 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Anytime, Anywhere: Human Arm Pose from Smartwatch Data for Ubiquitous Robot Control and Teleoperation
Jun 22, 2023
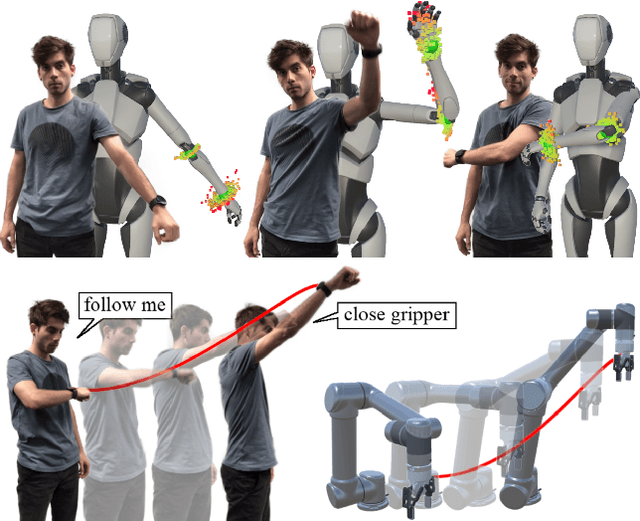

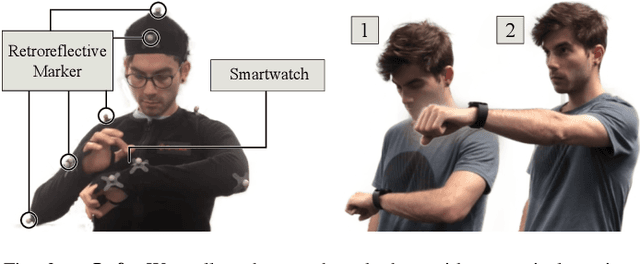
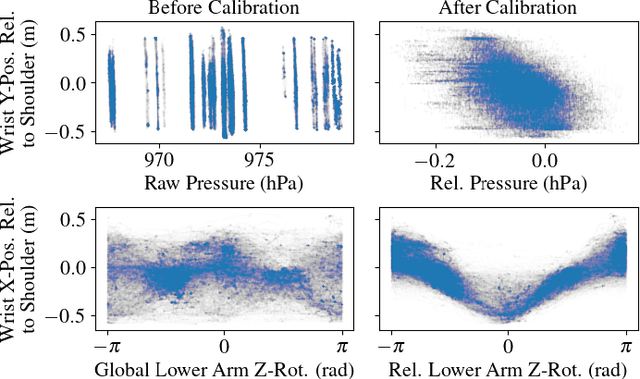
This work devises an optimized machine learning approach for human arm pose estimation from a single smartwatch. Our approach results in a distribution of possible wrist and elbow positions, which allows for a measure of uncertainty and the detection of multiple possible arm posture solutions, i.e., multimodal pose distributions. Combining estimated arm postures with speech recognition, we turn the smartwatch into a ubiquitous, low-cost and versatile robot control interface. We demonstrate in two use-cases that this intuitive control interface enables users to swiftly intervene in robot behavior, to temporarily adjust their goal, or to train completely new control policies by imitation. Extensive experiments show that the approach results in a 40% reduction in prediction error over the current state-of-the-art and achieves a mean error of 2.56cm for wrist and elbow positions.
