 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
DDColor: Towards Photo-Realistic and Semantic-Aware Image Colorization via Dual Decoders
Dec 23, 2022
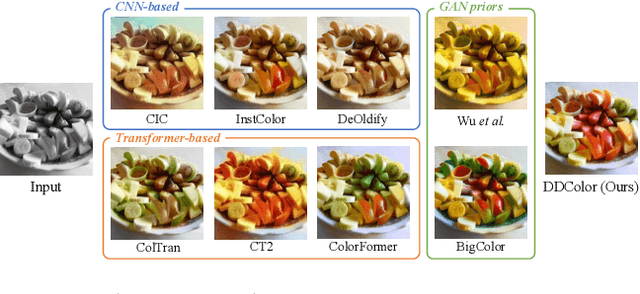
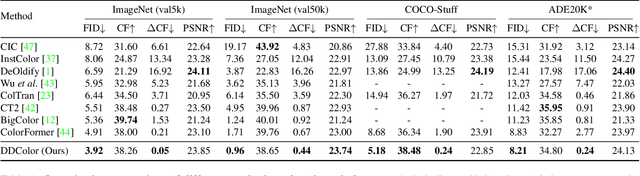
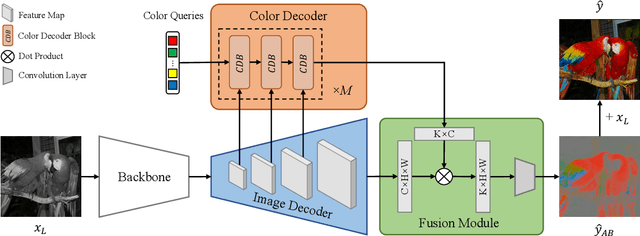

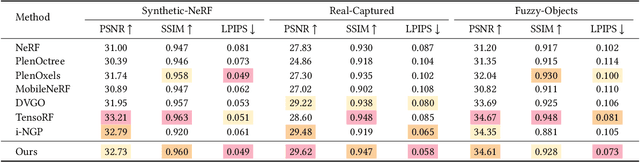
Automatic image colorization is a particularly challenging problem. Due to the high illness of the problem and multi-modal uncertainty, directly training a deep neural network usually leads to incorrect semantic colors and low color richness. Existing transformer-based methods can deliver better results but highly depend on hand-crafted dataset-level empirical distribution priors. In this work, we propose DDColor, a new end-to-end method with dual decoders, for image colorization. More specifically, we design a multi-scale image decoder and a transformer-based color decoder. The former manages to restore the spatial resolution of the image, while the latter establishes the correlation between semantic representations and color queries via cross-attention. The two decoders incorporate to learn semantic-aware color embedding by leveraging the multi-scale visual features. With the help of these two decoders, our method succeeds in producing semantically consistent and visually plausible colorization results without any additional priors. In addition, a simple but effective colorfulness loss is introduced to further improve the color richness of generated results. Our extensive experiments demonstrate that the proposed DDColor achieves significantly superior performance to existing state-of-the-art works both quantitatively and qualitatively. Codes will be made publicly available at https://github.com/piddnad/DDColor.
