 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Adversarial Attacks on Speech Recognition Systems for Mission-Critical Applications: A Survey
Feb 22, 2022
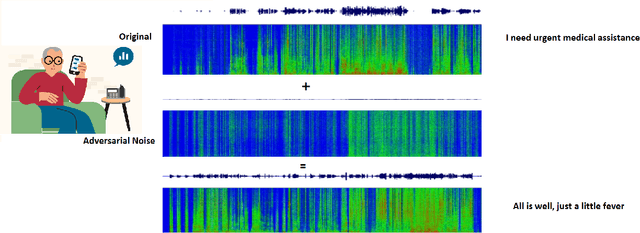
A Machine-Critical Application is a system that is fundamentally necessary to the success of specific and sensitive operations such as search and recovery, rescue, military, and emergency management actions. Recent advances in Machine Learning, Natural Language Processing, voice recognition, and speech processing technologies have naturally allowed the development and deployment of speech-based conversational interfaces to interact with various machine-critical applications. While these conversational interfaces have allowed users to give voice commands to carry out strategic and critical activities, their robustness to adversarial attacks remains uncertain and unclear. Indeed, Adversarial Artificial Intelligence (AI) which refers to a set of techniques that attempt to fool machine learning models with deceptive data, is a growing threat in the AI and machine learning research community, in particular for machine-critical applications. The most common reason of adversarial attacks is to cause a malfunction in a machine learning model. An adversarial attack might entail presenting a model with inaccurate or fabricated samples as it's training data, or introducing maliciously designed data to deceive an already trained model. While focusing on speech recognition for machine-critical applications, in this paper, we first review existing speech recognition techniques, then, we investigate the effectiveness of adversarial attacks and defenses against these systems, before outlining research challenges, defense recommendations, and future work. This paper is expected to serve researchers and practitioners as a reference to help them in understanding the challenges, position themselves and, ultimately, help them to improve existing models of speech recognition for mission-critical applications. Keywords: Mission-Critical Applications, Adversarial AI, Speech Recognition Systems.
Multi-stage Progressive Compression of Conformer Transducer for On-device Speech Recognition
Oct 01, 2022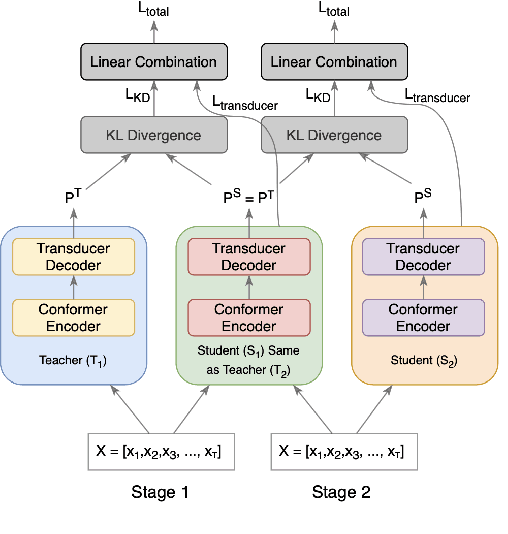
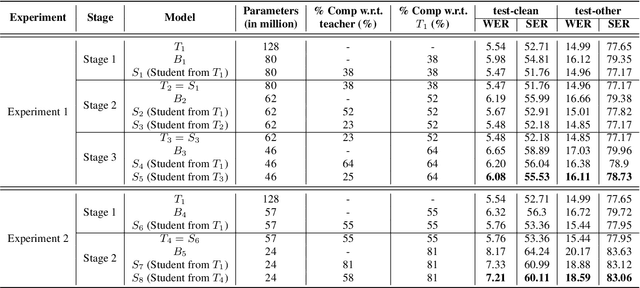
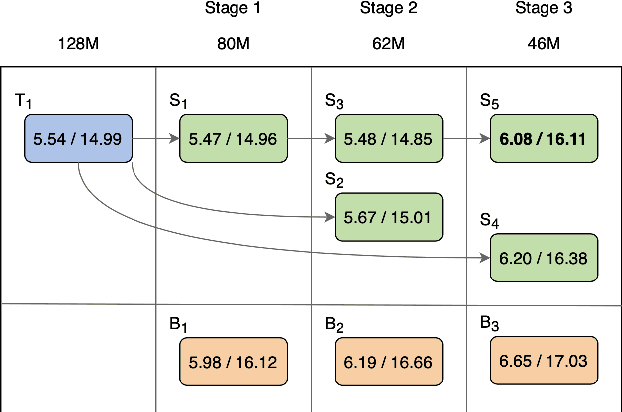
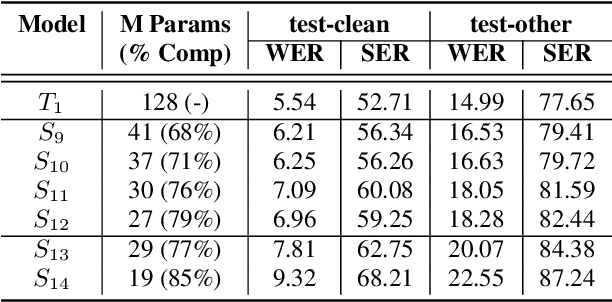
