 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Competitive and Resource Efficient Factored Hybrid HMM Systems are Simpler Than You Think
Jun 15, 2023

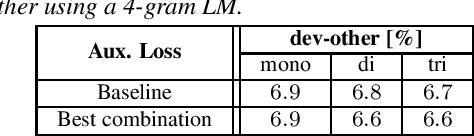

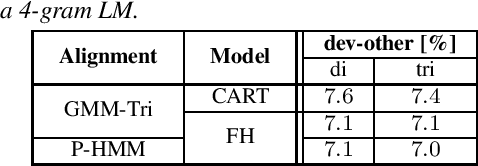
Building competitive hybrid hidden Markov model~(HMM) systems for automatic speech recognition~(ASR) requires a complex multi-stage pipeline consisting of several training criteria. The recent sequence-to-sequence models offer the advantage of having simpler pipelines that can start from-scratch. We propose a purely neural based single-stage from-scratch pipeline for a context-dependent hybrid HMM that offers similar simplicity. We use an alignment from a full-sum trained zero-order posterior HMM with a BLSTM encoder. We show that with this alignment we can build a Conformer factored hybrid that performs even better than both a state-of-the-art classic hybrid and a factored hybrid trained with alignments taken from more complex Gaussian mixture based systems. Our finding is confirmed on Switchboard 300h and LibriSpeech 960h tasks with comparable results to other approaches in the literature, and by additionally relying on a responsible choice of available computational resources.
Intermediate Fine-Tuning Using Imperfect Synthetic Speech for Improving Electrolaryngeal Speech Recognition
Nov 02, 2022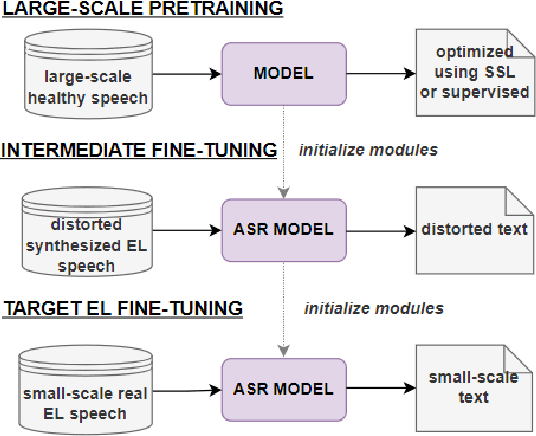
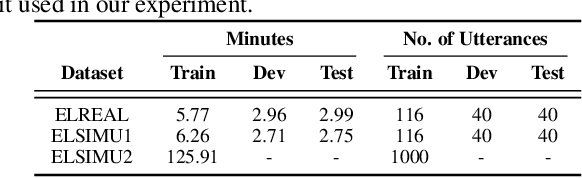
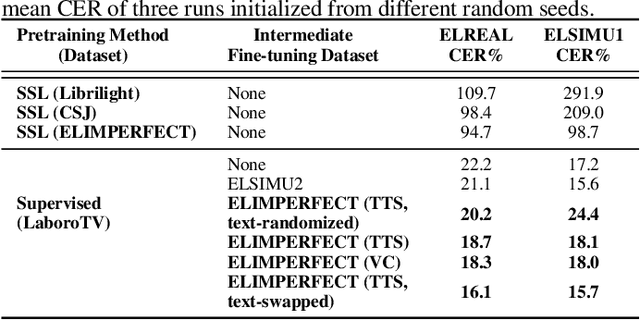
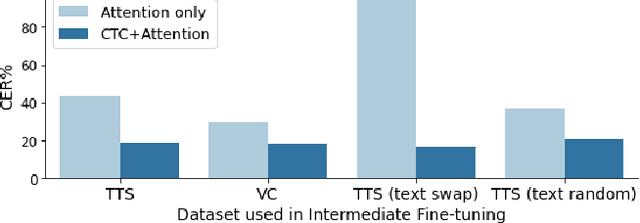
Research on automatic speech recognition (ASR) systems for electrolaryngeal speakers has been relatively unexplored due to small datasets. When training data is lacking in ASR, a large-scale pretraining and fine tuning framework is often sufficient to achieve high recognition rates; however, in electrolaryngeal speech, the domain shift between the pretraining and fine-tuning data is too large to overcome, limiting the maximum improvement of recognition rates. To resolve this, we propose an intermediate fine-tuning step that uses imperfect synthetic speech to close the domain shift gap between the pretraining and target data. Despite the imperfect synthetic data, we show the effectiveness of this on electrolaryngeal speech datasets, with improvements of 6.1% over the baseline that did not use imperfect synthetic speech. Results show how the intermediate fine-tuning stage focuses on learning the high-level inherent features of the imperfect synthetic data rather than the low-level features such as intelligibility.
