 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Challenges and Opportunities of Speech Recognition for Bengali Language
Sep 27, 2021
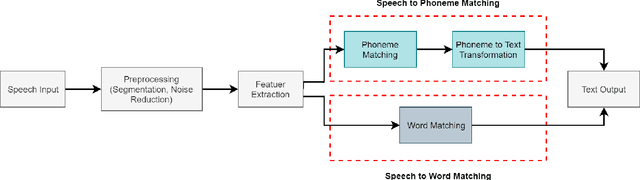
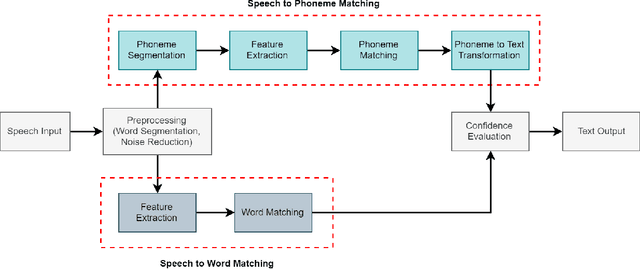
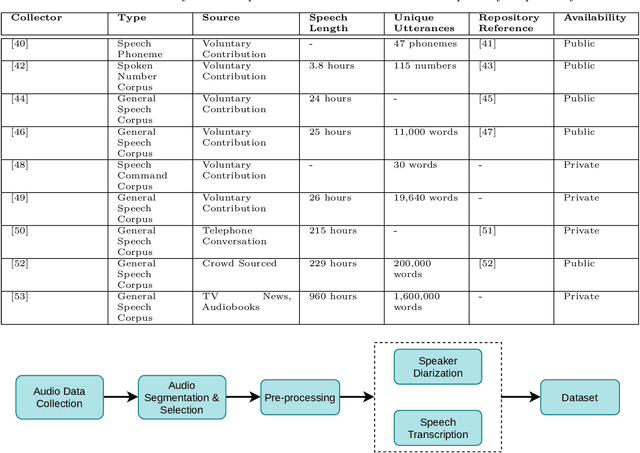
Speech recognition is a fascinating process that offers the opportunity to interact and command the machine in the field of human-computer interactions. Speech recognition is a language-dependent system constructed directly based on the linguistic and textual properties of any language. Automatic Speech Recognition (ASR) systems are currently being used to translate speech to text flawlessly. Although ASR systems are being strongly executed in international languages, ASR systems' implementation in the Bengali language has not reached an acceptable state. In this research work, we sedulously disclose the current status of the Bengali ASR system's research endeavors. In what follows, we acquaint the challenges that are mostly encountered while constructing a Bengali ASR system. We split the challenges into language-dependent and language-independent challenges and guide how the particular complications may be overhauled. Following a rigorous investigation and highlighting the challenges, we conclude that Bengali ASR systems require specific construction of ASR architectures based on the Bengali language's grammatical and phonetic structure.
Evil Operation: Breaking Speaker Recognition with PaddingBack
Aug 08, 2023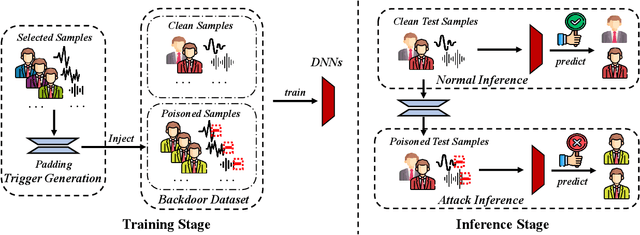
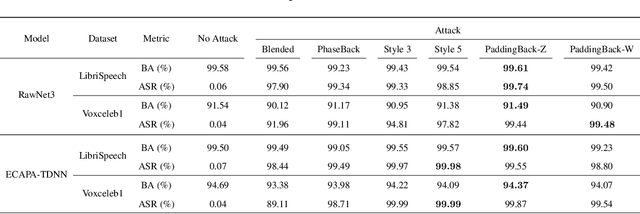
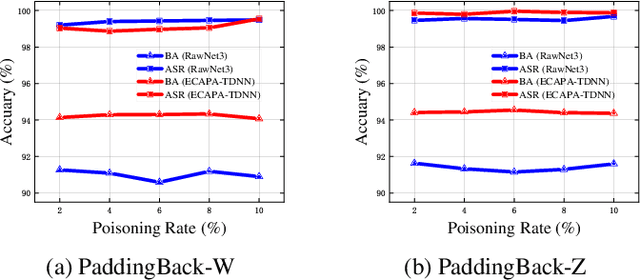
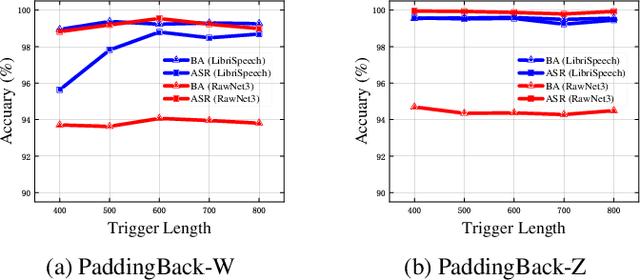
Machine Learning as a Service (MLaaS) has gained popularity due to advancements in machine learning. However, untrusted third-party platforms have raised concerns about AI security, particularly in backdoor attacks. Recent research has shown that speech backdoors can utilize transformations as triggers, similar to image backdoors. However, human ears easily detect these transformations, leading to suspicion. In this paper, we introduce PaddingBack, an inaudible backdoor attack that utilizes malicious operations to make poisoned samples indistinguishable from clean ones. Instead of using external perturbations as triggers, we exploit the widely used speech signal operation, padding, to break speaker recognition systems. Our experimental results demonstrate the effectiveness of the proposed approach, achieving a significantly high attack success rate while maintaining a high rate of benign accuracy. Furthermore, PaddingBack demonstrates the ability to resist defense methods while maintaining its stealthiness against human perception. The results of the stealthiness experiment have been made available at https://nbufabio25.github.io/paddingback/.
