 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Multilingual Transformer Language Model for Speech Recognition in Low-resource Languages
Sep 08, 2022
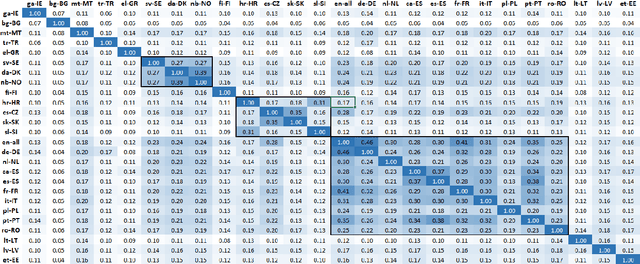

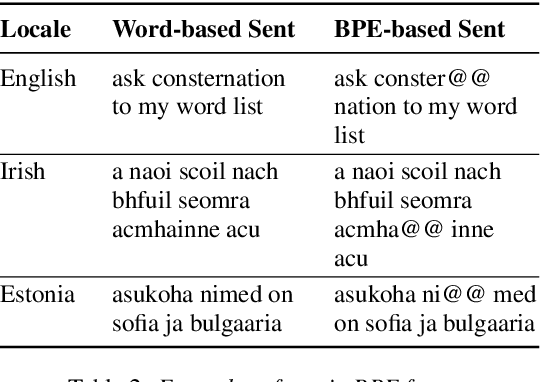
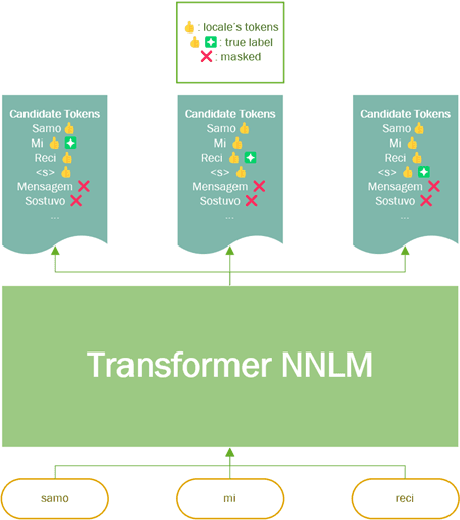
It is challenging to train and deploy Transformer LMs for hybrid speech recognition 2nd pass re-ranking in low-resource languages due to (1) data scarcity in low-resource languages, (2) expensive computing costs for training and refreshing 100+ monolingual models, and (3) hosting inefficiency considering sparse traffic. In this study, we present a new way to group multiple low-resource locales together and optimize the performance of Multilingual Transformer LMs in ASR. Our Locale-group Multilingual Transformer LMs outperform traditional multilingual LMs along with reducing maintenance costs and operating expenses. Further, for low-resource but high-traffic locales where deploying monolingual models is feasible, we show that fine-tuning our locale-group multilingual LMs produces better monolingual LM candidates than baseline monolingual LMs.