Automatic Assessment of Oral Reading Accuracy for Reading Diagnostics
Jun 06, 2023

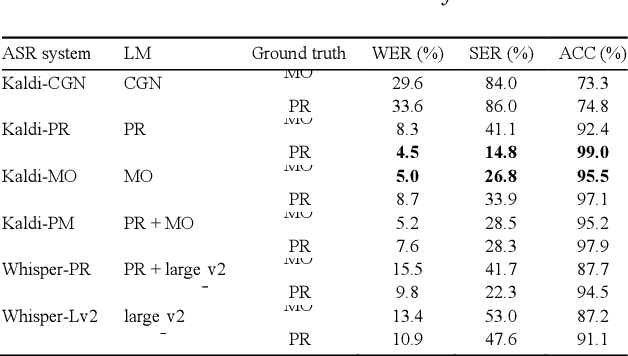
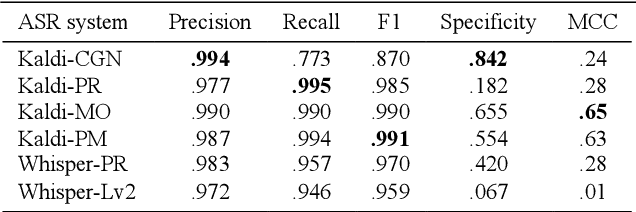
Automatic assessment of reading fluency using automatic speech recognition (ASR) holds great potential for early detection of reading difficulties and subsequent timely intervention. Precise assessment tools are required, especially for languages other than English. In this study, we evaluate six state-of-the-art ASR-based systems for automatically assessing Dutch oral reading accuracy using Kaldi and Whisper. Results show our most successful system reached substantial agreement with human evaluations (MCC = .63). The same system reached the highest correlation between forced decoding confidence scores and word correctness (r = .45). This system's language model (LM) consisted of manual orthographic transcriptions and reading prompts of the test data, which shows that including reading errors in the LM improves assessment performance. We discuss the implications for developing automatic assessment systems and identify possible avenues of future research.
Fast Entropy-Based Methods of Word-Level Confidence Estimation for End-To-End Automatic Speech Recognition
Dec 16, 2022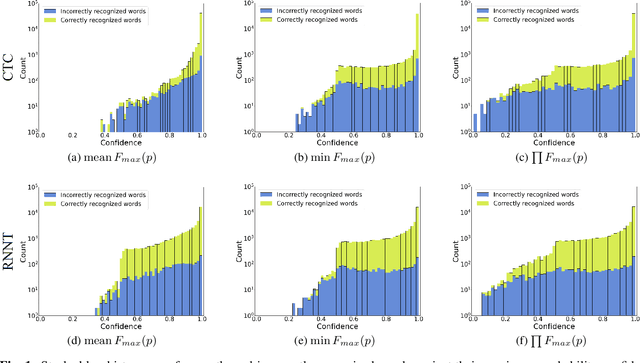
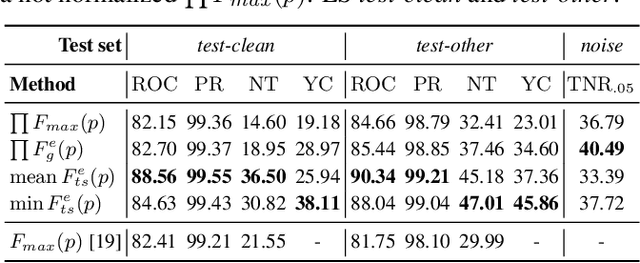
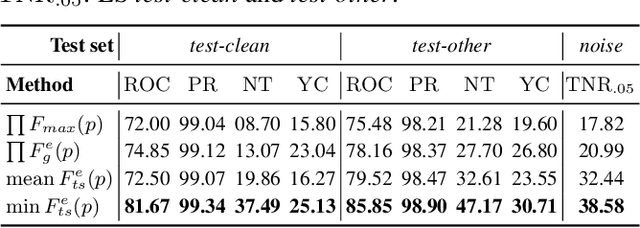
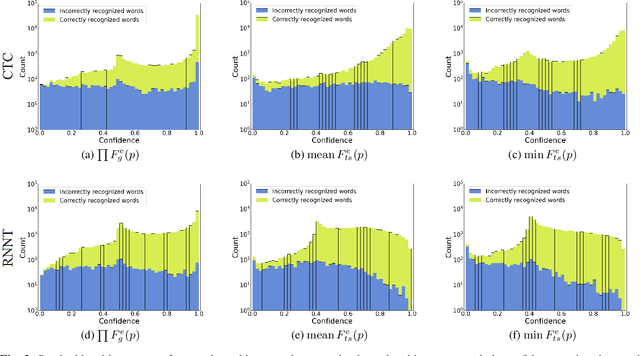
This paper presents a class of new fast non-trainable entropy-based confidence estimation methods for automatic speech recognition. We show how per-frame entropy values can be normalized and aggregated to obtain a confidence measure per unit and per word for Connectionist Temporal Classification (CTC) and Recurrent Neural Network Transducer (RNN-T) models. Proposed methods have similar computational complexity to the traditional method based on the maximum per-frame probability, but they are more adjustable, have a wider effective threshold range, and better push apart the