 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
WhisperX: Time-Accurate Speech Transcription of Long-Form Audio
Mar 01, 2023
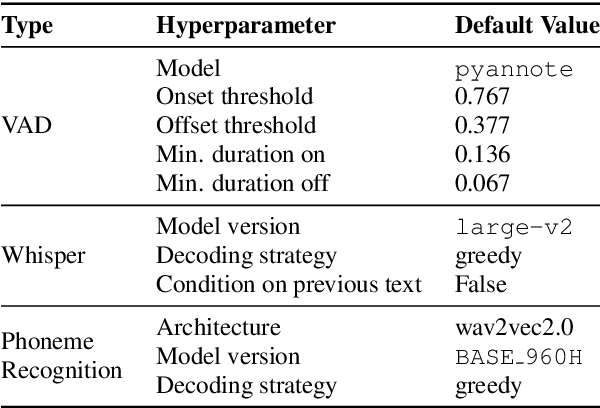

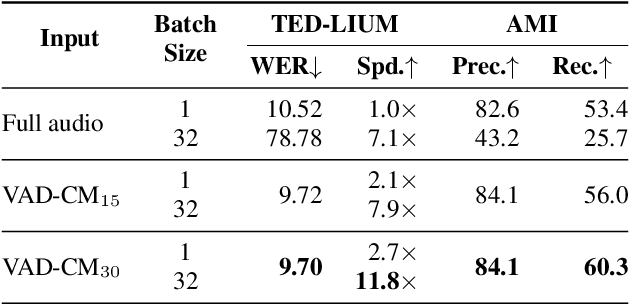
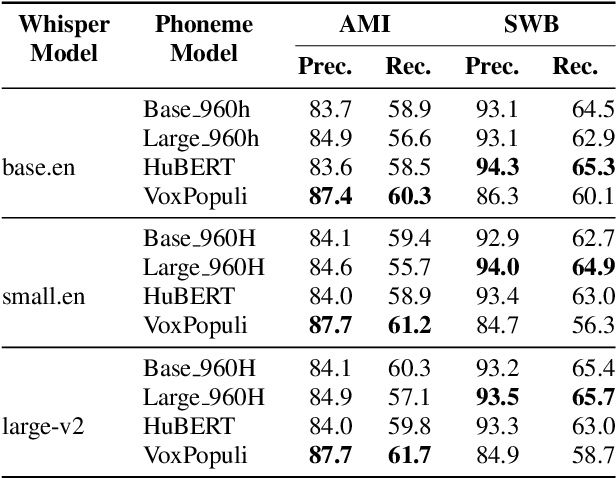
Large-scale, weakly-supervised speech recognition models, such as Whisper, have demonstrated impressive results on speech recognition across domains and languages. However, their application to long audio transcription via buffered or sliding window approaches is prone to drifting, hallucination & repetition; and prohibits batched transcription due to their sequential nature. Further, timestamps corresponding each utterance are prone to inaccuracies and word-level timestamps are not available out-of-the-box. To overcome these challenges, we present WhisperX, a time-accurate speech recognition system with word-level timestamps utilising voice activity detection and forced phoneme alignment. In doing so, we demonstrate state-of-the-art performance on long-form transcription and word segmentation benchmarks. Additionally, we show that pre-segmenting audio with our proposed VAD Cut & Merge strategy improves transcription quality and enables a twelve-fold transcription speedup via batched inference.
