 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Weight Averaging: A Simple Yet Effective Method to Overcome Catastrophic Forgetting in Automatic Speech Recognition
Oct 27, 2022
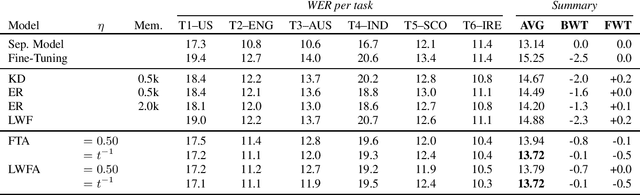
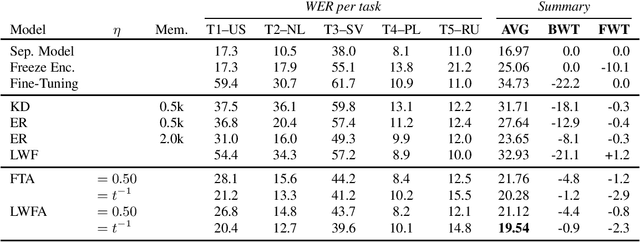
Adapting a trained Automatic Speech Recognition (ASR) model to new tasks results in catastrophic forgetting of old tasks, limiting the model's ability to learn continually and to be extended to new speakers, dialects, languages, etc. Focusing on End-to-End ASR, in this paper, we propose a simple yet effective method to overcome catastrophic forgetting: weight averaging. By simply taking the average of the previous and the adapted model, our method achieves high performance on both the old and new tasks. It can be further improved by introducing a knowledge distillation loss during the adaptation. We illustrate the effectiveness of our method on both monolingual and multilingual ASR. In both cases, our method strongly outperforms all baselines, even in its simplest form.
HuBERT-TR: Reviving Turkish Automatic Speech Recognition with Self-supervised Speech Representation Learning
Oct 13, 2022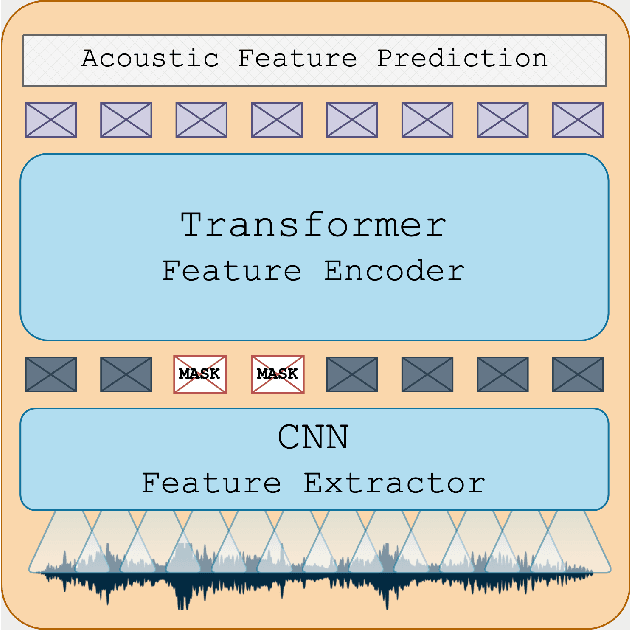
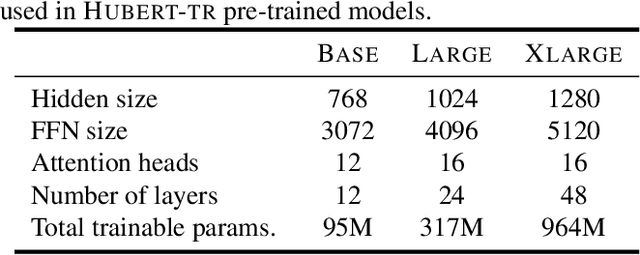
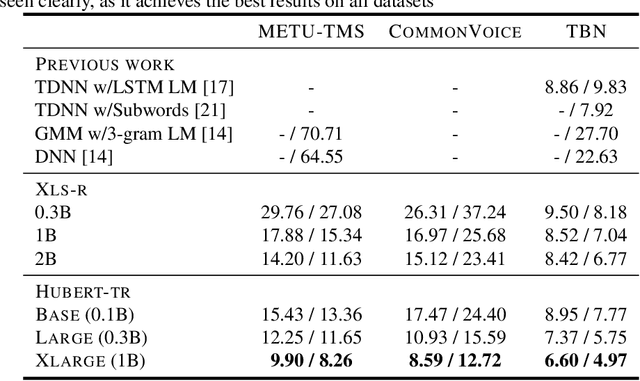
While the Turkish language is listed among low-resource languages, literature on Turkish automatic speech recognition (ASR) is relatively old. In this paper, we present HuBERT-TR, a speech representation model for Turkish based on HuBERT. HuBERT-TR achieves state-of-the-art results on several Turkish ASR datasets. We investigate pre-training HuBERT for Turkish with large-scale data curated from online resources. We pre-train HuBERT-TR using over 6,500 hours of speech data curated from YouTube that includes extensive variability in terms of quality and genre. We show that pre-trained models within a multi-lingual setup are inferior to language-specific models, where our Turkish model HuBERT-TR base performs better than its x10 times larger multi-lingual counterpart XLS-R-1B. Moreover, we study the effect of scaling on ASR performance by scaling our models up to 1B parameters. Our best model yields a state-of-the-art word error rate of 4.97% on the Turkish Broadcast News dataset. Models are available at huggingface.co/asafaya .