Bayesian Neural Network Language Modeling for Speech Recognition
Aug 28, 2022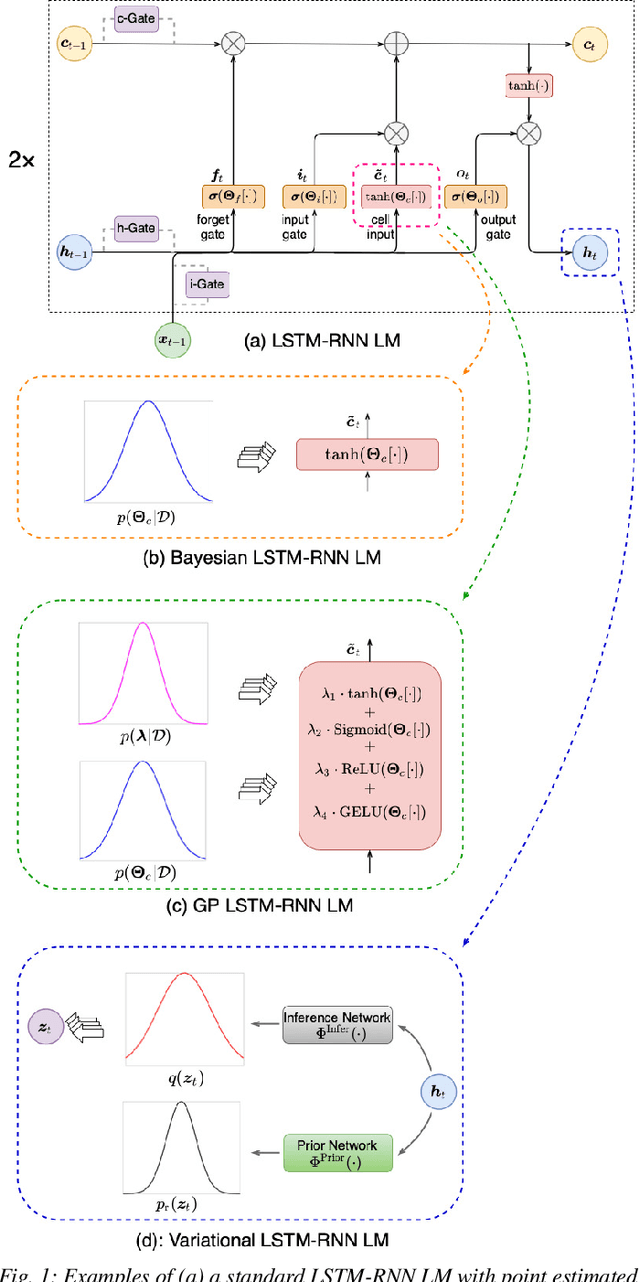
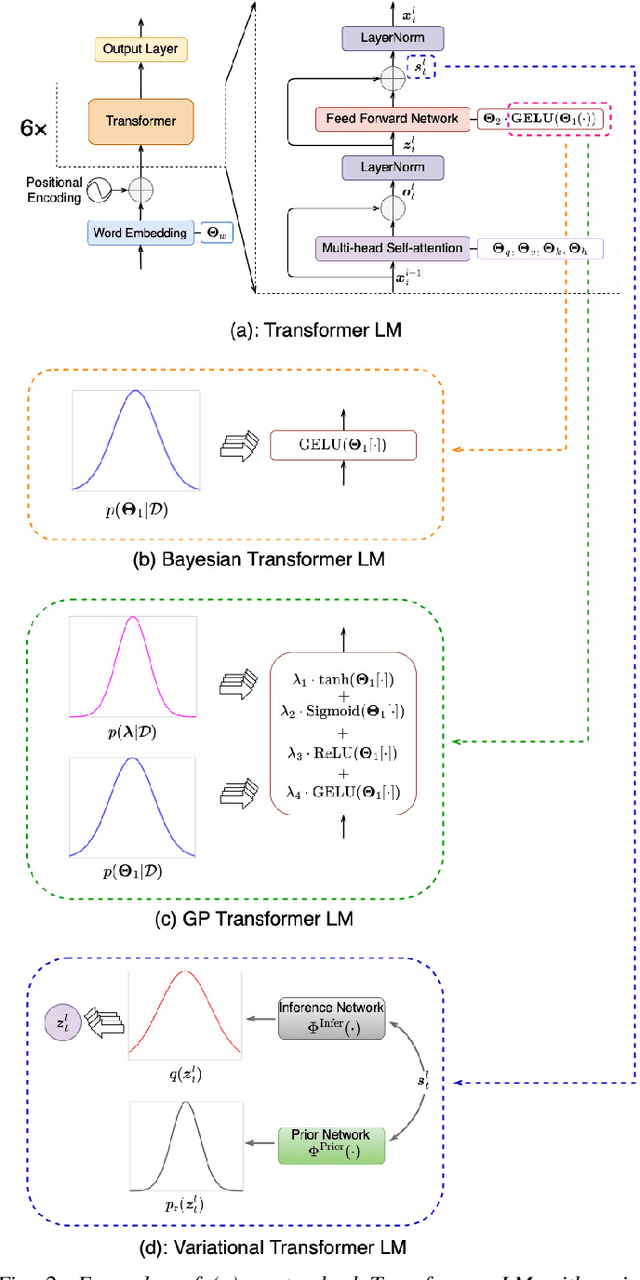
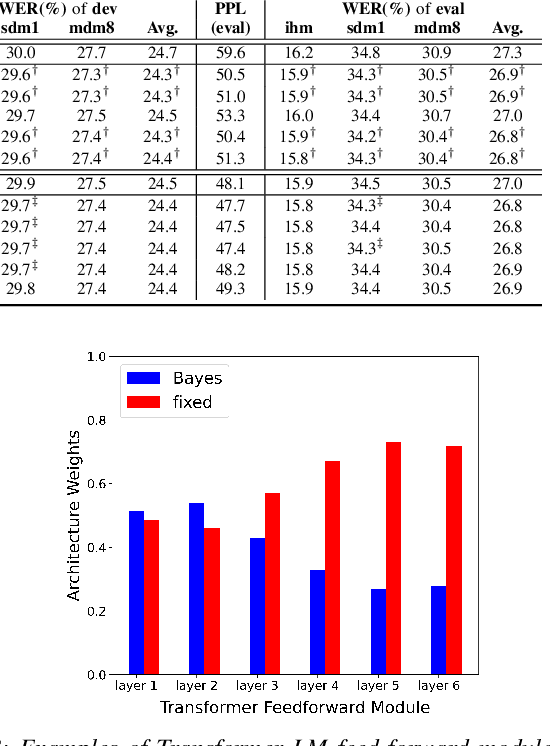
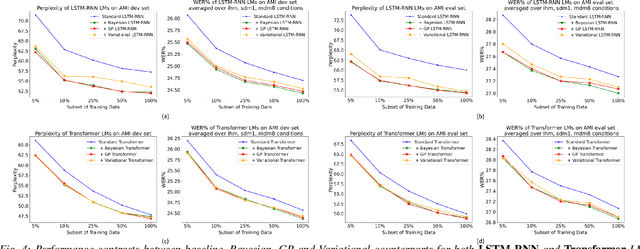
State-of-the-art neural network language models (NNLMs) represented by long short term memory recurrent neural networks (LSTM-RNNs) and Transformers are becoming highly complex. They are prone to overfitting and poor generalization when given limited training data. To this end, an overarching full Bayesian learning framework encompassing three methods is proposed in this paper to account for the underlying uncertainty in LSTM-RNN and Transformer LMs. The uncertainty over their model parameters, choice of neural activations and hidden output representations are modeled using Bayesian, Gaussian Process and variational LSTM-RNN or Transformer LMs respectively. Efficient inference approaches were used to automatically select the optimal network internal components to be Bayesian learned using neural architecture search. A minimal number of Monte Carlo parameter samples as low as one was also used. These allow the computational costs incurred in Bayesian NNLM training and evaluation to be minimized. Experiments are conducted on two tasks: AMI meeting transcription and Oxford-BBC LipReading Sentences 2 (LRS2) overlapped speech recognition using state-of-the-art LF-MMI trained factored TDNN systems featuring data augmentation, speaker adaptation and audio-visual multi-channel beamforming for overlapped speech. Consistent performance improvements over the baseline LSTM-RNN and Transformer LMs with point estimated model parameters and drop-out regularization were obtained across both tasks in terms of perplexity and word error rate (WER). In particular, on the LRS2 data, statistically significant WER reductions up to 1.3% and 1.2% absolute (12.1% and 11.3% relative) were obtained over the baseline LSTM-RNN and Transformer LMs respectively after model combination between Bayesian NNLMs and their respective baselines.
