 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Dynamic Latency for CTC-Based Streaming Automatic Speech Recognition With Emformer
Mar 29, 2022
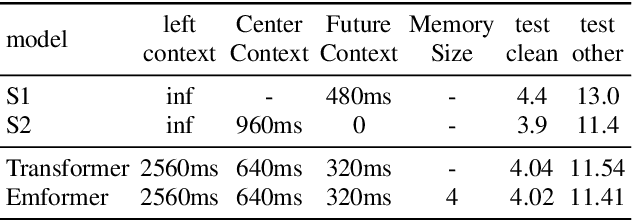
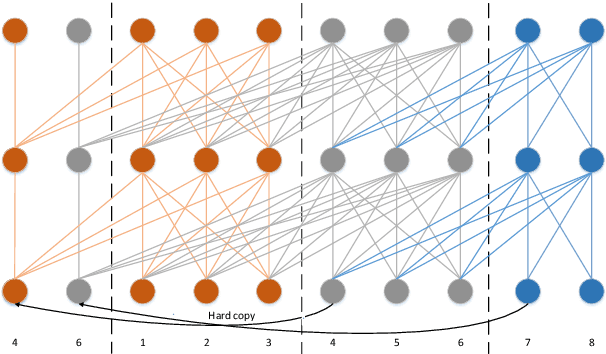
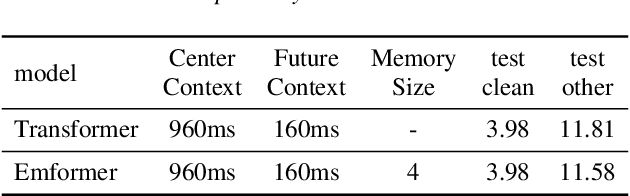
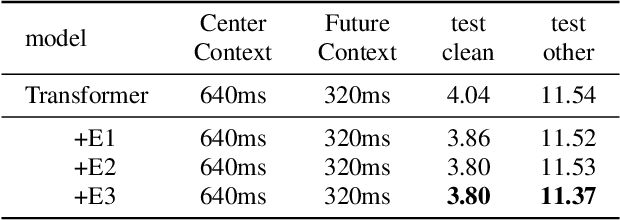
An inferior performance of the streaming automatic speech recognition models versus non-streaming model is frequently seen due to the absence of future context. In order to improve the performance of the streaming model and reduce the computational complexity, a frame-level model using efficient augment memory transformer block and dynamic latency training method is employed for streaming automatic speech recognition in this paper. The long-range history context is stored into the augment memory bank as a complement to the limited history context used in the encoder. Key and value are cached by a cache mechanism and reused for next chunk to reduce computation. Afterwards, a dynamic latency training method is proposed to obtain better performance and support low and high latency inference simultaneously. Our experiments are conducted on benchmark 960h LibriSpeech data set. With an average latency of 640ms, our model achieves a relative WER reduction of 6.0% on test-clean and 3.0% on test-other versus the truncate chunk-wise Transformer.
