 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Extending RNN-T-based speech recognition systems with emotion and language classification
Jul 28, 2022
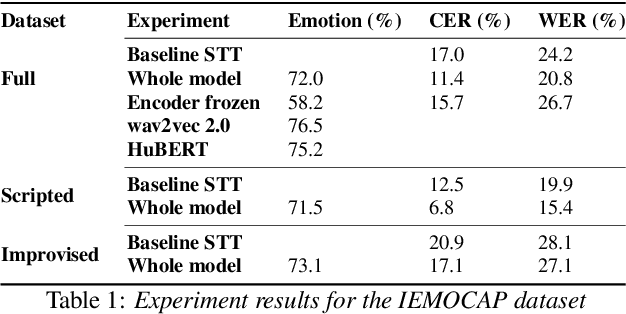
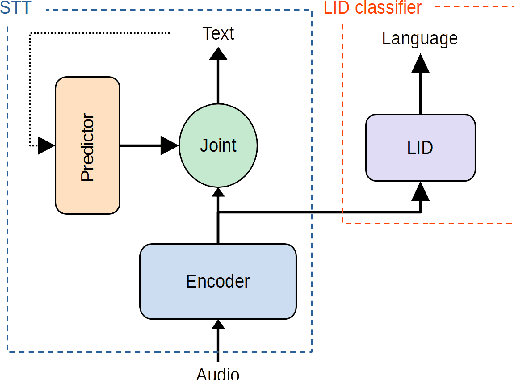
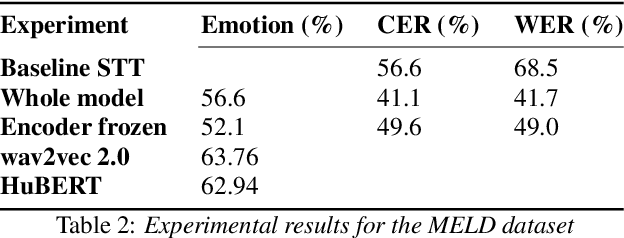
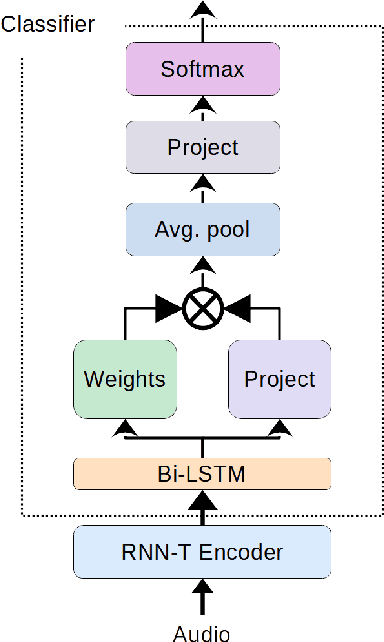
Speech transcription, emotion recognition, and language identification are usually considered to be three different tasks. Each one requires a different model with a different architecture and training process. We propose using a recurrent neural network transducer (RNN-T)-based speech-to-text (STT) system as a common component that can be used for emotion recognition and language identification as well as for speech recognition. Our work extends the STT system for emotion classification through minimal changes, and shows successful results on the IEMOCAP and MELD datasets. In addition, we demonstrate that by adding a lightweight component to the RNN-T module, it can also be used for language identification. In our evaluations, this new classifier demonstrates state-of-the-art accuracy for the NIST-LRE-07 dataset.