Analysis of EEG frequency bands for Envisioned Speech Recognition
Mar 29, 2022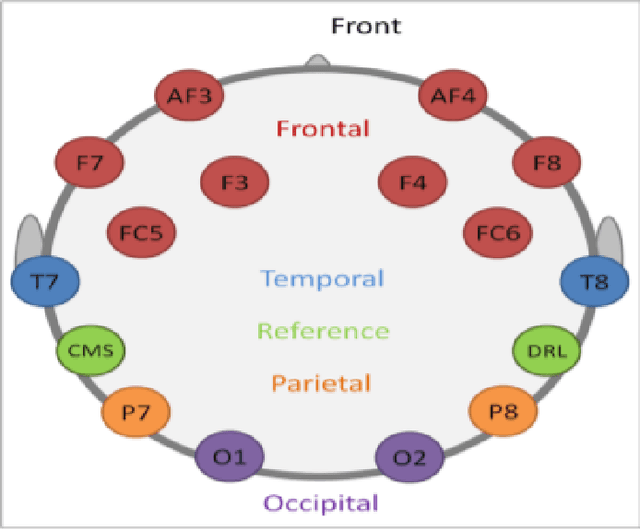
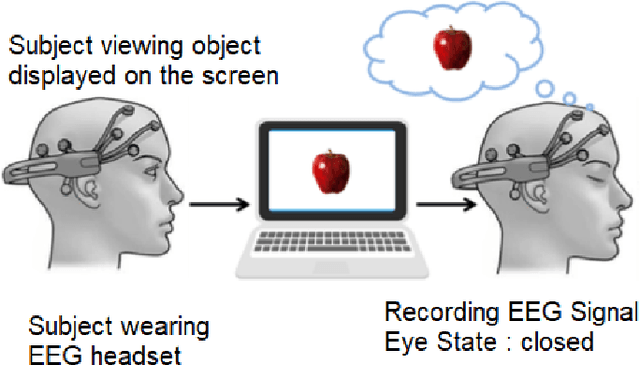
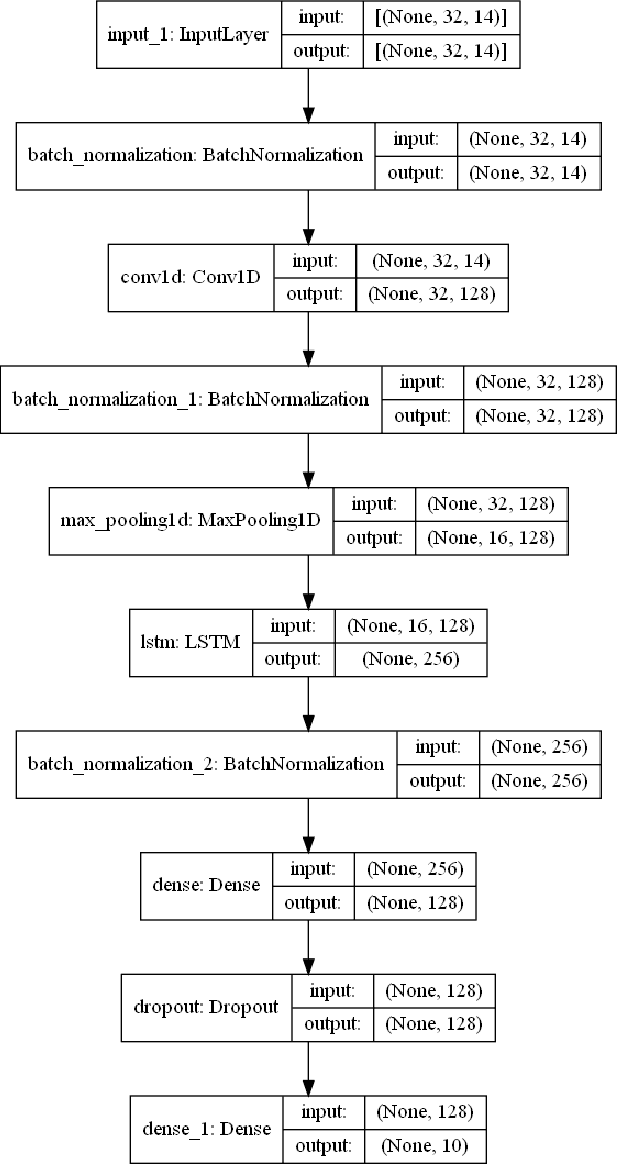
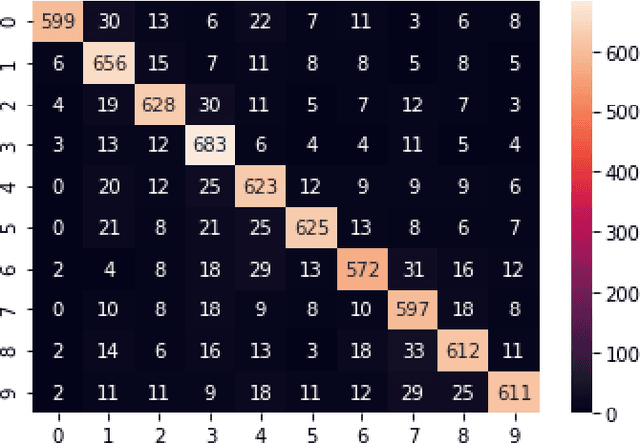
The use of Automatic speech recognition (ASR) interfaces have become increasingly popular in daily life for use in interaction and control of electronic devices. The interfaces currently being used are not feasible for a variety of users such as those suffering from a speech disorder, locked-in syndrome, paralysis or people with utmost privacy requirements. In such cases, an interface that can identify envisioned speech using electroencephalogram (EEG) signals can be of great benefit. Various works targeting this problem have been done in the past. However, there has been limited work in identifying the frequency bands ($\delta, \theta, \alpha, \beta, \gamma$) of the EEG signal that contribute towards envisioned speech recognition. Therefore, in this work, we aim to analyze the significance of different EEG frequency bands and signals obtained from different lobes of the brain and their contribution towards recognizing envisioned speech. Signals obtained from different lobes and bandpass filtered for different frequency bands are fed to a spatio-temporal deep learning architecture with Convolutional Neural Network (CNN) and Long Short-Term Memory (LSTM). The performance is evaluated on a publicly available dataset