Tensor decomposition for minimization of E2E SLU model toward on-device processing
Jun 02, 2023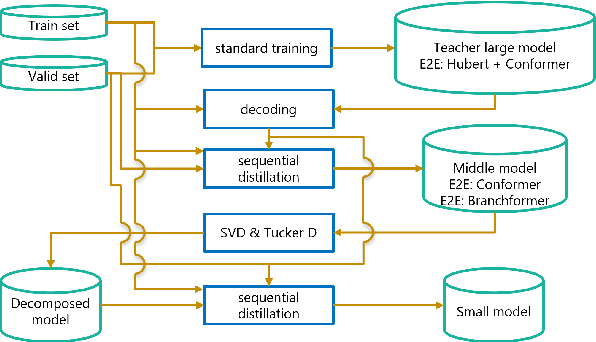
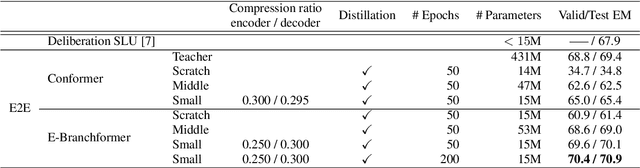

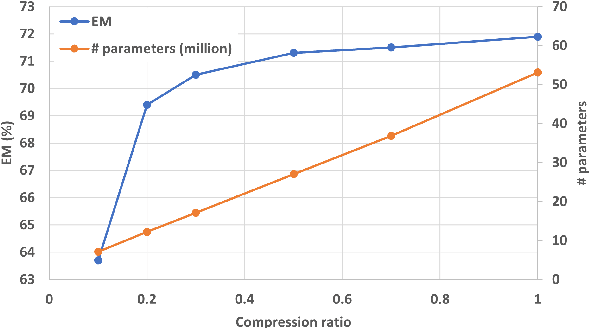
Spoken Language Understanding (SLU) is a critical speech recognition application and is often deployed on edge devices. Consequently, on-device processing plays a significant role in the practical implementation of SLU. This paper focuses on the end-to-end (E2E) SLU model due to its small latency property, unlike a cascade system, and aims to minimize the computational cost. We reduce the model size by applying tensor decomposition to the Conformer and E-Branchformer architectures used in our E2E SLU models. We propose to apply singular value decomposition to linear layers and the Tucker decomposition to convolution layers, respectively. We also compare COMP/PARFAC decomposition and Tensor-Train decomposition to the Tucker decomposition. Since the E2E model is represented by a single neural network, our tensor decomposition can flexibly control the number of parameters without changing feature dimensions. On the STOP dataset, we achieved 70.9% exact match accuracy under the tight constraint of only 15 million parameters.
Masked Audio Text Encoders are Effective Multi-Modal Rescorers
May 24, 2023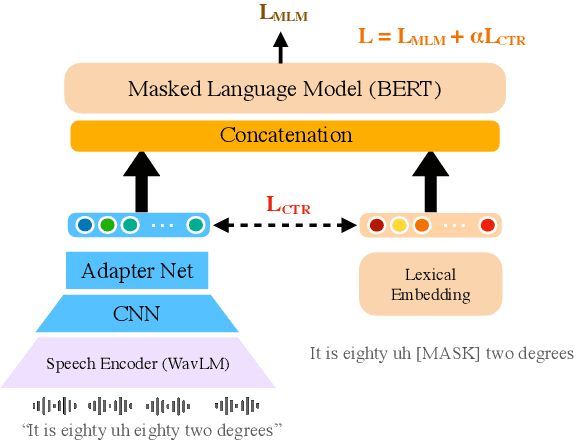
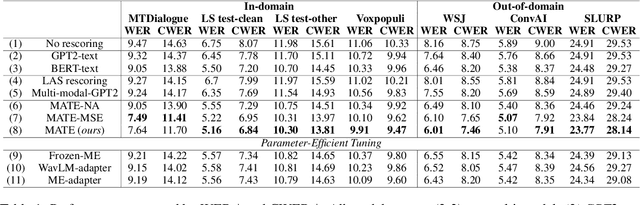
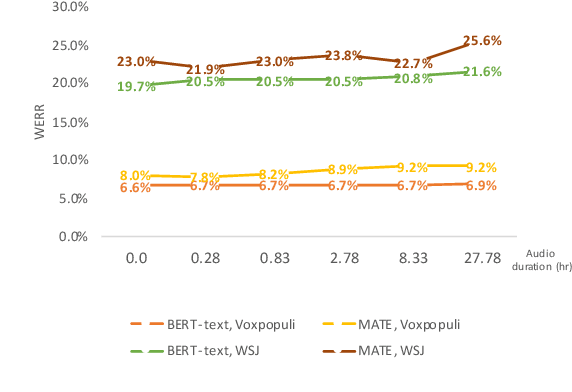
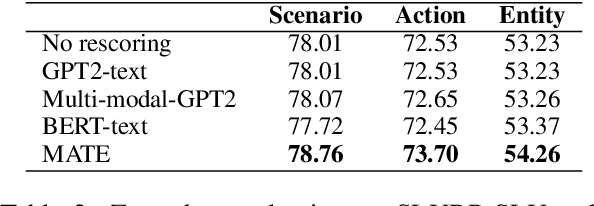
Masked Language Models (MLMs) have proven to be effective for second-pass rescoring in Automatic Speech Recognition (ASR) systems. In this work, we propose Masked Audio Text Encoder (MATE), a multi-modal masked language model rescorer which incorporates acoustic representations into the input space of MLM. We adopt contrastive learning for effectively aligning the modalities by learning shared representations. We show that using a multi-modal rescorer is beneficial for domain generalization of the ASR system when target domain data is unavailable. MATE reduces word error rate (WER) by 4%-16% on in-domain, and 3%-7% on out-of-domain datasets, over the text-only baseline. Additionally, with very limited amount of training data (0.8 hours), MATE achieves a WER reduction of 8%-23% over the first-pass baseline.
