 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
On the N-gram Approximation of Pre-trained Language Models
Jun 12, 2023
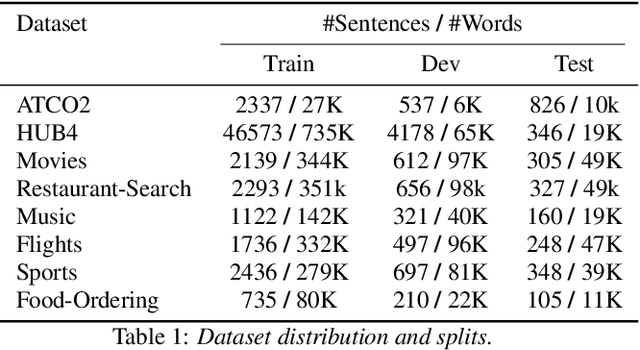
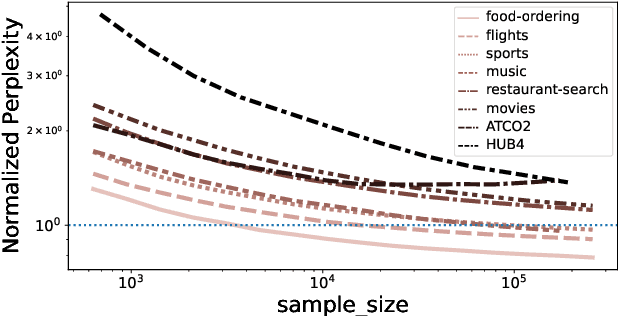
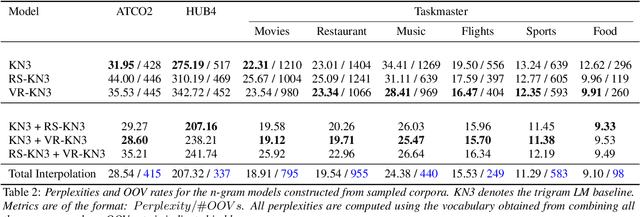
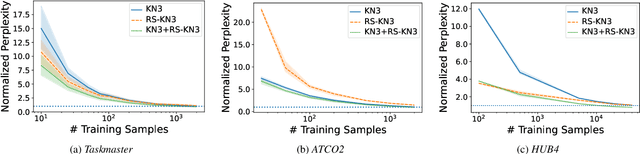
Large pre-trained language models (PLMs) have shown remarkable performance across various natural language understanding (NLU) tasks, particularly in low-resource settings. Nevertheless, their potential in Automatic Speech Recognition (ASR) remains largely unexplored. This study investigates the potential usage of PLMs for language modelling in ASR. We compare the application of large-scale text sampling and probability conversion for approximating GPT-2 into an n-gram model. Furthermore, we introduce a vocabulary-restricted decoding method for random sampling, and evaluate the effects of domain difficulty and data size on the usability of generated text. Our findings across eight domain-specific corpora support the use of sampling-based approximation and show that interpolating with a large sampled corpus improves test perplexity over a baseline trigram by 15%. Our vocabulary-restricted decoding method pushes this improvement further by 5% in domain-specific settings.