The smaller memory bandwidth in smart devices prompts development of smaller Automatic Speech Recognition (ASR) models. To obtain a smaller model, one can employ the model compression techniques. Knowledge distillation (KD) is a popular model compression approach that has shown to achieve smaller model size with relatively lesser degradation in the model performance. In this approach, knowledge is distilled from a trained large size teacher model to a smaller size student model. Also, the transducer based models have recently shown to perform well for on-device streaming ASR task, while the conformer models are efficient in handling long term dependencies. Hence in this work we employ a streaming transducer architecture with conformer as the encoder. We propose a multi-stage progressive approach to compress the conformer transducer model using KD. We progressively update our teacher model with the distilled student model in a multi-stage setup. On standard LibriSpeech dataset, our experimental results have successfully achieved compression rates greater than 60% without significant degradation in the performance compared to the larger teacher model.
* Published in INTERSPEECH 2022
Robust Self-Supervised Audio-Visual Speech Recognition
Jan 05, 2022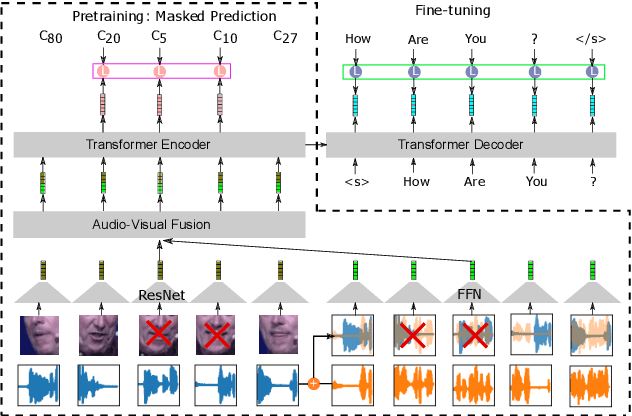

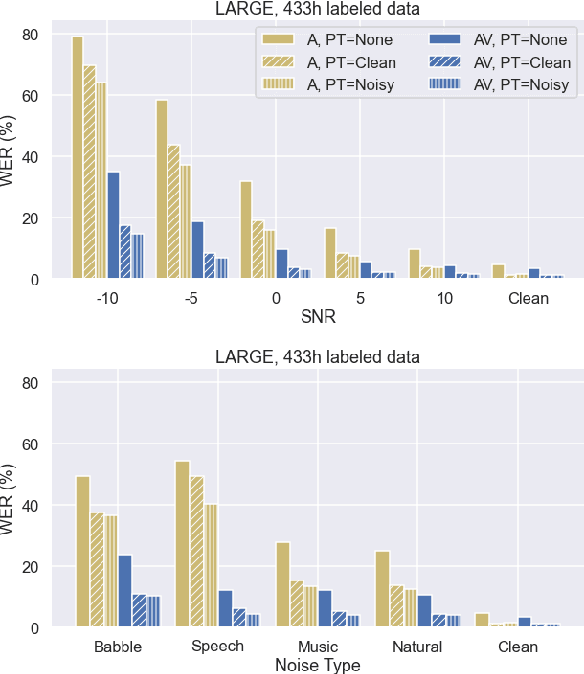
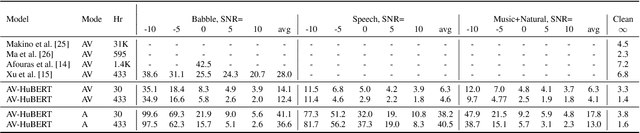
Audio-based automatic speech recognition (ASR) degrades significantly in noisy environments and is particularly vulnerable to interfering speech, as the model cannot determine which speaker to transcribe. Audio-visual speech recognition (AVSR) systems improve robustness by complementing the audio stream with the visual information that is invariant to noise and helps the model focus on the desired speaker. However, previous AVSR work focused solely on the supervised learning setup; hence the progress was hindered by the amount of labeled data available. In this work, we present a self-supervised AVSR framework built upon Audio-Visual HuBERT (AV-HuBERT), a state-of-the-art audio-visual speech representation learning model. On the largest available AVSR benchmark dataset LRS3, our approach outperforms prior state-of-the-art by ~50% (28.0% vs. 14.1%) using less than 10% of labeled data (433hr vs. 30hr) in the presence of babble noise, while reducing the WER of an audio-based model by over 75% (25.8% vs. 5.8%) on average.
