 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Learning Delays in Spiking Neural Networks using Dilated Convolutions with Learnable Spacings
Jun 30, 2023
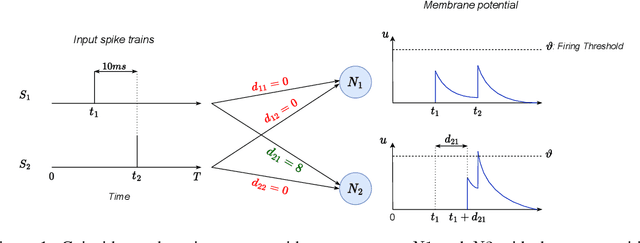

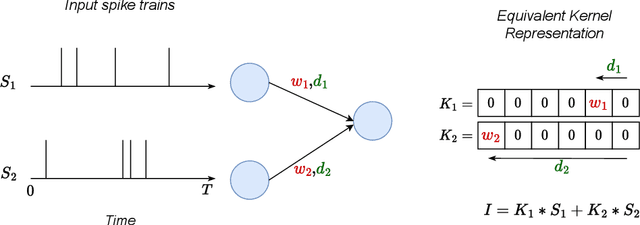
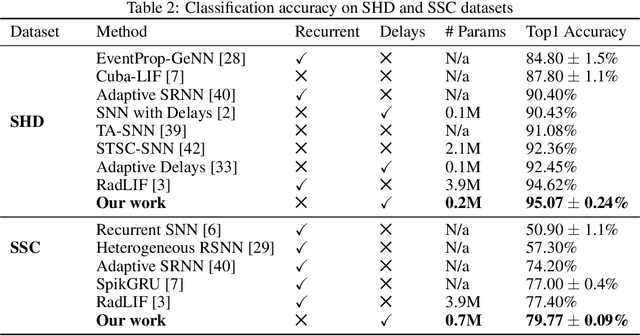
Spiking Neural Networks (SNNs) are a promising research direction for building power-efficient information processing systems, especially for temporal tasks such as speech recognition. In SNNs, delays refer to the time needed for one spike to travel from one neuron to another. These delays matter because they influence the spike arrival times, and it is well-known that spiking neurons respond more strongly to coincident input spikes. More formally, it has been shown theoretically that plastic delays greatly increase the expressivity in SNNs. Yet, efficient algorithms to learn these delays have been lacking. Here, we propose a new discrete-time algorithm that addresses this issue in deep feedforward SNNs using backpropagation, in an offline manner. To simulate delays between consecutive layers, we use 1D convolutions across time. The kernels contain only a few non-zero weights - one per synapse - whose positions correspond to the delays. These positions are learned together with the weights using the recently proposed Dilated Convolution with Learnable Spacings (DCLS). We evaluated our method on the Spiking Heidelberg Dataset (SHD) and the Spiking Speech Commands (SSC) benchmarks, which require detecting temporal patterns. We used feedforward SNNs with two hidden fully connected layers. We showed that fixed random delays help, and that learning them helps even more. Furthermore, our method outperformed the state-of-the-art in both SHD and SSC without using recurrent connections and with substantially fewer parameters. Our work demonstrates the potential of delay learning in developing accurate and precise models for temporal data processing. Our code is based on PyTorch / SpikingJelly and available at: https://github.com/Thvnvtos/SNN-delays
Masked Audio Text Encoders are Effective Multi-Modal Rescorers
May 24, 2023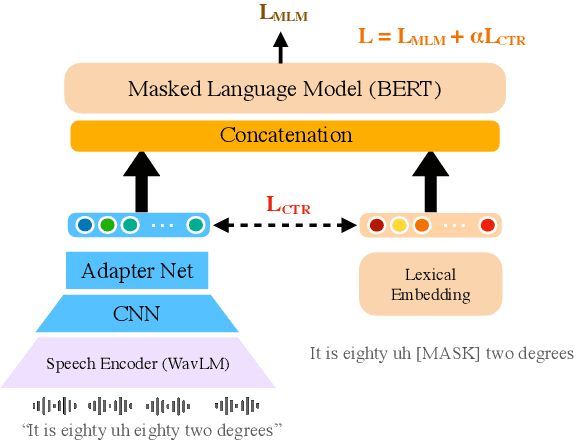
