 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Alzheimer Disease Classification through ASR-based Transcriptions: Exploring the Impact of Punctuation and Pauses
Jun 06, 2023
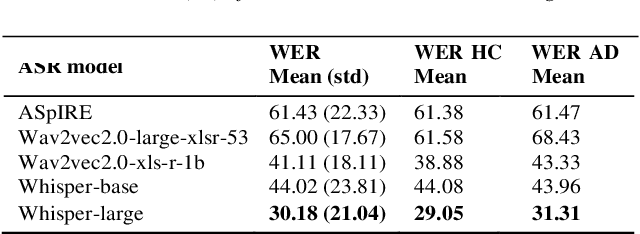
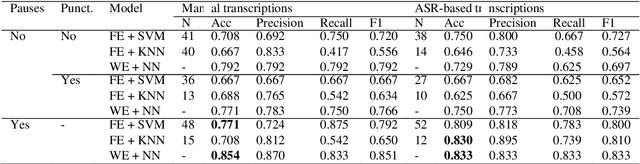
Alzheimer's Disease (AD) is the world's leading neurodegenerative disease, which often results in communication difficulties. Analysing speech can serve as a diagnostic tool for identifying the condition. The recent ADReSS challenge provided a dataset for AD classification and highlighted the utility of manual transcriptions. In this study, we used the new state-of-the-art Automatic Speech Recognition (ASR) model Whisper to obtain the transcriptions, which also include automatic punctuation. The classification models achieved test accuracy scores of 0.854 and 0.833 combining the pretrained FastText word embeddings and recurrent neural networks on manual and ASR transcripts respectively. Additionally, we explored the influence of including pause information and punctuation in the transcriptions. We found that punctuation only yielded minor improvements in some cases, whereas pause encoding aided AD classification for both manual and ASR transcriptions across all approaches investigated.
Sample-Efficient Unsupervised Domain Adaptation of Speech Recognition Systems A case study for Modern Greek
Dec 31, 2022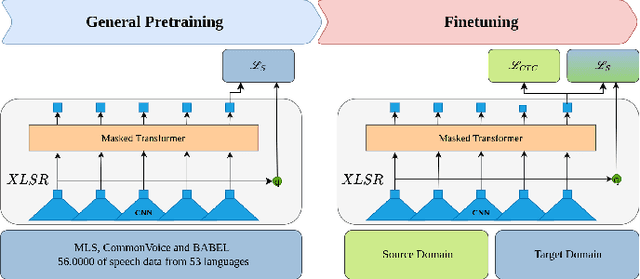
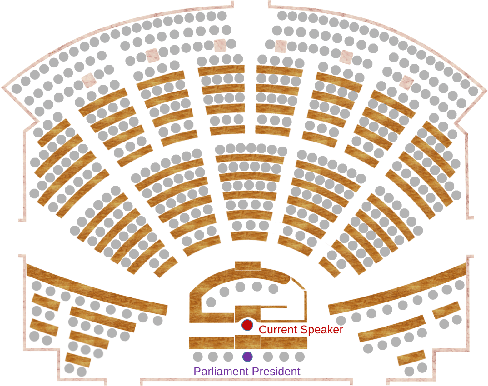
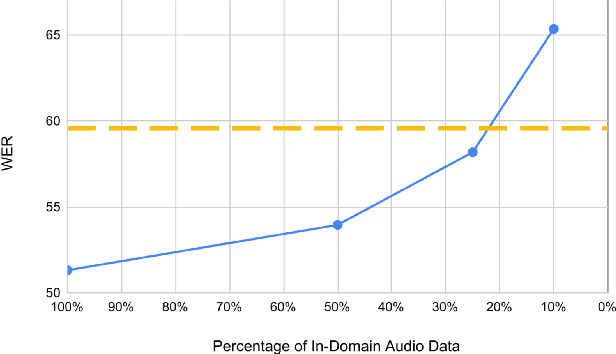

Modern speech recognition systems exhibits rapid performance degradation under domain shift. This issue is especially prevalent in data-scarce settings, such as low-resource languages, where diversity of training data is limited. In this work we propose M2DS2, a simple and sample-efficient finetuning strategy for large pretrained speech models, based on mixed source and target domain self-supervision. We find that including source domain self-supervision stabilizes training and avoids mode collapse of the latent representations. For evaluation, we collect HParl, a $120$ hour speech corpus for Greek, consisting of plenary sessions in the Greek Parliament. We merge HParl with two popular Greek corpora to create GREC-MD, a test-bed for multi-domain evaluation of Greek ASR systems. In our experiments we find that, while other Unsupervised Domain Adaptation baselines fail in this resource-constrained environment, M2DS2 yields significant improvements for cross-domain adaptation, even when a only a few hours of in-domain audio are available. When we relax the problem in a weakly supervised setting, we find that independent adaptation for audio using M2DS2 and language using simple LM augmentation techniques is particularly effective, yielding word error rates comparable to the fully supervised baselines.