Adaptive multilingual speech recognition with pretrained models
May 24, 2022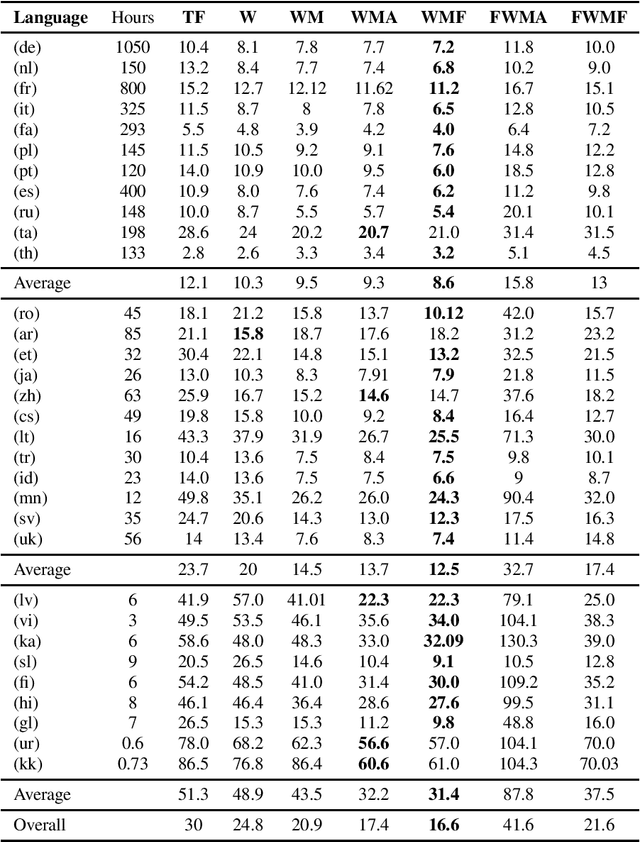
Multilingual speech recognition with supervised learning has achieved great results as reflected in recent research. With the development of pretraining methods on audio and text data, it is imperative to transfer the knowledge from unsupervised multilingual models to facilitate recognition, especially in many languages with limited data. Our work investigated the effectiveness of using two pretrained models for two modalities: wav2vec 2.0 for audio and MBART50 for text, together with the adaptive weight techniques to massively improve the recognition quality on the public datasets containing CommonVoice and Europarl. Overall, we noticed an 44% improvement over purely supervised learning, and more importantly, each technique provides a different reinforcement in different languages. We also explore other possibilities to potentially obtain the best model by slightly adding either depth or relative attention to the architecture.