comprising of three classification tasks - digit, character and images. We obtain a classification accuracy of $85.93\%$, $87.27\%$ and $87.51\%$ for the three tasks respectively. The code for the implementation has been made available at https://github.com/ayushayt/ImaginedSpeechRecognition.
SpeechGLUE: How Well Can Self-Supervised Speech Models Capture Linguistic Knowledge?
Jun 14, 2023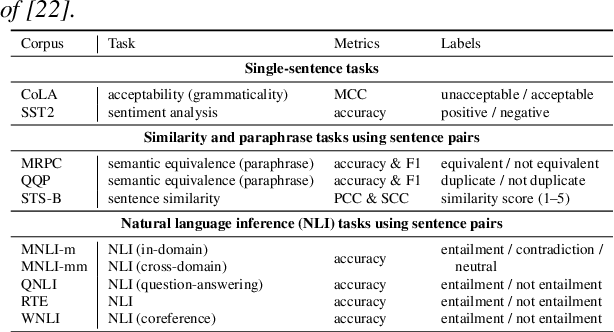
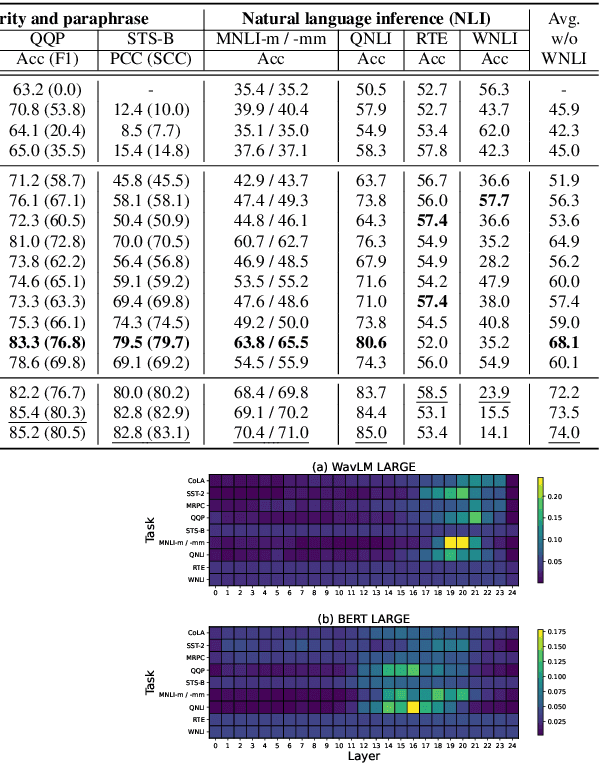
Self-supervised learning (SSL) for speech representation has been successfully applied in various downstream tasks, such as speech and speaker recognition. More recently, speech SSL models have also been shown to be beneficial in advancing spoken language understanding tasks, implying that the SSL models have the potential to learn not only acoustic but also linguistic information. In this paper, we aim to clarify if speech SSL techniques can well capture linguistic knowledge. For this purpose, we introduce SpeechGLUE, a speech version of the General Language Understanding Evaluation (GLUE) benchmark. Since GLUE comprises a variety of natural language understanding tasks, SpeechGLUE can elucidate the degree of linguistic ability of speech SSL models. Experiments demonstrate that speech SSL models, although inferior to text-based SSL models, perform better than baselines, suggesting that they can acquire a certain amount of general linguistic knowledge from just unlabeled speech data.
