 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Master-ASR: Achieving Multilingual Scalability and Low-Resource Adaptation in ASR with Modular Learning
Jun 23, 2023
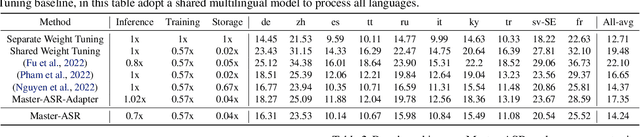
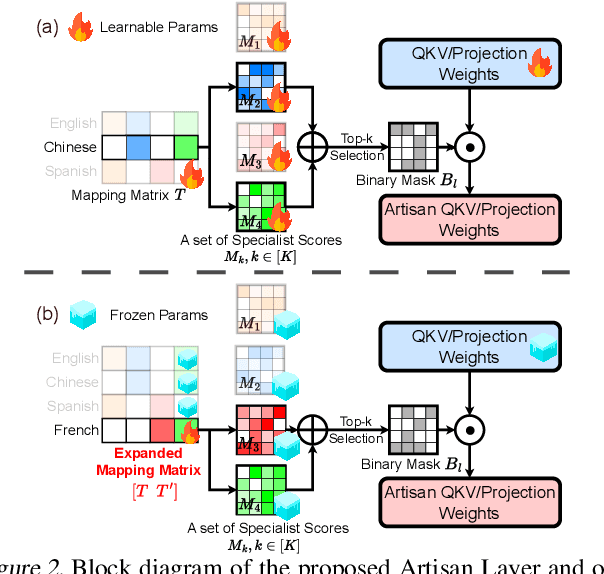
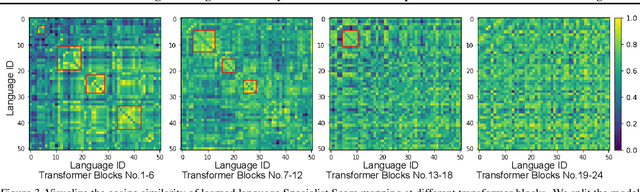
Despite the impressive performance recently achieved by automatic speech recognition (ASR), we observe two primary challenges that hinder its broader applications: (1) The difficulty of introducing scalability into the model to support more languages with limited training, inference, and storage overhead; (2) The low-resource adaptation ability that enables effective low-resource adaptation while avoiding over-fitting and catastrophic forgetting issues. Inspired by recent findings, we hypothesize that we can address the above challenges with modules widely shared across languages. To this end, we propose an ASR framework, dubbed \METHODNS, that, \textit{for the first time}, simultaneously achieves strong multilingual scalability and low-resource adaptation ability thanks to its modularize-then-assemble strategy. Specifically, \METHOD learns a small set of generalizable sub-modules and adaptively assembles them for different languages to reduce the multilingual overhead and enable effective knowledge transfer for low-resource adaptation. Extensive experiments and visualizations demonstrate that \METHOD can effectively discover language similarity and improve multilingual and low-resource ASR performance over state-of-the-art (SOTA) methods, e.g., under multilingual-ASR, our framework achieves a 0.13$\sim$2.41 lower character error rate (CER) with 30\% smaller inference overhead over SOTA solutions on multilingual ASR and a comparable CER, with nearly 50 times fewer trainable parameters over SOTA solutions on low-resource tuning, respectively.