Similarity and Content-based Phonetic Self Attention for Speech Recognition
Mar 28, 2022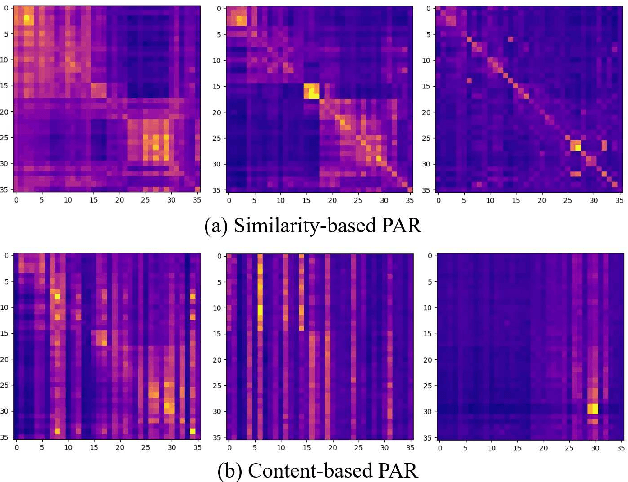
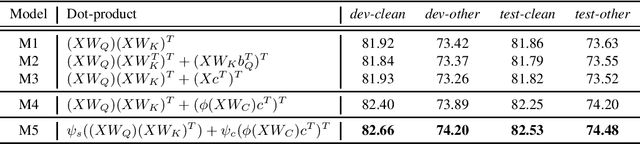
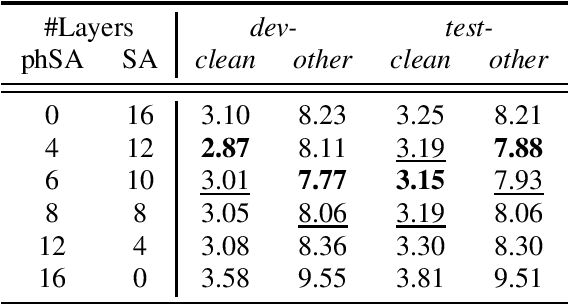
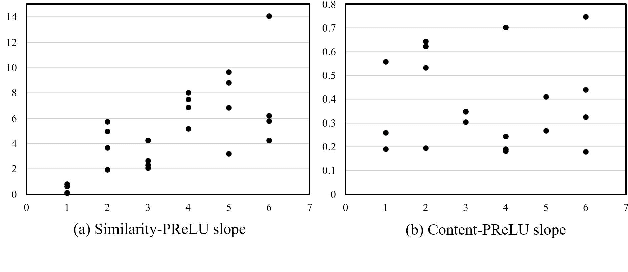
Transformer-based speech recognition models have achieved great success due to the self-attention (SA) mechanism that utilizes every frame in the feature extraction process. Especially, SA heads in lower layers capture various phonetic characteristics by the query-key dot product, which is designed to compute the pairwise relationship between frames. In this paper, we propose a variant of SA to extract more representative phonetic features. The proposed phonetic self-attention (phSA) is composed of two different types of phonetic attention; one is similarity-based and the other is content-based. In short, similarity-based attention utilizes the correlation between frames while content-based attention only considers each frame without being affected by others. We identify which parts of the original dot product are related to two different attention patterns and improve each part by simple modifications. Our experiments on phoneme classification and speech recognition show that replacing SA with phSA for lower layers improves the recognition performance without increasing the latency and the parameter size.
Mandarin-English Code-switching Speech Recognition with Self-supervised Speech Representation Models
Oct 07, 2021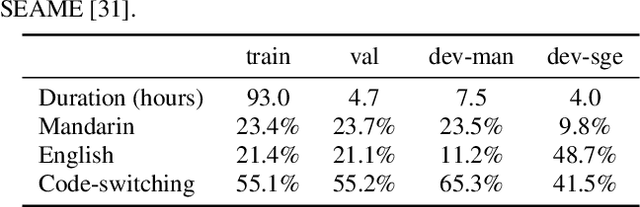
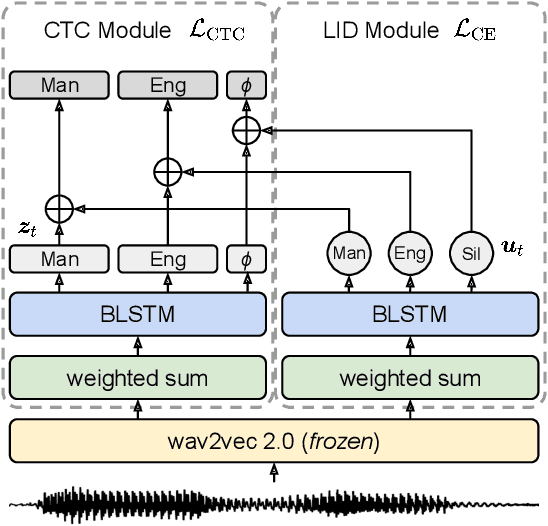
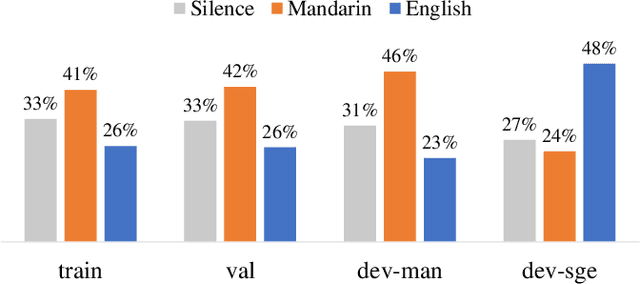
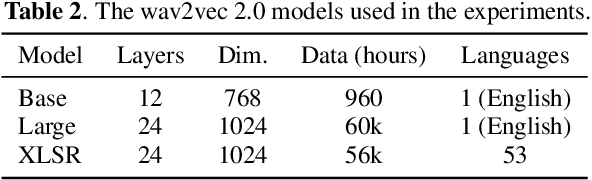
Code-switching (CS) is common in daily conversations where more than one language is used within a sentence. The difficulties of CS speech recognition lie in alternating languages and the lack of transcribed data. Therefore, this paper uses the recently successful self-supervised learning (SSL) methods to leverage many unlabeled