Machine Unlearning: A Survey
Jun 06, 2023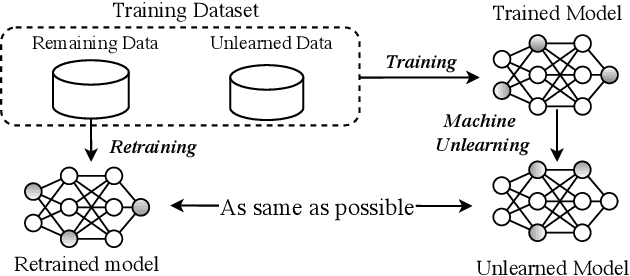
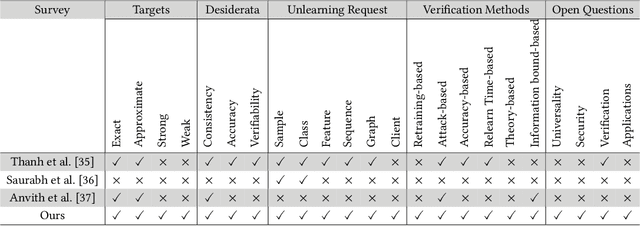
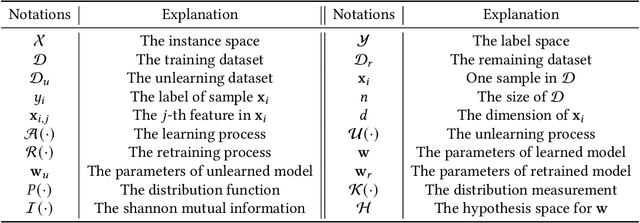
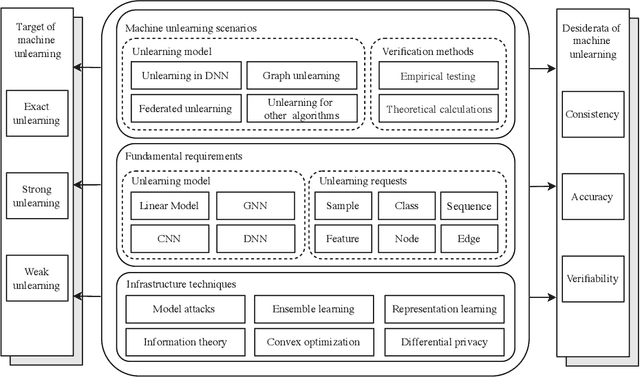
Machine learning has attracted widespread attention and evolved into an enabling technology for a wide range of highly successful applications, such as intelligent computer vision, speech recognition, medical diagnosis, and more. Yet a special need has arisen where, due to privacy, usability, and/or the right to be forgotten, information about some specific samples needs to be removed from a model, called machine unlearning. This emerging technology has drawn significant interest from both academics and industry due to its innovation and practicality. At the same time, this ambitious problem has led to numerous research efforts aimed at confronting its challenges. To the best of our knowledge, no study has analyzed this complex topic or compared the feasibility of existing unlearning solutions in different kinds of scenarios. Accordingly, with this survey, we aim to capture the key concepts of unlearning techniques. The existing solutions are classified and summarized based on their characteristics within an up-to-date and comprehensive review of each category's advantages and limitations. The survey concludes by highlighting some of the outstanding issues with unlearning techniques, along with some feasible directions for new research opportunities.
FonMTL: Towards Multitask Learning for the Fon Language
Aug 28, 2023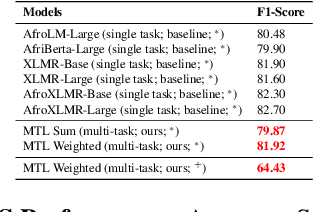
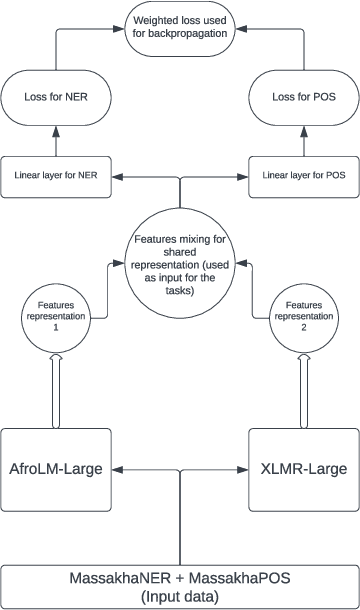
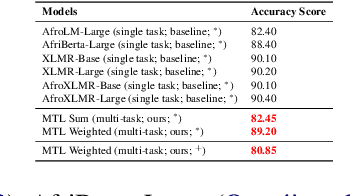
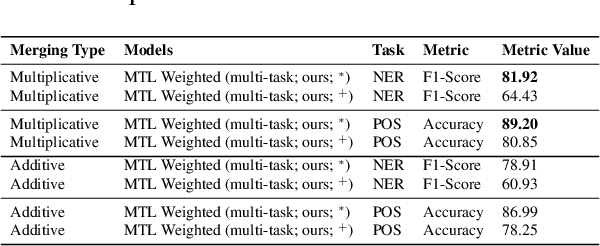
The Fon language, spoken by an average 2 million of people, is a truly low-resourced African language, with a limited online presence, and existing datasets (just to name but a few). Multitask learning is a learning paradigm that aims to improve the generalization capacity of a model by sharing knowledge across different but related tasks: this could be prevalent in very data-scarce scenarios. In this paper, we present the first explorative approach to multitask learning, for model capabilities enhancement