Adapting Multi-Lingual ASR Models for Handling Multiple Talkers
May 30, 2023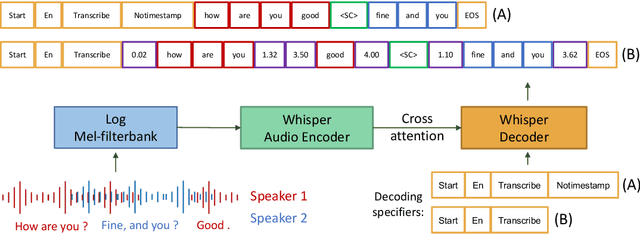
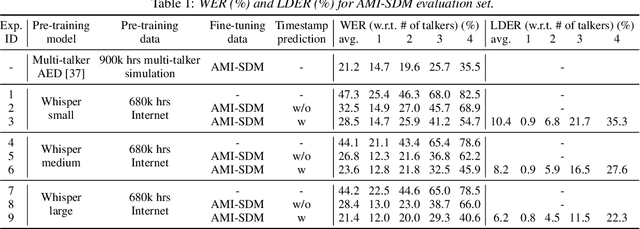
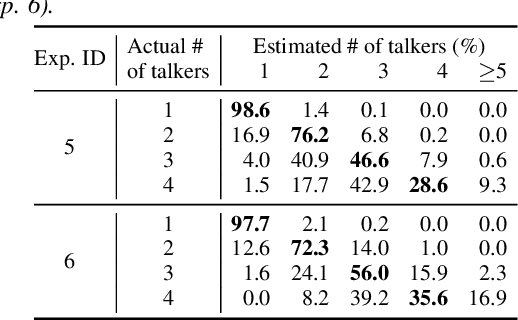
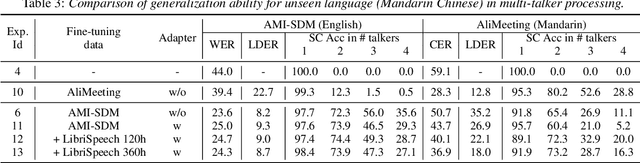
State-of-the-art large-scale universal speech models (USMs) show a decent automatic speech recognition (ASR) performance across multiple domains and languages. However, it remains a challenge for these models to recognize overlapped speech, which is often seen in meeting conversations. We propose an approach to adapt USMs for multi-talker ASR. We first develop an enhanced version of serialized output training to jointly perform multi-talker ASR and utterance timestamp prediction. That is, we predict the ASR hypotheses for all speakers, count the speakers, and estimate the utterance timestamps at the same time. We further introduce a lightweight adapter module to maintain the multilingual property of the USMs even when we perform the adaptation with only a single language. Experimental results obtained using the AMI and AliMeeting corpora show that our proposed approach effectively transfers the USMs to a strong multilingual multi-talker ASR model with timestamp prediction capability.
