 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Analysis of Self-Attention Head Diversity for Conformer-based Automatic Speech Recognition
Sep 13, 2022
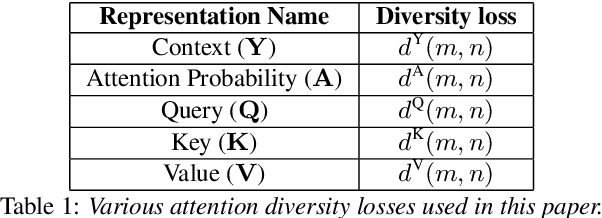
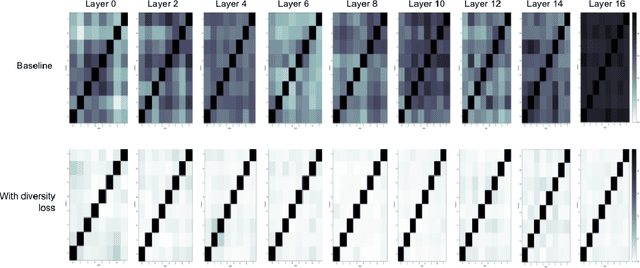
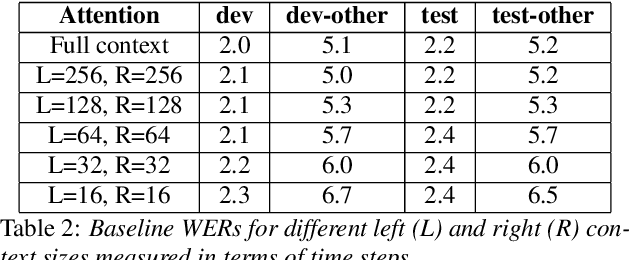
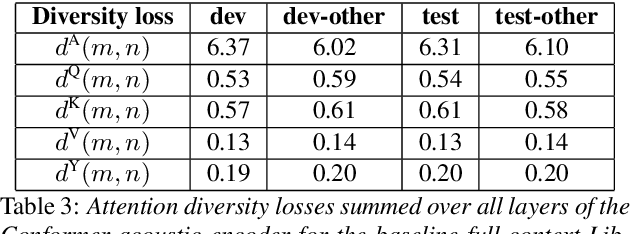
Attention layers are an integral part of modern end-to-end automatic speech recognition systems, for instance as part of the Transformer or Conformer architecture. Attention is typically multi-headed, where each head has an independent set of learned parameters and operates on the same input feature sequence. The output of multi-headed attention is a fusion of the outputs from the individual heads. We empirically analyze the diversity between representations produced by the different attention heads and demonstrate that the heads become highly correlated during the course of training. We investigate a few approaches to increasing attention head diversity, including using different attention mechanisms for each head and auxiliary training loss functions to promote head diversity. We show that introducing diversity-promoting auxiliary loss functions during training is a more effective approach, and obtain WER improvements of up to 6% relative on the Librispeech corpus. Finally, we draw a connection between the diversity of attention heads and the similarity of the gradients of head parameters.
Building a Non-native Speech Corpus Featuring Chinese-English Bilingual Children: Compilation and Rationale
Apr 30, 2023
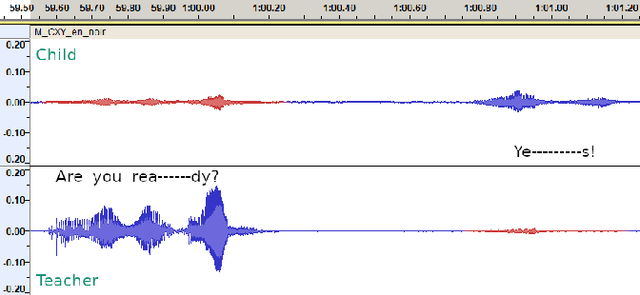
This paper introduces a non-native speech corpus consisting of narratives from fifty 5- to 6-year-old Chinese-English children. Transcripts totaling 6.5 hours of children taking a narrative comprehension test in English (L2) are presented, along with human-rated scores and annotations of grammatical and pronunciation errors. The children also completed the parallel MAIN tests in Chinese (L1) for reference purposes. For all tests we recorded audio and video with our innovative self-developed remote collection methods. The video recordings serve to mitigate the challenge of low intelligibility in L2 narratives produced by young children during the transcription process. This corpus offers valuable resources for second language teaching and has the potential to enhance the overall performance of automatic speech recognition (ASR).