in Natural Language Processing for the Fon language. Specifically, we explore the tasks of Named Entity Recognition (NER) and Part of Speech Tagging (POS) for Fon. We leverage two language model heads as encoders to build shared representations for the inputs, and we use linear layers blocks for classification relative to each task. Our results on the NER and POS tasks for Fon, show competitive (or better) performances compared to several multilingual pretrained language models finetuned on single tasks. Additionally, we perform a few ablation studies to leverage the efficiency of two different loss combination strategies and find out that the equal loss weighting approach works best in our case. Our code is open-sourced at https://github.com/bonaventuredossou/multitask_fon.
Leveraging Domain Features for Detecting Adversarial Attacks Against Deep Speech Recognition in Noise
Nov 03, 2022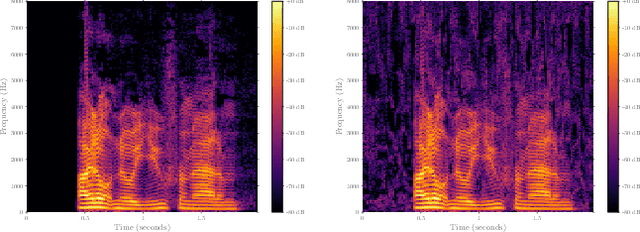
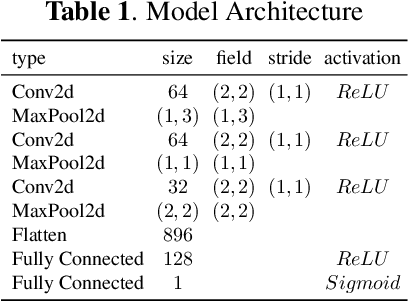
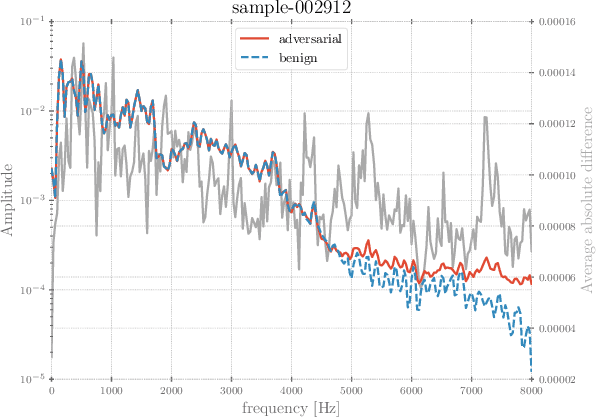
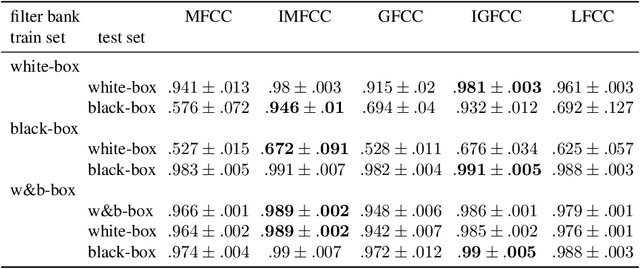
In recent years, significant progress has been made in deep model-based automatic speech recognition (ASR), leading to its widespread deployment in the real world. At the same time, adversarial attacks against deep ASR systems are highly successful. Various methods have been proposed to defend ASR systems from these attacks. However, existing classification based methods focus on the design of deep learning models while lacking exploration of domain specific features. This work leverages filter bank-based features to better capture the characteristics of attacks for improved detection. Furthermore, the paper analyses the potentials of using speech and non-speech parts separately in detecting adversarial attacks. In the end, considering adverse environments where ASR systems may be deployed, we study the impact of acoustic noise of various types and signal-to-noise ratios. Extensive experiments show that the inverse filter bank features generally perform better in both clean and noisy environments, the detection is effective using either speech or non-speech part, and the acoustic noise can largely degrade the detection performance.