Hybrid Transducer and Attention based Encoder-Decoder Modeling for Speech-to-Text Tasks
May 04, 2023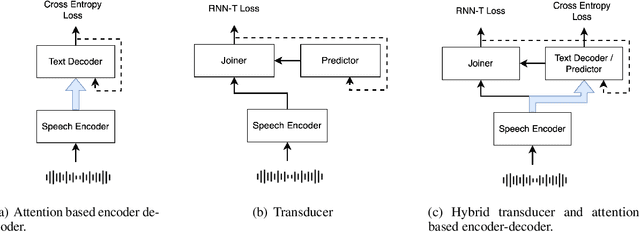


Transducer and Attention based Encoder-Decoder (AED) are two widely used frameworks for speech-to-text tasks. They are designed for different purposes and each has its own benefits and drawbacks for speech-to-text tasks. In order to leverage strengths of both modeling methods, we propose a solution by combining Transducer and Attention based Encoder-Decoder (TAED) for speech-to-text tasks. The new method leverages AED's strength in non-monotonic sequence to sequence learning while retaining Transducer's streaming property. In the proposed framework, Transducer and AED share the same speech encoder. The predictor in Transducer is replaced by the decoder in the AED model, and the outputs of the decoder are conditioned on the speech inputs instead of outputs from an unconditioned language model. The proposed solution ensures that the model is optimized by covering all possible read/write scenarios and creates a matched environment for streaming applications. We evaluate the proposed approach on the \textsc{MuST-C} dataset and the findings demonstrate that TAED performs significantly better than Transducer for offline automatic speech recognition (ASR) and speech-to-text translation (ST) tasks. In the streaming case, TAED outperforms Transducer in the ASR task and one ST direction while comparable results are achieved in another translation direction.
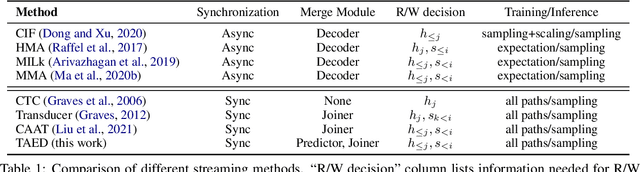
Pronunciation-aware unique character encoding for RNN Transducer-based Mandarin speech recognition
Jul 29, 2022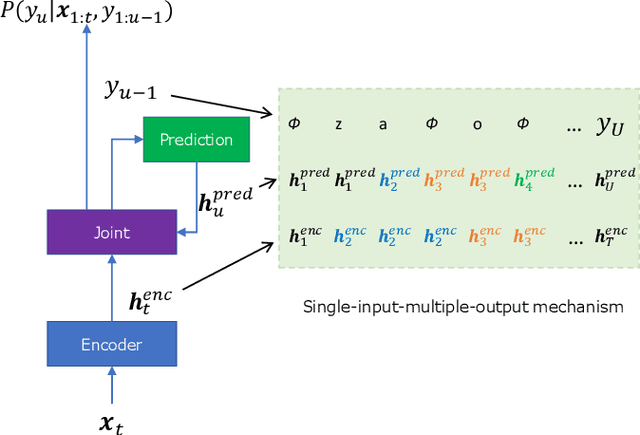
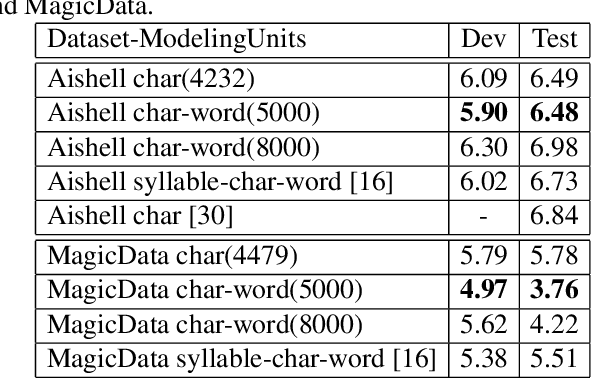

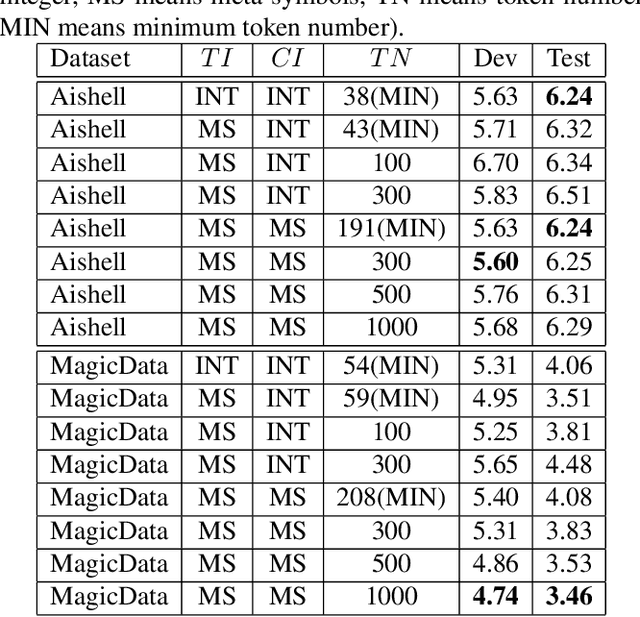
For Mandarin end-to-end (E2E) automatic speech recognition (ASR) tasks, compared to character-based modeling units, pronunciation-based modeling units could improve the sharing of modeling units in model training but meet homophone problems. In this study, we propose to use a novel pronunciation-aware unique character encoding for