 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
Album Storytelling with Iterative Story-aware Captioning and Large Language Models
May 24, 2023

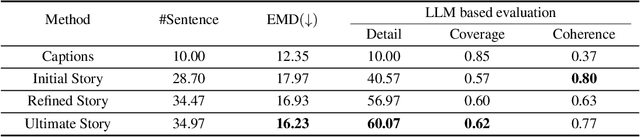
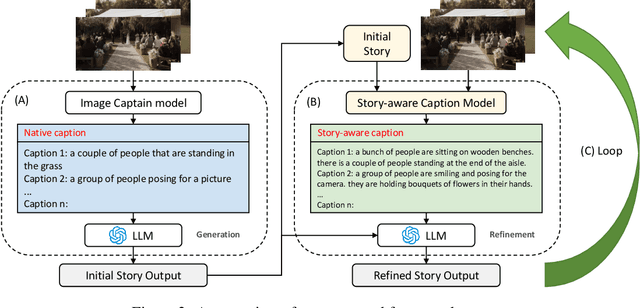

This work studies how to transform an album to vivid and coherent stories, a task we refer to as "album storytelling". While this task can help preserve memories and facilitate experience sharing, it remains an underexplored area in current literature. With recent advances in Large Language Models (LLMs), it is now possible to generate lengthy, coherent text, opening up the opportunity to develop an AI assistant for album storytelling. One natural approach is to use caption models to describe each photo in the album, and then use LLMs to summarize and rewrite the generated captions into an engaging story. However, we find this often results in stories containing hallucinated information that contradicts the images, as each generated caption ("story-agnostic") is not always about the description related to the whole story or miss some necessary information. To address these limitations, we propose a new iterative album storytelling pipeline. Specifically, we start with an initial story and build a story-aware caption model to refine the captions using the whole story as guidance. The polished captions are then fed into the LLMs to generate a new refined story. This process is repeated iteratively until the story contains minimal factual errors while maintaining coherence. To evaluate our proposed pipeline, we introduce a new dataset of image collections from vlogs and a set of systematic evaluation metrics. Our results demonstrate that our method effectively generates more accurate and engaging stories for albums, with enhanced coherence and vividness.
NerfBridge: Bringing Real-time, Online Neural Radiance Field Training to Robotics
May 16, 2023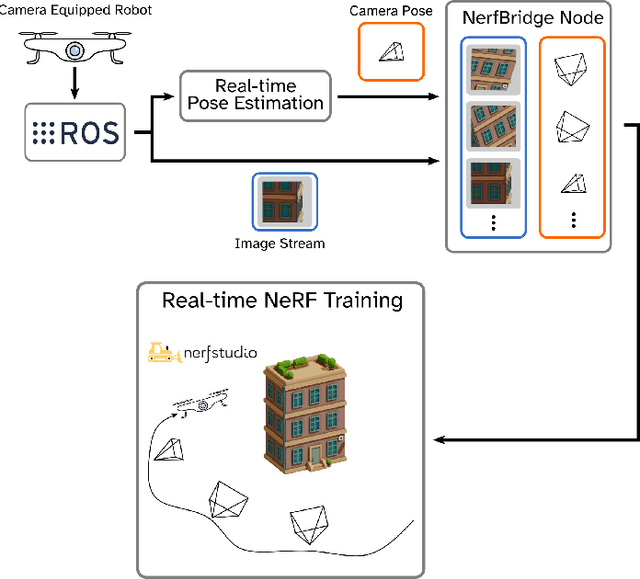


This work was presented at the IEEE International Conference on Robotics and Automation 2023 Workshop on Unconventional Spatial Representations. Neural radiance fields (NeRFs) are a class of implicit scene representations that model 3D environments from color images. NeRFs are expressive, and can model the complex and multi-scale geometry of real world environments, which potentially makes them a powerful tool for robotics applications. Modern NeRF training libraries can generate a photo-realistic NeRF from a static data set in just a few seconds, but are designed for offline use and require a slow pose optimization pre-computation step. In this work we propose NerfBridge, an open-source bridge between the Robot Operating System (ROS) and the popular Nerfstudio library for real-time, online training of NeRFs from a stream of images. NerfBridge enables rapid development of research on applications of NeRFs in robotics by providing an extensible interface to the efficient training pipelines and model libraries provided by Nerfstudio. As an example use case we outline a hardware setup that can be used NerfBridge to train a NeRF from images captured by a camera mounted to a quadrotor in both indoor and outdoor environments. For accompanying video https://youtu.be/EH0SLn-RcDg and code https://github.com/javieryu/nerf_bridge.