pMCT: Patched Multi-Condition Training for Robust Speech Recognition
Jul 11, 2022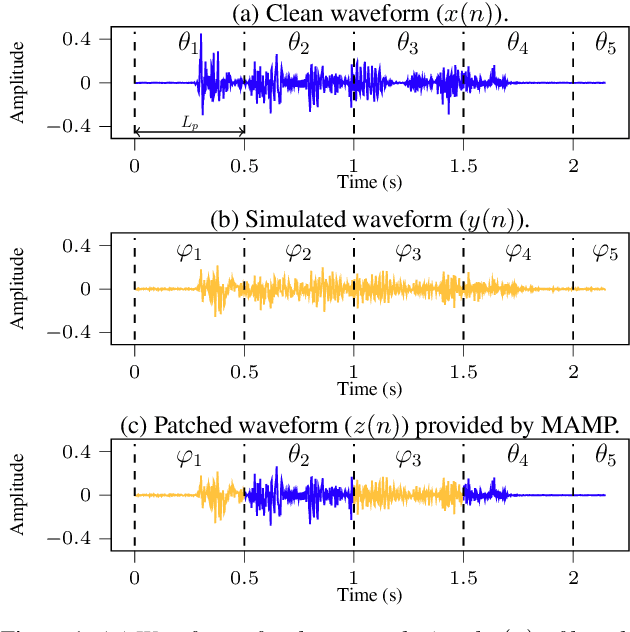
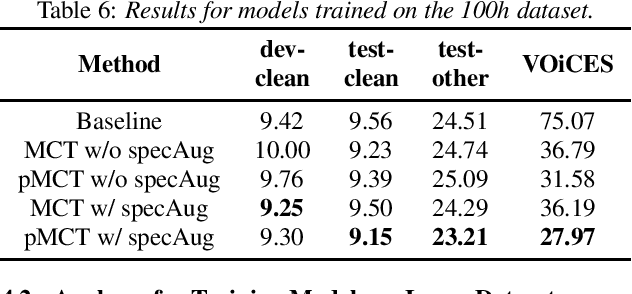
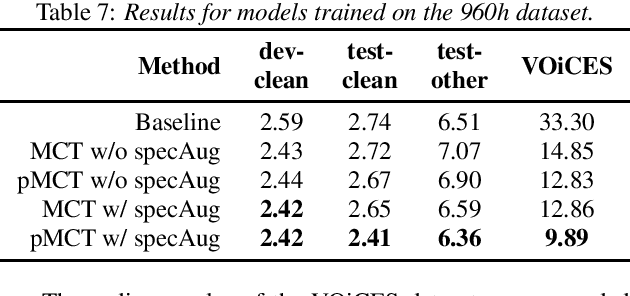
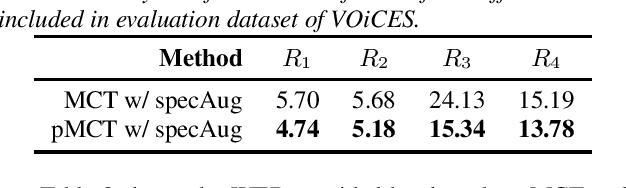
We propose a novel Patched Multi-Condition Training (pMCT) method for robust Automatic Speech Recognition (ASR). pMCT employs Multi-condition Audio Modification and Patching (MAMP) via mixing {\it patches} of the same utterance extracted from clean and distorted speech. Training using patch-modified signals improves robustness of models in noisy reverberant scenarios. Our proposed pMCT is evaluated on the LibriSpeech dataset showing improvement over using vanilla Multi-Condition Training (MCT). For analyses on robust ASR, we employed pMCT on the VOiCES dataset which is a noisy reverberant dataset created using utterances from LibriSpeech. In the analyses, pMCT achieves 23.1% relative WER reduction compared to the MCT.