Pseudo Rehearsal using non photo-realistic images
Apr 28, 2020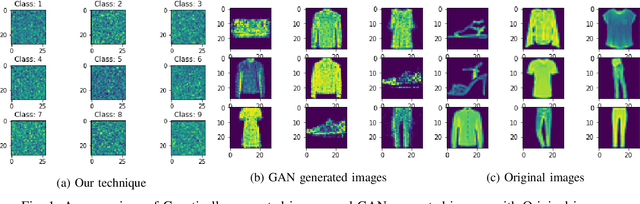
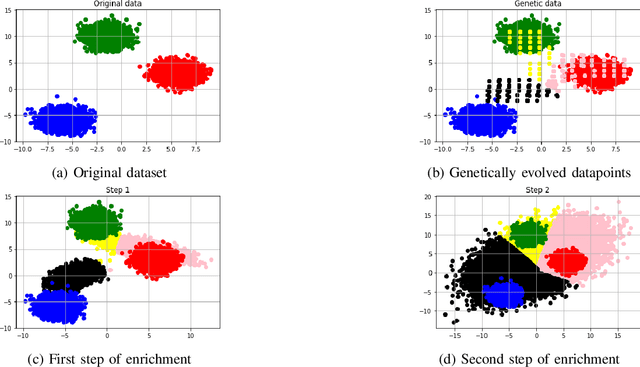
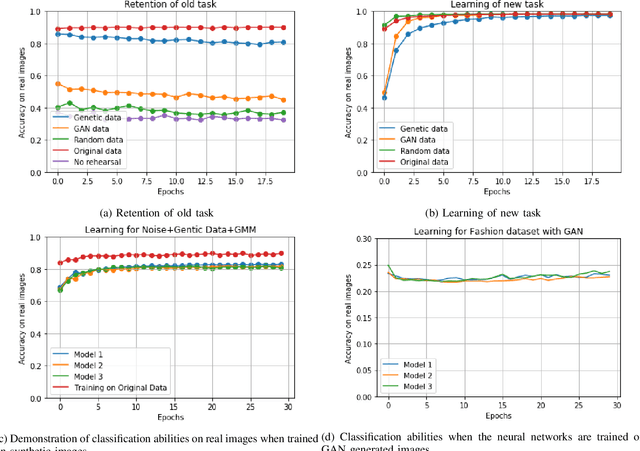

Deep Neural networks forget previously learnt tasks when they are faced with learning new tasks. This is called catastrophic forgetting. Rehearsing the neural network with the training data of the previous task can protect the network from catastrophic forgetting. Since rehearsing requires the storage of entire previous data, Pseudo rehearsal was proposed, where samples belonging to the previous data are generated synthetically for rehearsal. In an image classification setting, while current techniques try to generate synthetic data that is photo-realistic, we demonstrated that Neural networks can be rehearsed on data that is not photo-realistic and still achieve good retention of the previous task. We also demonstrated that forgoing the constraint of having photo realism in the generated data can result in a significant reduction in the consumption of computational and memory resources for pseudo rehearsal.
Feature Likelihood Score: Evaluating Generalization of Generative Models Using Samples
Feb 09, 2023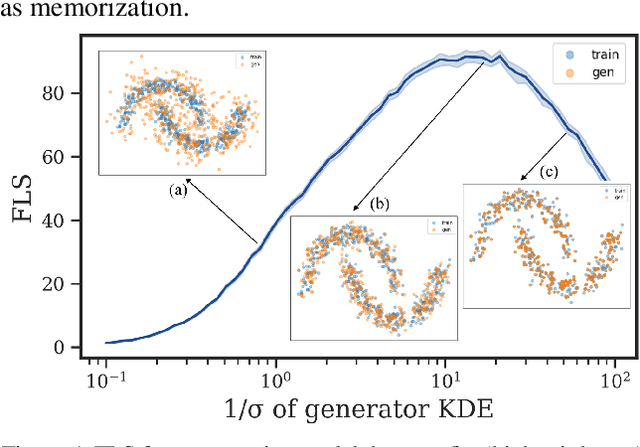
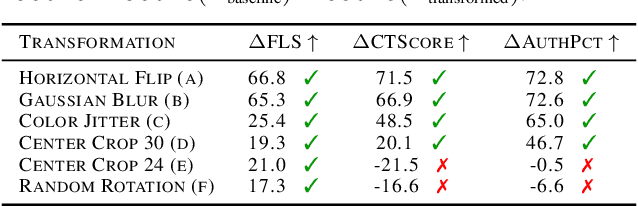
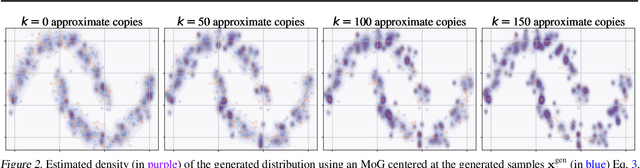
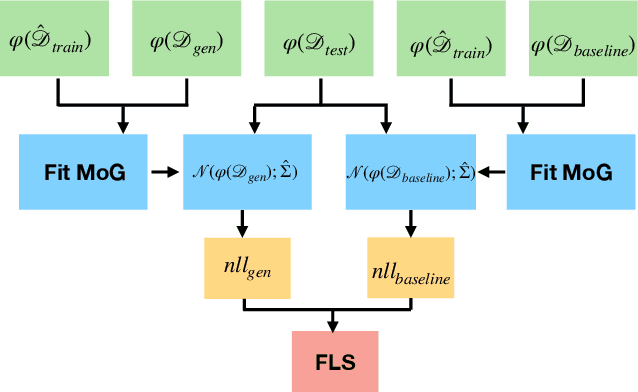
Deep generative models have demonstrated the ability to generate complex, high-dimensional, and photo-realistic data. However, a unified framework for evaluating different generative modeling families remains a challenge. Indeed, likelihood-based metrics do not apply in many cases while pure sample-based metrics such as FID fail to capture known failure modes such as overfitting on training data. In this work, we introduce the Feature Likelihood Score (FLS), a parametric sample-based score that uses