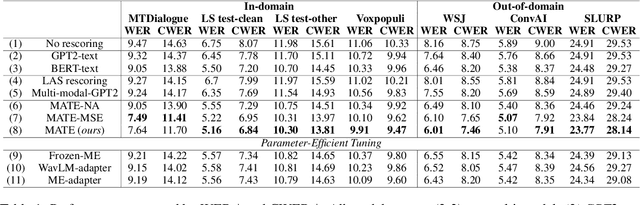
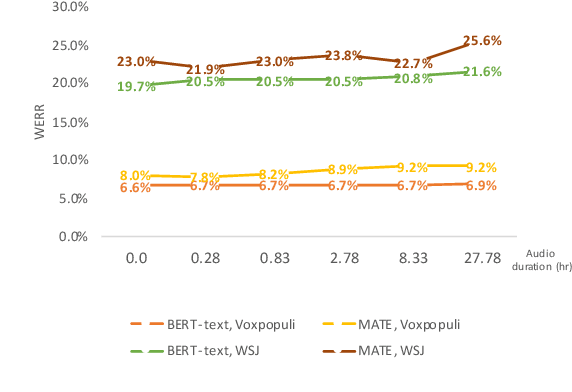
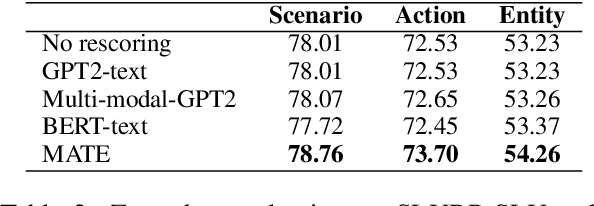
Masked Language Models (MLMs) have proven to be effective for second-pass rescoring in Automatic Speech Recognition (ASR) systems. In this work, we propose Masked Audio Text Encoder (MATE), a multi-modal masked language model rescorer which incorporates acoustic representations into the input space of MLM. We adopt contrastive learning for effectively aligning the modalities by learning shared representations. We show that using a multi-modal rescorer is beneficial for domain generalization of the ASR system when target domain data is unavailable. MATE reduces word error rate (WER) by 4%-16% on in-domain, and 3%-7% on out-of-domain datasets, over the text-only baseline. Additionally, with very limited amount of training data (0.8 hours), MATE achieves a WER reduction of 8%-23% over the first-pass baseline.
Adapting Multi-Lingual ASR Models for Handling Multiple Talkers
May 30, 2023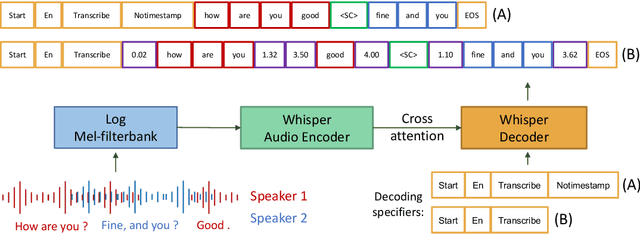
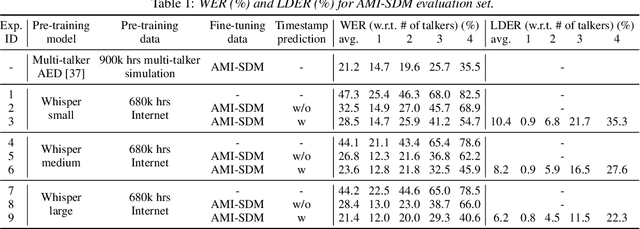
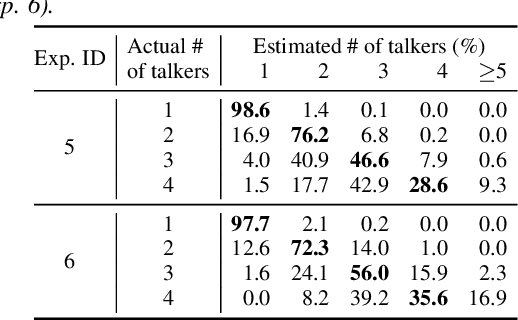
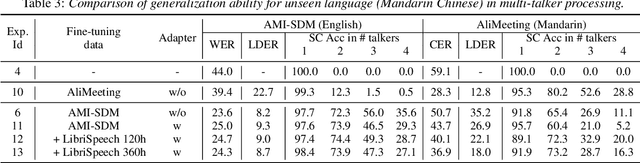
State-of-the-art large-scale universal speech models (USMs) show a decent automatic speech recognition (ASR) performance across multiple domains and languages. However, it remains a challenge for these models to recognize overlapped speech, which is often seen in meeting conversations. We propose an approach to adapt USMs for multi-talker ASR. We first develop an enhanced version of serialized output training to jointly perform multi-talker ASR and utterance timestamp prediction. That is, we predict the ASR hypotheses for all speakers, count the speakers, and estimate the utterance timestamps at the same time. We further introduce a lightweight adapter module to maintain the multilingual property of the USMs even when we perform the adaptation with only a single language. Experimental results obtained using the AMI and AliMeeting corpora show that our proposed approach effectively transfers the USMs to a strong multilingual multi-talker ASR model with timestamp prediction capability.