Robustness of Multi-Source MT to Transcription Errors
May 26, 2023
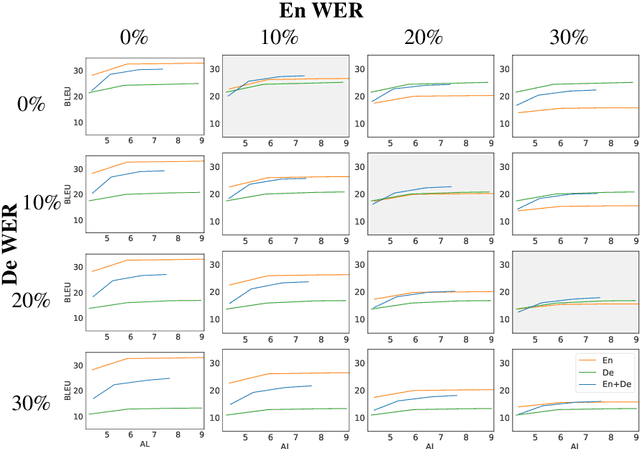

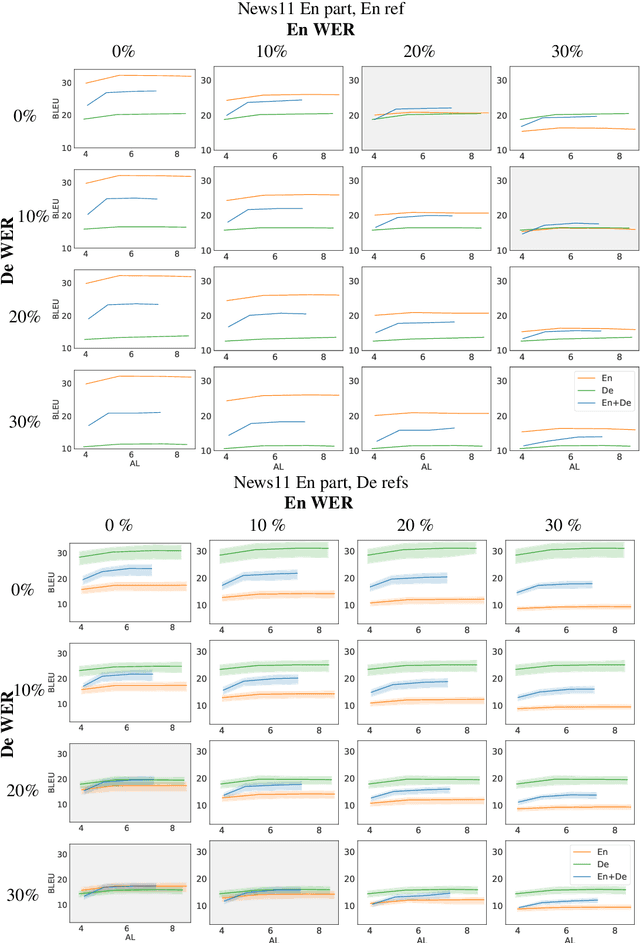
Automatic speech translation is sensitive to speech recognition errors, but in a multilingual scenario, the same content may be available in various languages via simultaneous interpreting, dubbing or subtitling. In this paper, we hypothesize that leveraging multiple sources will improve translation quality if the sources complement one another in terms of correct information they contain. To this end, we first show that on a 10-hour ESIC corpus, the ASR errors in the original English speech and its simultaneous interpreting into German and Czech are mutually independent. We then use two sources, English and German, in a multi-source setting for translation into Czech to establish its robustness to ASR errors. Furthermore, we observe this robustness when translating both noisy sources together in a simultaneous translation setting. Our results show that multi-source neural machine translation has the potential to be useful in a real-time simultaneous translation setting, thereby motivating further investigation in this area.