density estimation to quantitatively measure the quality/diversity of generated samples while taking into account overfitting. We empirically demonstrate the ability of FLS to identify specific overfitting problem cases, even when previously proposed metrics fail. We further perform an extensive experimental evaluation on various image datasets and model classes. Our results indicate that FLS matches intuitions of previous metrics, such as FID, while providing a more holistic evaluation of generative models that highlights models whose generalization abilities are under or overappreciated. Code for computing FLS is provided at https://github.com/marcojira/fls
GeneFace: Generalized and High-Fidelity Audio-Driven 3D Talking Face Synthesis
Jan 31, 2023
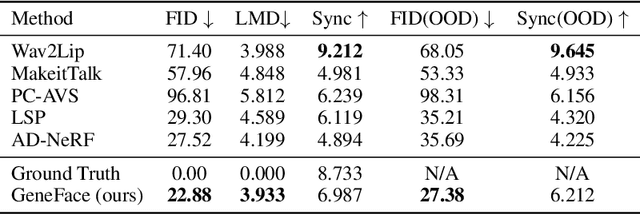
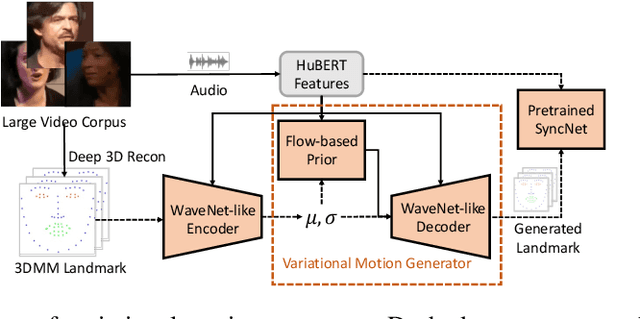

Generating photo-realistic video portrait with arbitrary speech audio is a crucial problem in film-making and virtual reality. Recently, several works explore the usage of neural radiance field in this task to improve 3D realness and image fidelity. However, the generalizability of previous NeRF-based methods to out-of-domain audio is limited by the small scale of training data. In this work, we propose GeneFace, a generalized and high-fidelity NeRF-based talking face generation method, which can generate natural results corresponding to various out-of-domain audio. Specifically, we learn a variaitional motion generator on a large lip-reading corpus, and introduce a domain adaptative post-net to calibrate the result. Moreover, we learn a NeRF-based renderer conditioned on the predicted facial motion. A head-aware torso-NeRF is proposed to eliminate the head-torso separation problem. Extensive experiments show that our method achieves more generalized and high-fidelity talking face generation compared to previous methods.