Robustness of Multi-Source MT to Transcription Errors
May 26, 2023
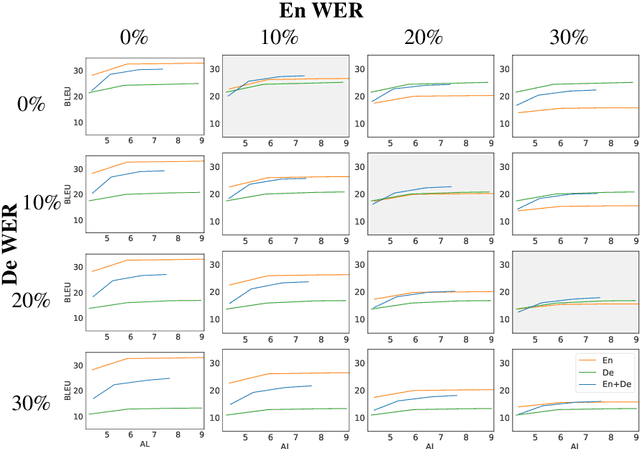

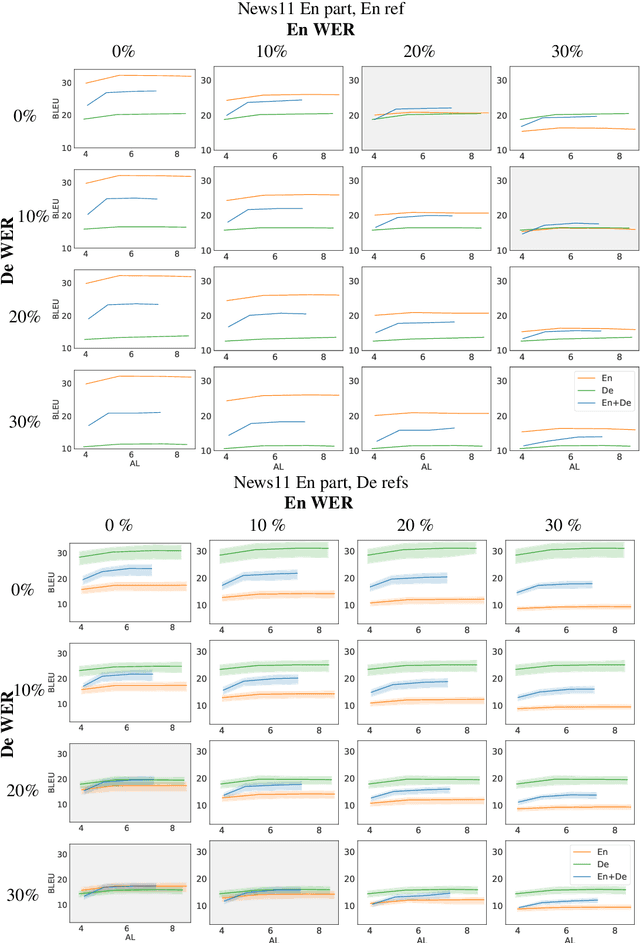
Automatic speech translation is sensitive to speech recognition errors, but in a multilingual scenario, the same content may be available in various languages via simultaneous interpreting, dubbing or subtitling. In this paper, we hypothesize that leveraging multiple sources will improve translation quality if the sources complement one another in terms of correct information they contain. To this end, we first show that on a 10-hour ESIC corpus, the ASR errors in the original English speech and its simultaneous interpreting into German and Czech are mutually independent. We then use two sources, English and German, in a multi-source setting for translation into Czech to establish its robustness to ASR errors. Furthermore, we observe this robustness when translating both noisy sources together in a simultaneous translation setting. Our results show that multi-source neural machine translation has the potential to be useful in a real-time simultaneous translation setting, thereby motivating further investigation in this area.
Joint Speech Recognition and Audio Captioning
Feb 03, 2022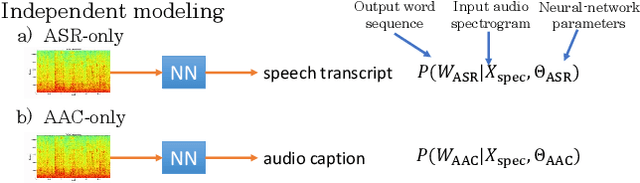
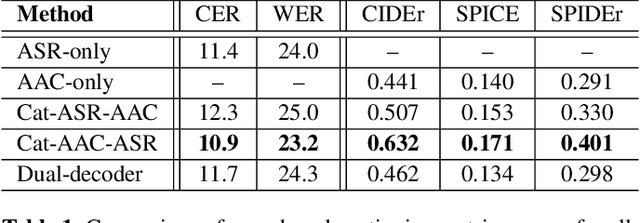
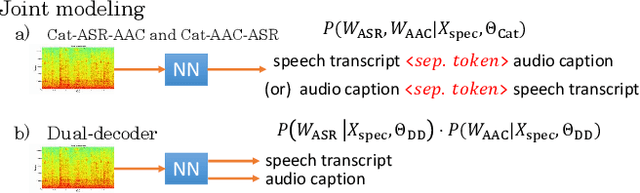
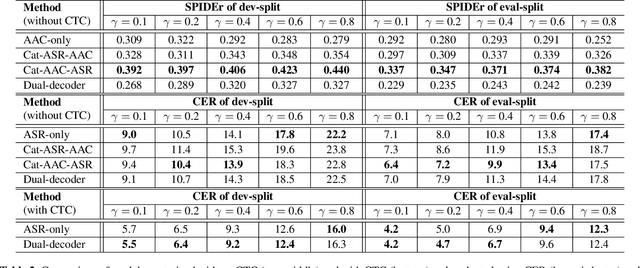
Speech samples recorded in both indoor and outdoor environments are often contaminated with secondary audio sources. Most end-to-end monaural speech recognition systems either remove these background sounds using speech enhancement or train noise-robust models. For better model interpretability and holistic understanding, we aim to bring together the growing field of automated audio captioning (AAC) and the thoroughly studied automatic speech recognition (ASR). The goal of AAC is to generate