Unsupervised ASR via Cross-Lingual Pseudo-Labeling
May 19, 2023

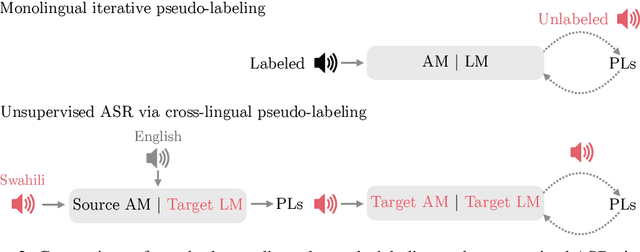

Recent work has shown that it is possible to train an $\textit{unsupervised}$ automatic speech recognition (ASR) system using only unpaired audio and text. Existing unsupervised ASR methods assume that no labeled data can be used for training. We argue that even if one does not have any labeled audio for a given language, there is $\textit{always}$ labeled data available for other languages. We show that it is possible to use character-level acoustic models (AMs) from other languages to bootstrap an $\textit{unsupervised}$ AM in a new language. Here, "unsupervised" means no labeled audio is available for the $\textit{target}$ language. Our approach is based on two key ingredients: (i) generating pseudo-labels (PLs) of the $\textit{target}$ language using some $\textit{other}$ language AM and (ii) constraining these PLs with a $\textit{target language model}$. Our approach is effective on Common Voice: e.g. transfer of English AM to Swahili achieves 18% WER. It also outperforms character-based wav2vec-U 2.0 by 15% absolute WER on LJSpeech with 800h of labeled German data instead of 60k hours of unlabeled English data.
Speech Emotion Diarization: Which Emotion Appears When?
Jun 22, 2023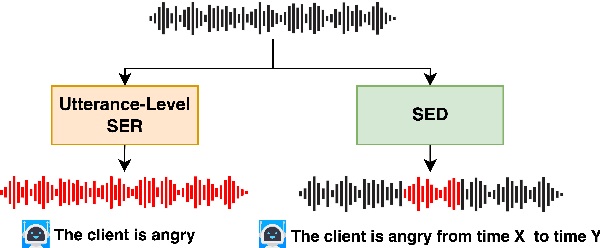


Speech Emotion Recognition (SER) typically relies on utterance-level solutions. However, emotions conveyed through speech should be considered as discrete speech events with definite temporal boundaries, rather than attributes of the entire utterance. To reflect the fine-grained nature of speech emotions, we propose a new task: Speech Emotion Diarization (SED). Just as Speaker Diarization answers the question of "Who speaks when?", Speech Emotion Diarization answers the question of "Which emotion appears when?". To facilitate the evaluation of the performance and establish a common benchmark for researchers, we introduce the Zaion Emotion Dataset (ZED), an openly accessible speech emotion dataset that includes non-acted emotions recorded in real-life conditions, along with manually-annotated boundaries of emotion segments within the utterance. We provide competitive baselines and open-source the code and the pre-trained models.