Multilingual Transformer Language Model for Speech Recognition in Low-resource Languages
Sep 08, 2022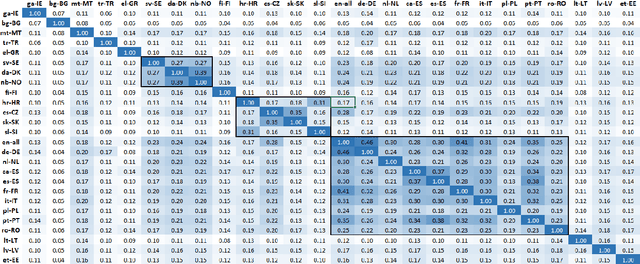

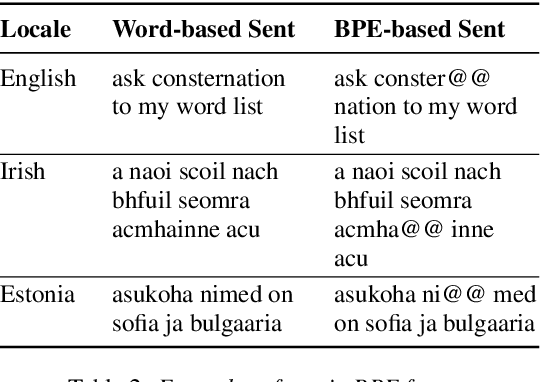
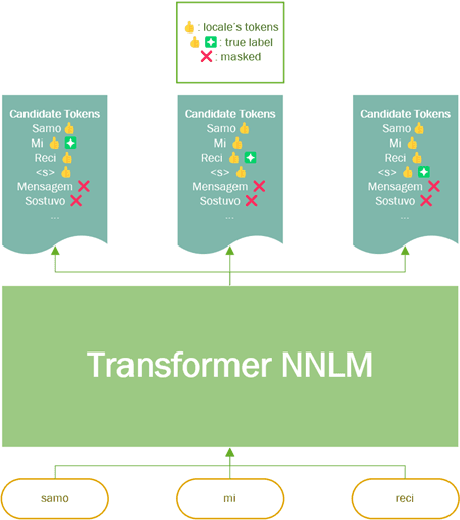
It is challenging to train and deploy Transformer LMs for hybrid speech recognition 2nd pass re-ranking in low-resource languages due to (1) data scarcity in low-resource languages, (2) expensive computing costs for training and refreshing 100+ monolingual models, and (3) hosting inefficiency considering sparse traffic. In this study, we present a new way to group multiple low-resource locales together and optimize the performance of Multilingual Transformer LMs in ASR. Our Locale-group Multilingual Transformer LMs outperform traditional multilingual LMs along with reducing maintenance costs and operating expenses. Further, for low-resource but high-traffic locales where deploying monolingual models is feasible, we show that fine-tuning our locale-group multilingual LMs produces better monolingual LM candidates than baseline monolingual LMs.