Multilingual Speech Emotion Recognition With Multi-Gating Mechanism and Neural Architecture Search
Nov 16, 2022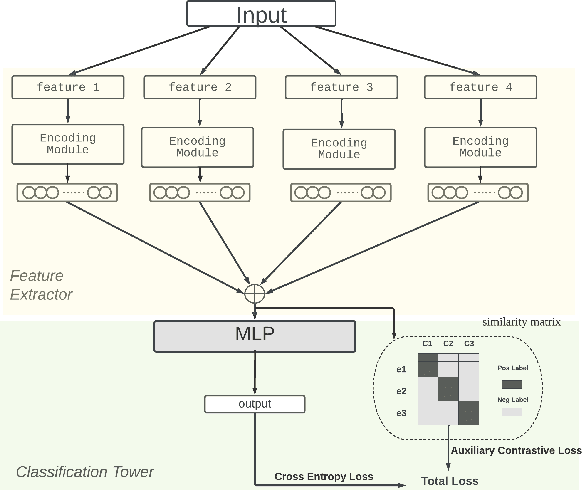

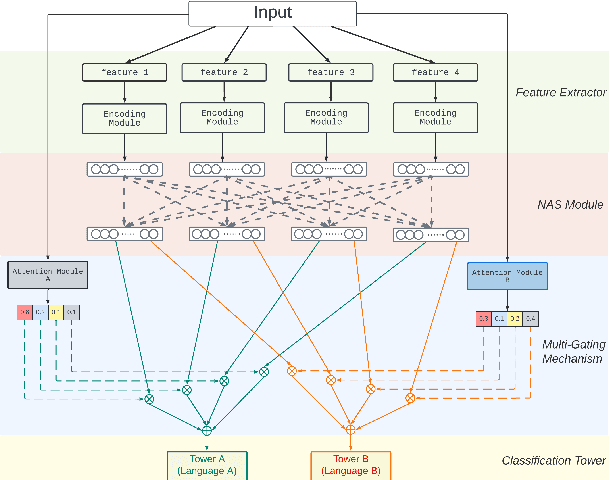

Speech emotion recognition (SER) classifies audio into emotion categories such as Happy, Angry, Fear, Disgust and Neutral. While Speech Emotion Recognition (SER) is a common application for popular languages, it continues to be a problem for low-resourced languages, i.e., languages with no pretrained speech-to-text recognition models. This paper firstly proposes a language-specific model that extract emotional information from multiple pre-trained speech models, and then designs a multi-domain model that simultaneously performs SER for various languages. Our multidomain model employs a multi-gating mechanism to generate unique weighted feature combination for each language, and also searches for specific neural network structure for each language through a neural architecture search module. In addition, we introduce a contrastive auxiliary loss to build more separable representations for audio data. Our experiments show that our model raises the state-of-the-art accuracy by 3% for German and 14.3% for French.
Multi-Channel Transformer Transducer for Speech Recognition
Aug 30, 2021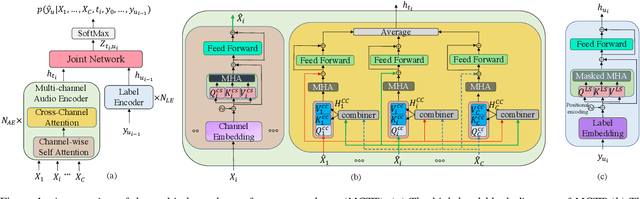
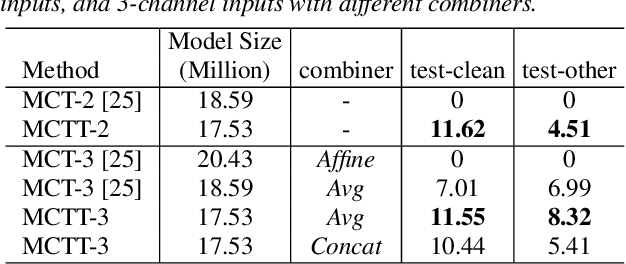
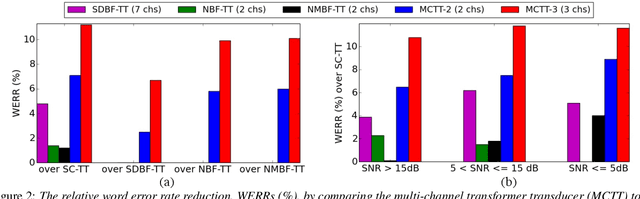
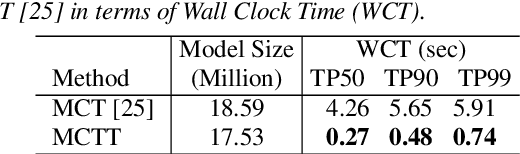
Multi-channel inputs offer several advantages over single-channel, to improve the robustness of on-device speech recognition systems. Recent work on multi-channel transformer, has proposed a way to incorporate such inputs into end-to-end ASR for improved accuracy. However, this approach is characterized by a high computational complexity, which prevents it from being deployed in on-device systems. In this paper, we present a novel speech recognition model, Multi-Channel Transformer Transducer (MCTT), which features end-to-end multi-channel training, low computation cost, and low latency so that it is suitable for streaming decoding in on-device speech recognition. In a far-field in-house dataset, our MCTT outperforms stagewise multi-channel models with transformer-transducer up to 6.01% relative WER improvement (WERR). In addition, MCTT outperforms the multi-channel transformer up to 11.62% WERR, and is 15.8 times faster in terms of inference speed. We further show that we can improve the computational cost of MCTT by constraining the future and previous context in attention computations.