Bridging the Granularity Gap for Acoustic Modeling
May 27, 2023
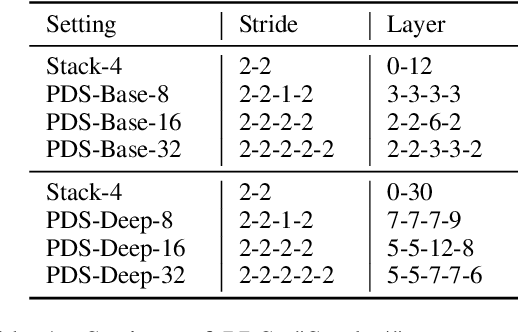
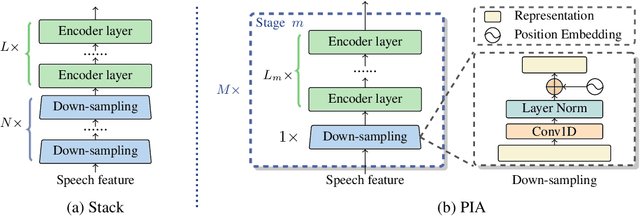
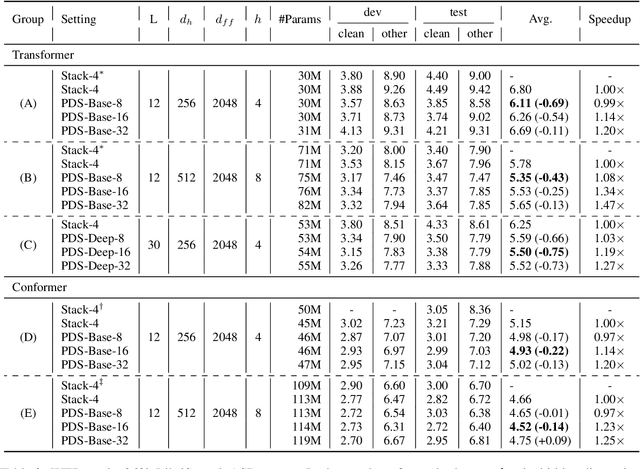
While Transformer has become the de-facto standard for speech, modeling upon the fine-grained frame-level features remains an open challenge of capturing long-distance dependencies and distributing the attention weights. We propose \textit{Progressive Down-Sampling} (PDS) which gradually compresses the acoustic features into coarser-grained units containing more complete semantic information, like text-level representation. In addition, we develop a representation fusion method to alleviate information loss that occurs inevitably during high compression. In this way, we compress the acoustic features into 1/32 of the initial length while achieving better or comparable performances on the speech recognition task. And as a bonus, it yields inference speedups ranging from 1.20$\times$ to 1.47$\times$. By reducing the modeling burden, we also achieve competitive results when training on the more challenging speech translation task.
