 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
PETA: Photo Albums Event Recognition using Transformers Attention
Sep 26, 2021
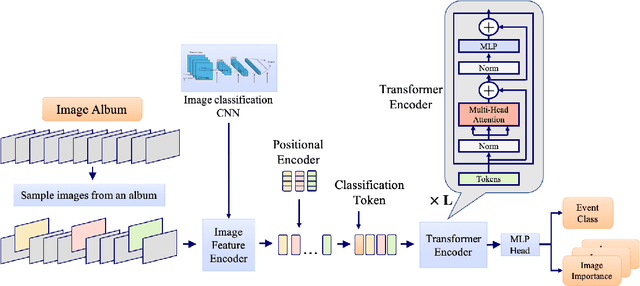
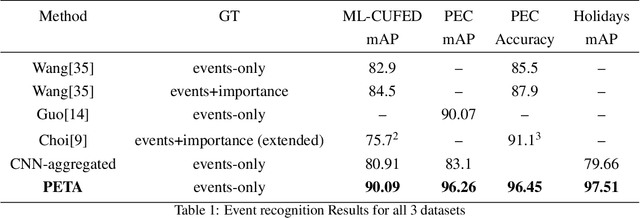

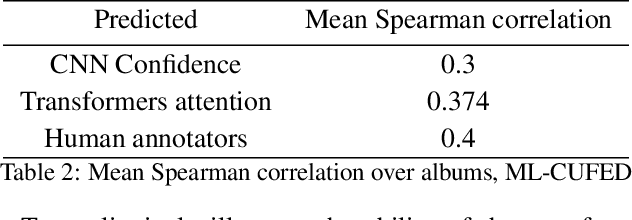
In recent years the amounts of personal photos captured increased significantly, giving rise to new challenges in multi-image understanding and high-level image understanding. Event recognition in personal photo albums presents one challenging scenario where life events are recognized from a disordered collection of images, including both relevant and irrelevant images. Event recognition in images also presents the challenge of high-level image understanding, as opposed to low-level image object classification. In absence of methods to analyze multiple inputs, previous methods adopted temporal mechanisms, including various forms of recurrent neural networks. However, their effective temporal window is local. In addition, they are not a natural choice given the disordered characteristic of photo albums. We address this gap with a tailor-made solution, combining the power of CNNs for image representation and transformers for album representation to perform global reasoning on image collection, offering a practical and efficient solution for photo albums event recognition. Our solution reaches state-of-the-art results on 3 prominent benchmarks, achieving above 90\% mAP on all datasets. We further explore the related image-importance task in event recognition, demonstrating how the learned attentions correlate with the human-annotated importance for this subjective task, thus opening the door for new applications.
ViP-NeRF: Visibility Prior for Sparse Input Neural Radiance Fields
Apr 28, 2023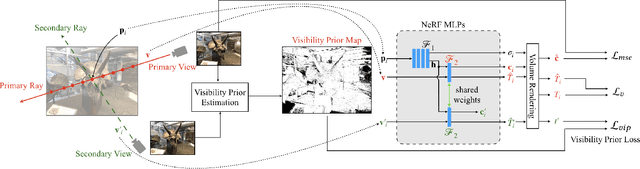
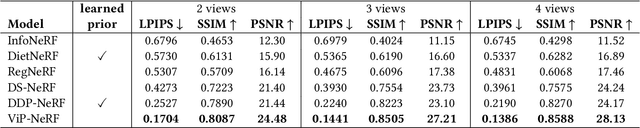
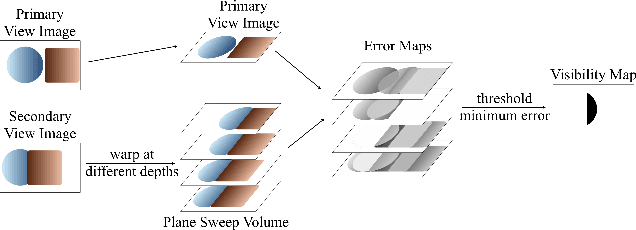
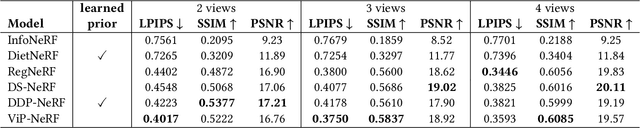
Neural radiance fields (NeRF) have achieved impressive performances in view synthesis by encoding neural representations of a scene. However, NeRFs require hundreds of images per scene to synthesize photo-realistic novel views. Training them on sparse input views leads to overfitting and incorrect scene depth estimation resulting in artifacts in the rendered novel views. Sparse input NeRFs were recently regularized by providing dense depth estimated from pre-trained networks as