Knowledge-Aware Audio-Grounded Generative Slot Filling for Limited Annotated Data
Jul 04, 2023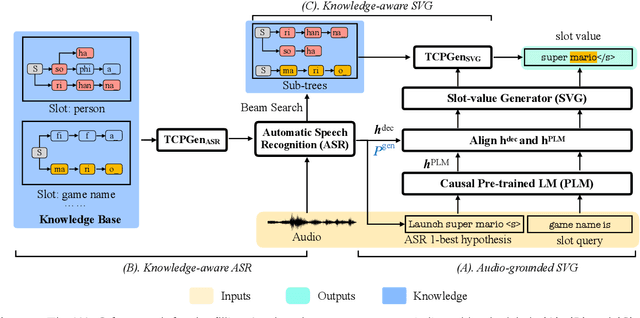
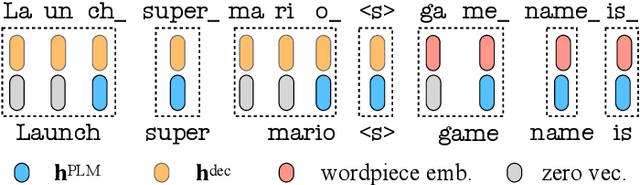

Manually annotating fine-grained slot-value labels for task-oriented dialogue (ToD) systems is an expensive and time-consuming endeavour. This motivates research into slot-filling methods that operate with limited amounts of labelled data. Moreover, the majority of current work on ToD is based solely on text as the input modality, neglecting the additional challenges of imperfect automatic speech recognition (ASR) when working with spoken language. In this work, we propose a Knowledge-Aware Audio-Grounded generative slot-filling framework, termed KA2G, that focuses on few-shot and zero-shot slot filling for ToD with speech input. KA2G achieves robust and data-efficient slot filling for speech-based ToD by 1) framing it as a text generation task, 2) grounding text generation additionally in the audio modality, and 3) conditioning on available external knowledge (e.g. a predefined list of possible slot values). We show that combining both modalities within the KA2G framework improves the robustness against ASR errors. Further, the knowledge-aware slot-value generator in KA2G, implemented via a pointer generator mechanism, particularly benefits few-shot and zero-shot learning. Experiments, conducted on the standard speech-based single-turn SLURP dataset and a multi-turn dataset extracted from a commercial ToD system, display strong and consistent gains over prior work, especially in few-shot and zero-shot setups.
End-to-End Joint Target and Non-Target Speakers ASR
Jun 04, 2023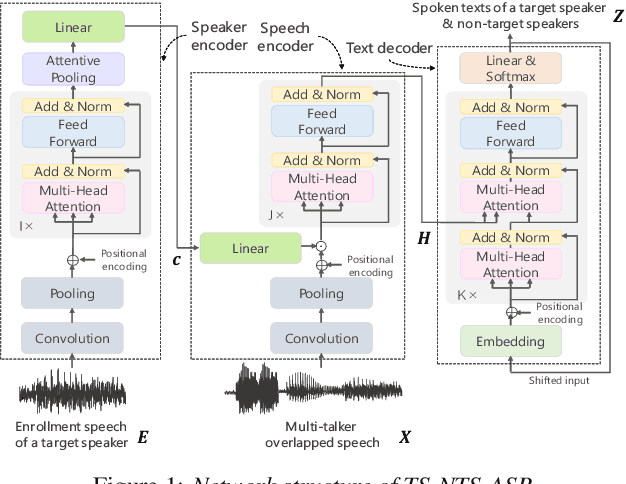
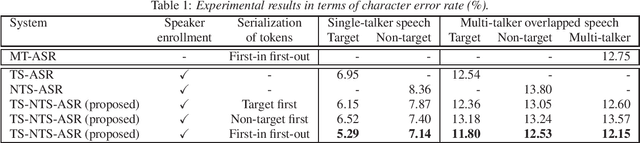
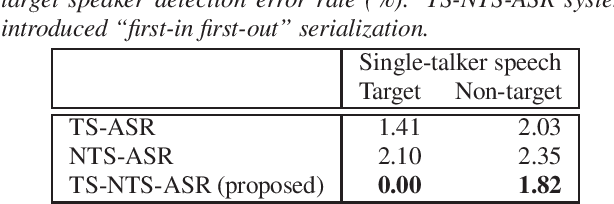
This paper proposes a novel automatic speech recognition (ASR) system that can transcribe individual speaker's speech while identifying whether they are target or non-target speakers from multi-talker overlapped speech. Target-speaker ASR systems are a promising way to only transcribe a target speaker's speech by enrolling the target speaker's information. However, in conversational ASR applications, transcribing both the target speaker's speech and non-target speakers' ones is often required to understand interactive information. To naturally consider both target and non-target speakers in a single ASR model, our idea is to extend autoregressive modeling-based multi-talker ASR systems to utilize the enrollment speech of the target speaker. Our proposed ASR is performed by recursively generating both textual tokens and tokens that represent target or non-target speakers. Our experiments demonstrate the effectiveness of our proposed method.