Multi-task learning of speech and speaker recognition
Feb 24, 2023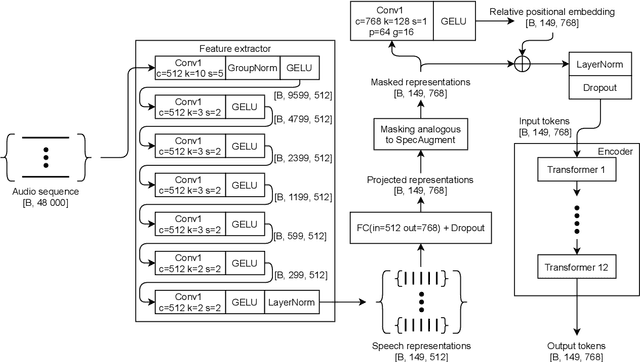
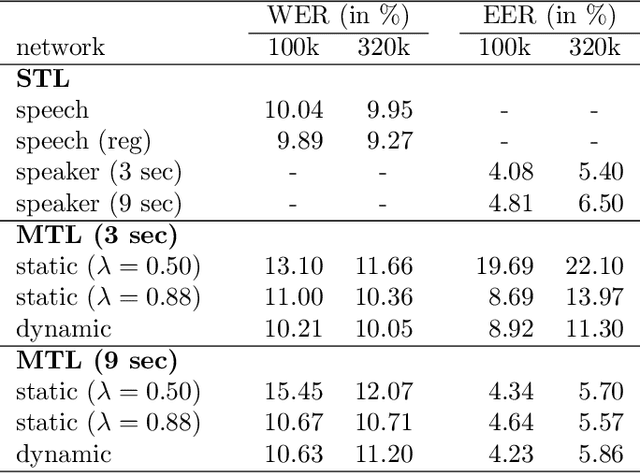
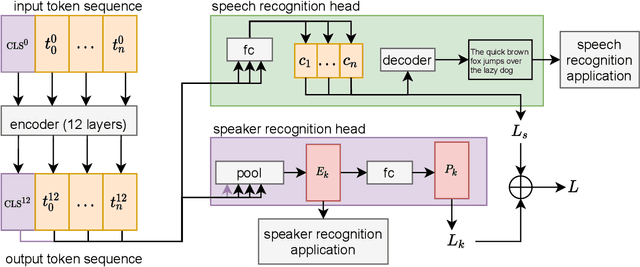
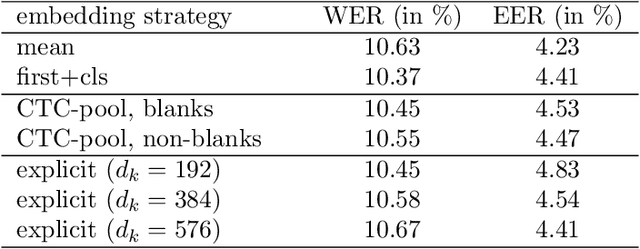
We study multi-task learning for two orthogonal speech technology tasks: speech and speaker recognition. We use wav2vec2 as a base architecture with two task-specific output heads. We experiment with different methods to mix speaker and speech information in the output embedding sequence, and propose a simple dynamic approach to balance the speech and speaker recognition loss functions. Our multi-task learning networks can produce a shared speaker and speech embedding, which are evaluated on the LibriSpeech and VoxCeleb test sets, and achieve a performance comparable to separate single-task models. Code is available at https://github.com/nikvaessen/2022-repo-mt-w2v2.
Unified End-to-End Speech Recognition and Endpointing for Fast and Efficient Speech Systems
Nov 01, 2022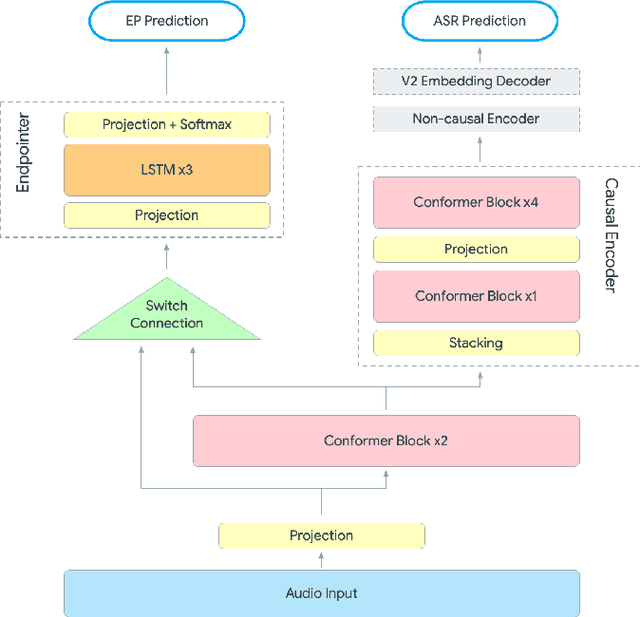
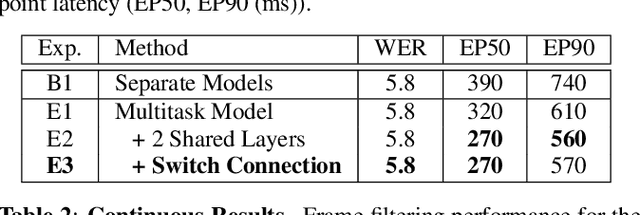
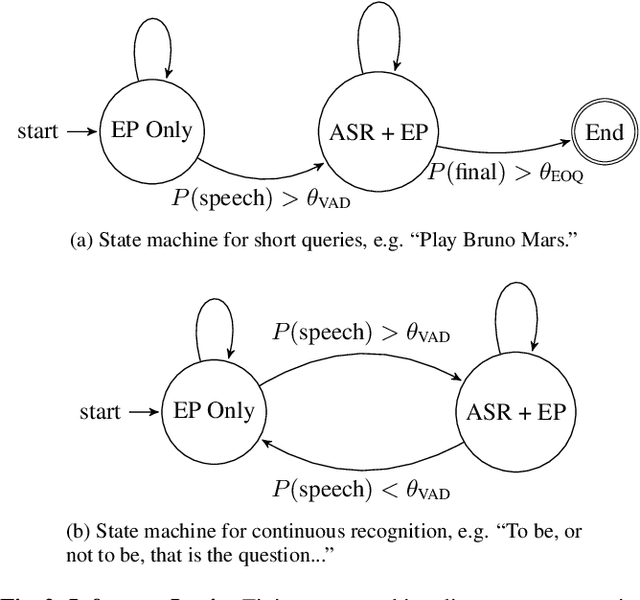
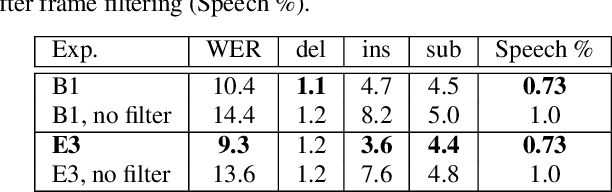
Automatic speech recognition (ASR) systems typically rely on an external endpointer (EP) model to identify speech boundaries. In this work, we propose a method to jointly train the ASR and EP tasks in a single end-to-end (E2E) multitask model, improving EP quality by optionally leveraging information from the ASR audio encoder. We introduce a "switch" connection, which trains the EP to consume either the audio frames directly or low-level latent representations from the ASR model. This results in a single E2E model that can be used during inference to perform frame filtering at low cost, and also make high quality