Recent Progress in the CUHK Dysarthric Speech Recognition System
Jan 15, 2022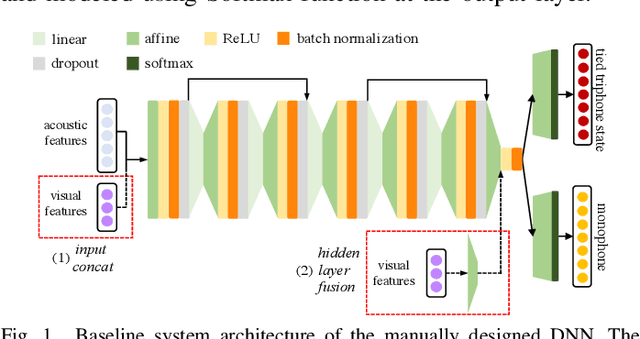
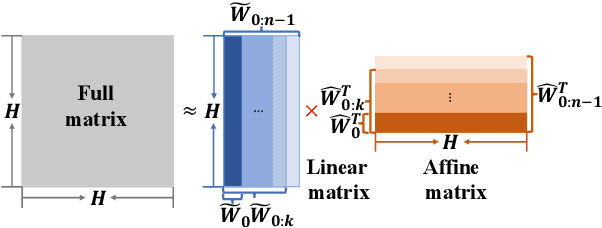
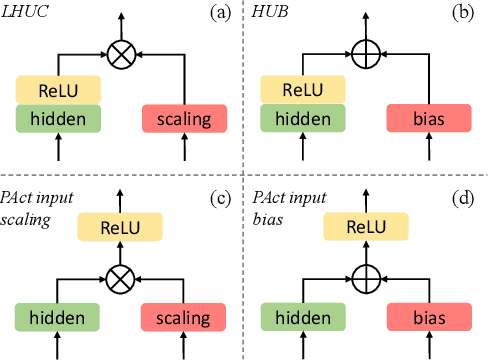
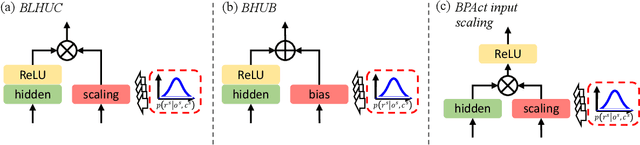
Despite the rapid progress of automatic speech recognition (ASR) technologies in the past few decades, recognition of disordered speech remains a highly challenging task to date. Disordered speech presents a wide spectrum of challenges to current data intensive deep neural networks (DNNs) based ASR technologies that predominantly target normal speech. This paper presents recent research efforts at the Chinese University of Hong Kong (CUHK) to improve the performance of disordered speech recognition systems on the largest publicly available UASpeech dysarthric speech corpus. A set of novel modelling techniques including neural architectural search, data augmentation using spectra-temporal perturbation, model based speaker adaptation and cross-domain generation of visual features within an audio-visual speech recognition (AVSR) system framework were employed to address the above challenges. The combination of these techniques produced the lowest published word error rate (WER) of 25.21% on the UASpeech test set 16 dysarthric speakers, and an overall WER reduction of 5.4% absolute (17.6% relative) over the CUHK 2018 dysarthric speech recognition system featuring a 6-way DNN system combination and cross adaptation of out-of-domain normal speech data trained systems. Bayesian model adaptation further allows rapid adaptation to individual dysarthric speakers to be performed using as little as 3.06 seconds of speech. The efficacy of these techniques were further demonstrated on a CUDYS Cantonese dysarthric speech recognition task.
