 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
A Study on the Integration of Pipeline and E2E SLU systems for Spoken Semantic Parsing toward STOP Quality Challenge
May 02, 2023
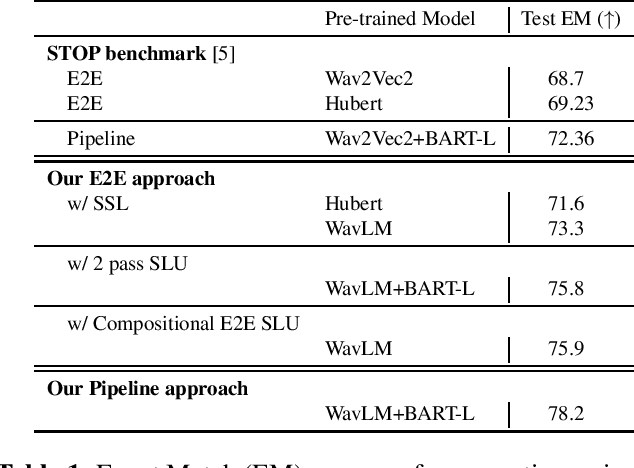

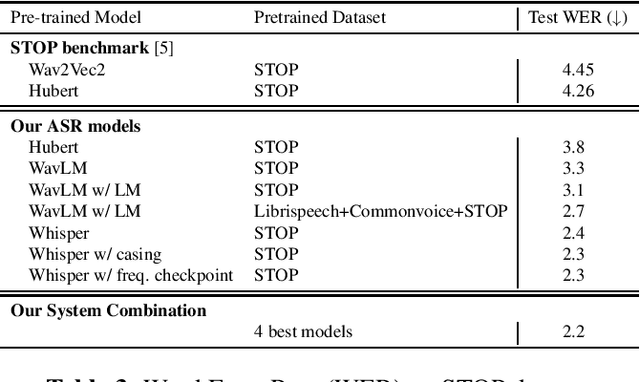
Recently there have been efforts to introduce new benchmark tasks for spoken language understanding (SLU), like semantic parsing. In this paper, we describe our proposed spoken semantic parsing system for the quality track (Track 1) in Spoken Language Understanding Grand Challenge which is part of ICASSP Signal Processing Grand Challenge 2023. We experiment with both end-to-end and pipeline systems for this task. Strong automatic speech recognition (ASR) models like Whisper and pretrained Language models (LM) like BART are utilized inside our SLU framework to boost performance. We also investigate the output level combination of various models to get an exact match accuracy of 80.8, which won the 1st place at the challenge.
Critical Appraisal of Artificial Intelligence-Mediated Communication
May 15, 2023Over the last two decades, technology use in language learning and teaching has significantly advanced and is now referred to as Computer-Assisted Language Learning (CALL). Recently, the integration of Artificial Intelligence (AI) into CALL has brought about a significant shift in the traditional approach to language education both inside and outside the classroom. In line with this book's scope, I explore the advantages and disadvantages of AI-mediated communication in language education. I begin with a brief review of AI in education. I then introduce the ICALL and give a critical appraisal of the potential of AI-powered automatic speech recognition (ASR), Machine Translation (MT), Intelligent Tutoring Systems (ITSs), AI-powered chatbots, and Extended Reality (XR). In conclusion, I argue that it is crucial for language teachers to engage in CALL teacher education and professional development to keep up with the ever-evolving technology landscape and improve their teaching effectiveness.