end-of-query (EOQ) predictions based on ongoing ASR computation. We present results on a voice search test set showing that, compared to separate single-task models, this approach reduces median endpoint latency by 120 ms (30.8% reduction), and 90th percentile latency by 170 ms (23.0% reduction), without regressing word error rate. For continuous recognition, WER improves by 10.6% (relative).
Deep Learning Enabled Semantic Communications with Speech Recognition and Synthesis
May 09, 2022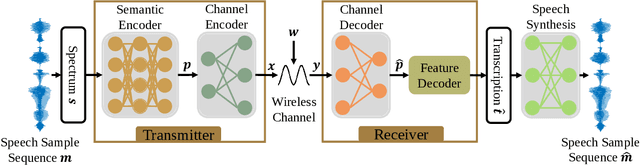
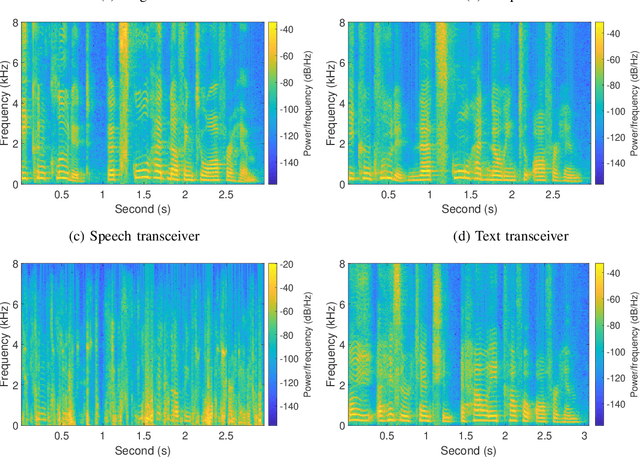
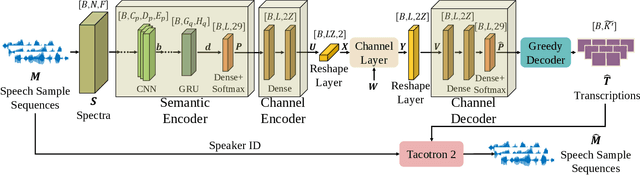
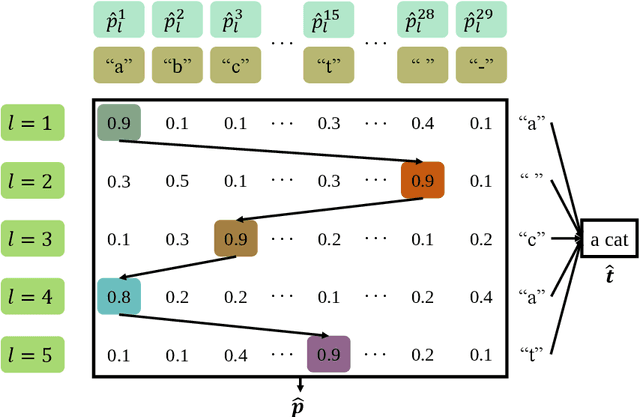
In this paper, we develop a deep learning based semantic communication system for speech transmission, named DeepSC-ST. We take the speech recognition and speech synthesis as the transmission tasks of the communication system, respectively. First, the speech recognition-related semantic features are extracted for transmission by a joint semantic-channel encoder and the text is recovered at the receiver based on the received semantic features, which significantly reduces the required amount of data transmission without performance degradation. Then, we perform speech synthesis at the receiver, which dedicates to re-generate the speech signals by feeding the recognized text transcription into a neural network based speech synthesis module. To enable the DeepSC-ST adaptive to dynamic channel environments, we identify a robust model to cope with different channel conditions. According to the simulation results, the proposed DeepSC-ST significantly outperforms conventional communication systems, especially in the low signal-to-noise ratio (SNR) regime. A demonstration is further developed as a proof-of-concept of the DeepSC-ST.