SoftCorrect: Error Correction with Soft Detection for Automatic Speech Recognition
Dec 02, 2022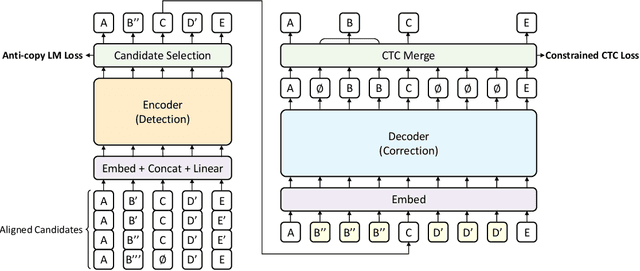
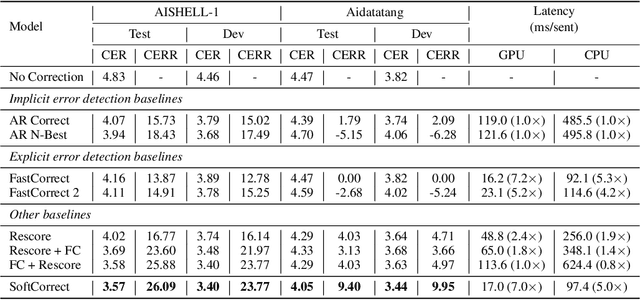
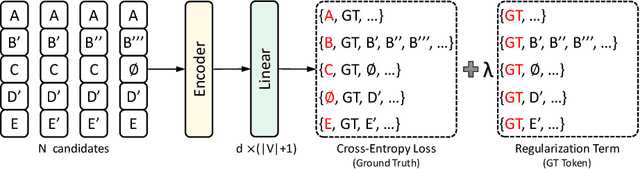
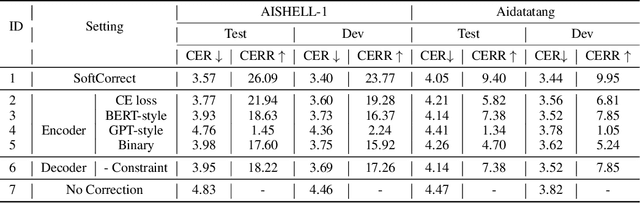
Error correction in automatic speech recognition (ASR) aims to correct those incorrect words in sentences generated by ASR models. Since recent ASR models usually have low word error rate (WER), to avoid affecting originally correct tokens, error correction models should only modify incorrect words, and therefore detecting incorrect words is important for error correction. Previous works on error correction either implicitly detect error words through target-source attention or CTC (connectionist temporal classification) loss, or explicitly locate specific deletion/substitution/insertion errors. However, implicit error detection does not provide clear signal about which tokens are incorrect and explicit error detection suffers from low detection accuracy. In this paper, we propose SoftCorrect with a soft error detection mechanism to avoid the limitations of both explicit and implicit error detection. Specifically, we first detect whether a token is correct or not through a probability produced by a dedicatedly designed language model, and then design a constrained CTC loss that only duplicates the detected incorrect tokens to let the decoder focus on the correction of error tokens. Compared with implicit error detection with CTC loss, SoftCorrect provides explicit signal about which words are incorrect and thus does not need to duplicate every token but only incorrect tokens; compared with explicit error detection, SoftCorrect does not detect specific deletion/substitution/insertion errors but just leaves it to CTC loss. Experiments on AISHELL-1 and Aidatatang datasets show that SoftCorrect achieves 26.1% and 9.4% CER reduction respectively, outperforming previous works by a large margin, while still enjoying fast speed of parallel generation.
Can Contextual Biasing Remain Effective with Whisper and GPT-2?