Bridging the Granularity Gap for Acoustic Modeling
May 27, 2023
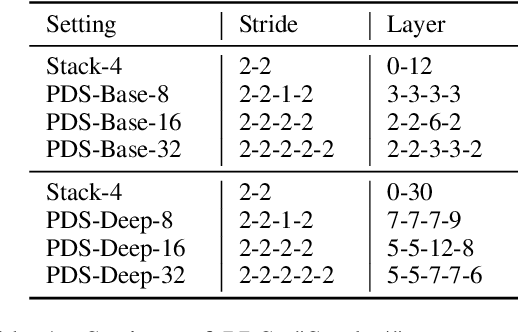
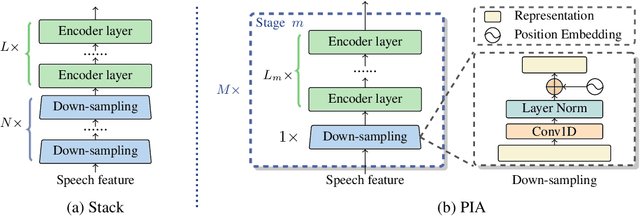
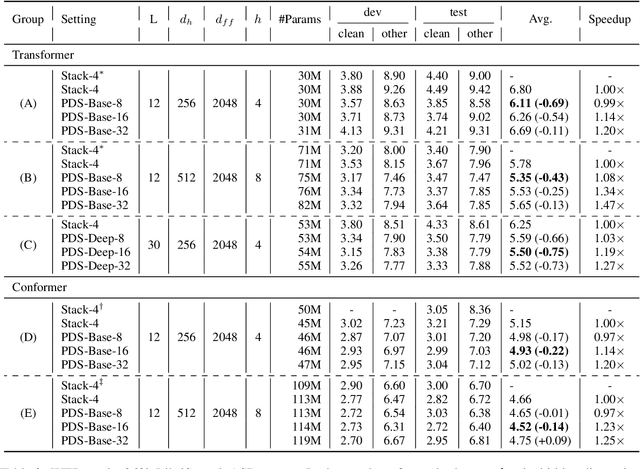
While Transformer has become the de-facto standard for speech, modeling upon the fine-grained frame-level features remains an open challenge of capturing long-distance dependencies and distributing the attention weights. We propose \textit{Progressive Down-Sampling} (PDS) which gradually compresses the acoustic features into coarser-grained units containing more complete semantic information, like text-level representation. In addition, we develop a representation fusion method to alleviate information loss that occurs inevitably during high compression. In this way, we compress the acoustic features into 1/32 of the initial length while achieving better or comparable performances on the speech recognition task. And as a bonus, it yields inference speedups ranging from 1.20$\times$ to 1.47$\times$. By reducing the modeling burden, we also achieve competitive results when training on the more challenging speech translation task.
wav2vec and its current potential to Automatic Speech Recognition in German for the usage in Digital History: A comparative assessment of available ASR-technologies for the use in cultural heritage contexts
Mar 06, 2023In this case study we trained and published a state-of-the-art open-source model for Automatic Speech Recognition (ASR) for German to evaluate the current potential of this technology for the use in the larger context of Digital Humanities and cultural heritage indexation. Along with this paper we publish our wav2vec2 based speech to text model while we evaluate its performance on a corpus of historical recordings we assembled compared against commercial cloud-based and proprietary services. While our model achieves moderate results, we see that proprietary cloud services fare significantly better. As our results show, recognition rates over 90 percent can currently be achieved, however, these numbers drop quickly once the recordings feature limited audio quality or use of non-every day or outworn language. A big issue is the high variety of different dialects and accents in the German language. Nevertheless, this paper highlights that the currently available quality of recognition is high enough to address various use cases in the Digital Humanities. We argue that ASR will become a key technology for the documentation and analysis of audio-visual sources and identify an array of important questions that the DH community and cultural heritage stakeholders will have to address in the near future.