Face Photo-Sketch Recognition Using Bidirectional Collaborative Synthesis Network
Aug 23, 2021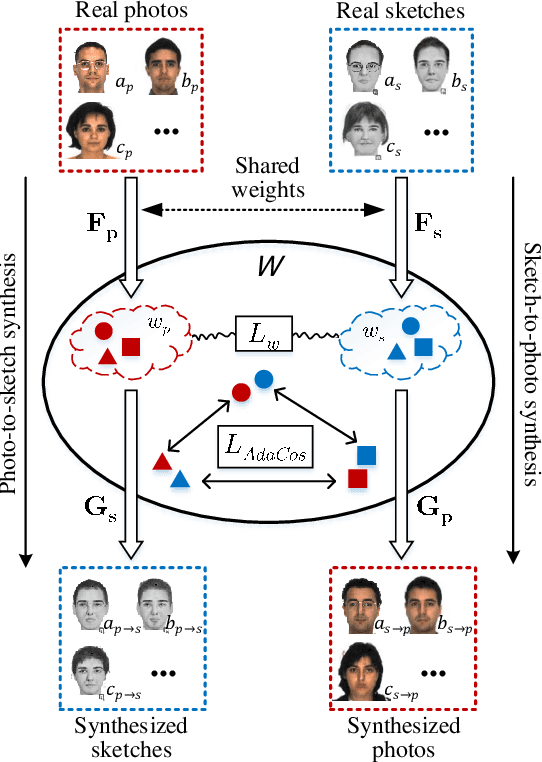
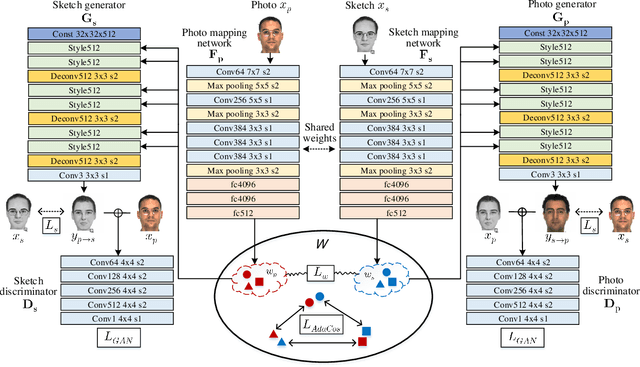
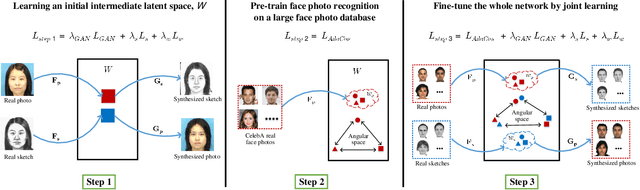

This research features a deep-learning based framework to address the problem of matching a given face sketch image against a face photo database. The problem of photo-sketch matching is challenging because 1) there is large modality gap between photo and sketch, and 2) the number of paired training samples is insufficient to train deep learning based networks. To circumvent the problem of large modality gap, our approach is to use an intermediate latent space between the two modalities. We effectively align the distributions of the two modalities in this latent space by employing a bidirectional (photo -> sketch and sketch -> photo) collaborative synthesis network. A StyleGAN-like architecture is utilized to make the intermediate latent space be equipped with rich representation power. To resolve the problem of insufficient training samples, we introduce a three-step training scheme. Extensive evaluation on public composite face sketch database confirms superior performance of our method compared to existing state-of-the-art methods. The proposed methodology can be employed in matching other modality pairs.