Code-Switching Text Generation and Injection in Mandarin-English ASR
Mar 20, 2023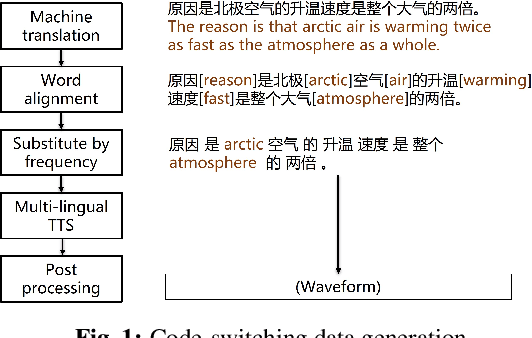
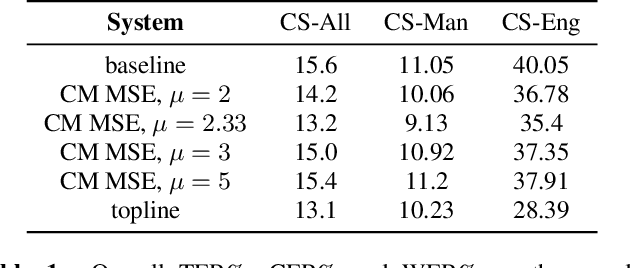
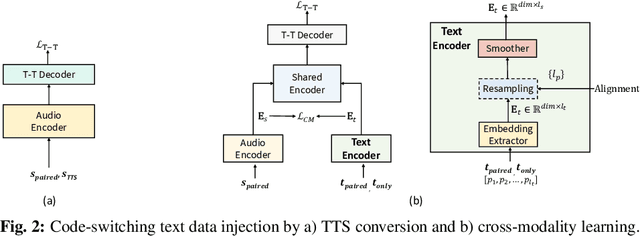

Code-switching speech refers to a means of expression by mixing two or more languages within a single utterance. Automatic Speech Recognition (ASR) with End-to-End (E2E) modeling for such speech can be a challenging task due to the lack of data. In this study, we investigate text generation and injection for improving the performance of an industry commonly-used streaming model, Transformer-Transducer (T-T), in Mandarin-English code-switching speech recognition. We first propose a strategy to generate code-switching text data and then investigate injecting generated text into T-T model explicitly by Text-To-Speech (TTS) conversion or implicitly by tying speech and text latent spaces. Experimental results on the T-T model trained with a dataset containing 1,800 hours of real Mandarin-English code-switched speech show that our approaches to inject generated code-switching text significantly boost the performance of T-T models, i.e., 16% relative Token-based Error Rate (TER) reduction averaged on three evaluation sets, and the approach of tying speech and text latent spaces is superior to that of TTS conversion on the evaluation set which contains more homogeneous data with the training set.