Jun 02, 2023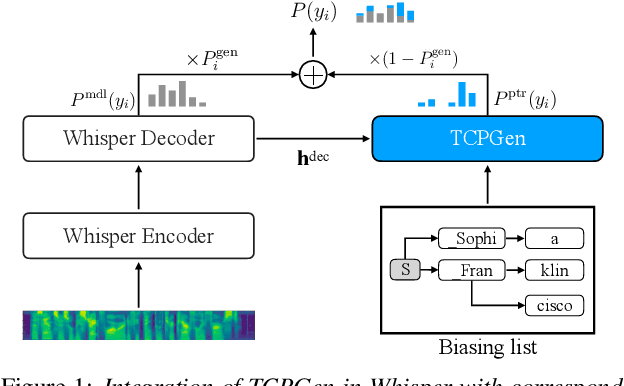
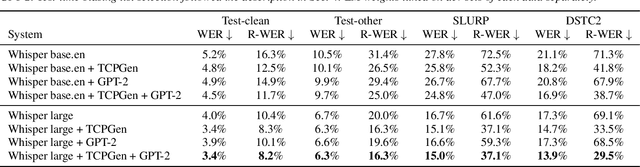


End-to-end automatic speech recognition (ASR) and large language models, such as Whisper and GPT-2, have recently been scaled to use vast amounts of training data. Despite the large amount of training data, infrequent content words that occur in a particular task may still exhibit poor ASR performance, with contextual biasing a possible remedy. This paper investigates the effectiveness of neural contextual biasing for Whisper combined with GPT-2. Specifically, this paper proposes integrating an adapted tree-constrained pointer generator (TCPGen) component for Whisper and a dedicated training scheme to dynamically adjust the final output without modifying any Whisper model parameters. Experiments across three datasets show a considerable reduction in errors on biasing words with a biasing list of 1000 words. Contextual biasing was more effective when applied to domain-specific data and can boost the performance of Whisper and GPT-2 without losing their generality.
Improved DeepFake Detection Using Whisper Features
Jun 02, 2023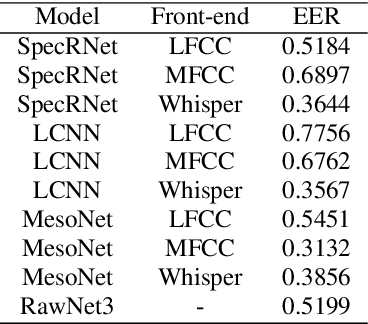
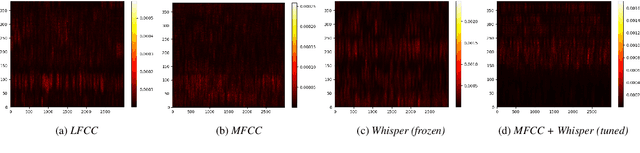

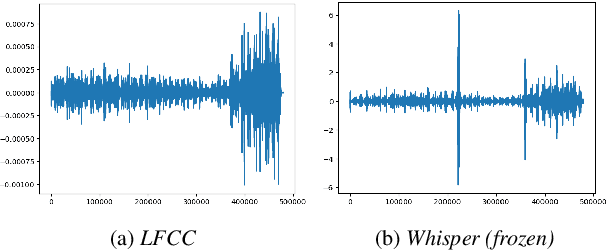
With a recent influx of voice generation methods, the threat introduced by audio DeepFake (DF) is ever-increasing. Several different detection methods have been presented as a countermeasure. Many methods are based on so-called front-ends, which, by transforming the raw audio, emphasize features crucial for assessing the genuineness of the audio sample. Our contribution contains investigating the influence of the state-of-the-art Whisper automatic speech recognition model as a DF detection front-end. We compare various combinations of Whisper and well-established front-ends by training 3 detection models (LCNN, SpecRNet, and MesoNet) on a widely used ASVspoof 2021 DF dataset and later evaluating them on the DF In-The-Wild dataset. We show that using Whisper-based features improves the detection for each model and outperforms recent results on the In-The-Wild dataset by reducing Equal Error Rate by 21%.