Improving Noisy Student Training on Non-target Domain Data for Automatic Speech Recognition
Nov 09, 2022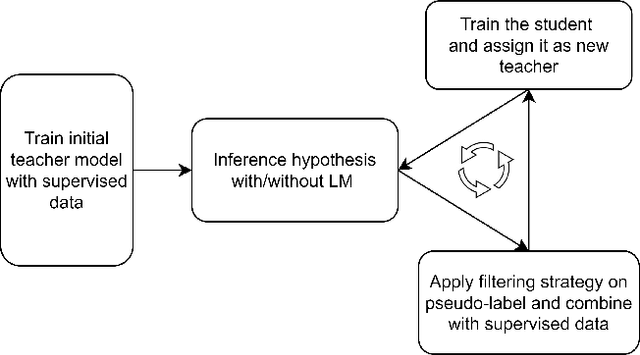


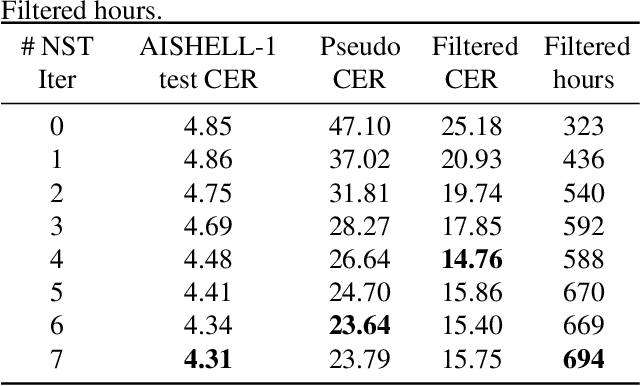
Noisy Student Training (NST) has recently demonstrated extremely strong performance in Automatic Speech Recognition (ASR). In this paper, we propose a data selection strategy named LM Filter to improve the performances of NST on non-target domain data in ASR tasks. Hypothesis with and without Language Model are generated and CER differences between them are utilized as a filter threshold. Results reveal that significant improvements of 10.4% compared with no data filtering baselines. We can achieve 3.31% CER in AISHELL-1 test set, which is best result from our knowledge without any other supervised data. We also perform evaluations on supervised 1000 hour AISHELL-2 dataset and competitive results of 4.72% CER can be achieved.
E-Branchformer: Branchformer with Enhanced merging for speech recognition
Sep 30, 2022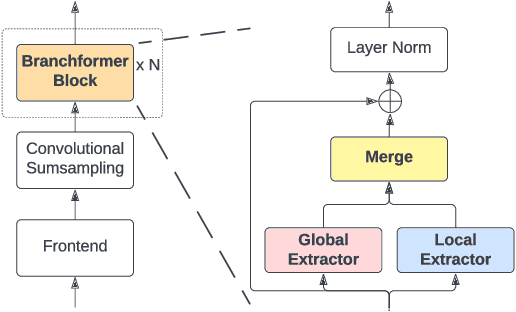
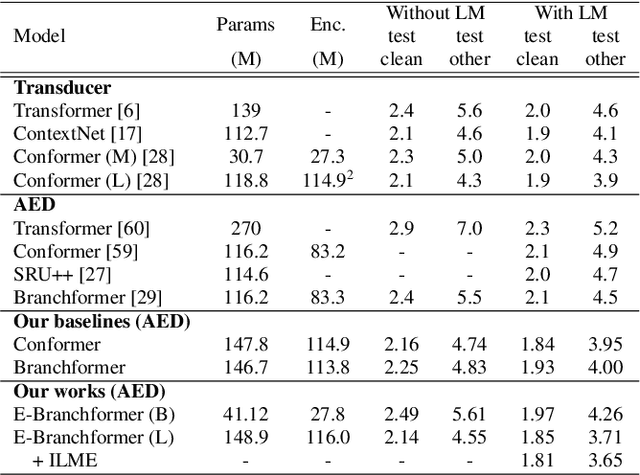
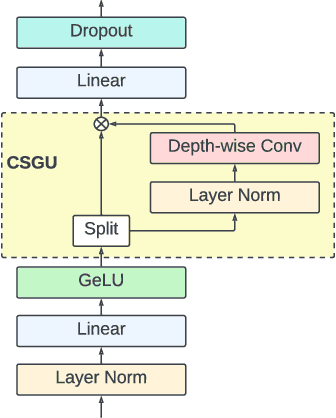
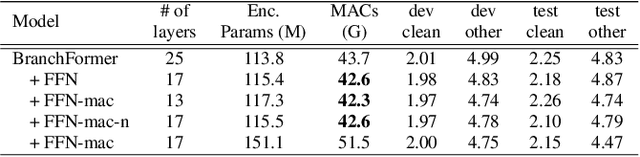
Conformer, combining convolution and self-attention sequentially to capture both local and global information, has shown remarkable performance and is currently regarded as the state-of-the-art for automatic speech recognition (ASR). Several other studies have explored integrating convolution and self-attention but they have not managed to match Conformer's performance. The recently introduced Branchformer achieves comparable performance to Conformer by using dedicated branches of convolution and self-attention and merging local and global context from each branch. In this paper, we propose E-Branchformer, which enhances Branchformer by applying an effective merging method and stacking additional point-wise modules. E-Branchformer sets new state-of-the-art word error rates (WERs) 1.81% and 3.65% on LibriSpeech test-clean and test-other sets without using any external training data.