Large-scale unsupervised audio pre-training for video-to-speech synthesis
Jun 27, 2023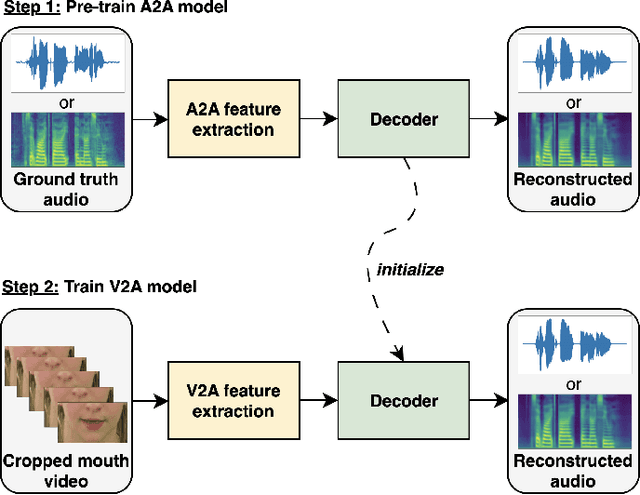
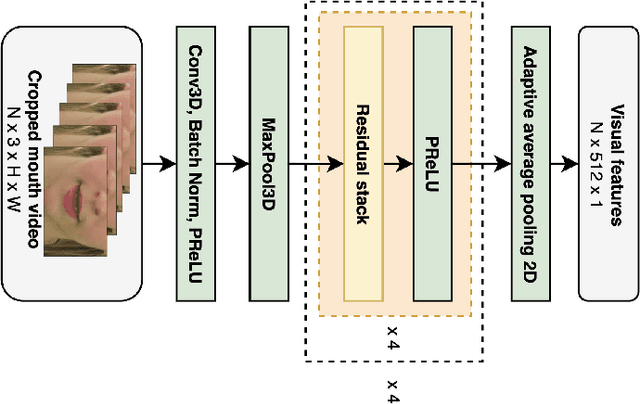
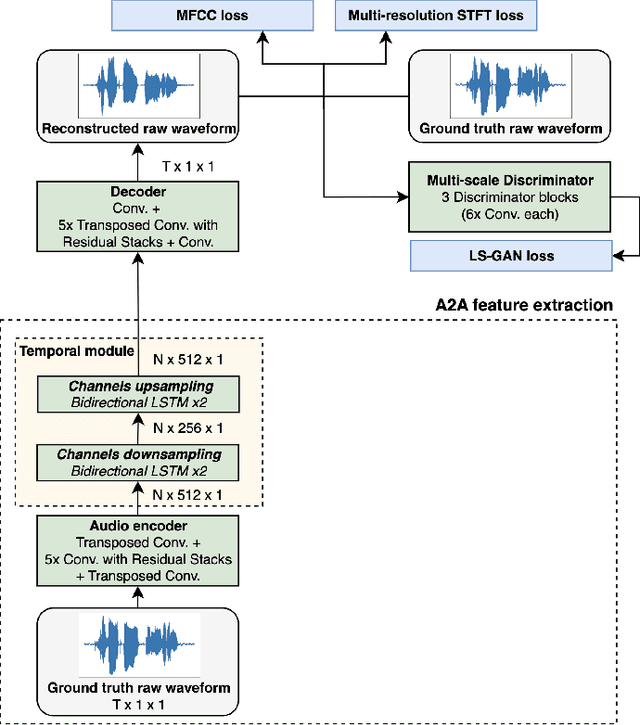
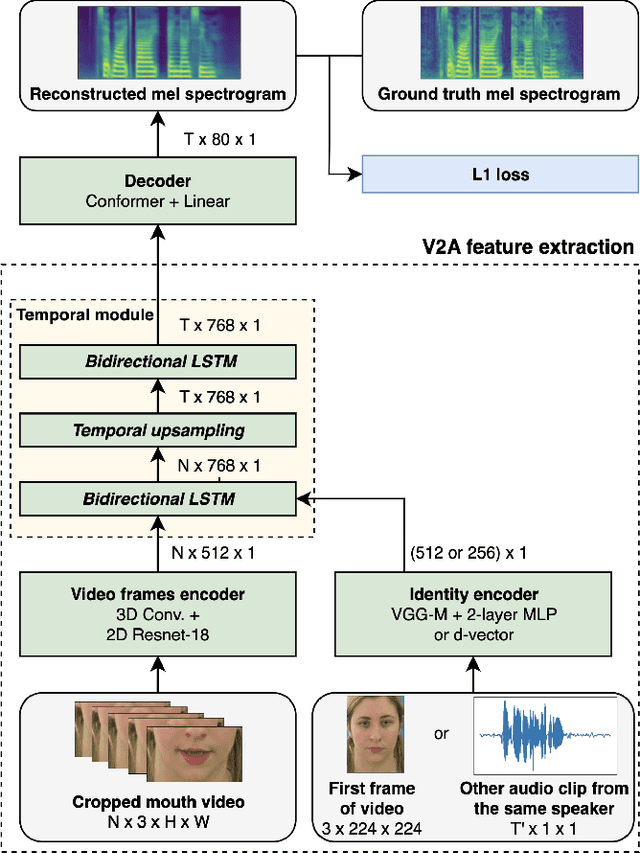
Video-to-speech synthesis is the task of reconstructing the speech signal from a silent video of a speaker. Most established approaches to date involve a two-step process, whereby an intermediate representation from the video, such as a spectrogram, is extracted first and then passed to a vocoder to produce the raw audio. Some recent work has focused on end-to-end synthesis, whereby the generation of raw audio and any intermediate representations is performed jointly. All such approaches involve training on data from almost exclusively audio-visual datasets, i.e. every audio sample has a corresponding video sample. This precludes the use of abundant audio-only datasets which may not have a corresponding visual modality (e.g. audiobooks, radio podcasts, speech recognition datasets etc.), as well as audio-only architectures that have been developed by the audio machine learning community over the years. In this paper we propose to train encoder-decoder models on more than 3,500 hours of audio data at 24kHz, and then use the pre-trained decoders to initialize the audio decoders for the video-to-speech synthesis task. The pre-training step uses audio samples only and does not require labels or corresponding samples from other modalities (visual, text). We demonstrate that this pre-training step improves the reconstructed speech and that it is an unexplored way to improve the quality of the generator in a cross-modal task while only requiring samples from one of the modalities. We conduct experiments using both raw audio and mel spectrograms as target outputs and benchmark our models with existing work.