Text2NeRF: Text-Driven 3D Scene Generation with Neural Radiance Fields
May 19, 2023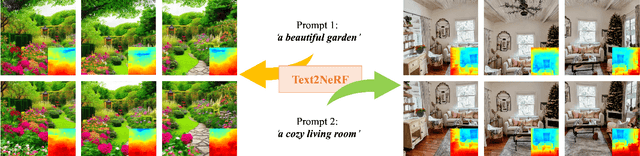

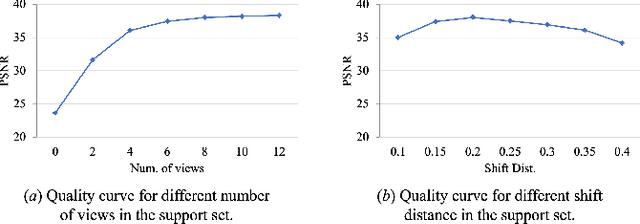

Text-driven 3D scene generation is widely applicable to video gaming, film industry, and metaverse applications that have a large demand for 3D scenes. However, existing text-to-3D generation methods are limited to producing 3D objects with simple geometries and dreamlike styles that lack realism. In this work, we present Text2NeRF, which is able to generate a wide range of 3D scenes with complicated geometric structures and high-fidelity textures purely from a text prompt. To this end, we adopt NeRF as the 3D representation and leverage a pre-trained text-to-image diffusion model to constrain the 3D reconstruction of the NeRF to reflect the scene description. Specifically, we employ the diffusion model to infer the text-related image as the content prior and use a monocular depth estimation method to offer the geometric prior. Both content and geometric priors are utilized to update the NeRF model. To guarantee textured and geometric consistency between different views, we introduce a progressive scene inpainting and updating strategy for novel view synthesis of the scene. Our method requires no additional training data but only a natural language description of the scene as the input. Extensive experiments demonstrate that our Text2NeRF outperforms existing methods in producing photo-realistic, multi-view consistent, and diverse 3D scenes from a variety of natural language prompts.
Synthetic Data from Diffusion Models Improves ImageNet Classification
Apr 17, 2023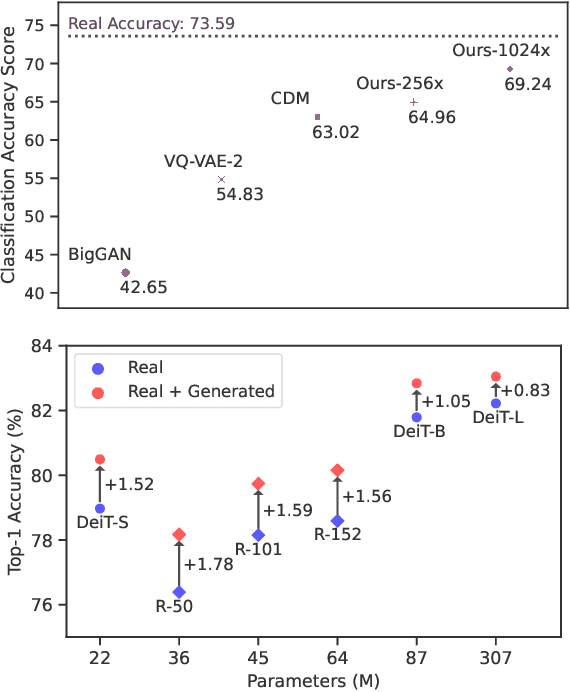
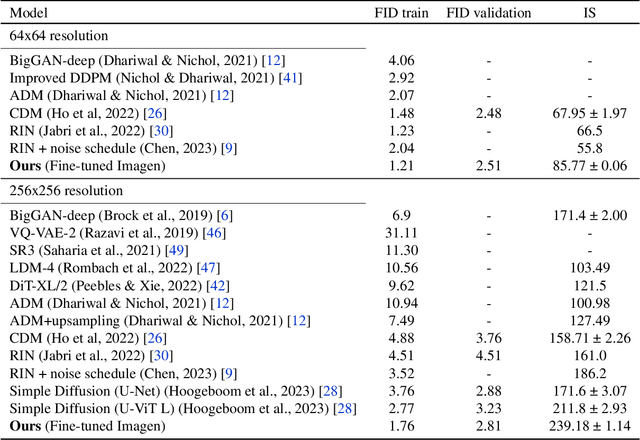

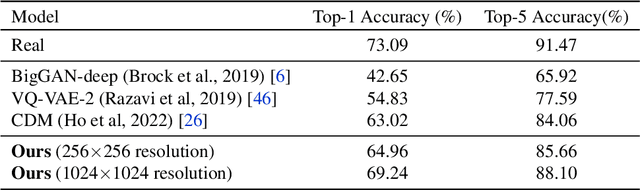
Deep generative models are becoming increasingly powerful, now generating diverse high fidelity photo-realistic samples given text prompts. Have they reached the point where models of natural images can be used for generative data augmentation, helping to improve challenging discriminative tasks? We show that large-scale text-to image diffusion models can be fine-tuned to produce class conditional models with SOTA FID (1.76 at 256x256 resolution) and Inception Score (239 at 256x256). The model also yields a new SOTA in Classification Accuracy Scores (64.96 for 256x256 generative samples, improving to 69.24 for 1024x1024 samples). Augmenting the ImageNet training set with samples from the resulting models yields significant improvements in ImageNet classification accuracy over strong ResNet and Vision Transformer baselines.