Conformer Based Elderly Speech Recognition System for Alzheimer's Disease Detection
Jun 23, 2022
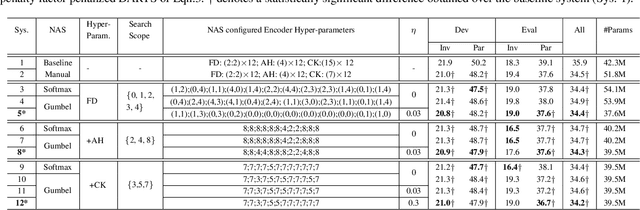
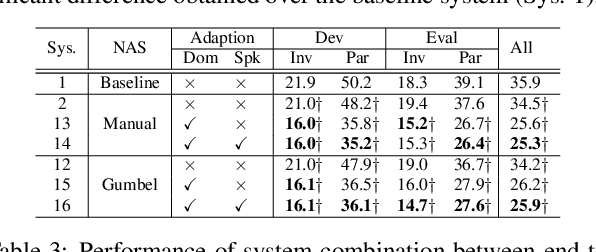
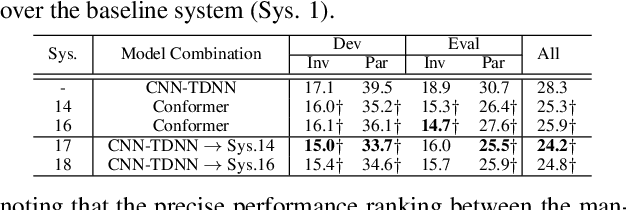
Early diagnosis of Alzheimer's disease (AD) is crucial in facilitating preventive care to delay further progression. This paper presents the development of a state-of-the-art Conformer based speech recognition system built on the DementiaBank Pitt corpus for automatic AD detection. The baseline Conformer system trained with speed perturbation and SpecAugment based data augmentation is significantly improved by incorporating a set of purposefully designed modeling features, including neural architecture search based auto-configuration of domain-specific Conformer hyper-parameters in addition to parameter fine-tuning; fine-grained elderly speaker adaptation using learning hidden unit contributions (LHUC); and two-pass cross-system rescoring based combination with hybrid TDNN systems. An overall word error rate (WER) reduction of 13.6% absolute (34.8% relative) was obtained on the evaluation data of 48 elderly speakers. Using the final systems' recognition outputs to extract textual features, the best-published speech recognition based AD detection accuracy of 91.7% was obtained.
Can Self-Supervised Learning solve the problem of child speech recognition?
Apr 06, 2022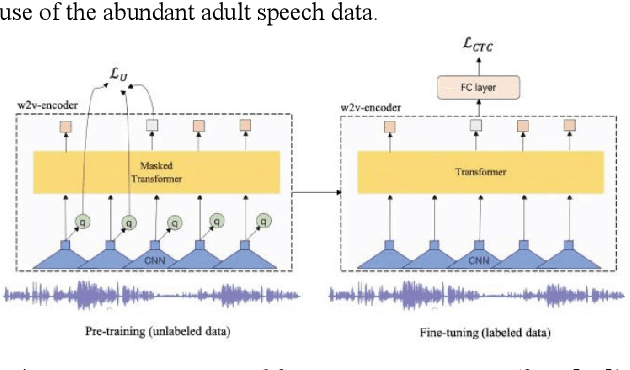
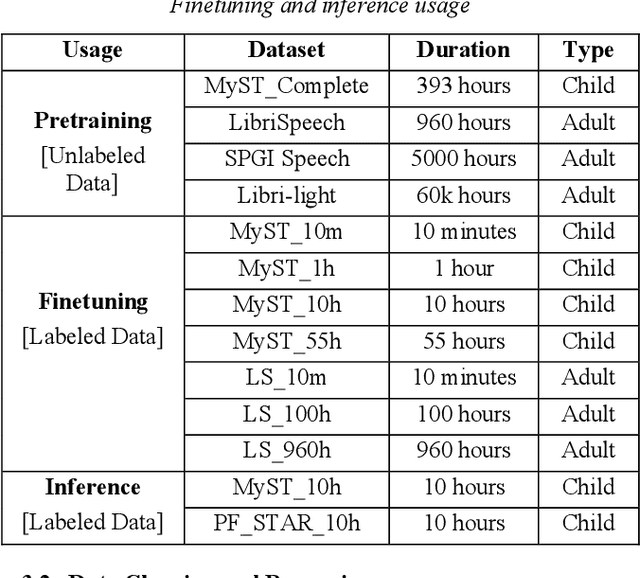
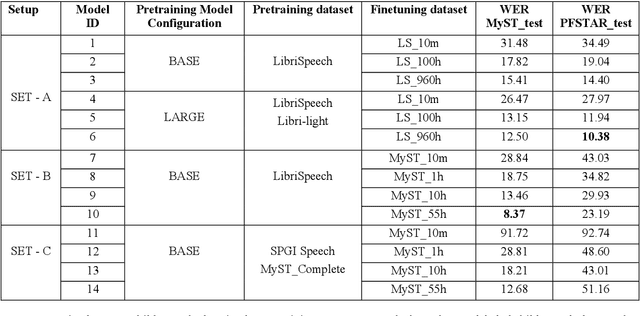