The ISCSLP 2022 Intelligent Cockpit Speech Recognition Challenge (ICSRC): Dataset, Tracks, Baseline and Results
Nov 03, 2022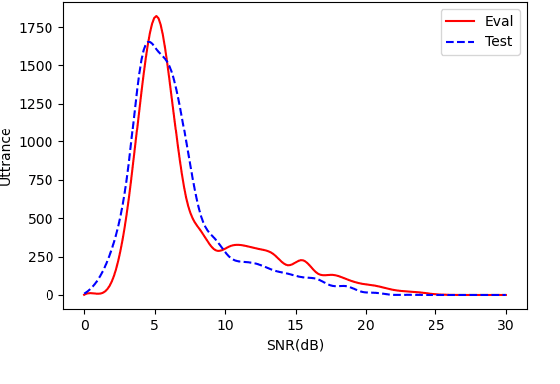



This paper summarizes the outcomes from the ISCSLP 2022 Intelligent Cockpit Speech Recognition Challenge (ICSRC). We first address the necessity of the challenge and then introduce the associated dataset collected from a new-energy vehicle (NEV) covering a variety of cockpit acoustic conditions and linguistic contents. We then describe the track arrangement and the baseline system. Specifically, we set up two tracks in terms of allowed model/system size to investigate resource-constrained and -unconstrained setups, targeting to vehicle embedded as well as cloud ASR systems respectively. Finally we summarize the challenge results and provide the major observations from the submitted systems.
Competitive and Resource Efficient Factored Hybrid HMM Systems are Simpler Than You Think
Jun 15, 2023
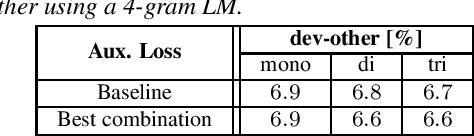

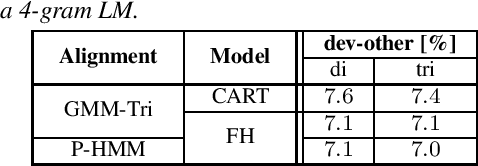
Building competitive hybrid hidden Markov model~(HMM) systems for automatic speech recognition~(ASR) requires a complex multi-stage pipeline consisting of several training criteria. The recent sequence-to-sequence models offer the advantage of having simpler pipelines that can start from-scratch. We propose a purely neural based single-stage from-scratch pipeline for a context-dependent hybrid HMM that offers similar simplicity. We use an alignment from a full-sum trained zero-order posterior HMM with a BLSTM encoder. We show that with this alignment we can build a Conformer factored hybrid that performs even better than both a state-of-the-art classic hybrid and a factored hybrid trained with alignments taken from more complex Gaussian mixture based systems. Our finding is confirmed on Switchboard 300h and LibriSpeech 960h tasks with comparable results to other approaches in the literature, and by additionally relying on a responsible choice of available computational resources.