Dynamic Neural Portraits
Nov 25, 2022
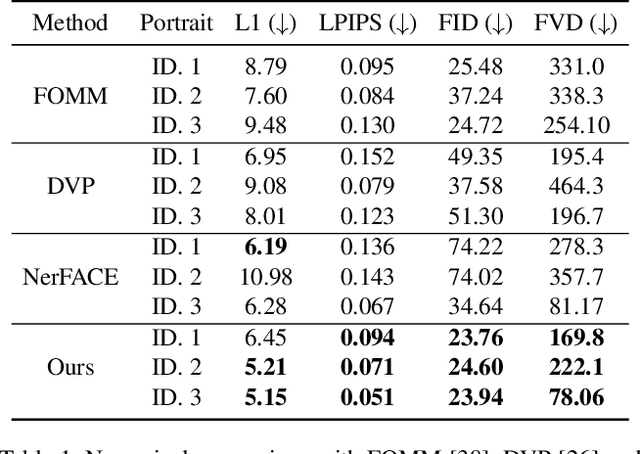
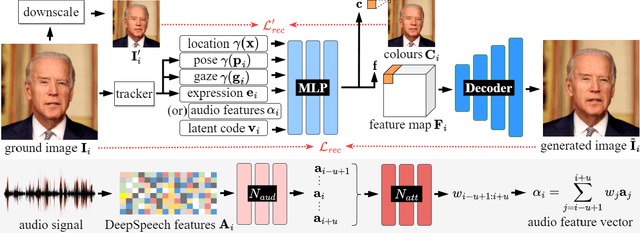
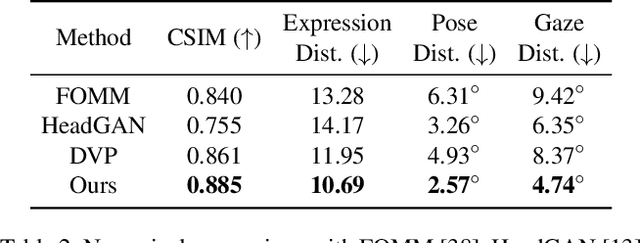
We present Dynamic Neural Portraits, a novel approach to the problem of full-head reenactment. Our method generates photo-realistic video portraits by explicitly controlling head pose, facial expressions and eye gaze. Our proposed architecture is different from existing methods that rely on GAN-based image-to-image translation networks for transforming renderings of 3D faces into photo-realistic images. Instead, we build our system upon a 2D coordinate-based MLP with controllable dynamics. Our intuition to adopt a 2D-based representation, as opposed to recent 3D NeRF-like systems, stems from the fact that video portraits are captured by monocular stationary cameras, therefore, only a single viewpoint of the scene is available. Primarily, we condition our generative model on expression blendshapes, nonetheless, we show that our system can be successfully driven by audio features as well. Our experiments demonstrate that the proposed method is 270 times faster than recent NeRF-based reenactment methods, with our networks achieving speeds of 24 fps for resolutions up to 1024 x 1024, while outperforming prior works in terms of visual quality.
Interpretable Semantic Photo Geolocalization
Apr 30, 2021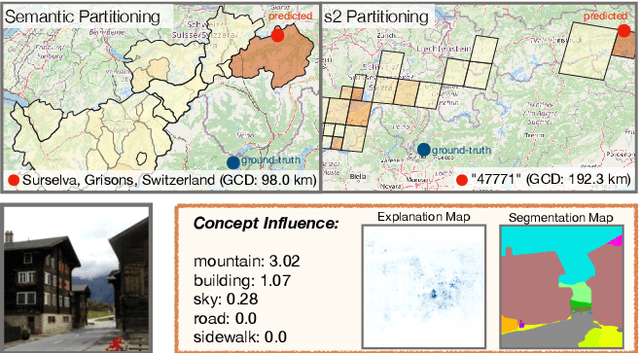

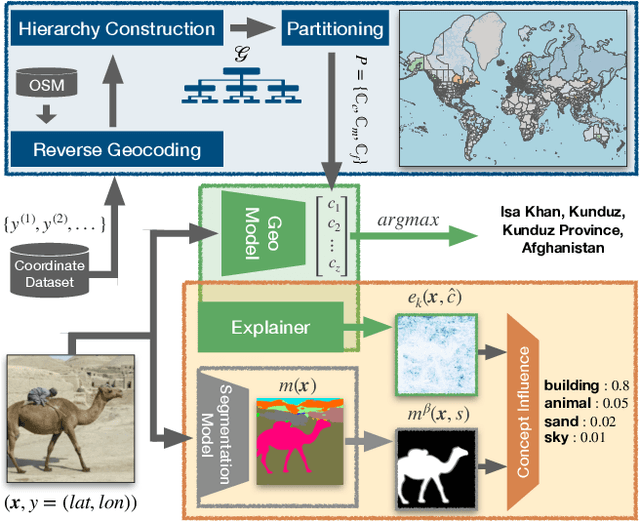
Planet-scale photo geolocalization is the complex task of estimating the location depicted in an image solely based on its visual content. Due to the success of convolutional neural networks (CNNs), current approaches achieve super-human performance. However, previous work has exclusively focused on optimizing geolocalization accuracy. Moreover, due to the black-box property of deep learning systems, their predictions are difficult to validate for humans. State-of-the-art methods treat the task as a classification problem, where the choice of the classes, that is the partitioning of the world map, is the key for success. In this paper, we present two contributions in order to improve the interpretability of a geolocalization model: (1) We propose a novel, semantic partitioning method which intuitively leads to an improved understanding of the predictions, while at the same time state-of-the-art results are achieved for geolocational accuracy on benchmark test sets; (2) We introduce a novel metric to assess the importance of semantic visual concepts for a certain prediction to provide additional interpretable information, which allows for a large-scale analysis of already trained models.