supervision, to achieve improved performance over sparse depth constraints. However, we find that such depth priors may be inaccurate due to generalization issues. Instead, we hypothesize that the visibility of pixels in different input views can be more reliably estimated to provide dense supervision. In this regard, we compute a visibility prior through the use of plane sweep volumes, which does not require any pre-training. By regularizing the NeRF training with the visibility prior, we successfully train the NeRF with few input views. We reformulate the NeRF to also directly output the visibility of a 3D point from a given viewpoint to reduce the training time with the visibility constraint. On multiple datasets, our model outperforms the competing sparse input NeRF models including those that use learned priors. The source code for our model can be found on our project page: https://nagabhushansn95.github.io/publications/2023/ViP-NeRF.html.
Adversarial Open Domain Adaption Framework (AODA): Sketch-to-Photo Synthesis
Jul 28, 2021

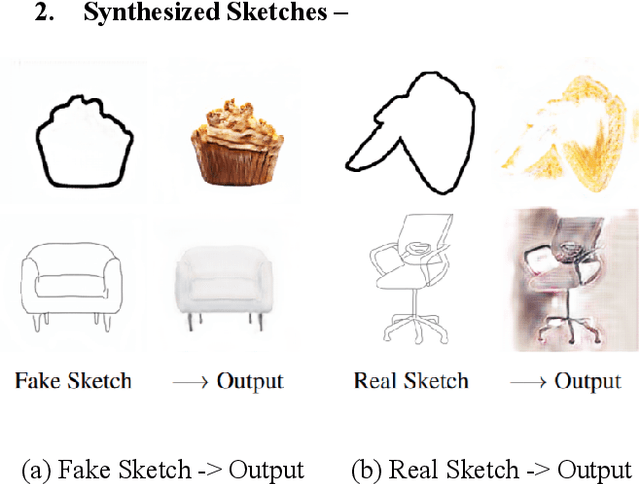
This paper aims to demonstrate the efficiency of the Adversarial Open Domain Adaption framework for sketch-to-photo synthesis. The unsupervised open domain adaption for generating realistic photos from a hand-drawn sketch is challenging as there is no such sketch of that class for training data. The absence of learning supervision and the huge domain gap between both the freehand drawing and picture domains make it hard. We present an approach that learns both sketch-to-photo and photo-to-sketch generation to synthesise the missing freehand drawings from pictures. Due to the domain gap between synthetic sketches and genuine ones, the generator trained on false drawings may produce unsatisfactory results when dealing with drawings of lacking classes. To address this problem, we offer a simple but effective open-domain sampling and optimization method that tricks the generator into considering false drawings as genuine. Our approach generalises the learnt sketch-to-photo and photo-to-sketch mappings from in-domain input to open-domain categories. On the Scribble and SketchyCOCO datasets, we compared our technique to the most current competing methods. For many types of open-domain drawings, our model outperforms impressive results in synthesising accurate colour, substance, and retaining the structural layout.