confidence distributions of correct and incorrect words. We evaluate the proposed confidence measures on LibriSpeech test sets, and show that they are up to 2 and 4 times better than confidence estimation based on the maximum per-frame probability at detecting incorrect words for Conformer-CTC and Conformer-RNN-T models, respectively.
Insights on Neural Representations for End-to-End Speech Recognition
May 19, 2022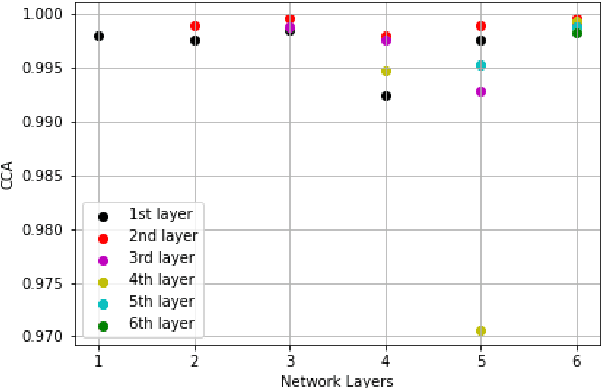

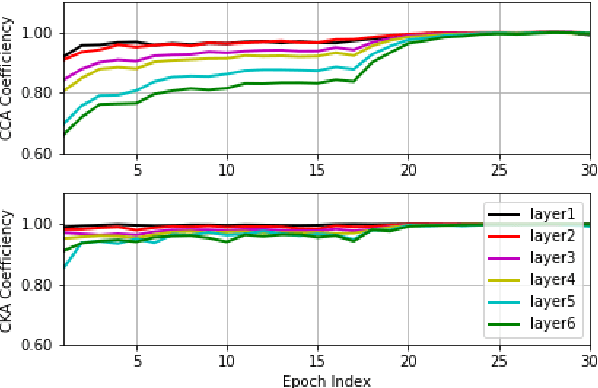

End-to-end automatic speech recognition (ASR) models aim to learn a generalised speech representation. However, there are limited tools available to understand the internal functions and the effect of hierarchical dependencies within the model architecture. It is crucial to understand the correlations between the layer-wise representations, to derive insights on the relationship between neural representations and performance. Previous investigations of network similarities using correlation analysis techniques have not been explored for End-to-End ASR models. This paper analyses and explores the internal dynamics between layers during training with CNN, LSTM and Transformer based approaches using Canonical correlation analysis (CCA) and centered kernel alignment (CKA) for the experiments. It was found that neural representations within CNN layers exhibit hierarchical correlation dependencies as layer depth increases but this is mostly limited to cases where neural representation correlates more closely. This behaviour is not observed in LSTM architecture, however there is a bottom-up pattern observed across the training process, while Transformer encoder layers exhibit irregular coefficiency correlation as neural depth increases. Altogether, these results provide new insights into the role that neural architectures have upon speech recognition performance. More specifically, these techniques can be used as indicators to build better performing speech recognition models.