Conformers are All You Need for Visual Speech Recogntion
Feb 17, 2023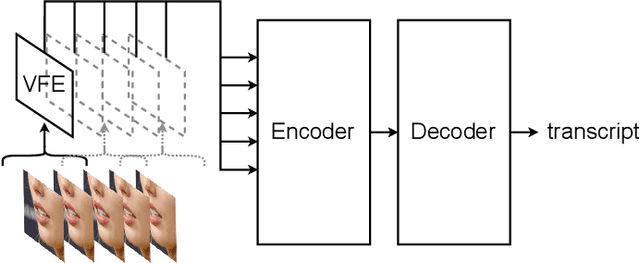

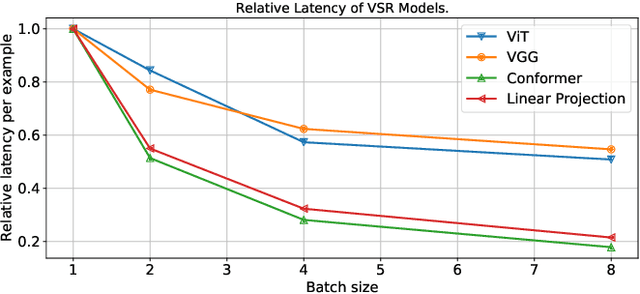
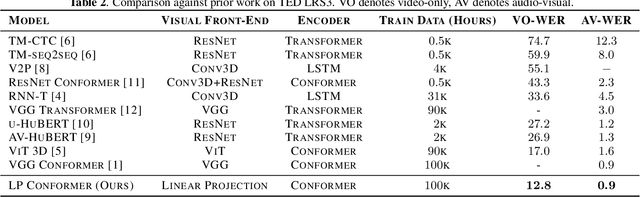
Visual speech recognition models extract visual features in a hierarchical manner. At the lower level, there is a visual front-end with a limited temporal receptive field that processes the raw pixels depicting the lips or faces. At the higher level, there is an encoder that attends to the embeddings produced by the front-end over a large temporal receptive field. Previous work has focused on improving the visual front-end of the model to extract more useful features for speech recognition. Surprisingly, our work shows that complex visual front-ends are not necessary. Instead of allocating resources to a sophisticated visual front-end, we find that a linear visual front-end paired with a larger Conformer encoder results in lower latency, more efficient memory usage, and improved WER performance. We achieve a new state-of-the-art of $12.8\%$ WER for visual speech recognition on the TED LRS3 dataset, which rivals the performance of audio-only models from just four years ago.
Deep Speech Based End-to-End Automated Speech Recognition (ASR) for Indian-English Accents
Apr 03, 2022Automated Speech Recognition (ASR) is an interdisciplinary application of computer science and linguistics that enable us to derive the transcription from the uttered speech waveform. It finds several applications in Military like High-performance fighter aircraft, helicopters, air-traffic controller. Other than military speech recognition is used in healthcare, persons with disabilities and many more. ASR has been an active research area. Several models and algorithms for speech to text (STT) have been proposed. One of the most recent is Mozilla Deep Speech, it is based on the Deep Speech research paper by Baidu. Deep Speech is a state-of-art speech recognition system is developed using end-to-end deep learning, it is trained using well-optimized Recurrent Neural Network (RNN) training system utilizing multiple Graphical Processing Units (GPUs). This training is mostly done using American-English accent datasets, which results in poor generalizability to other English accents. India is a land of vast diversity. This can even be seen in the speech, there are several English accents which vary from state to state. In this work, we have used transfer learning approach using most recent Deep Speech model i.e., deepspeech-0.9.3 to develop an end-to-end speech recognition system for Indian-English accents. This work utilizes fine-tuning and data argumentation to further optimize and improve the Deep Speech ASR system. Indic TTS data of Indian-English accents is used for transfer learning and fine-tuning the pre-trained Deep Speech model. A general comparison is made among the untrained model, our trained model and other available speech recognition services for Indian-English Accents.