The History of Speech Recognition to the Year 2030
Jul 30, 2021

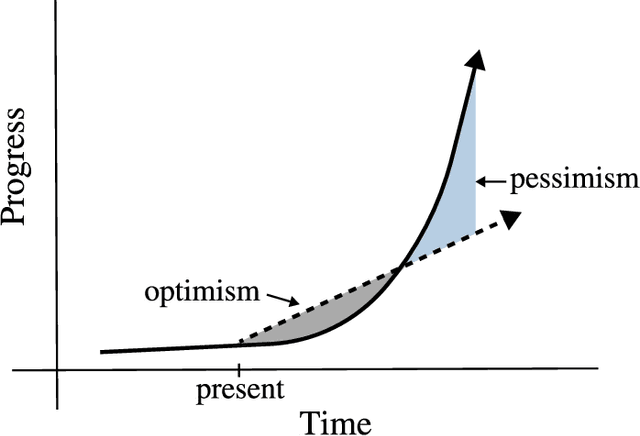
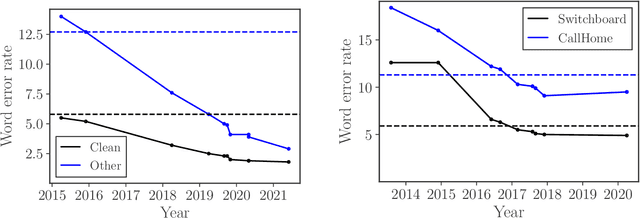
The decade from 2010 to 2020 saw remarkable improvements in automatic speech recognition. Many people now use speech recognition on a daily basis, for example to perform voice search queries, send text messages, and interact with voice assistants like Amazon Alexa and Siri by Apple. Before 2010 most people rarely used speech recognition. Given the remarkable changes in the state of speech recognition over the previous decade, what can we expect over the coming decade? I attempt to forecast the state of speech recognition research and applications by the year 2030. While the changes to general speech recognition accuracy will not be as dramatic as in the previous decade, I suggest we have an exciting decade of progress in speech technology ahead of us.
Unit-based Speech-to-Speech Translation Without Parallel Data
May 24, 2023
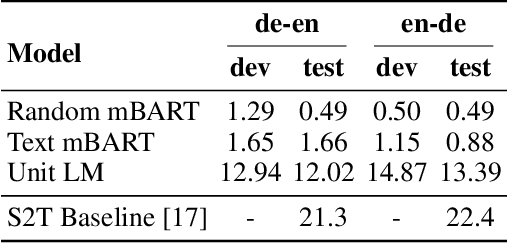
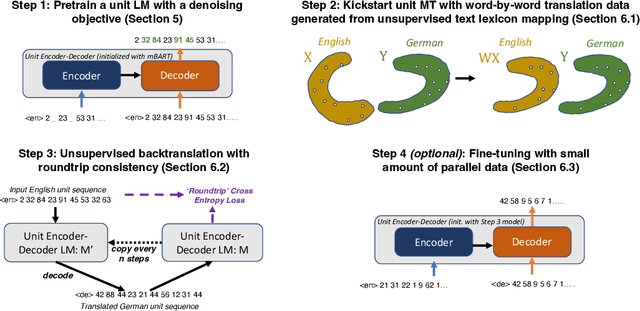
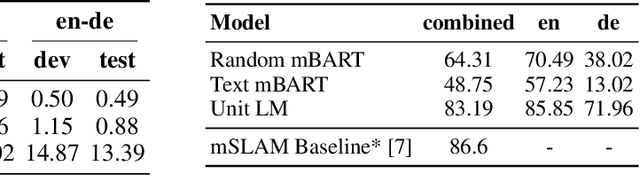
We propose an unsupervised speech-to-speech translation (S2ST) system that does not rely on parallel data between the source and target languages. Our approach maps source and target language speech signals into automatically discovered, discrete units and reformulates the problem as unsupervised unit-to-unit machine translation. We develop a three-step training procedure that involves (a) pre-training an unit-based encoder-decoder language model with a denoising objective (b) training it with word-by-word translated utterance pairs created by aligning monolingual text embedding spaces and (c) running unsupervised backtranslation bootstrapping off of the initial translation model. Our approach avoids mapping the speech signal into text and uses speech-to-unit and unit-to-speech models instead of automatic speech recognition and text to speech models. We evaluate our model on synthetic-speaker Europarl-ST English-German and German-English evaluation sets, finding that unit-based translation is feasible under this constrained scenario, achieving 9.29 ASR-BLEU in German to English and 8.07 in English to German.