Towards Model-Size Agnostic, Compute-Free, Memorization-based Inference of Deep Learning
Jul 14, 2023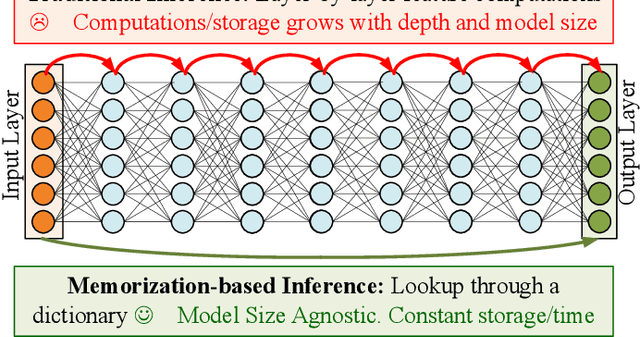
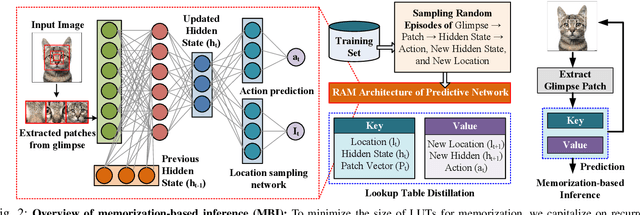
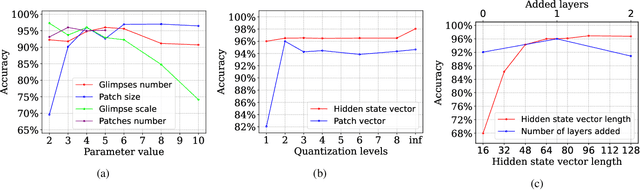
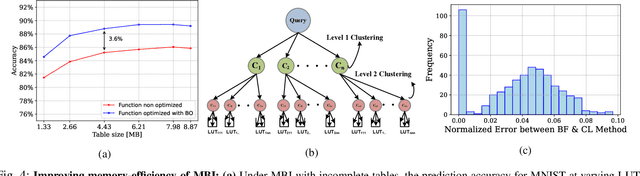
The rapid advancement of deep neural networks has significantly improved various tasks, such as image and speech recognition. However, as the complexity of these models increases, so does the computational cost and the number of parameters, making it difficult to deploy them on resource-constrained devices. This paper proposes a novel memorization-based inference (MBI) that is compute free and only requires lookups. Specifically, our work capitalizes on the inference mechanism of the recurrent attention model (RAM), where only a small window of input domain (glimpse) is processed in a one time step, and the outputs from multiple glimpses are combined through a hidden vector to determine the overall classification output of the problem. By leveraging the low-dimensionality of glimpse, our inference procedure stores key value pairs comprising of glimpse location, patch vector, etc. in a table. The computations are obviated during inference by utilizing the table to read out key-value pairs and performing compute-free inference by memorization. By exploiting Bayesian optimization and clustering, the necessary lookups are reduced, and accuracy is improved. We also present in-memory computing circuits to quickly look up the matching key vector to an input query. Compared to competitive compute-in-memory (CIM) approaches, MBI improves energy efficiency by almost 2.7 times than multilayer perceptions (MLP)-CIM and by almost 83 times than ResNet20-CIM for MNIST character recognition.
Time-Domain Speech Enhancement for Robust Automatic Speech Recognition
Oct 27, 2022
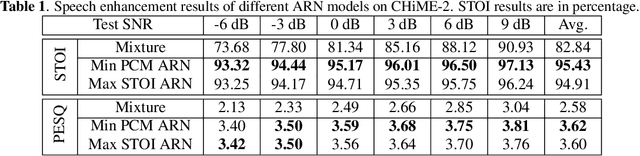
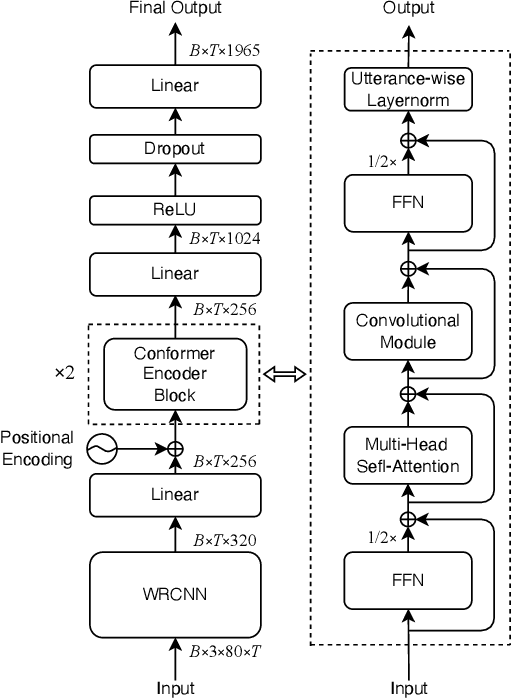
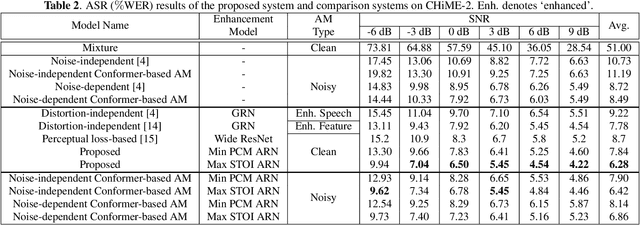