HMM vs. CTC for Automatic Speech Recognition: Comparison Based on Full-Sum Training from Scratch
Oct 18, 2022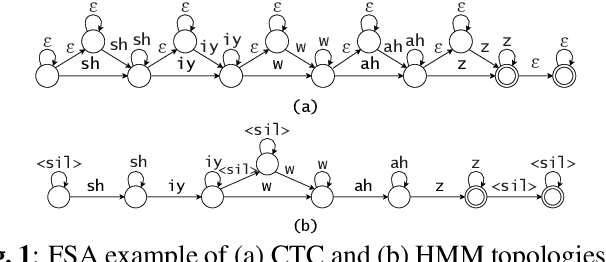
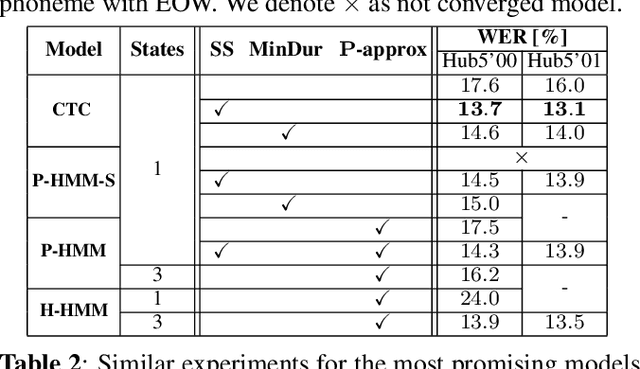
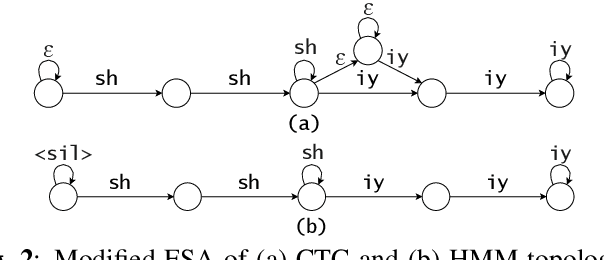
In this work, we compare from-scratch sequence-level cross-entropy (full-sum) training of Hidden Markov Model (HMM) and Connectionist Temporal Classification (CTC) topologies for automatic speech recognition (ASR). Besides accuracy, we further analyze their capability for generating high-quality time alignment between the speech signal and the transcription, which can be crucial for many subsequent applications. Moreover, we propose several methods to improve convergence of from-scratch full-sum training by addressing the alignment modeling issue. Systematic comparison is conducted on both Switchboard and LibriSpeech corpora across CTC, posterior HMM with and w/o transition probabilities, and standard hybrid HMM. We also provide a detailed analysis of both Viterbi forced-alignment and Baum-Welch full-sum occupation probabilities.
The Far Side of Failure: Investigating the Impact of Speech Recognition Errors on Subsequent Dementia Classification
Nov 11, 2022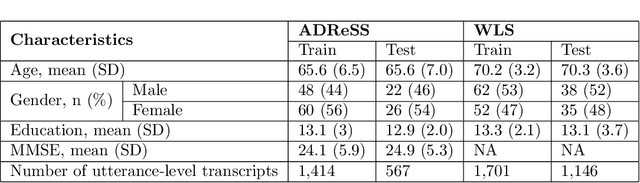
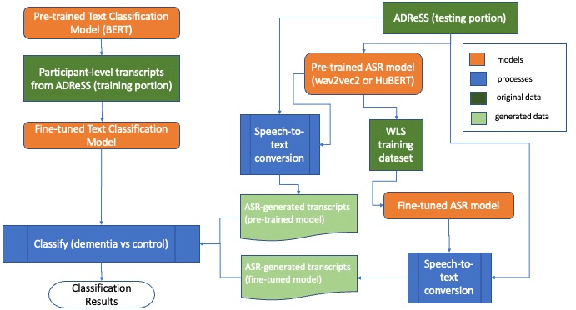
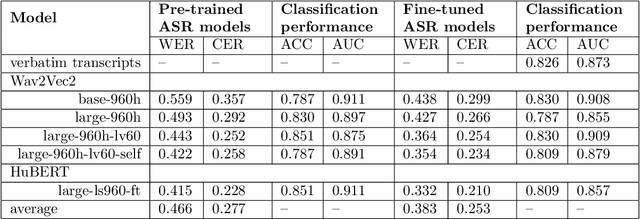
Linguistic anomalies detectable in spontaneous speech have shown promise for various clinical applications including screening for dementia and other forms of cognitive impairment. The feasibility of deploying automated tools that can classify language samples obtained from speech in large-scale clinical settings depends on the ability to capture and automatically transcribe the speech for subsequent analysis. However, the impressive performance of self-supervised learning (SSL) automatic speech recognition (ASR) models with curated speech data is not apparent with challenging speech samples from clinical settings. One of the key questions for successfully applying ASR models for clinical applications is whether imperfect transcripts they generate provide sufficient information for downstream tasks to operate at an acceptable level of accuracy. In this study, we examine the relationship between the errors produced by several deep learning ASR systems and their impact on the downstream task of dementia classification. One of our key findings is that, paradoxically, ASR systems with relatively high error rates can produce transcripts that result in better downstream classification accuracy than classification based on verbatim transcripts.