natural language descriptions of contents in audio samples. We propose several approaches for end-to-end joint modeling of ASR and AAC tasks and demonstrate their advantages over traditional approaches, which model these tasks independently. A major hurdle in evaluating our proposed approach is the lack of labeled audio datasets with both speech transcriptions and audio captions. Therefore we also create a multi-task dataset by mixing the clean speech Wall Street Journal corpus with multiple levels of background noises chosen from the AudioCaps dataset. We also perform extensive experimental evaluation and show improvements of our proposed methods as compared to existing state-of-the-art ASR and AAC methods.
Multimodal Audio-textual Architecture for Robust Spoken Language Understanding
Jun 13, 2023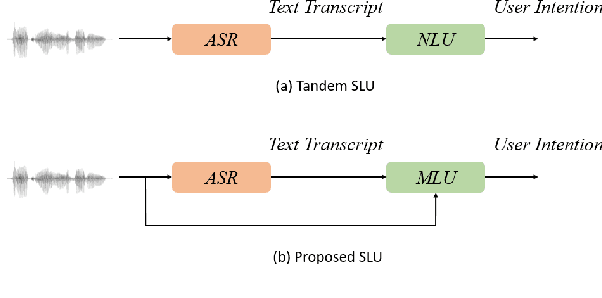
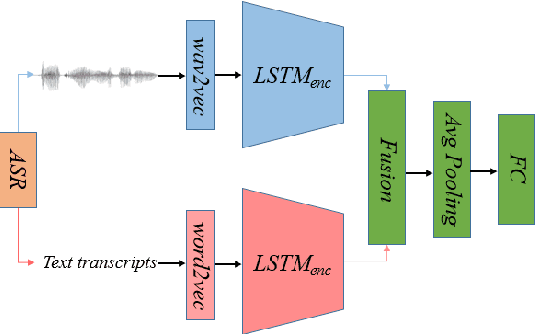
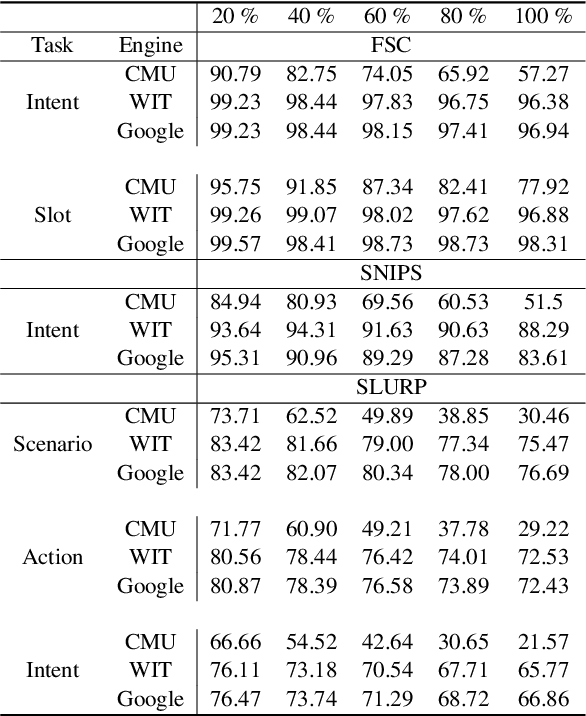
Recent voice assistants are usually based on the cascade spoken language understanding (SLU) solution, which consists of an automatic speech recognition (ASR) engine and a natural language understanding (NLU) system. Because such approach relies on the ASR output, it often suffers from the so-called ASR error propagation. In this work, we investigate impacts of this ASR error propagation on state-of-the-art NLU systems based on pre-trained language models (PLM), such as BERT and RoBERTa. Moreover, a multimodal language understanding (MLU) module is proposed to mitigate SLU performance degradation caused by errors present in the ASR transcript. The MLU benefits from self-supervised features learned from both audio and text modalities, specifically Wav2Vec for speech and Bert/RoBERTa for language. Our MLU combines an encoder network to embed the audio signal and a text encoder to process text transcripts followed by a late fusion layer to fuse audio and text logits. We