It has been shown that the intelligibility of noisy speech can be improved by speech enhancement algorithms. However, speech enhancement has not been established as an effective front-end for robust automatic speech recognition (ASR) in comparison with an ASR model trained on noisy speech directly. The divide between speech enhancement and ASR impedes the progress of robust ASR systems especially as speech enhancement has made big strides in recent years. In this work, we focus on eliminating such divide with an ARN (attentive recurrent network) based time-domain enhancement model. The proposed system fully decouples speech enhancement and an acoustic model trained only on clean speech. Results on the CHiME-2 corpus show that ARN enhanced speech translates to improved ASR results. The proposed system achieves $6.28\%$ average word error rate, outperforming the previous best by $19.3\%$.
Inter-KD: Intermediate Knowledge Distillation for CTC-Based Automatic Speech Recognition
Nov 28, 2022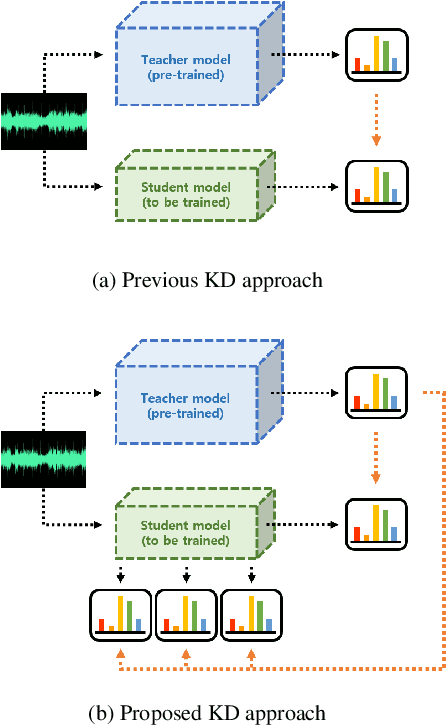
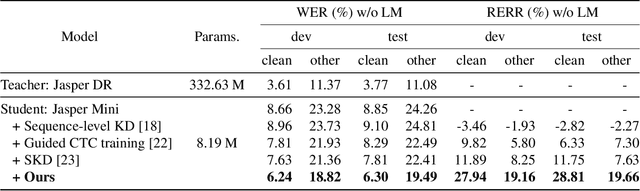
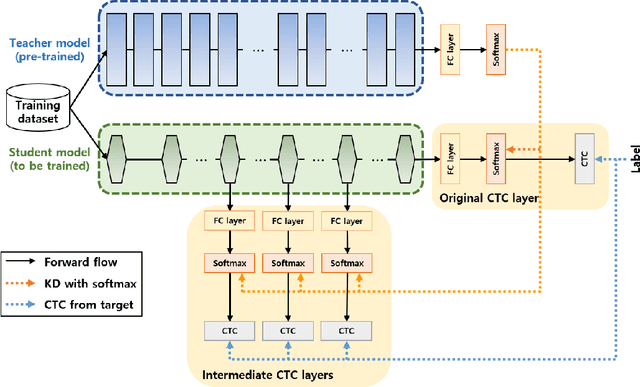
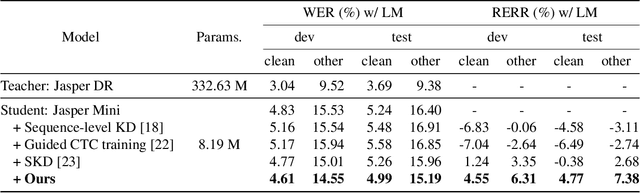
Recently, the advance in deep learning has brought a considerable improvement in the end-to-end speech recognition field, simplifying the traditional pipeline while producing promising results. Among the end-to-end models, the connectionist temporal classification (CTC)-based model has attracted research interest due to its non-autoregressive nature. However, such CTC models require a heavy computational cost to achieve outstanding performance. To mitigate the computational burden, we propose a simple yet effective knowledge distillation (KD) for the CTC framework, namely Inter-KD, that additionally transfers the teacher's knowledge to the intermediate CTC layers of the student network. From the experimental results on the LibriSpeech, we verify that the Inter-KD shows better achievements compared to the conventional KD methods. Without using any language model (LM) and data augmentation, Inter-KD improves the word error rate (WER) performance from 8.85 % to 6.30 % on the test-clean.