Debiased Fine-Tuning for Vision-language Models by Prompt Regularization
Jan 29, 2023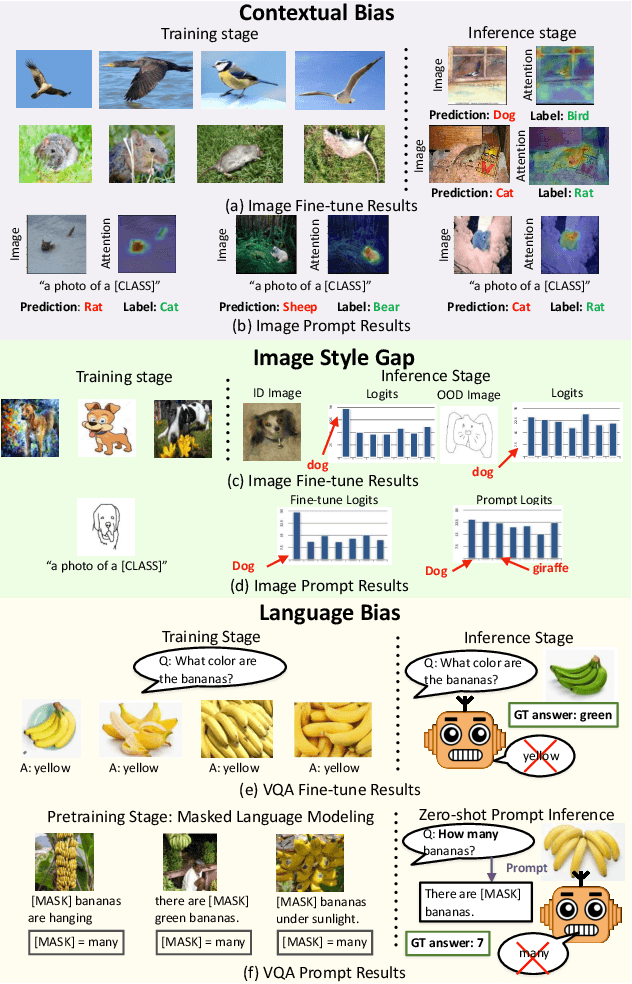
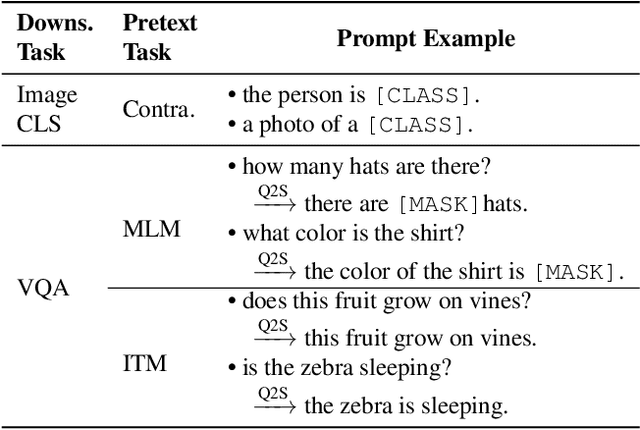
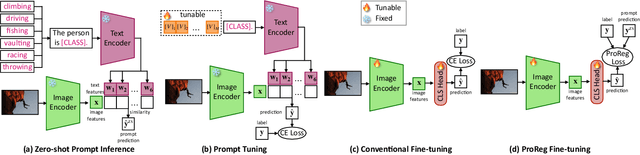
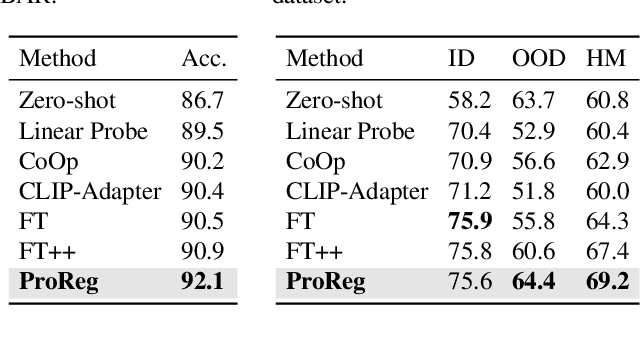
We present a new paradigm for fine-tuning large-scale visionlanguage pre-trained models on downstream task, dubbed Prompt Regularization (ProReg). Different from traditional fine-tuning which easily overfits to the downstream task data, ProReg uses the prediction by prompting the pretrained model to regularize the fine-tuning. The motivation is: by prompting the large model "a photo of a [CLASS]", the fil-lin answer is only dependent on the pretraining encyclopedic knowledge while independent of the task data distribution, which is usually biased. Specifically, given a training sample prediction during fine-tuning, we first calculate its KullbackLeibler loss of the prompt prediction and Cross-Entropy loss of the ground-truth label, and then combine them with a proposed sample-wise adaptive trade-off weight, which automatically adjusts the transfer between the pretrained and downstream domains. On various out-of-distribution benchmarks, we show the consistently strong performance of ProReg compared with conventional fine-tuning, zero-shot prompt, prompt tuning, and other state-of-the-art methods.
NEPHELE: A Neural Platform for Highly Realistic Cloud Radiance Rendering
Mar 07, 2023
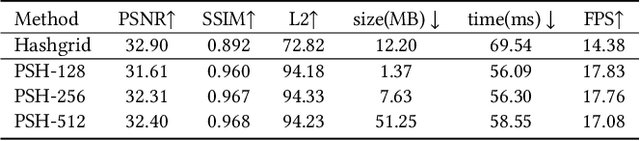
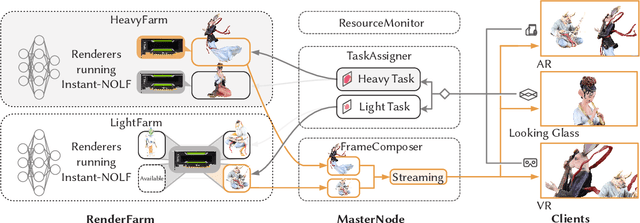