found that the proposed MLU showed to be robust towards poor quality ASR transcripts, while the performance of BERT and RoBERTa are severely compromised. Our model is evaluated on five tasks from three SLU datasets and robustness is tested using ASR transcripts from three ASR engines. Results show that the proposed approach effectively mitigates the ASR error propagation problem, surpassing the PLM models' performance across all datasets for the academic ASR engine.
Exploring Effective Distillation of Self-Supervised Speech Models for Automatic Speech Recognition
Oct 27, 2022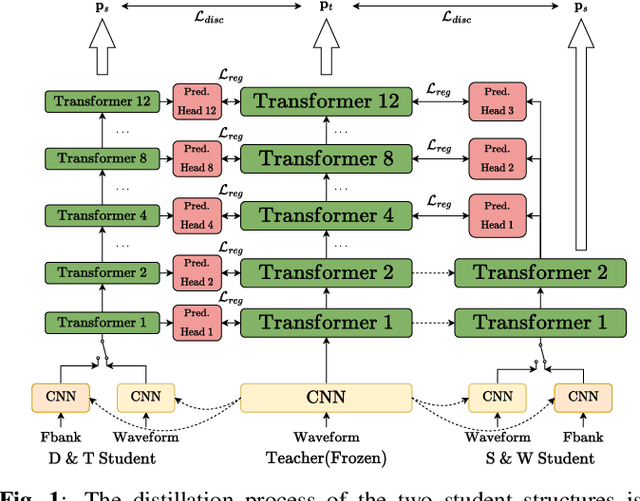
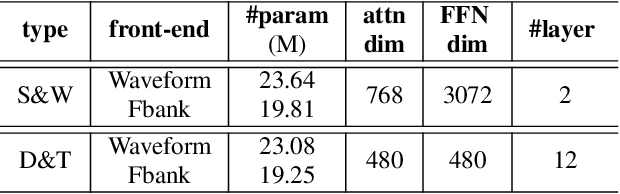
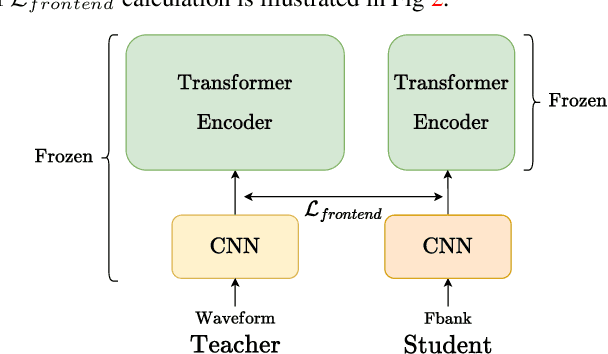
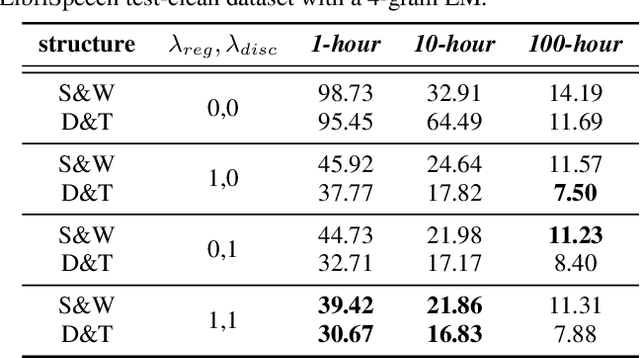
Recent years have witnessed great strides in self-supervised learning (SSL) on the speech processing. The SSL model is normally pre-trained on a great variety of unlabelled data and a large model size is preferred to increase the modeling capacity. However, this might limit its potential applications due to the expensive computation and memory costs introduced by the oversize model. Miniaturization for SSL models has become an important research direction of practical value. To this end, we explore the effective distillation of HuBERT-based SSL models for automatic speech recognition (ASR). First, in order to establish a strong baseline, a comprehensive study on different student model structures is conducted. On top of this, as a supplement to the regression loss widely adopted in previous works, a discriminative loss is introduced for HuBERT to enhance the distillation performance, especially in low-resource scenarios. In addition, we design a simple and effective algorithm to distill the front-end input from waveform to Fbank feature, resulting in 17% parameter reduction and doubling inference speed, at marginal performance degradation.