* Submitted to Interspeech 2021
Avoid Overthinking in Self-Supervised Models for Speech Recognition
Nov 01, 2022
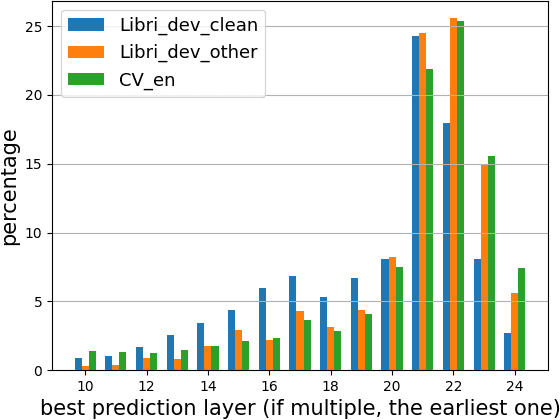
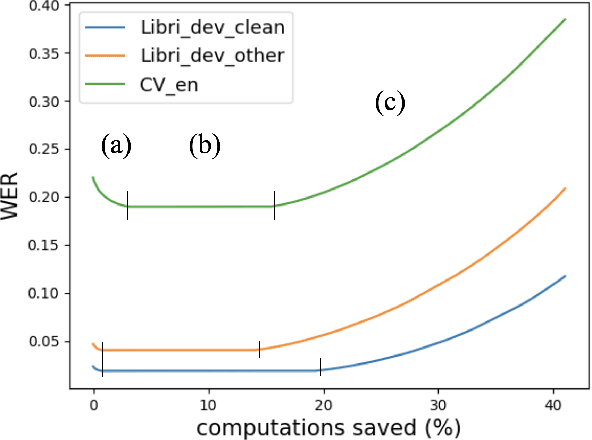

Self-supervised learning (SSL) models reshaped our approach to speech, language and vision. However their huge size and the opaque relations between their layers and tasks result in slow inference and network overthinking, where predictions made from the last layer of large models is worse than those made from intermediate layers. Early exit (EE) strategies can solve both issues by dynamically reducing computations at inference time for certain samples. Although popular for classification tasks in vision and language, EE has seen less use for sequence-to-sequence speech recognition (ASR) tasks where outputs from early layers are often degenerate. This challenge is further compounded when speech SSL models are applied on out-of-distribution (OOD) data. This paper first shows that SSL models do overthinking in ASR. We then motivate further research in EE by computing an optimal bound for performance versus speed trade-offs. To approach this bound we propose two new strategies for ASR: (1) we adapt the recently proposed patience strategy to ASR; and (2) we design a new EE strategy specific to ASR that performs better than all strategies previously introduced.