RAND: Robustness Aware Norm Decay For Quantized Seq2seq Models
May 24, 2023

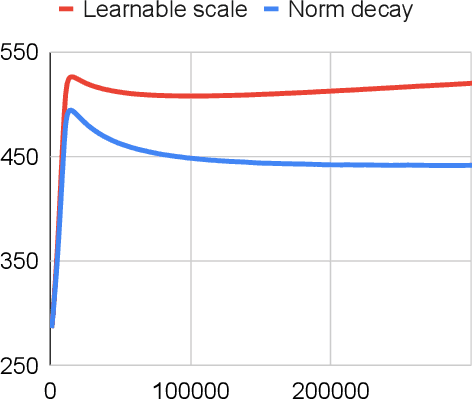
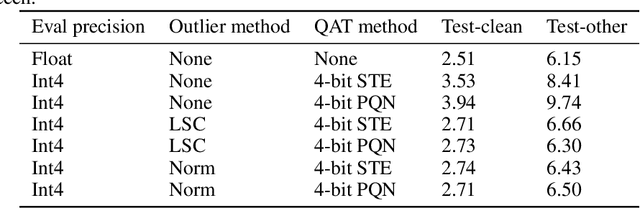
With the rapid increase in the size of neural networks, model compression has become an important area of research. Quantization is an effective technique at decreasing the model size, memory access, and compute load of large models. Despite recent advances in quantization aware training (QAT) technique, most papers present evaluations that are focused on computer vision tasks, which have different training dynamics compared to sequence tasks. In this paper, we first benchmark the impact of popular techniques such as straight through estimator, pseudo-quantization noise, learnable scale parameter, clipping, etc. on 4-bit seq2seq models across a suite of speech recognition datasets ranging from 1,000 hours to 1 million hours, as well as one machine translation dataset to illustrate its applicability outside of speech. Through the experiments, we report that noise based QAT suffers when there is insufficient regularization signal flowing back to the quantization scale. We propose low complexity changes to the QAT process to improve model accuracy (outperforming popular learnable scale and clipping methods). With the improved accuracy, it opens up the possibility to exploit some of the other benefits of noise based QAT: 1) training a single model that performs well in mixed precision mode and 2) improved generalization on long form speech recognition.