Speech-enhanced and Noise-aware Networks for Robust Speech Recognition
Mar 25, 2022
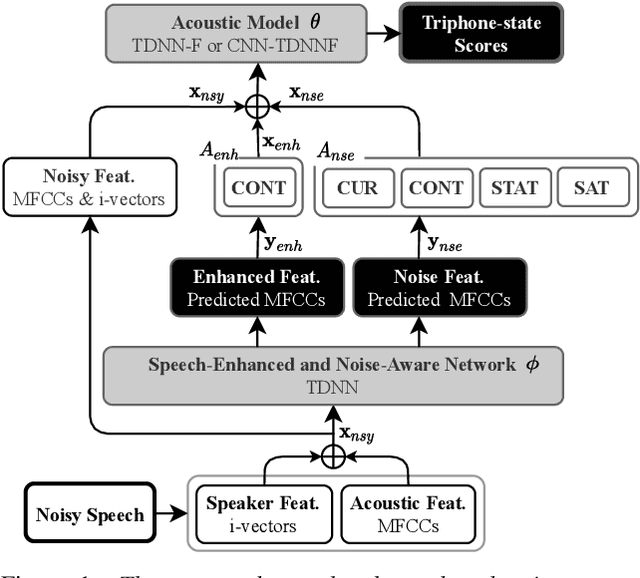
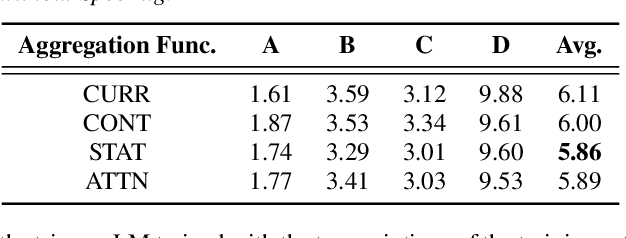
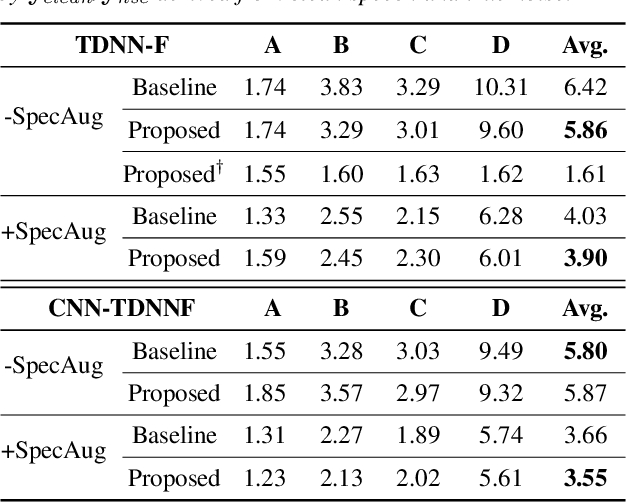
Compensation for channel mismatch and noise interference is essential for robust automatic speech recognition. Enhanced speech has been introduced into the multi-condition training of acoustic models to improve their generalization ability. In this paper, a noise-aware training framework based on two cascaded neural structures is proposed to jointly optimize speech enhancement and speech recognition. The feature enhancement module is composed of a multi-task autoencoder, where noisy speech is decomposed into clean speech and noise. By concatenating its enhanced, noise-aware, and noisy features for each frame, the acoustic-modeling module maps each feature-augmented frame into a triphone state by optimizing the lattice-free maximum mutual information and cross entropy between the predicted and actual state sequences. On top of the factorized time delay neural network (TDNN-F) and its convolutional variant (CNN-TDNNF), both with SpecAug, the two proposed systems achieve word error rate (WER) of 3.90% and 3.55%, respectively, on the Aurora-4 task. Compared with the best existing systems that use bigram and trigram language models for decoding, the proposed CNN-TDNNF-based system achieves a relative WER reduction of 15.20% and 33.53%, respectively. In addition, the proposed CNN-TDNNF-based system also outperforms the baseline CNN-TDNNF system on the AMI task.