Multi-Camera Visual-Inertial Simultaneous Localization and Mapping for Autonomous Valet Parking
Apr 27, 2023
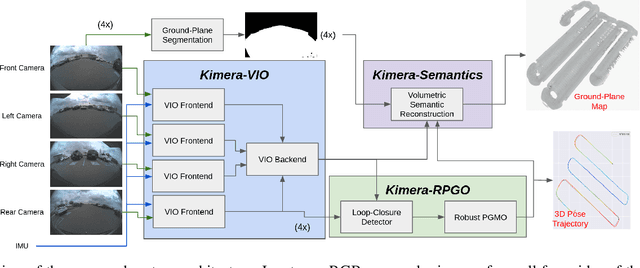
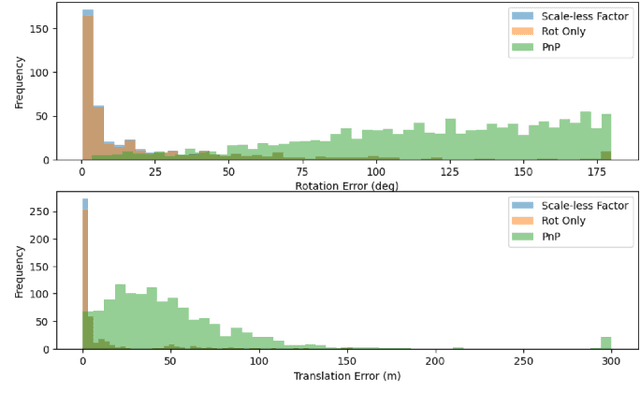
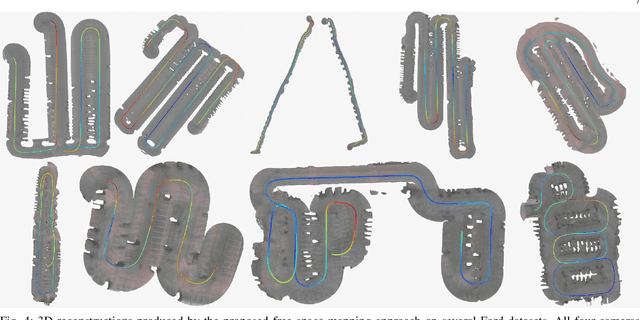
Localization and mapping are key capabilities for self-driving vehicles. This paper describes a visual-inertial SLAM system that estimates an accurate and globally consistent trajectory of the vehicle and reconstructs a dense model of the free space surrounding the car. Towards this goal, we build on Kimera and extend it to use multiple cameras as well as external (e.g. wheel) odometry sensors, to obtain accurate and robust odometry estimates in real-world problems. Additionally, we propose an effective scheme for closing loops that circumvents the drawbacks of common alternatives based on the Perspective-n-Point method and also works with a single monocular camera. Finally, we develop a method for dense 3D mapping of the free space that combines a segmentation network for free-space detection with a homography-based dense mapping technique. We test our system on photo-realistic simulations and on several real datasets collected by a car prototype developed by the Ford Motor Company, spanning both indoor and outdoor parking scenarios. Our multi-camera system is shown to outperform state-of-the art open-source visual-inertial-SLAM pipelines (Vins-Fusion, ORB-SLAM3), and exhibits an average trajectory error under 1% of the trajectory length across more than 8 km of distance traveled (combined across all datasets). A video showcasing the system is available here: youtu.be/H8CpzDpXOI8
Audio-Driven Talking Face Generation with Diverse yet Realistic Facial Animations
Apr 18, 2023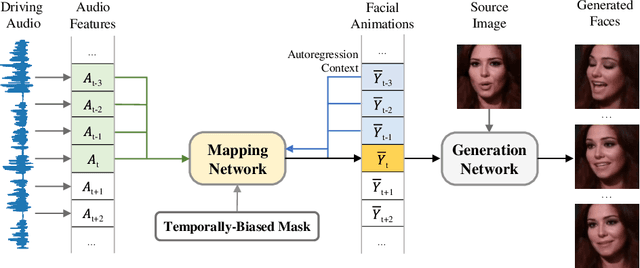
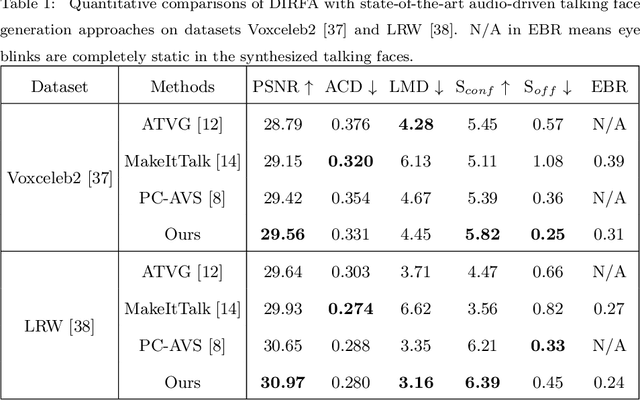

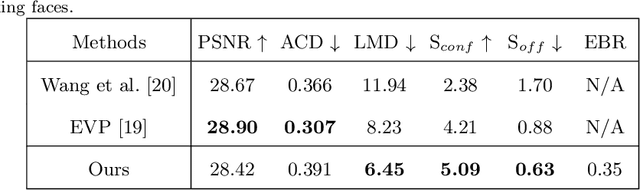
Audio-driven talking face generation, which aims to synthesize talking faces with realistic facial animations (including accurate lip movements, vivid facial expression details and natural head poses) corresponding to the audio, has achieved rapid progress in recent years. However, most existing work focuses on generating lip movements only without handling the closely correlated facial expressions, which degrades the realism of the generated faces greatly. This paper presents