Despite recent advancements in deep learning technologies, Child Speech Recognition remains a challenging task. Current Automatic Speech Recognition (ASR) models required substantial amounts of annotated data for training, which is scarce. In this work, we explore using the ASR model, wav2vec2, with different pretraining and finetuning configurations for self supervised learning (SSL) towards improving automatic child speech recognition. The pretrained wav2vec2 models were finetuned using different amounts of child speech training data to discover the optimum amount of data required to finetune the model for the task of child ASR. Our trained model receives the best word error rate (WER) of 8.37 on the in domain MyST dataset and WER of 10.38 on the out of domain PFSTAR dataset. We do not use any Language Models (LM) in our experiments.
RASR2: The RWTH ASR Toolkit for Generic Sequence-to-sequence Speech Recognition
May 28, 2023
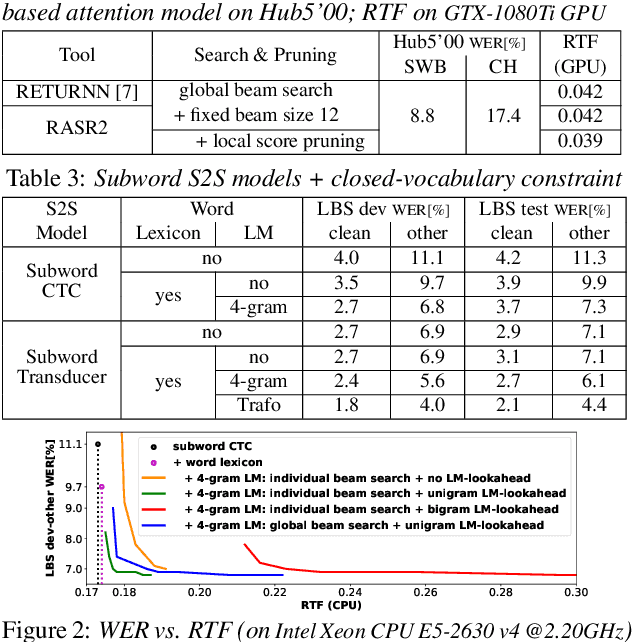
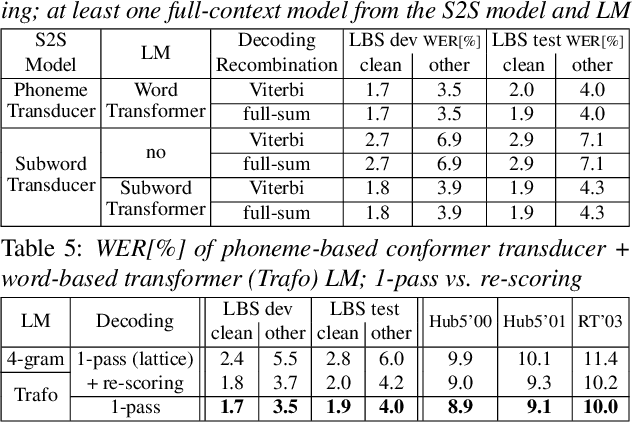
Modern public ASR tools usually provide rich support for training various sequence-to-sequence (S2S) models, but rather simple support for decoding open-vocabulary scenarios only. For closed-vocabulary scenarios, public tools supporting lexical-constrained decoding are usually only for classical ASR, or do not support all S2S models. To eliminate this restriction on research possibilities such as modeling unit choice, we present RASR2 in this work, a research-oriented generic S2S decoder implemented in C++. It offers a strong flexibility/compatibility for various S2S models, language models, label units/topologies and neural network architectures. It provides efficient decoding for both open- and closed-vocabulary scenarios based on a generalized search framework with rich support for different search modes and settings. We evaluate RASR2 with a wide range of experiments on both switchboard and Librispeech corpora. Our source code is public online.