Self-supervised learning with bi-label masked speech prediction for streaming multi-talker speech recognition
Nov 10, 2022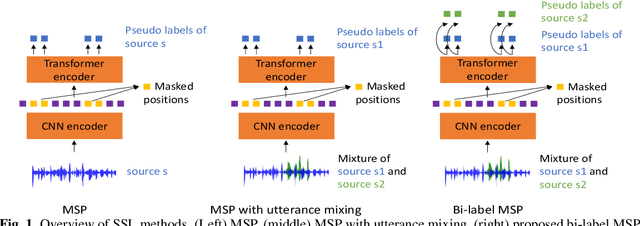
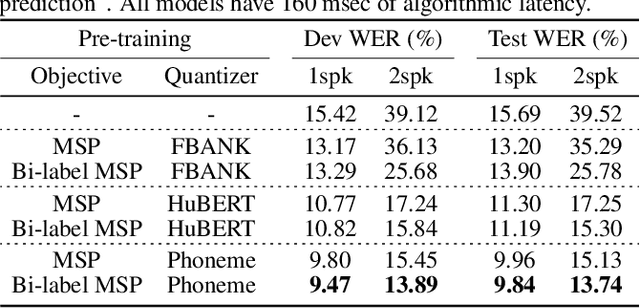

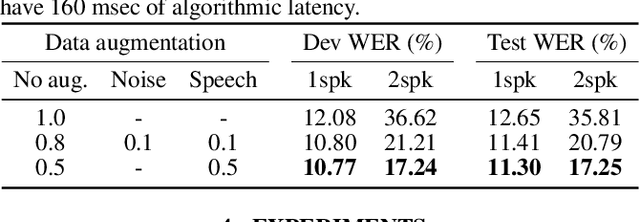
Self-supervised learning (SSL), which utilizes the input data itself for representation learning, has achieved state-of-the-art results for various downstream speech tasks. However, most of the previous studies focused on offline single-talker applications, with limited investigations in multi-talker cases, especially for streaming scenarios. In this paper, we investigate SSL for streaming multi-talker speech recognition, which generates transcriptions of overlapping speakers in a streaming fashion. We first observe that conventional SSL techniques do not work well on this task due to the poor representation of overlapping speech. We then propose a novel SSL training objective, referred to as bi-label masked speech prediction, which explicitly preserves representations of all speakers in overlapping speech. We investigate various aspects of the proposed system including data configuration and quantizer selection. The proposed SSL setup achieves substantially better word error rates on the LibriSpeechMix dataset.