Self-supervised Fine-tuning for Improved Content Representations by Speaker-invariant Clustering
May 18, 2023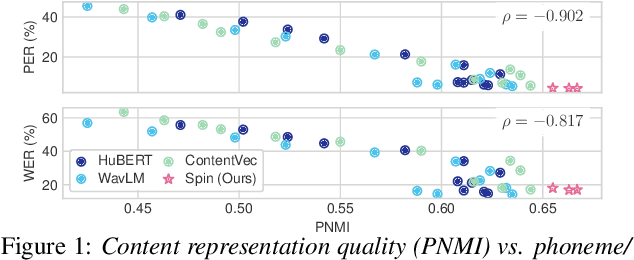
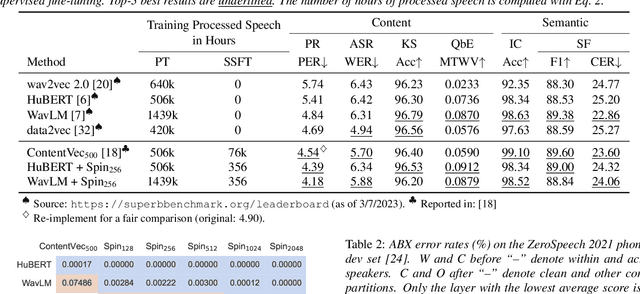
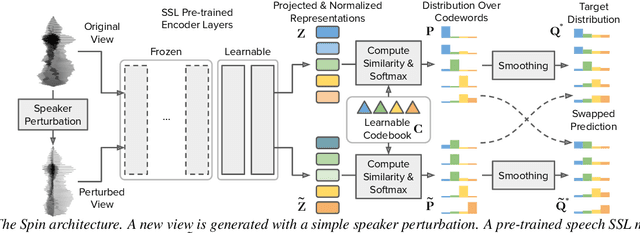
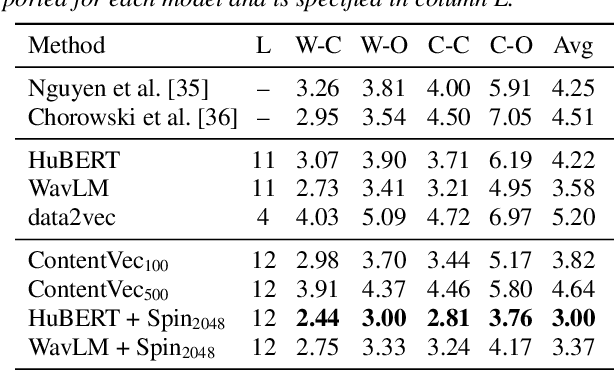
Self-supervised speech representation models have succeeded in various tasks, but improving them for content-related problems using unlabeled data is challenging. We propose speaker-invariant clustering (Spin), a novel self-supervised learning method that clusters speech representations and performs swapped prediction between the original and speaker-perturbed utterances. Spin disentangles speaker information and preserves content representations with just 45 minutes of fine-tuning on a single GPU. Spin improves pre-trained networks and outperforms prior methods in speech recognition and acoustic unit discovery.