DIRFA, a novel method that can generate talking faces with diverse yet realistic facial animations from the same driving audio. To accommodate fair variation of plausible facial animations for the same audio, we design a transformer-based probabilistic mapping network that can model the variational facial animation distribution conditioned upon the input audio and autoregressively convert the audio signals into a facial animation sequence. In addition, we introduce a temporally-biased mask into the mapping network, which allows to model the temporal dependency of facial animations and produce temporally smooth facial animation sequence. With the generated facial animation sequence and a source image, photo-realistic talking faces can be synthesized with a generic generation network. Extensive experiments show that DIRFA can generate talking faces with realistic facial animations effectively.
Foundations of Spatial Perception for Robotics: Hierarchical Representations and Real-time Systems
May 11, 2023
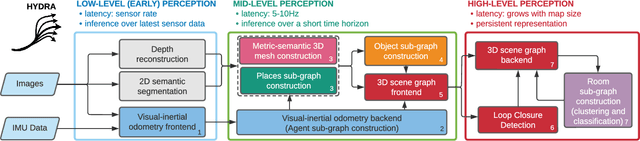

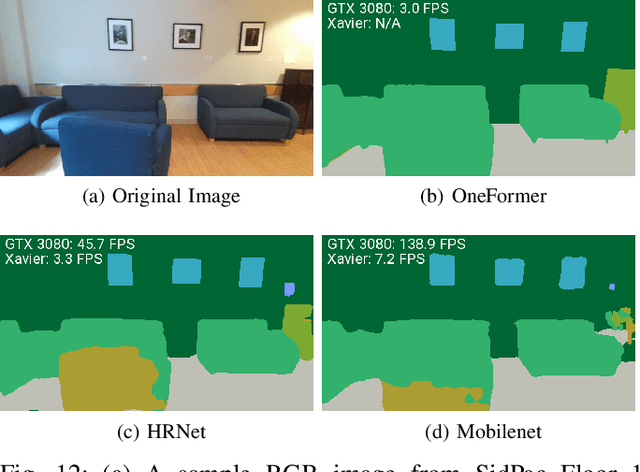
3D spatial perception is the problem of building and maintaining an actionable and persistent representation of the environment in real-time using sensor data and prior knowledge. Despite the fast-paced progress in robot perception, most existing methods either build purely geometric maps (as in traditional SLAM) or flat metric-semantic maps that do not scale to large environments or large dictionaries of semantic labels. The first part of this paper is concerned with representations: we show that scalable representations for spatial perception need to be hierarchical in nature. Hierarchical representations are efficient to store, and lead to layered graphs with small treewidth, which enable provably efficient inference. We then introduce an example of hierarchical representation for indoor environments, namely a 3D scene graph, and discuss its structure and properties. The second part of the paper focuses on algorithms to incrementally construct a 3D scene graph as the robot explores the environment. Our algorithms combine 3D geometry, topology (to cluster the places into rooms), and geometric deep learning (e.g., to classify the type of rooms the robot is moving across). The third part of the paper focuses on algorithms