Knowledge Distillation for Neural Transducer-based Target-Speaker ASR: Exploiting Parallel Mixture/Single-Talker Speech Data
May 25, 2023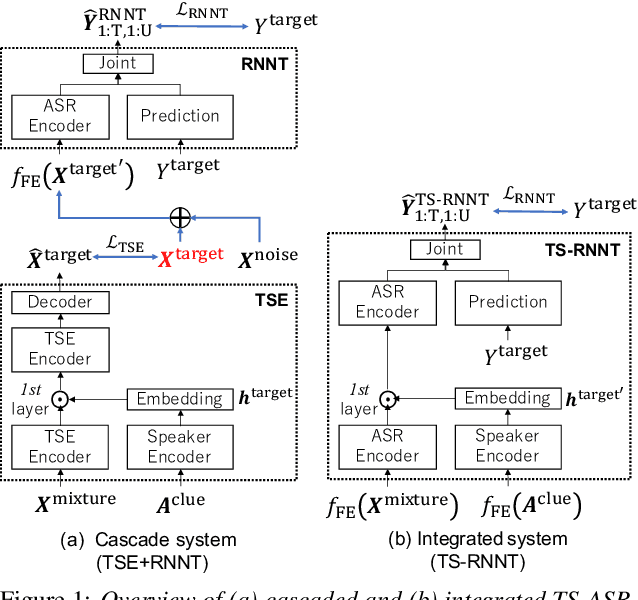

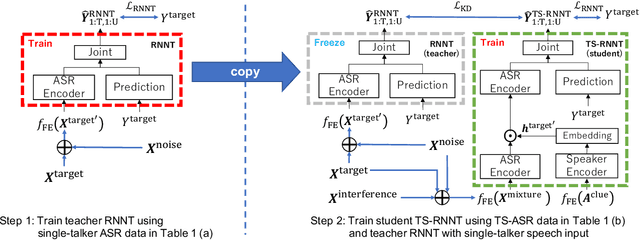
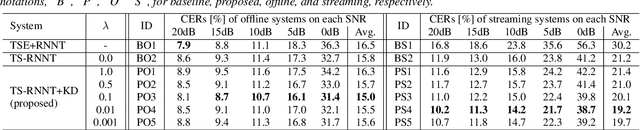
Neural transducer (RNNT)-based target-speaker speech recognition (TS-RNNT) directly transcribes a target speaker's voice from a multi-talker mixture. It is a promising approach for streaming applications because it does not incur the extra computation costs of a target speech extraction frontend, which is a critical barrier to quick response. TS-RNNT is trained end-to-end given the input speech (i.e., mixtures and enrollment speech) and reference transcriptions. The training mixtures are generally simulated by mixing single-talker signals, but conventional TS-RNNT training does not utilize single-speaker signals. This paper proposes using knowledge distillation (KD) to exploit the parallel mixture/single-talker speech data. Our proposed KD scheme uses an RNNT system pretrained with the target single-talker speech input to generate pseudo labels for the TS-RNNT training. Experimental results show that TS-RNNT systems trained with the proposed KD scheme outperform a baseline TS-RNNT.