speech data without CS. We show that hidden representations of SSL models offer frame-level language identity even if the models are trained with English speech only. Jointly training CTC and language identification modules with self-supervised speech representations improves CS speech recognition performance. Furthermore, using multilingual speech data for pre-training obtains the best CS speech recognition.
Graph Neural Networks for Contextual ASR with the Tree-Constrained Pointer Generator
May 30, 2023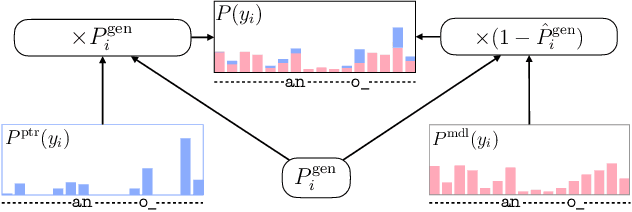
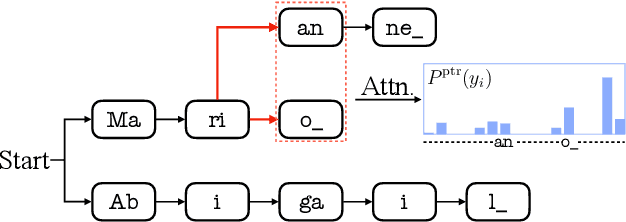

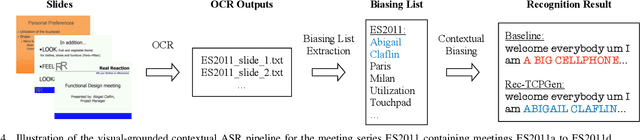
The incorporation of biasing words obtained through contextual knowledge is of paramount importance in automatic speech recognition (ASR) applications. This paper proposes an innovative method for achieving end-to-end contextual ASR using graph neural network (GNN) encodings based on the tree-constrained pointer generator method. GNN node encodings facilitate lookahead for future word pieces in the process of ASR decoding at each tree node by incorporating information about all word pieces on the tree branches rooted from it. This results in a more precise prediction of the generation probability of the biasing words. The study explores three GNN encoding techniques, namely tree recursive neural networks, graph convolutional network (GCN), and GraphSAGE, along with different combinations of the complementary GCN and GraphSAGE structures. The performance of the systems was evaluated using the Librispeech and AMI corpus, following the visual-grounded contextual ASR pipeline. The findings indicate that using GNN encodings achieved consistent and significant reductions in word error rate (WER), particularly for words that are rare or have not been seen during the training process. Notably, the most effective combination of GNN encodings obtained more than 60% WER reduction for rare and unseen words compared to standard end-to-end systems.