Language-specific Characteristic Assistance for Code-switching Speech Recognition
Jun 29, 2022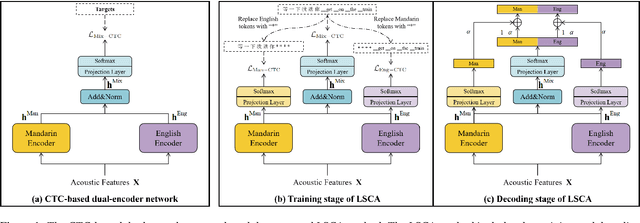
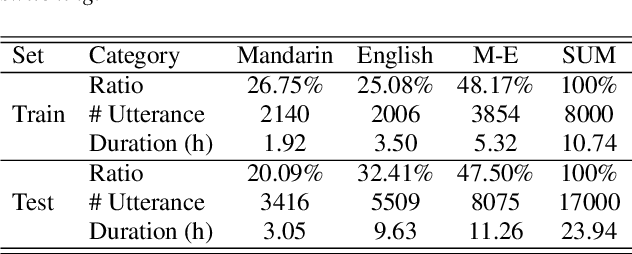

Dual-encoder structure successfully utilizes two language-specific encoders (LSEs) for code-switching speech recognition. Because LSEs are initialized by two pre-trained language-specific models (LSMs), the dual-encoder structure can exploit sufficient monolingual data and capture the individual language attributes. However, existing methods have no language constraints on LSEs and underutilize language-specific knowledge of LSMs. In this paper, we propose a language-specific characteristic assistance (LSCA) method to mitigate the above problems. Specifically, during training, we introduce two language-specific losses as language constraints and generate corresponding language-specific targets for them. During decoding, we take the decoding abilities of LSMs into account by combining the output probabilities of two LSMs and the mixture model to obtain the final predictions. Experiments show that either the training or decoding method of LSCA can improve the model's performance. Furthermore, the best result can obtain up to 15.4% relative error reduction on the code-switching test set by combining the training and decoding methods of LSCA. Moreover, the system can process code-switching speech recognition tasks well without extra shared parameters or even retraining based on two pre-trained LSMs by using our method.
AfriNames: Most ASR models "butcher" African Names
Jun 02, 2023
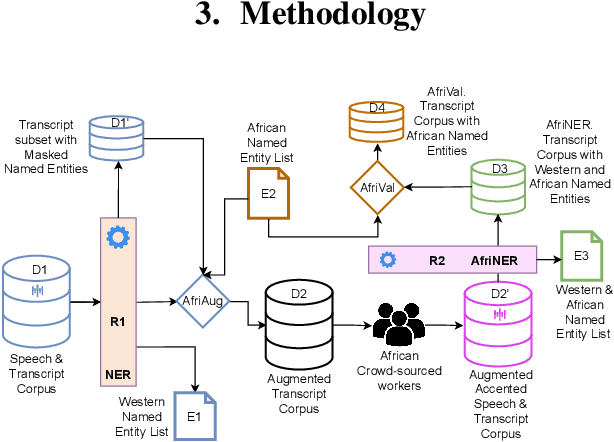
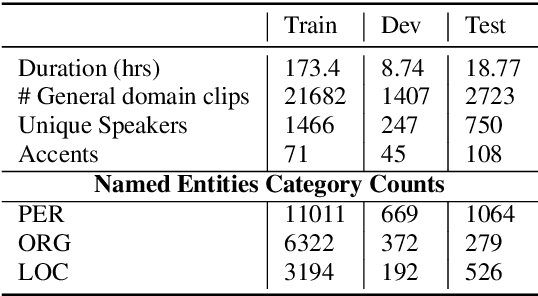
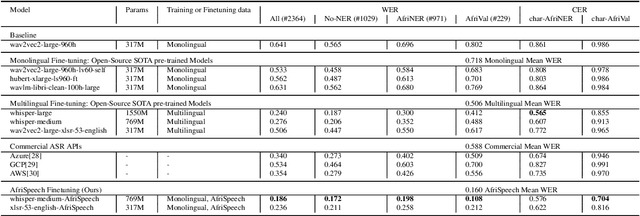
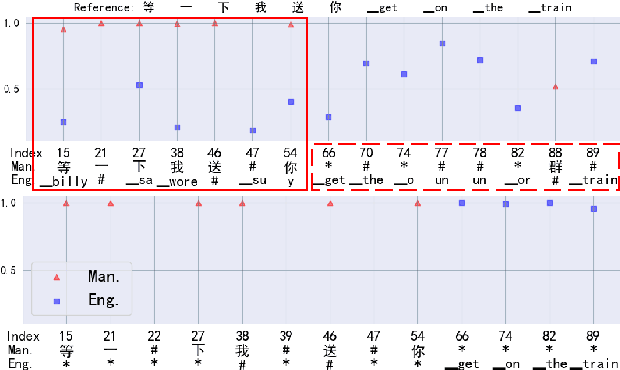