MC-DRE: Multi-Aspect Cross Integration for Drug Event/Entity Extraction
Aug 15, 2023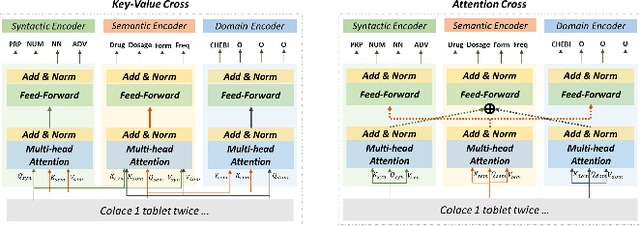
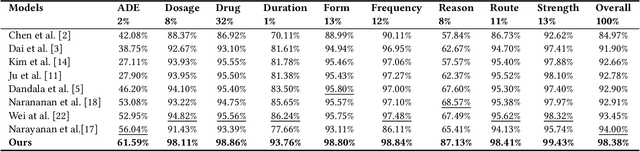

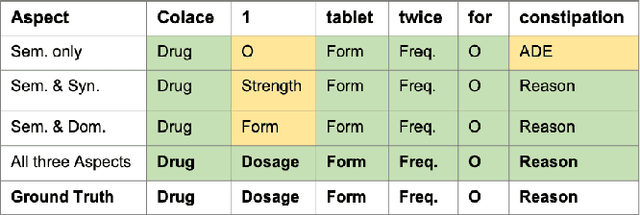
Extracting meaningful drug-related information chunks, such as adverse drug events (ADE), is crucial for preventing morbidity and saving many lives. Most ADEs are reported via an unstructured conversation with the medical context, so applying a general entity recognition approach is not sufficient enough. In this paper, we propose a new multi-aspect cross-integration framework for drug entity/event detection by capturing and aligning different context/language/knowledge properties from drug-related documents. We first construct multi-aspect encoders to describe semantic, syntactic, and medical document contextual information by conducting those slot tagging tasks, main drug entity/event detection, part-of-speech tagging, and general medical named entity recognition. Then, each encoder conducts cross-integration with other contextual information in three ways: the key-value cross, attention cross, and feedforward cross, so the multi-encoders are integrated in depth. Our model outperforms all SOTA on two widely used tasks, flat entity detection and discontinuous event extraction.
Text is All You Need: Personalizing ASR Models using Controllable Speech Synthesis
Mar 27, 2023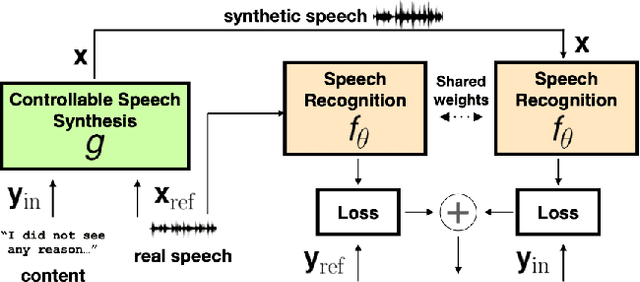
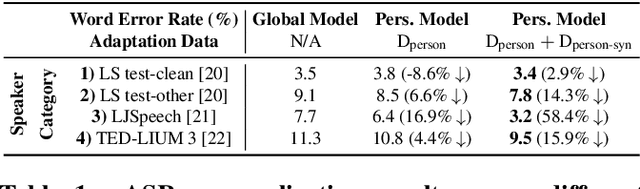
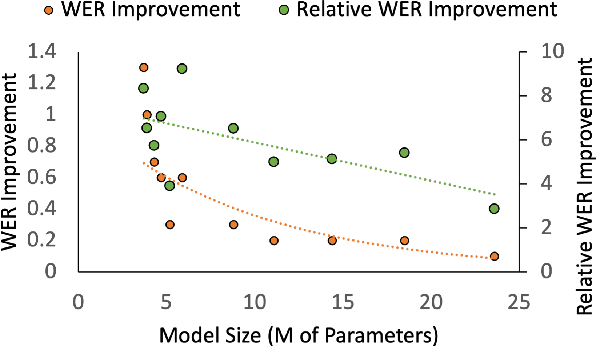
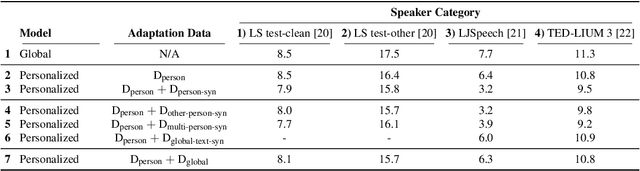
Adapting generic speech recognition models to specific individuals is a challenging problem due to the scarcity of personalized data. Recent works have proposed boosting the amount of training data using personalized text-to-speech synthesis. Here, we ask two fundamental questions about this strategy: when is synthetic data effective for personalization, and why is it effective in those cases? To address the first question, we adapt a state-of-the-art automatic speech recognition (ASR) model to target speakers from four benchmark datasets representative of different speaker types. We show that ASR personalization with synthetic data is effective in all cases, but particularly when (i) the target speaker is underrepresented in the global data, and (ii) the capacity of the global model is limited. To address the second question of why personalized synthetic data is effective, we use controllable speech synthesis to generate speech with varied styles and content. Surprisingly, we find that the text content of the synthetic data, rather than style, is important for speaker adaptation. These results lead us to propose a data selection strategy for ASR personalization based on speech content.