Self-supervised representations in speech-based depression detection
May 20, 2023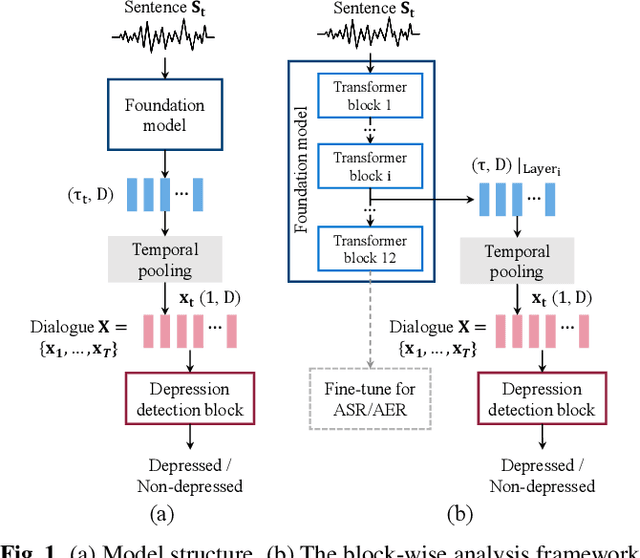
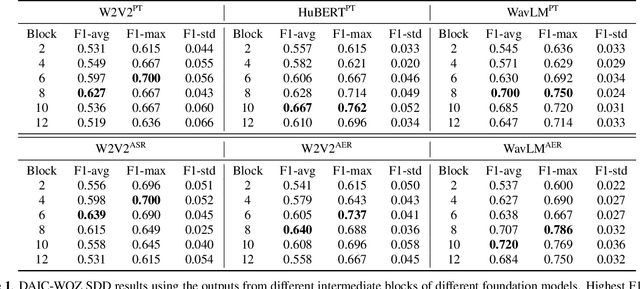
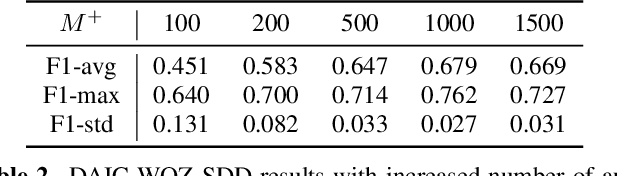
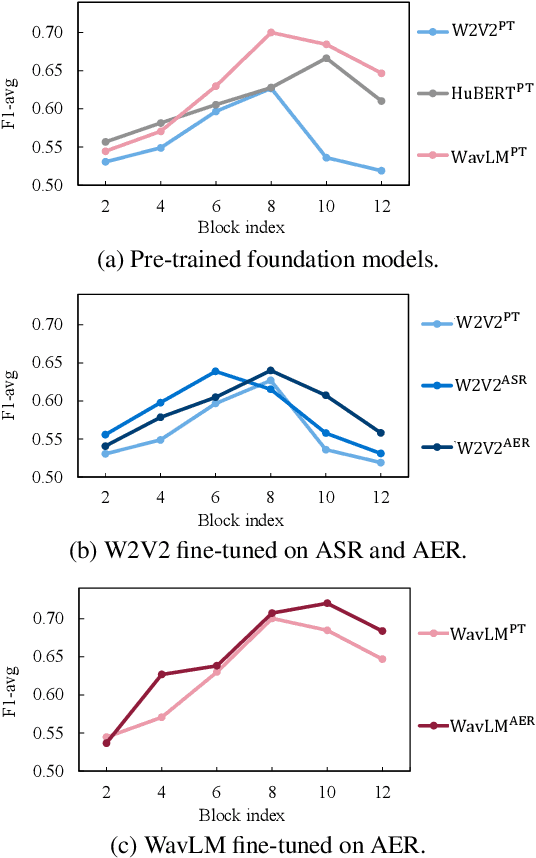
This paper proposes handling training data sparsity in speech-based automatic depression detection (SDD) using foundation models pre-trained with self-supervised learning (SSL). An analysis of SSL representations derived from different layers of pre-trained foundation models is first presented for SDD, which provides insight to suitable indicator for depression detection. Knowledge transfer is then performed from automatic speech recognition (ASR) and emotion recognition to SDD by fine-tuning the foundation models. Results show that the uses of oracle and ASR transcriptions yield similar SDD performance when the hidden representations of the ASR model is incorporated along with the ASR textual information. By integrating representations from multiple foundation models, state-of-the-art SDD results based on real ASR were achieved on the DAIC-WOZ dataset.