Self-supervised representations in speech-based depression detection
May 20, 2023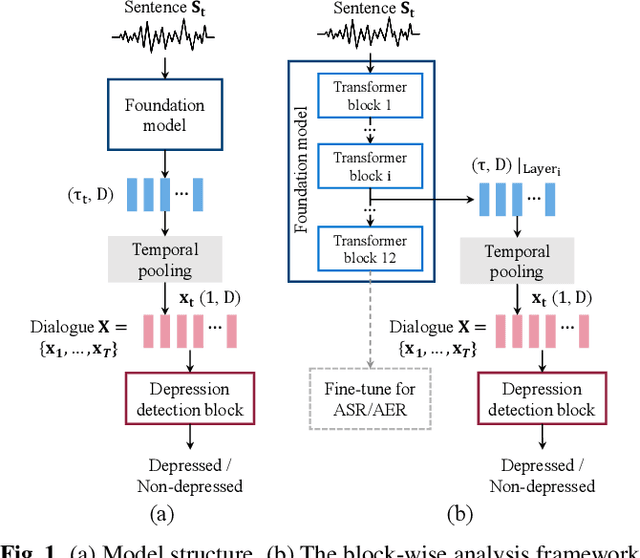
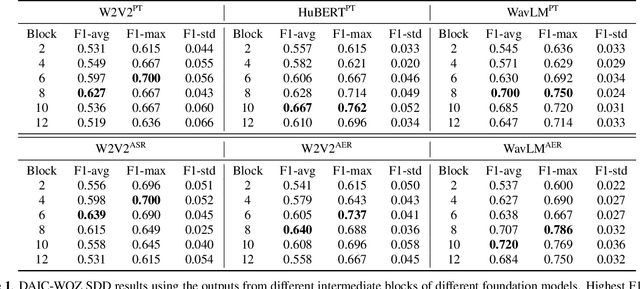
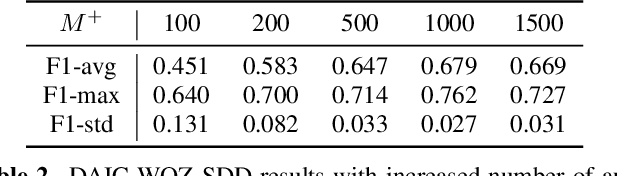
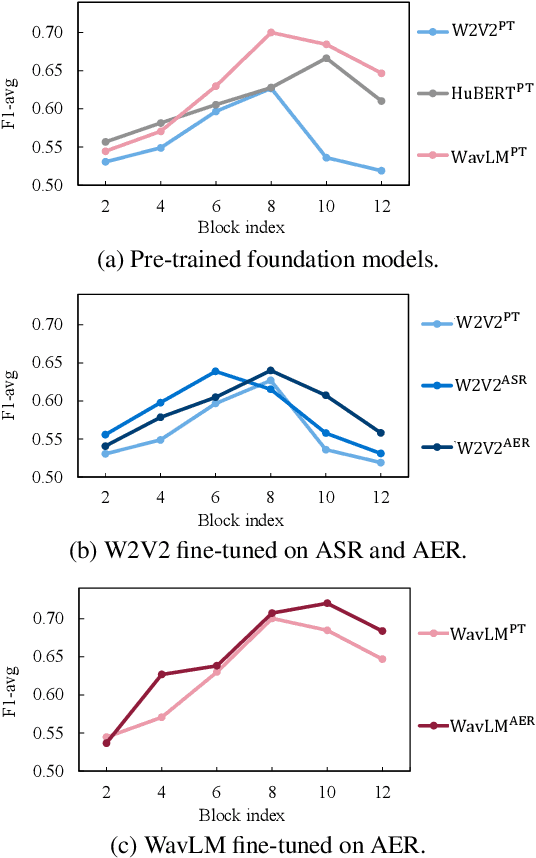
This paper proposes handling training data sparsity in speech-based automatic depression detection (SDD) using foundation models pre-trained with self-supervised learning (SSL). An analysis of SSL representations derived from different layers of pre-trained foundation models is first presented for SDD, which provides insight to suitable indicator for depression detection. Knowledge transfer is then performed from automatic speech recognition (ASR) and emotion recognition to SDD by fine-tuning the foundation models. Results show that the uses of oracle and ASR transcriptions yield similar SDD performance when the hidden representations of the ASR model is incorporated along with the ASR textual information. By integrating representations from multiple foundation models, state-of-the-art SDD results based on real ASR were achieved on the DAIC-WOZ dataset.
Learning Delays in Spiking Neural Networks using Dilated Convolutions with Learnable Spacings
Jun 30, 2023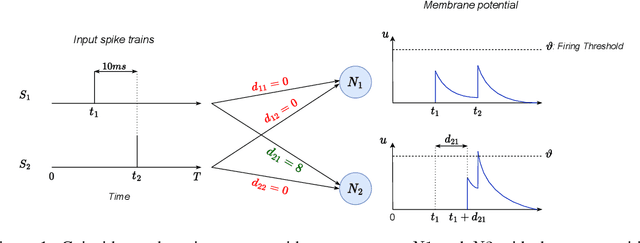

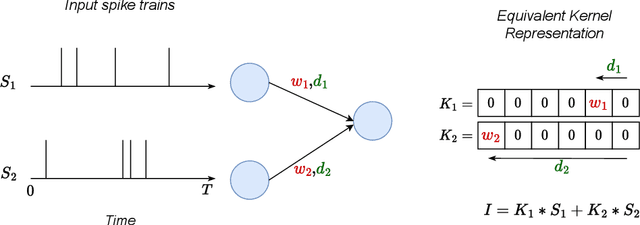
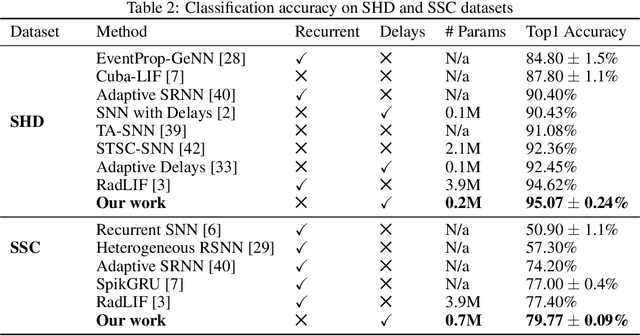