We have recently seen tremendous progress in neural rendering (NR) advances, i.e., NeRF, for photo-real free-view synthesis. Yet, as a local technique based on a single computer/GPU, even the best-engineered Instant-NGP or i-NGP cannot reach real-time performance when rendering at a high resolution, and often requires huge local computing resources. In this paper, we resort to cloud rendering and present NEPHELE, a neural platform for highly realistic cloud radiance rendering. In stark contrast with existing NR approaches, our NEPHELE allows for more powerful rendering capabilities by combining multiple remote GPUs and facilitates collaboration by allowing multiple people to view the same NeRF scene simultaneously. We introduce i-NOLF to employ opacity light fields for ultra-fast neural radiance rendering in a one-query-per-ray manner. We further resemble the Lumigraph with geometry proxies for fast ray querying and subsequently employ a small MLP to model the local opacity lumishperes for high-quality rendering. We also adopt Perfect Spatial Hashing in i-NOLF to enhance cache coherence. As a result, our i-NOLF achieves an order of magnitude performance gain in terms of efficiency than i-NGP, especially for the multi-user multi-viewpoint setting under cloud rendering scenarios. We further tailor a task scheduler accompanied by our i-NOLF representation and demonstrate the advance of our methodological design through a comprehensive cloud platform, consisting of a series of cooperated modules, i.e., render farms, task assigner, frame composer, and detailed streaming strategies. Using such a cloud platform compatible with neural rendering, we further showcase the capabilities of our cloud radiance rendering through a series of applications, ranging from cloud VR/AR rendering.