End-to-End Integration of Speech Recognition, Dereverberation, Beamforming, and Self-Supervised Learning Representation
Oct 19, 2022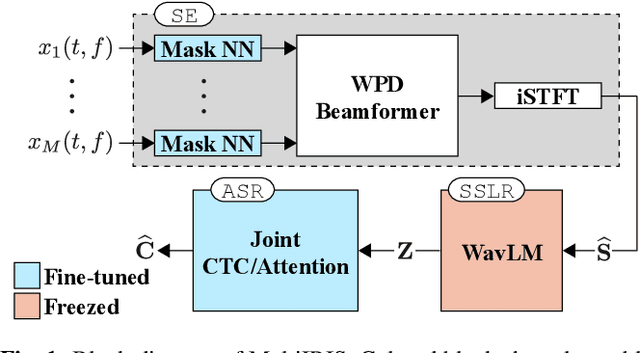
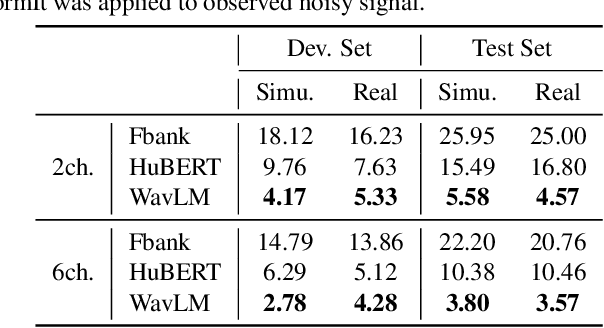
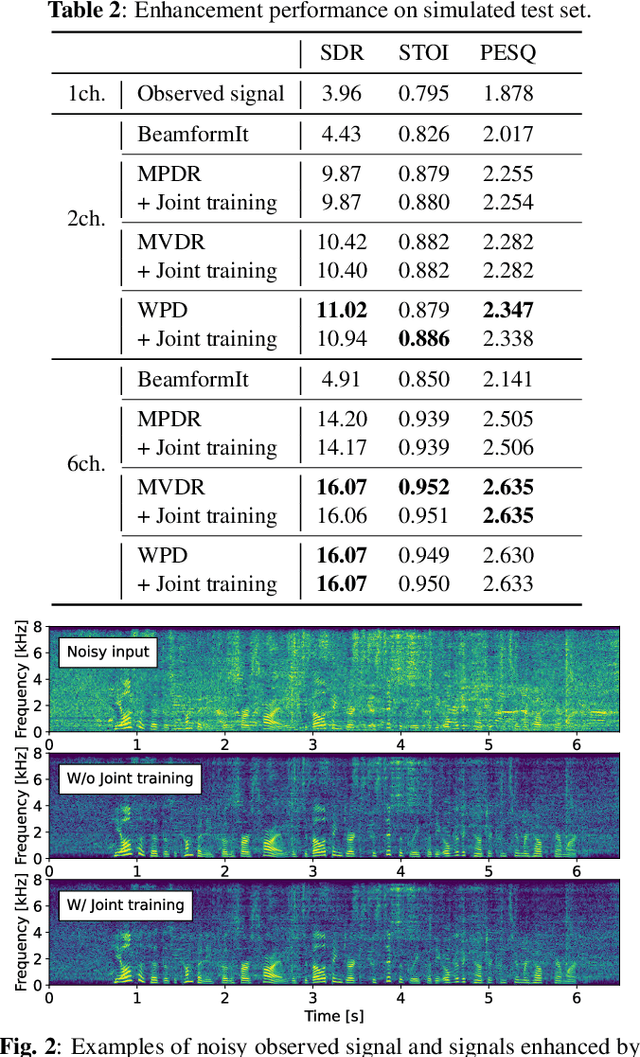
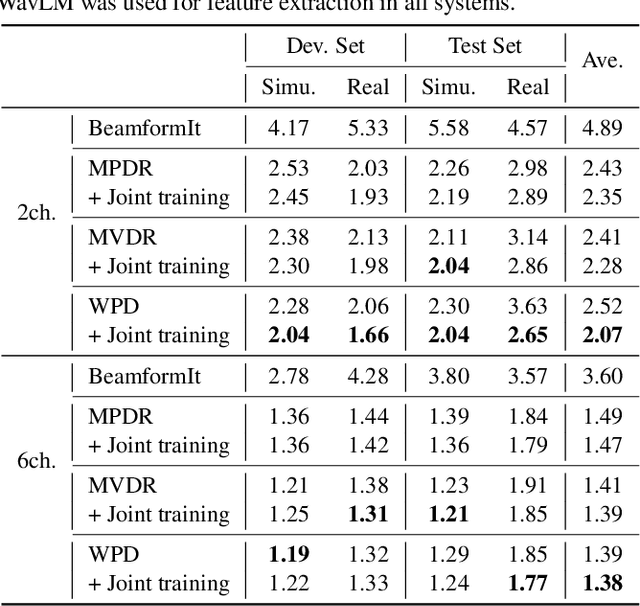
Self-supervised learning representation (SSLR) has demonstrated its significant effectiveness in automatic speech recognition (ASR), mainly with clean speech. Recent work pointed out the strength of integrating SSLR with single-channel speech enhancement for ASR in noisy environments. This paper further advances this integration by dealing with multi-channel input. We propose a novel end-to-end architecture by integrating dereverberation, beamforming, SSLR, and ASR within a single neural network. Our system achieves the best performance reported in the literature on the CHiME-4 6-channel track with a word error rate (WER) of 1.77%. While the WavLM-based strong SSLR demonstrates promising results by itself, the end-to-end integration with the weighted power minimization distortionless response beamformer, which simultaneously performs dereverberation and denoising, improves WER significantly. Its effectiveness is also validated on the REVERB dataset.