Incorporating Ultrasound Tongue Images for Audio-Visual Speech Enhancement through Knowledge Distillation
May 24, 2023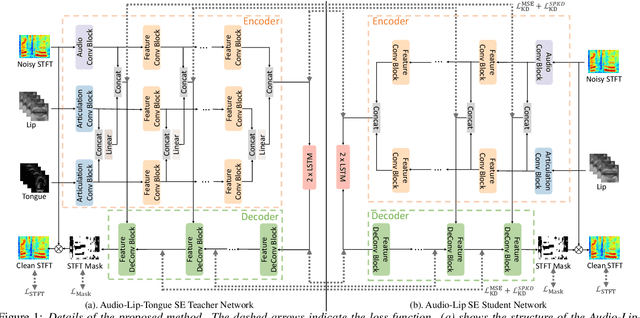
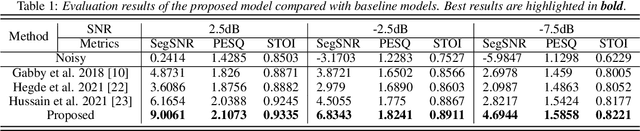
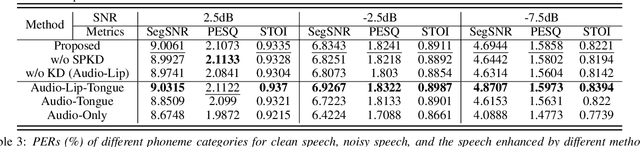
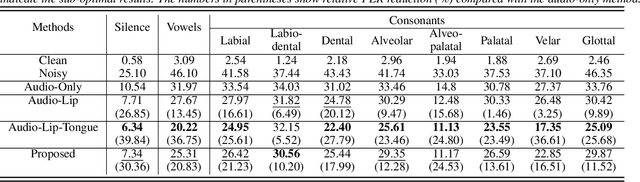
Audio-visual speech enhancement (AV-SE) aims to enhance degraded speech along with extra visual information such as lip videos, and has been shown to be more effective than audio-only speech enhancement. This paper proposes further incorporating ultrasound tongue images to improve lip-based AV-SE systems' performance. Knowledge distillation is employed at the training stage to address the challenge of acquiring ultrasound tongue images during inference, enabling an audio-lip speech enhancement student model to learn from a pre-trained audio-lip-tongue speech enhancement teacher model. Experimental results demonstrate significant improvements in the quality and intelligibility of the speech enhanced by the proposed method compared to the traditional audio-lip speech enhancement baselines. Further analysis using phone error rates (PER) of automatic speech recognition (ASR) shows that palatal and velar consonants benefit most from the introduction of ultrasound tongue images.
The Makerere Radio Speech Corpus: A Luganda Radio Corpus for Automatic Speech Recognition
Jun 20, 2022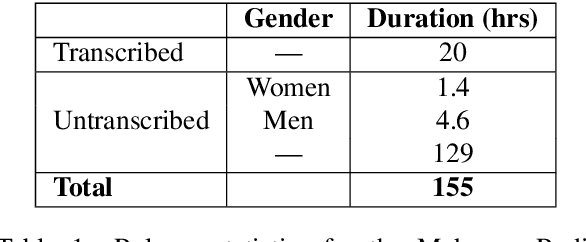

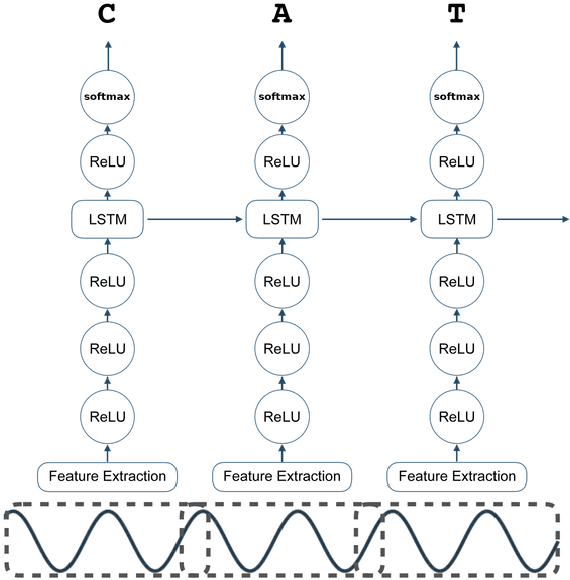
Building a usable radio monitoring automatic speech recognition (ASR) system is a challenging task for under-resourced languages and yet this is paramount in societies where radio is the main medium of public communication and discussions. Initial efforts by the United Nations in Uganda have proved how understanding the perceptions of rural people who are excluded from social media is important in national planning. However, these efforts are being challenged by the absence of transcribed speech datasets. In this paper, The Makerere Artificial Intelligence research lab releases a Luganda radio speech corpus of 155 hours. To our knowledge, this is the first publicly available radio dataset in sub-Saharan Africa. The paper describes the development of the voice corpus and presents baseline Luganda ASR performance results using Coqui STT toolkit, an open source speech recognition toolkit.