Unsupervised Speech Recognition
May 24, 2021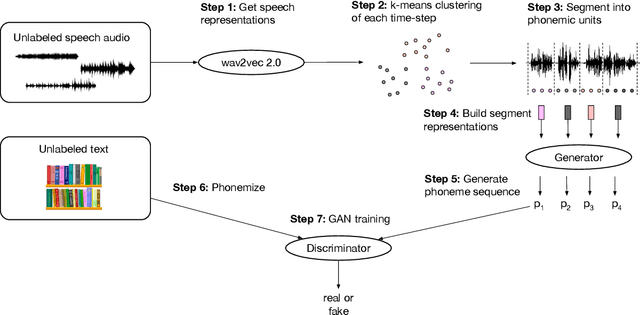

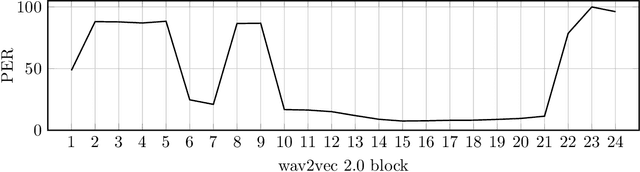
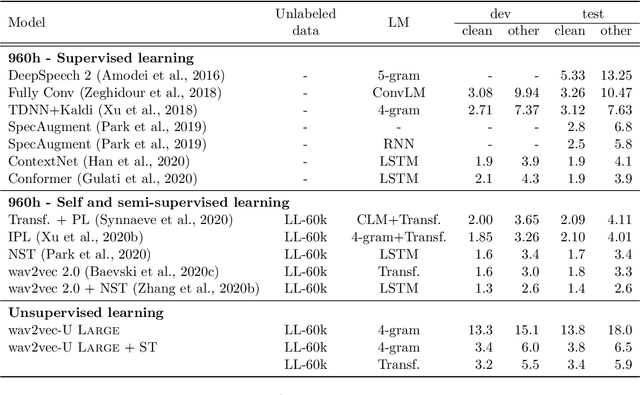
Despite rapid progress in the recent past, current speech recognition systems still require labeled training data which limits this technology to a small fraction of the languages spoken around the globe. This paper describes wav2vec-U, short for wav2vec Unsupervised, a method to train speech recognition models without any labeled data. We leverage self-supervised speech representations to segment unlabeled audio and learn a mapping from these representations to phonemes via adversarial training. The right representations are key to the success of our method. Compared to the best previous unsupervised work, wav2vec-U reduces the phoneme error rate on the TIMIT benchmark from 26.1 to 11.3. On the larger English Librispeech benchmark, wav2vec-U achieves a word error rate of 5.9 on test-other, rivaling some of the best published systems trained on 960 hours of labeled data from only two years ago. We also experiment on nine other languages, including low-resource languages such as Kyrgyz, Swahili and Tatar.