Reducing the gap between streaming and non-streaming Transducer-based ASR by adaptive two-stage knowledge distillation
Jun 27, 2023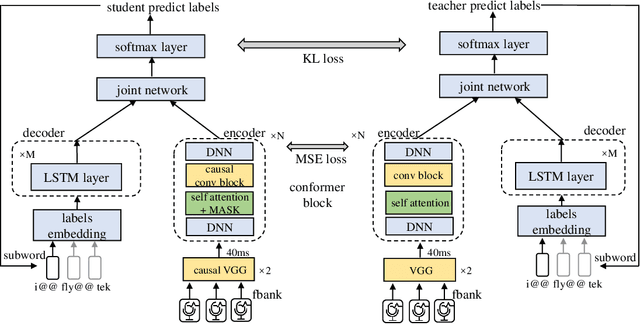
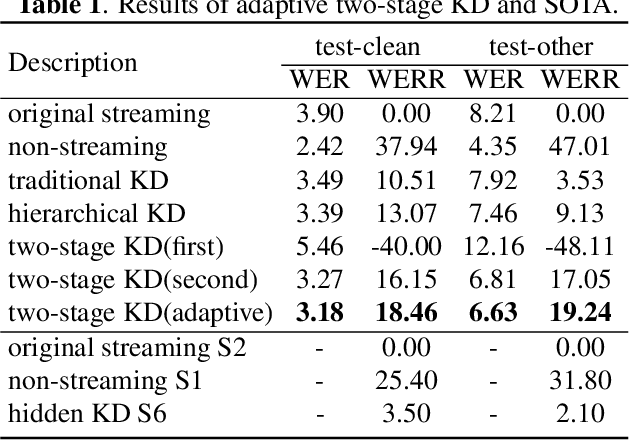
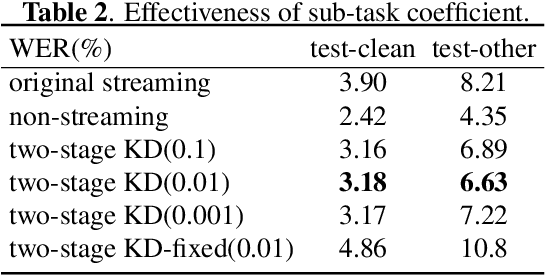
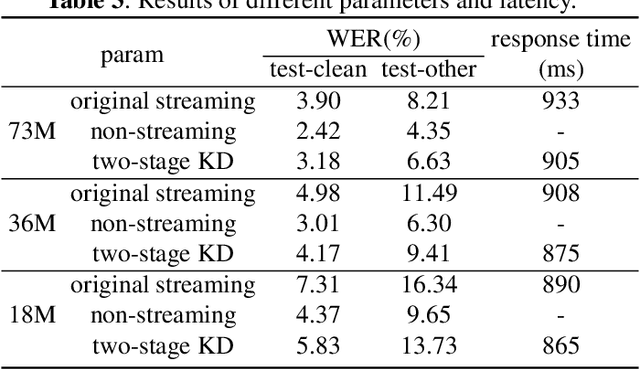
Transducer is one of the mainstream frameworks for streaming speech recognition. There is a performance gap between the streaming and non-streaming transducer models due to limited context. To reduce this gap, an effective way is to ensure that their hidden and output distributions are consistent, which can be achieved by hierarchical knowledge distillation. However, it is difficult to ensure the distribution consistency simultaneously because the learning of the output distribution depends on the hidden one. In this paper, we propose an adaptive two-stage knowledge distillation method consisting of hidden layer learning and output layer learning. In the former stage, we learn hidden representation with full context by applying mean square error loss function. In the latter stage, we design a power transformation based adaptive smoothness method to learn stable output distribution. It achieved 19\% relative reduction in word error rate, and a faster response for the first token compared with the original streaming model in LibriSpeech corpus.
