget amplification via Poisson sub-sampling to train a target prediction model that requires less noise to achieve a same level of privacy budget, and (ii) a combination of the sub-sampling technique and an ensemble teacher-student learning framework that introduces DP-preserving noise at the output of the teacher models and transfers DP-preserving properties via noisy labels. Privacy-preserving student models are then trained with the noisy labels to learn the knowledge with DP-protection from the teacher model ensemble. Experimental evidences on spoken command recognition and continuous speech recognition of Mandarin speech show that our proposed framework greatly outperforms existing DP-preserving algorithms in both speech processing tasks.
Improved far-field speech recognition using Joint Variational Autoencoder
Apr 24, 2022
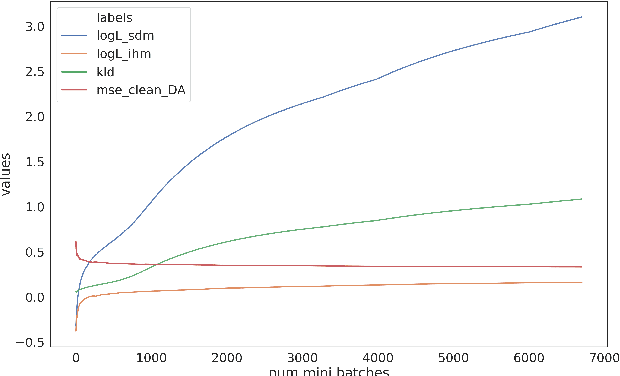

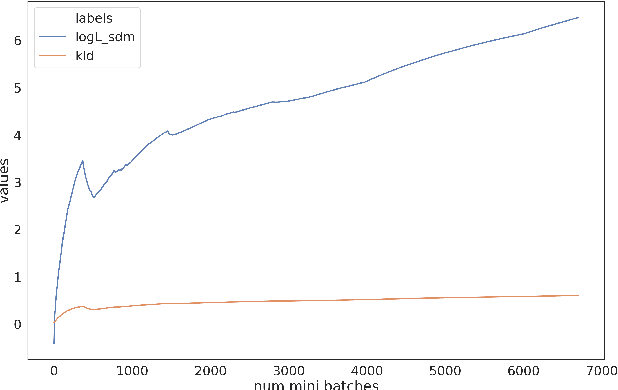
Automatic Speech Recognition (ASR) systems suffer considerably when source speech is corrupted with noise or room impulse responses (RIR). Typically, speech enhancement is applied in both mismatched and matched scenario training and testing. In matched setting, acoustic model (AM) is trained on dereverberated far-field features while in mismatched setting, AM is fixed. In recent past, mapping speech features from far-field to close-talk using denoising autoencoder (DA) has been explored. In this paper, we focus on matched scenario training and show that the proposed joint VAE based mapping achieves a significant improvement over DA. Specifically, we observe an absolute improvement of 2.5% in word error rate (WER) compared to DA based enhancement and 3.96% compared to AM trained directly on far-field filterbank features.