SE-Bridge: Speech Enhancement with Consistent Brownian Bridge
May 23, 2023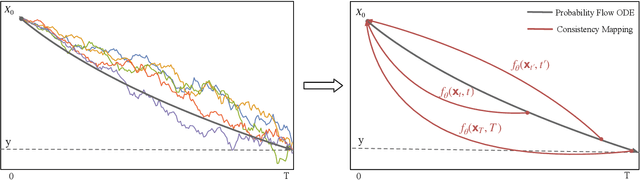
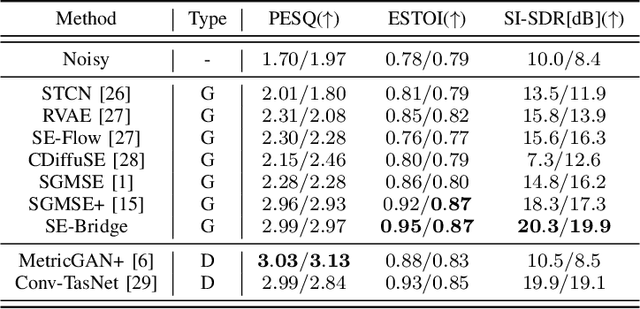
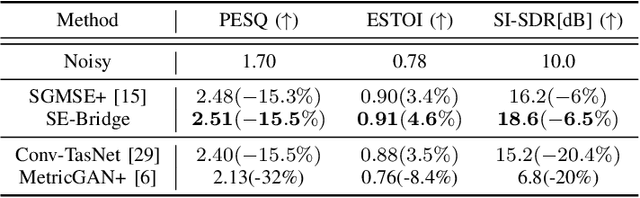
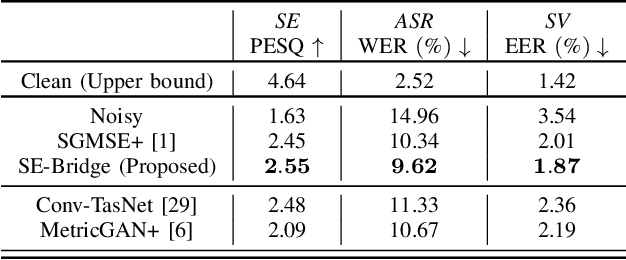
We propose SE-Bridge, a novel method for speech enhancement (SE). After recently applying the diffusion models to speech enhancement, we can achieve speech enhancement by solving a stochastic differential equation (SDE). Each SDE corresponds to a probabilistic flow ordinary differential equation (PF-ODE), and the trajectory of the PF-ODE solution consists of the speech states at different moments. Our approach is based on consistency model that ensure any speech states on the same PF-ODE trajectory, correspond to the same initial state. By integrating the Brownian Bridge process, the model is able to generate high-intelligibility speech samples without adversarial training. This is the first attempt that applies the consistency models to SE task, achieving state-of-the-art results in several metrics while saving 15 x the time required for sampling compared to the diffusion-based baseline. Our experiments on multiple datasets demonstrate the effectiveness of SE-Bridge in SE. Furthermore, we show through extensive experiments on downstream tasks, including Automatic Speech Recognition (ASR) and Speaker Verification (SV), that SE-Bridge can effectively support multiple downstream tasks.
Understanding Shared Speech-Text Representations
Apr 27, 2023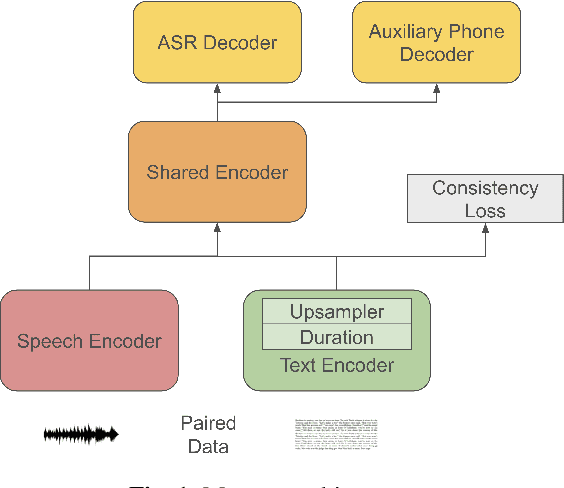
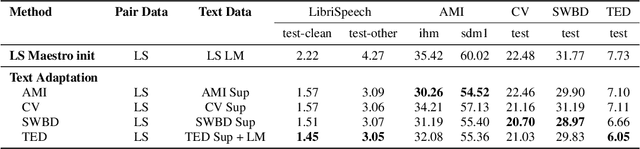

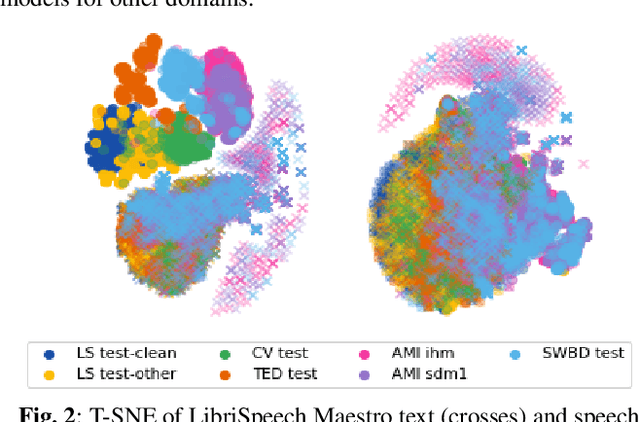
Recently, a number of approaches to train speech models by incorpo-rating text into end-to-end models have been developed, with Mae-stro advancing state-of-the-art automatic speech recognition (ASR)and Speech Translation (ST) performance. In this paper, we expandour understanding of the resulting shared speech-text representationswith two types of analyses. First we examine the limits of speech-free domain adaptation, finding that a corpus-specific duration modelfor speech-text alignment is the most important component for learn-ing a shared speech-text representation. Second, we inspect the sim-ilarities between activations of unimodal (speech or text) encodersas compared to the activations of a shared encoder. We find that theshared encoder learns a more compact and overlapping speech-textrepresentation than the uni-modal encoders. We hypothesize that thispartially explains the effectiveness of the Maestro shared speech-textrepresentations.