DisfluencyFixer: A tool to enhance Language Learning through Speech To Speech Disfluency Correction
May 26, 2023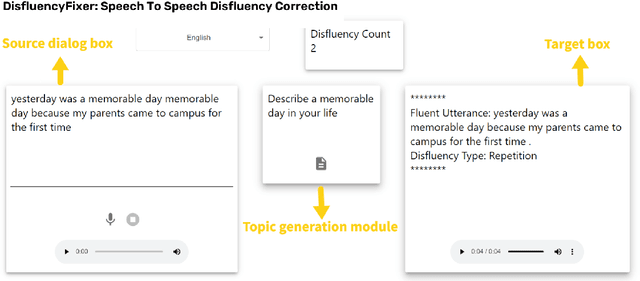
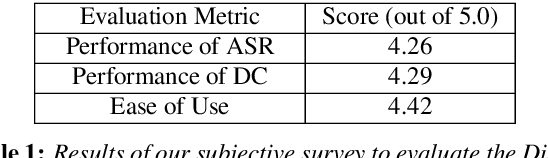
Conversational speech often consists of deviations from the speech plan, producing disfluent utterances that affect downstream NLP tasks. Removing these disfluencies is necessary to create fluent and coherent speech. This paper presents DisfluencyFixer, a tool that performs speech-to-speech disfluency correction in English and Hindi using a pipeline of Automatic Speech Recognition (ASR), Disfluency Correction (DC) and Text-To-Speech (TTS) models. Our proposed system removes disfluencies from input speech and returns fluent speech as output along with its transcript, disfluency type and total disfluency count in source utterance, providing a one-stop destination for language learners to improve the fluency of their speech. We evaluate the performance of our tool subjectively and receive scores of 4.26, 4.29 and 4.42 out of 5 in ASR performance, DC performance and ease-of-use of the system. Our tool can be accessed openly at the following link.
On the Robustness of Arabic Speech Dialect Identification
Jun 01, 2023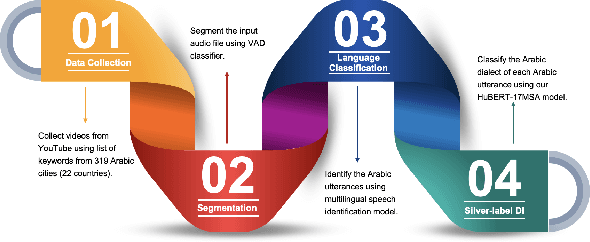
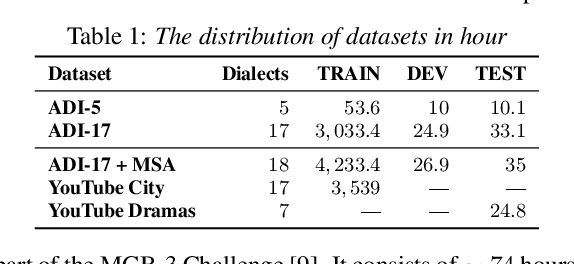


Arabic dialect identification (ADI) tools are an important part of the large-scale data collection pipelines necessary for training speech recognition models. As these pipelines require application of ADI tools to potentially out-of-domain data, we aim to investigate how vulnerable the tools may be to this domain shift. With self-supervised learning (SSL) models as a starting point, we evaluate transfer learning and direct classification from SSL features. We undertake our evaluation under rich conditions, with a goal to develop ADI systems from pretrained models and ultimately evaluate performance on newly collected data. In order to understand what factors contribute to model decisions, we carry out a careful human study of a subset of our data. Our analysis confirms that domain shift is a major challenge for ADI models. We also find that while self-training does alleviate this challenges, it may be insufficient for realistic conditions.