Filter and evolve: progressive pseudo label refining for semi-supervised automatic speech recognition
Oct 28, 2022
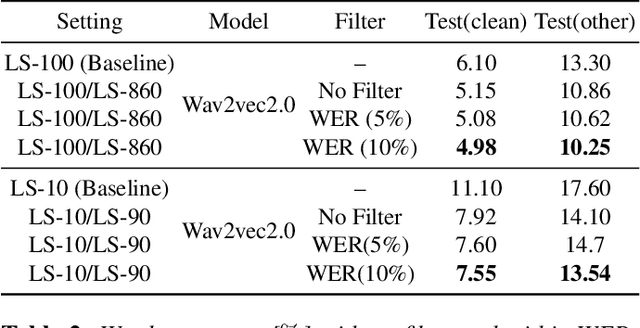
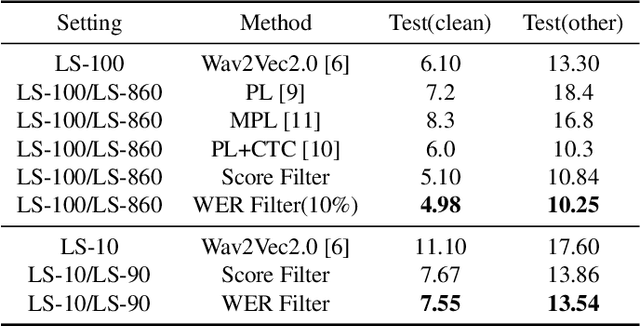
Fine tuning self supervised pretrained models using pseudo labels can effectively improve speech recognition performance. But, low quality pseudo labels can misguide decision boundaries and degrade performance. We propose a simple yet effective strategy to filter low quality pseudo labels to alleviate this problem. Specifically, pseudo-labels are produced over the entire training set and filtered via average probability scores calculated from the model output. Subsequently, an optimal percentage of utterances with high probability scores are considered reliable training data with trustworthy labels. The model is iteratively updated to correct the unreliable pseudo labels to minimize the effect of noisy labels. The process above is repeated until unreliable pseudo abels have been adequately corrected. Extensive experiments on LibriSpeech show that these filtered samples enable the refined model to yield more correct predictions, leading to better ASR performances under various experimental settings.