Spiking Neural Networks (SNNs) are a promising research direction for building power-efficient information processing systems, especially for temporal tasks such as speech recognition. In SNNs, delays refer to the time needed for one spike to travel from one neuron to another. These delays matter because they influence the spike arrival times, and it is well-known that spiking neurons respond more strongly to coincident input spikes. More formally, it has been shown theoretically that plastic delays greatly increase the expressivity in SNNs. Yet, efficient algorithms to learn these delays have been lacking. Here, we propose a new discrete-time algorithm that addresses this issue in deep feedforward SNNs using backpropagation, in an offline manner. To simulate delays between consecutive layers, we use 1D convolutions across time. The kernels contain only a few non-zero weights - one per synapse - whose positions correspond to the delays. These positions are learned together with the weights using the recently proposed Dilated Convolution with Learnable Spacings (DCLS). We evaluated our method on the Spiking Heidelberg Dataset (SHD) and the Spiking Speech Commands (SSC) benchmarks, which require detecting temporal patterns. We used feedforward SNNs with two hidden fully connected layers. We showed that fixed random delays help, and that learning them helps even more. Furthermore, our method outperformed the state-of-the-art in both SHD and SSC without using recurrent connections and with substantially fewer parameters. Our work demonstrates the potential of delay learning in developing accurate and precise models for temporal data processing. Our code is based on PyTorch / SpikingJelly and available at: https://github.com/Thvnvtos/SNN-delays
MMSpeech: Multi-modal Multi-task Encoder-Decoder Pre-training for Speech Recognition
Nov 29, 2022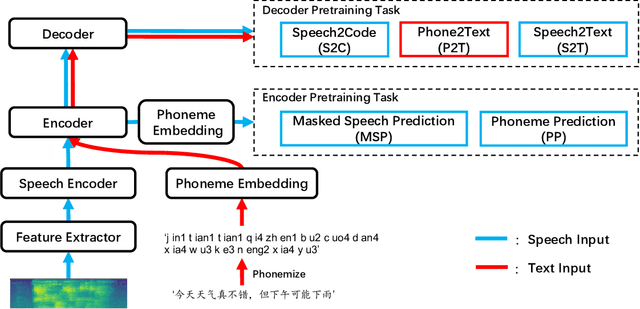
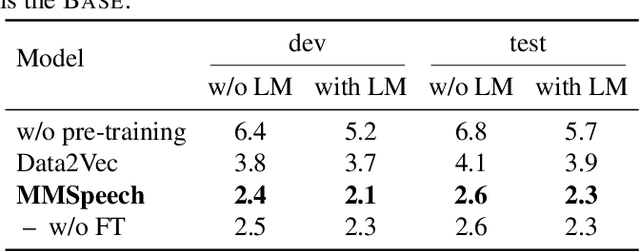
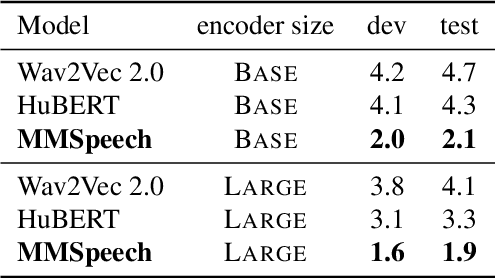