Exploring the Role of Audio in Video Captioning
Jun 21, 2023
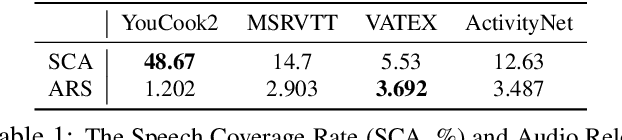


Recent focus in video captioning has been on designing architectures that can consume both video and text modalities, and using large-scale video datasets with text transcripts for pre-training, such as HowTo100M. Though these approaches have achieved significant improvement, the audio modality is often ignored in video captioning. In this work, we present an audio-visual framework, which aims to fully exploit the potential of the audio modality for captioning. Instead of relying on text transcripts extracted via automatic speech recognition (ASR), we argue that learning with raw audio signals can be more beneficial, as audio has additional information including acoustic events, speaker identity, etc. Our contributions are twofold. First, we observed that the model overspecializes to the audio modality when pre-training with both video and audio modality, since the ground truth (i.e., text transcripts) can be solely predicted using audio. We proposed a Modality Balanced Pre-training (MBP) loss to mitigate this issue and significantly improve the performance on downstream tasks. Second, we slice and dice different design choices of the cross-modal module, which may become an information bottleneck and generate inferior results. We proposed new