 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
Embedding Fourier for Ultra-High-Definition Low-Light Image Enhancement
Feb 23, 2023


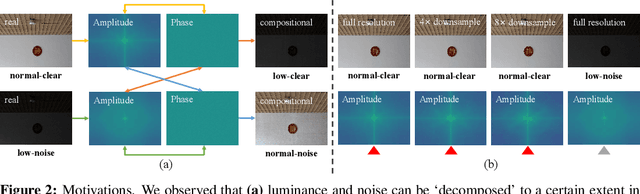
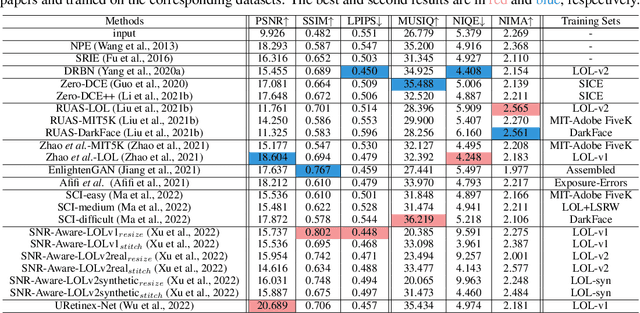
Ultra-High-Definition (UHD) photo has gradually become the standard configuration in advanced imaging devices. The new standard unveils many issues in existing approaches for low-light image enhancement (LLIE), especially in dealing with the intricate issue of joint luminance enhancement and noise removal while remaining efficient. Unlike existing methods that address the problem in the spatial domain, we propose a new solution, UHDFour, that embeds Fourier transform into a cascaded network. Our approach is motivated by a few unique characteristics in the Fourier domain: 1) most luminance information concentrates on amplitudes while noise is closely related to phases, and 2) a high-resolution image and its low-resolution version share similar amplitude patterns.Through embedding Fourier into our network, the amplitude and phase of a low-light image are separately processed to avoid amplifying noise when enhancing luminance. Besides, UHDFour is scalable to UHD images by implementing amplitude and phase enhancement under the low-resolution regime and then adjusting the high-resolution scale with few computations. We also contribute the first real UHD LLIE dataset, \textbf{UHD-LL}, that contains 2,150 low-noise/normal-clear 4K image pairs with diverse darkness and noise levels captured in different scenarios. With this dataset, we systematically analyze the performance of existing LLIE methods for processing UHD images and demonstrate the advantage of our solution. We believe our new framework, coupled with the dataset, would push the frontier of LLIE towards UHD. The code and dataset are available at https://li-chongyi.github.io/UHDFour.
* Porject page: https://li-chongyi.github.io/UHDFour
Uncovering the Disentanglement Capability in Text-to-Image Diffusion Models
Dec 16, 2022
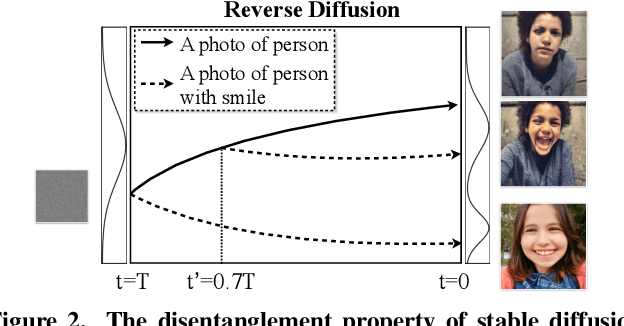
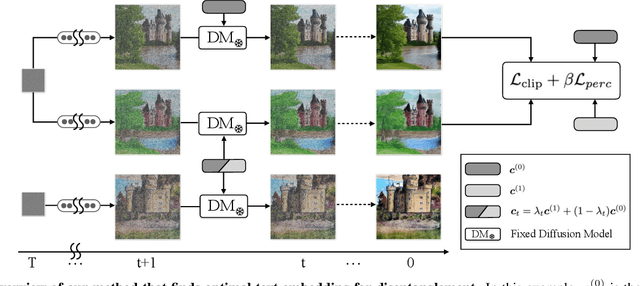
Generative models have been widely studied in computer vision. Recently, diffusion models have drawn substantial attention due to the high quality of their generated images. A key desired property of image generative models is the ability to disentangle different attributes, which should enable modification towards a style without changing the semantic content, and the modification parameters should generalize to different images. Previous studies have found that generative adversarial networks (GANs) are inherently endowed with such disentanglement capability, so they can perform disentangled image editing without re-training or fine-tuning the network. In this work, we explore whether diffusion models are also inherently equipped with such a capability. Our finding is that for stable diffusion models, by partially changing the input text embedding from a neutral description (e.g., "a photo of person") to one with style (e.g., "a photo of person with smile") while fixing all the Gaussian random noises introduced during the denoising process, the generated images can be modified towards the target style without changing the semantic content. Based on this finding, we further propose a simple, light-weight image editing algorithm where the mixing weights of the two text embeddings are optimized for style matching and content preservation. This entire process only involves optimizing over around 50 parameters and does not fine-tune the diffusion model itself. Experiments show that the proposed method can modify a wide range of attributes, with the performance outperforming diffusion-model-based image-editing algorithms that require fine-tuning. The optimized weights generalize well to different images. Our code is publicly available at https://github.com/UCSB-NLP-Chang/DiffusionDisentanglement.