to maintain and correct 3D scene graphs during long-term operation. We propose hierarchical descriptors for loop closure detection and describe how to correct a scene graph in response to loop closures, by solving a 3D scene graph optimization problem. We conclude the paper by combining the proposed perception algorithms into Hydra, a real-time spatial perception system that builds a 3D scene graph from visual-inertial data in real-time. We showcase Hydra's performance in photo-realistic simulations and real data collected by a Clearpath Jackal robots and a Unitree A1 robot. We release an open-source implementation of Hydra at https://github.com/MIT-SPARK/Hydra.
Zero-Shot Text-to-Parameter Translation for Game Character Auto-Creation
Mar 02, 2023
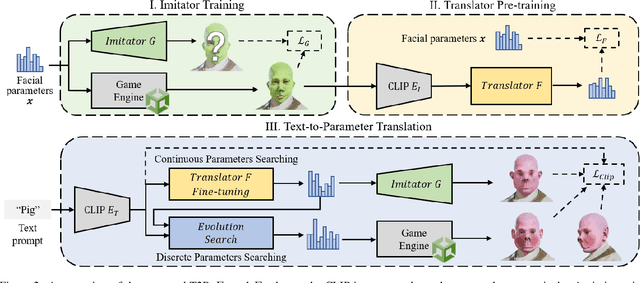

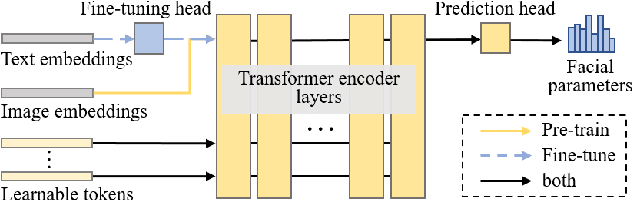
Recent popular Role-Playing Games (RPGs) saw the great success of character auto-creation systems. The bone-driven face model controlled by continuous parameters (like the position of bones) and discrete parameters (like the hairstyles) makes it possible for users to personalize and customize in-game characters. Previous in-game character auto-creation systems are mostly image-driven, where facial parameters are optimized so that the rendered character looks similar to the reference face photo. This paper proposes a novel text-to-parameter translation method (T2P) to achieve zero-shot text-driven game character auto-creation. With our method, users can create a vivid in-game character with arbitrary text description without using any reference photo or editing hundreds of parameters manually. In our method, taking the power of large-scale pre-trained multi-modal CLIP and neural rendering, T2P searches both continuous facial parameters and discrete facial parameters in a unified framework. Due to the discontinuous parameter representation, previous methods have difficulty in effectively learning discrete facial parameters. T2P, to our best knowledge, is the first method that can handle the optimization of both discrete and continuous parameters. Experimental results show that T2P can generate high-quality and vivid game characters with given text prompts. T2P outperforms other SOTA text-to-3D generation methods on both objective evaluations and subjective evaluations.