local-global fusion mechanisms to improve information exchange across audio and video. We demonstrate significant improvements by leveraging the audio modality on four datasets, and even outperform the state of the art on some metrics without relying on the text modality as the input.
Computing Optimal Location of Microphone for Improved Speech Recognition
Mar 24, 2022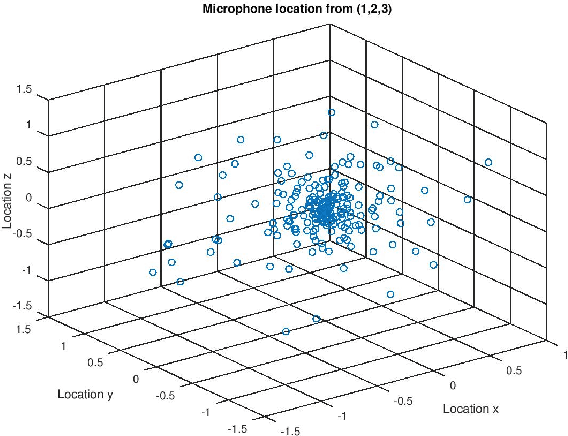
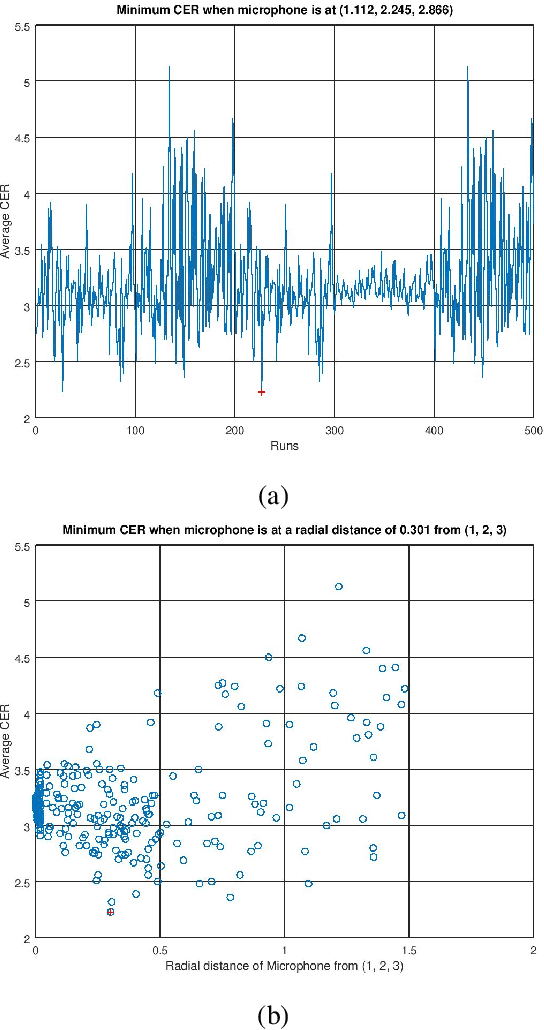
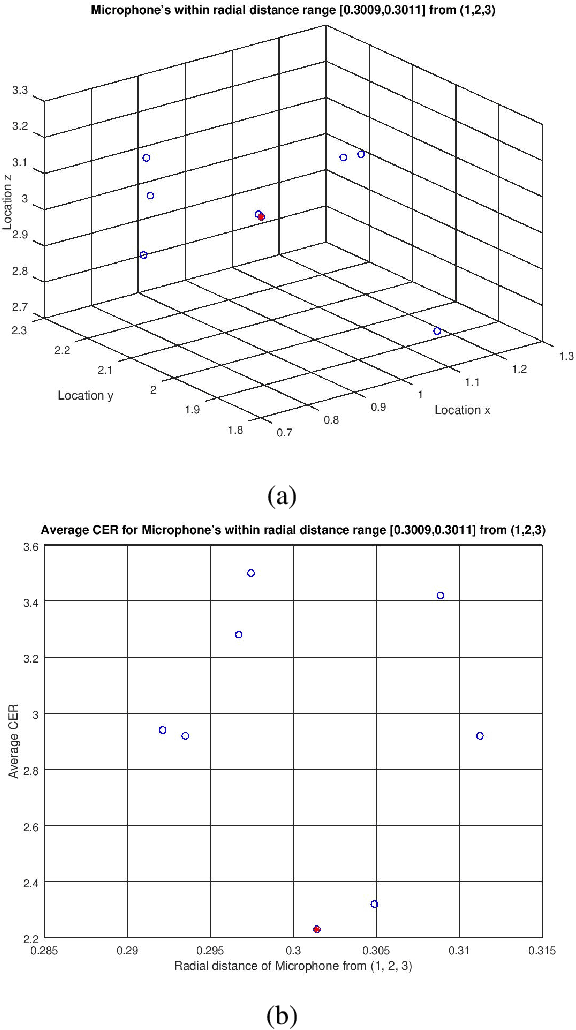
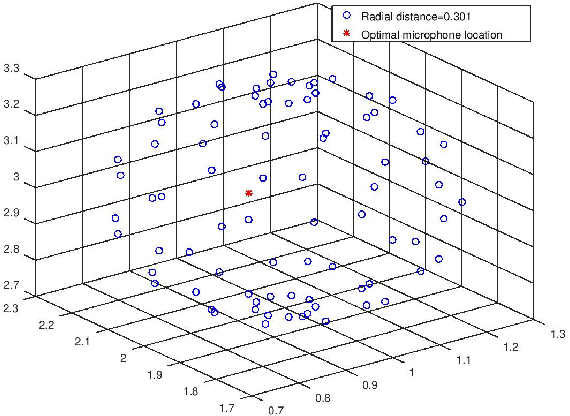
It was shown in our earlier work that the measurement error in the microphone position affected the room impulse response (RIR) which in turn affected the single-channel close microphone and multi-channel distant microphone speech recognition. In this paper, as an extension, we systematically study to identify the optimal location of the microphone, given an approximate and hence erroneous location of the microphone in 3D space. The primary idea is to use Monte-Carlo technique to generate a large number of random microphone positions around the erroneous microphone position and select the microphone position that results in the best performance of a general purpose automatic speech recognition (gp-asr). We experiment with clean and noisy speech and show that the optimal location of the microphone is unique and is affected by noise.