MagicVideo: Efficient Video Generation With Latent Diffusion Models
Nov 20, 2022


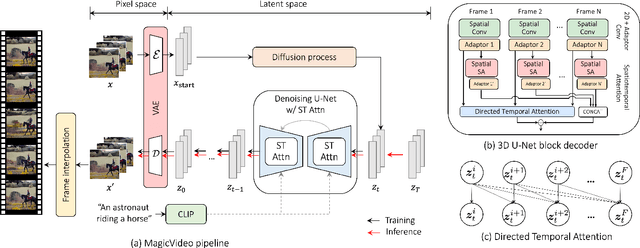
We present an efficient text-to-video generation framework based on latent diffusion models, termed MagicVideo. Given a text description, MagicVideo can generate photo-realistic video clips with high relevance to the text content. With the proposed efficient latent 3D U-Net design, MagicVideo can generate video clips with 256x256 spatial resolution on a single GPU card, which is 64x faster than the recent video diffusion model (VDM). Unlike previous works that train video generation from scratch in the RGB space, we propose to generate video clips in a low-dimensional latent space. We further utilize all the convolution operator weights of pre-trained text-to-image generative U-Net models for faster training. To achieve this, we introduce two new designs to adapt the U-Net decoder to video data: a framewise lightweight adaptor for the image-to-video distribution adjustment and a directed temporal attention module to capture frame temporal dependencies. The whole generation process is within the low-dimension latent space of a pre-trained variation auto-encoder. We demonstrate that MagicVideo can generate both realistic video content and imaginary content in a photo-realistic style with a trade-off in terms of quality and computational cost. Refer to https://magicvideo.github.io/# for more examples.
GANalyzer: Analysis and Manipulation of GANs Latent Space for Controllable Face Synthesis
Feb 02, 2023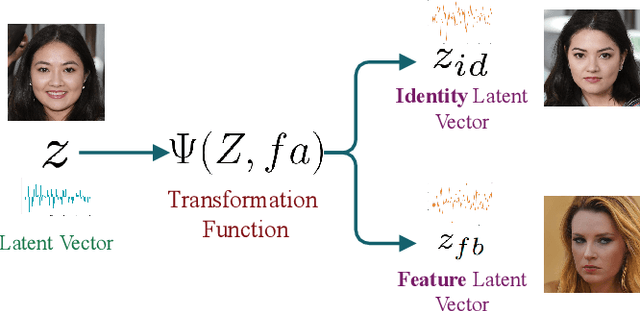

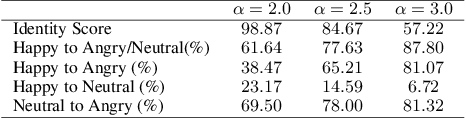

Generative Adversarial Networks (GANs) are capable of synthesizing high-quality facial images. Despite their success, GANs do not provide any information about the relationship between the input vectors and the generated images. Currently, facial GANs are trained on imbalanced datasets, which generate less diverse images. For example, more than 77% of 100K images that we randomly synthesized using the StyleGAN3 are classified as Happy, and only around 3% are Angry. The problem even becomes worse when a mixture of facial attributes is desired: less than 1% of the generated samples are Angry Woman, and only around 2% are Happy Black. To address these problems, this paper proposes a framework, called GANalyzer, for the analysis, and manipulation of the latent space of well-trained GANs. GANalyzer consists of a set of transformation functions designed to manipulate latent vectors for a specific facial attribute such as facial Expression, Age, Gender, and Race. We analyze facial attribute entanglement in the latent space of GANs and apply the proposed transformation for editing the disentangled facial attributes. Our experimental results demonstrate the strength of GANalyzer in editing facial attributes and generating any desired faces. We also create and release a balanced photo-realistic human face dataset. Our code is publicly available on GitHub.