Exploration of Efficient End-to-End ASR using Discretized Input from Self-Supervised Learning
May 29, 2023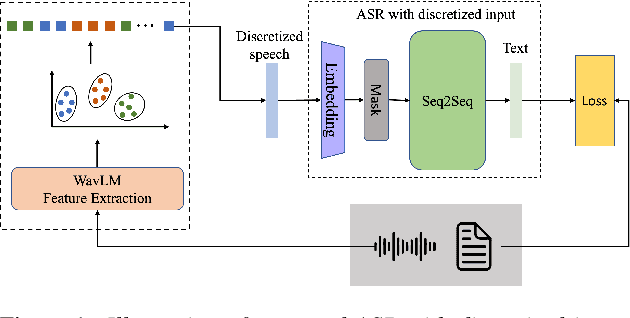
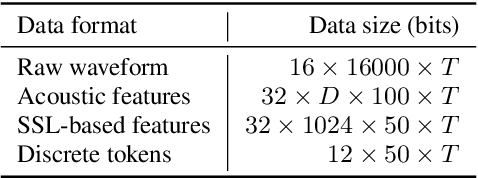
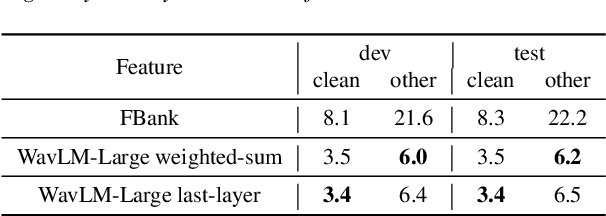
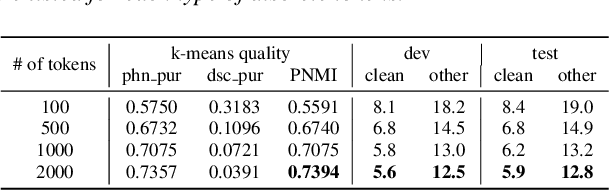
Self-supervised learning (SSL) of speech has shown impressive results in speech-related tasks, particularly in automatic speech recognition (ASR). While most methods employ the output of intermediate layers of the SSL model as real-valued features for downstream tasks, there is potential in exploring alternative approaches that use discretized token sequences. This approach offers benefits such as lower storage requirements and the ability to apply techniques from natural language processing. In this paper, we propose a new protocol that utilizes discretized token sequences in ASR tasks, which includes de-duplication and sub-word modeling to enhance the input sequence. It reduces computational cost by decreasing the length of the sequence. Our experiments on the LibriSpeech dataset demonstrate that our proposed protocol performs competitively with conventional ASR systems using continuous input features, while reducing computational and storage costs.
Retraining-free Customized ASR for Enharmonic Words Based on a Named-Entity-Aware Model and Phoneme Similarity Estimation
May 29, 2023End-to-end automatic speech recognition (E2E-ASR) has the potential to improve performance, but a specific issue that needs to be addressed is the difficulty it has in handling enharmonic words: named entities (NEs) with the same pronunciation and part of speech that are spelled differently. This often occurs with Japanese personal names that have the same pronunciation but different Kanji characters. Since such NE words tend to be important keywords, ASR easily loses user trust if it misrecognizes them. To solve these problems, this paper proposes a novel retraining-free customized method for E2E-ASRs based on a named-entity-aware E2E-ASR model and phoneme similarity estimation. Experimental results show that the proposed method improves the target NE character error rate by 35.7% on average relative to the conventional E2E-ASR model when selecting personal names as a target NE.
BIG-C: a Multimodal Multi-Purpose Dataset for Bemba
May 26, 2023
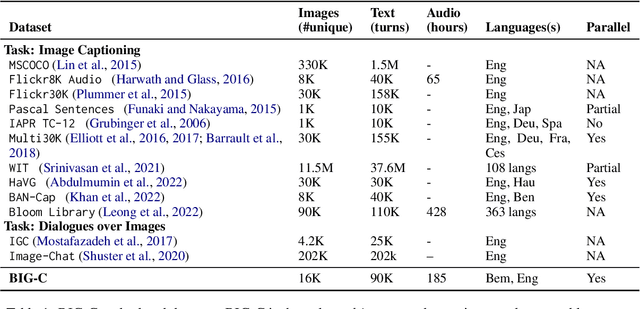