Context-Aware Selective Label Smoothing for Calibrating Sequence Recognition Model
Mar 13, 2023
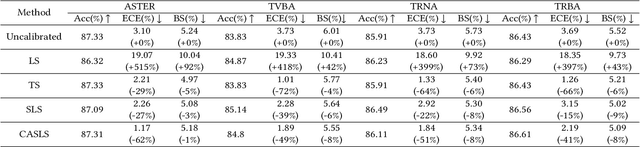
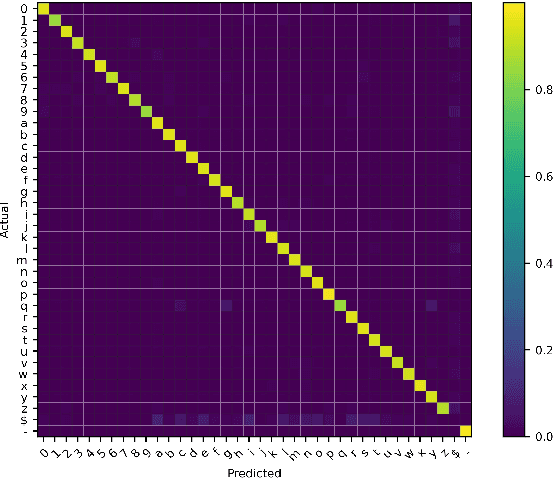
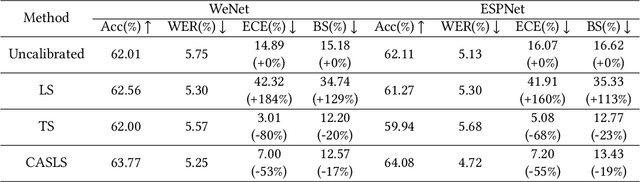
Despite the success of deep neural network (DNN) on sequential data (i.e., scene text and speech) recognition, it suffers from the over-confidence problem mainly due to overfitting in training with the cross-entropy loss, which may make the decision-making less reliable. Confidence calibration has been recently proposed as one effective solution to this problem. Nevertheless, the majority of existing confidence calibration methods aims at non-sequential data, which is limited if directly applied to sequential data since the intrinsic contextual dependency in sequences or the class-specific statistical prior is seldom exploited. To the end, we propose a Context-Aware Selective Label Smoothing (CASLS) method for calibrating sequential data. The proposed CASLS fully leverages the contextual dependency in sequences to construct confusion matrices of contextual prediction statistics over different classes. Class-specific error rates are then used to adjust the weights of smoothing strength in order to achieve adaptive calibration. Experimental results on sequence recognition tasks, including scene text recognition and speech recognition, demonstrate that our method can achieve the state-of-the-art performance.
Korean Tokenization for Beam Search Rescoring in Speech Recognition
Feb 22, 2022
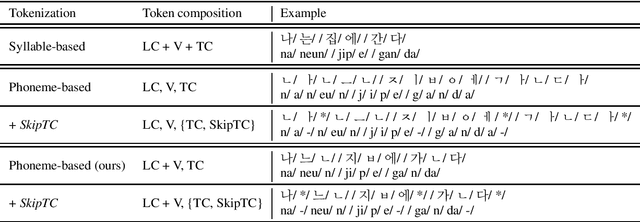
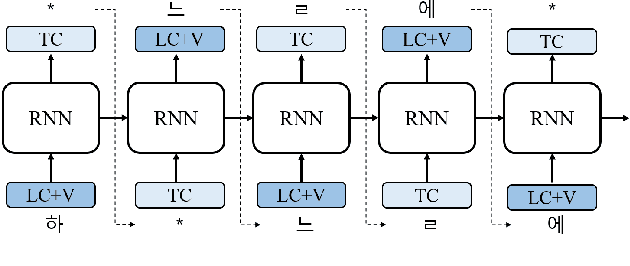
The performance of automatic speech recognition (ASR) models can be greatly improved by proper beam-search decoding with external language model (LM). There has been an increasing interest in Korean speech recognition, but not many studies have been focused on the decoding procedure. In this paper, we propose a Korean tokenization method for neural network-based LM used for Korean ASR. Although the common approach is to use the same tokenization method for external LM as the ASR model, we show that it may not be the best choice for Korean. We propose a new tokenization method that inserts a special token, SkipTC, when there is no trailing consonant in a Korean syllable. By utilizing the proposed SkipTC token, the input sequence for LM becomes very regularly patterned so that the LM can better learn the linguistic characteristics. Our experiments show that the proposed approach achieves a lower word error rate compared to the same LM model without SkipTC. In addition, we are the first to report the ASR performance for the recently introduced large-scale 7,600h Korean speech dataset.