Everybody Sign Now: Translating Spoken Language to Photo Realistic Sign Language Video
Nov 26, 2020
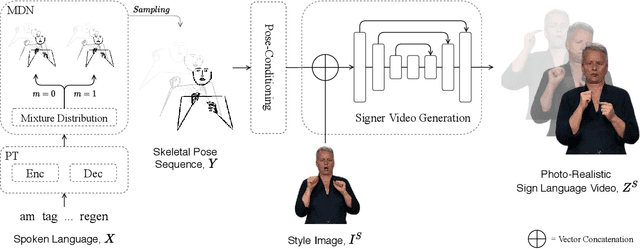
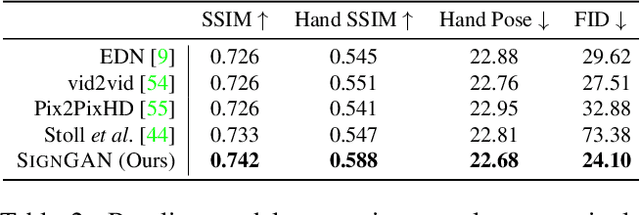
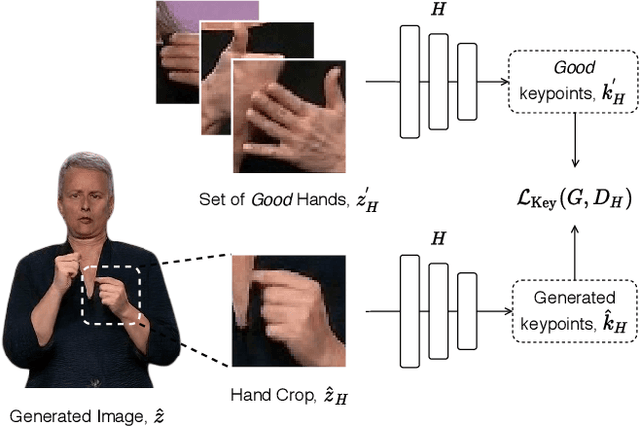
To be truly understandable and accepted by Deaf communities, an automatic Sign Language Production (SLP) system must generate a photo-realistic signer. Prior approaches based on graphical avatars have proven unpopular, whereas recent neural SLP works that produce skeleton pose sequences have been shown to be not understandable to Deaf viewers. In this paper, we propose SignGAN, the first SLP model to produce photo-realistic continuous sign language videos directly from spoken language. We employ a transformer architecture with a Mixture Density Network (MDN) formulation to handle the translation from spoken language to skeletal pose. A pose-conditioned human synthesis model is then introduced to generate a photo-realistic sign language video from the skeletal pose sequence. This allows the photo-realistic production of sign videos directly translated from written text. We further propose a novel keypoint-based loss function, which significantly improves the quality of synthesized hand images, operating in the keypoint space to avoid issues caused by motion blur. In addition, we introduce a method for controllable video generation, enabling training on large, diverse sign language datasets and providing the ability to control the signer appearance at inference. Using a dataset of eight different sign language interpreters extracted from broadcast footage, we show that SignGAN significantly outperforms all baseline methods for quantitative metrics and human perceptual studies.