Visual Context-driven Audio Feature Enhancement for Robust End-to-End Audio-Visual Speech Recognition
Jul 13, 2022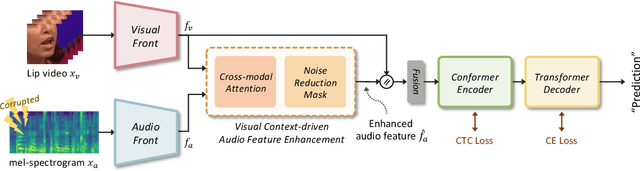
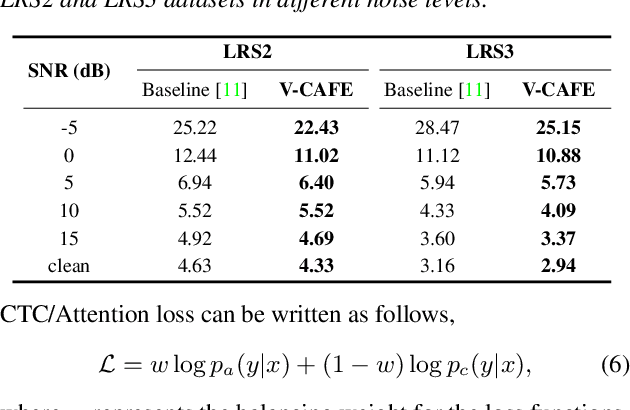
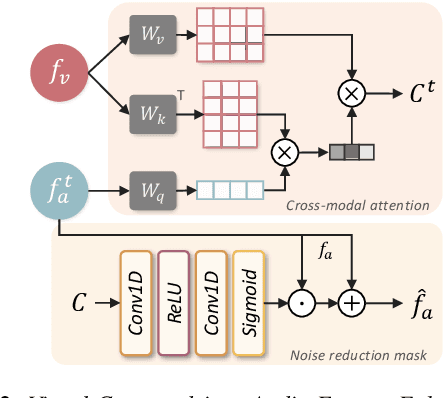
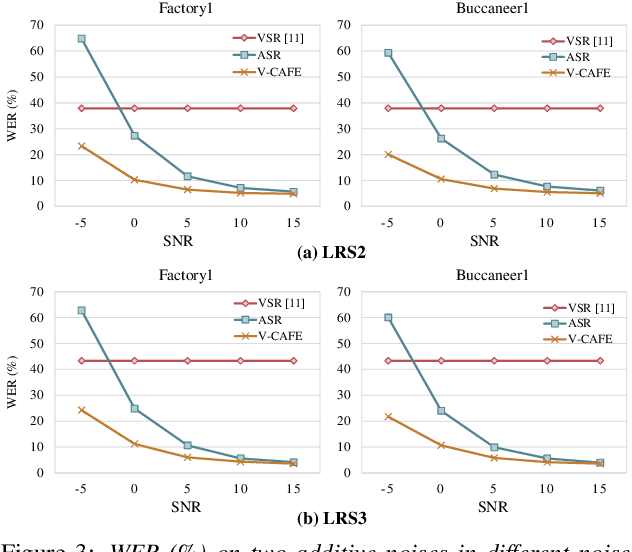
This paper focuses on designing a noise-robust end-to-end Audio-Visual Speech Recognition (AVSR) system. To this end, we propose Visual Context-driven Audio Feature Enhancement module (V-CAFE) to enhance the input noisy audio speech with a help of audio-visual correspondence. The proposed V-CAFE is designed to capture the transition of lip movements, namely visual context and to generate a noise reduction mask by considering the obtained visual context. Through context-dependent modeling, the ambiguity in viseme-to-phoneme mapping can be refined for mask generation. The noisy representations are masked out with the noise reduction mask resulting in enhanced audio features. The enhanced audio features are fused with the visual features and taken to an encoder-decoder model composed of Conformer and Transformer for speech recognition. We show the proposed end-to-end AVSR with the V-CAFE can further improve the noise-robustness of AVSR. The effectiveness of the proposed method is evaluated in noisy speech recognition and overlapped speech recognition experiments using the two largest audio-visual datasets, LRS2 and LRS3.