Exploring Effective Distillation of Self-Supervised Speech Models for Automatic Speech Recognition
Oct 27, 2022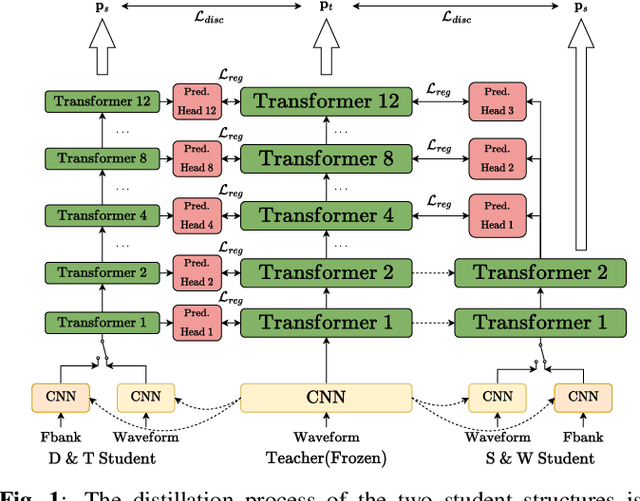
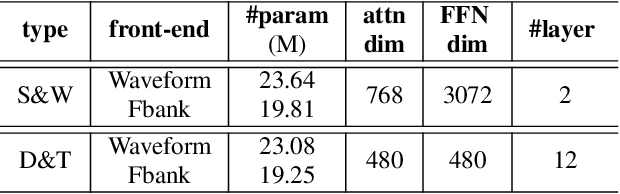
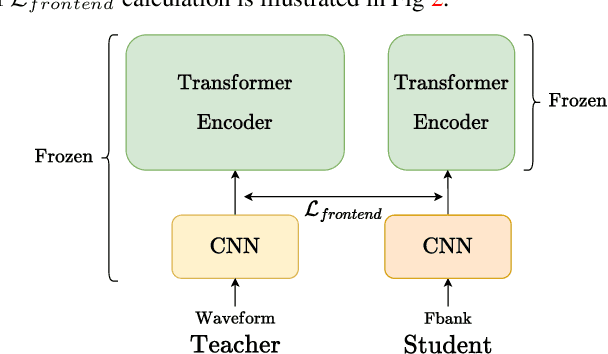
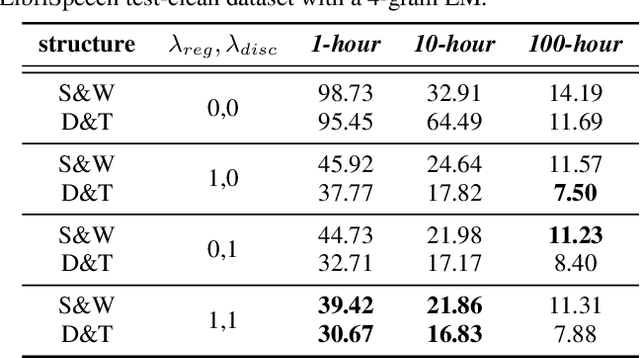
Recent years have witnessed great strides in self-supervised learning (SSL) on the speech processing. The SSL model is normally pre-trained on a great variety of unlabelled data and a large model size is preferred to increase the modeling capacity. However, this might limit its potential applications due to the expensive computation and memory costs introduced by the oversize model. Miniaturization for SSL models has become an important research direction of practical value. To this end, we explore the effective distillation of HuBERT-based SSL models for automatic speech recognition (ASR). First, in order to establish a strong baseline, a comprehensive study on different student model structures is conducted. On top of this, as a supplement to the regression loss widely adopted in previous works, a discriminative loss is introduced for HuBERT to enhance the distillation performance, especially in low-resource scenarios. In addition, we design a simple and effective algorithm to distill the front-end input from waveform to Fbank feature, resulting in 17% parameter reduction and doubling inference speed, at marginal performance degradation.