Face Generation and Editing with StyleGAN: A Survey
Dec 18, 2022
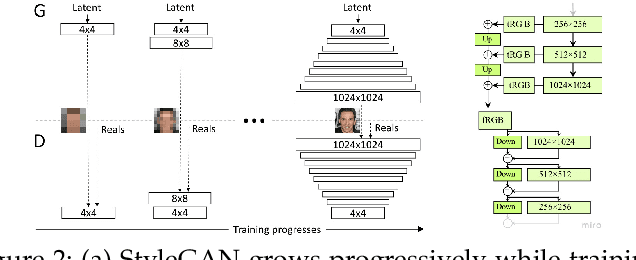
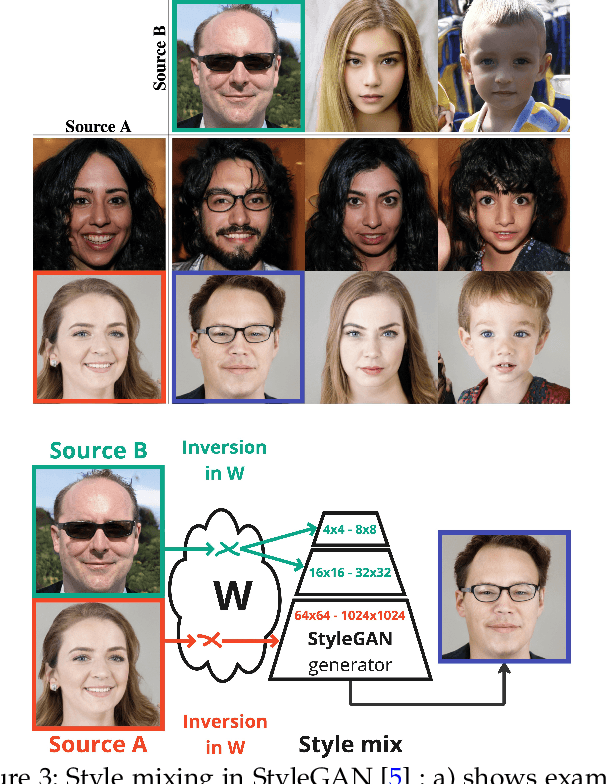
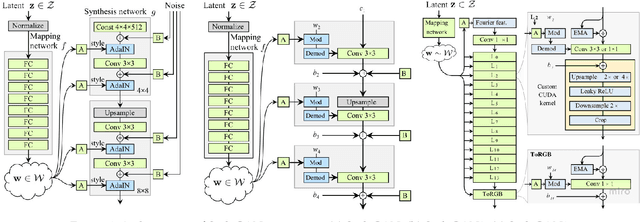
Our goal with this survey is to provide an overview of the state of the art deep learning technologies for face generation and editing. We will cover popular latest architectures and discuss key ideas that make them work, such as inversion, latent representation, loss functions, training procedures, editing methods, and cross domain style transfer. We particularly focus on GAN-based architectures that have culminated in the StyleGAN approaches, which allow generation of high-quality face images and offer rich interfaces for controllable semantics editing and preserving photo quality. We aim to provide an entry point into the field for readers that have basic knowledge about the field of deep learning and are looking for an accessible introduction and overview.
Flexible Piecewise Curves Estimation for Photo Enhancement
Oct 26, 2020
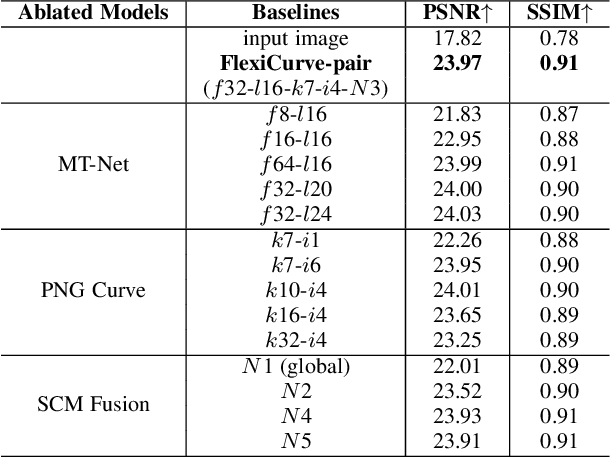
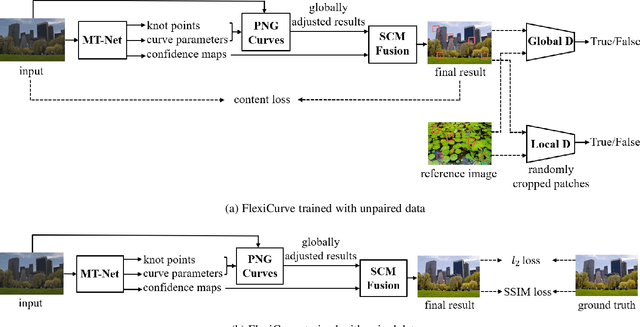
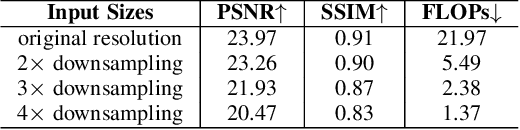
This paper presents a new method, called FlexiCurve, for photo enhancement. Unlike most existing methods that perform image-to-image mapping, which requires expensive pixel-wise reconstruction, FlexiCurve takes an input image and estimates global curves to adjust the image. The adjustment curves are specially designed for performing piecewise mapping, taking nonlinear adjustment and differentiability into account. To cope with challenging and diverse illumination properties in real-world images, FlexiCurve is formulated as a multi-task framework to produce diverse estimations and the associated confidence maps. These estimations are adaptively fused to improve local enhancements of different regions. Thanks to the image-to-curve formulation, for an image with a size of 512*512*3, FlexiCurve only needs a lightweight network (150K trainable parameters) and it has a fast inference speed (83FPS on a single NVIDIA 2080Ti GPU). The proposed method improves efficiency without compromising the enhancement quality and losing details in the original image. The method is also appealing as it is not limited to paired training data, thus it can flexibly learn rich enhancement styles from unpaired data. Extensive experiments demonstrate that our method achieves state-of-the-art performance on photo enhancement quantitively and qualitatively.