Pseudo-Labeling for Massively Multilingual Speech Recognition
Oct 30, 2021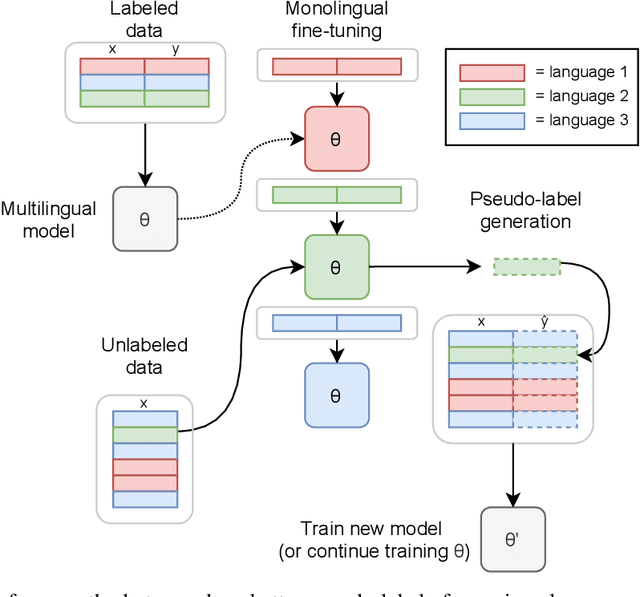
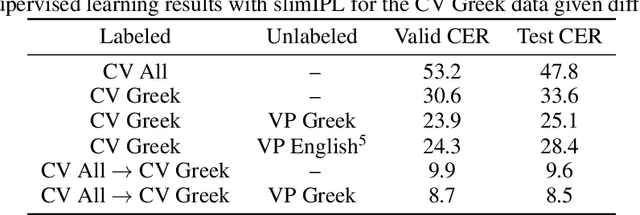
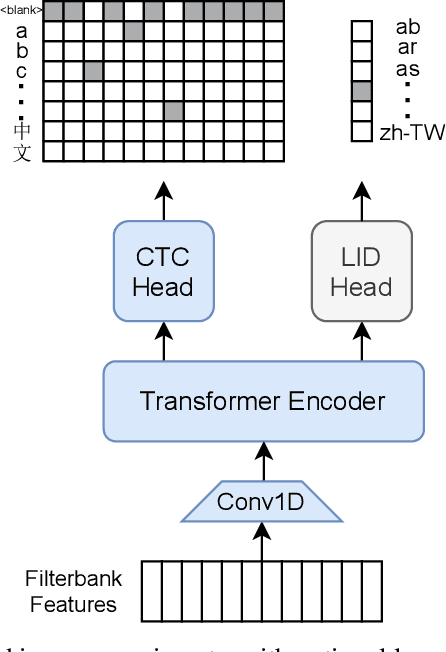
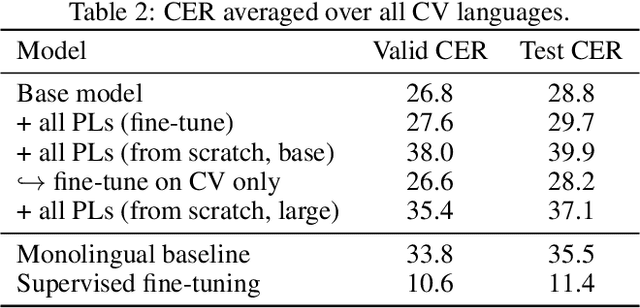
Semi-supervised learning through pseudo-labeling has become a staple of state-of-the-art monolingual speech recognition systems. In this work, we extend pseudo-labeling to massively multilingual speech recognition with 60 languages. We propose a simple pseudo-labeling recipe that works well even with low-resource languages: train a supervised multilingual model, fine-tune it with semi-supervised learning on a target language, generate pseudo-labels for that language, and train a final model using pseudo-labels for all languages, either from scratch or by fine-tuning. Experiments on the labeled Common Voice and unlabeled VoxPopuli datasets show that our recipe can yield a model with better performance for many languages that also transfers well to LibriSpeech.