Adaptation and Optimization of Automatic Speech Recognition (ASR) for the Maritime Domain in the Field of VHF Communication
Jun 01, 2023This paper introduces a multilingual automatic speech recognizer (ASR) for maritime radio communi-cation that automatically converts received VHF radio signals into text. The challenges of maritime radio communication are described at first, and the deep learning architecture of marFM consisting of audio processing techniques and machine learning algorithms is presented. Subsequently, maritime radio data of interest is analyzed and then used to evaluate the transcription performance of our ASR model for various maritime radio data.
Performance Disparities Between Accents in Automatic Speech Recognition
Aug 01, 2022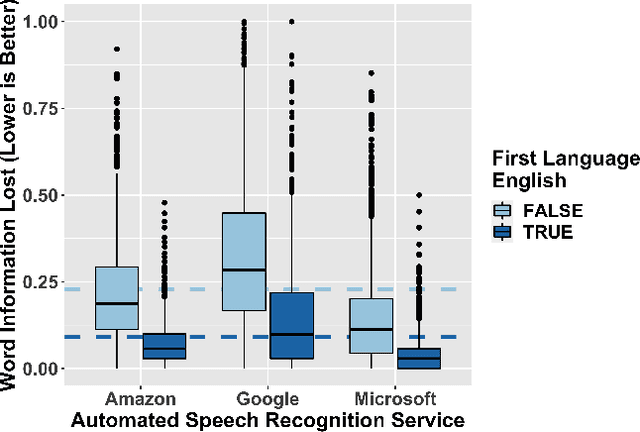
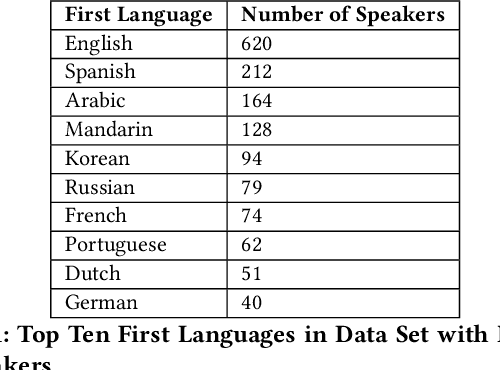
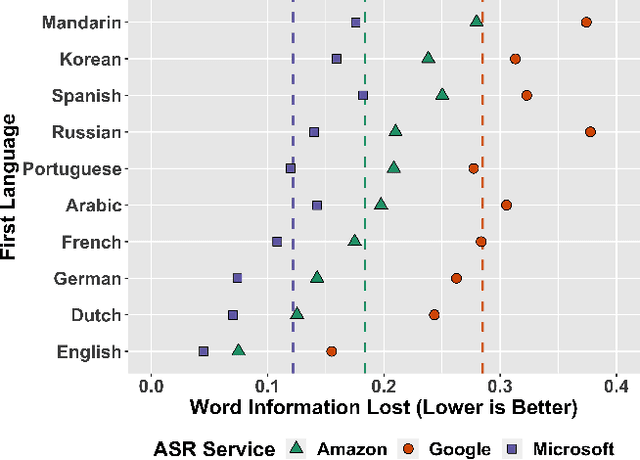
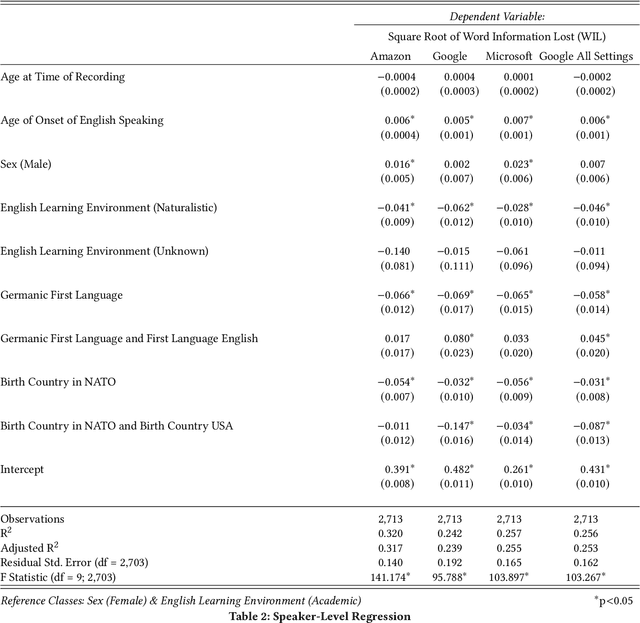
Automatic speech recognition (ASR) services are ubiquitous, transforming speech into text for systems like Amazon's Alexa, Google's Assistant, and Microsoft's Cortana. However, researchers have identified biases in ASR performance between particular English language accents by racial group and by nationality. In this paper, we expand this discussion both qualitatively by relating it to historical precedent and quantitatively through a large-scale audit. Standardization of language and the use of language to maintain global and political power have played an important role in history, which we explain to show the parallels in the ways in which ASR services act on English language speakers today. Then, using a