Svarah: Evaluating English ASR Systems on Indian Accents
May 25, 2023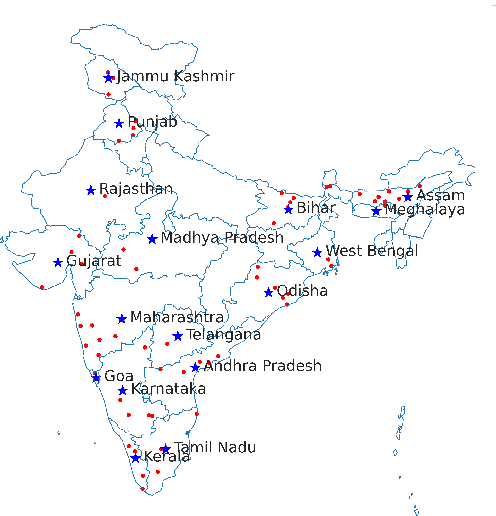
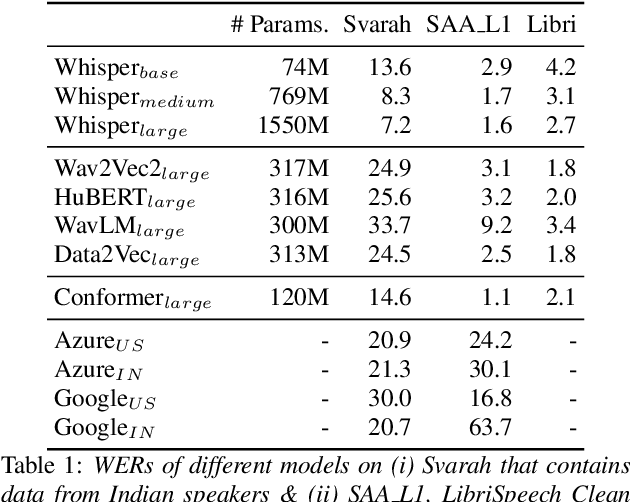
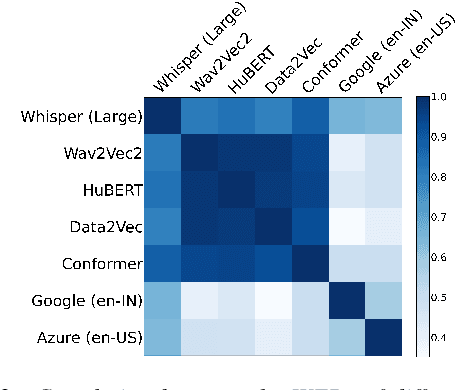
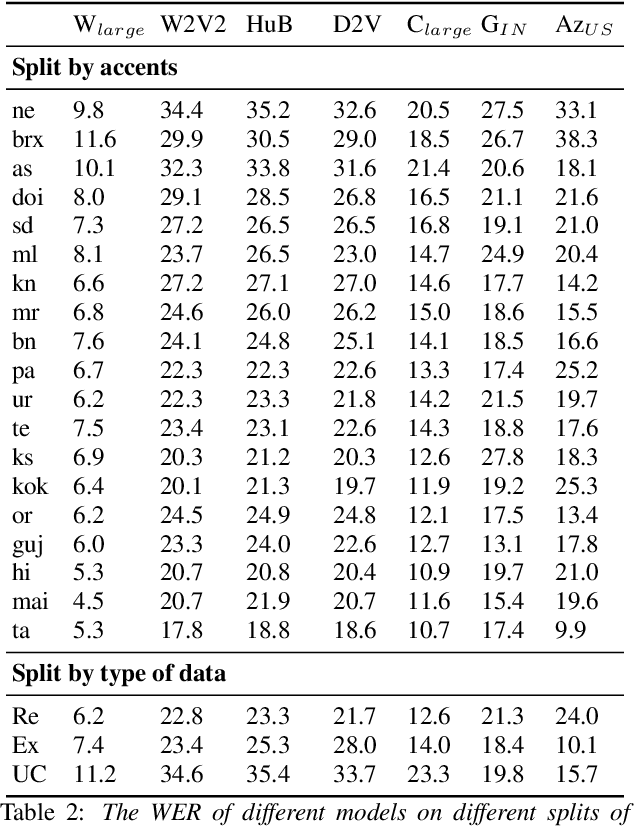
India is the second largest English-speaking country in the world with a speaker base of roughly 130 million. Thus, it is imperative that automatic speech recognition (ASR) systems for English should be evaluated on Indian accents. Unfortunately, Indian speakers find a very poor representation in existing English ASR benchmarks such as LibriSpeech, Switchboard, Speech Accent Archive, etc. In this work, we address this gap by creating Svarah, a benchmark that contains 9.6 hours of transcribed English audio from 117 speakers across 65 geographic locations throughout India, resulting in a diverse range of accents. Svarah comprises both read speech and spontaneous conversational data, covering various domains, such as history, culture, tourism, etc., ensuring a diverse vocabulary. We evaluate 6 open source ASR models and 2 commercial ASR systems on Svarah and show that there is clear scope for improvement on Indian accents. Svarah as well as all our code will be publicly available.