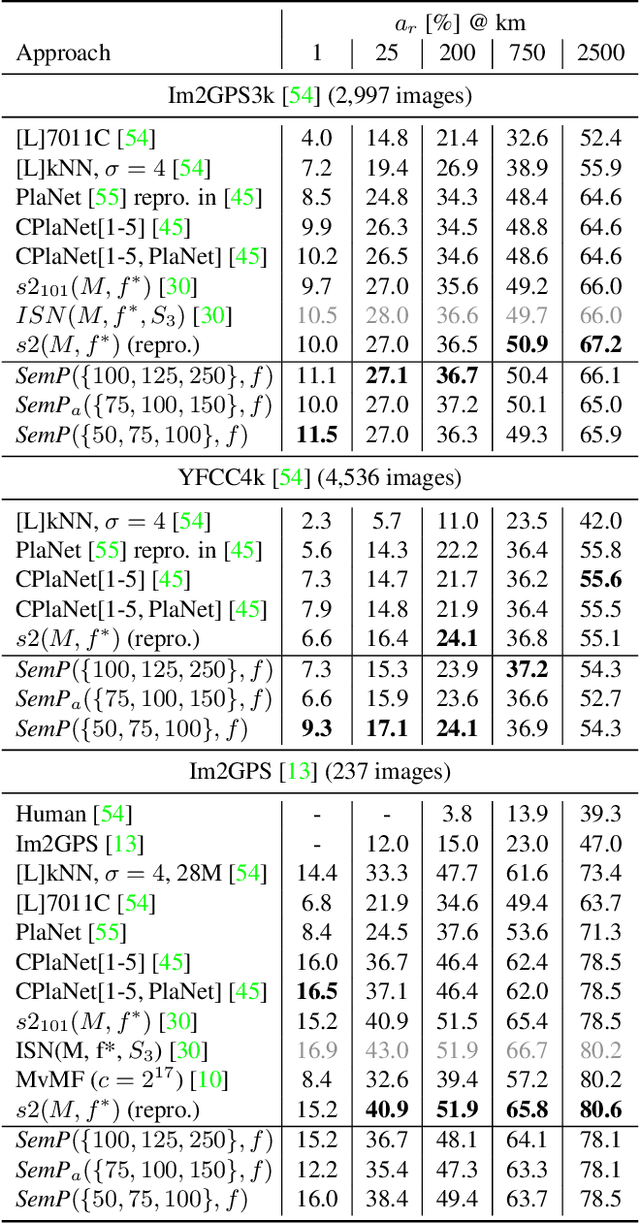
Where We Are and What We're Looking At: Query Based Worldwide Image Geo-localization Using Hierarchies and Scenes
Mar 07, 2023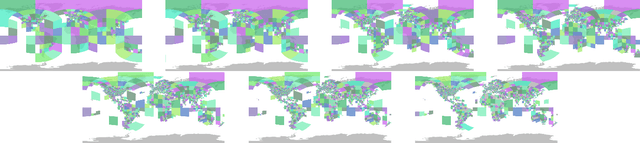
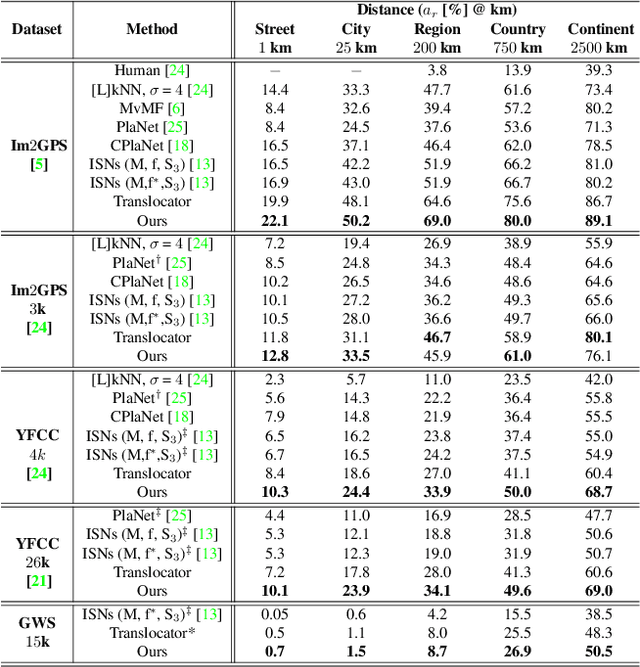

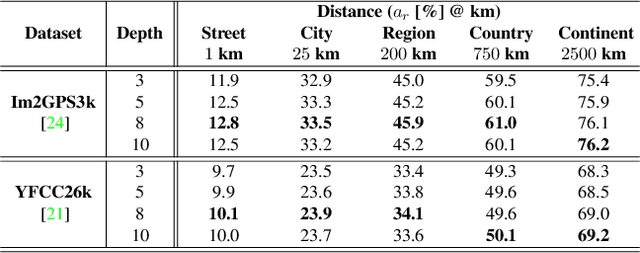
Determining the exact latitude and longitude that a photo was taken is a useful and widely applicable task, yet it remains exceptionally difficult despite the accelerated progress of other computer vision tasks. Most previous approaches have opted to learn a single representation of query images, which are then classified at different levels of geographic granularity. These approaches fail to exploit the different visual cues that give context to different hierarchies, such as the country, state, and city level. To this end, we introduce an end-to-end transformer-based architecture that exploits the relationship between different geographic levels (which we refer to as hierarchies) and the corresponding visual scene information in an image through hierarchical cross-attention. We achieve this by learning a query for each geographic hierarchy and scene type. Furthermore, we learn a separate representation for different environmental scenes, as different scenes in the same location are often defined by completely different visual features. We achieve state of the art street level accuracy on 4 standard geo-localization datasets : Im2GPS, Im2GPS3k, YFCC4k, and YFCC26k, as well as qualitatively demonstrate how our method learns different representations for different visual hierarchies and scenes, which has not been demonstrated in the previous methods. These previous testing datasets mostly consist of iconic landmarks or images taken from social media, which makes them either a memorization