Hi,KIA: A Speech Emotion Recognition Dataset for Wake-Up Words
Nov 07, 2022
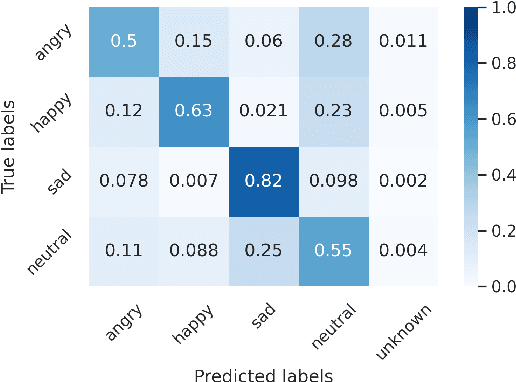
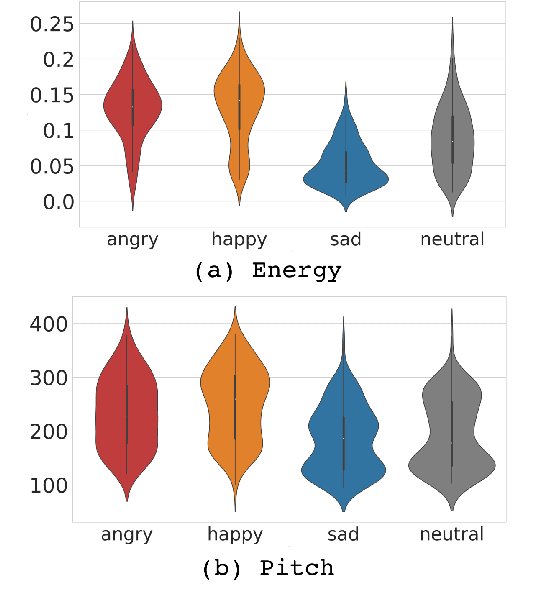
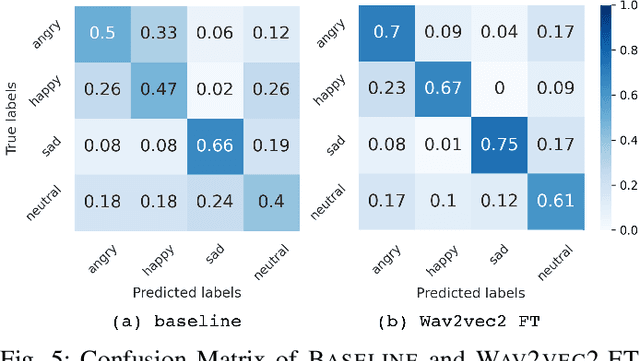
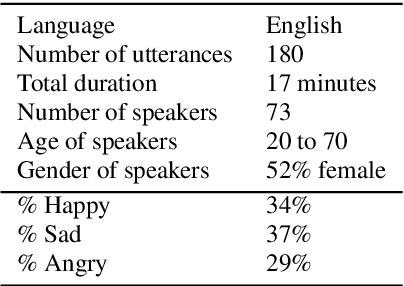
Wake-up words (WUW) is a short sentence used to activate a speech recognition system to receive the user's speech input. WUW utterances include not only the lexical information for waking up the system but also non-lexical information such as speaker identity or emotion. In particular, recognizing the user's emotional state may elaborate the voice communication. However, there is few dataset where the emotional state of the WUW utterances is labeled. In this paper, we introduce Hi, KIA, a new WUW dataset which consists of 488 Korean accent emotional utterances collected from four male and four female speakers and each of utterances is labeled with four emotional states including anger, happy, sad, or neutral. We present the step-by-step procedure to build the dataset, covering scenario selection, post-processing, and human validation for label agreement. Also, we provide two classification models for WUW speech emotion recognition using the dataset. One is based on traditional hand-craft features and the other is a transfer-learning approach using a pre-trained neural network. These classification models could be used as benchmarks in further research.