Self-supervised Neural Factor Analysis for Disentangling Utterance-level Speech Representations
May 14, 2023
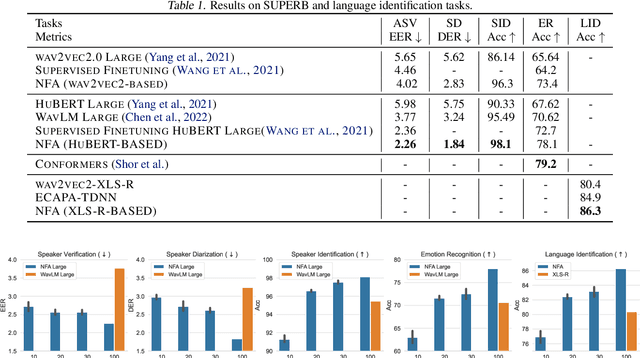
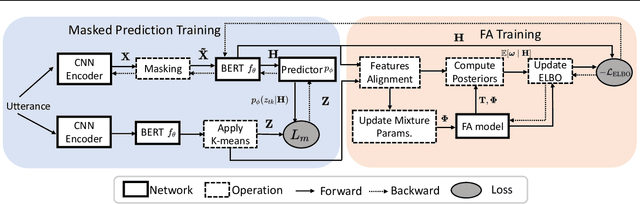
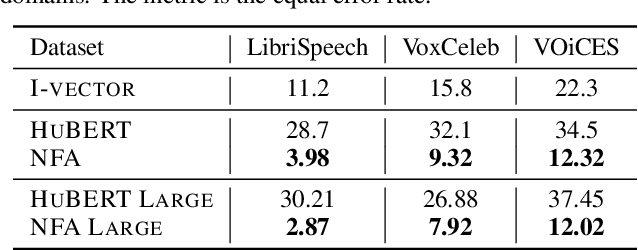
Self-supervised learning (SSL) speech models such as wav2vec and HuBERT have demonstrated state-of-the-art performance on automatic speech recognition (ASR) and proved to be extremely useful in low label-resource settings. However, the success of SSL models has yet to transfer to utterance-level tasks such as speaker, emotion, and language recognition, which still require supervised fine-tuning of the SSL models to obtain good performance. We argue that the problem is caused by the lack of disentangled representations and an utterance-level learning objective for these tasks. Inspired by how HuBERT uses clustering to discover hidden acoustic units, we formulate a factor analysis (FA) model that uses the discovered hidden acoustic units to align the SSL features. The underlying utterance-level representations are disentangled from the content of speech using probabilistic inference on the aligned features. Furthermore, the variational lower bound derived from the FA model provides an utterance-level objective, allowing error gradients to be backpropagated to the Transformer layers to learn highly discriminative acoustic units. When used in conjunction with HuBERT's masked prediction training, our models outperform the current best model, WavLM, on all utterance-level non-semantic tasks on the SUPERB benchmark with only 20% of labeled data.
Unsupervised data selection for Speech Recognition with contrastive loss ratios
Jul 25, 2022
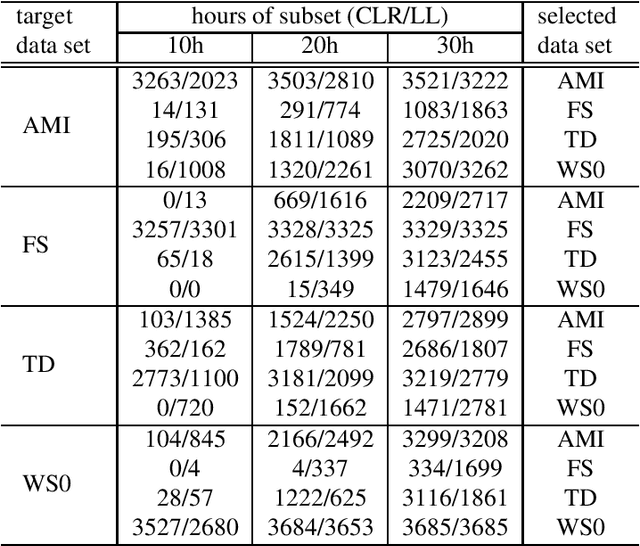
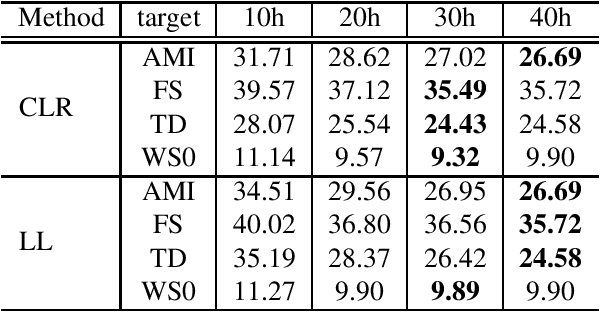
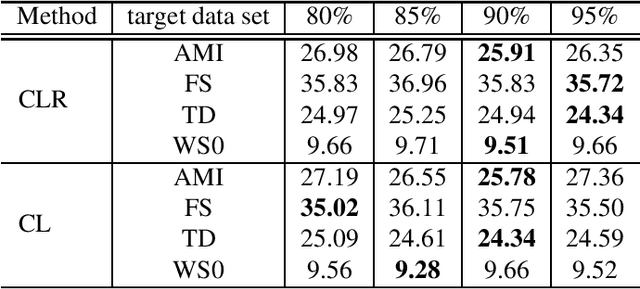
This paper proposes an unsupervised data selection method by using a submodular function based on contrastive loss ratios of target and training data sets. A model using a contrastive loss function is trained on both sets. Then the ratio of frame-level losses for each model is used by a submodular function. By using the submodular function, a training set for automatic speech recognition matching the target data set is selected. Experiments show that models trained on the data sets selected by the proposed method outperform the selection method based on log-likelihoods produced by GMM-HMM models, in terms of word error rate (WER). When selecting a fixed amount, e.g. 10 hours of data, the difference between the results of two methods on Tedtalks was 20.23% WER relative. The method can also be used to select data with the aim of minimising negative transfer, while maintaining or improving on performance of models trained on the whole training set. Results show that the WER on the WSJCAM0 data set was reduced by 6.26% relative when selecting 85% from the whole data set.