Four-in-One: A Joint Approach to Inverse Text Normalization, Punctuation, Capitalization, and Disfluency for Automatic Speech Recognition
Oct 26, 2022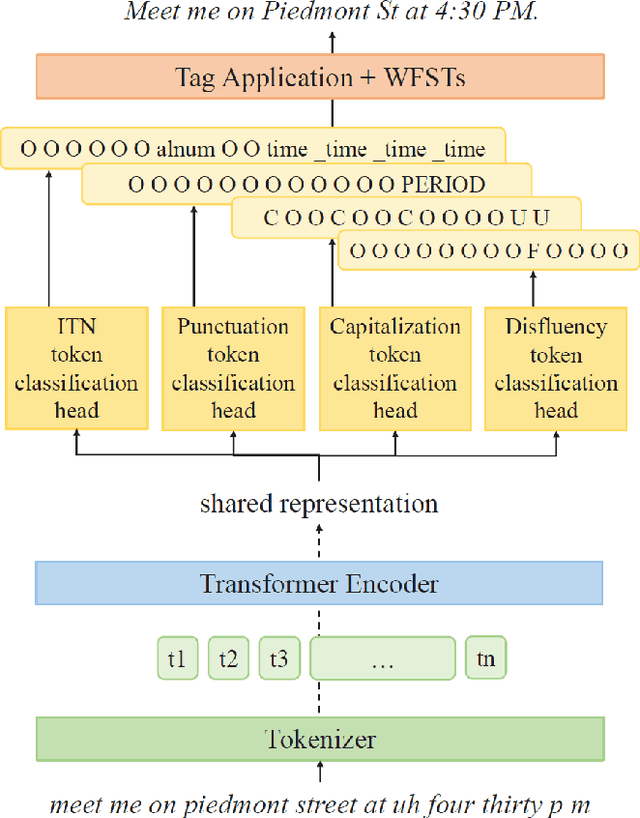
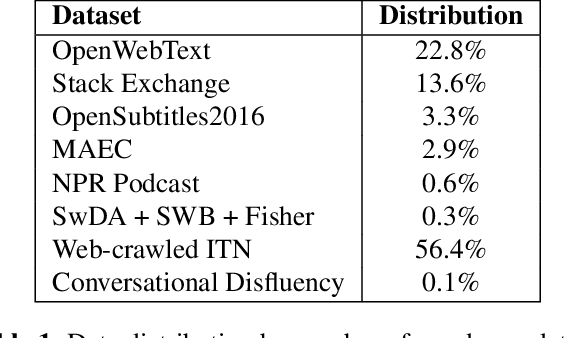
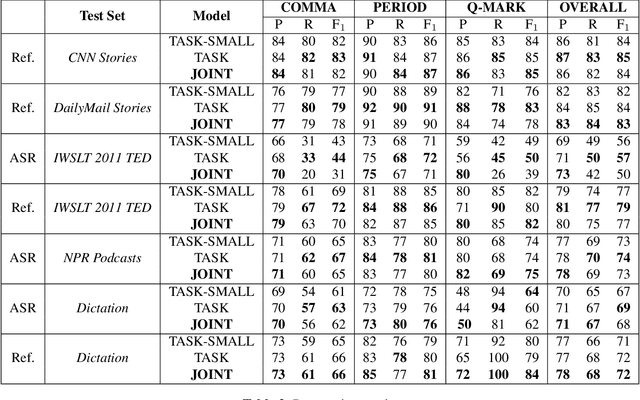
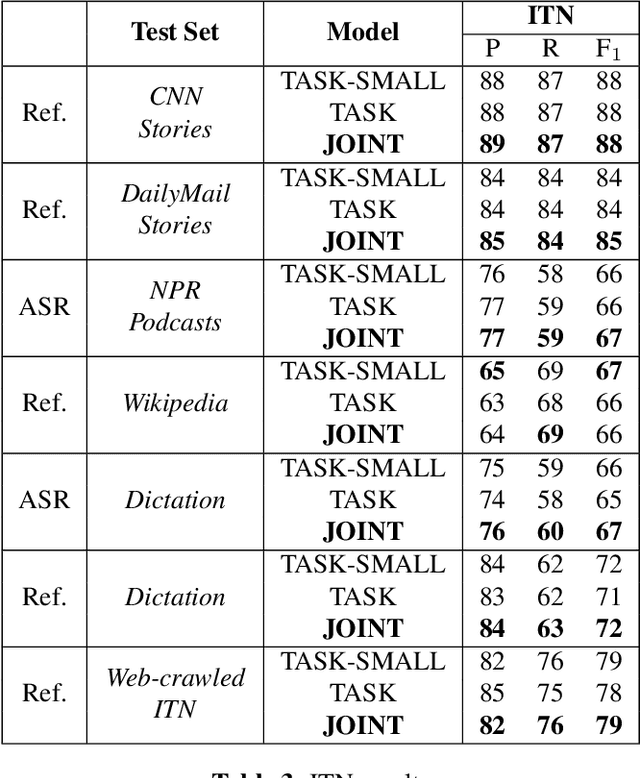
Features such as punctuation, capitalization, and formatting of entities are important for readability, understanding, and natural language processing tasks. However, Automatic Speech Recognition (ASR) systems produce spoken-form text devoid of formatting, and tagging approaches to formatting address just one or two features at a time. In this paper, we unify spoken-to-written text conversion via a two-stage process: First, we use a single transformer tagging model to jointly produce token-level tags for inverse text normalization (ITN), punctuation, capitalization, and disfluencies. Then, we apply the tags to generate written-form text and use weighted finite state transducer (WFST) grammars to format tagged ITN entity spans. Despite joining four models into one, our unified tagging approach matches or outperforms task-specific models across all four tasks on benchmark test sets across several domains.