Adapt and Align to Improve Zero-Shot Sketch-Based Image Retrieval
May 09, 2023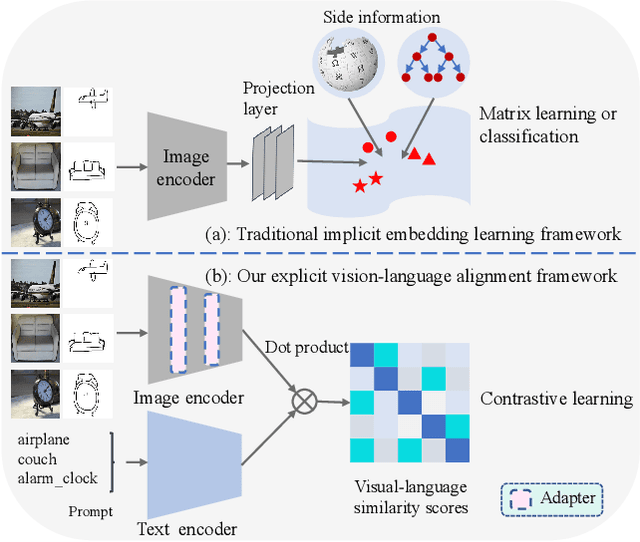
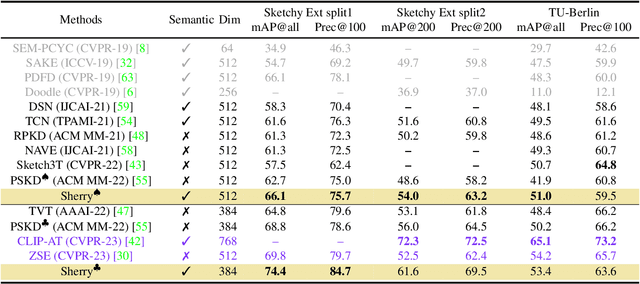
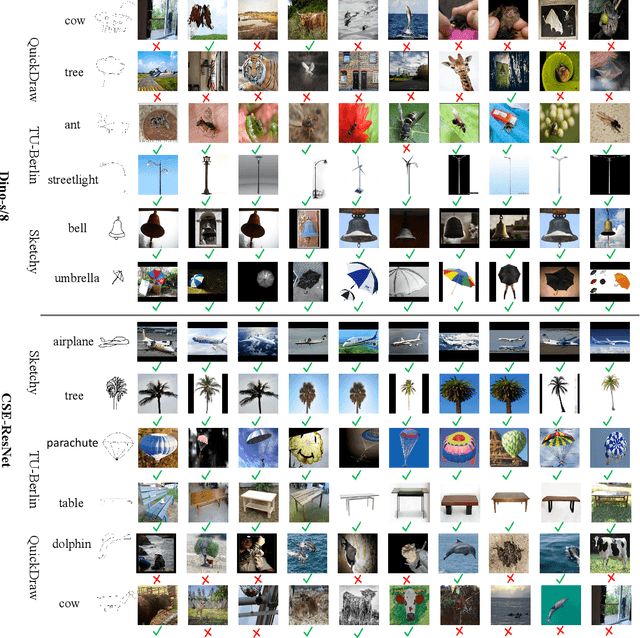
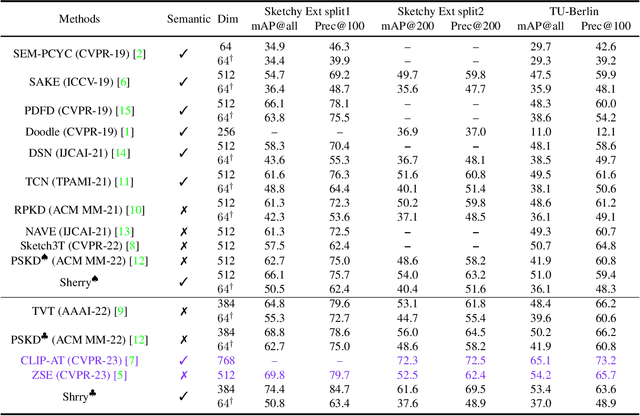
Zero-shot sketch-based image retrieval (ZS-SBIR) is challenging due to the cross-domain nature of sketches and photos, as well as the semantic gap between seen and unseen image distributions. Previous methods fine-tune pre-trained models with various side information and learning strategies to learn a compact feature space that (\romannumeral1) is shared between the sketch and photo domains and (\romannumeral2) bridges seen and unseen classes. However, these efforts are inadequate in adapting domains and transferring knowledge from seen to unseen classes. In this paper, we present an effective \emph{``Adapt and Align''} approach to address the key challenges. Specifically, we insert simple and lightweight domain adapters to learn new abstract concepts of the sketch domain and improve cross-domain representation capabilities. Inspired by recent advances in image-text foundation models (\textit{e.g.}, CLIP) on zero-shot scenarios, we explicitly align the learned image embedding with a more semantic text embedding to achieve the desired knowledge transfer from seen to unseen classes. Extensive experiments on three benchmark datasets and two popular backbones demonstrate the superiority of our method in terms of retrieval accuracy and flexibility.