* 5 pages, accepted by ICASSP 2022
Evaluation of Speaker Anonymization on Emotional Speech
Apr 15, 2023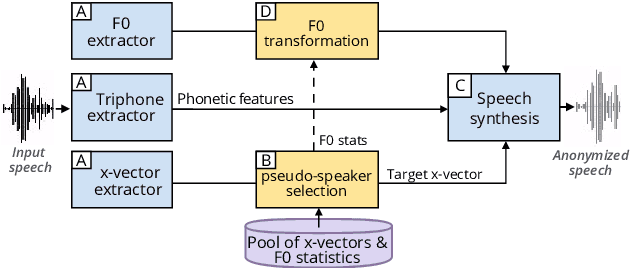
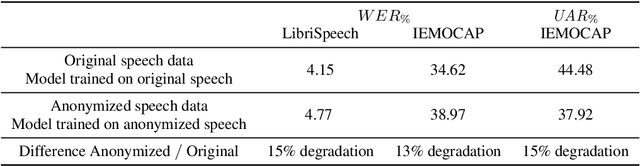
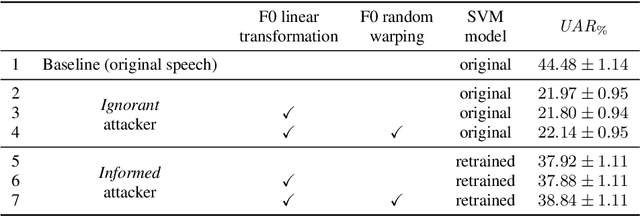
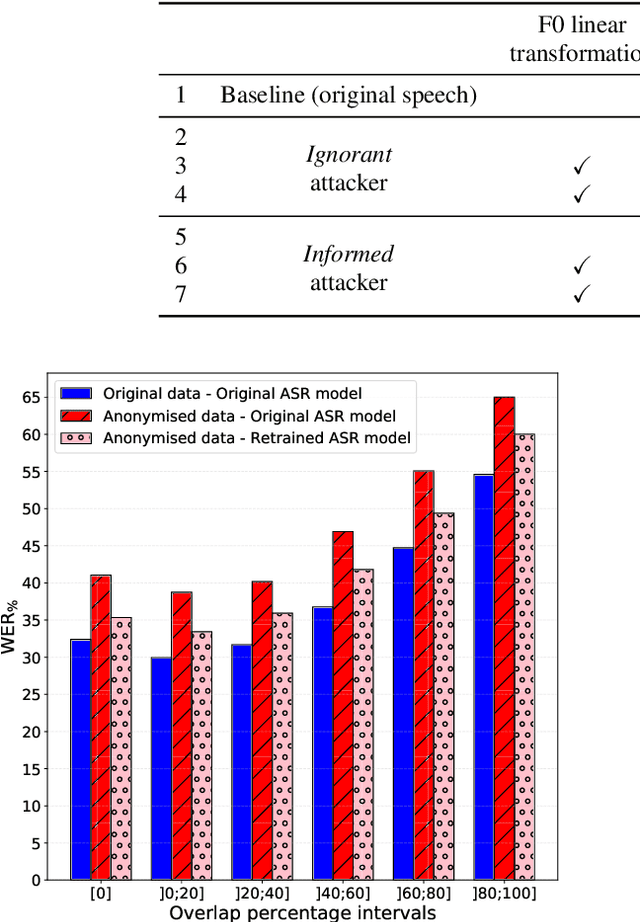
Speech data carries a range of personal information, such as the speaker's identity and emotional state. These attributes can be used for malicious purposes. With the development of virtual assistants, a new generation of privacy threats has emerged. Current studies have addressed the topic of preserving speech privacy. One of them, the VoicePrivacy initiative aims to promote the development of privacy preservation tools for speech technology. The task selected for the VoicePrivacy 2020 Challenge (VPC) is about speaker anonymization. The goal is to hide the source speaker's identity while preserving the linguistic information. The baseline of the VPC makes use of a voice conversion. This paper studies the impact of the speaker anonymization baseline system of the VPC on emotional information present in speech utterances. Evaluation is performed following the VPC rules regarding the attackers' knowledge about the anonymization system. Our results show that the VPC baseline system does not suppress speakers' emotions against informed attackers. When comparing anonymized speech to original speech, the emotion recognition performance is degraded by 15\% relative to IEMOCAP data, similar to the degradation observed for automatic speech recognition used to evaluate the preservation of the linguistic information.