large and global data set of speech from The Speech Accent Archive which includes over 2,700 speakers of English born in 171 different countries, we perform an international audit of some of the most popular English ASR services. We show that performance disparities exist as a function of whether or not a speaker's first language is English and, even when controlling for multiple linguistic covariates, that these disparities have a statistically significant relationship to the political alignment of the speaker's birth country with respect to the United States' geopolitical power.
End-to-end spoken language understanding using joint CTC loss and self-supervised, pretrained acoustic encoders
May 04, 2023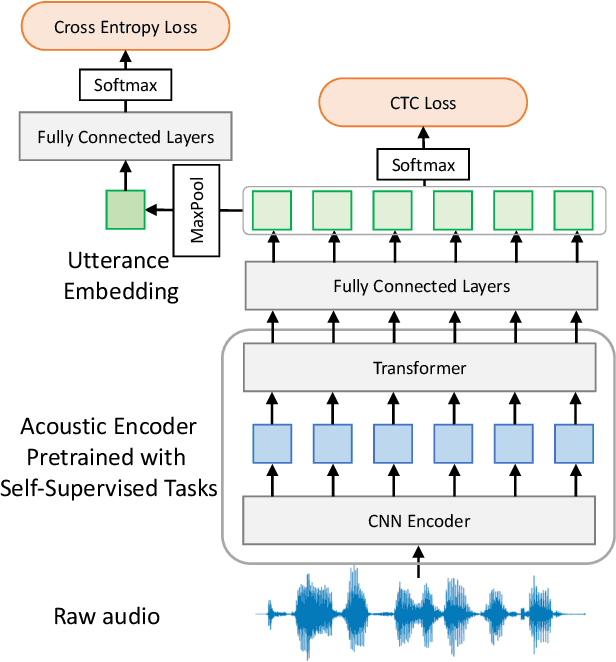
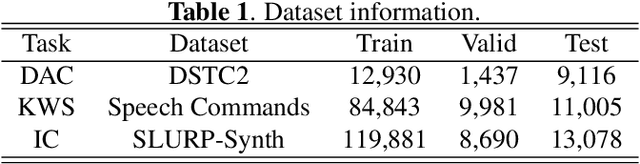


It is challenging to extract semantic meanings directly from audio signals in spoken language understanding (SLU), due to the lack of textual information. Popular end-to-end (E2E) SLU models utilize sequence-to-sequence automatic speech recognition (ASR) models to extract textual embeddings as input to infer semantics, which, however, require computationally expensive auto-regressive decoding. In this work, we leverage self-supervised acoustic encoders fine-tuned with Connectionist Temporal Classification (CTC) to extract textual embeddings and use joint CTC and SLU losses for utterance-level SLU tasks. Experiments show that our model achieves 4% absolute improvement over the the state-of-the-art (SOTA) dialogue act classification model on the DSTC2 dataset and 1.3% absolute improvement over the SOTA SLU model on the SLURP dataset.