Boosting Local Spectro-Temporal Features for Speech Analysis
May 17, 2023We introduce the problem of phone classification in the context of speech recognition, and explore several sets of local spectro-temporal features that can be used for phone classification. In particular, we present some preliminary results for phone classification using two sets of features that are commonly used for object detection: Haar features and SVM-classified Histograms of Gradients (HoG)
Evaluating OpenAI's Whisper ASR for Punctuation Prediction and Topic Modeling of life histories of the Museum of the Person
May 23, 2023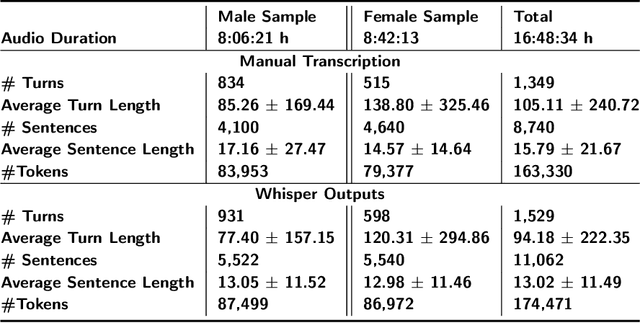
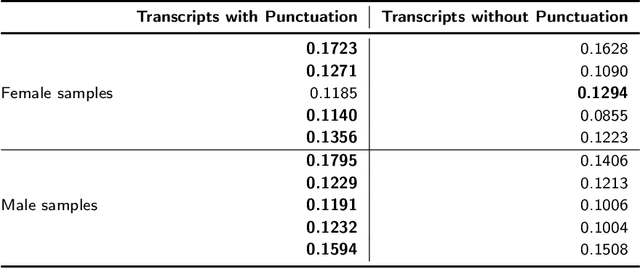
Automatic speech recognition (ASR) systems play a key role in applications involving human-machine interactions. Despite their importance, ASR models for the Portuguese language proposed in the last decade have limitations in relation to the correct identification of punctuation marks in automatic transcriptions, which hinder the use of transcriptions by other systems, models, and even by humans. However, recently Whisper ASR was proposed by OpenAI, a general-purpose speech recognition model that has generated great expectations in dealing with such limitations. This chapter presents the first study on the performance of Whisper for punctuation prediction in the Portuguese language. We present an experimental evaluation considering both theoretical aspects involving pausing points (comma) and complete ideas (exclamation, question, and fullstop), as well as practical aspects involving transcript-based topic modeling - an application dependent on punctuation marks for promising performance. We analyzed experimental results from videos of Museum of the Person, a virtual museum that aims to tell and preserve people's life histories, thus discussing the pros and cons of Whisper in a real-world scenario. Although our experiments indicate that Whisper achieves state-of-the-art results, we conclude that some punctuation marks require improvements, such as exclamation, semicolon and colon.
AVFormer: Injecting Vision into Frozen Speech Models for Zero-Shot AV-ASR
Mar 29, 2023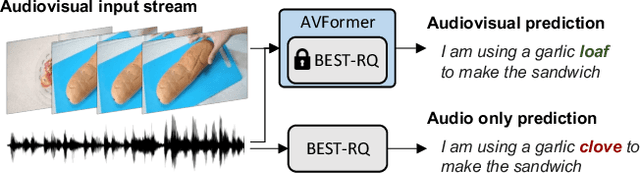
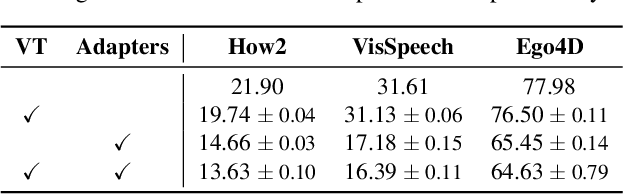
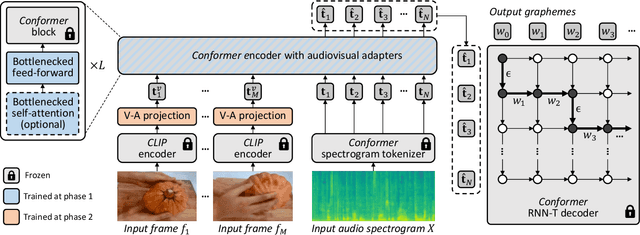

Audiovisual automatic speech recognition (AV-ASR) aims to improve the robustness of a speech recognition system by incorporating visual information. Training fully supervised multimodal models for this task from scratch, however is limited by the need for large labelled audiovisual datasets (in each downstream domain of interest). We present AVFormer, a simple method for augmenting audio-only models with visual information, at the same time performing lightweight domain adaptation. We do this by (i) injecting visual embeddings into a frozen ASR model using lightweight trainable adaptors. We show that these can be trained on a small amount of weakly labelled video data with minimum additional training time and parameters. (ii) We also introduce a simple curriculum scheme during training which we show is crucial to enable the model to jointly process audio and visual information effectively; and finally (iii) we show that our model achieves state of the art zero-shot results on three different AV-ASR benchmarks (How2, VisSpeech and Ego4D), while also crucially preserving decent performance on traditional audio-only speech recognition benchmarks (LibriSpeech). Qualitative results show that our model effectively leverages visual information for robust speech recognition.