Lookahead When It Matters: Adaptive Non-causal Transformers for Streaming Neural Transducers
May 09, 2023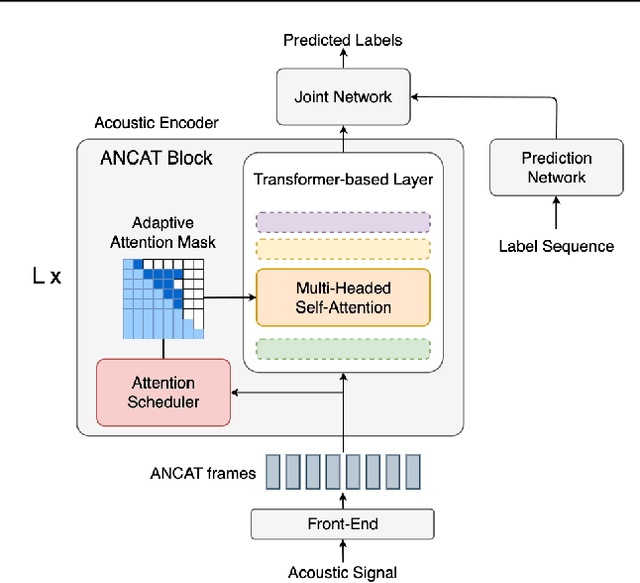
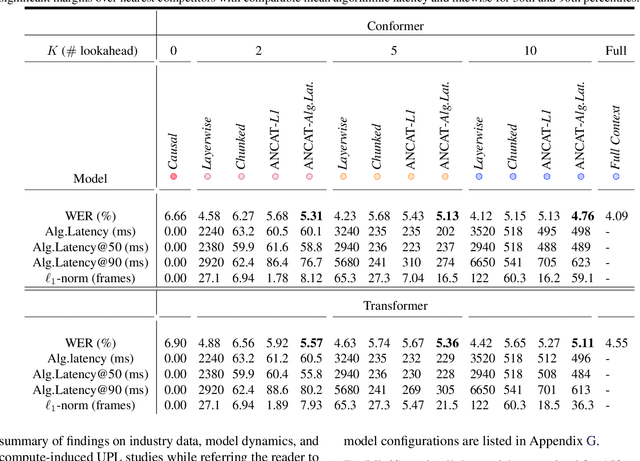
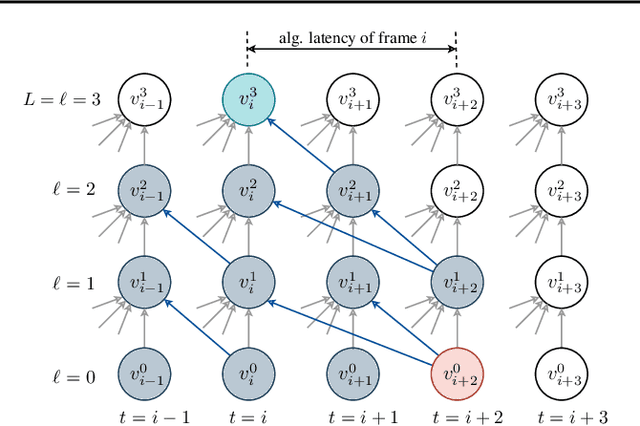
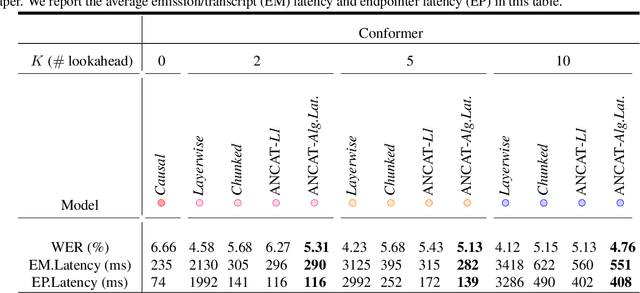
Streaming speech recognition architectures are employed for low-latency, real-time applications. Such architectures are often characterized by their causality. Causal architectures emit tokens at each frame, relying only on current and past signal, while non-causal models are exposed to a window of future frames at each step to increase predictive accuracy. This dichotomy amounts to a trade-off for real-time Automatic Speech Recognition (ASR) system design: profit from the low-latency benefit of strictly-causal architectures while accepting predictive performance limitations, or realize the modeling benefits of future-context models accompanied by their higher latency penalty. In this work, we relax the constraints of this choice and present the Adaptive Non-Causal Attention Transducer (ANCAT). Our architecture is non-causal in the traditional sense, but executes in a low-latency, streaming manner by dynamically choosing when to rely on future context and to what degree within the audio stream. The resulting mechanism, when coupled with our novel regularization algorithms, delivers comparable accuracy to non-causal configurations while improving significantly upon latency, closing the gap with their causal counterparts. We showcase our design experimentally by reporting comparative ASR task results with measures of accuracy and latency on both publicly accessible and production-scale, voice-assistant datasets.