Automatic Assessment of Oral Reading Accuracy for Reading Diagnostics
Jun 06, 2023

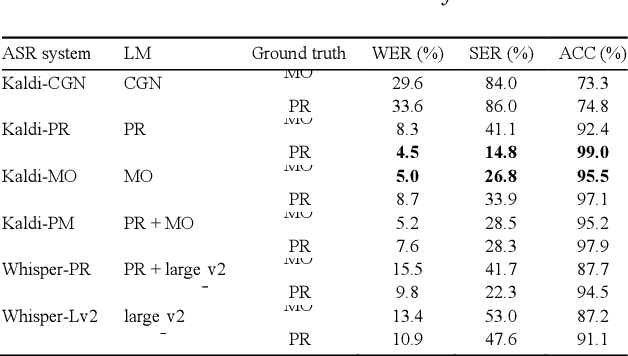
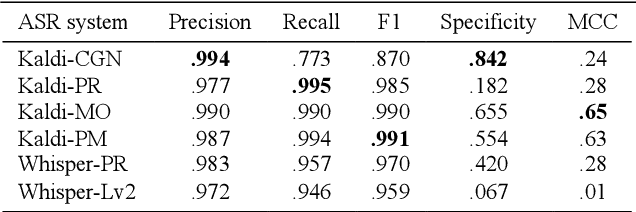
Automatic assessment of reading fluency using automatic speech recognition (ASR) holds great potential for early detection of reading difficulties and subsequent timely intervention. Precise assessment tools are required, especially for languages other than English. In this study, we evaluate six state-of-the-art ASR-based systems for automatically assessing Dutch oral reading accuracy using Kaldi and Whisper. Results show our most successful system reached substantial agreement with human evaluations (MCC = .63). The same system reached the highest correlation between forced decoding confidence scores and word correctness (r = .45). This system's language model (LM) consisted of manual orthographic transcriptions and reading prompts of the test data, which shows that including reading errors in the LM improves assessment performance. We discuss the implications for developing automatic assessment systems and identify possible avenues of future research.
Writer adaptation for offline text recognition: An exploration of neural network-based methods
Jul 11, 2023
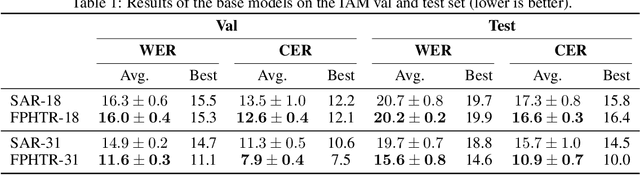
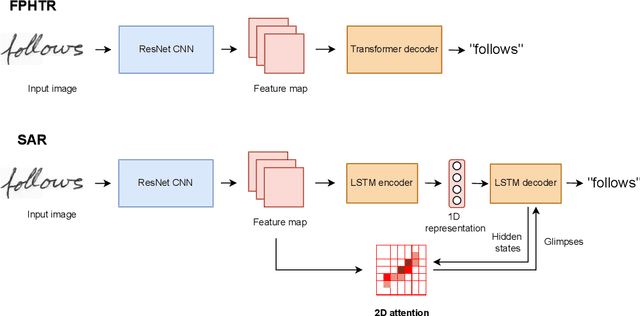

Handwriting recognition has seen significant success with the use of deep learning. However, a persistent shortcoming of neural networks is that they are not well-equipped to deal with shifting data distributions. In the field of handwritten text recognition (HTR), this shows itself in poor recognition accuracy for writers that are not similar to those seen during training. An ideal HTR model should be adaptive to new writing styles in order to handle the vast amount of possible writing styles. In this paper, we explore how HTR models can be made writer adaptive by using only a handful of examples from a new writer (e.g., 16 examples) for adaptation. Two HTR architectures are used as base models, using a ResNet backbone along with either an LSTM or Transformer sequence decoder. Using these base models, two methods are considered to make them writer adaptive: 1) model-agnostic meta-learning (MAML), an algorithm commonly used for tasks such as few-shot classification, and 2) writer codes, an idea originating from automatic speech recognition. Results show that an HTR-specific version of MAML known as MetaHTR improves performance compared to the baseline with a 1.4 to 2.0 improvement in word error rate (WER). The improvement due to writer adaptation is between 0.2 and 0.7 WER, where a deeper model seems to lend itself better to adaptation using MetaHTR than a shallower model. However, applying MetaHTR to larger HTR models or sentence-level HTR may become prohibitive due to its high computational and memory requirements. Lastly, writer codes based on learned features or Hinge statistical features did not lead to improved recognition performance.