Applying wav2vec2 for Speech Recognition on Bengali Common Voices Dataset
Sep 11, 2022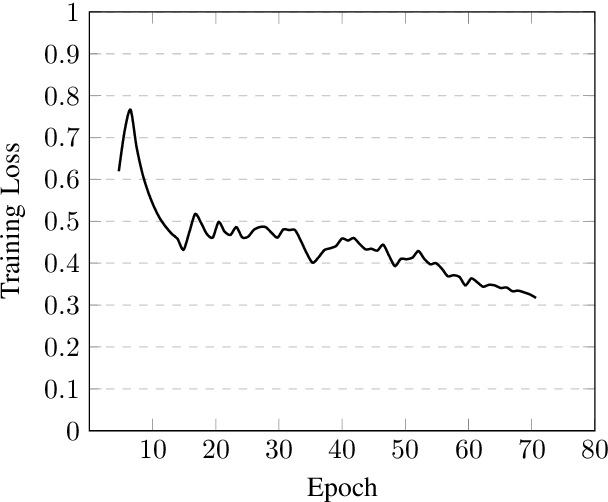
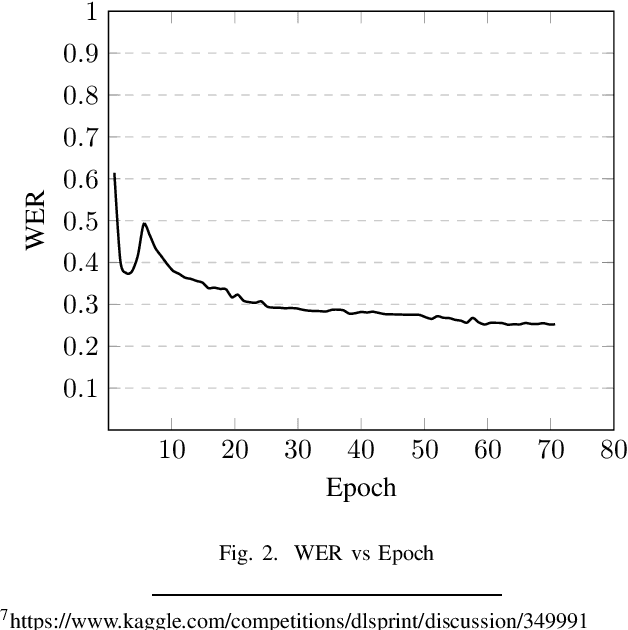

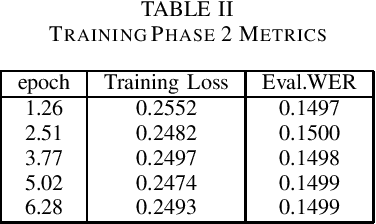
Speech is inherently continuous, where discrete words, phonemes and other units are not clearly segmented, and so speech recognition has been an active research problem for decades. In this work we have fine-tuned wav2vec 2.0 to recognize and transcribe Bengali speech -- training it on the Bengali Common Voice Speech Dataset. After training for 71 epochs, on a training set consisting of 36919 mp3 files, we achieved a training loss of 0.3172 and WER of 0.2524 on a validation set of size 7,747. Using a 5-gram language model, the Levenshtein Distance was 2.6446 on a test set of size 7,747. Then the training set and validation set were combined, shuffled and split into 85-15 ratio. Training for 7 more epochs on this combined dataset yielded an improved Levenshtein Distance of 2.60753 on the test set. Our model was the best performing one, achieving a Levenshtein Distance of 6.234 on a hidden dataset, which was 1.1049 units lower than other competing submissions.