Useful conversational agents must accurately capture named entities to minimize error for downstream tasks, for example, asking a voice assistant to play a track from a certain artist, initiating navigation to a specific location, or documenting a laboratory result for a patient. However, where named entities such as ``Ukachukwu`` (Igbo), ``Lakicia`` (Swahili), or ``Ingabire`` (Rwandan) are spoken, automatic speech recognition (ASR) models' performance degrades significantly, propagating errors to downstream systems. We model this problem as a distribution shift and demonstrate that such model bias can be mitigated through multilingual pre-training, intelligent data augmentation strategies to increase the representation of African-named entities, and fine-tuning multilingual ASR models on multiple African accents. The resulting fine-tuned models show an 81.5\% relative WER improvement compared with the baseline on samples with African-named entities.
Adversarial Training For Low-Resource Disfluency Correction
Jun 10, 2023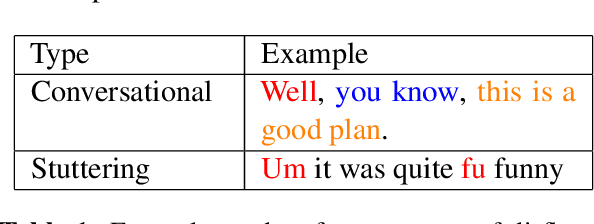
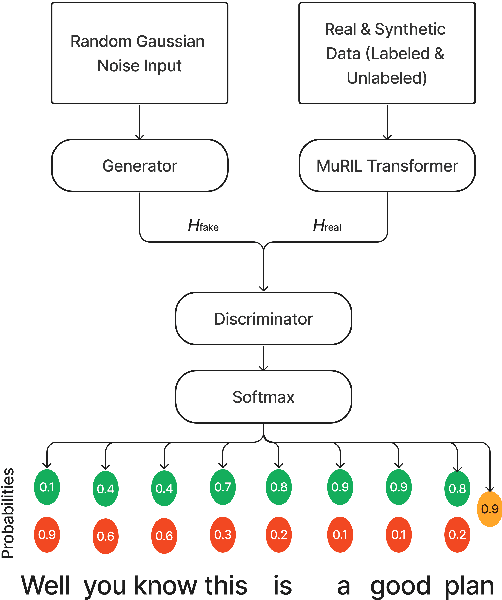
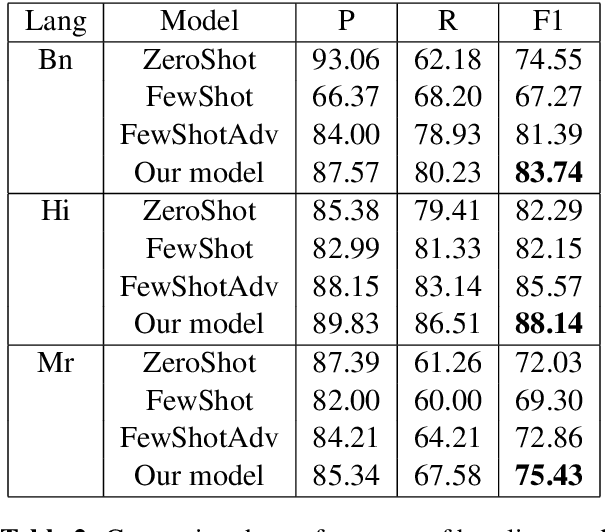
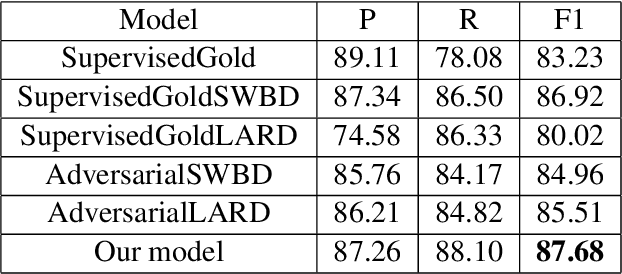
Disfluencies commonly occur in conversational speech. Speech with disfluencies can result in noisy Automatic Speech Recognition (ASR) transcripts, which affects downstream tasks like machine translation. In this paper, we propose an adversarially-trained sequence-tagging model for Disfluency Correction (DC) that utilizes a small amount of labeled real disfluent data in conjunction with a large amount of unlabeled data. We show the benefit of our proposed technique, which crucially depends on synthetically