Learning-based Inverse Rendering of Complex Indoor Scenes with Differentiable Monte Carlo Raytracing
Nov 06, 2022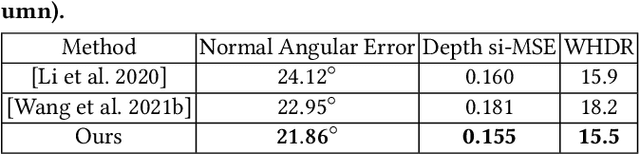

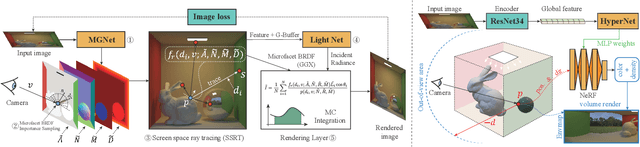

Indoor scenes typically exhibit complex, spatially-varying appearance from global illumination, making inverse rendering a challenging ill-posed problem. This work presents an end-to-end, learning-based inverse rendering framework incorporating differentiable Monte Carlo raytracing with importance sampling. The framework takes a single image as input to jointly recover the underlying geometry, spatially-varying lighting, and photorealistic materials. Specifically, we introduce a physically-based differentiable rendering layer with screen-space ray tracing, resulting in more realistic specular reflections that match the input photo. In addition, we create a large-scale, photorealistic indoor scene dataset with significantly richer details like complex furniture and dedicated decorations. Further, we design a novel out-of-view lighting network with uncertainty-aware refinement leveraging hypernetwork-based neural radiance fields to predict lighting outside the view of the input photo. Through extensive evaluations on common benchmark datasets, we demonstrate superior inverse rendering quality of our method compared to state-of-the-art baselines, enabling various applications such as complex object insertion and material editing with high fidelity. Code and data will be made available at \url{https://jingsenzhu.github.io/invrend}.
Searching for Uncollected Litter with Computer Vision
Nov 27, 2022


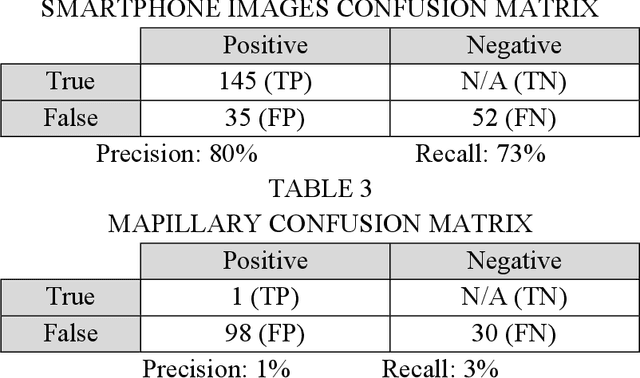
This study combines photo metadata and computer vision to quantify where uncollected litter is present. Images from the Trash Annotations in Context (TACO) dataset were used to teach an algorithm to detect 10 categories of garbage. Although it worked well with smartphone photos, it struggled when trying to process images from vehicle mounted cameras. However, increasing the variety of perspectives and backgrounds in the dataset will help it improve in unfamiliar situations. These data are plotted onto a map which, as accuracy improves, could be used for measuring waste management strategies and quantifying trends.