VioLA: Unified Codec Language Models for Speech Recognition, Synthesis, and Translation
May 25, 2023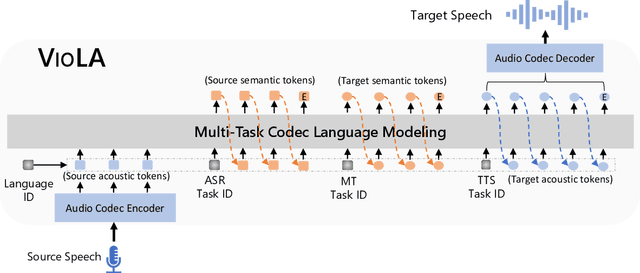
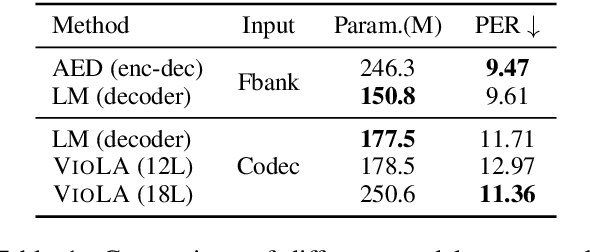
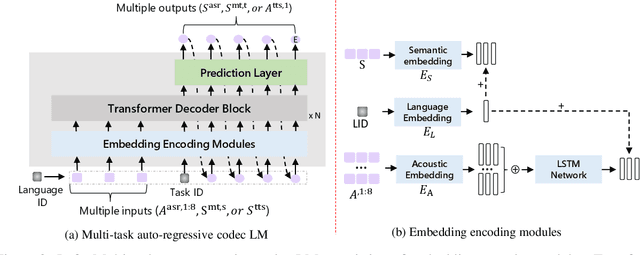
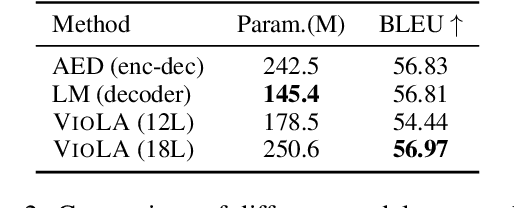
Recent research shows a big convergence in model architecture, training objectives, and inference methods across various tasks for different modalities. In this paper, we propose VioLA, a single auto-regressive Transformer decoder-only network that unifies various cross-modal tasks involving speech and text, such as speech-to-text, text-to-text, text-to-speech, and speech-to-speech tasks, as a conditional codec language model task via multi-task learning framework. To accomplish this, we first convert all the speech utterances to discrete tokens (similar to the textual data) using an offline neural codec encoder. In such a way, all these tasks are converted to token-based sequence conversion problems, which can be naturally handled with one conditional language model. We further integrate task IDs (TID) and language IDs (LID) into the proposed model to enhance the modeling capability of handling different languages and tasks. Experimental results demonstrate that the proposed VioLA model can support both single-modal and cross-modal tasks well, and the decoder-only model achieves a comparable and even better performance than the strong baselines.
Audio-Visual Speech Enhancement with Score-Based Generative Models
Jun 02, 2023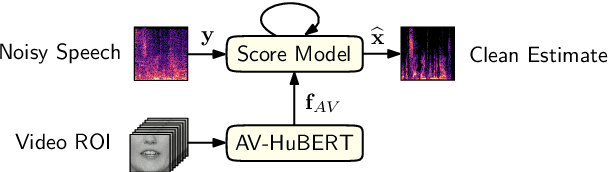

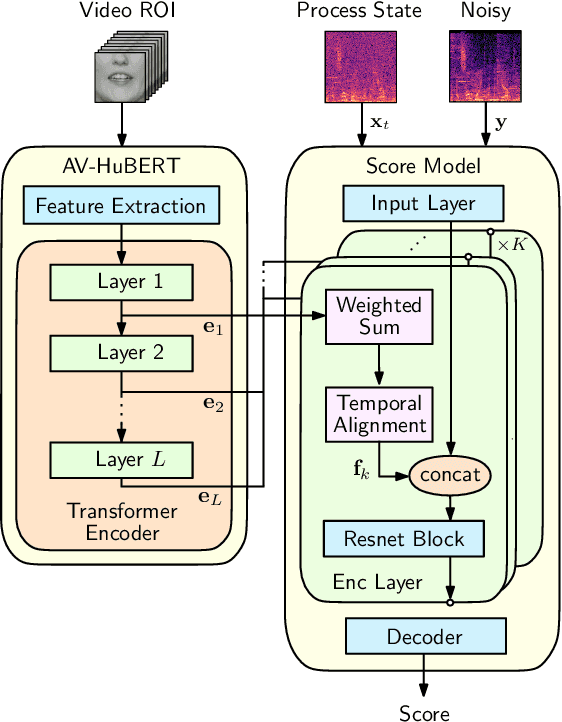
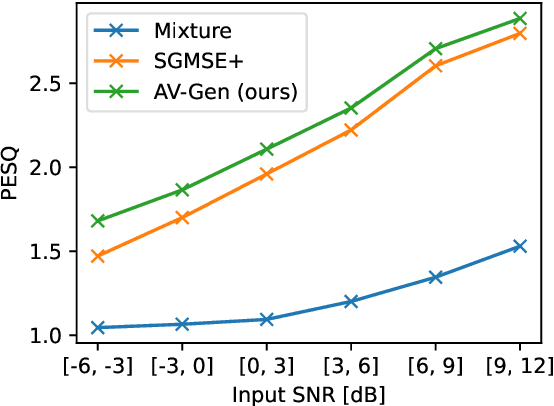
This paper introduces an audio-visual speech enhancement system that leverages score-based generative models, also known as diffusion models, conditioned on visual information. In particular, we exploit audio-visual embeddings obtained from a self-super\-vised learning model that has been fine-tuned on lipreading. The layer-wise features of its transformer-based encoder are aggregated, time-aligned, and incorporated into the noise conditional score network. Experimental evaluations show that the proposed audio-visual speech enhancement system yields improved speech quality and reduces generative artifacts such as phonetic confusions with respect to the audio-only equivalent. The latter is supported by the word error rate of a downstream automatic speech recognition model, which decreases noticeably, especially at low input signal-to-noise ratios.