building E2E RNN-T-based Mandarin ASR systems. The proposed encoding is a combination of pronunciation-base syllable and character index (CI). By introducing the CI, the RNN-T model can overcome the homophone problem while utilizing the pronunciation information for extracting modeling units. With the proposed encoding, the model outputs can be converted into the final recognition result through a one-to-one mapping. We conducted experiments on Aishell and MagicData datasets, and the experimental results showed the effectiveness of the proposed method.
End-to-end Speech-to-Punctuated-Text Recognition
Jul 07, 2022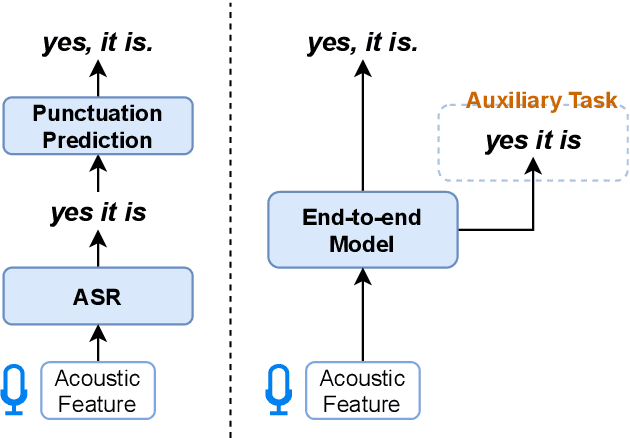
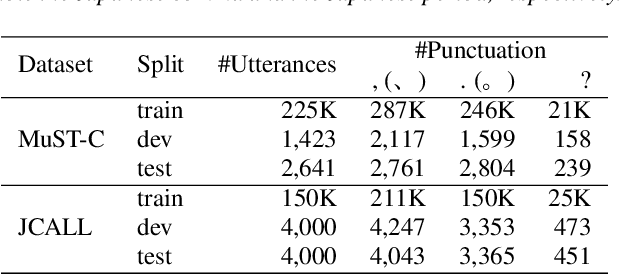

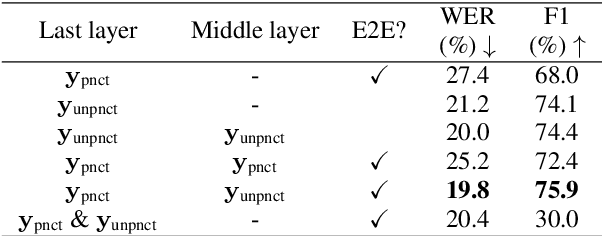
Conventional automatic speech recognition systems do not produce punctuation marks which are important for the readability of the speech recognition results. They are also needed for subsequent natural language processing tasks such as machine translation. There have been a lot of works on punctuation prediction models that insert punctuation marks into speech recognition results as post-processing. However, these studies do not utilize acoustic information for punctuation prediction and are directly affected by speech recognition errors. In this study, we propose an end-to-end model that takes speech as input and outputs punctuated texts. This model is expected to predict punctuation robustly against speech recognition errors while using acoustic information. We also propose to incorporate an auxiliary loss to train the model using the output of the intermediate layer and unpunctuated texts. Through experiments, we compare the performance of the proposed model to that of a cascaded system. The proposed model achieves higher punctuation prediction accuracy than the cascaded system without sacrificing the speech recognition error rate. It is also demonstrated that the multi-task learning using the intermediate output against the unpunctuated text is effective. Moreover, the proposed model has only about 1/7th of the parameters compared to the cascaded system.