Analysis of Self-Attention Head Diversity for Conformer-based Automatic Speech Recognition
Sep 13, 2022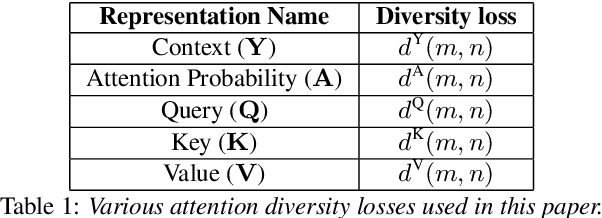
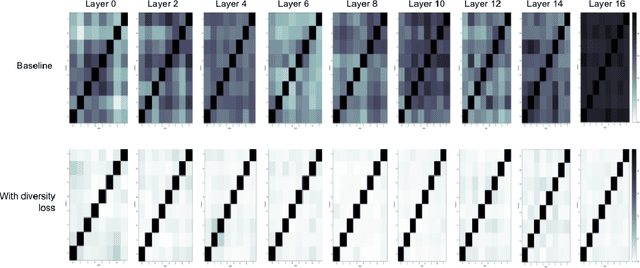
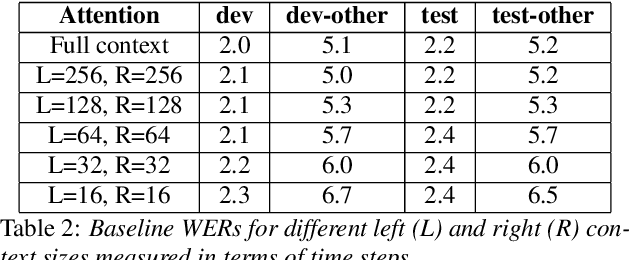
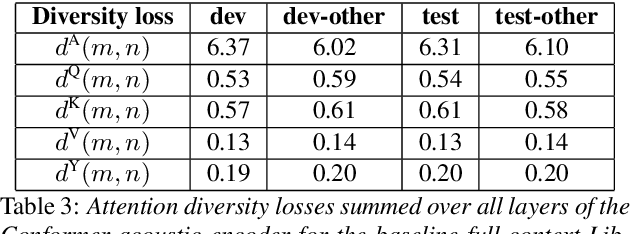
Attention layers are an integral part of modern end-to-end automatic speech recognition systems, for instance as part of the Transformer or Conformer architecture. Attention is typically multi-headed, where each head has an independent set of learned parameters and operates on the same input feature sequence. The output of multi-headed attention is a fusion of the outputs from the individual heads. We empirically analyze the diversity between representations produced by the different attention heads and demonstrate that the heads become highly correlated during the course of training. We investigate a few approaches to increasing attention head diversity, including using different attention mechanisms for each head and auxiliary training loss functions to promote head diversity. We show that introducing diversity-promoting auxiliary loss functions during training is a more effective approach, and obtain WER improvements of up to 6% relative on the Librispeech corpus. Finally, we draw a connection between the diversity of attention heads and the similarity of the gradients of head parameters.