Synt++: Utilizing Imperfect Synthetic Data to Improve Speech Recognition
Oct 21, 2021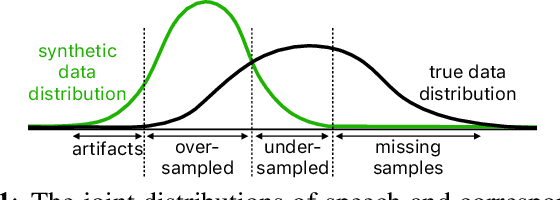
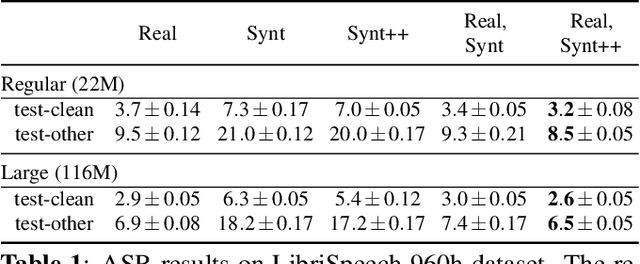
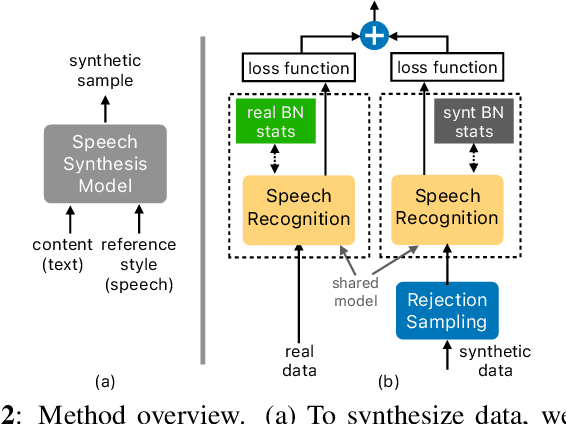
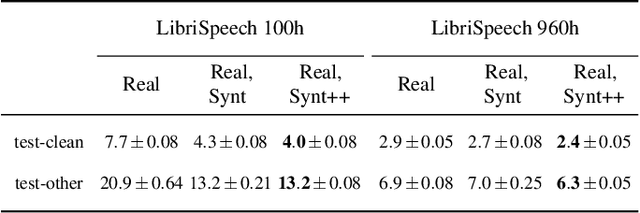
With recent advances in speech synthesis, synthetic data is becoming a viable alternative to real data for training speech recognition models. However, machine learning with synthetic data is not trivial due to the gap between the synthetic and the real data distributions. Synthetic datasets may contain artifacts that do not exist in real data such as structured noise, content errors, or unrealistic speaking styles. Moreover, the synthesis process may introduce a bias due to uneven sampling of the data manifold. We propose two novel techniques during training to mitigate the problems due to the distribution gap: (i) a rejection sampling algorithm and (ii) using separate batch normalization statistics for the real and the synthetic samples. We show that these methods significantly improve the training of speech recognition models using synthetic data. We evaluate the proposed approach on keyword detection and Automatic Speech Recognition (ASR) tasks, and observe up to 18% and 13% relative error reduction, respectively, compared to naively using the synthetic data.