Face Animation with an Attribute-Guided Diffusion Model
Apr 06, 2023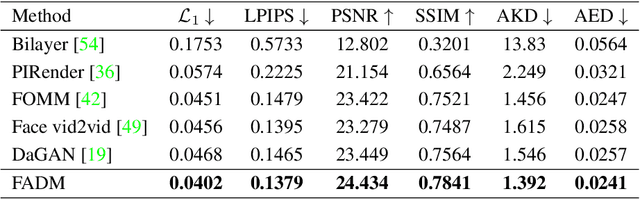
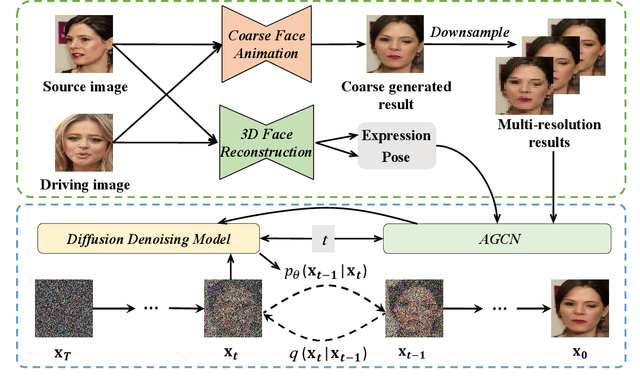
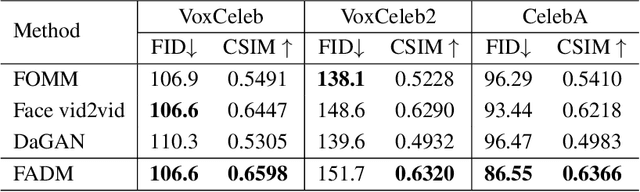
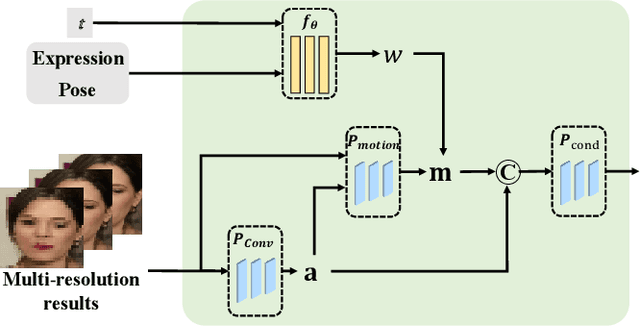
Face animation has achieved much progress in computer vision. However, prevailing GAN-based methods suffer from unnatural distortions and artifacts due to sophisticated motion deformation. In this paper, we propose a Face Animation framework with an attribute-guided Diffusion Model (FADM), which is the first work to exploit the superior modeling capacity of diffusion models for photo-realistic talking-head generation. To mitigate the uncontrollable synthesis effect of the diffusion model, we design an Attribute-Guided Conditioning Network (AGCN) to adaptively combine the coarse animation features and 3D face reconstruction results, which can incorporate appearance and motion conditions into the diffusion process. These specific designs help FADM rectify unnatural artifacts and distortions, and also enrich high-fidelity facial details through iterative diffusion refinements with accurate animation attributes. FADM can flexibly and effectively improve existing animation videos. Extensive experiments on widely used talking-head benchmarks validate the effectiveness of FADM over prior arts.
Deep Photo Cropper and Enhancer
Aug 03, 2020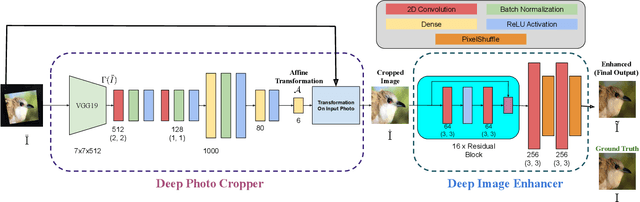


This paper introduces a new type of image enhancement problem. Compared to traditional image enhancement methods, which mostly deal with pixel-wise modifications of a given photo, our proposed task is to crop an image which is embedded within a photo and enhance the quality of the cropped image. We split our proposed approach into two deep networks: deep photo cropper and deep image enhancer. In the photo cropper network, we employ a spatial transformer to extract the embedded image. In the photo enhancer, we employ super-resolution to increase the number of pixels in the embedded image and reduce the effect of stretching and distortion of pixels. We use cosine distance loss between image features and ground truth for the cropper and the mean square loss for the enhancer. Furthermore, we propose a new dataset to train and test the proposed method. Finally, we analyze the proposed method with respect to qualitative and quantitative evaluations.