AvatarReX: Real-time Expressive Full-body Avatars
May 08, 2023

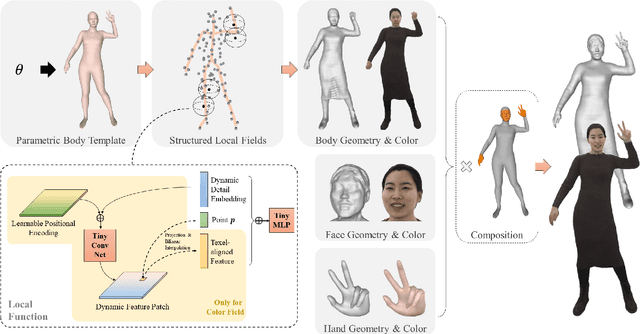
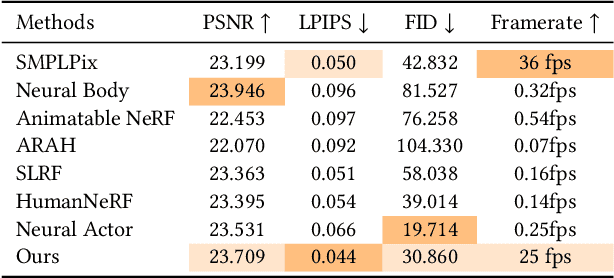
We present AvatarReX, a new method for learning NeRF-based full-body avatars from video data. The learnt avatar not only provides expressive control of the body, hands and the face together, but also supports real-time animation and rendering. To this end, we propose a compositional avatar representation, where the body, hands and the face are separately modeled in a way that the structural prior from parametric mesh templates is properly utilized without compromising representation flexibility. Furthermore, we disentangle the geometry and appearance for each part. With these technical designs, we propose a dedicated deferred rendering pipeline, which can be executed in real-time framerate to synthesize high-quality free-view images. The disentanglement of geometry and appearance also allows us to design a two-pass training strategy that combines volume rendering and surface rendering for network training. In this way, patch-level supervision can be applied to force the network to learn sharp appearance details on the basis of geometry estimation. Overall, our method enables automatic construction of expressive full-body avatars with real-time rendering capability, and can generate photo-realistic images with dynamic details for novel body motions and facial expressions.