AV-data2vec: Self-supervised Learning of Audio-Visual Speech Representations with Contextualized Target Representations
Feb 10, 2023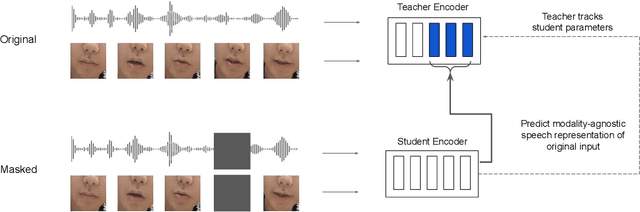
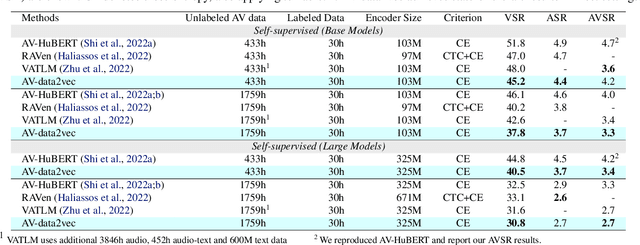
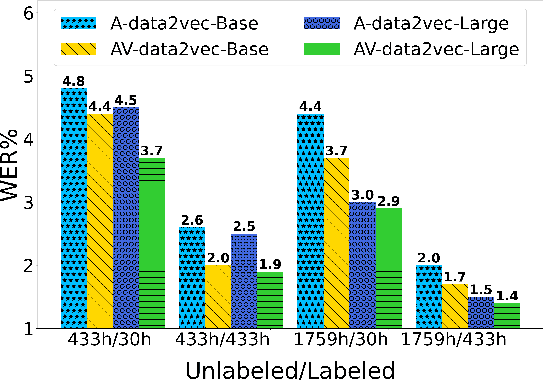
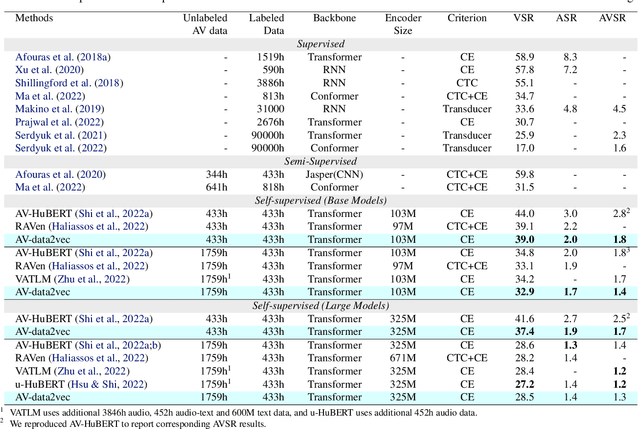
Self-supervision has shown great potential for audio-visual speech recognition by vastly reducing the amount of labeled data required to build good systems. However, existing methods are either not entirely end-to-end or do not train joint representations of both modalities. In this paper, we introduce AV-data2vec which addresses these challenges and builds audio-visual representations based on predicting contextualized representations which has been successful in the uni-modal case. The model uses a shared transformer encoder for both audio and video and can combine both modalities to improve speech recognition. Results on LRS3 show that AV-data2vec consistently outperforms existing methods under most settings.