Approximate Nearest Neighbour Phrase Mining for Contextual Speech Recognition
Apr 18, 2023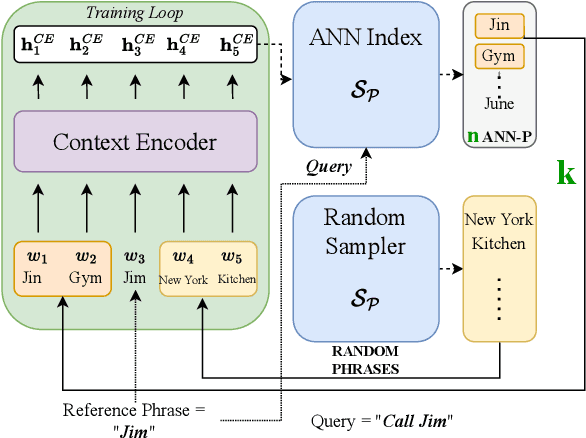
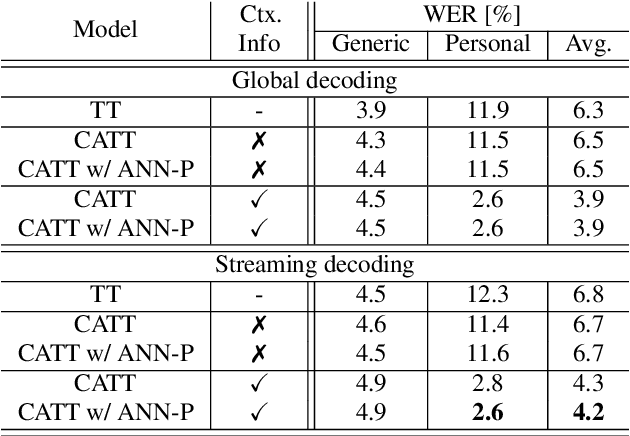
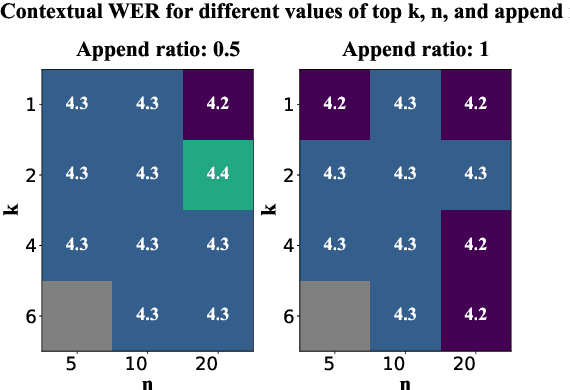

This paper presents an extension to train end-to-end Context-Aware Transformer Transducer ( CATT ) models by using a simple, yet efficient method of mining hard negative phrases from the latent space of the context encoder. During training, given a reference query, we mine a number of similar phrases using approximate nearest neighbour search. These sampled phrases are then used as negative examples in the context list alongside random and ground truth contextual information. By including approximate nearest neighbour phrases (ANN-P) in the context list, we encourage the learned representation to disambiguate between similar, but not identical, biasing phrases. This improves biasing accuracy when there are several similar phrases in the biasing inventory. We carry out experiments in a large-scale data regime obtaining up to 7% relative word error rate reductions for the contextual portion of test data. We also extend and evaluate CATT approach in streaming applications.