generated disfluent data, by evaluating it for DC in three Indian languages- Bengali, Hindi, and Marathi (all from the Indo-Aryan family). Our technique also performs well in removing stuttering disfluencies in ASR transcripts introduced by speech impairments. We achieve an average 6.15 points improvement in F1-score over competitive baselines across all three languages mentioned. To the best of our knowledge, we are the first to utilize adversarial training for DC and use it to correct stuttering disfluencies in English, establishing a new benchmark for this task.
Automatic Speech Recognition of Low-Resource Languages Based on Chukchi
Oct 11, 2022
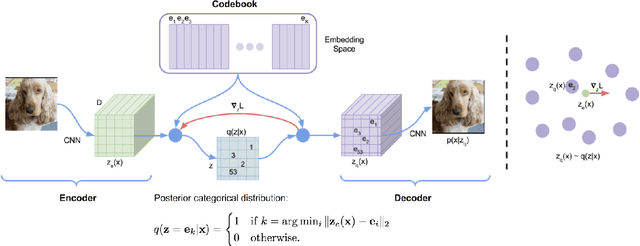
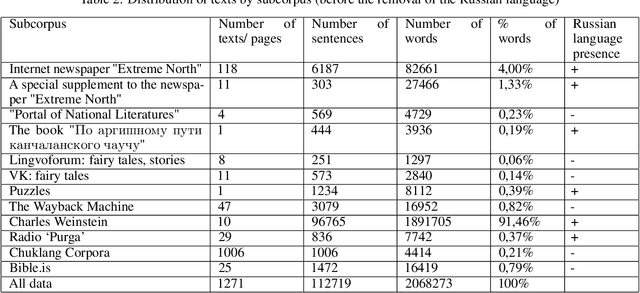
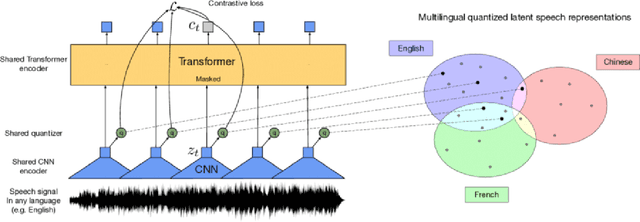
The following paper presents a project focused on the research and creation of a new Automatic Speech Recognition (ASR) based in the Chukchi language. There is no one complete corpus of the Chukchi language, so most of the work consisted in collecting audio and texts in the Chukchi language from open sources and processing them. We managed to collect 21:34:23 hours of audio recordings and 112,719 sentences (or 2,068,273 words) of text in the Chukchi language. The XLSR model was trained on the obtained data, which showed good results even with a small amount of data. Besides the fact that the Chukchi language is a low-resource language, it is also polysynthetic, which significantly complicates any automatic processing. Thus, the usual WER metric for evaluating ASR becomes less indicative for a polysynthetic language. However, the CER metric showed good results. The question of metrics for polysynthetic languages remains open.