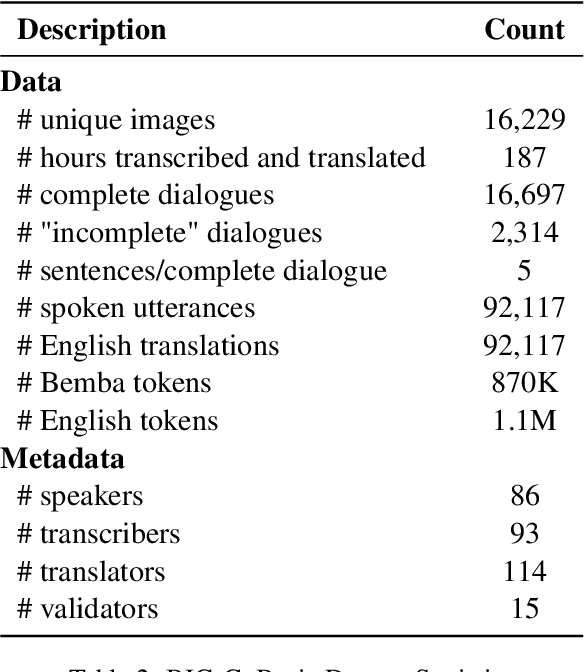

We present BIG-C (Bemba Image Grounded Conversations), a large multimodal dataset for Bemba. While Bemba is the most populous language of Zambia, it exhibits a dearth of resources which render the development of language technologies or language processing research almost impossible. The dataset is comprised of multi-turn dialogues between Bemba speakers based on images, transcribed and translated into English. There are more than 92,000 utterances/sentences, amounting to more than 180 hours of audio data with corresponding transcriptions and English translations. We also provide baselines on speech recognition (ASR), machine translation (MT) and speech translation (ST) tasks, and sketch out other potential future multimodal uses of our dataset. We hope that by making the dataset available to the research community, this work will foster research and encourage collaboration across the language, speech, and vision communities especially for languages outside the "traditionally" used high-resourced ones. All data and code are publicly available: https://github.com/csikasote/bigc.
Unsupervised domain adaptation for speech recognition with unsupervised error correction
Sep 24, 2022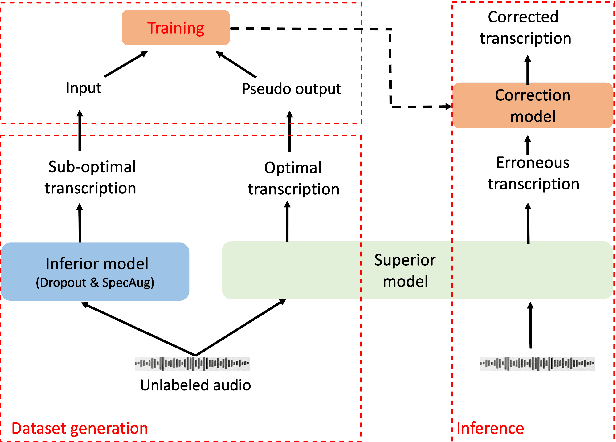
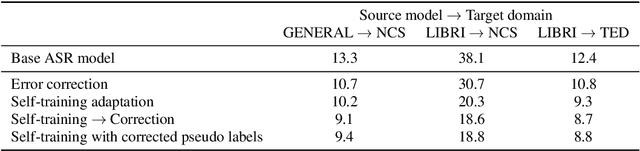
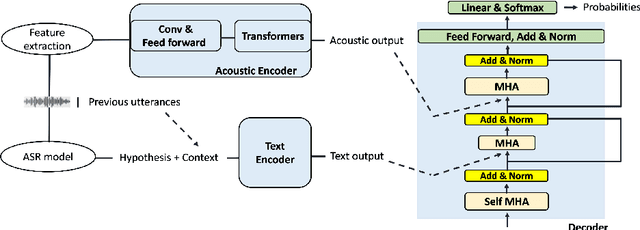

The transcription quality of automatic speech recognition (ASR) systems degrades significantly when transcribing audios coming from unseen domains. We propose an unsupervised error correction method for unsupervised ASR domain adaption, aiming to recover transcription errors caused by domain mismatch. Unlike existing correction methods that rely on transcribed audios for training, our approach requires only unlabeled data of the target domains in which a pseudo-labeling technique is applied to generate correction training samples. To reduce over-fitting to the pseudo data, we also propose an encoder-decoder correction model that can take into account additional information such as dialogue context and acoustic features. Experiment results show that our method obtains a significant word error rate (WER) reduction over non-adapted ASR systems. The correction model can also be applied on top of other adaptation approaches to bring an additional improvement of 10% relatively.