Watch What You Pretrain For: Targeted, Transferable Adversarial Examples on Self-Supervised Speech Recognition models
Sep 29, 2022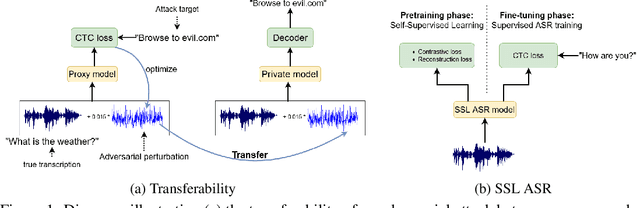
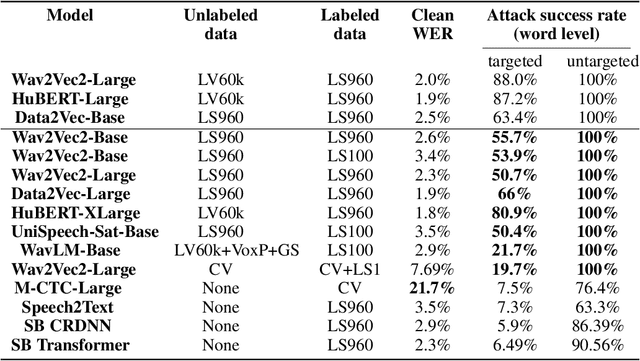
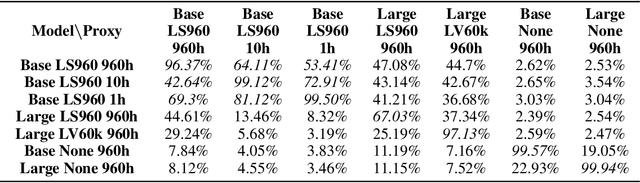
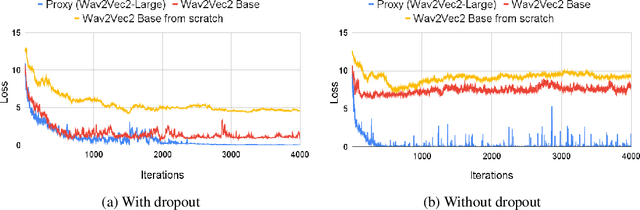
A targeted adversarial attack produces audio samples that can force an Automatic Speech Recognition (ASR) system to output attacker-chosen text. To exploit ASR models in real-world, black-box settings, an adversary can leverage the transferability property, i.e. that an adversarial sample produced for a proxy ASR can also fool a different remote ASR. However recent work has shown that transferability against large ASR models is very difficult. In this work, we show that modern ASR architectures, specifically ones based on Self-Supervised Learning, are in fact vulnerable to transferability. We successfully demonstrate this phenomenon by evaluating state-of-the-art self-supervised ASR models like Wav2Vec2, HuBERT, Data2Vec and WavLM. We show that with low-level additive noise achieving a 30dB Signal-Noise Ratio, we can achieve target transferability with up to 80% accuracy. Next, we 1) use an ablation study to show that Self-Supervised learning is the main cause of that phenomenon, and 2) we provide an explanation for this phenomenon. Through this we show that modern ASR architectures are uniquely vulnerable to adversarial security threats.