On the Impact of Speech Recognition Errors in Passage Retrieval for Spoken Question Answering
Sep 26, 2022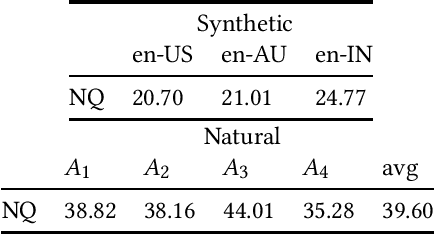

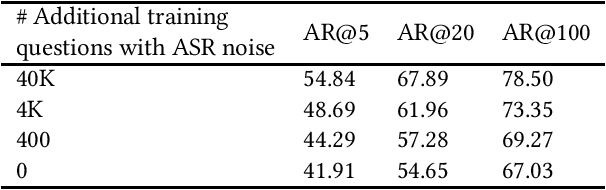
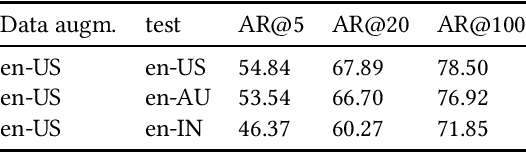
Interacting with a speech interface to query a Question Answering (QA) system is becoming increasingly popular. Typically, QA systems rely on passage retrieval to select candidate contexts and reading comprehension to extract the final answer. While there has been some attention to improving the reading comprehension part of QA systems against errors that automatic speech recognition (ASR) models introduce, the passage retrieval part remains unexplored. However, such errors can affect the performance of passage retrieval, leading to inferior end-to-end performance. To address this gap, we augment two existing large-scale passage ranking and open domain QA datasets with synthetic ASR noise and study the robustness of lexical and dense retrievers against questions with ASR noise. Furthermore, we study the generalizability of data augmentation techniques across different domains; with each domain being a different language dialect or accent. Finally, we create a new dataset with questions voiced by human users and use their transcriptions to show that the retrieval performance can further degrade when dealing with natural ASR noise instead of synthetic ASR noise.
Self-supervised Neural Factor Analysis for Disentangling Utterance-level Speech Representations
May 18, 2023
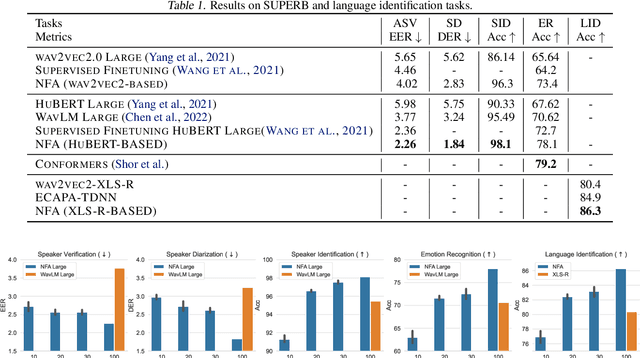
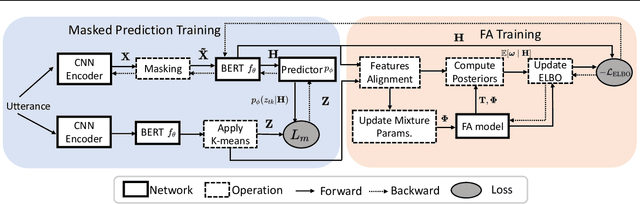
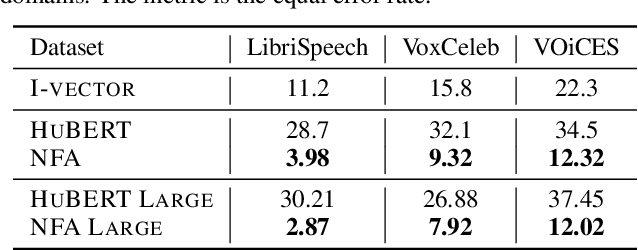
Self-supervised learning (SSL) speech models such as wav2vec and HuBERT have demonstrated state-of-the-art performance on automatic speech recognition (ASR) and proved to be extremely useful in low label-resource settings. However, the success of SSL models has yet to transfer to utterance-level tasks such as speaker, emotion, and language recognition, which still require supervised fine-tuning of the SSL models to obtain good performance. We argue that the problem is caused by the lack of disentangled representations and an utterance-level learning objective for these tasks. Inspired by how HuBERT uses clustering to discover hidden acoustic units, we formulate a factor analysis (FA) model that uses the discovered hidden acoustic units to align the SSL features. The underlying utterance-level representations are disentangled from the content of speech using probabilistic inference on the aligned features. Furthermore, the variational lower bound derived from the FA model provides an utterance-level objective, allowing error gradients to be backpropagated to the Transformer layers to learn highly discriminative acoustic units. When used in conjunction with HuBERT's masked prediction training, our models outperform the current best model, WavLM, on all utterance-level non-semantic tasks on the SUPERB benchmark with only 20% of labeled data.