SceneTrilogy: On Scene Sketches and its Relationship with Text and Photo
Apr 25, 2022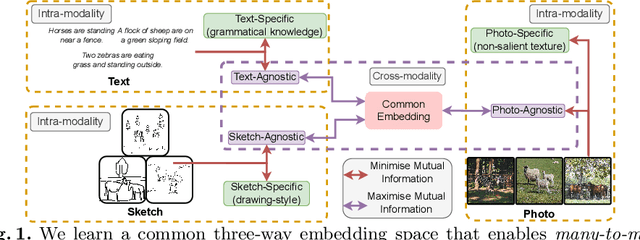
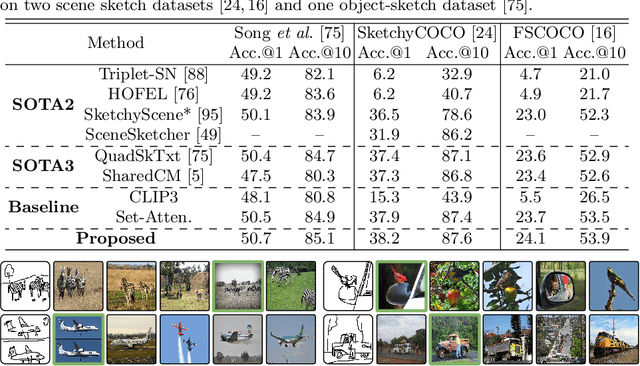
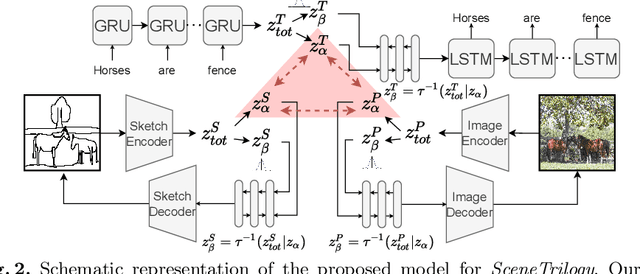

We for the first time extend multi-modal scene understanding to include that of free-hand scene sketches. This uniquely results in a trilogy of scene data modalities (sketch, text, and photo), where each offers unique perspectives for scene understanding, and together enable a series of novel scene-specific applications across discriminative (retrieval) and generative (captioning) tasks. Our key objective is to learn a common three-way embedding space that enables many-to-many modality interactions (e.g, sketch+text $\rightarrow$ photo retrieval). We importantly leverage the information bottleneck theory to achieve this goal, where we (i) decouple intra-modality information by minimising the mutual information between modality-specific and modality-agnostic components via a conditional invertible neural network, and (ii) align \textit{cross-modalities information} by maximising the mutual information between their modality-agnostic components using InfoNCE, with a specific multihead attention mechanism to allow many-to-many modality interactions. We spell out a few insights on the complementarity of each modality for scene understanding, and study for the first time a series of scene-specific applications like joint sketch- and text-based image retrieval, sketch captioning.
StyleGenes: Discrete and Efficient Latent Distributions for GANs
Apr 30, 2023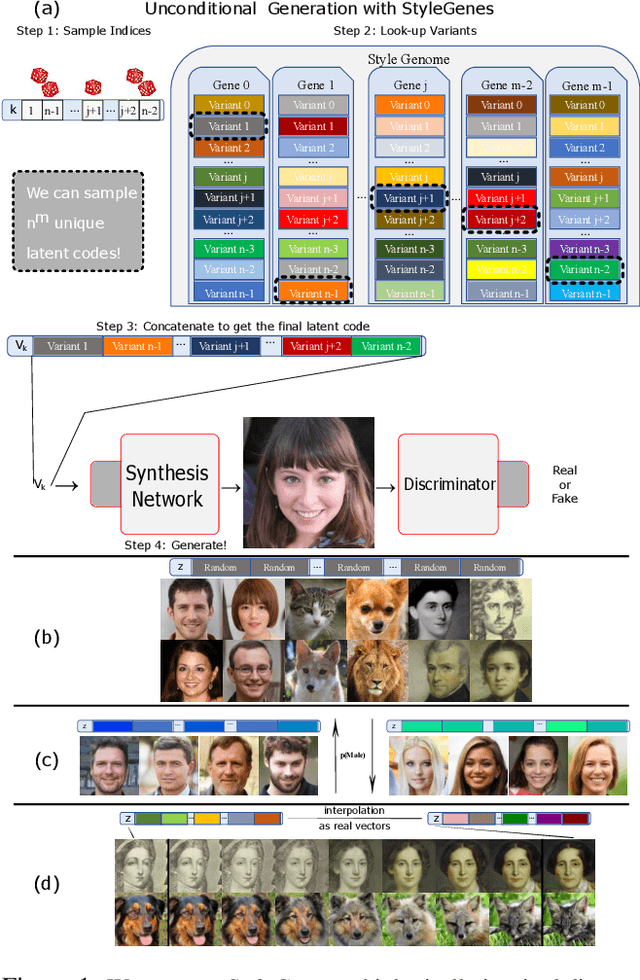


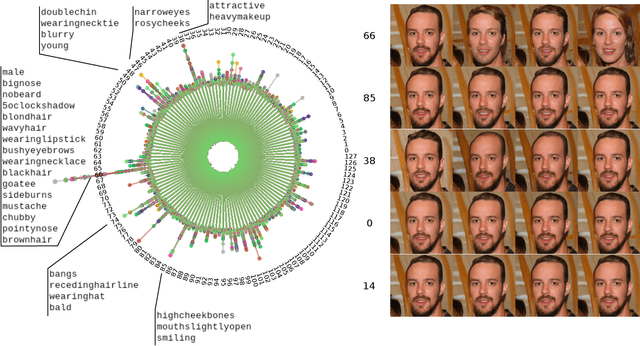
We propose a discrete latent distribution for Generative Adversarial Networks (GANs). Instead of drawing latent vectors from a continuous prior, we sample from a finite set of learnable latents. However, a direct parametrization of such a distribution leads to an intractable linear increase in memory in order to ensure sufficient sample diversity. We address this key issue by taking