The Makerere Radio Speech Corpus: A Luganda Radio Corpus for Automatic Speech Recognition
Jun 20, 2022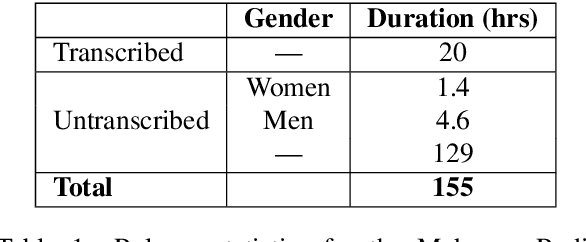

Building a usable radio monitoring automatic speech recognition (ASR) system is a challenging task for under-resourced languages and yet this is paramount in societies where radio is the main medium of public communication and discussions. Initial efforts by the United Nations in Uganda have proved how understanding the perceptions of rural people who are excluded from social media is important in national planning. However, these efforts are being challenged by the absence of transcribed speech datasets. In this paper, The Makerere Artificial Intelligence research lab releases a Luganda radio speech corpus of 155 hours. To our knowledge, this is the first publicly available radio dataset in sub-Saharan Africa. The paper describes the development of the voice corpus and presents baseline Luganda ASR performance results using Coqui STT toolkit, an open source speech recognition toolkit.
CopyNE: Better Contextual ASR by Copying Named Entities
May 22, 2023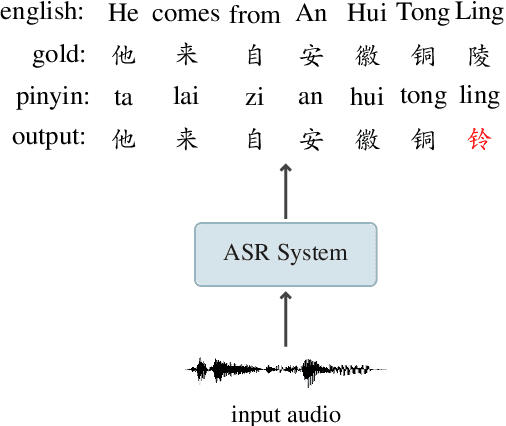
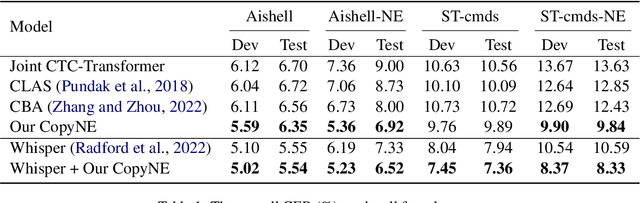
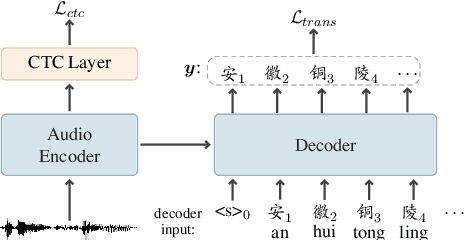
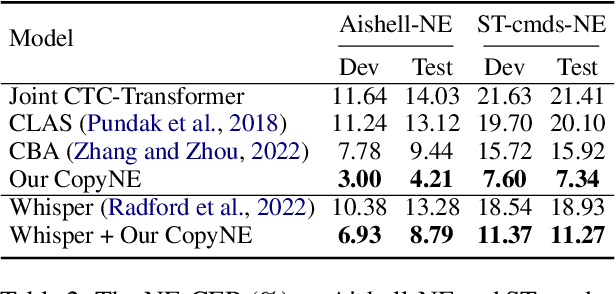
Recent years have seen remarkable progress in automatic speech recognition (ASR). However, traditional token-level ASR models have struggled with accurately transcribing entities due to the problem of homophonic and near-homophonic tokens. This paper introduces a novel approach called CopyNE, which uses a span-level copying mechanism to improve ASR in transcribing entities. CopyNE can copy all tokens of an entity at once, effectively avoiding errors caused by homophonic or near-homophonic tokens that occur when predicting multiple tokens separately. Experiments on Aishell and ST-cmds datasets demonstrate that CopyNE achieves significant reductions in character error rate (CER) and named entity CER (NE-CER), especially in entity-rich scenarios. Furthermore, even when compared to the strong Whisper baseline, CopyNE still achieves notable reductions in CER and NE-CER. Qualitative comparisons with previous approaches demonstrate that CopyNE can better handle entities, effectively improving the accuracy of ASR.