In this paper, we propose a novel multi-modal multi-task encoder-decoder pre-training framework (MMSpeech) for Mandarin automatic speech recognition (ASR), which employs both unlabeled speech and text data. The main difficulty in speech-text joint pre-training comes from the significant difference between speech and text modalities, especially for Mandarin speech and text. Unlike English and other languages with an alphabetic writing system, Mandarin uses an ideographic writing system where character and sound are not tightly mapped to one another. Therefore, we propose to introduce the phoneme modality into pre-training, which can help capture modality-invariant information between Mandarin speech and text. Specifically, we employ a multi-task learning framework including five self-supervised and supervised tasks with speech and text data. For end-to-end pre-training, we introduce self-supervised speech-to-pseudo-codes (S2C) and phoneme-to-text (P2T) tasks utilizing unlabeled speech and text data, where speech-pseudo-codes pairs and phoneme-text pairs are a supplement to the supervised speech-text pairs. To train the encoder to learn better speech representation, we introduce self-supervised masked speech prediction (MSP) and supervised phoneme prediction (PP) tasks to learn to map speech into phonemes. Besides, we directly add the downstream supervised speech-to-text (S2T) task into the pre-training process, which can further improve the pre-training performance and achieve better recognition results even without fine-tuning. Experiments on AISHELL-1 show that our proposed method achieves state-of-the-art performance, with a more than 40% relative improvement compared with other pre-training methods.