Sketch Less Face Image Retrieval: A New Challenge
Feb 11, 2023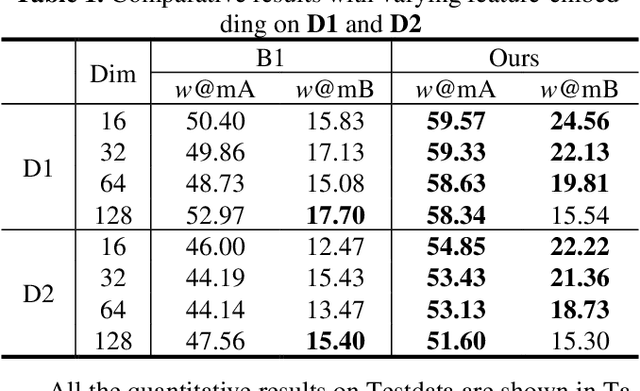
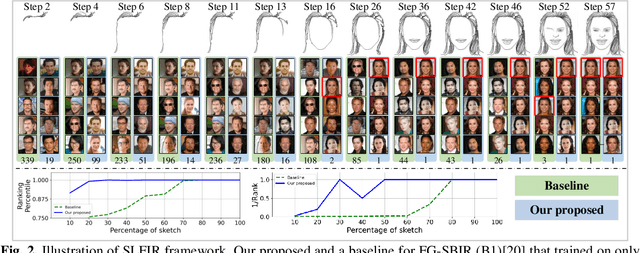
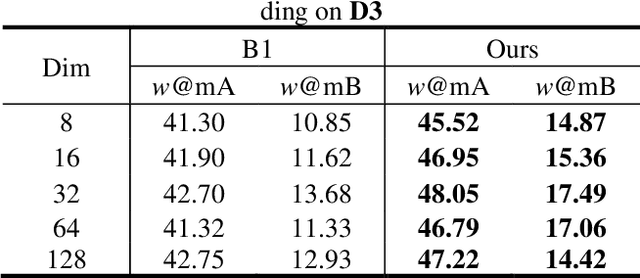
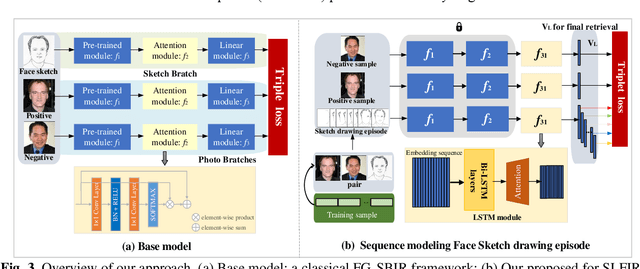
In some specific scenarios, face sketch was used to identify a person. However, drawing a complete face sketch often needs skills and takes time, which hinder its widespread applicability in the practice. In this study, we proposed a new task named sketch less face image retrieval (SLFIR), in which the retrieval was carried out at each stroke and aim to retrieve the target face photo using a partial sketch with as few strokes as possible (see Fig.1). Firstly, we developed a method to generate the data of sketch with drawing process, and opened such dataset; Secondly, we proposed a two-stage method as the baseline for SLFIR that (1) A triplet network, was first adopt to learn the joint embedding space shared between the complete sketch and its target face photo; (2) Regarding the sketch drawing episode as a sequence, we designed a LSTM module to optimize the representation of the incomplete face sketch. Experiments indicate that the new framework can finish the retrieval using a partial or pool drawing sketch.