Adversarial Speaker Disentanglement Using Unannotated External Data for Self-supervised Representation Based Voice Conversion
May 16, 2023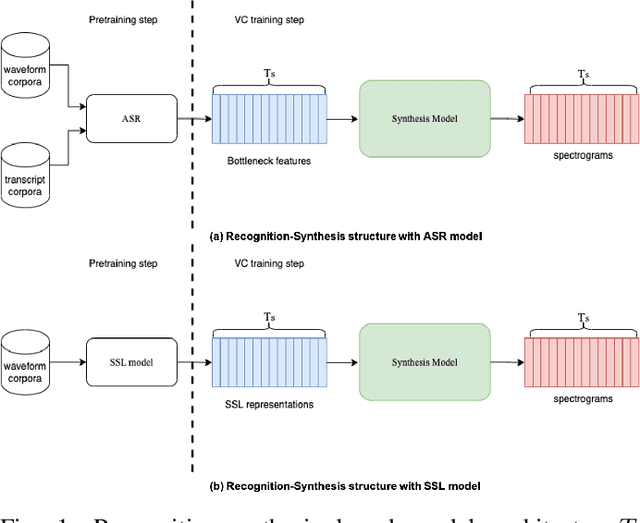
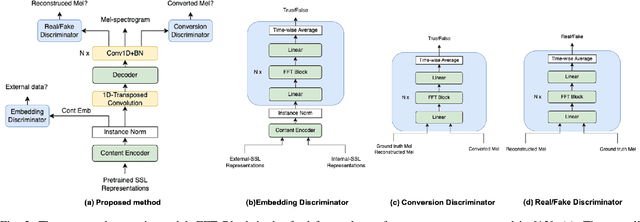
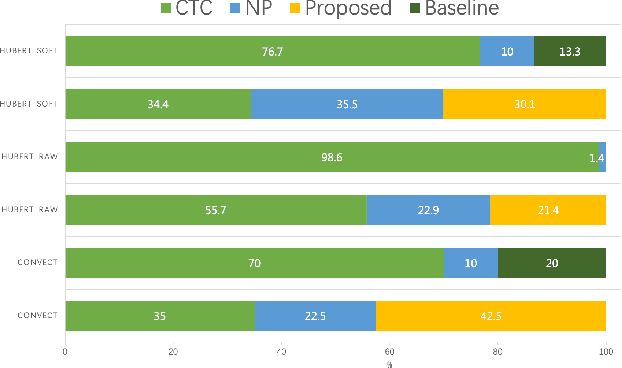
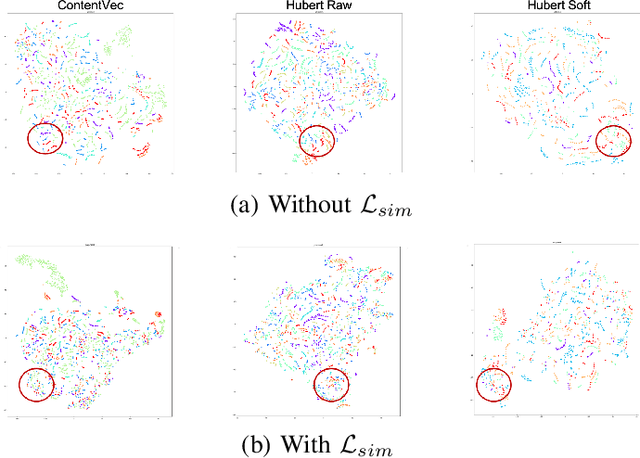
Nowadays, recognition-synthesis-based methods have been quite popular with voice conversion (VC). By introducing linguistics features with good disentangling characters extracted from an automatic speech recognition (ASR) model, the VC performance achieved considerable breakthroughs. Recently, self-supervised learning (SSL) methods trained with a large-scale unannotated speech corpus have been applied to downstream tasks focusing on the content information, which is suitable for VC tasks. However, a huge amount of speaker information in SSL representations degrades timbre similarity and the quality of converted speech significantly. To address this problem, we proposed a high-similarity any-to-one voice conversion method with the input of SSL representations. We incorporated adversarial training mechanisms in the synthesis module using external unannotated corpora. Two auxiliary discriminators were trained to distinguish whether a sequence of mel-spectrograms has been converted by the acoustic model and whether a sequence of content embeddings contains speaker information from external corpora. Experimental results show that our proposed method achieves comparable similarity and higher naturalness than the supervised method, which needs a huge amount of annotated corpora for training and is applicable to improve similarity for VC methods with other SSL representations as input.