task, or biased towards certain places. To address this issue we introduce a much harder testing dataset, Google-World-Streets-15k, comprised of images taken from Google Streetview covering the whole planet and present state of the art results. Our code will be made available in the camera-ready version.
Aesthetic Photo Collage with Deep Reinforcement Learning
Oct 19, 2021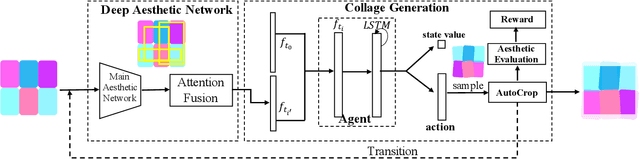



Photo collage aims to automatically arrange multiple photos on a given canvas with high aesthetic quality. Existing methods are based mainly on handcrafted feature optimization, which cannot adequately capture high-level human aesthetic senses. Deep learning provides a promising way, but owing to the complexity of collage and lack of training data, a solution has yet to be found. In this paper, we propose a novel pipeline for automatic generation of aspect ratio specified collage and the reinforcement learning technique is introduced in collage for the first time. Inspired by manual collages, we model the collage generation as sequential decision process to adjust spatial positions, orientation angles, placement order and the global layout. To instruct the agent to improve both the overall layout and local details, the reward function is specially designed for collage, considering subjective and objective factors. To overcome the lack of training data, we pretrain our deep aesthetic network on a large scale image aesthetic dataset (CPC) for general aesthetic feature extraction and propose an attention fusion module for structural collage feature representation. We test our model against competing methods on two movie datasets and our results outperform others in aesthetic quality evaluation. Further user study is also conducted to demonstrate the effectiveness.