Censer: Curriculum Semi-supervised Learning for Speech Recognition Based on Self-supervised Pre-training
Jun 16, 2022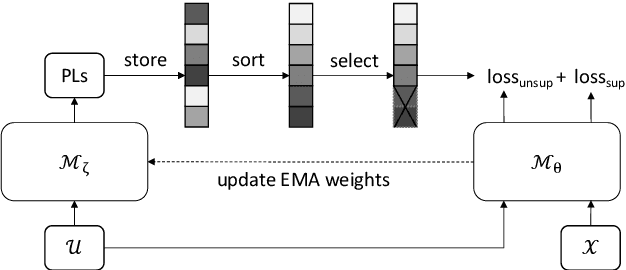

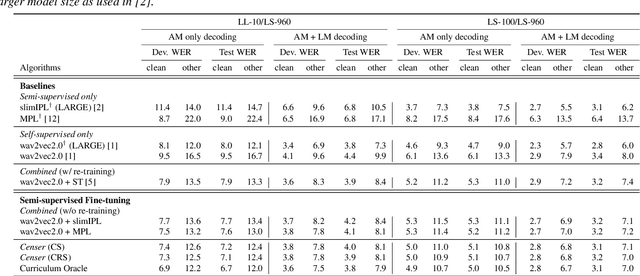
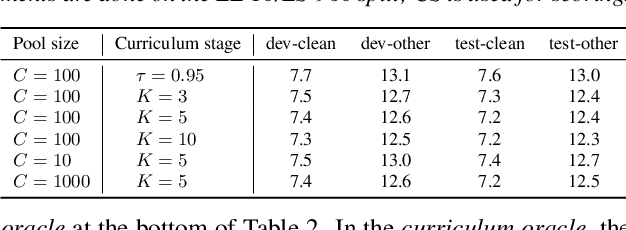
Recent studies have shown that the benefits provided by self-supervised pre-training and self-training (pseudo-labeling) are complementary. Semi-supervised fine-tuning strategies under the pre-training framework, however, remain insufficiently studied. Besides, modern semi-supervised speech recognition algorithms either treat unlabeled data indiscriminately or filter out noisy samples with a confidence threshold. The dissimilarities among different unlabeled data are often ignored. In this paper, we propose Censer, a semi-supervised speech recognition algorithm based on self-supervised pre-training to maximize the utilization of unlabeled data. The pre-training stage of Censer adopts wav2vec2.0 and the fine-tuning stage employs an improved semi-supervised learning algorithm from slimIPL, which leverages unlabeled data progressively according to their pseudo labels' qualities. We also incorporate a temporal pseudo label pool and an exponential moving average to control the pseudo labels' update frequency and to avoid model divergence. Experimental results on Libri-Light and LibriSpeech datasets manifest our proposed method achieves better performance compared to existing approaches while being more unified.
Cross-lingual Self-Supervised Speech Representations for Improved Dysarthric Speech Recognition
Apr 04, 2022

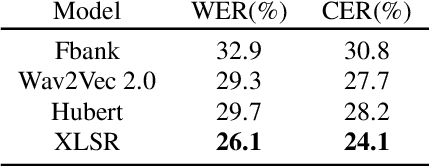
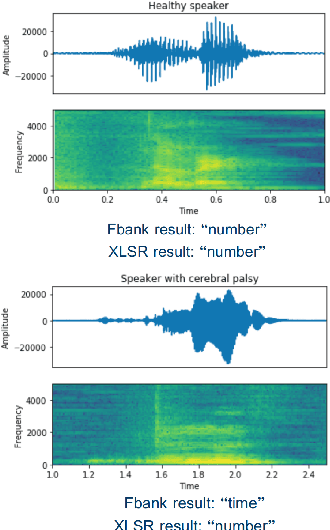
State-of-the-art automatic speech recognition (ASR) systems perform well on healthy speech. However, the performance on impaired speech still remains an issue. The current study explores the usefulness of using Wav2Vec self-supervised speech representations as features for training an ASR system for dysarthric speech. Dysarthric speech recognition is particularly difficult as several aspects of speech such as articulation, prosody and phonation can be impaired. Specifically, we train an acoustic model with features extracted from Wav2Vec, Hubert, and the cross-lingual XLSR model. Results suggest that speech representations pretrained on large unlabelled data can improve word error rate (WER) performance. In particular, features from the multilingual model led to lower WERs than filterbanks (Fbank) or models trained on a single language. Improvements were observed in English speakers with cerebral palsy caused dysarthria (UASpeech corpus), Spanish speakers with Parkinsonian dysarthria (PC-GITA corpus) and Italian speakers with paralysis-based dysarthria (EasyCall corpus). Compared to using Fbank features, XLSR-based features reduced WERs by 6.8%, 22.0%, and 7.0% for the UASpeech, PC-GITA, and EasyCall corpus, respectively.