Heterogeneous Reservoir Computing Models for Persian Speech Recognition
May 25, 2022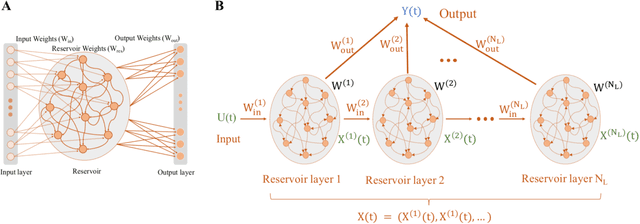
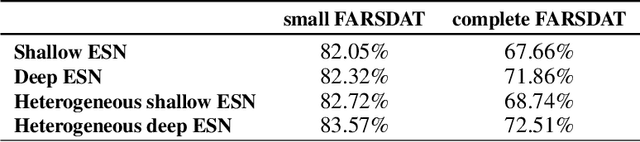
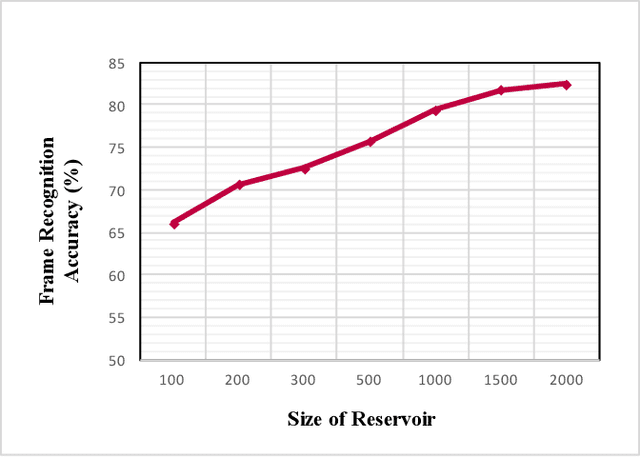
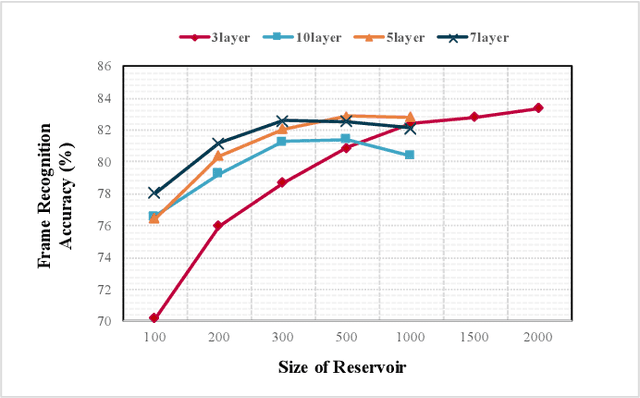
Over the last decade, deep-learning methods have been gradually incorporated into conventional automatic speech recognition (ASR) frameworks to create acoustic, pronunciation, and language models. Although it led to significant improvements in ASRs' recognition accuracy, due to their hard constraints related to hardware requirements (e.g., computing power and memory usage), it is unclear if such approaches are the most computationally- and energy-efficient options for embedded ASR applications. Reservoir computing (RC) models (e.g., echo state networks (ESNs) and liquid state machines (LSMs)), on the other hand, have been proven inexpensive to train, have vastly fewer parameters, and are compatible with emergent hardware technologies. However, their performance in speech processing tasks is relatively inferior to that of the deep-learning-based models. To enhance the accuracy of the RC in ASR applications, we propose heterogeneous single and multi-layer ESNs to create non-linear transformations of the inputs that capture temporal context at different scales. To test our models, we performed a speech recognition task on the Farsdat Persian dataset. Since, to the best of our knowledge, standard RC has not yet been employed to conduct any Persian ASR tasks, we also trained conventional single-layer and deep ESNs to provide baselines for comparison. Besides, we compared the RC performance with a standard long-short-term memory (LSTM) model. Heterogeneous RC models (1) show improved performance to the standard RC models; (2) perform on par in terms of recognition accuracy with the LSTM, and (3) reduce the training time considerably.