Writer adaptation for offline text recognition: An exploration of neural network-based methods
Jul 11, 2023
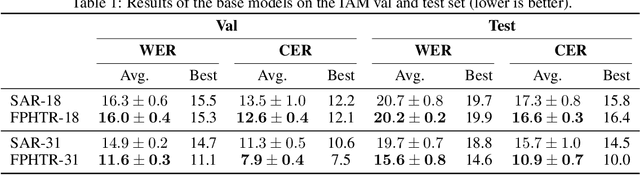
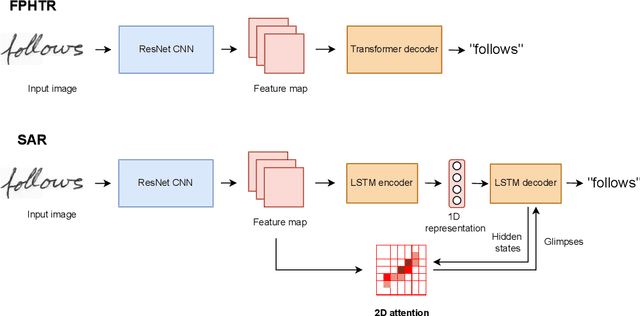

Handwriting recognition has seen significant success with the use of deep learning. However, a persistent shortcoming of neural networks is that they are not well-equipped to deal with shifting data distributions. In the field of handwritten text recognition (HTR), this shows itself in poor recognition accuracy for writers that are not similar to those seen during training. An ideal HTR model should be adaptive to new writing styles in order to handle the vast amount of possible writing styles. In this paper, we explore how HTR models can be made writer adaptive by using only a handful of examples from a new writer (e.g., 16 examples) for adaptation. Two HTR architectures are used as base models, using a ResNet backbone along with either an LSTM or Transformer sequence decoder. Using these base models, two methods are considered to make them writer adaptive: 1) model-agnostic meta-learning (MAML), an algorithm commonly used for tasks such as few-shot classification, and 2) writer codes, an idea originating from automatic speech recognition. Results show that an HTR-specific version of MAML known as MetaHTR improves performance compared to the baseline with a 1.4 to 2.0 improvement in word error rate (WER). The improvement due to writer adaptation is between 0.2 and 0.7 WER, where a deeper model seems to lend itself better to adaptation using MetaHTR than a shallower model. However, applying MetaHTR to larger HTR models or sentence-level HTR may become prohibitive due to its high computational and memory requirements. Lastly, writer codes based on learned features or Hinge statistical features did not lead to improved recognition performance.