inspiration from the encoding of information in biological organisms. Instead of learning a separate latent vector for each sample, we split the latent space into a set of genes. For each gene, we train a small bank of gene variants. Thus, by independently sampling a variant for each gene and combining them into the final latent vector, our approach can represent a vast number of unique latent samples from a compact set of learnable parameters. Interestingly, our gene-inspired latent encoding allows for new and intuitive approaches to latent-space exploration, enabling conditional sampling from our unconditionally trained model. Moreover, our approach preserves state-of-the-art photo-realism while achieving better disentanglement than the widely-used StyleMapping network.
Learning Visibility Field for Detailed 3D Human Reconstruction and Relighting
Apr 24, 2023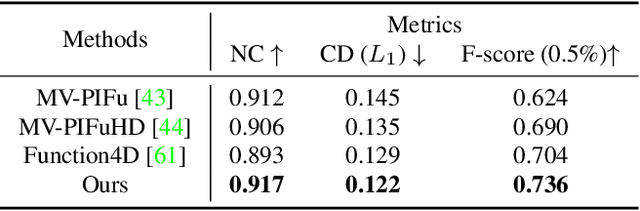

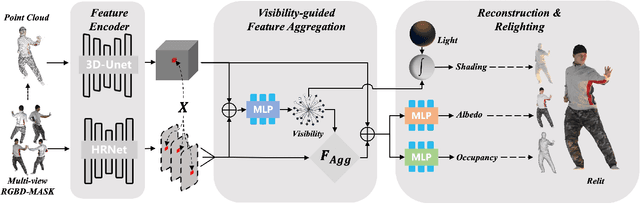
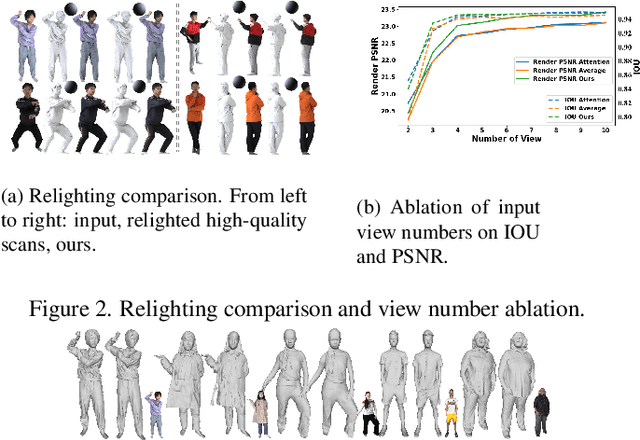
Detailed 3D reconstruction and photo-realistic relighting of digital humans are essential for various applications. To this end, we propose a novel sparse-view 3d human reconstruction framework that closely incorporates the occupancy field and albedo field with an additional visibility field--it not only resolves occlusion ambiguity in multiview feature aggregation, but can also be used to evaluate light attenuation for self-shadowed relighting. To enhance its training viability and efficiency, we discretize visibility onto a fixed set of sample directions and supply it with coupled geometric 3D depth feature and local 2D image feature. We further propose a novel rendering-inspired loss, namely TransferLoss, to implicitly enforce the alignment between visibility and occupancy field, enabling end-to-end joint training. Results and extensive experiments demonstrate the effectiveness of the proposed method, as it surpasses state-of-the-art in terms of reconstruction accuracy while achieving comparably accurate relighting to ray-traced ground truth.